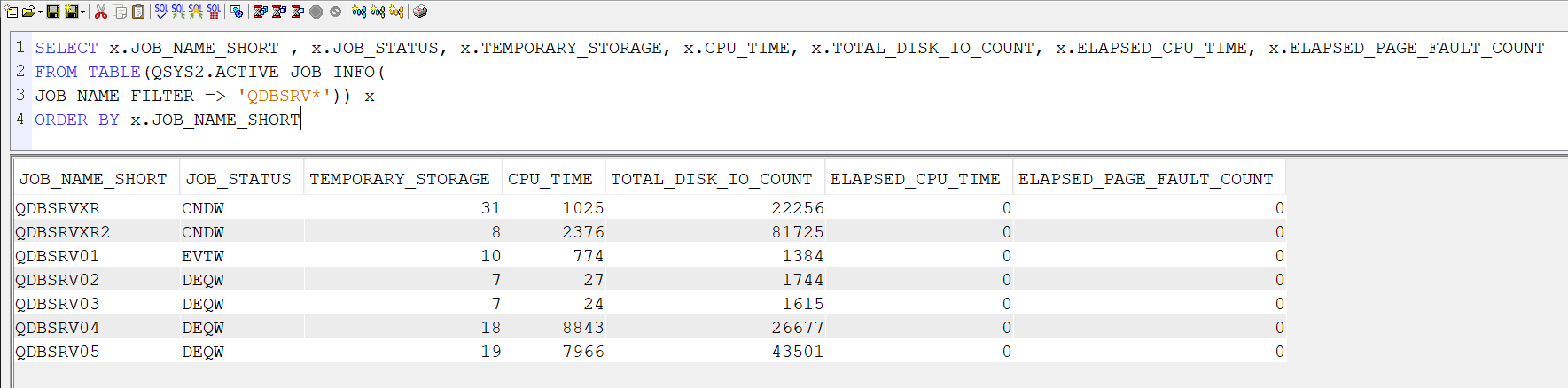
Le fichier QAQQINI sert à paramétrer les exécutions SQL pour un travail , et donc à donner des directives spécifiques sur les exécutions de requêtes, pour un travail donné.
On ne verra pas ici toutes les options disponibles à ce jour, mais on présentera le principe.
Celui qui est utilisé par défaut, c’est celui que QUSRSYS
Vous avez le message bien connu dans vos logs
Vous pouvez dupliquer ce fichier par ==>CRTDUPOBJ, puis le customiser par SQL,
Vous pouvez alors changer ce fichier pour votre travail en indiquant la bibliothèque qui contient le fichier QAQQINI souhaité
Par la commande CLP
==>CHGQRYA QRYOPTLIB(VOTREBIB)
En sql en utilisant la procédure OVERRIDE_QAQQINI
Création d'un fichier QAQQINI dans QTEMP
Call override_qaqqini(‘1’ , ‘ ‘ , ‘ ‘)
Modification des valeurs le job ici pour utiliser les MQTs
Call override_qaqqini(‘2’ , ‘MATERIALIZED_QUERY_TABLE_REFRESH_AGE‘ , ‘*ANY‘)
Call override_qaqqini(‘2’ , ‘MATERIALIZED_QUERY_ TABLE_USAGE‘ , ‘*ALL‘)
Suppression de qaqqini de QTEMP, si nécessaire
Call override_qaqqini(‘3’ , ‘ ‘ , ‘ ‘)
Attention le profil qui exécute doit à voir *JOBCTL (gestion des travaux)
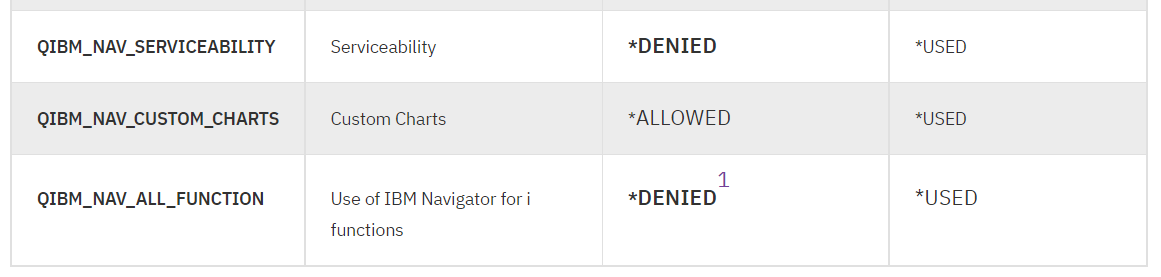
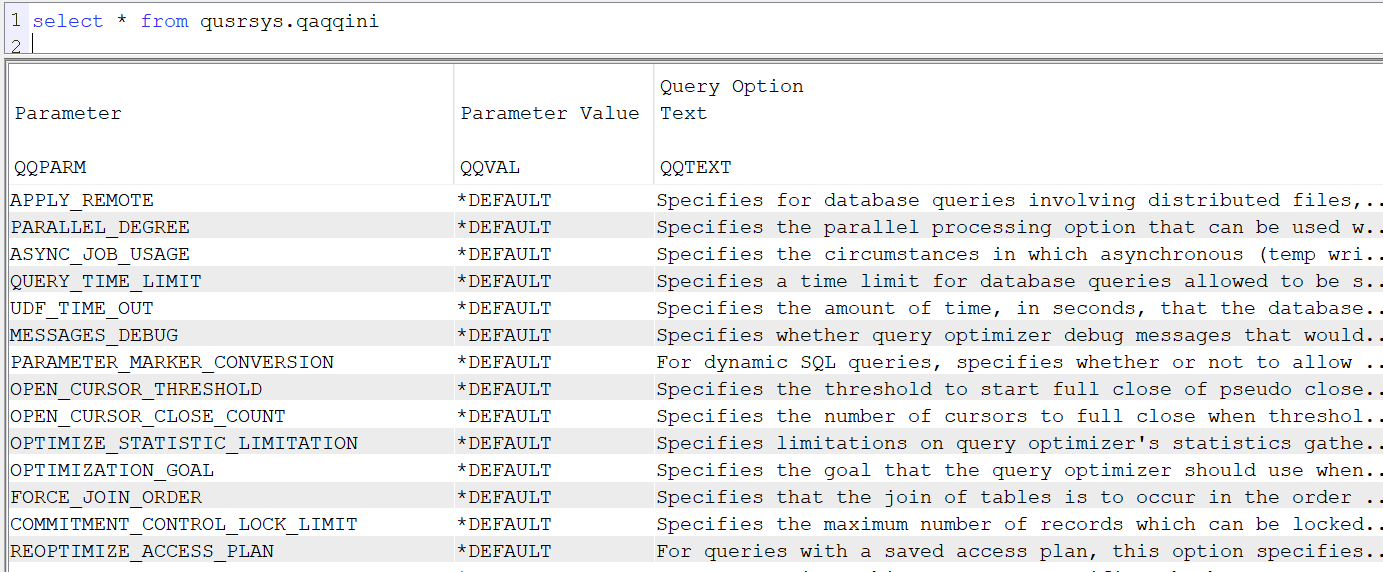
La table est livrée avec *DEFAULT dans tous les paramètres
Pour comprendre la valeur *DEFAULT ci joint une table qui contient les valeurs décryptées
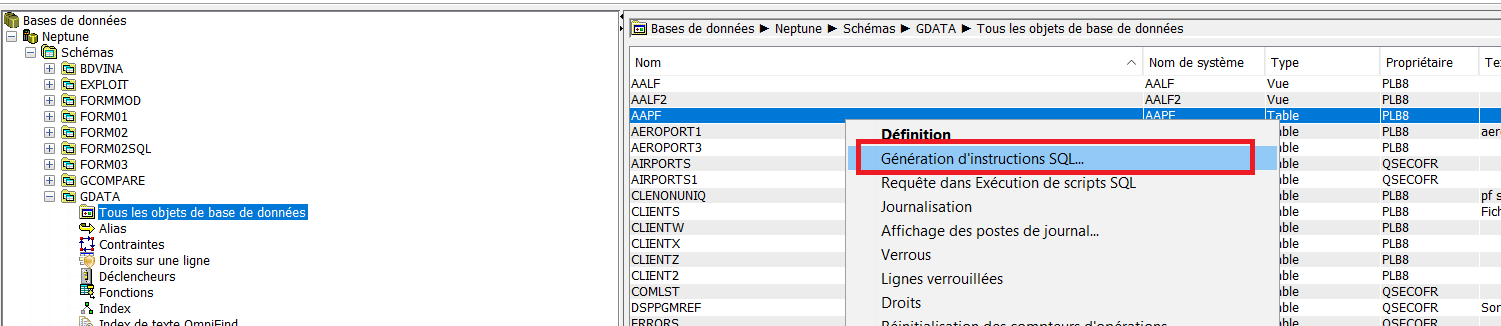
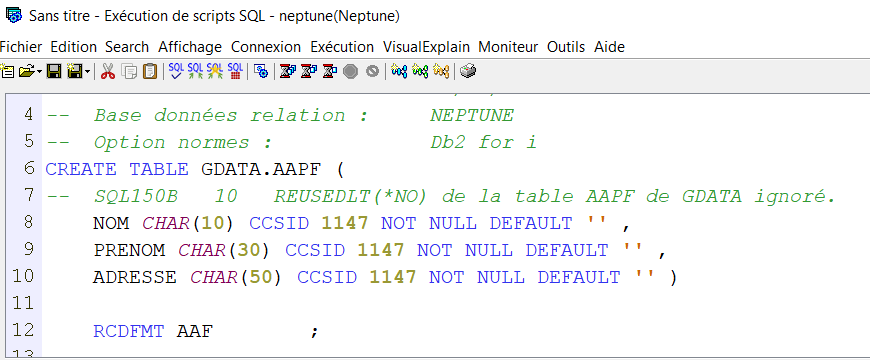
Création de la table des valeurs par défauts
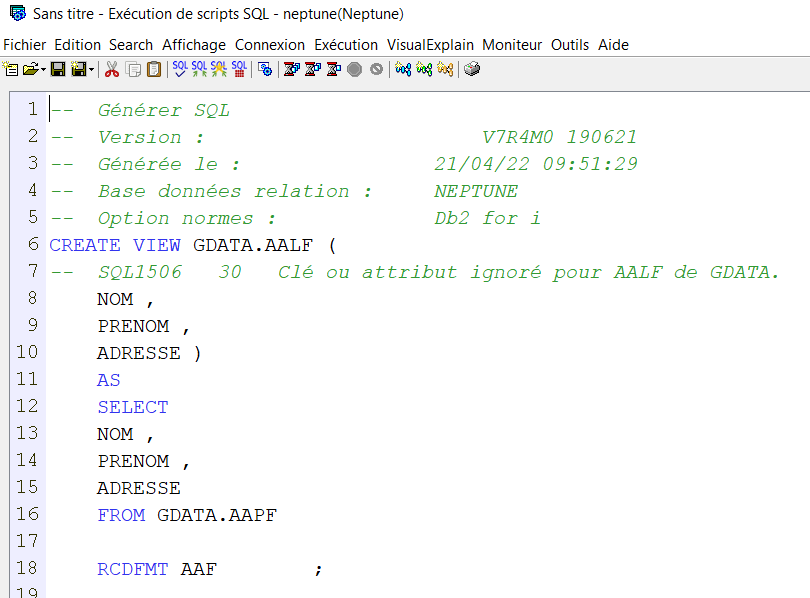
CREATE TABLE GAIA/QAQQINDFT (
QQPARM VARCHAR(256) ALLOCATE(10) CCSID 297 NOT NULL ,
QQVAL VARCHAR(256) ALLOCATE(10) CCSID 297 NOT NULL )
RCDFMT QAQQINDFT ;
LABEL ON COLUMN GAIA/QAQQINDFT
( QQPARM IS ‘Parameter’ ,
