Pour traduire du texte dans un programme RPGLE, on peut utiliser un appel à une API de traduction (via SQL). Les principales API de traductions publiques sont DeepL API et Google Cloud Translation. Dans cet article nous utiliserons l’API de DeepL dans sa version gratuite, limitée à 500 000 caractères par mois, mais DeepL propose également d’autres offres payantes pour son API.
Documentation de l’API DeepL : https://www.deepl.com/docs-api
Introduction
Pour réaliser simplement un appel API en RPGLE, il est possible d’utiliser plusieurs méthodes SQL qui permettent de :
- Formater le corps d’une requête API en JSON
- Exécuter la requête API en POST
- Récupérer des informations dans la réponse JSON
Nous allons voir ensemble un exemple d’utilisation de ces méthodes pour créer un programme qui traduit un texte donné dans la langue choisie.
Cas d’exemple
Prenons donc le cas d’un programme simple qui récupère les paramètres suivants :
- Le texte à traduire
- Le code de la langue ciblée (‘FR’, ‘EN’, ‘ES’, ‘DE’, …)
Le programme affichera ensuite via un dsply le résultat de la traduction et le code retour HTTP de la requête.
On commence par les déclarations du programme.
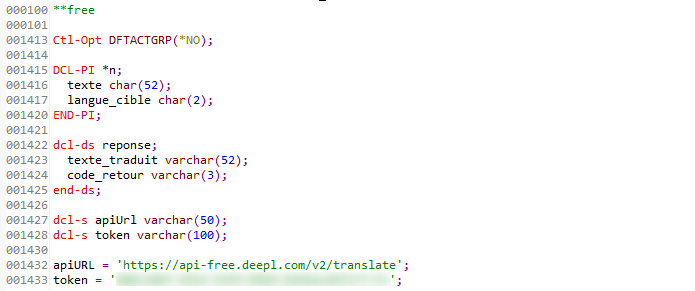
On y retrouve :
- nos paramètres texte et langue_cible
- une ds qui contiendra les données retournées par la requête API (traduction et code HTTP)
- deux variables pour l’URL de la requête et le token d’authentification (qui s’obtient en créant un compte API sur DeepL)
On peut maintenant construire notre requête API en utilisant SQL.
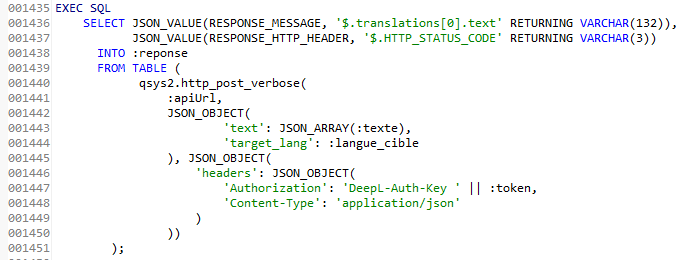
La requête HTTP faite à l’API est exécutée via la fonction de table QSYS2.HTTP_POST_VERBOSE (qui est similaire à QSYS2.HTTP_POST, mais avec plus de détails en retour).
Elle prend en paramètres :
- l’URL d’appel de l’API
- le body de notre requête -> un objet JSON contenant le texte et la langue cible
- le header de notre requête -> un objet JSON contenant des informations supplémentaires requises comme le token d’authentification
Ici la traduction se fera avec une détection automatique de la langue source (celle du texte qu’on demande à traduire), mais on peut également ajouter le paramètre source_lang dans notre body si on veut préciser la langue source de notre texte.
On remarque l’usage des fonctions SQL JSON_OBJECT et JSON_ARRAY qui permettent de formater des données au format JSON (JSON_ARRAY pour un tableau JSON)
Les éléments que l’on récupère grâce à cette fonction sont au format JSON, on utilise donc la fonction JSON_VALUE pour les récupérer en VARCHAR dans notre ds résultat.
Dans notre cas, on s’intéresse au texte traduit et au code retour HTTP, c’est donc les valeurs translations et HTTP_STATUS_CODE qui sont extraites du JSON.
Vous pouvez obtenir plus d’informations sur la structure des requêtes API DeepL et leurs retours sur la documentation en ligne de l’API : https://www.deepl.com/docs-api
Pour finir, on affiche avec un simple dsply nos éléments de retour (dans le cas où la requête SQL a été exécutée sans erreur).

Test du programme
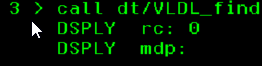
Lorsqu’on appelle notre programme avec les bons paramètres :
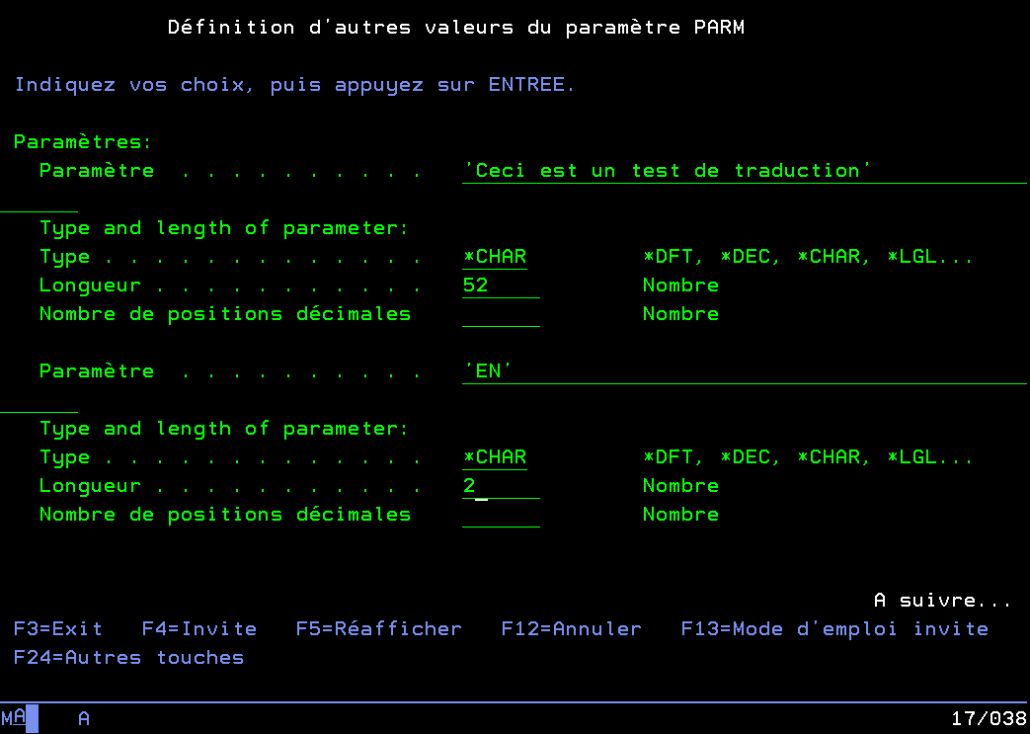
On obtient bien une traduction du texte saisi, et le code retour 200 (réussite).