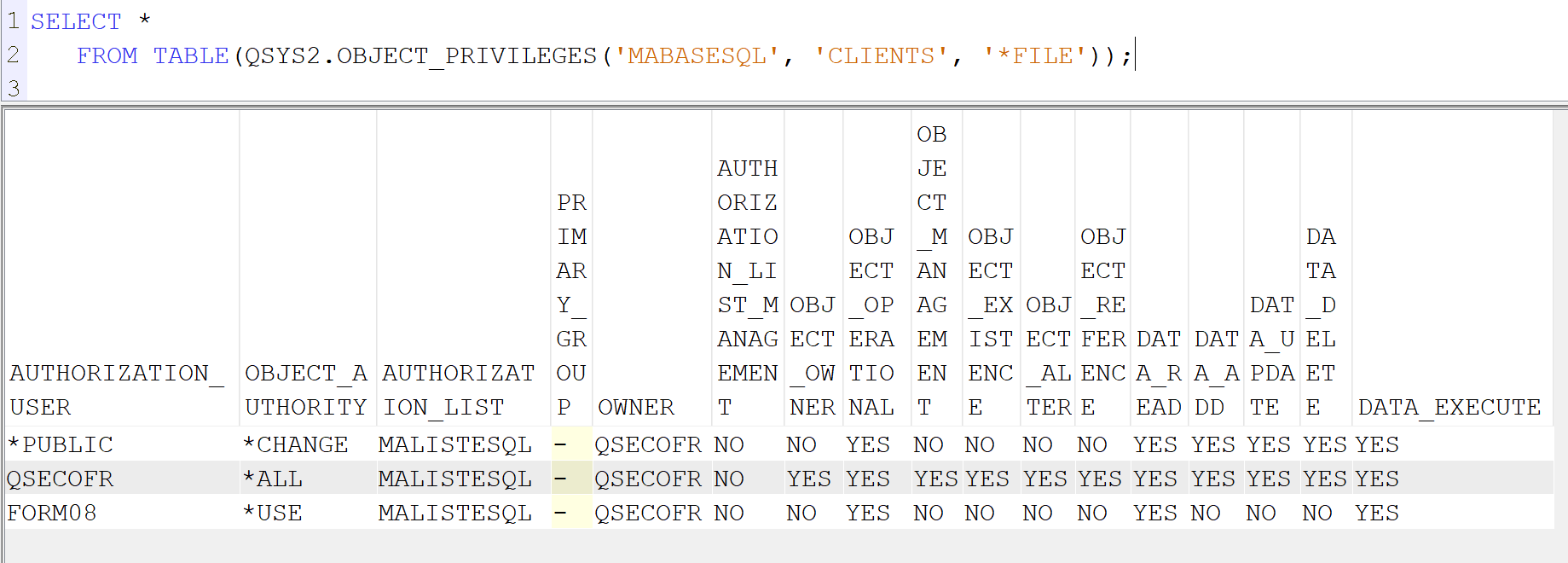
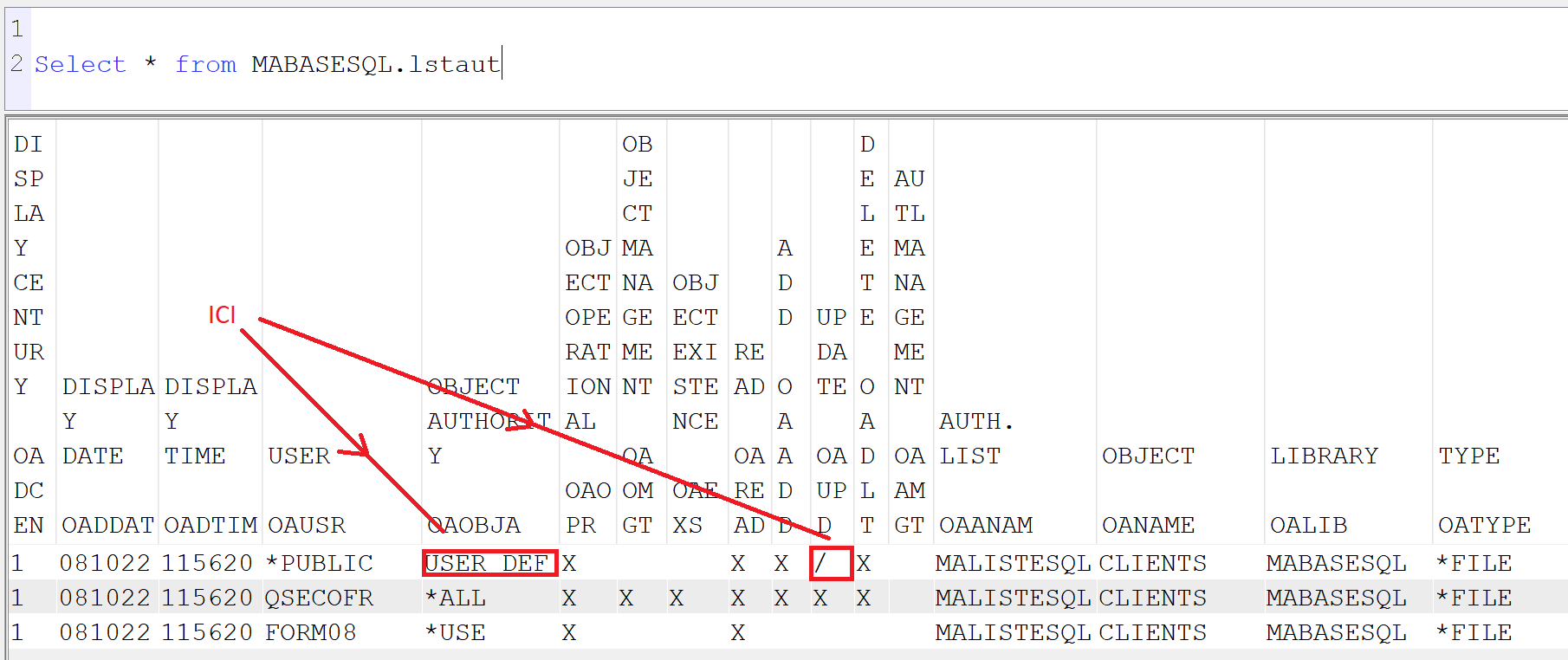
et la on a le résultat qui l’indique ZONE OAOBJA à ‘USER DEF’ et une ZONE des DATA ici OAUPD à ‘/’
En résumé
On ne sait pas par SQL, mais on sait faire par une sortie fichier historique