QQVAL IS ‘Parameter Value’ ) ;
LABEL ON COLUMN GAIA/QAQQINDFT
( QQPARM TEXT IS ‘Query option parameter’ ,
QQVAL TEXT IS ‘Query option parameter value’ ) ;
Insérer les valeurs correspondantes aux valeurs par défaut
insert into GAIA/QAQQINDFT VALUES(‘APPLY_REMOTE’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘PARALLEL_DEGREE’, ‘OPTIMIZE’) ;
insert into GAIA/QAQQINDFT VALUES(‘ASYNC_JOB_USAGE’, ‘LOCAL’) ;
insert into GAIA/QAQQINDFT VALUES(‘QUERY_TIME_LIMIT’, ‘NOMAX’) ;
insert into GAIA/QAQQINDFT VALUES(‘UDF_TIME_OUT’, ’30’) ;
insert into GAIA/QAQQINDFT VALUES(‘MESSAGES_DEBUG’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘PARAMETER_MARKER_CONVERSION’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘OPEN_CURSOR_THRESHOLD’, ‘0’) ;
insert into GAIA/QAQQINDFT VALUES(‘OPEN_CURSOR_CLOSE_COUNT’, ‘0’) ;
insert into GAIA/QAQQINDFT VALUES(‘OPTIMIZE_STATISTIC_LIMITATION’, ‘Calculez par l’optimiseur’) ;
insert into GAIA/QAQQINDFT VALUES(‘OPTIMIZATION_GOAL’, ‘Dans l’interface’) ;
insert into GAIA/QAQQINDFT VALUES(‘FORCE_JOIN_ORDER’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘COMMITMENT_CONTROL_LOCK_LIMIT’, ‘500000000’) ;
insert into GAIA/QAQQINDFT VALUES(‘REOPTIMIZE_ACCESS_PLAN’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQLSTANDARDS_MIXED_CONSTANT’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘SYSTEM_SQL_STATEMENT_CACHE’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘IGNORE_LIKE_REDUNDANT_SHIFTS’, ‘OPTIMIZE’) ;
insert into GAIA/QAQQINDFT VALUES(‘STAR_JOIN’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_SUPPRESS_WARNINGS’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_TRANSLATE_ASCII_TO_JOB’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘NORMALIZE_DATA’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘LOB_LOCATOR_THRESHOLD’, ‘0’) ;
