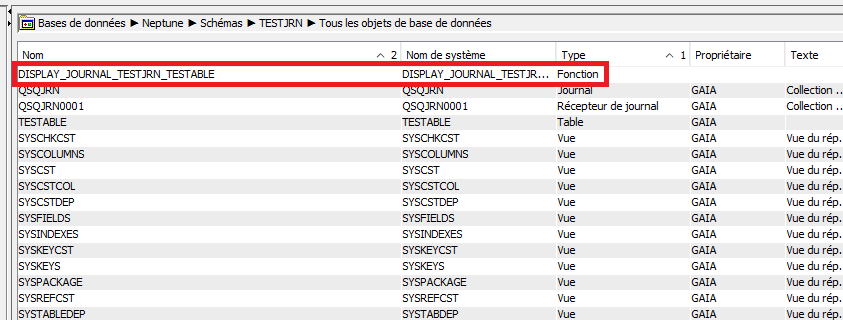
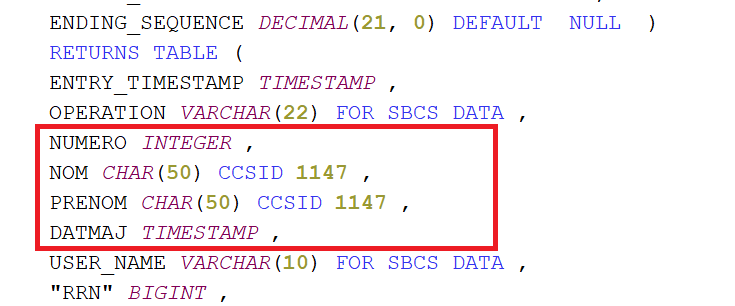
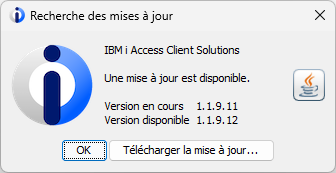
Pour analyser des journaux la difficulté est de traiter le poste *entry data qui est spécifique à chaque fichier
La tr2 de la v7R6 et la tr8 de la v7r5 permet de résoudre cette problématique en créant une fonction spécifique sur un fichier pour analyser les postes de TYPE R
Voici un petit protocole de test
— création d’un schéma
create schema testjrn ;
création d’une table journalisée par défaut sur qdftjrn
CREATE TABLE TESTJRN/TESTABLE ( NUMERO INT NOT NULL WITH DEFAULT, NOM CHAR ( 50) NOT NULL WITH DEFAULT, PRENOM CHAR ( 50) NOT NULL WITH DEFAULT, DATMAJ TIMESTAMP NOT NULL WITH DEFAULT) ;
— génération de modifications dans le journal
INSERT INTO TESTJRN/TESTABLE VALUES(1, ‘Berthoin’, ‘Pierre-Louis’, current timestamp);
INSERT INTO TESTJRN/TESTABLE VALUES(2, ‘Berthoin’, ‘Younes’, current timestamp) ;
INSERT INTO TESTJRN/TESTABLE VALUES(3, ‘Mbappé’, ‘Kilian’, current timestamp) ;
INSERT INTO TESTJRN/TESTABLE VALUES(4, ‘Chombier’, ‘Patrice’, current timestamp) ;
UPDATE TESTJRN/TESTABLE SET PRENOM = ‘Robert’ WHERE NUMERO = 4;
DELETE FROM TESTJRN/TESTABLE WHERE NUMERO =3 :
— génération de la fonction table spécifique à votre fichier
C’est un projet qui a eu plusieurs Vies, il existe même un plugin RDI et une extension vscode
C’est un projet qui permet de faire des tests unitaires sur des fonctions ILE
Il est basé sur les « assertions »
En informatique c’est une vérification intégrée dans le code qui s’assure qu’une condition spécifique est vraie à un moment donné de l’exécution du programme
D’abord vous devez installer une version de la bibliothèque RPGUNIT sur votre systéme, cette bibliothèque contient le Framework qui va permettre de mettre en œuvre vos tests
Vous devrez avoir un programme service et connaitre la fonction à tester
Vous allez créer un programme de service spécifique qui va créer des surcouche à vos fonction
Exemple : Fonction calcul dans votre application deviendra Fonction test_calcul dans le programme de service RPGUNIT
Votre programme CALCUL ici dans la bibliothèque DEMOUNIT
**free
ctl-opt nomain;
dcl-proc Addition export;
dcl-pi *n int(10);
a int(10) const;
b int(10) const;
end-pi;
return a + b;
end-proc;
Vous avez pouvez faire des choses plus évoluées et VSCODE vous offre un assistant pour générer le programme RPGUNIT de Test, mais je pense qu’il est important de comprendre ce qu’on fait
Les assertions sont inclues en standard dans la TR2 en V7R6 pour le RPGLE
Vous devez ou vous devrez vous conformer à la norme ISO27001 :
Voici quelques points à contrôler qu’un auditeur pourrait vous demander
1) séparation DEV / TEST / PROD
Ils vérifieront que vous avez à minima 3 environnements, 2 machines sont une bonne pratique
2) Git ou gestionnaire de versions
Ils vérifieront que vous avez un versioning de votre code source, aujourd’hui git est incontournable pour réaliser cette opération
3) Revue de code documentée
Ils vérifieront que vous faites des revues de code et que vous avez des actions suite à celle-ci, exemple modernisation du code obsolète entrant en maintenance.
