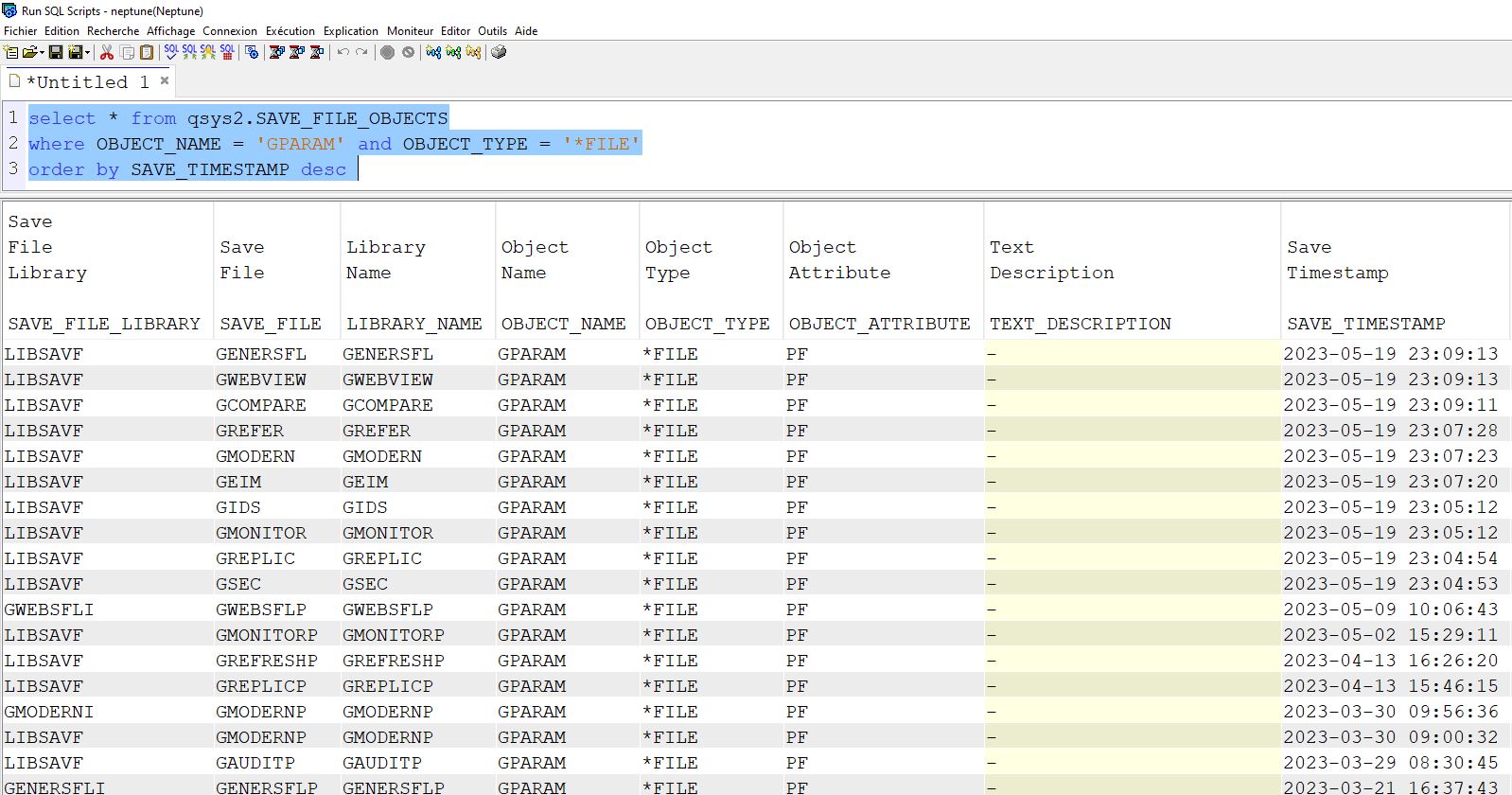
Egalement appelée clés étrangères, c’est une approche data centrique pour gérer les dépendances des données entre les tables de votre base de données.
