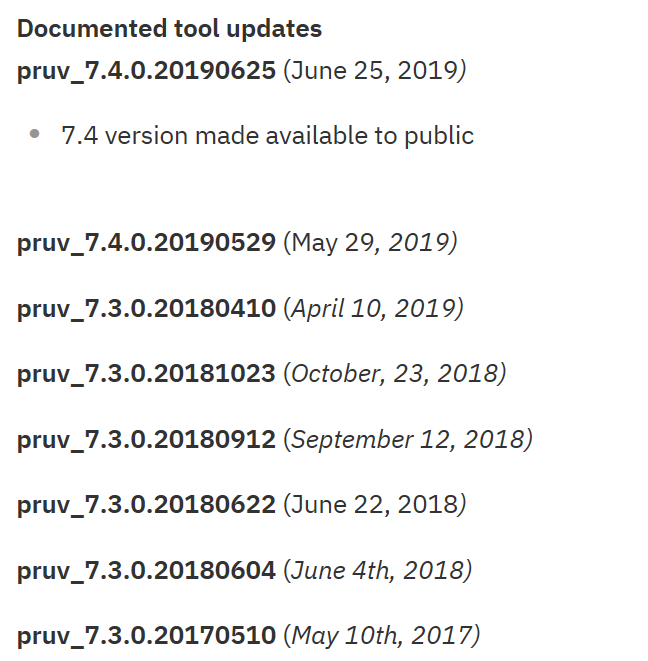
Sans être un expert base de données, on peut être amené à faire un minimum de gestion. Voici comment gérer vos index.
Index advisor est un logiciel, intégré à SQL, qui analyse tous les index inexistants dont le système à besoin et qui choisit de les créer.
il collecte des informations sur le nombre de fois dont il en a eu besoin, la dernière utilisation etc…
On estime aujourd’hui l’impact de vos index à 70 % de la performance totale de votre SGBD.
Il est donc important de savoir bien gérer ces index.
Pour matérialiser index advisor, Vous pouvez voir des informations à plusieurs endroits :
Dans ACS Shémas/Tables/ clique droit / utilisation index , ou directement dans le table système interrogeable par un simple select sur la table QSYS2.SYSIXADV,
ou un select sur la vue fournie sur cette table QSYS2/CONDENSEDINDEXADVICE nom sql et CONDIDXA nom système.
Nous allons voir comment être efficace en utilisant ces informations.
1) Périmètre
Il faut déterminer le périmètre que vous voulez analyser.
C’est une liste de bibliothèques contenants vos pf ou un schéma contenant vos tables.
2) Réinitialisation des statistiques
Il va vous falloir réinitialiser régulièrement les statistiques
des index sur votre périmètre, souvent à la semaine ou au mois.
Il existe une procédure sql qui permet de réaliser cette tache,
RESET_TABLE_INDEX_STATISTICS nom sql et RESET_STAT nom système.
Exemple :
CALL QSYS2.RESET_TABLE_INDEX_STATISTICS(‘Votre_Bib’,’%’, ‘*YES’);
-% indique pour toutes les tables de votre bibliothèque.
-la valeur *YES indique que la ligne sera supprimée de la table QSYS2.SYSIXADV.
3) Analyse
Vous allez pouvoir analyser les index qui ont été nécessaire depuis votre précédente réinitialisation !
Voici un exemple de requête sur une bibliothèque de votre périmètre :
SELECT
substr(TABLE_NAME, 1, 10) as TABLE_NAME,
LAST_ADVISED,
TIMES_ADVISED,
substr(KEY_COLUMNS_ADVISED, 1 , 100)
FROM QSYS2/SYSIXADV WHERE TABLE_SCHEMA = ‘Votre_Bib’
ORDER BY TIMES_ADVISED desc ;
4) Création
Vous allez pouvoir envisager des actions pour les index manquants que vous analysez comme pertinent.
