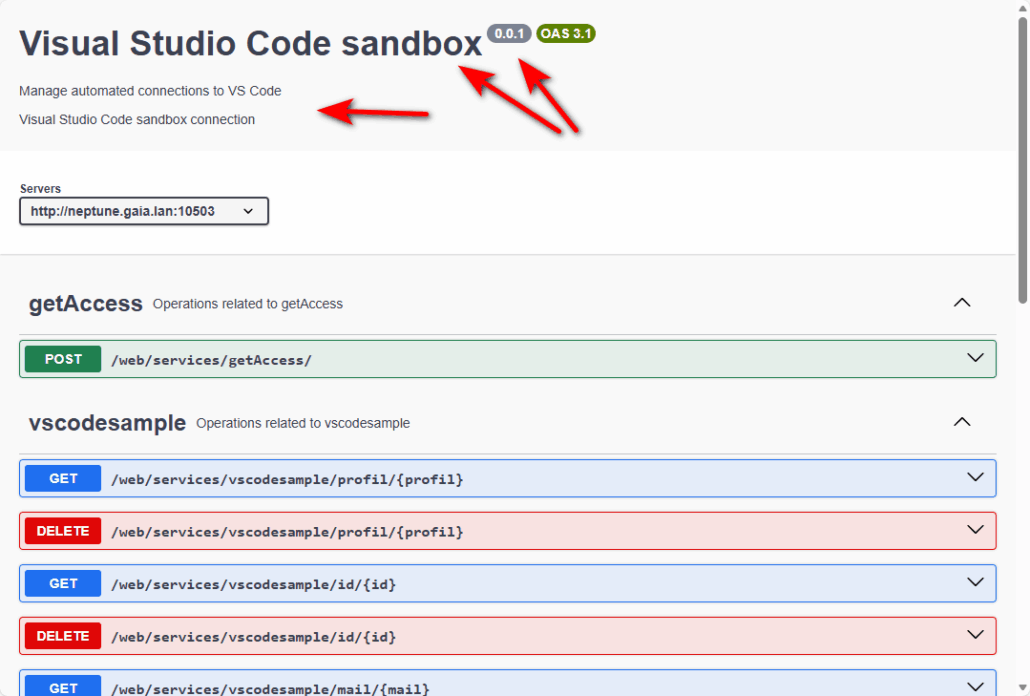
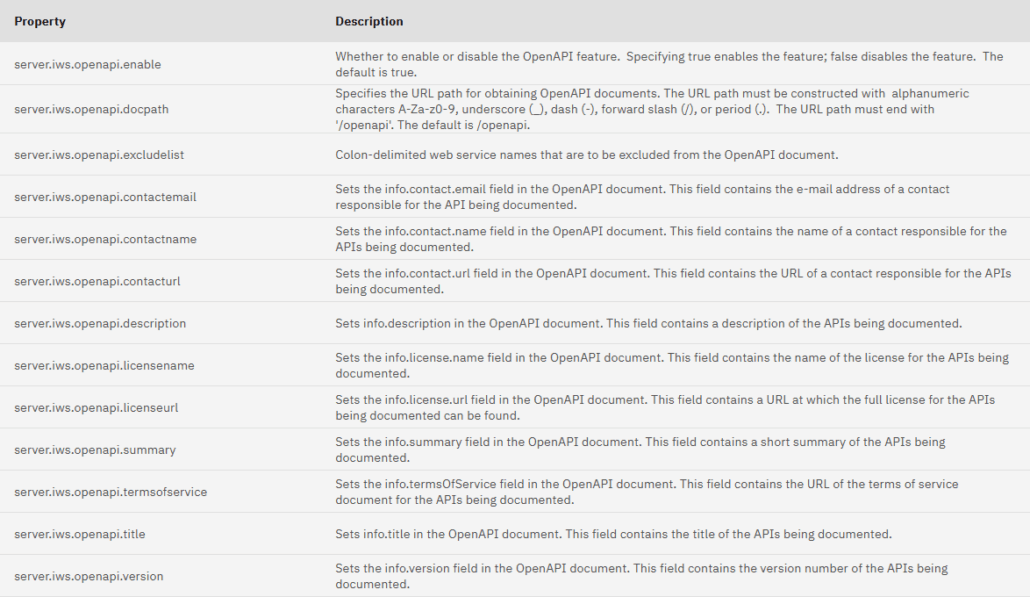
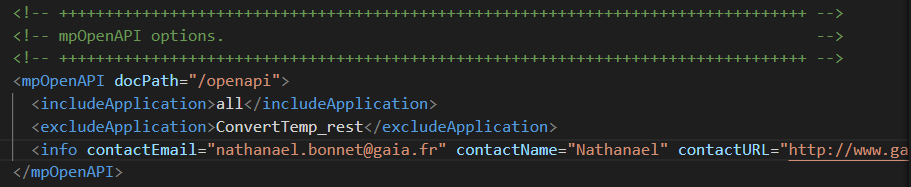
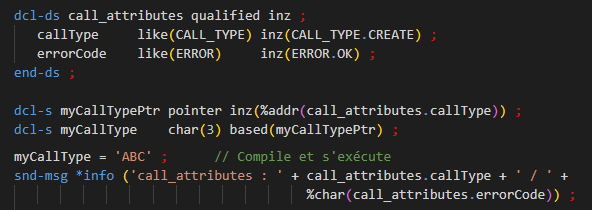
Aujourd’hui vous verrez comment créer un programme capable de convertir un fichier html en PDF depuis votre IBM i à l’aide d’un appel d’API externe.
Rappel sur l’IBMi vous pouvez générer du PDF en utilisant :
- Transform Services produit sous licence IBM mais très sommaire
- Une solution open source que vous installez sur votre partition
Exemple:
wkhtmltopdf (outil de conversion) qui n’est en fait plus du tout maintenu.
On va donc présenter une autre solution qui se base sur les API
Nous avons choisi l’API qui s’appelle PDFSPARK.
Cette solution vous permet de tester notre outil, vous avez jusqu’à 20 requêtes/minute sans clé alors que la plupart des autres API demandent une inscription et proposent environ que 15 requêtes/jour avec un forfait gratuit.
Normalement l’API reçoit une page en ligne en html puis la convertie, mais ici on voulait un .html depuis l’IFS donc j’ai demandé à l’IA (claude) de me faire juste un mini programme pour l’utiliser avec un fichier local et il m’a donné ça :
#!/QOpenSys/usr/bin/bash
export PATH=/QOpenSys/pkgs/bin:/QOpenSys/usr/bin:/usr/bin:$PATH
HTML_FILE=$(echo -n "$1" | tr -d ' ')
PDF_FILE="${HTML_FILE%.html}.pdf"
if [ ! -f "$HTML_FILE" ]; then
echo "ERROR: HTML file not found"
exit 1
fi
HTML_CONTENT=$(cat "$HTML_FILE" | jq -Rs .)