Oui je sais , on peut trouver l’information par des vues spécifiques dans QSYS2 et SYSIBM
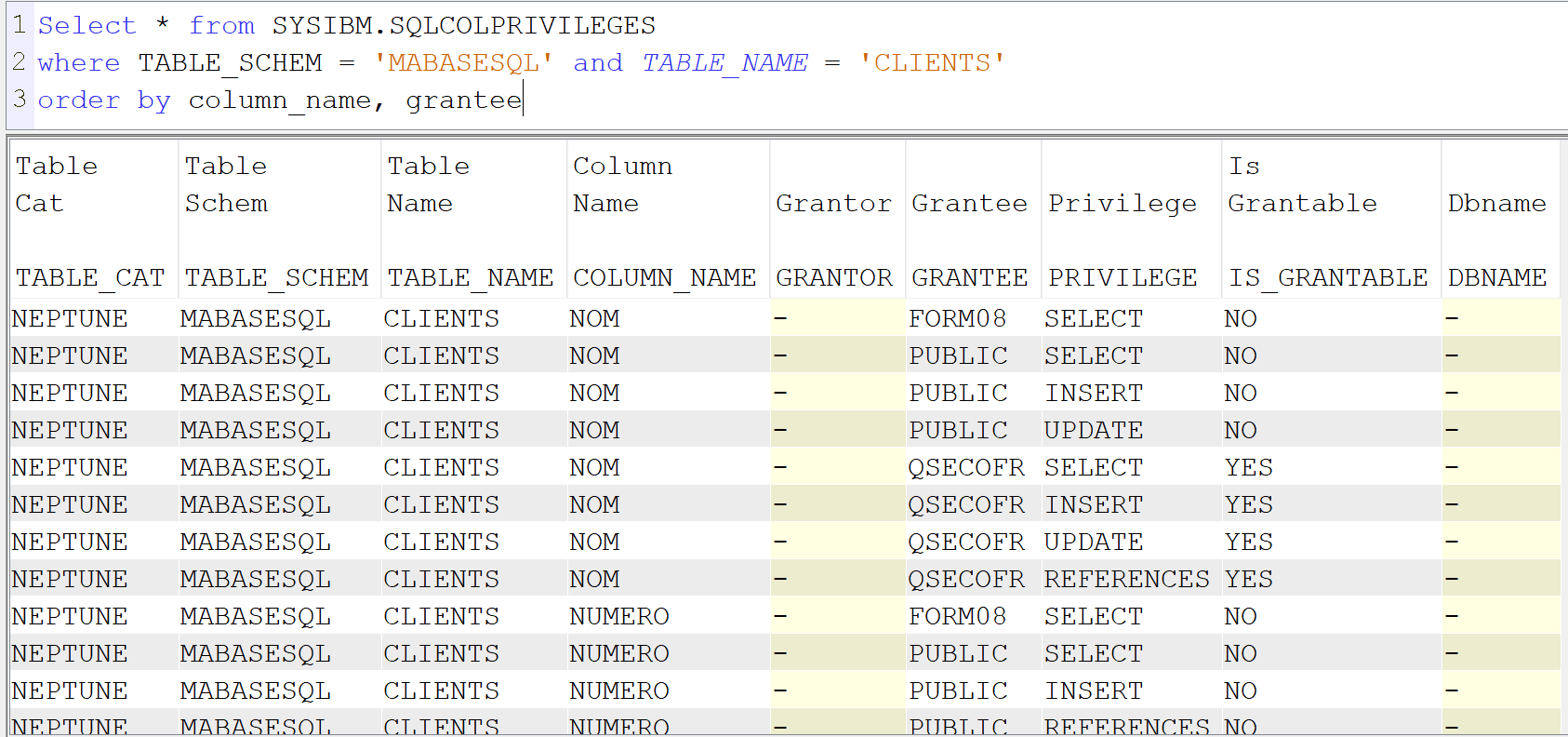
Vous avez d’abord la vue SYSIBM.SQLCOLPRIVILEGES mais attention, vous avez toutes les autorisations sur la zone y compris celles qui correspondent à un *CHANGE sur le fichier par exemple.
