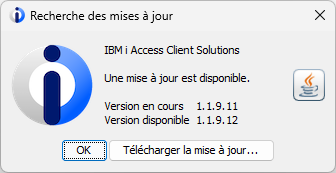
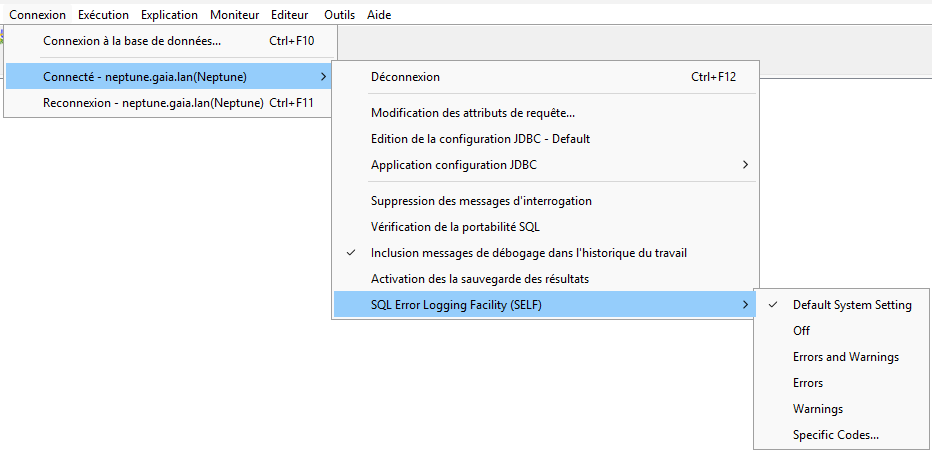
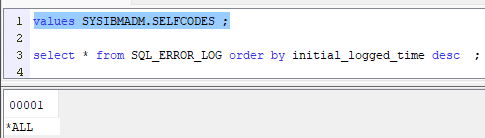
Concrètement, cela modifie la liste des erreurs qui sont tracées dans la vue SQL_ERROR_LOG. Cette liste est stockée dans la variable globale SYSIBMADM.SELFCODES, avec quelques valeurs spéciales (*ALL, *ERROR, *WARN, *NONE).
Fichiers physiques source
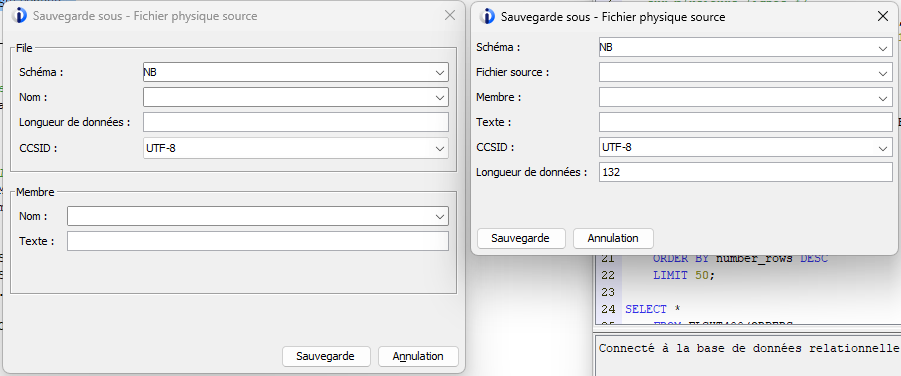
Amélioration de la fenêtre de dialogue pour la sauvegarde en fichiers sources :
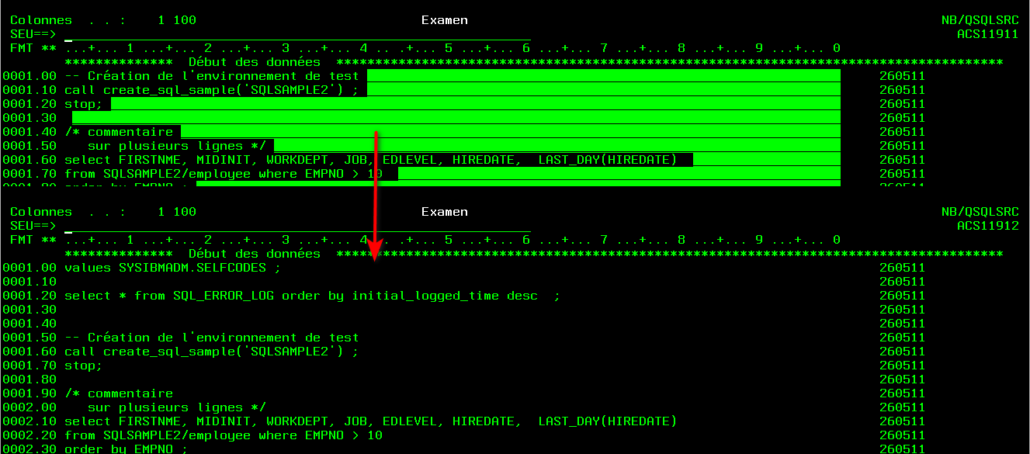
Gestion des fins de ligne
Les caractères LF (x’25’) ne sont plus insérés en fin de ligne dans le cas d’une sauvegarde en fichier source :
Il n’y pas d’impact à l’éxecution (RUNSQLSTM), mais plus de confort !
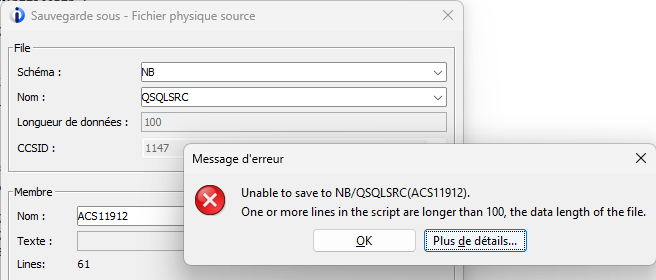
Gestion de la taille des lignes
Lors de l’enregistrement, au lieu de tronquer les lignes, un message permet d’avertir :
Exemples SQL
13 nouveaux exemples pour les services SQL :
SELF – System-wide controls
SELF – Job-level controls
SELF – Log Queries
SELF – Removing historical rows
SELF – Initial Stack
SELF – Top occurrences
SELF – QA use case exampleSecurity – Who is creating objects in the IFS root
Security – Who is creating objects in the /QOpenSys subdirectory
Security – IFS first-level directories that are open to attack
Sur IBM i, les groups d’activation sont au cœur de l’architecture ILE. Ils permettent de mutualiser efficacement les ressources tout en offrant un cadre d’exécution structuré et performant.
Dans la majorité des cas, le mécanisme de nettoyage automatique fourni par le système suffit largement. Mais dès que l’on travaille avec des service programs persistants, des ressources externes ou des APIs dont le cycle de vie dépasse un simple appel de programme, il devient nécessaire de reprendre la main.
C’est précisément là qu’intervient l’API CEE4RAGE.
CEE4RAGE signifie Register Activation Group Exit Procedure.
Son rôle est très simple mais fondamental : elle permet d’enregistrer une procédure qui sera appelée automatiquement lorsque l’activation group est détruit. Cette procédure est exécutée après les exit procedures des langages de haut niveau, mais avant le nettoyage final effectué par le système. On peut la voir comme un équivalent conceptuel d’un destructeur dans les langages orientés objet.