curl -s -X POST "https://pdfspark.dev/api/v1/pdf/from-html" \
-H "Content-Type: application/json" \
-d "{\"html\": $HTML_CONTENT, \"options\": {\"format\": \"A4\"}}" \
-o "$PDF_FILE"
echo "DONE : $PDF_FILE"
echo "Your file is located in : $HTML_FILE"Le programme fait, dans l’ordre :
- Récupère le chemin du fichier à convertir en paramètre
- Crée un PDF du même nom (que le nom du fichier)
- Vérifie si le fichier existe vraiment
- Lis le .html passé en paramètre et le converti en JSON pour ensuite l’injecter dans l’API (
jq -Rs) - Et ensuite la requête curl donnée par le site de l’API
Puis il y a le programme CL qui appelle le .sh depuis 5250 :
PGM PARM(&FILE)
/* début de la construction de la commande bash */
DCL VAR(&NULL) TYPE(*CHAR) LEN(1) VALUE(X'00')
DCL VAR(&BASH) TYPE(*CHAR) LEN(100) +
VALUE('/QOpenSys/usr/bin/bash')
DCL VAR(&CONVERT) TYPE(*CHAR) LEN(100) +
VALUE('/chemin/vers/votre/fichier/html2pdf.sh')
/* fin de la construction de la commande bash */
/* Création de la variable FILE pour rentrer en paramètre
le chemin vers le fichier à convertir depuis 5250 */
DCL VAR(&FILE) TYPE(*CHAR) LEN(256)
DCL VAR(&FILETRIM) TYPE(*CHAR) LEN(100)
/* concaténation des variables
pour former la commande bash final */
CHGVAR VAR(&FILETRIM) VALUE(&FILE)
CHGVAR VAR(&BASH) VALUE(&BASH *TCAT &NULL)
CHGVAR VAR(&CONVERT) VALUE(&CONVERT *TCAT &NULL)
CHGVAR VAR(&FILETRIM) VALUE(&FILETRIM *TCAT &NULL)
/*Appel de QP2SHELL pour l'exécution de la commande*/
CALL PGM(QP2SHELL) PARM(&BASH &CONVERT &FILETRIM)
ENDIT:
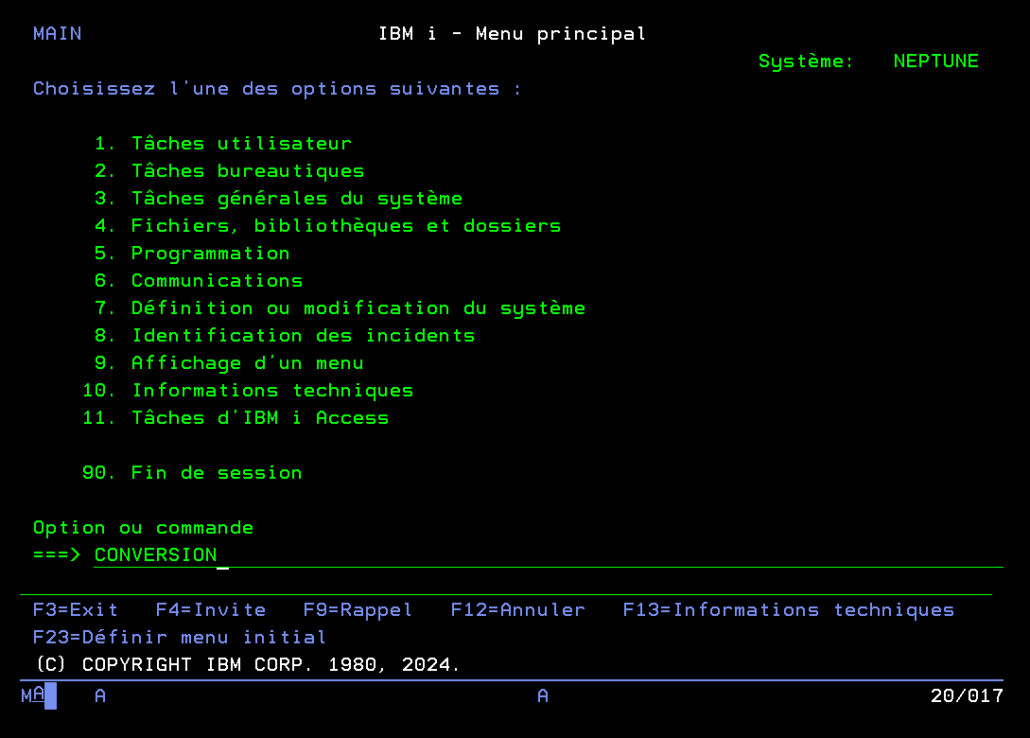
ENDPGMAprès compilation et ajout de la librairie, il suffit d’appeler ce programme via l’interface 5250 avec en paramètre le chemin vers le fichier .html que vous voulez convertir en PDF :
==>CALL CONVERSION PARM('/chemin/vers/fichier.html')
Pour l’instant, le nouveau fichier .PDF sera enregistré au même endroit que le .html
Et pour vous faciliter encore plus la tâche,
vous pouvez créer une commande à appeler depuis 5250 en créant un fichier CONVERSION.CMD comme ceci :
CMD PROMPT('Conversion html vers pdf')
PARM KWD(FICHIER) TYPE(*CHAR) LEN(256) MIN(1) +
PROMPT('Fichier à convertir')puis la compiler.