exemple : Select * from SYSIBM.SQLCOLPRIVILEGES where TABLE_SCHEM = ‘MABASESQL’ and TABLE_NAME = ‘CLIENTS’
order by column_name, grantee
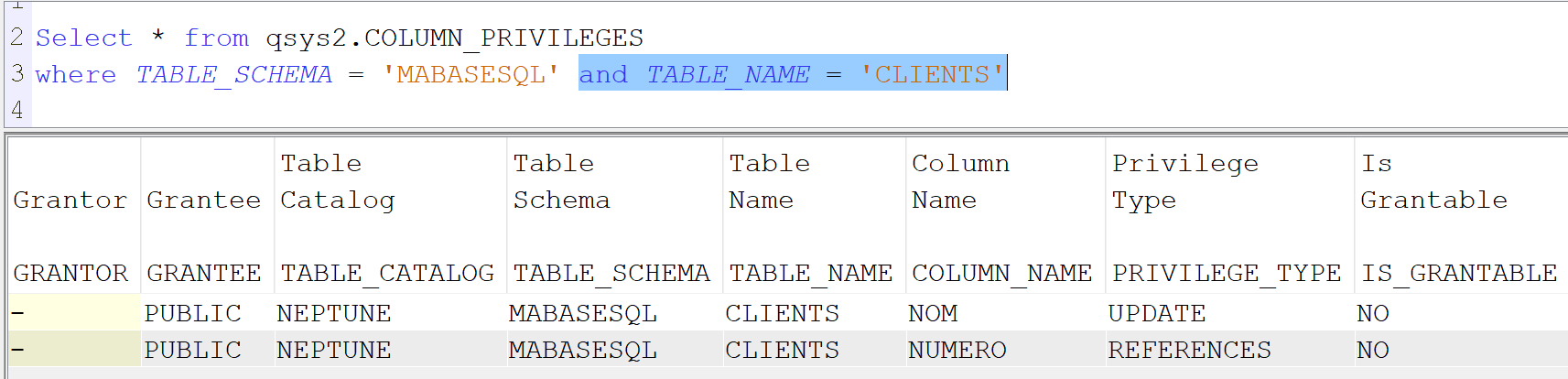
Ou mieux la vue QSYS2.COLUMN_PRIVILEGES qui ne contient que les zones avec des autorisations spécifiques
exemple
Select * from QSYS2.COLUMN_PRIVILEGES where TABLE_SCHEMA = ‘MABASESQL’ and TABLE_NAME = ‘CLIENTS’
j’ai donc fait une RFE pour avoir l’information dans la fonction table QSYS2.OBJECT_PRIVILEGES
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-10-08 16:12:502022-10-25 09:54:57Droits SQL sur les Zones
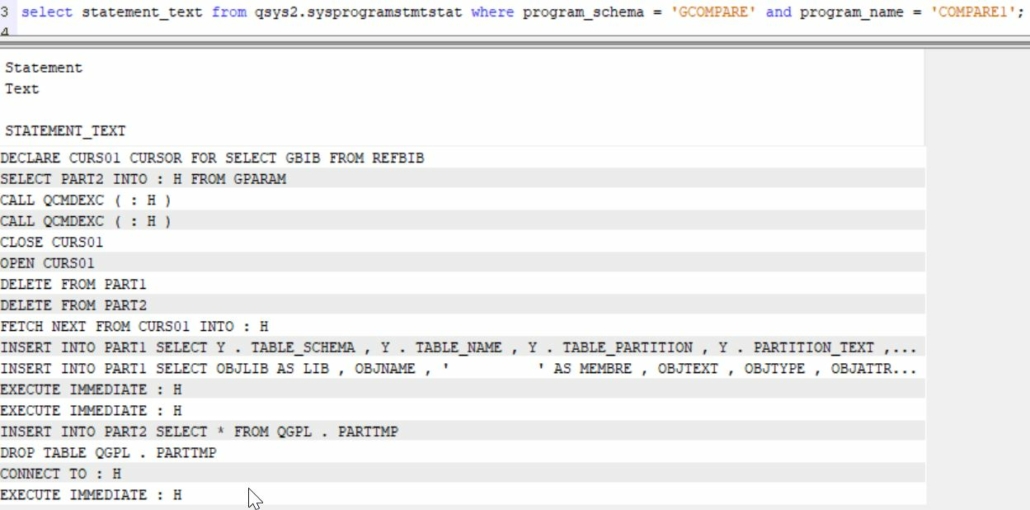
Toutes les instructions SQL contenues dans un programme – mais pas les CL – sont écrites dans qsys2.sysprogramstmtstat; qu’on ait le source du programme ou pas. En plus de stocker l’instruction, on accède à d’autres informations comme le nombre d’exécutions, le nombre de variables hôtes … DSPPGMREF référence l’utilisation de fichier par SQL de façon très succincte, on accède à bien plus de détails en explorant QSYS2.SYSPROGRAMSTMTSTAT.
On peut visualiser directement les différentes instructions :
Si on n’est intéressé que par les tables écrites dans les instructions contenues dans un programme, il faut filtrer. On utilise la fonction table qsys2.parse_statement qui sait parser le SQL. Cette dernière, pour faire le travail, a besoin d’informations supplémentaires contenues dans qsys2.sysprogrammstat :
convention de nommage
séparateur décimal
délimitateur de chaine
Cela donne la requête :
WITH program_statements(naming_mode, dec_point, string_delim, stmt_text, stmt_nbr, system_program_name, program_type) AS (SELECT a.naming, a.decimal_point, a.sql_string_delimiter, b.statement_text, b.statement_number, a.system_program_name, a.program_type FROM qsys2.sysprogramstat a INNER JOIN qsys2.sysprogramstmtstat b ON a.program_schema = b.program_schema AND a.program_name = b.program_name AND a.module_name = b.module_name WHERE a.number_statements > 0 AND a.program_schema = ‘GCOMPARE’ AND a.program_name =’COMPARE1′ ) SELECT system_program_name, program_type, c.schema, c.name, stmt_nbr, stmt_text FROM program_statements, TABLE(qsys2.parse_statement(stmt_text, naming_mode, dec_point, string_delim)) c WHERE c.name_type = ‘TABLE’ ORDER BY stmt_nbr, c.schema, c.name;
On peut modifier cette dernière requête en indiquant une liste de bibliothèques pour a.program_schema. En la planifiant régulièrement et en récupérant son resultset dans un fichier, on pourra voir rapidement les utilisations connues d’une table.
Malheureusement (ou pas) les « Execute Immediate :var » n’indiquent pas ce qu’elles contiennent …
https://www.gaia.fr/wp-content/uploads/2022/04/Id-Niko-BW-20220407-1-scaled.jpg25601689Nicolas kintz/wp-content/uploads/2017/05/logogaia.pngNicolas kintz2022-09-20 10:10:222022-10-12 14:55:51Retrouver les instructions SQL contenues dans les programmes
Lorsque l’on travaille sur une belle requête SQL, nous avons tendance à la garder et la sauvegarder en local sur notre poste (parfois dans l’IFS). Pour la partager à un collègue quoi de mieux qu’un bon vieux mail ?