Prenons un exemple :
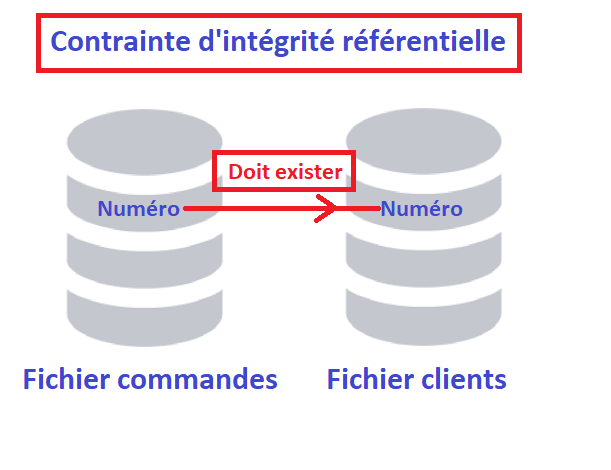
Une commande ne peut pas avoir un client qui n’existe pas et à l’inverse, vous ne pouvez pas supprimer un client qui a encore des commandes
Jusqu’à maintenant, on avait tendance à laisser gérer cette dépendance à l’application, ce qui immanquablement créait des orphelins, qu’on devait corriger par des programmes de contrôle
Il existe donc une alternative c’est de demander à SQL de gérer cette dépendance, c’est l’approche data centrique, voyons comment
Dans la bibliothèque PLB nous allons créer 2 tables
tclients pour les clients
CREATE TABLE PLB.TCLIENTS (
NUMERO CHAR(6) CCSID 1147 NOT NULL DEFAULT » ,
NOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » )
ALTER TABLE PLB.TCLIENTS
ADD CONSTRAINT PLB.Q_PLB_TCLIENTS_NUMERO_00001 PRIMARY KEY( NUMERO )
Cette table doit impérativement avoir une clé primaire sur la clé que vous voulez contrôler ici NUMERO
tcommande pour les commandes
CREATE TABLE PLB.TCOMMANDE (
NUMERO CHAR(6) CCSID 1147 NOT NULL DEFAULT » ,
NUMEROCDE CHAR(6) CCSID 1147 NOT NULL DEFAULT » ,
DESCRCDE CHAR(30) CCSID 1147 NOT NULL DEFAULT » )
ALTER TABLE PLB.TCOMMANDE
ADD CONSTRAINT PLB.Q_PLB_TCOMMANDE_NUMEROCDE_00001
UNIQUE( NUMEROCDE ) ;
On ajoute une clé sur le numéro de commande qui ne sert pas pour la contrainte, mais qui logiquement serait présente pour identifier votre commande
Mise en Œuvre
Pour ajouter votre contrainte vous avez 2 solutions
Par les commandes IBM i natives
ADDPFCST FILE(PLB/TCOMMANDE)
TYPE(REFCST) KEY(NUMERO) PRNFILE(PLB/TCLIENTS) DLTRULE(RESTRICT)
UPDRULE(*RESTRICT)
Par SQL
ALTER TABLE PLB.TCOMMANDE
ADD CONSTRAINT PLB.Q_PLB_TCOMMANDE_NUMERO_00001
FOREIGN KEY( NUMERO )
REFERENCES PLB.TCLIENTS ( NUMERO )
ON DELETE RESTRICT
ON UPDATE RESTRICT ;
Vous fixez une action sur le fichier parent, en cas de non respect de la règle posée, le plus souvent on met RESTRICT qui interdira l’opération.
Vous pouvez regarder les autres actions pour voir , attention à *CASCADE qui peut être très brutal …
En ajoutant votre contrainte, vous pouvez avoir ce message qui indique que des valeurs ne respectent pas la régle de contrôle énoncée
ID message . . . . . . : CPD32C5
Date d’envoi . . . . . : 11/02/23 Heure d’envoi . . . . : 07:51:54
Message . . . . : Les valeurs de clé de la contrainte référentielle sont
incorrectes.