insert into GAIA/QAQQINDFT VALUES(‘MATERIALIZED_QUERY_TABLE_USAGE’, ‘0’) ;
insert into GAIA/QAQQINDFT VALUES(‘MATERIALIZED_QUERY_TABLE_REFRESH_AGE’, ‘NONE’) ;
insert into GAIA/QAQQINDFT VALUES(‘ALLOW_TEMPORARY_INDEXES’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘VARIABLE_LENGTH_OPTIMIZATION’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘CACHE_RESULTS’, ‘SYSTEM’) ;
insert into GAIA/QAQQINDFT VALUES(‘LIMIT_PREDICATE_OPTIMIZATION’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘STORAGE_LIMIT’, ‘NOMAX’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_DECFLOAT_WARNINGS’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_STMT_COMPRESS_MAX’, ‘2’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_FAST_DELETE_ROW_COUNT’, ‘0’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_STMT_REUSE’, ‘3’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_CONCURRENT_ACCESS_RESOLUTION’, ‘WAIT’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_XML_DATA_CCSID’, ‘1208’) ;
insert into GAIA/QAQQINDFT VALUES(‘FIELDPROC_ENCODED_COMPARISON’, ‘ALLOW_EQUAL’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_MODIFIES_SQL_DATA’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘ALLOW_ARRAY_VALUE_CHANGES’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘ALLOW_ADAPTIVE_QUERY_PROCESSING’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘COLLATE_ERRORS’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_PSEUDO_CLOSE’, ‘QSQPSCLS1 DTAARA’) ;
insert into GAIA/QAQQINDFT VALUES(‘MEMORY_POOL_PREFERENCE’, ‘JOB’) ;
insert into GAIA/QAQQINDFT VALUES(‘TEXT_SEARCH_DEFAULT_TIMEZONE’, ‘UTC’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQE_NATIVE_ACCESS_POSITION_BEHAVIOR’, ‘Normal positioning behavior is performed’) ;