Ou alors, on peut exploiter les Exemples personnalisés d’ACS pour mutualiser nos découvertes !
Exemples SQL sur ACS
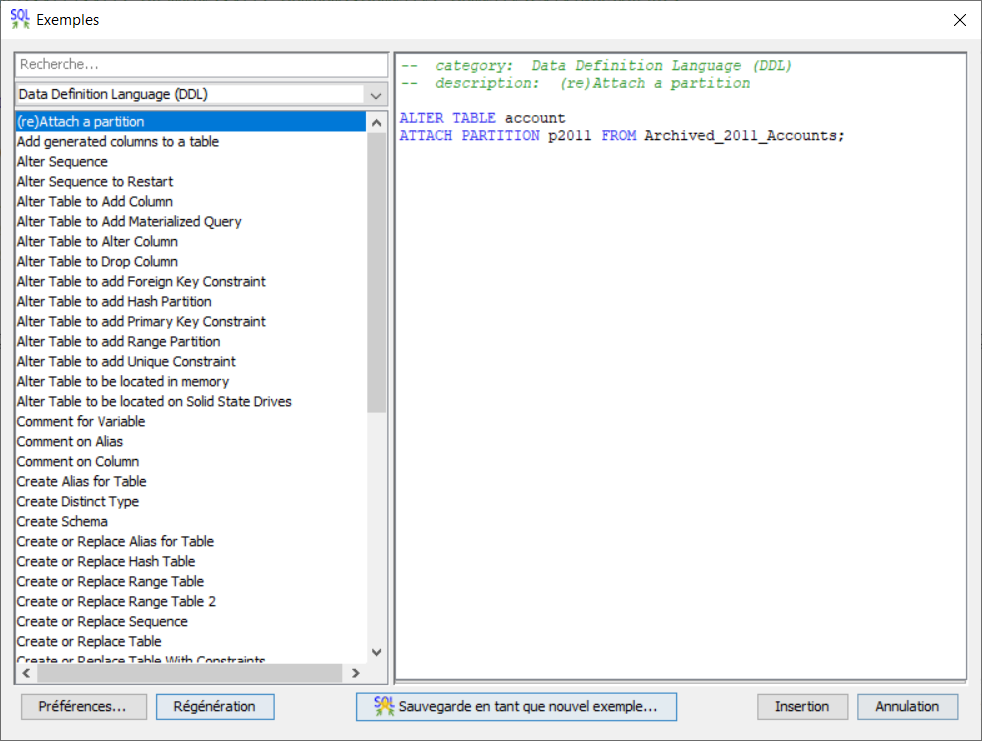
Via l’Exécuteur de scripts SQL d’ACS, une multitude d’exemples est fournie. Pour y accéder trois possibilités :
Edition > Exemples > Insertion à partir d’exemples…
Ctrl + I
Via la petite icône SQL avec les deux flèches ci-dessous
On y retrouve tout un catalogue d’exemples relativement bien fourni :
Il suffit de rechercher les mots clés qui nous intéressent puis de cliquer sur Insertion, et enfin de remplacer les données variables de la requête.
Ajouter ses exemples personnalisés
Création d’un répertoire dans l’IFS
La première étape consiste à créer un répertoire commun dans l’IFS, le plus simple est de le créer dans /home/ qui est généralement déjà configuré comme partagé (donc visible pour Windows). Par la suite nous utiliserons le chemin suivant : /home/exemples_sql/. C’est ici que nous travaillerons pour créer nos exemples personnalisés.
Création d’un exemple
Il suffit de créer un nouveau source SQL, par exemple via ACS :
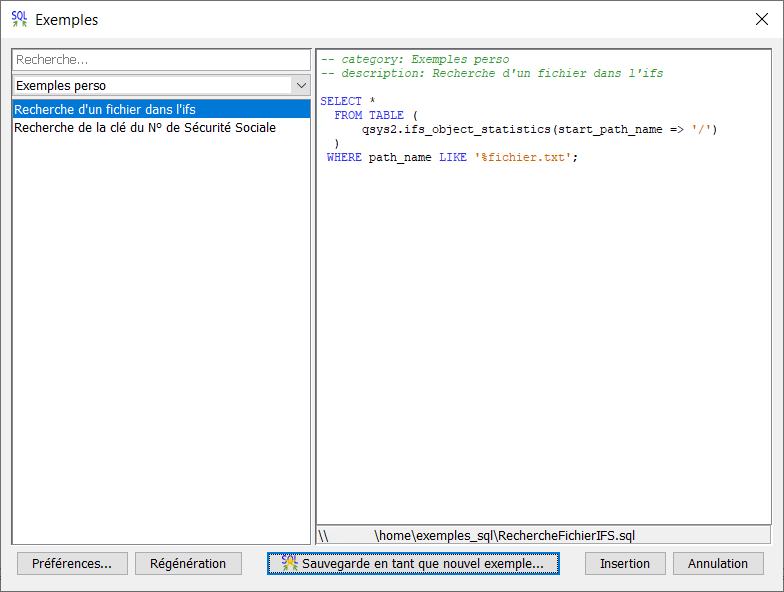
-- category: Exemples perso
-- description: Recherche d'un fichier dans l'ifs
SELECT *
FROM TABLE (
qsys2.ifs_object_statistics(start_path_name => '/')
)
WHERE path_name LIKE '%fichier.txt';
Le commentaire category permet de trier et regrouper vos exemples par usages. Le commentaire description correspond au texte indiqué dans la liste des exemples.