En effet, certains « nettoyages » ne peuvent pas, ou ne doivent pas, être laissés au seul mécanisme système. Certains composants nécessitent une fermeture explicite : mémoire allouée dynamiquement, connexions réseau persistantes, APIs externes, sockets, workers auxiliaires ou encore structures partagées. CEE4RAGE garantit que votre code de nettoyage sera exécuté quelle que soit la manière dont l’activation group se termine : retour normal, reclaim, exception ou même ENDJOB.
Le besoin dépend clairement du code ILE produit.
Usage
Un cas d’usage très courant concerne les service programs persistants. Lorsqu’un service program est chargé dans un activation group nommé ou avec *ACTGRP(CALLER), il peut rester actif longtemps, parfois pendant toute la durée de vie d’un job interactif. Dans ce contexte, il est essentiel de disposer d’un point fiable pour libérer proprement les ressources lorsque l’activation group disparaît enfin. CEE4RAGE fournit exactement ce point d’ancrage.
Une approche éprouvée consiste à mettre en place un pattern « constructeur / destructeur ». L’idée est simple : initialiser les ressources lors du premier appel effectif au service program, puis enregistrer une exit procedure via CEE4RAGE pour garantir le nettoyage automatique à la fin de l’activation group.
Exemple
Voyons maintenant un exemple concret en RPGLE free format, typique d’un service program.
Le service program est défini sans programme principal, hors DFTACTGRP, et dans un activation group persistant :
Le cœur du pattern repose sur une procédure d’initialisation, appelée systématiquement par les procédures métier exportées, mais dont le contenu réel ne s’exécute qu’une seule fois :
dcl-proc InzSrvPgm;
if Initialized;
return;
endif;
// Initialisation des ressources (exemple simulé)
ResourceHandle = 12345;
// Enregistrement de l'activation group exit procedure
CEE4RAGE(%paddr(EndSrvPgm): *omit);
Initialized = *on;
end-proc;
Cette procédure effectue trois choses essentielles :
elle initialise les ressources
enregistre l’exit procedure
mémorise le fait que l’initialisation est désormais réalisée
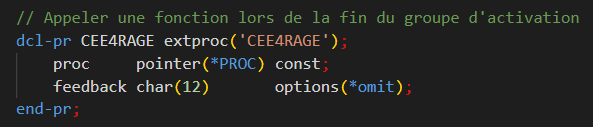
La procédure de terminaison, elle, sera appelée automatiquement par le système lorsque l’activation group prendra fin. Elle doit impérativement être exportée et respecter la signature attendue par l’ILE :
Enfin, toutes les procédures métier exportées commencent par appeler la procédure d’initialisation. Cela garantit que l’environnement est prêt avant toute logique fonctionnelle :
Une procédure d’exit d’activation group repose sur une interface composée de quatre paramètres standards, transmis automatiquement par le runtime lors de la terminaison de l’activation group :
agMark, correspond au marqueur interne de l’activation group. Il s’agit d’un identifiant numérique unique dans le job, principalement utile à des fins diagnostiques ou pour des scénarios avancés impliquant plusieurs activation groups simultanés. Dans la majorité des cas, ce paramètre est simplement ignoré, mais il permet théoriquement de corréler une terminaison précise à un contexte donné.
reason, indique la raison de la fin de l’activation group : retour normal, reclaim, fin de job, exception non interceptée, etc. Ce code est particulièrement précieux pour adapter le comportement du cleanup, par exemple en évitant certaines opérations coûteuses lors d’une fin brutale.
result et userRC, sont des champs en entrée/sortie permettant respectivement au système et au programme de communiquer un code de résultat et une information spécifique utilisateur. En pratique, ils sont rarement exploités, mais ils offrent un mécanisme de retour standardisé permettant à une exit procedure de signaler son état ou d’influencer légèrement le déroulement du traitement global. L’ensemble de ces paramètres est optionnel côté RPG, ce qui explique l’usage fréquent de options(*nopass) ; toutefois, leur présence formalise le contrat entre le runtime ILE et la procédure d’exit, et rappelle que cette dernière s’exécute dans un contexte très particulier, où la logique doit être minimale, robuste et parfaitement maîtrisée.
Multiples procédures
Dans certains cas plus avancés, il peut être tout à fait légitime d’enregistrer plusieurs procédures d’exit pour un même activation group.
CEE4RAGE ne limite ni le nombre de procédures enregistrées, ni leur nature : chaque appel ajoute une entrée dans la pile des exit procedures, qui seront exécutées dans l’ordre inverse de leur enregistrement lors de la fin de l’activation group.
Cette capacité est particulièrement utile lorsque plusieurs composants indépendants partagent le même activation group : chaque service program peut alors enregistrer sa propre procédure de nettoyage, sans dépendre d’un point centralisé.
Il est cependant essentiel de concevoir ces exit procedures comme autonomes, simples et robustes, car une défaillance dans l’une d’elles empêche l’exécution des suivantes. Dans ce contexte, l’ordre d’enregistrement devient un véritable élément d’architecture : on veillera par exemple à enregistrer en dernier les procédures critiques, ou à utiliser une procédure « chef d’orchestre » qui appelle explicitement plusieurs routines de cleanup internes.
L’utilisation de procédures d’exit multiples est donc un mécanisme puissant, mais qui impose une discipline stricte : absence d’effets de bord, opérations idempotentes, et compréhension claire du cycle de vie global de l’activation group.
Conclusion
Ce pattern est robuste, simple et parfaitement aligné avec les mécanismes de l’ILE.
Il fonctionne aussi bien en batch qu’en interactif, résiste aux fins de job brutales et assure un comportement prévisible dans les architectures persistantes. Il est particulièrement adapté aux environnements modernisés où des composants RPG sont exposés comme briques partagées, parfois appelées par des couches Java, C ou web.
Il convient toutefois de garder quelques points en tête. CEE4RAGE n’est jamais appelée tant que l’activation group reste actif ; si celui-ci est volontairement maintenu pendant toute la durée du job, le nettoyage n’aura lieu qu’à la toute fin. De plus, si une exit procedure échoue, les suivantes ne seront pas exécutées. Il est donc essentiel d’y écrire un code simple, robuste et sans dépendances fragiles.
En conclusion, CEE4RAGE est une API discrète mais fondamentale. Elle ne sert pas à gérer des erreurs ni à intercepter des messages système ; elle sert à maîtriser la fin de vie d’un activation group.
Dès que l’on conçoit des service programs persistants et que l’on vise une architecture propre et professionnelle sur IBM i, CEE4RAGE devrait faire partie des outils de base de tout concepteur ILE.
