Pourquoi transformer des DDS en SQL?
Une des raisons est que les index peuvent être beaucoup plus performants que les LF quand le moteur SQL les utilise.
Rappel
Pour transformer un PF en table
Vous devez extraire le source en utilisant l’API QSQGNDDL
Le plus simple est de passer par ACS
En faisant génération instruction SQL
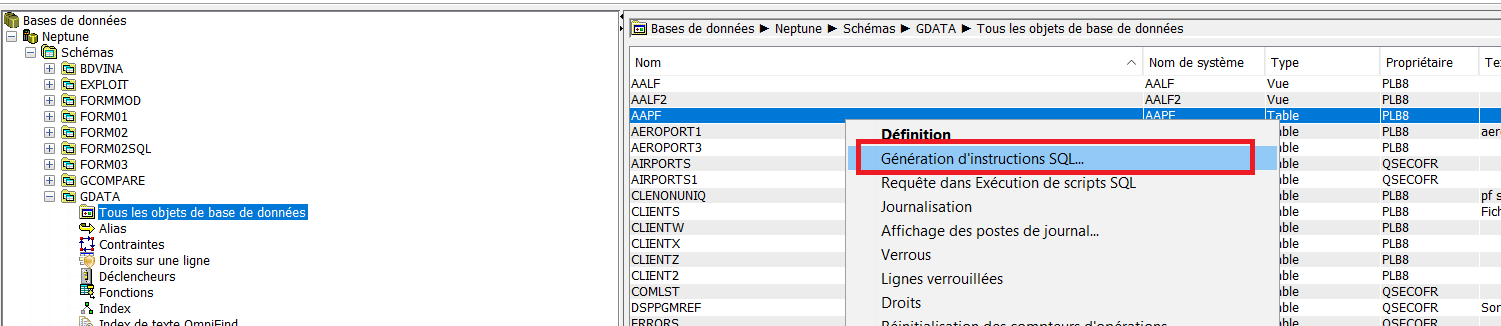
Vous obtenez le source SQL qu’il aurait fallu pour générer cette table.
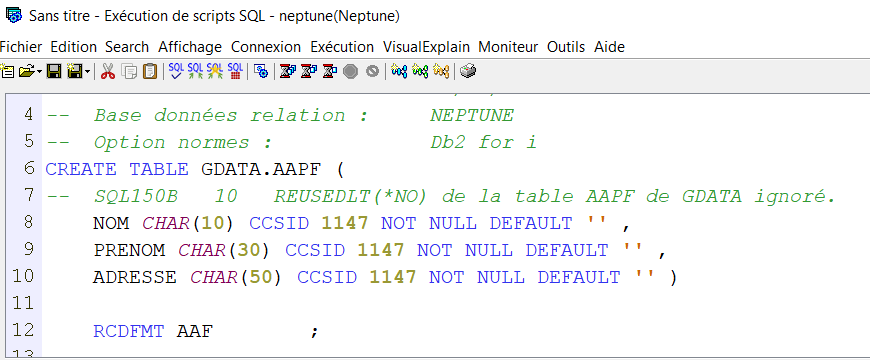
Attention tout n’est pas traduit (exemple un PF sans clé unique)
Pour transformer un LF en index sur nom par exemple

Si vous utilisez ACS, votre index est considéré comme une vue et si vous faites l’opération de génération SQL vous obtenez un source qui ne va pas vous servir à grand chose.