Cause . . . . . : La contrainte référentielle Q_PLB_TCOMMANDE_NUMERO_00001 du
fichier dépendant TCOMMANDE, bibliothèque PLB, est en instance de
vérification. Le fichier parent TCLIENTS, bibliothèque PLB, possède une
règle de suppression de *RESTRICT et une règle de mise à jour de *RESTRICT.
La contrainte est en instance de vérification car l’enregistrement 2 du
fichier dépendant comporte une valeur de clé étrangère qui ne correspond pas
à celle du fichier parent pour l’enregistrement 0.
Si le numéro d’enregistrement du fichier parent ou du fichier dépendant
est 0, l’enregistrement ne peut pas être identifié ou ne satisfait pas à
l’état vérification en instance.
A ce moment la contrainte est active mais vous avez des enregistrements non conformes
vous pouvez les voir par WRKPFCST
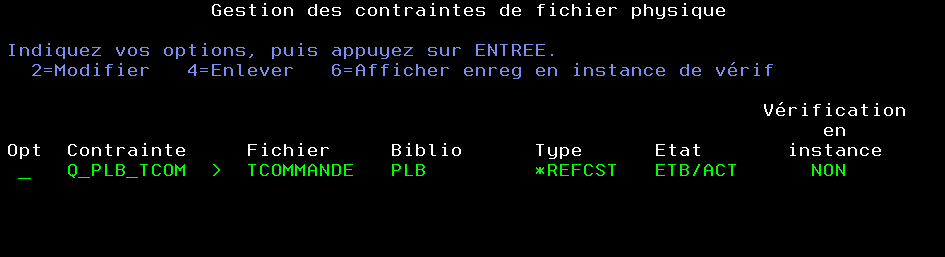
l’option 6 permet de voir les enregistrements en attente de validation et en erreur
Testons, si vous essayez de créer une commande avec un client qui n’existe pas vous aurez un message de ce type par DFU ou dans un programme RPGLE
ID message . . . . . . : CPF502D
Date d’envoi . . . . . : 09/02/23 Heure d’envoi . . . . : 16:17:38
Message . . . . : Violation de contrainte référentielle sur le membre
TCOMMANDE.
Cause . . . . . : L’opération en cours sur le membre TCOMMANDE, fichier
TCOMMANDE, bibliothèque PLB a échoué. La contrainte
Q_PLB_TCOMMANDE_NUMERO_00001 empêche l’insertion ou la mise à jour du numéro
d’enregistrement 0 dans le membre TCOMMANDE du fichier dépendant TCOMMANDE
dans la bibliothèque PLB : aucune valeur de clé correspondante n’a été
trouvée dans le membre TCLIENTS du fichier parent TCLIENTS de la
bibliothèque PLB. Si le numéro d’enregistrement est zéro, l’erreur s’est
produite lors d’une opération d’insertion. La règle de contrainte est 2. Les
règles de contrainte sont les suivantes :
1 — *RESTRICT
dans vos programmes RPG vous pourrez par exemple utiliser les fonctions %error()
Maintenant essayons de voir ce qui ce passe dans un programme SQLRPGLE, ce qui est la norme de développement à ce jour
**FREE
// création d'une commande avec un client qui n'existe pas
exec sql
INSERT INTO PLB/TCOMMANDE VALUES('000004', '000007',
'Lunettes bleaues') ;
dsply ('Insert : ' + %char(sqlcode)) ;
// modification d'une commande avec un client qui n'existe pas
exec sql
UPDATE PLB/TCOMMANDE SET NUMERO = '000007' ;
dsply ('Update : ' + %char(sqlcode)) ;
// supression d'un client qui a des commandes
exec sql