4) Les droits des développeurs
Ils vérifieront par exemple qu’aucun développeur reste avec *ALLOBJ permanent, et qu’il a des droits limités et tracés à les actions en production
5) Données sensibles chiffrées en transit (TLS/HTTPS)
Ils vérifieront qu’aucune données ne circule en claire , mise en œuvre de TLS
6) Contrôle des accès aux objets
Ils vérifieront les droits d’accès aux objets , la bonne pratique est *use sur les programmes *change sur les datas
7) Journalisation et suivi des changements
Ils vérifieront que les modifications effectuées correspondent à une demande documentée et éventuellement un ticket d’incident ou de correctif
8) Procédure de mise en production documentée
Ils vérifieront que vous avez un process de mise en production avec de interlocuteurs différents pour les rôles jusqu’à la mise en production
9) Normes de développement sécurisées
Ils vérifieront que vous avez des normes de développement (nommage , SQL préparé, validation des entrées ou paramètres, gestion des erreurs)
Conclusion :
Tous ces points ne vous garantissent pas de passer un audit confortable, mais ils vous permettront d’avoir des éléments pour engager un dialogue
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-03 10:54:102026-07-03 11:00:16Les droits d’un fichier IFS à sa création
Vous voulez savoir le droit qu’un utilisateur aura quand il tentera d’accéder à un fichier IFS
Voici un script avec les requêtes qui vous aidera à déterminer le droit que vous obtiendrez.
Vous aurez 8 étapes possibles , et il s’arrêtera à la première correspondance.
--
-- Voici une liste de commande SQL pour trouver le droit d'un utilisateur
-- Sur un fichier IFS
-- ici l'utilisateur PLB
-- tente d'accéder au fichier
--/home/plb/Controle_demarrage_SBS.csv
-- 1 si user *ALLOBJ
-- Si oui tous les droits
--
SELECT SPECIAL_AUTHORITIES,
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 2 si user sur l'objet
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 3 si utilisateur dans liste d'autorisations
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = 'PLB'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
-- 4 si groupe all obj
-- Si oui tous les droits
--
SELECT
SPECIAL_AUTHORITIES
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = ( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
-- 5 si groupe sur l'objet
--
SELECT * FROM TABLE(QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv'))
where AUTHORIZATION_NAME =
( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
--6 Si groupe dans la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = (SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB')
AND AUTHORIZATION_LIST = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
--7 Si public
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND DATA_AUTHORITY <> '*AUTL';
--
--8 Si public reporté sur la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
Remarque :
Ce mécanisme peut être complété par des groupe additionnels , les droits proposés devenant complétifs (‘Ajouter au droit existant’)
Il est conseillé de les utiliser modérément , on peut avoir un système de droit assez efficace juste avec le mécanisme historique
Dans l’IFS l’adoption de droit ne s’applique pas, mais dans vos sript sh vous pouvez utiliser la notion de SETUID
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-03 10:13:032026-07-03 10:13:04Droit d’utilisateur sur un fichier IFS
Aujourd’hui vous verrez comment créer un programme capable de convertir un fichier html en PDF depuis votre IBM i à l’aide d’un appel d’API externe.
Rappel sur l’IBMi vous pouvez générer du PDF en utilisant :
Transform Services produit sous licence IBM mais très sommaire
Une solution open source que vous installez sur votre partition
Exemple:
wkhtmltopdf (outil de conversion) qui n’est en fait plus du tout maintenu.
On va donc présenter une autre solution qui se base sur les API
Nous avons choisi l’API qui s’appelle PDFSPARK. Cette solution vous permet de tester notre outil, vous avez jusqu’à 20 requêtes/minute sans clé alors que la plupart des autres API demandent une inscription et proposent environ que 15 requêtes/jour avec un forfait gratuit.
Normalement l’API reçoit une page en ligne en html puis la convertie, mais ici on voulait un .html depuis l’IFS donc j’ai demandé à l’IA (claude) de me faire juste un mini programme pour l’utiliser avec un fichier local et il m’a donné ça :
#!/QOpenSys/usr/bin/bash
export PATH=/QOpenSys/pkgs/bin:/QOpenSys/usr/bin:/usr/bin:$PATH
HTML_FILE=$(echo -n "$1" | tr -d ' ')
PDF_FILE="${HTML_FILE%.html}.pdf"
if [ ! -f "$HTML_FILE" ]; then
echo "ERROR: HTML file not found"
exit 1
fi
HTML_CONTENT=$(cat "$HTML_FILE" | jq -Rs .)
