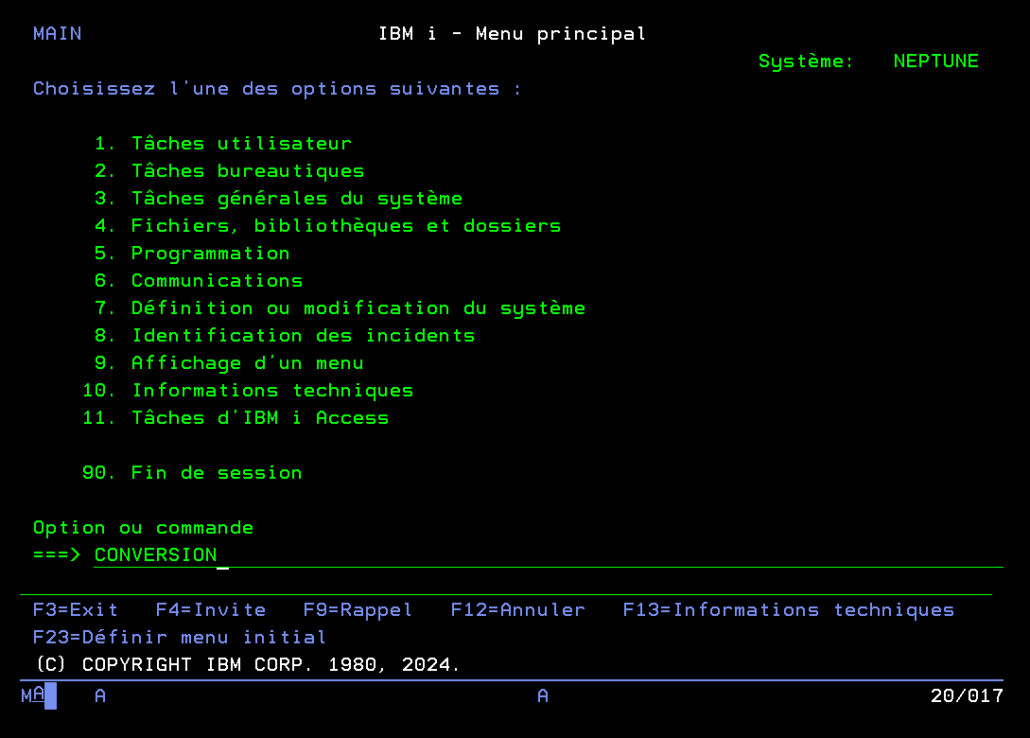
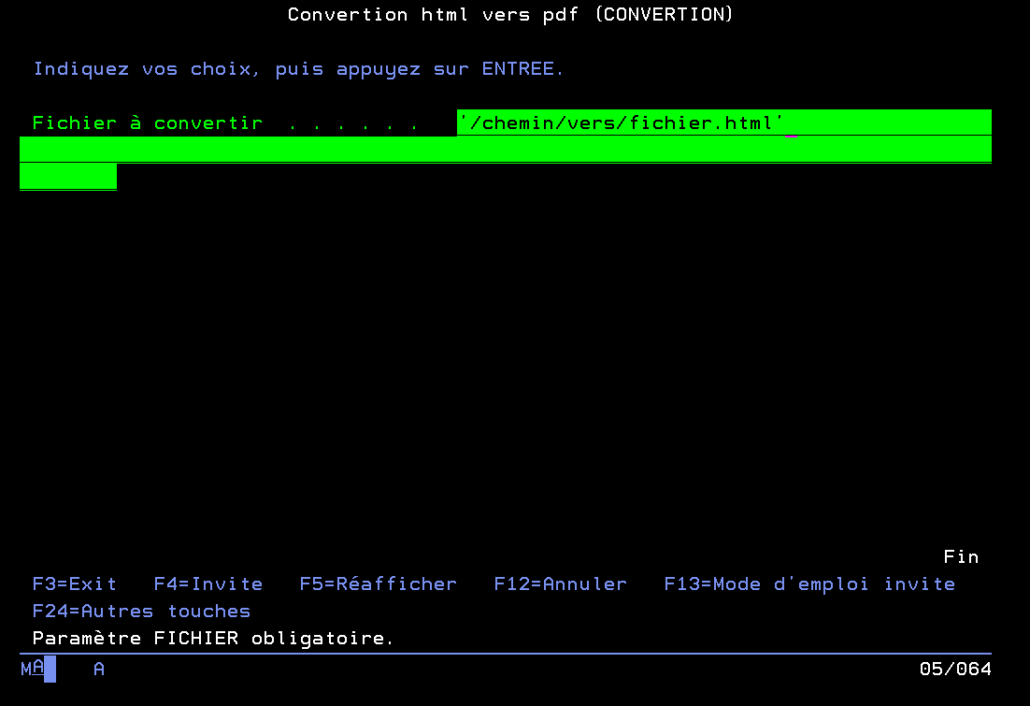
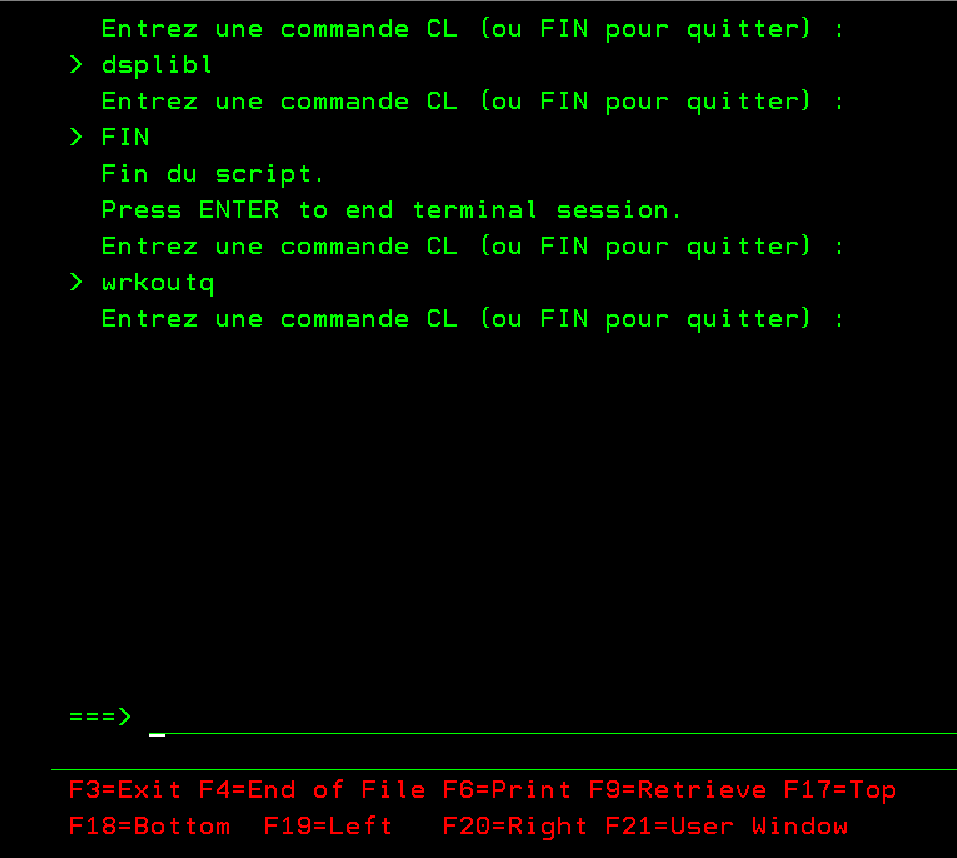
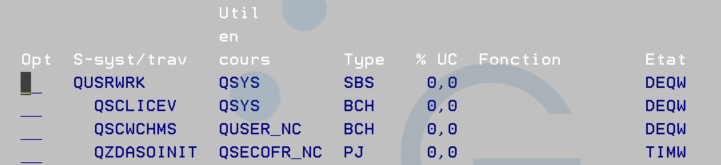
La semaine dernière, à Lyon, lors du congrès Common Europe 2026, nous avons parlé modernisation, APIs, IA… et futur de l’IBM i.
Mais au détour des conversations, difficile d’oublier une évidence :
une partie de notre ADN technologique est née ici même, à Lyon.
Et si les développeurs RPG d’aujourd’hui partageaient, sans toujours le savoir, un héritage direct avec les canuts et les métiers Jacquard ?
Lyon, berceau d’une révolution : le métier Jacquard
Au début du XIXe siècle, Lyon est la capitale mondiale de la soie. Les métiers à tisser sont complexes, coûteux et surtout… difficiles à piloter.
En 1801, Joseph Marie Jacquard introduit une innovation majeure : un métier à tisser contrôlé par des cartes perforées.
Chaque carte représente une ligne du motif à tisser. Les trous dictent mécaniquement quelles aiguilles doivent être activées.
C’est simple, robuste, et surtout :
- programmable
- reproductible
- automatisable
Autrement dit : le premier système programmable industriel de l’histoire.