Exemple ceux qui ont été demandés 500 fois au moins
SELECT
substr(TABLE_NAME, 1, 10) as TABLE_NAME,
LAST_ADVISED,
TIMES_ADVISED,
substr(KEY_COLUMNS_ADVISED, 1 , 100)
FROM QSYS2/SYSIXADV WHERE TABLE_SCHEMA = ‘Votre_Bib’
and TIMES_ADVISED > 500
ORDER BY TIMES_ADVISED desc
Il y a 2 types d’actions possibles
A) Les index nécessaires
Il faudra les construire.
B) Les index demandés :
A cause d’une requête mal écrite.
On trouve très souvent le défaut dans la clause WHERE d’un select
Exemple :
Vous avez une liste d’objets avec un index sur le nom d’objet et le Type
Si vous écrivez :
select * from votre_table where …
order by objet , type
Vous allez utiliser l’index existant.
Si vous écrivez
select * from votre_table where …
order by type, objet
Le système va construire un nouvel index, ordonné par type puis par nom d’objet, mais il ne sert à rien…
Si vous avez la main sur l’applicatif, corrigez la requête …
5) Génération de scripts
Il existe des procédures dans la bibliothèque SYSTOOLS pour vous
aidez dans votre gestion.
La première procédure va permettre de créer des index automatiquement sur une table en fonction de critères statistiques :
ACT_ON_INDEX_ADVICE(‘Votre_bib’ , ‘Votre_table’, Nb_fois,
nb_maint, tps_estim)
Exemple (plus de 5OO utilisations) :
CALL SYSTOOLS.ACT_ON_INDEX_ADVICE(‘Votre_bib’,’votre_table’, NULL,
500, NULL )
La valeur à utiliser est à déterminer après avoir fait une analyse.
Cette méthode est plus destinée à un applicatif avec un ERP dont vous n’avez pas les sources et par conséquent dont où vous ne pouvez pas intervenir directement dans l’applicatif.
La deuxième procédure va vous permettre de générer les scripts SQL en fonction de critères statistiques , qui vous aiderons à créer vos
index suggérés.
Vous devez créer un fichier source assez long, par exemple qsqlsrc.
Exemple
CRTSRCPF FILE(VOTRE_BIB/QSQLSRC)
RCDLEN(512)
TEXT(‘SOURCE pour génération index’)
voici la procédure
HARVEST_INDEX_ADVICE(‘Votre_bib’ , ‘Votre_table’, Nb_fois, nb_maint,
tps_estim, ‘Bib_src’, ‘Fic_src’)
Exemple:
CALL SYSTOOLS.HARVEST_INDEX_ADVICE(‘Votre_bib’,’votre_table’, 1, 500,
0, ‘Votre_bib’, ‘QSQLSRC’)
Pour exécuter vos scripts vous pouvez ensuite le faire par la
commande système RUNSQLSTM.
RUNSQLSTM SRCFILE(Votre_bib/QSQLSRC) SRCMBR(Votre_Table)
COMMIT(*NONE) NAMING(*SQL) ERRLVL(30) MARGINS(512)
MARGINS étant la longueur de votre fichier source.
Cette méthode permet de vérifier les index proposés avant de les générer. Toujours privilégier une correction de requête dans l’applicatifs que la génération d’un index pour palier des légèretés de programmation…
6) Suppression des index générés
Il est possible d’utiliser une procédure cataloguée REMOVE_INDEXES,
pour supprimer les index générés, ne supprime pas les autres index.
Vous pouvez la planifier une fois par an :
Exemple :
CALL SYSTOOLS.REMOVE_INDEXES(NULL, 1, ’12 MONTHS’)
Attention si vous voulez supprimer des index applicatifs,
il faut analyser ceux qui n’ont pas été utilisés et surtout penser à
supprimer les objets dépendants.
Conclusion :
Vous allez de en plus utiliser SQL et les index sont un facteur important de la gestion de votre base de données.
Il est donc intéressant de mettre en place une politique adaptée à la gestion de ceux ci.