curl -s -X POST "https://pdfspark.dev/api/v1/pdf/from-html" \
-H "Content-Type: application/json" \
-d "{\"html\": $HTML_CONTENT, \"options\": {\"format\": \"A4\"}}" \
-o "$PDF_FILE"
echo "DONE : $PDF_FILE"
echo "Your file is located in : $HTML_FILE"
Le programme fait, dans l’ordre :
Récupère le chemin du fichier à convertir en paramètre
Crée un PDF du même nom (que le nom du fichier)
Vérifie si le fichier existe vraiment
Lis le .html passé en paramètre et le converti en JSON pour ensuite l’injecter dans l’API (jq -Rs)
Et ensuite la requête curl donnée par le site de l’API
Puis il y a le programme CL qui appelle le .sh depuis 5250 :
PGM PARM(&FILE)
/* début de la construction de la commande bash */
DCL VAR(&NULL) TYPE(*CHAR) LEN(1) VALUE(X'00')
DCL VAR(&BASH) TYPE(*CHAR) LEN(100) +
VALUE('/QOpenSys/usr/bin/bash')
DCL VAR(&CONVERT) TYPE(*CHAR) LEN(100) +
VALUE('/chemin/vers/votre/fichier/html2pdf.sh')
/* fin de la construction de la commande bash */
/* Création de la variable FILE pour rentrer en paramètre
le chemin vers le fichier à convertir depuis 5250 */
DCL VAR(&FILE) TYPE(*CHAR) LEN(256)
DCL VAR(&FILETRIM) TYPE(*CHAR) LEN(100)
/* concaténation des variables
pour former la commande bash final */
CHGVAR VAR(&FILETRIM) VALUE(&FILE)
CHGVAR VAR(&BASH) VALUE(&BASH *TCAT &NULL)
CHGVAR VAR(&CONVERT) VALUE(&CONVERT *TCAT &NULL)
CHGVAR VAR(&FILETRIM) VALUE(&FILETRIM *TCAT &NULL)
/*Appel de QP2SHELL pour l'exécution de la commande*/
CALL PGM(QP2SHELL) PARM(&BASH &CONVERT &FILETRIM)
ENDIT:
ENDPGM
Après compilation et ajout de la librairie, il suffit d’appeler ce programme via l’interface 5250 avec en paramètre le chemin vers le fichier .html que vous voulez convertir en PDF :
Pour l’instant, le nouveau fichier .PDF sera enregistré au même endroit que le .html
Et pour vous faciliter encore plus la tâche,
vous pouvez créer une commande à appeler depuis 5250 en créant un fichier CONVERSION.CMD comme ceci :
CMD PROMPT('Conversion html vers pdf')
PARM KWD(FICHIER) TYPE(*CHAR) LEN(256) MIN(1) +
PROMPT('Fichier à convertir')
puis la compiler.
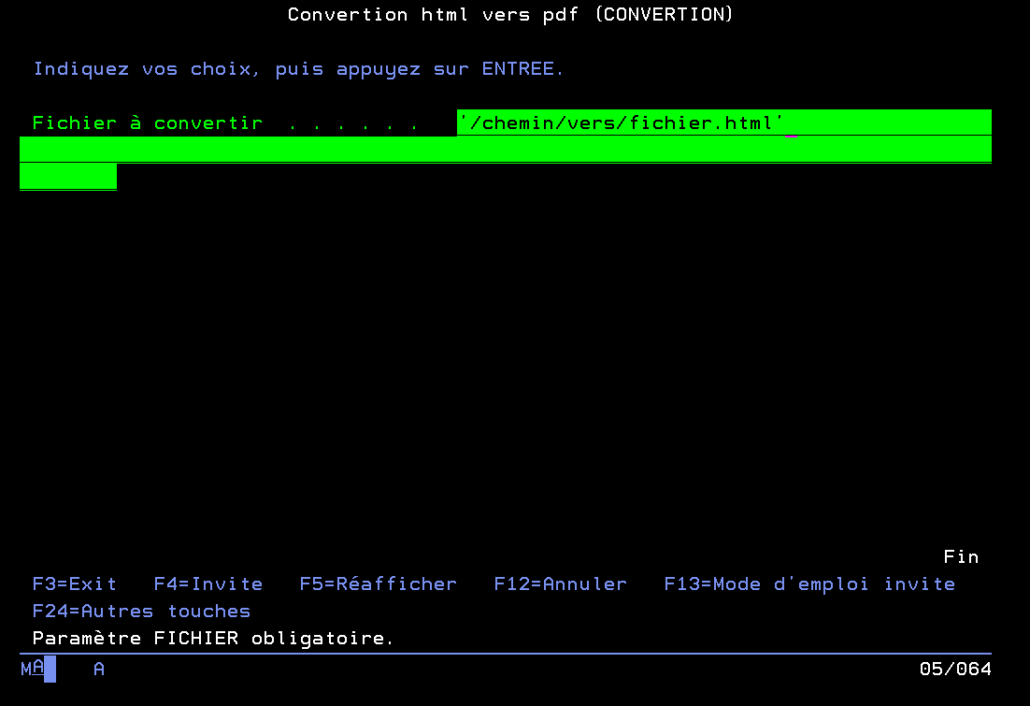
Au final
Vous pourrez appeler votre programme de conversion depuis 5250 juste avec la commande : conversion puis en appuyant sur F4, tomber sur cet écran qui vous permettra de renseigner (entre simple quote ‘ ) le chemin vers le fichier à convertir (également utilisable en batch):
Remarques :
Votre IBMi devra sortir vers l’URL https://pdfspark.dev sur le port 443 , ou vers le provider que vous aurez choisi
Vous pourrez faire des PDF plus évolués que par Transformer, et il est assez facile de générer du HTML.