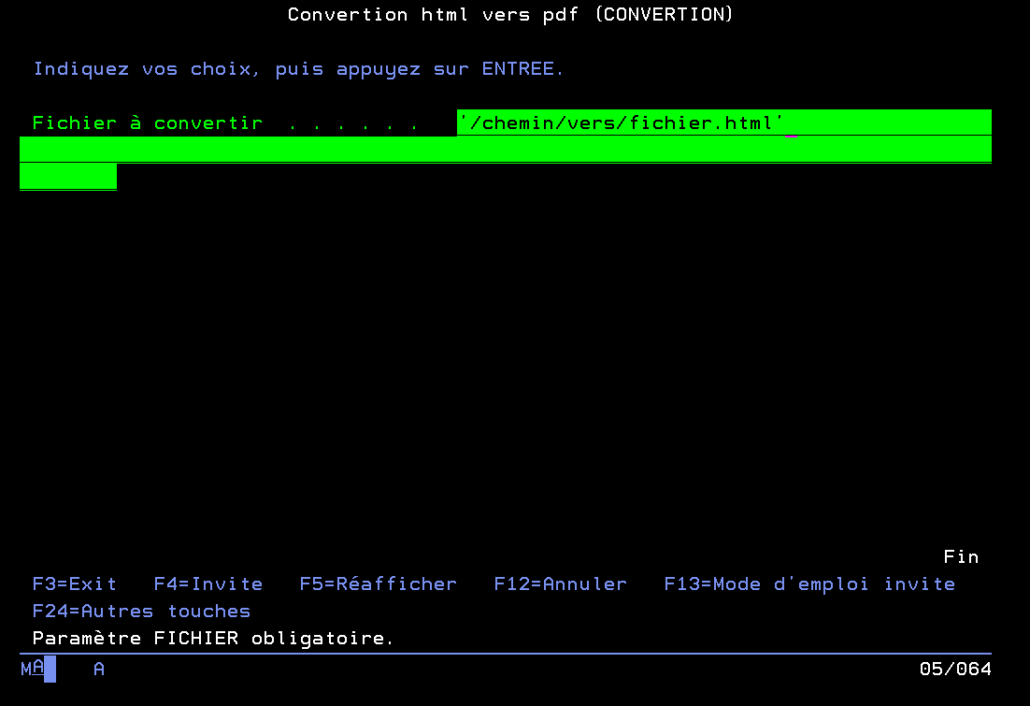
Au final
Vous pourrez appeler votre programme de conversion depuis 5250 juste avec la commande : conversion puis en appuyant sur F4, tomber sur cet écran qui vous permettra de renseigner (entre simple quote ‘ ) le chemin vers le fichier à convertir (également utilisable en batch):
Remarques :
Votre IBMi devra sortir vers l’URL https://pdfspark.dev sur le port 443 , ou vers le provider que vous aurez choisi
Vous pourrez faire des PDF plus évolués que par Transformer, et il est assez facile de générer du HTML.
Vous devrez choisir votre partenaire surtout si vous voulez traiter des données confidentielles
Ici nous avons choisi de faire du CURL , mais vous pouvez utiliser si vous le préférez un programme SQLRPGLE
Vous pouvez bien sur améliorer ce code à votre guise.