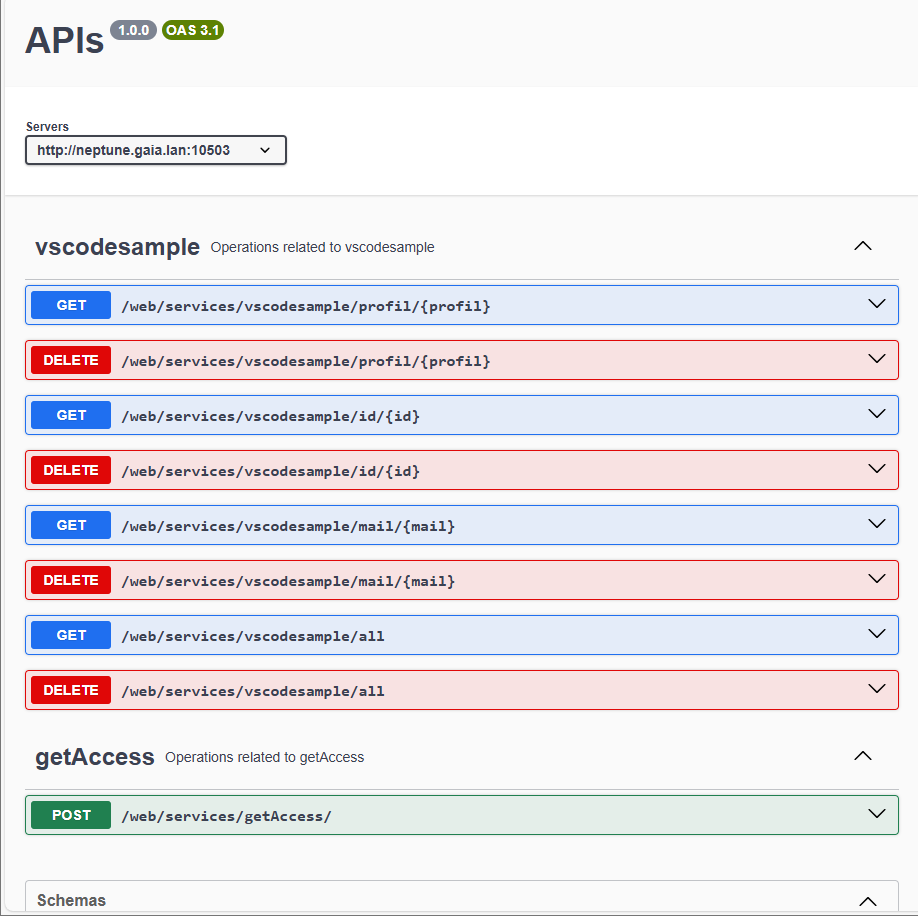
C’est en réalité l’évolution du Swagger qui permet de décrire les web services et leurs interfaces. L’interface produit désormais une page, personnalisable, epxosant la description des services, et permettant leur test !
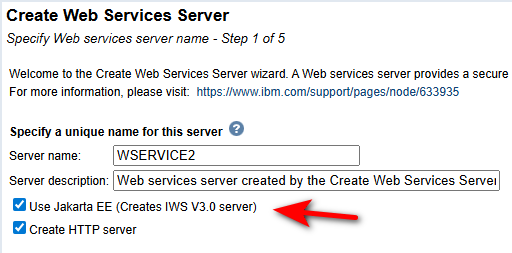
Modifications de l’interface
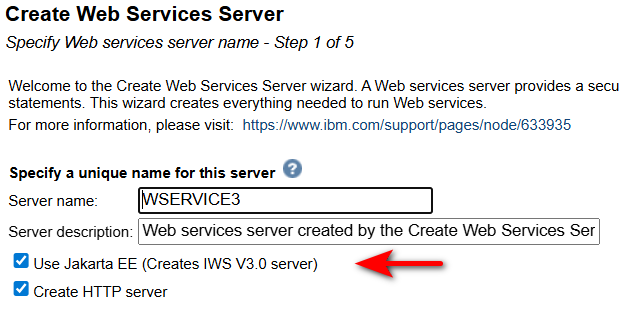
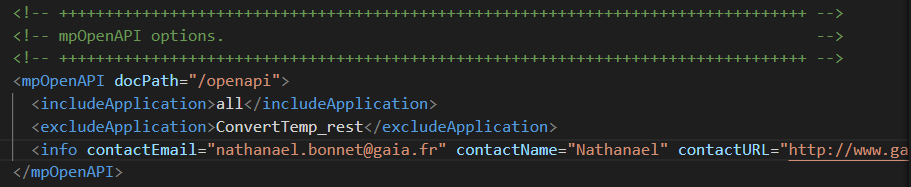
Lors de la création d’une instance IWS :
Les propriétés openapi ne sont pas affichables ou modifiables par l’interface, mais pas fichier de configuration et commande shell.
Remarque : seuls les services démarrés apparraissent dans l’interface openapi.
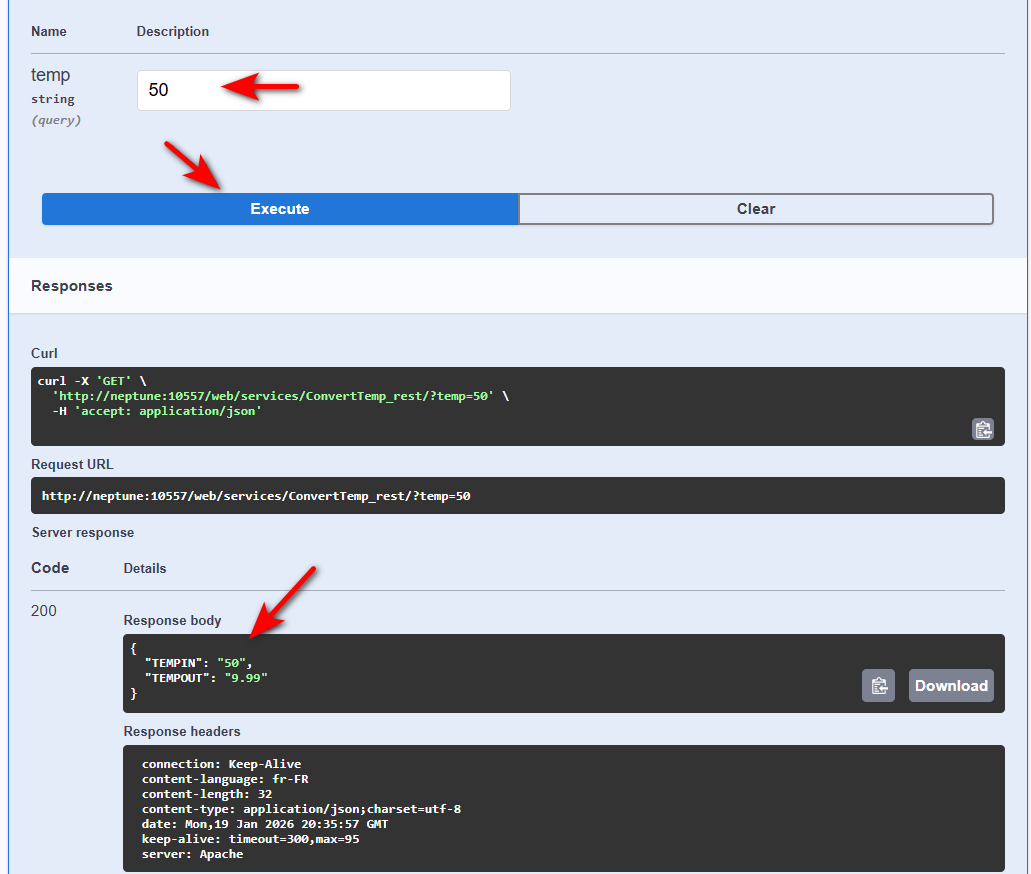
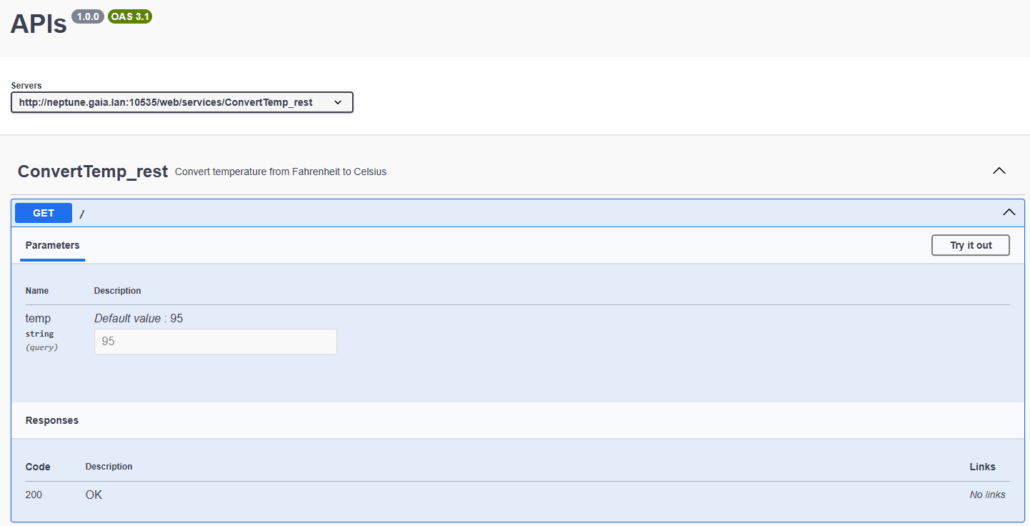
Tester un service REST
Puis indiquez vos valeurs de paramètres :
Des options sont disponibles pour les situations plus avancées (authentification basique etc …)
Modifications des commandes shell
Depuis la documentation IBM, création d’un fichier :
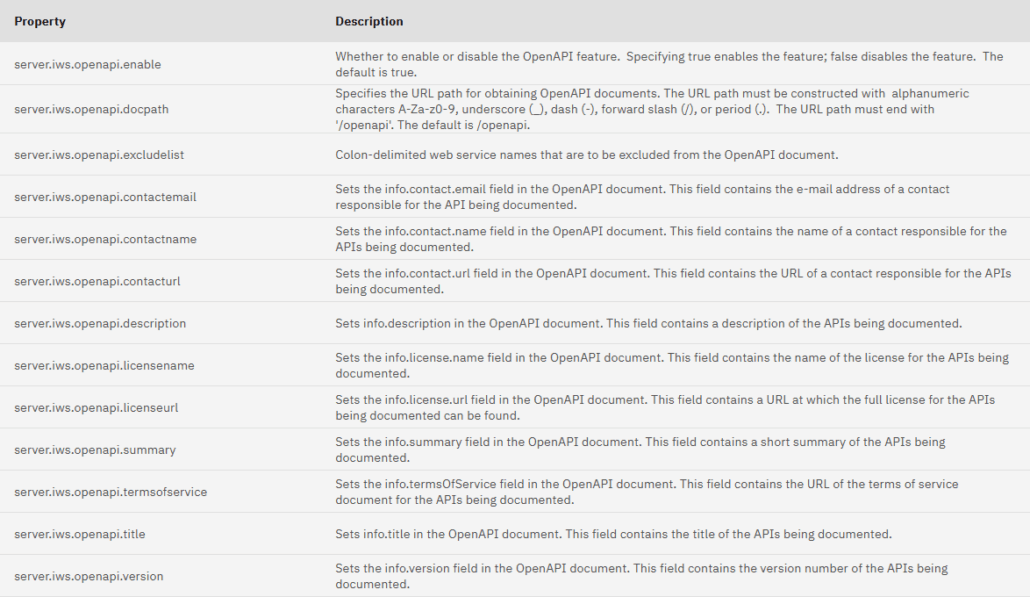
#server.iws.gen.httpport=52000 #server.iws.gen.httpsport=52499 #server.iws.gen.adminport=52005 #server.iws.gen.contextroot=/api #server.iws.gen.defaultkeystore=*NONE #server.iws.gen.defaultkeystorepassword= #server.iws.gen.verifyhostname=false #server.iws.gen.trace=none