Vous devrez choisir votre partenaire surtout si vous voulez traiter des données confidentielles
Ici nous avons choisi de faire du CURL , mais vous pouvez utiliser si vous le préférez un programme SQLRPGLE
Vous pouvez bien sur améliorer ce code à votre guise.
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-06-09 09:16:082026-06-09 09:16:10Html vers pdf dans l’IBM i
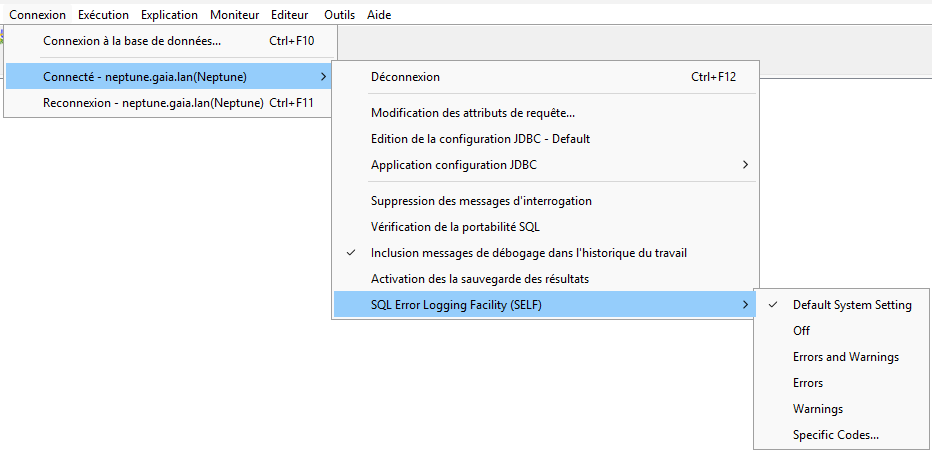
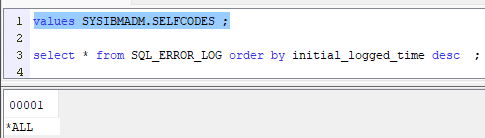
Concrètement, cela modifie la liste des erreurs qui sont tracées dans la vue SQL_ERROR_LOG. Cette liste est stockée dans la variable globale SYSIBMADM.SELFCODES, avec quelques valeurs spéciales (*ALL, *ERROR, *WARN, *NONE).
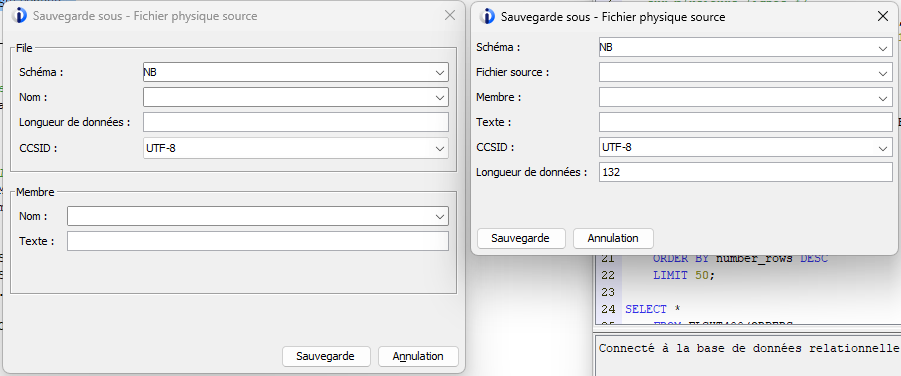
Fichiers physiques source
Amélioration de la fenêtre de dialogue pour la sauvegarde en fichiers sources :
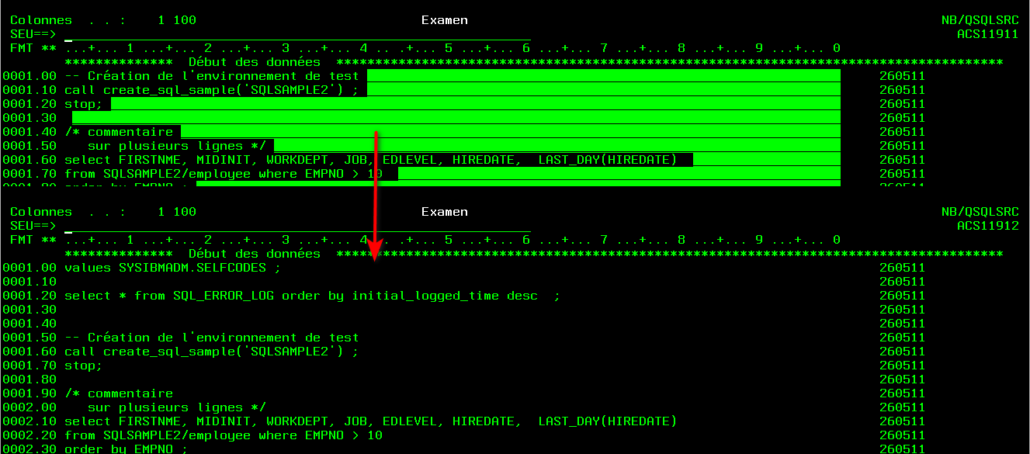
Gestion des fins de ligne
Les caractères LF (x’25’) ne sont plus insérés en fin de ligne dans le cas d’une sauvegarde en fichier source :
Il n’y pas d’impact à l’éxecution (RUNSQLSTM), mais plus de confort !