Napoléon, sponsor inattendu du “code”
Le métier Jacquard n’a pas été immédiatement accepté. Les canuts voyaient cette innovation comme une menace pour leur savoir-faire… et certains métiers ont même été détruits. C’est finalement Napoléon Bonaparte qui a soutenu Jacquard et officialisé l’usage de sa machine.
On pourrait presque dire que l’histoire de la “programmation” a démarré avec :
- une innovation disruptive
- une résistance des utilisateurs
- et un sponsor politique pour imposer le changement
Un schéma… encore très actuel ?

La carte perforée : premier support de programmation
Le principe est fondamental :
L’information n’est plus dans la machine, elle est dans un support externe.
Chaque trou correspond à une instruction binaire :
- trou → action
- pas de trou → pas d’action
Ce modèle va traverser les décennies et inspirer directement les premiers systèmes informatiques.

Ada Lovelace avait déjà compris
Au XIXe siècle, Charles Babbage conçoit sa “machine analytique”, ancêtre de l’ordinateur.
Son idée ? Utiliser… des cartes perforées inspirées directement du métier Jacquard.
Et Ada Lovelace, souvent considérée comme la première développeuse de l’histoire, va encore plus loin. Elle comprend que la machine pourrait manipuler autre chose que des chiffres.
Elle écrit, en substance :
“La machine pourrait composer de la musique si on lui donnait les règles.”
Autrement dit : la programmation n’était déjà plus une question de calcul, mais de logique et de création.

Du textile au numérique : l’héritage IBM
IBM industrialise massivement l’usage des cartes perforées au XXe siècle.
Le RPG : un langage façonné par les cartes
Le langage RPG, introduit dans les années 1960, est directement conçu pour… les cartes perforées.
Chaque ligne de code correspond à une carte. Chaque colonne a une signification précise.
Exemple :
- colonnes 1–5 : libre
- colonne 6 : type de ligne
- reste : spécifications
Ce format n’est pas une contrainte arbitraire, c’est un héritage physique.
Une histoire de continuité
Nous n’avons pas changé de paradigme
Nous avons changé de support
Du métier Jacquard à l’IBM i :
- on programme
- on structure
- on exécute
Conclusion : coder, c’est tisser
À Lyon, pendant le Congrès de Common Europe, difficile de ne pas voir le parallèle :
Les développeurs IBM i sont les héritiers des canuts !
Et au fond, nous faisons le même métier : Transformer des instructions en valeur.