# Following are OpenAPI properties - IWS 3.0 only properties
server.iws.openapi.enable=true
server.iws.openapi.docpath=/openapi
server.iws.openapi.contactemail=nathanael.bonnet@gaia.fr
server.iws.openapi.contactname=Nathanael
server.iws.openapi.contacturl=http://www.gaia.fr/contact
server.iws.openapi.description=Description : test NB pour IWS 3.0
server.iws.openapi.licensename=License Gaia 2.0
server.iws.openapi.licenseurl=https://www.gaia.fr/license
server.iws.openapi.summary=Summary : test NB pour openAPI
server.iws.openapi.termsofservice=https://www.gaia.fr/terms
server.iws.openapi.title=Titres : APIs for IWS 3.0
server.iws.openapi.version=9.8.7
server.iws.openapi.excludelist=ConvertTemp_rest
Vous pouvez ensuite demander la mise à jour des propriétés de l’instance :
qsh
cd /qibm/proddata/os/webservices/bin
setWebServicesServerProperties.sh -server 'vsc_sndbox' -propertiesFile '/www/vsc_sndbox/conf/server.properties'
Affiche :
IWS00106I - Command completed successfully. Restart of web service or server may be required for changes to take affect.
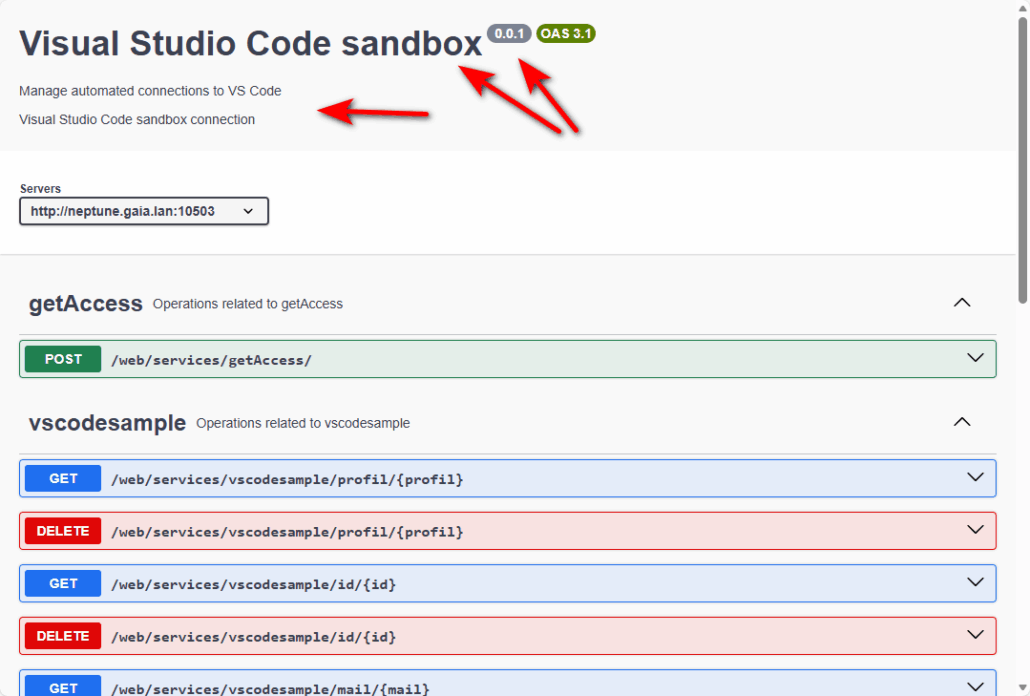
Après redémarrage de votre instance, accès à http[s]//…./openapi/ui :
Remarque : il est aujourd’hui impossible de générer un fichier de configuration pour un serveur existant.