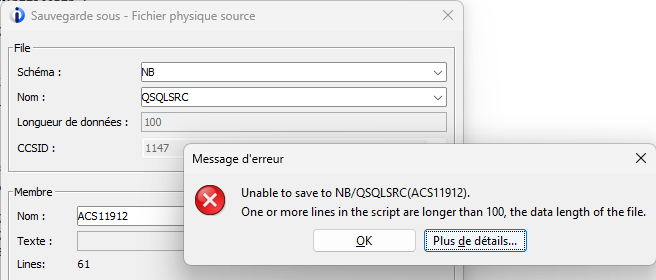
Gestion de la taille des lignes
Lors de l’enregistrement, au lieu de tronquer les lignes, un message permet d’avertir :
Exemples SQL
13 nouveaux exemples pour les services SQL :
SELF – System-wide controls
SELF – Job-level controls
SELF – Log Queries
SELF – Removing historical rows
SELF – Initial Stack
SELF – Top occurrences
SELF – QA use case exampleSecurity – Who is creating objects in the IFS root
Security – Who is creating objects in the /QOpenSys subdirectory
Security – IFS first-level directories that are open to attack
Pour connaitre le type d’un fichier, vous pouvez vous baser sur le type du Fichier .PDF, .JPG, etc …
Ou vous baser sur le nombre magique , ou signature binaire soit les 4 premiers octets en Hexa
SELECT HEX(SUBSTR(LINE, 1, 4)) AS SIGNATURE FROM TABLE(QSYS2.IFS_READ_BINARY(‘/home/test.pdf’)) FETCH FIRST 1 ROW ONLY;
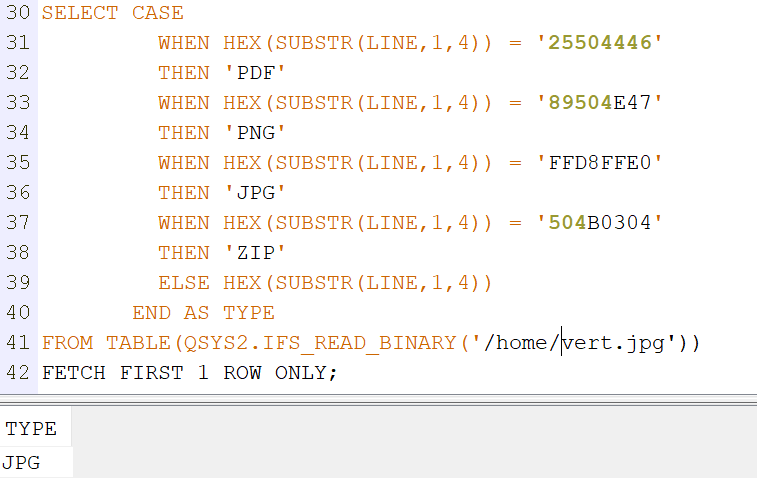
Voici un exemple sur 4 fichiers que vous pouvez trouver sur votre partition
SELECT CASE
WHEN HEX(SUBSTR(LINE,1,4)) = '25504446'
THEN 'PDF'
WHEN HEX(SUBSTR(LINE,1,4)) = '89504E47'
THEN 'PNG'
WHEN HEX(SUBSTR(LINE,1,4)) = 'FFD8FFE0'
THEN 'JPG'
WHEN HEX(SUBSTR(LINE,1,4)) = '504B0304'
THEN 'ZIP'
ELSE 'Autre' // inconnu
END AS TYPE
FROM TABLE(QSYS2.IFS_READ_BINARY('/home/vert.jpg'))
FETCH FIRST 1 ROW ONLY;
Résultat :
Conclusion :
C’est simple, et efficace, il y a sans doute d’autres manières de faire
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-05-11 14:42:272026-05-11 14:42:28Trouver le type d’un fichier
Vous avez des spools que vous ne voyez pas et vous ne pouvez pas agir dessus
==>WRKOUTQ
en Face de votre Outq vous avez 918 et quand quand vous regarder dans l’outq vous en avez que 37 par exemple
que faire
Vous regardez par SQL, vous les voyez tous
SELECT OUTPUT_QUEUE_NAME, SPOOLED_FILE_NAME, USER_DATA, JOB_NAME, FILE_NUMBER FROM QSYS2.OUTPUT_QUEUE_ENTRIES WHERE OUTPUT_QUEUE_NAME = ‘votre outq’;
Même par sql vous ne pouvez pas les effacer , c’est un probléme de spool fantômes , souvent le système n’a pas pu les écrire probléme d’espace disque par exemple, que faire ?