DELETE FROM PLB/TCLIENTS WHERE NUMERO = '000001' ;
dsply ('delete : ' + %char(sqlcode)) ;
*inlr = *on ;
Vous obtenez les SQLCODEs suivants
DSPLY Insert : -530
DSPLY Update : -530
DSPLY Delete : -532
Voir les contraintes existantes
pour voir les contraintes existantes
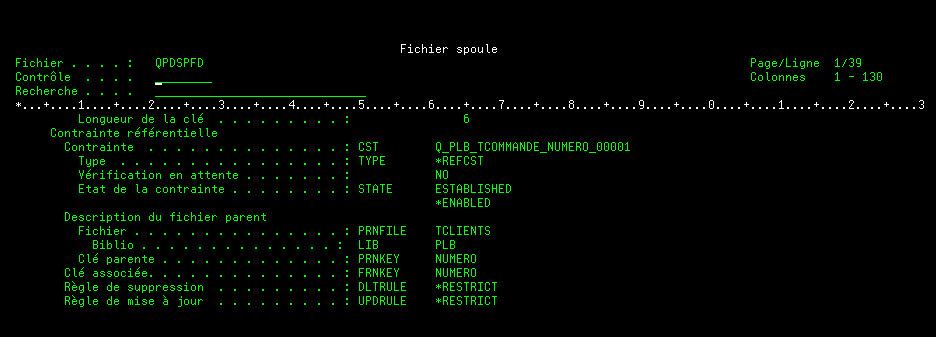
Vous pouvez faire un DSPFD
exemple :
DSPFD FILE(PLB/TCOMMANDE)
TYPE(*CST)
Par les vues SQL
exemple
SELECT * FROM qsys2.SYSCST WHERE TDBNAME = ‘PLB’ and TBNAME =
‘TCOMMANDE’ and CONSTRAINT_TYPE = ‘FOREIGN KEY’ ;

Vous pouvez les administrer par la commande WRKPFCST
exemple :
QSYS/WRKPFCST FILE(PLB/TCOMMANDE)
TYPE(*REFCST)
Avec l’option 6 vous pourrez par exemple voir les enregistrements en instance de vérification, c’est la commande DSPCPCST, pas de sortie fichier !

Conseil :
C’est une très bonne solution sur vos nouvelles bases de données, mais attention l’ajouter sur des bases de données existantes peut être risqué en effet certain traitements pouvant essayer de bypasser ce contrôle, ou avoir des erreurs présentes sur votre base …
Astuces
Vous pouvez utiliser une contrainte temporaire pour vérifier les orphelins de votre base :
Ajout de la contrainte
DSPCPCST pour voir les erreurs
Retrait de la contrainte
Cette opération doit se faire hors activité utilisateur !
Quelques liens :
https://www.ibm.com/docs/en/i/7.5?topic=objects-constraints
https://www.ibm.com/docs/en/i/7.5?topic=constraints-adding-using-check
https://fr.wikipedia.org/wiki/Cl%C3%A9_%C3%A9trang%C3%A8re
Les vues SQL sur les contraintes
SYSCST La vue SYSCST contient une ligne pour chaque contrainte du schéma SQL.
SYSREFCST La vue SYSREFCST contient une ligne pour chaque clé étrangère du schéma SQL.
SYSKEYCST La vue SYSKEYCST contient une ou plusieurs lignes pour chaque UNIQUE KEY, PRIMARY KEY ou FOREIGN KEY dans le schéma SQL. Il existe une ligne pour chaque colonne dans chaque contrainte de clé unique ou primaire et les colonnes de référence d’une contrainte référentielle.
SYSCHKCST La vue SYSCHKCST contient une ligne pour chaque contrainte de vérification dans le schéma SQL. Le tableau suivant décrit les colonnes de la vue SYSCHKCST.
SYSCSTCOL La vue SYSCSTCOL enregistre les colonnes sur lesquelles les contraintes sont définies. Il existe une ligne pour chaque colonne dans une clé primaire unique et une contrainte de vérification et les colonnes de référence d’une contrainte référentielle.
SYSCSTDEP La vue SYSCSTDEP enregistre les tables sur lesquelles les contraintes sont définies.