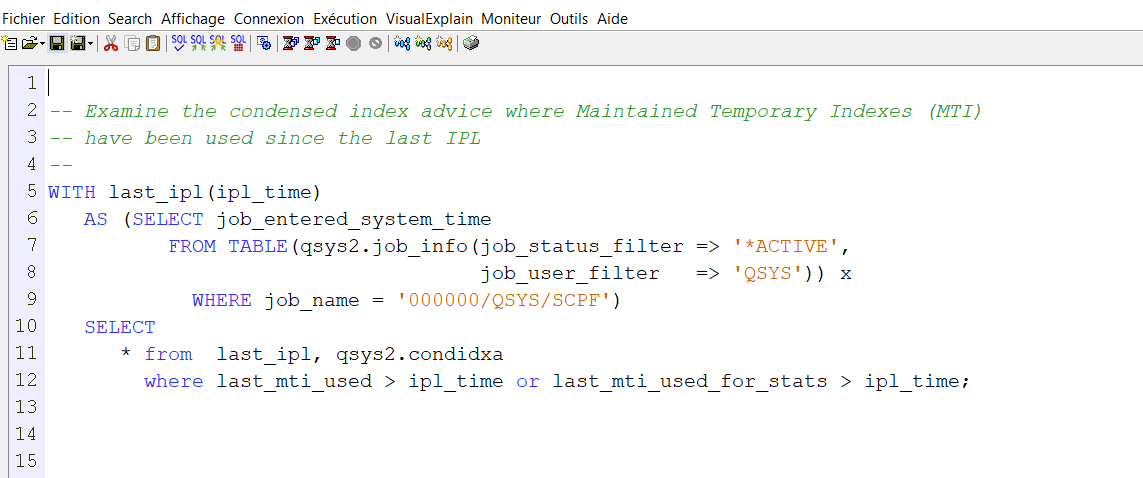
Remarque, par contre si vous regardez par Visual Explain vous voyez bien que le moteur utilise le PF comme un index.
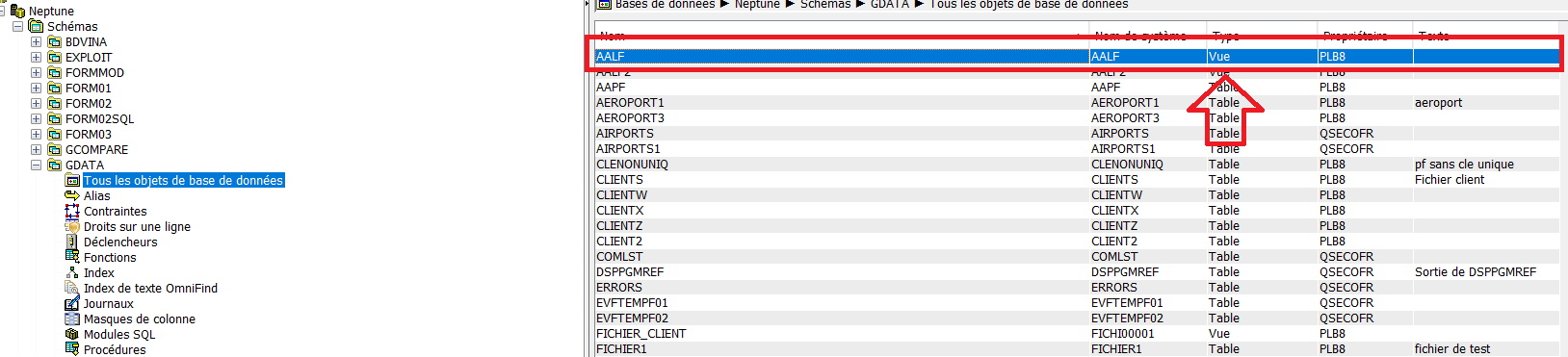
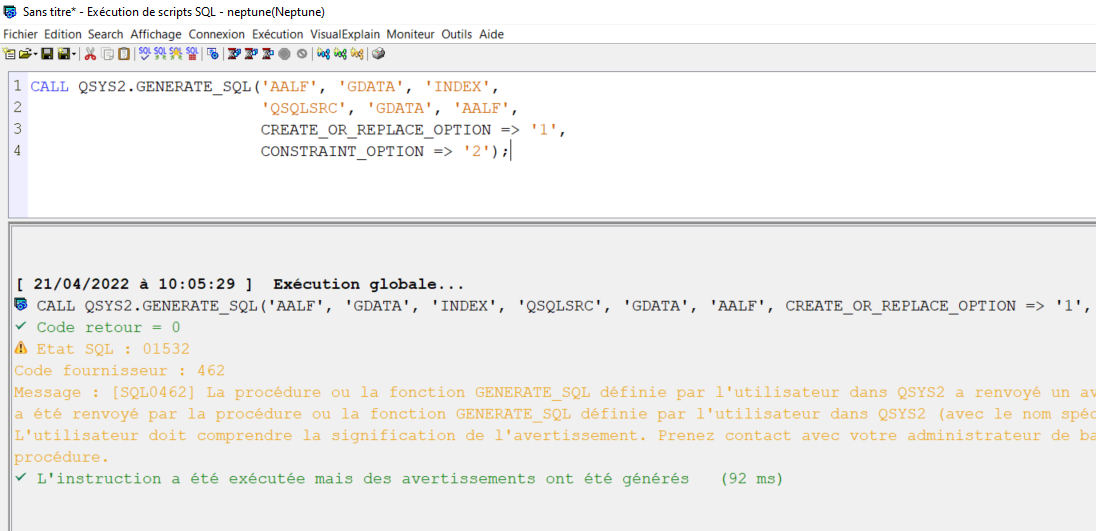
Si vous utilisez la procédure de QSYS2.GENERATE_SQL, même problème.