un petit rappel, il existe depuis quelque temps un mini ETL qui permet de mettre en place un suivi des codes d’audit pour avoir des statistiques et même un visuel dans Navigator for i
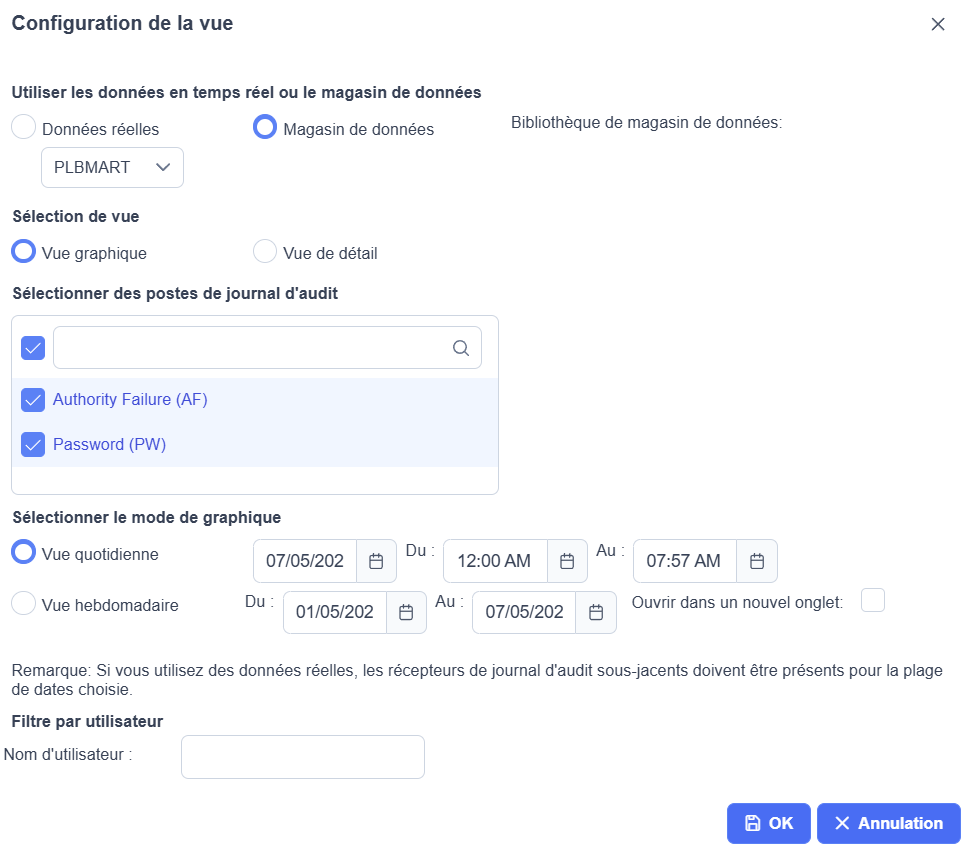
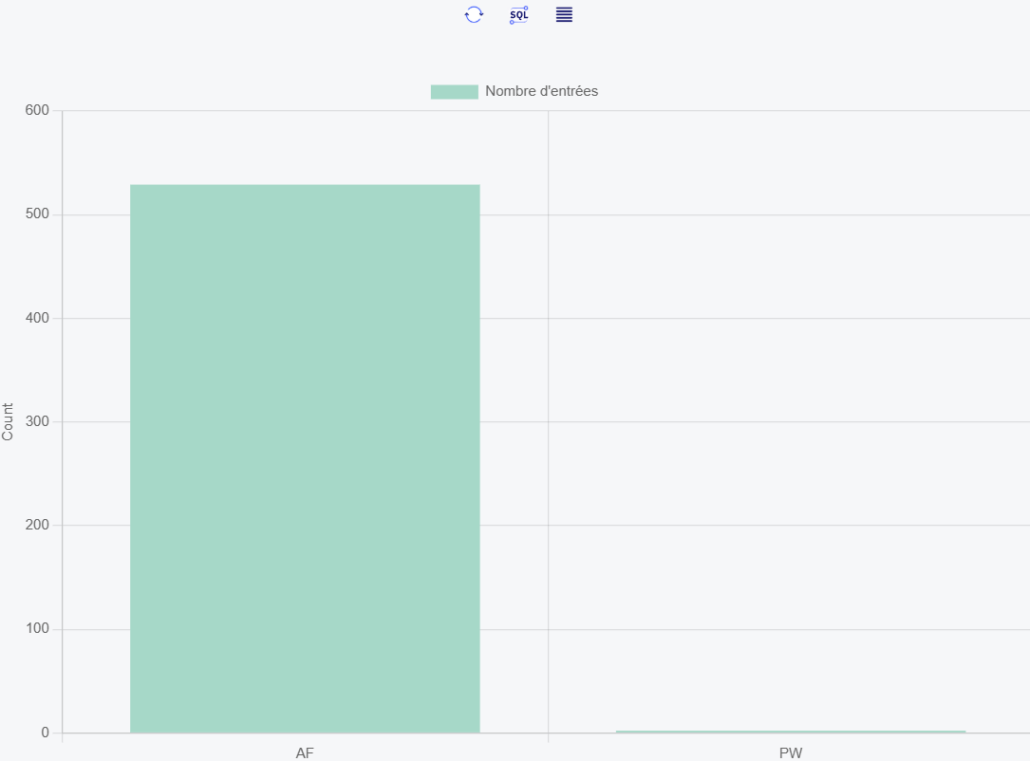
Vous voulez créer un datamart sur plusieurs code exemple PW et AF
et avoir un rafraichissement régulier sur la journée
Vous devez créer vos datamarts avant de commencer
En SQL
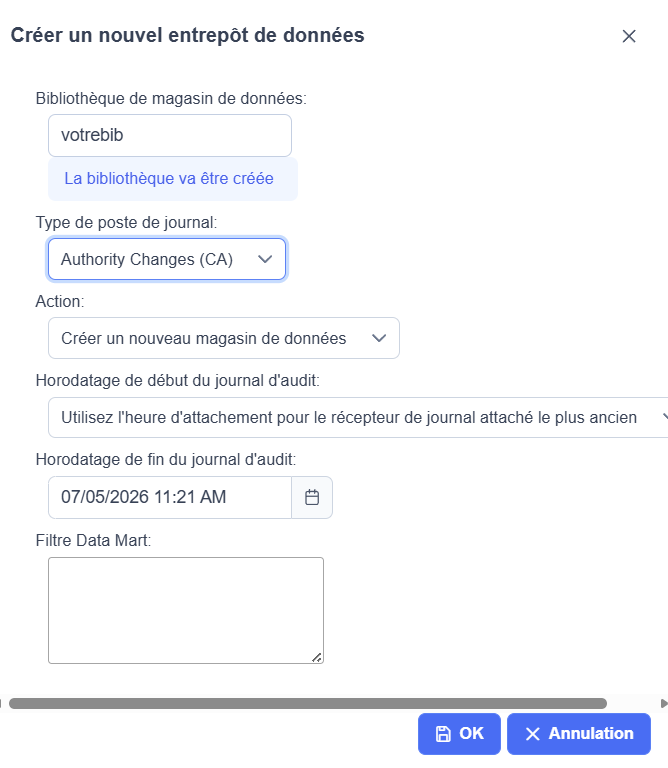
CALL QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART( JOURNAL_ENTRY_TYPE => ‘Votre code’, DATA_MART_LIBRARY => ‘Votre bib’, STARTING_TIMESTAMP => CURRENT DATE – 30 DAYS, ENDING_TIMESTAMP => CURRENT TIMESTAMP, DATA_MART_ACTION => ‘CREATE’ );
ou dans l’interface Navigator for i Journal d’audit
Gérer magasin de donnée
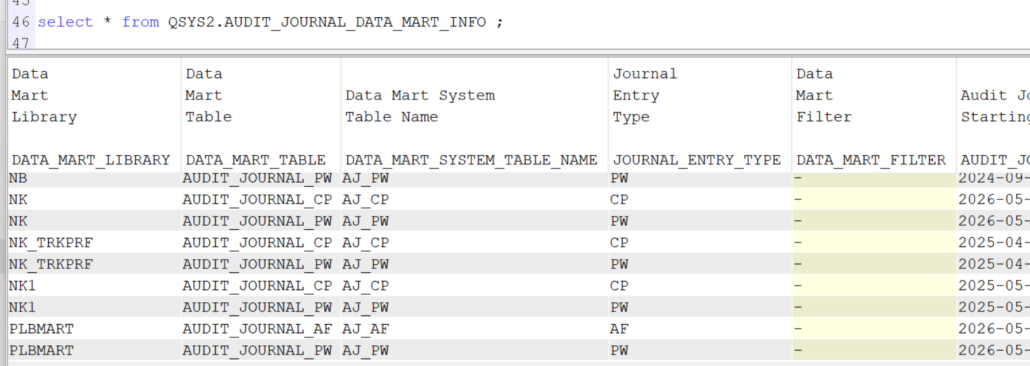
Ca va créer des fichiers dans la bibliothèque choisie
AUDIT_JOURNAL_XX nom SQL AJ_XX en nom systéme
Vous pouvez les interroger par SQL
exemple:
SELECT
ENTRY_TIMESTAMP,
USER_PROFILE_NAME,
OBJECT_NAME
FROM votrebib.AUDIT_JOURNAL_DO
ORDER BY ENTRY_TIMESTAMP DESC;
Nous allons donc créer un fichier de paramétrage qui contiendra les informations de votre datamart code, bibliothèque, type de rafraichissement , et durée de rétention
Création de la table
CREATE TABLE votrebib/PARMART ( CODE_SUIVI CHAR ( 2) NOT NULL WITH DEFAULT, BIBLIO CHAR ( 10) NOT NULL WITH DEFAULT, MISEAJOUR CHAR (10) NOT NULL WITH DEFAULT duree CHAR ( 03) NOT NULL WITH DEFAULT )
Exemple insertion data dans cette table
INSERT INTO GDATA/PARMART VALUES(‘AF’, ‘PLBMART’, ‘*CONTINUE’, ‘030’)