Les différentes propriétés :
server.xml
La commande sss.sh met à jour les propriétés openapi dans le fichier \www\instance\wlp\usr\servers\instance\server.xml
Migration des instances en version 2.6
Vous pouvez migrer une instance par la commande /qibm/proddata/os/webservices/bin/
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-02-24 09:50:002026-02-23 11:56:40Open api avec IWS 3.0 – partie 2
News, Non classéIBM i en 2026 : la pénurie de compétences, une réalité désormais impossible à ignorer
En 2026, un fait majeur ressort du IBM i Marketplace Survey : la pénurie de compétences IBM i devient la préoccupation n°1, devant la cybersécurité, pour la première fois en presque dix ans.
Les départs à la retraite s’accélèrent, les équipes se réduisent, les projets se complexifient… et le renouvellement est insuffisant. Pourtant, tout n’est pas sombre : l’écosystème évolue, de nouvelles approches émergent, et certains pays — comme la France — disposent d’atouts uniques pour former rapidement.
Un départ massif des experts… et un vivier insuffisant pour les remplacer
La démographie joue contre les organisations : une large majorité des spécialistes IBM i ont plus de 50 ans, beaucoup étant déjà partis ou proches de la retraite. Pendant ce temps, le monde académique continue d’ignorer RPG et IBM i.
Résultat :
une perte d’expertise métier cumulée,
des applications critiques peu documentées,
et un risque croissant de dépendance à un ou deux profils clés.
Cette situation explique pourquoi 69 % des entreprises déclarent la compétence IBM i comme souci majeur.
La France dispose pourtant d’un avantage rare pour former rapidement
Sans trop appuyer le trait, il faut reconnaître un point souvent méconnu : la France bénéficie d’un écosystème particulièrement performant pour former rapidement de nouveaux talents. Nous profitons en effet d’un ensemble de dispositifs privés et publics qui, fait notable, savent travailler en synergie.
Les POEI, organisées depuis plus de dix ans sous de multiples formats, en sont une illustration concrète : elles permettent de financer une formation ciblée avant embauche pour répondre à un besoin métier précis. S’y ajoutent un foisonnement d’initiatives autour de l’alternance, ainsi qu’une offre de formation professionnelle soutenue par les OPCO, qui facilite la montée en compétences sur des technologies spécifiques.
Cet ensemble de mécanismes donne aux entreprises la possibilité de former un candidat avant embauche afin de combler un écart de compétences — une approche parfaitement alignée avec les réalités IBM i, où l’on privilégie depuis longtemps la montée en compétences plutôt que la quête du “profil idéal introuvable”.
On observe toutefois une absence notable de formations institutionnelles (lycées professionnels, BUT, universités, écoles d’informatique) portant sur IBM i ou RPG. Cela limite naturellement la visibilité du domaine auprès des jeunes.
Cela ne règle pas tout, mais c’est un avantage concret pour les organisations françaises qui souhaitent attirer et intégrer de nouveaux talents dans l’écosystème IBM i.
Quand l’IA ralentit l’entrée des jeunes dans l’IT… y compris sur IBM i
Un autre phénomène joue en arrière‑plan en 2026 : l’IA fait baisser les embauches juniors dans l’ensemble du secteur IT.
Selon Korn Ferry, 37 % des entreprises prévoient de remplacer des postes d’entrée de carrière par l’IA. Gartner observe la même tendance : les entreprises recourent davantage à l’IA pour les tâches “low value”, ce qui réduit mécaniquement les opportunités d’entrée des jeunes diplômés.
Sans dramatiser, cela signifie que :
le renouvellement naturel des compétences pourrait ralentir,
les experts actuels deviennent encore plus stratégiques,
et il sera mécaniquement plus difficile de les remplacer lorsqu’ils partiront.
Pour IBM i, déjà confronté à un déficit de nouveaux talents, cet effet secondaire de l’IA mérite d’être surveillé.
Mais où sont les “centaines” ou “milliers” de postes IBM i dont on parle ?
La question revient souvent, et elle est légitime : si les besoins sont si énormes, pourquoi ne voit‑on pas une avalanche d’offres d’emploi IBM i ?
Quelques éléments de réponse — sans exagération :
1. Un besoin réel mais très fragmenté
Les organisations IBM i fonctionnent souvent avec de petites équipes (3–5 personnes), un modèle stable depuis des années selon la Marketplace Survey. Elles recrutent surtout au fil des départs, pas par vagues massives.
2. Un marché qui “tient” avec ce qu’il a
Les entreprises retardent les modernisations, réorganisent en interne, externalisent ponctuellement ou repoussent le recrutement. Le marché de l’emploi IBM i montre d’ailleurs une embauche lente, malgré la hausse des salaires, comme observé dans les analyses emploi de 2024–2025.
3. Une demande qui change de nature
Les entreprises ne cherchent plus seulement des “développeurs RPG”, mais des profils capables de :
faire du Git,
moderniser le code,
exposer des API,
intégrer des outils open source ou cloud.
La demande existe, mais elle est hybride, moins visible, et souvent absorbée par de la prestation.
4. Une partie du besoin est transférée vers des MSP ou vers le cloud
Le survey 2026 montre une montée du cloud et des providers de services, utilisés pour déporter une partie des responsabilités (maintenance, HA/DR, sécurité). Cela réduit mécaniquement le volume d’offres en direct.
Conclusion : un vrai défi… mais aussi une fenêtre d’opportunité
L’écosystème IBM i fait face à une équation complexe :
Une pénurie de compétences reconnue et mesurée (69 % des organisations).
Une dynamique mondiale où l’IA réduit les postes juniors, freinant l’arrivée des nouveaux talents.
Une demande réelle mais diffuse, structurée par du remplacement plutôt que du recrutement massif.
Pour autant, les solutions existent :
programmes de formation internes,
mentorat et documentation,
modernisation technique,
et, en France, un atout concret avec la POEI qui permet d’intégrer et de former des jeunes profils rapidement.
La plateforme IBM i reste robuste, moderne et stratégique. Désormais, l’enjeu est clair : organiser le renouvellement des compétences plutôt que l’attendre.
Nous avons bien d’autres thèmes à prendre en compte, comme une communauté active et engagée, mais nous en reparlerons !
/wp-content/uploads/2017/05/logogaia.png00Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-02-09 16:16:442026-02-09 16:16:45IBM i en 2026 : la pénurie de compétences, une réalité désormais impossible à ignorer
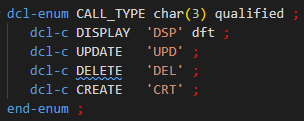
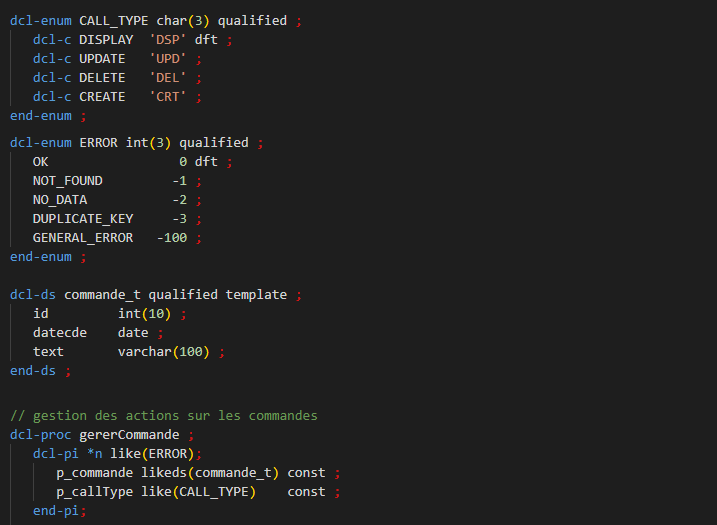
Depuis décembre 2025, le compilateur RPG permet la déclaration d’une énumération typée, ainsi que de variables de même type que l’énumération.