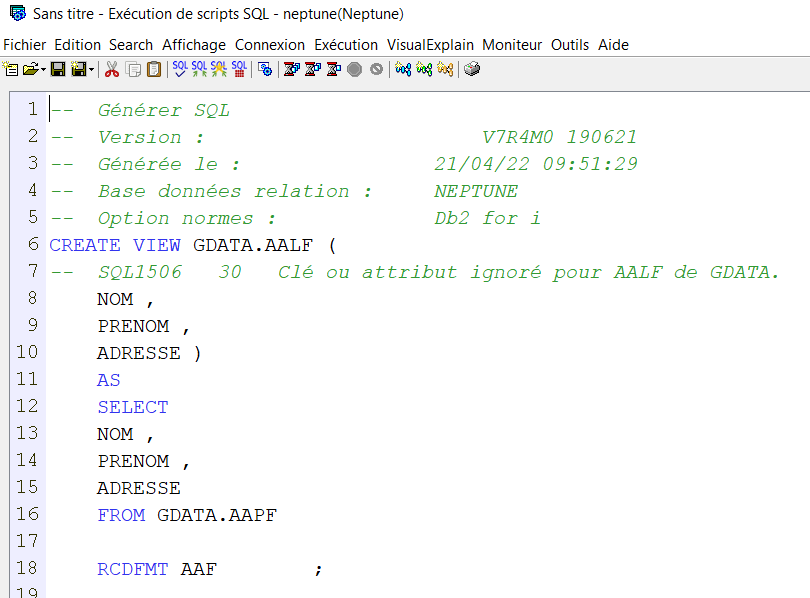
.
Si vous lui indiquez index, il ne trouve pas l’objet SQL
CALL QSYS2.GENERATE_SQL(‘AALF’, ‘GDATA’, ‘INDEX’,
‘QSQLSRC’, ‘GDATA’, ‘AALF’,
CREATE_OR_REPLACE_OPTION => ‘1’,
CONSTRAINT_OPTION => ‘2’);
La solution est donc passer directement par l’API système QSQGNDDL.