Nous allons créer un programme AUDITREF
PGM PARM(&TIMa &timlim)
/*--------------------------------------------------------*/
/* Ce programme sert de robot pour rafraichir un datamart */
/* exemple toutes les 2 heures, 120 minutes */
/*--------------------------------------------------------*/
dcl &tima *char 3 /* Fréquence de rafraichissement en minutes */
dcl &timlim *char 6 /* Heure d'arret du robot */
/* Fichier de paramétrage des datamart à rafraichir */
DCLF FILE(PARMART)
/* Variable préformatée pour service sql */
DCL VAR(&SQL) TYPE(*CHAR) LEN(512) VALUE('CALL +
QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART(JOURNA+
L_ENTRY_TYPE => ''XX'', +
DATA_MART_LIBRARY => ''0123456789'', +
STARTING_TIMESTAMP => ''0123456789'', +
ENDING_TIMESTAMP => CURRENT TIMESTAMP, +
DATA_MART_ACTION => ''ADD'')')
dcl &finfichier *lgl
dcl &timsys *char 6 /* Heure système */
dcl &timn *dec 3 /* conversion numérique */
/* Boucle de lecture */
chgvar &timn &tima
boucle:
DOUNTIL COND(&FINFICHIER)
rcvf
MONMSG MSGID(CPF0864) EXEC(LEAVE)
CHGVAR %sst(&SQL 66 2) VALUE(&code_suivi)
CHGVAR %sst(&SQL 94 10) VALUE(&Biblio)
CHGVAR %sst(&SQL 130 10) VALUE(&miseajour)
RUNSQL SQL(&SQL) COMMIT(*NONE)
monmsg sql0000 exec(do)
SNDUSRMSG MSG('Raffraichissement impossible pour,' +
*BCAT &CODE_SUIVI *BCAT 'dans le +
datamart' *BCAT &BIBLIO) MSGTYPE(*INFO)
enddo
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA('Raffraichisement des datamarts +
terminé') MSGTYPE(*COMP)
/* on boucle jusqu'a l'heure limite */
rtvsysval qtime &timsys
IF COND(&TIMLIM > &TIMSYS) THEN(do)