Prérequis
Avoir les PTFs :
7.5:
ILE RPG compiler: 5770WDS SJ08375
7.6:
ILE RPG compiler: 5770WDS SJ08384
ILE RPG compiler, TGTRLS(V7R5M0): 5770WDS SJ08394
Syntaxe
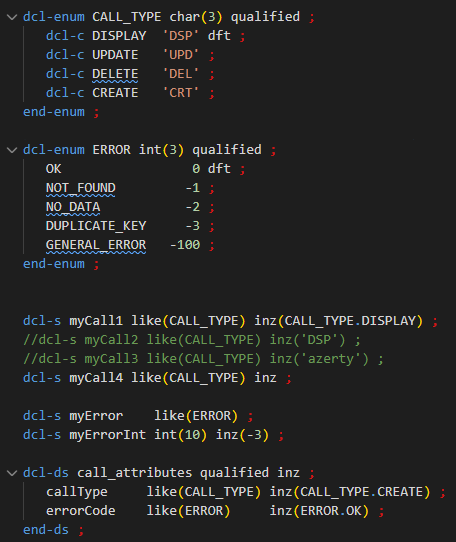
Par exemple :
Il faut indiquer le type précis de l’énumération, ici CHAR(3). Les valeurs des constantes énumérées doivent correspondre au type.
DFT indique une valeur par défaut : 1 et 1 seule, facultatif.
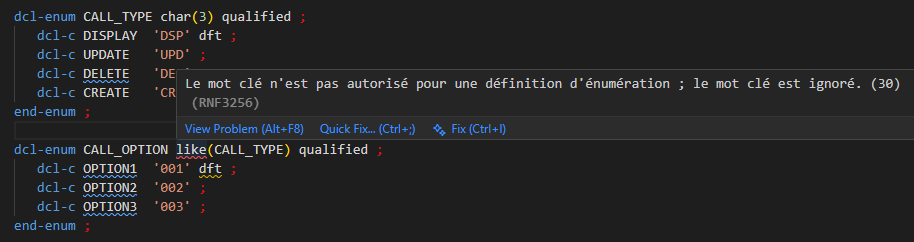
Il est impossible de définir une énumération comme une autre énumération :
Par contre, vous pouvez définir des variables comme une énumération typée :
Quelques règles
une valeur par défaut supportée par énumération
initialisation des variables ou zone de DS par une valeur de l’énumération :
dcl-s myCall1 like(CALL_TYPE) inz(CALL_TYPE.DISPLAY) : OK
dcl-s myCall2 like(CALL_TYPE) inz('DSP') : Erreur, même si la valeur existe dans l’énumération
si inz est indiqué sans valeur, la valeur par défaut de l’énumération est utilisée
de même pour l’affectation d’une nouvelle valeur, doit se faire via l’énumération, quelque soit le type de valeur :
myCall1 = CALL_TYPE.UPDATE : OK
myCall1 = 'UPD' oumyCall1 = ('U' + 'PD') : Erreur
Les fonctions %hival et %loval fonctionnent
Contrairement à*hival et*loval
En tant que tableau ou liste
Il est possible d’utiliser une énumération partout où un tableau est utilisable, sauf avec :
SORTA
%elem
%lookup
%subarr
Par exemple en tant que liste :
Domaine de validité
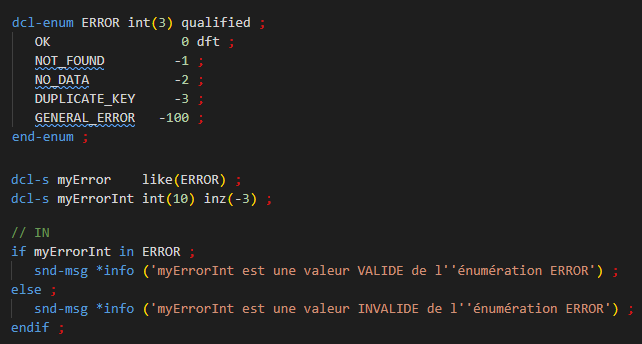
Seules les valeur de l’énumération sont utilisables, toute autre valeur provoque une erreur de compilation.
Toutefois, il est possible de contourner ce fonctionnement.
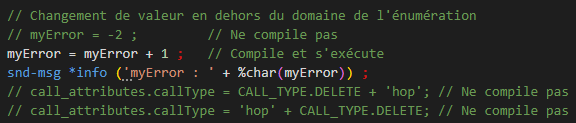
Pour les variables de type numérique, les calculs sont autorisés :
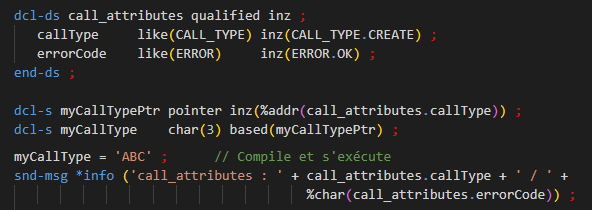
En passant avec un pointeur :
En paramètre de procédure
Cela permet d’indiquer explicitement les valeurs autorisés pour les paramètres définis comme une énumération :
la valeur de retour est définie parlike(ERROR) et ne pourra avoir que les valeurs définies
le paramètre p_callType est défini parlike(CALL_TYPE) pour lequel les valeurs sont également définies
C’est beaucoup plus pertinent qu’un commentaire, le compilateur effetuant le contrôle.
Précompilateur SQL
Les valeurs énumérées sont reconnues en tant que constantes, et les variables définies depuis une énumération sont utilisables :
Par contre, l’affectation d’une valeur non énumérée est possible :
L’utilisation en tant que liste de valeurs dans un IN SQL n’est pas supportée :
option de compilation CCSID(*EXACT)
Si votre énumération est définie en CHAR ou VARCHAR et contient des valeurs non définies par des constantes hexadécimales, c’est à dire la plupart des cas, vous devez indiquer ctl-opt ccsid(*exact).
C’est une obligation afin que le compilateur ne fasse pas de supposition incorrecte sur le CCSID des littéraux pour comparaison avec les variables de vos programmes. Aucune conversion implicite n’est effectuée et cela évote les incohérences que l’on peut avoir, particulièrement avec des fichiers source dans l’IFS, généralement encodés en UTF-8.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-01-20 09:50:002026-01-19 11:18:19Open api avec IWS 3.0
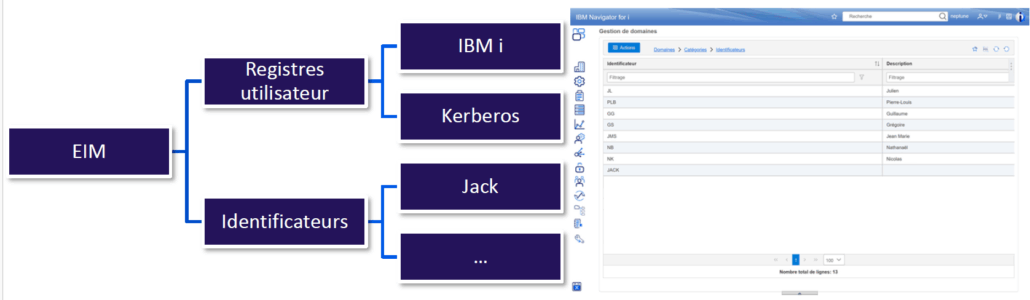
Si vous êtes utilisateur de SSO (Single Sign On) sur l’IBM i, alors vous utilisez l’EIM (Enterprise Identity Mapping).