insert into GAIA/QAQQINDFT VALUES(‘SQL_SUPPRESS_MASKED_DATA_DETECTION’, ‘NO’) ;
insert into GAIA/QAQQINDFT VALUES(‘SYSTIME_PERIOD_ADJ’, ‘ERROR’) ;
insert into GAIA/QAQQINDFT VALUES(‘CONCURRENT_ACCESS_BEHAVIOR’, ‘OPTIMIZE’) ;
insert into GAIA/QAQQINDFT VALUES(‘ALLOW_EVI_ONLY_ACCESS’, ‘YES’) ;
insert into GAIA/QAQQINDFT VALUES(‘PSEUDO_OPEN_CHECK_HOST_VARS’, ‘*NO’)
Quelques requêtes SQL pour faire votre analyse
Voir les valeurs par défaut décryptées
SELECT substr(QQPARM, 1, 40) as Parametre, substr(QQVAL, 1, 40) as
valeur FROM gdata/qaqqindft
Voir les valeurs modifiées sur le système dans qusrsys par exemple
SELECT substr(QQPARM, 1, 40) as Parametre, substr(QQVAL, 1, 40) as
valeur FROM qusrsys/qaqqini where qqval <> ‘*DEFAULT’
Voir les fichiers QAQQINI présents sur la machine
SELECT OBJNAME, objlib , X.LAST_USED_TIMESTAMP FROM TABLE (QSYS2.OBJECT_STATISTICS(‘*ALL’,’FILE’,’QAQQINI’)) X
pour voir toutes les valeurs actives dans qaqqini
SELECT ‘DFT’ as type , substr(A.QQPARM, 1, 40) as Parametre,
substr(b.QQVAL, 1, 40) as
valeur FROM gdata/qaqqini A join gdata/qaqqindft b on
A.QQPARM = b.QQPARM
where a.QQVAL = ‘DEFAULT’
union
SELECT ‘CST’ as type, substr(A.QQPARM, 1, 40) as Parametre, substr(A.QQVAL, 1, 40) as valeur
FROM gdata/qaqqini A where a.QQVAL <> ‘DEFAULT’
order by parametre
Référence pour les valeurs et leur signification ici
https://www.ibm.com/docs/en/i/7.4?topic=qaqqini-query-options
Attention :
Ces modifications peuvent avoir des effets désastreux sur les performances, essayer de faire des analyses précises par Visual explain ou l’analyse du plan cache.
Et le cas échéant prévoyez un rollback rapide
Exemple
update gdata.qaqqini set qqval = ‘*DEFAULT’ where qqparm = ‘MATERIALIZED_QUERY_TABLE_REFRESH_AGE’