dlyjob &timn
GOTO CMDLBL(BOUCLE)
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) MSGDTA('Robot +
de Raffraichisement arrêté') MSGTYPE(*COMP)
endpgm
Voici la commande pour démarrer le robot ici toute les heures jusqu’à 22 h Vous pouvez le mettre dans un scheduler
Vous devrez si vous utilisez le mode continue faire le ménage dans le datamart Exemple DELETE FROM PLBMART/AJ_AF WHERE ENTRY_TIMESTAMP < current timestamp – 30 days
voici un programme de ménage qui se basera sur la zone durée du fichier
PGM
/*--------------------------------------------------------*/
/* Ce programme sert à épurer les datamarts */
/* qui travaillent *CONTINUE */
/*--------------------------------------------------------*/
/* Fichier de paramétrage des datamart à rafraichir */
DCLF FILE(PARMART)
/* Variable préformatée pour service sql */
DCL VAR(&SQL) TYPE(*CHAR) LEN(512)
dcl &finfichier *lgl
/* Boucle de lecture */
DOUNTIL COND(&FINFICHIER)
rcvf
MONMSG MSGID(CPF0864) EXEC(LEAVE)
CHGVAR VAR(&SQL) VALUE('DELETE FROM' *BCAT &BIBLIO +
*TCAT '/' *TCAT 'AJ_' *TCAT &CODE_SUIVI +
*BCAT 'WHERE ENTRY_TIMESTAMP < current +
timestamp - ' *BCAT &DUREE *BCAT 'days')
SNDUSRMSG MSG(&sql ) MSGTYPE(*INFO)
RUNSQL SQL(&SQL) COMMIT(*NONE)
monmsg sql0000 exec(do)
SNDUSRMSG MSG('épuration impossible pour,' +
*BCAT &CODE_SUIVI *BCAT 'dans le +
datamart' *BCAT &BIBLIO) MSGTYPE(*INFO)
enddo
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA('Epuration des datamarts +
terminé') MSGTYPE(*COMP)
endpgm
Pour automatiser, lancer le une fois par semaine par exemple vous pouvez le mettre dans un scheduler