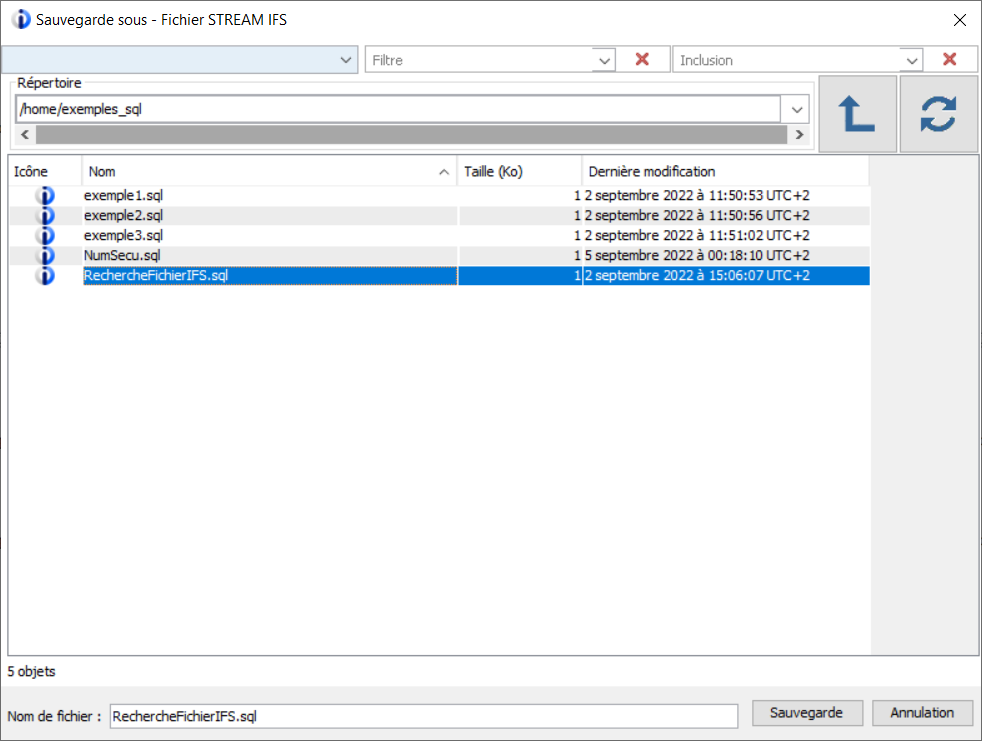
Une fois l’exemple terminé il suffit de sauvegarder le script dans le répertoire de l’IFS choisi : Fichier > Sauvegarde sous… > Fichier STREAM IFS.
Il est bien entendu toujours possible de modifier ou supprimer des exemples à partir de ce répertoire.
Intégration du répertoire d’exemples à ACS
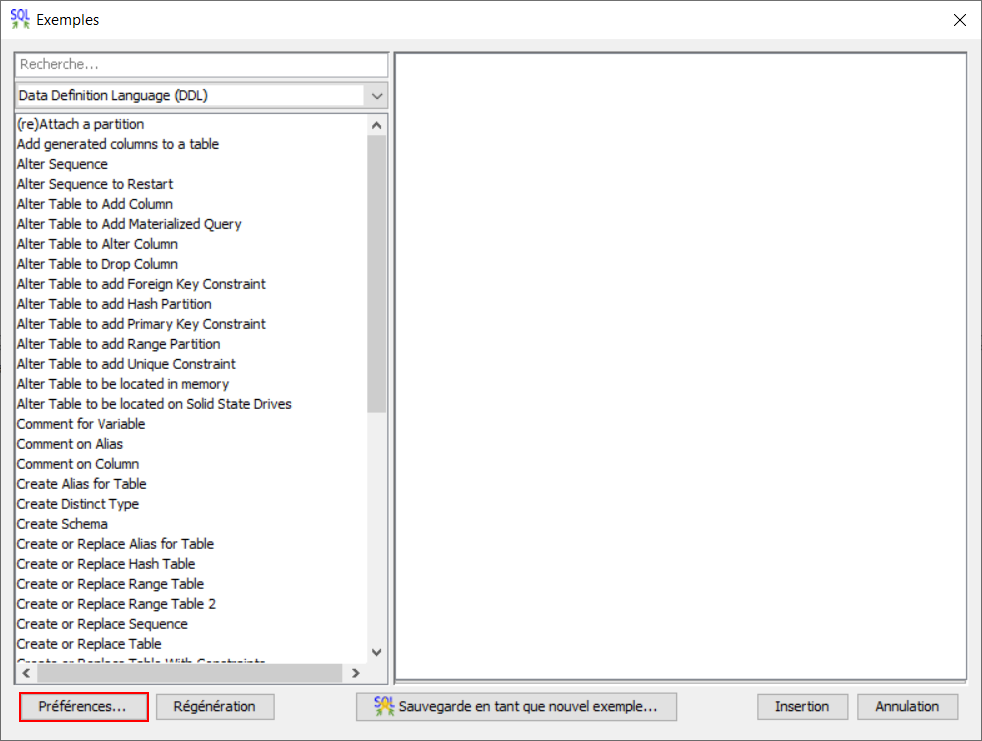
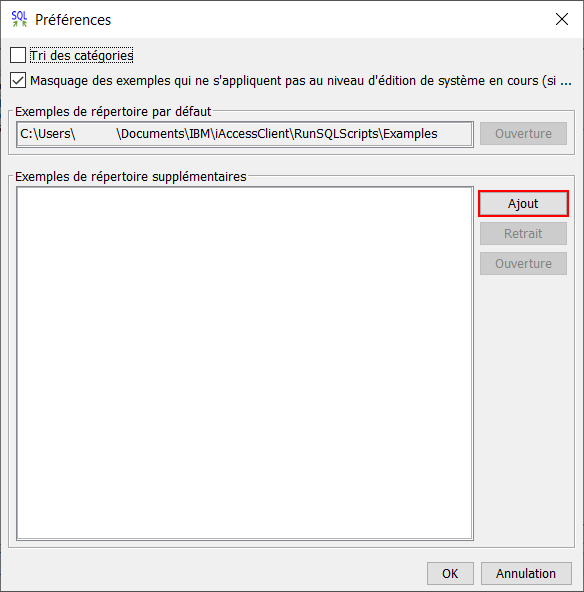
Dans un onglet d’ACS, ouvrir le menu des exemples : Edition > Exemples > Insertion à partir d’exemples… Puis cliquer sur Préférences…
Cliquer ensuite sur Ajout
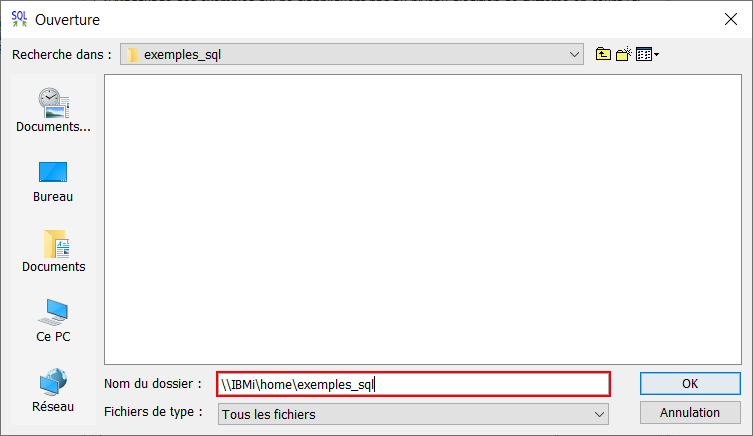
Indiquer ici le chemin vers le répertoire de l’IBM i qui contient les exemples SQL : \\<Nom de l’IBM i>\home\exemples_sql
Les exemples sont maintenant dans la liste avec les autres. Ils sont triés par catégorie (que l’on retrouve juste en dessous de la mire de recherche). Ils sont listés en dessus par description et un aperçu est disponible à droite.