Pour vous aider, on a fait une commande RTVSQLSRC que vous pouvez trouver ici
https://github.com/Plberthoin/PLB/tree/master/GOUTILS
et là vous pouvez forcer le type INDEX
RTVSQLSRC FILE(GDATA/AALF) SRCFILE(GDATA/QSQLSRC) TYPSQL(INDEX)
et là vous obtenez le source qui va bien
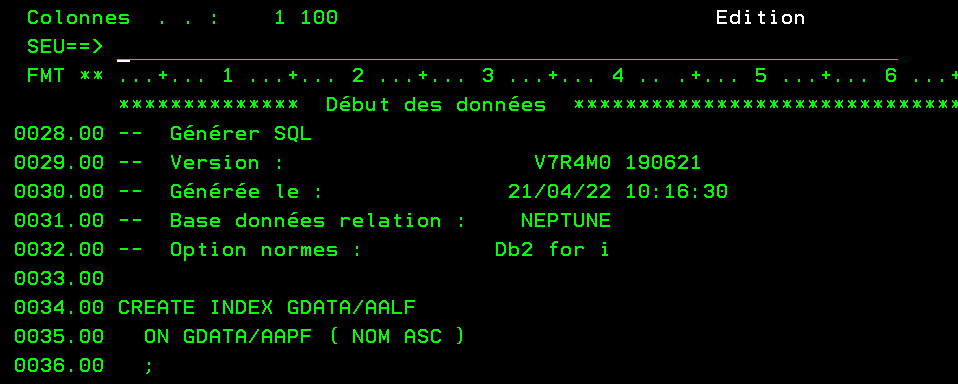
Même remarque que pour les PF (tout ne se traduit pas exemple LF avec sélection)
Une fois que vous avez le source il vous suffit alors de rejouer le script SQL.
Remarque :
Vous ne pouvez pas faire un create or replace , puisque SQL continue à voir le LF comme une vue.
Vous devez donc le supprimer avant le recréer.
Compléments apportés par Birgitta merci à elle
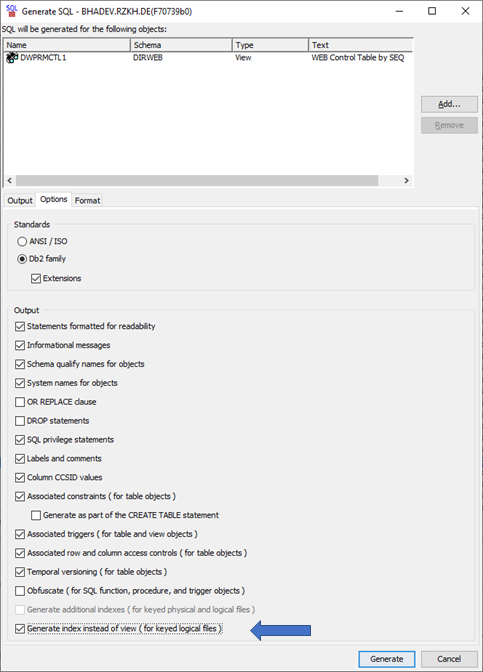
Il y a 2 options en GENERATE_SQL et le ACS wizard avec lesquelles on peut transformer LFs en index.
https://www.ibm.com/docs/en/i/7.4?topic=services-generate-sql-procedure
Out of the GENERATE_SQL documentation:
INDEX_INSTEAD_OF_VIEW – option:
The index instead of view option specifies whether a CREATE INDEX or CREATE VIEW statement will be generated for a DDS-created keyed logical file. The valid values are:
0 – A CREATE VIEW statement will be generated.
1 – A CREATE INDEX statement will be generated that matches the index for a DDS-created keyed logical file.
ADDITONAL_INDEX_OPTION:
The additional index option specifies whether additional CREATE INDEX statements will be generated for DDS-created keyed physical or logical files. The valid values are:
0 – Additional CREATE INDEX statements will not be generated.
1 – An additional CREATE INDEX statement will be generated that matches the index for a DDS-created keyed physical file. If the physical file has a PRIMARY KEY constraint, a CREATE INDEX statement is not generated.
An additional CREATE INDEX statement will be generated that matches the index for a DDS-created keyed logical file. If a value of ‘1’ is specified for the index instead of view option, an additional CREATE INDEX statement is not generated. Additional CREATE INDEX statements will also be generated that match the join indexes of a DDS-created join logical file.