Pour rappel (en très simplifié), le SSO vous permet de propager votre authentification Windows jusqu’à l’IBM i de sorte que n’avez pas besoin de saisir votre profil/mot de passe : une association entre vos comptes Windows et IBM i est réalisée et prise en compte automatiquement.
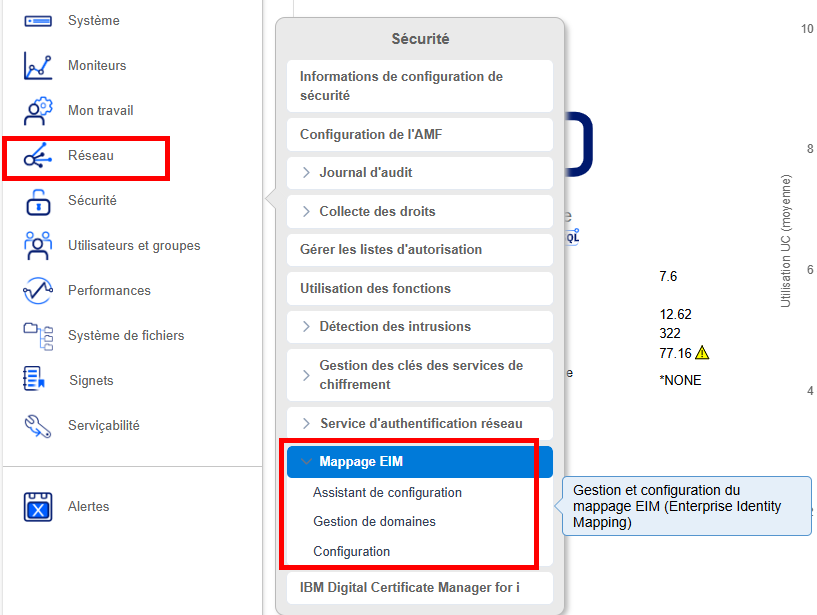
Pour gérer ces associations, vous pouvez utiliser IBM Navigator for i :
A partir de là vous avez accès à toute la gestion de l’annuaire (nécessite une authentification).
Bien entendu, ces fonctions sont critiques d’un point de vue de la sécurité : une modification de la configuration peut empêcher toute connexion, ou au contraire permettre une connexion avec un profil IBM i élevé !
IBM a donc délivré une nouvelle fonction d’usage QIBM_NAV_SECURITY_EIM (EIM related security) à cet effet : limiter l’accès aux fonctions EIM via Navigator for i.
La valeur par défaut est *ALLOWED pour tous -> vous devriez la passer à *DENIED !
Dès lors, si vous tentez d’accéder aux fonctions EIM, vous obtenez :
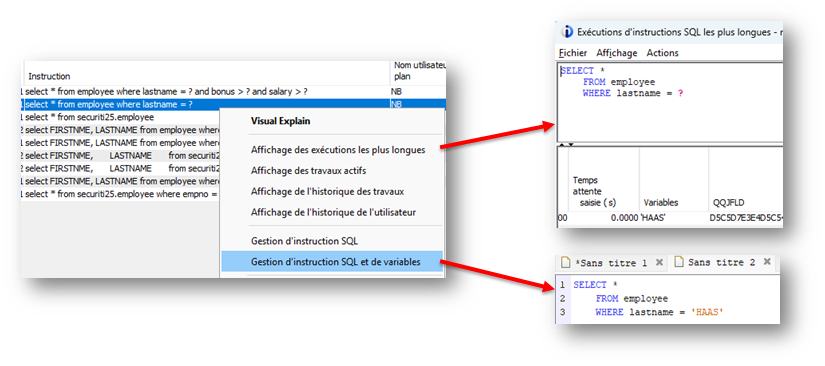
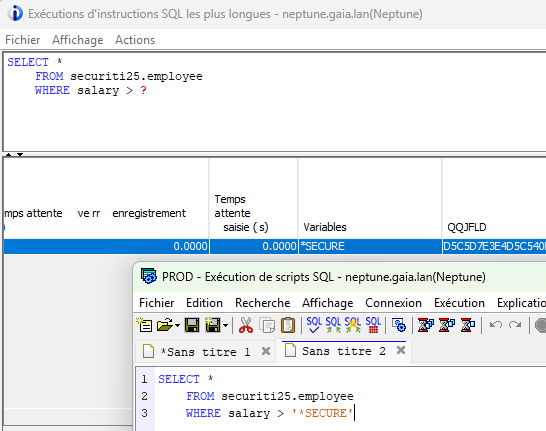
Si vous avez assisté à l’événement Securiti 2025 organisé par i.gayte.it, nous avions présenté une fonctionnalité SQL permettant de limiter l’accès aux informations du plan cache SQL.
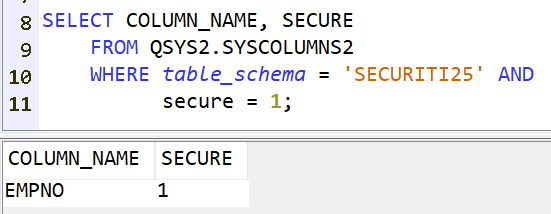
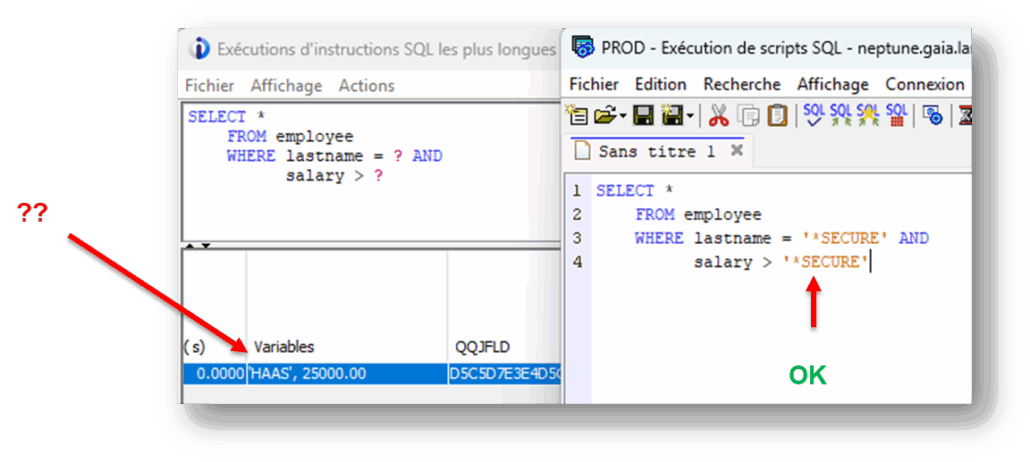
En effet, ce dernier contient de nombreuses informations nécessaires à l’adaptation du moteur SQL. Mais il contient aussi les données utilisées dans vos requêtes : constantes littérales, valeurs de comparaisons …
Bien entendu, certaines valeurs sont à protéger, y compris des utilisateurs ayant les droits de consulter le plan cache.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-12-23 09:50:002025-12-16 08:44:24Sécurité du plan Cache SQL
Vous avez assisté, ou non, à la Power Week coorganisée par IBM France et Common France :
Gaia-Volubis a été très heureux de participer à cette édition, riche en annonces. Avant de reprendre une vie normale, de retourner à notre quotidien, voici le retour de nos speakers !