Pour retrouver des exemples deux possibilités :
Choisir la catégorie à afficher en cliquant sur la catégorie actuelle (ici Exemples perso)
Utiliser la mire de recherche, qui affichera les exemples correspondant aux mots clés, toutes catégories confondues
On entend beaucoup de choses, je vais essayer de vous clarifier un peu les choses
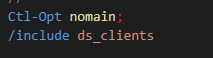
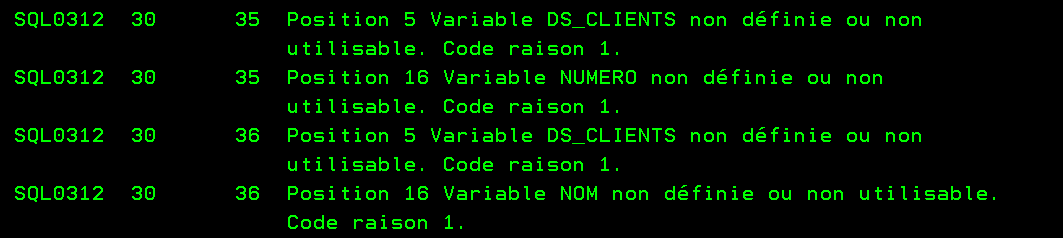
Les directives /COPY et /INCLUDE sont identiques sauf qu’elles sont gérées différemment par le précompilateur SQL, en gros si vous codez avec un Source en SQLRPGLE.
Sur la commande CRTSQLRPGI vous avez le paramètre RPGPPOPT Permet d’indiquer si le compilateur ILE RPG va être appelé pour prétraiter le membre source avant lancement de la précompilation SQL. Cette étape sur le membre source SQL permet de traiter certaines instructions de compilation avant la précompilation SQL. Le source prétraité est placé dans le fichier QSQLPRE de la bibliothèque QTEMP. Il servira à la précompilation SQL. puis à la complilation RPGLE
3 valeurs possibles sont : *NONE Le compilateur n’est pas appelé pour le prétraitement. *LVL1 Le compilateur est appelé pour le prétraitement afin de développer /COPY et traiter les instructions de compilation conditionnelles à l’exception de /INCLUDE. *LVL2 Le compilateur est appelé pour le prétraitement afin de développer /COPY et /INCLUDE et traiter les instructions de compilation conditionnelles
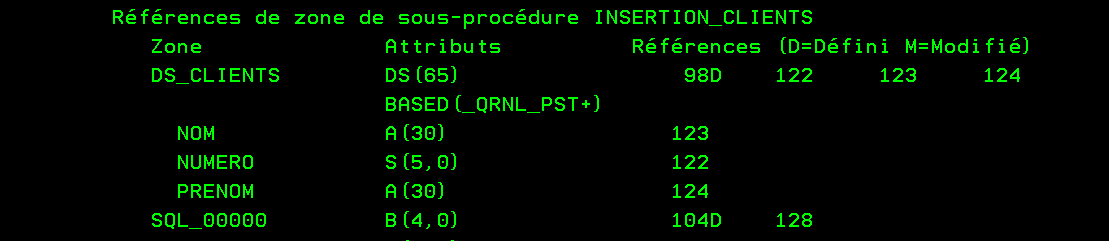
voici un exemple Un module utilise la description d’un fichier qui est dans un include
le source à inclure
sa déclaration dans le programme ou le module
.
Compile avec *NONE
Compile avec *LVL2
Remarque Si vous faites du SQLRPGLE, ce qui est fortement recommandé à ce jour forcer cette valeur *LVL2 comme ca pas de doute !
Bien que le MD5 ne soit plus utilisé pour l’encryption, il est toujours utilisé pour valider l’authenticité et la conformité des fichiers.
Qu’est-ce qu’un MD5
Un md5 est une chaine de 16 caractères composée de symboles hexadécimaux. Il s’agit en réalité du nom de l’algorithme utilisé pour générer la chaine.
Comme indiqué précédemment son usage est le contrôle d’intégrité des fichier, par exemple lors du partage d’un fichier, on peut mettre à disposition le MD5 afin de contrôler que le téléchargement du fichier s’est bien passé ou que le fichier n’a pas été modifié entre temps.
Pour la suite nous aurons besoin d’un fichier, par simplicité j’utiliserai un simple .txt qui contient la phrase « This is not a test! » présent dans mon répertoire de l’ifs.
