

Jusqu’en version 7.3, on utilisait une dtaara QFDTJRN qui indiquait comment journaliser les objets de la bibliothèque.
En version 7.4, les informations de journalisation sont inclues dans la description de la bibliothèque et la dtaara QDFTJRN n’est plus utilisée.
Il n’y aura pas d’erreur, juste les nouveaux fichiers ne seront pas journalisés, ce qui peut générer des problèmes plus tard …
On peut les voir par la commande
==>DSPLIBD votre_bib puis <F10> Affichage des règles d’héritage
Vous avez une ligne par type d’objets, *FILE, *DTAARA, *DTAQ

Pour les mettre en place, on peut utiliser les commandes suivante
STRJRNLIB démarrer la journalisation
ENDJRNLIB arrêter la journalisation
CHGJRNOBJ *LIB modifier les attributs de journalisation
Exemple :
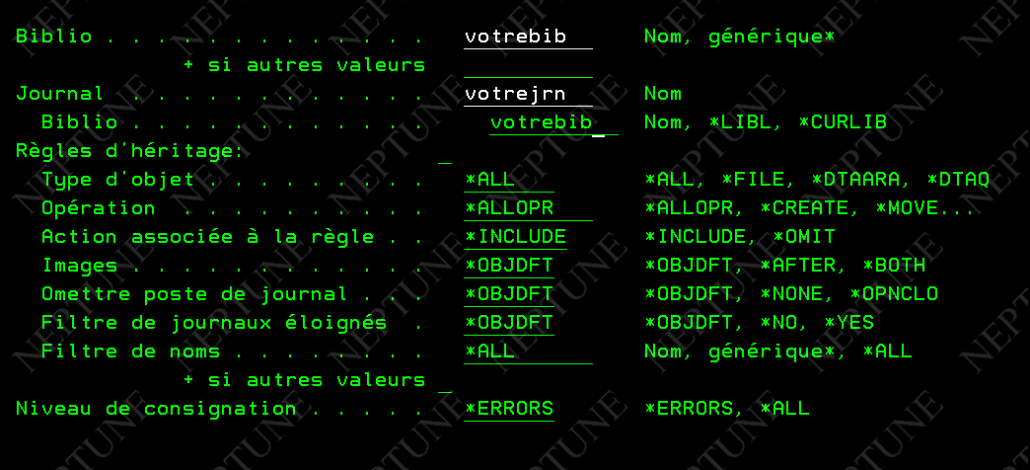
STRJRNLIB LIB(VOTREBIB)
JRN(VOTREBIB/VOTREJRN)
INHRULES((*FILE *ALLOPR *INCLUDE *BOTH *OPNCLO))
Ici les fichiers seront journalisés, pour toutes les opérations et on gardera l’image avant et après …
Si vous créer une bibliothèque par un create collection en SQL, vous aurez les valeurs suivantes
*FILE *CREATE *INCLUDE *BOTH *OPNCLO
Donc quand vous migrez vers la version 7.4, vous devrez migrer les informations de la dtaara QDFTJRN, vers la description de la bibliothèque.
Si vous êtes en V7R3, vous pouvez anticiper et déjà mettre en oeuvre les règles d’héritage.
Remarque :
Vous pouvez changer les règles d’héritage existantes par la commande
CHGJRNOBJ.
Ces informations ne concerne pas les fichiers journalisés avant la commande STRJRNLIB
Voici un lien ou vous trouverez un outil qui permet de migrer d’une manière à l’autre indispensable si vous passez en V7R4.