Damien
C’est toujours un moment particulier pour nous dans notre calendrier, et cette année n’aura pas dérogée aux autres : beaucoup de participants, d’échanges que ce soit avec des clients ou des IBMers, quelques dépannages en direct ! 3 jours intenses.
Merci aux participants à nos sessions et à leurs retours. Il est toujours appréciables de savoir que nos choix de sujets correspondent à des attentes des participants à l’évènement. Prochain évènement de masse : le Common Europe à Lyon en juin 2026…
Florian
Trois jours intenses et passionnants pour cette édition de la Power Week 2025 !
Au-delà du programme officiel, ce sont surtout les échanges directs avec nos clients, partenaires, IBMers et l’ensemble des participants qui ont marqué l’événement. Ces discussions spontanées, souvent en marge des sessions, sont celles qui font grandir notre réseau, ouvrent des perspectives et apportent des idées concrètes pour aller plus loin.
J’ai également pu présenter COMMON France et toutes les actions que nous avons menées cette année, notamment la Battle Dev que j’ai eu le plaisir de coorganiser avec Philippe Bourgeois et Jérôme Clément. J’espère que nous pourrons organiser une 4ᵉ édition l’année prochaine !
Merci à tous d’être venus !
Julien
Merci à toutes et à tous pour ces trois journées intenses à la Power Week 2025 !
J’ai particulièrement apprécié la qualité des échanges avec nos clients, partenaires et IBMers. Ces moments informels, toujours très enrichissants, sont essentiels pour nourrir notre réseau et nos perspectives.
J’ai également été heureux de présenter deux sessions orientées sécurité et bonnes pratiques sur IBM i, des sujets au cœur des préoccupations de nombreux clients. Merci pour votre participation et vos questions !
L’événement a une nouvelle fois confirmé sa convivialité, et la troisième édition de la Battle Dev a été remarquablement organisée.
Ravi de vous avoir retrouvés en nombre, et déjà impatient de vous revoir au Common Europe à Lyon en juin 2026 !
Betty
Ces trois jours au cœur de la communauté IBM étaient d’une richesse incroyable.
Ils m’ont permis d’avoir une vue plus globale et plus synthétique de la puissance, des possibilités et de l’avenir du power et de ses applications.
Mais le futur s’écrit aussi avec la jeune génération de programmeurs, et la présence des participants à la pépinière de cette année m’a permis de voir que la relève était assurée grâce à ces formations.
J’ai eu l’occasion de faire une première présentation qui concernait la modernisation via SQL, et je n’ai aucun doute que les équipes hybrides qui se construisent actuellement avec des jeunes et des personnes plus expérimentées sauront trouver des méthodes de travail permettant d’aller vers cette modernisation, nécessaire, et souhaitée.
Eric
3 jours intenses de rencontres, des visages connus et des nouveaux venus. 3 jours de sessions intéressantes. Toutes les personnes rassemblées ont en commun un grand intérêt, voire même une passion pour leur système favori. Une communauté IBMi toujours aussi active.
J’ai pu cette année présenter la session « Modernisation avec SQL : comment Intégrer l’existant », avec BETTY et LUCAS. Notre première session. Ce fut intense à préparer, et à présenter.
Les outils open source ont suscité mon intérêt cette année. La présentation de BOB a été très instructive, bien qu’il reste de nombreuses questions encore sans réponse.
Merci à tous pour votre énergie et votre participation!
Pierre Louis
C’est avec plaisir que comme chaque année, on retrouve la communauté IBMi, cette année pour la première fois les gens du monde Power nous ont rejoint.
On a pu assister à des présentations techniques intéressantes, beaucoup était basées sur l’IA, comme BOB , dont la présentation a été très prometteuse …
Pour ma part j’ai trouvé très intéressant le produit MANZAN qui permet de supervisé votre IBMi et qui a l’air simple et efficace.
Cette année, j’ai présenté 2 sessions en duo avec Gautier Dumas, sur le chemin de modernisation et avec Florian Gradot sur, comment donner une seconde vie à vos application 5250, merci a eux de m’avoir supporté, ce fut une expérience intéressante.
J’ai pu échangé sur des thèmes différents, avec des clients et des partenaires, ce qui est toujours enrichissant.
Merci à IBM et à Common pour cette organisation, merci à ceux qui sont venus, et l’année prochaine !
Nathanaël
3 jours très intenses pour ma part, mais très enrichissants !
Les meilleurs moments : ceux que l’on ne peut pas mettre en photo 😉
J’ai particulièrement apprécié de pouvoir échanger de façon libre et informelle avec nos clients, partenaires, IBMers et de façon plus globale toutes les personnes présentes. C’est important, c’est la construction d’un réseau, un réseau qui apporte des perspectives, des solutions.
Donc merci à vous d’être venu, nombreux, y compris dans non sessions, de poser des questions. C’est ce qui nous donne l’énergie pour les mois à venir jusqu’au prochain grand rassemblement !
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
https://www.gaia.fr/wp-content/uploads/2025/11/Media-xx-7.jpg12001600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-25 10:04:172025-11-25 10:05:02Power Week 2025 : retour à la maison !
Cela n’a pas pu vous échapper, la semaine prochaine c’est (déjà) la Power Week, événement gratuit coorganisé par IBM France et Common France :
Durant ces 3 jours dédiés au Power Systems, au stockage, au Power11, à l’IA, à l’IBM i, AIX, Linux, la modernisation … retrouvez l’ensemble des speakers, des partenaires et des clients qui font la force de notre plateforme.
Un programme riche (et international)
Pendant trois jours, les participants auront accès à des sessions animées par les meilleurs experts, venus de France, d’Allemagne, des États-Unis … Parmi eux, des IBM Champions, reconnus pour leur expertise et leur engagement auprès de la communauté, partageront leurs connaissances sur des sujets variés : modernisation, sécurité, SQL, DevOps, IA, cloud hybride, et bien plus encore.
La Power Week est 100 % gratuite et ouverte à tous les professionnels de l’IBM i : développeurs, architectes, DSI, chefs de projet, consultants… C’est une opportunité rare de bénéficier de contenus de qualité sans contrainte logistique ni financière.
La force de la communauté
Au-delà des conférences, la Power Week est un lieu de rencontre et d’échange. Elle permet de :
Réseauter avec d’autres professionnels confrontés aux mêmes enjeux
Confronter les points de vue, partager des bonnes pratiques
Découvrir les clubs utilisateurs comme Common France, qui jouent un rôle dans l’animation de la communauté en France, mais aussi au niveau Européen.
Ces moments d’échange sont essentiels pour faire évoluer les pratiques, identifier des solutions concrètes, et tisser des liens durables.
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
Les speakers de Gaia et Volubis sont très heureux de participer à cette célébration : échange, partage, connaissance.
En tant que sociétés liées à la formation, il est dans notre ADN de participer à ces initiatives, comme nous le faisons depuis longtemps : les Universités IBM i depuis 2011, Pause Café en physique ou en ligne, articles de blogs …
N’hésitez pas à solliciter nos speakers sur place !
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-11 10:00:002025-11-10 19:37:40Power Week 2025 : 3 jours pour se connecter, apprendre et faire rayonner la communauté IBM i