Fichier dans l’ifs
/home/jl/file.txt
Contenu du fichier
This is not a test!
md5
EDA20FB86FE23401A5671734E4E55A12
QSH – md5sum
La première méthode pour générer le MD5 d’un fichier est d’utiliser la commande unix md5sum via QSH :
La fonction retourne le hash et le chemin du fichier.
RPGLE – _cipher
Il est également possible de générer le MD5 via RPG en exploitant la procédure externe cipher. Je ne m’épancherai pas sur son implémentation complète ici, car bien plus complexe que les deux autres méthodes présentées. De plus, passer par cette méthode, n’est plus le sens de l’histoire.
// Déclaration de la procédure
dcl-pr cipher extproc('_cipher');
*n pointer value;
*n pointer value;
*n pointer value;
end-pr;
// Appel de la procédure
cipher(%ADDR(receiver) : %ADDR(controls) : %ADDR(source));
En sql on retrouve la fonction hash_md5, qui retourne le hash d’une chaine de caractère passée en paramètre.
❗ Attention à l’encodage de votre chaine de caractères. ❗
Pour que le résultat soit cohérent entre différents systèmes il faut commencer par convertir la chaine de caractère en UTF-8 :
VALUES CAST('This is not a test!' AS VARCHAR(512) CCSID 1208); -- 1208 = UTF-8
-- Retour : This is not a test!
Le résultat est plutôt flagrant ! D’accord pas vraiment… Par contre si on regarde la valeur hexadécimale de la chaine avec et sans conversion :
VALUES HEX('This is not a test!');
-- Retour : E38889A24089A2409596A3408140A385A2A34F
VALUES HEX(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : 54686973206973206E6F742061207465737421
Le hachage se fait en hexadécimal, donc le résultat ne serait pas le même sans conversion préalable.
Il suffit maintenant de hacher notre chaine de caractères :
VALUES HASH_MD5(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : EDA20FB86FE23401A5671734E4E55A12
On obtient donc la même valeur que celle que l’on a obtenu précédemment (puisque que le contenu de notre fichier est strictement égale à cette chaine de caractère).
La dernière étape est de générer le MD5 directement à partir du fichier, pour cela il suffit d’utiliser la fonction GET_BLOB_FROM_FILE :
VALUES HASH_MD5(GET_BLOB_FROM_FILE('/home/jl/file.txt')) WITH CS;
-- Retour : EDA20FB86FE23401A5671734E4E55A12
Autres algorithmes de hash
Il existe d’autres algorithmes de hash qui permettent de hacher du texte et des fichiers. Trois autres algorithmes sont généralement disponibles :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2022-08-18 00:30:512022-08-18 12:51:20Utilisation du MD5 sur votre IBM i
Il existe de nombreuses tables dans QSYS qui constituent le catalogue DB2, Ces tables sont accessibles par des vues qui se trouvent dans QSYS2 de manière globale et dans les bibliothèques de vos collections SQL.
On utilise pas assez ces informations pour analyser la base de données, elles contiennent une multitude d’informations
On va faire une petit exemple:
Imaginons que nous voulons savoir ou est utilisée une zone
Nous fixerons la database par set schema , pour éviter les qualifications
exemple de manière globale SET SCHEMA QSYS2
On va utiliser une vue qui s’appelle SYSCOLUMNS qui contient les zones de votre database
SELECT A.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS A WHERE COLUMN_NAME = ‘NUMCLI’
Vous obtenez une liste de tous les fichiers (tables, vue, PF, LF) etc …
Imaginons ensuite que vous ne vouliez que les tables ou PF vous pouvez utiliser la vue SYSTABLES
SELECT a.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in(‘T’ , ‘P’) WHERE COLUMN_NAME = ‘NUMCLI’
Vous limitez ainsi votre recherche aux tables et PF
Imaginons maintenant que vous ne vouliez que les tables et PF qui ont été utilisées sur l’année flottante (13 mois), on va utiliser la vue SYSTABLESTAT
SELECT a.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in( ‘T’ , ‘P’) join SYSTABLESTAT c on A.SYSTEM_TABLE_NAME=c.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = c.SYSTEM_TABLE_SCHEMA and c.LAST_USED_TIMESTAMP > (current date – 13 months) WHERE COLUMN_NAME = ‘NUMCLI’
Cette exemple n’est pas parfait, mais il vous montre qu’avec le catalogue db2 et un peu de SQL vous pouvez avoir de nombreuses informations pertinentes sur cette dernière . Vous pouvez par exemple avoir des informations statistiques sur vos colonnes par la vue SYSCOLUMNSTAT et une vue globale avec la vue SYSFILES qui permet d’avoir un bon résumé de vos fichiers
https://www.ibm.com/support/pages/node/6486897
Voici un lien qui vous présente les vues disponibles,
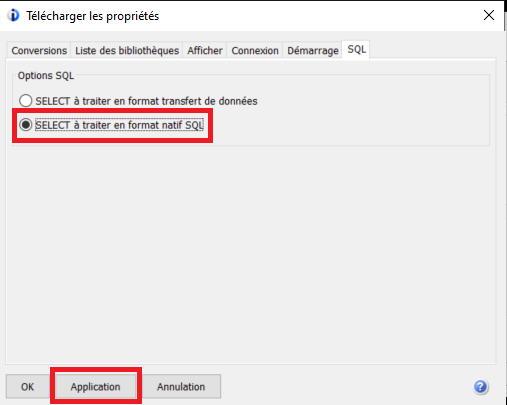
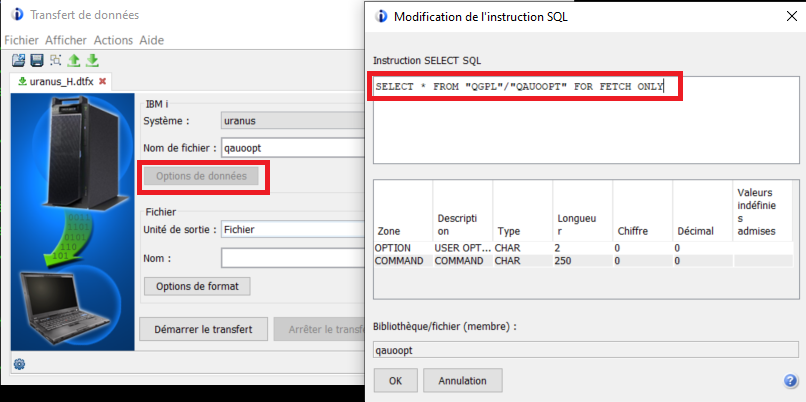
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-08-08 18:14:582022-08-08 18:14:59Créer une requête DTFX en SQL
Pour faire un peu de place il peut être important de supprimer certains récepteurs de journaux inutiles
D’abord la liste des récepteurs détachés de plus de 30 jours
SELECT JOURNAL_RECEIVER_LIBRARY, JOURNAL_RECEIVER_NAME FROM QSYS2.JOURNAL_RECEIVER_INFO WHERE ATTACH_TIMESTAMP < current date – 30 days and DETACH_TIMESTAMP is not null
A partir de cette liste vous pouvez faire une DLTJRNRCV de ces recepteurs
Liste des journaux qui n’éffacent pas les récepteurs après détachement SELECT JOURNAL_NAME, JOURNAL_LIBRARY FROM qsys2/JOURNAL_INFO WHERE DELETE_RECEIVER_OPTION = ‘NO’
A partir de cette liste vous pouvez modifier le récepteur en indiquant de supprimer les recepteurs après détachement !
CHGJRN DLTRCV(*YES)
Attention :
Il ne faut pas supprimer des récepteurs de votre base de données de production mais il y a souvent une multitude de bases de tests qui n’ont pas besoin de leurs récepteurs détachés pour permettre de faire des tests
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-08-08 17:39:102022-08-08 17:39:112 requêtes pour gérer vos récepteurs de journaux
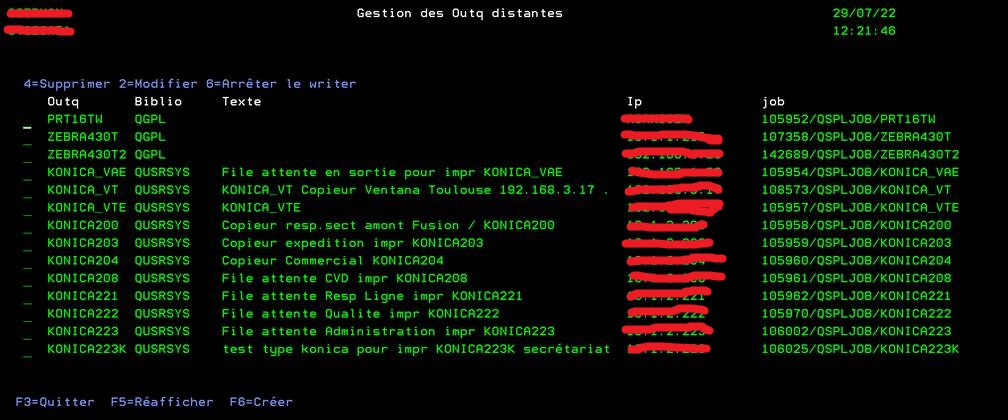
Nous avons développé une petite commande pour un client, elle facilite la gestion des remotes Outqs par exemple pour changer une adresse IP La commande est WRKOUTQIP
Vous pouvez Arrêter le travail d’édition Supprimer une outq Changer une outq
Les sources sont ici https://github.com/Plberthoin/PLB/tree/master/GTOOLS
Il y a une commande, un programme et un écran
Cet outil est un peu brut, vous pouvez l’améliorer, par exemple, un 3 dupliquer pourrait intéresser tout le monde
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-07-31 09:34:562022-07-31 09:34:57Outil pour gérer les outqs
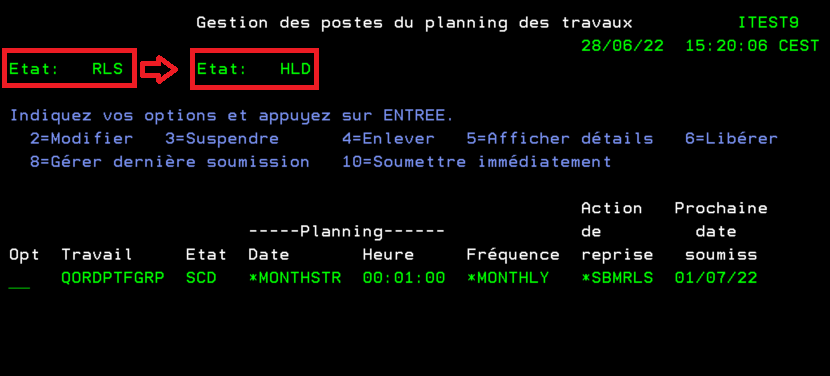
En une seule commande vous pouvez holder tous les travaux en suspendant le scheduler lui même, vous voyez le status dans la commande wrkjobscde, bien utile pour les installations , les machines de backups etc..
.
HLDJOBSCDE JOB(JOBSCD) ENTRYNBR(ALL)
pour libérer
HLDJOBSCDE JOB(JOBSCD) ENTRYNBR(ALL)
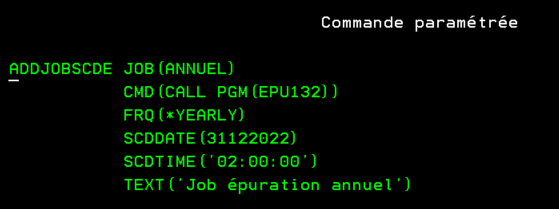
Vous pouvez désormais soumettre une tâche annuellement
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-07-22 16:05:112022-08-09 15:46:49Amélioration du scheduler IBMi en V7R5