


Retour sur une problématique récurrente et souvent mal comprise, donc mal gérée … Et qui pourrait bien s’amplifier avec l’usage plus intensif de l’Open Source.
Vous utilisez historiquement des fichiers sources (objet *FILE attribut PF-SRC) pour stocker vos sources : ces fichiers sont créés avec un CCSID, par défaut le CCSID du job dans lequel vous exécutez la commande CRTSRCPF
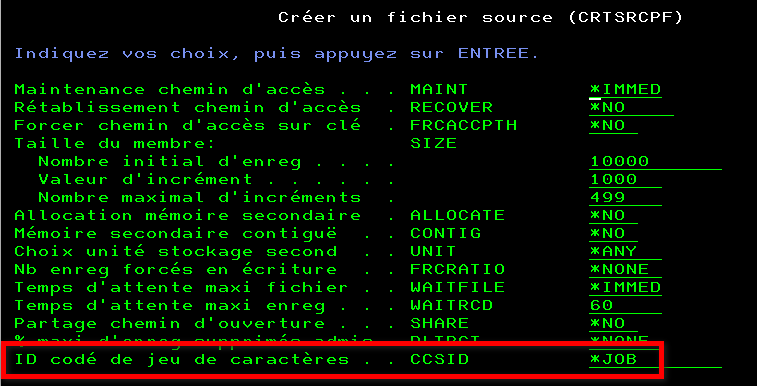
Usuellement vous obtiendrez des fichiers sources avec un CCSID 297 ou 1147 pour la France. Si vos machines sont « incorrectement » réglées, un CCSID 65535 (hexadécimal).
Mais également, par restauration d’autres produits, certainement des fichiers avec un CCSID 37 (US).
Pour les langages de programmation (dont le SQL), le CCSID du fichier source est important pour les constantes, qui peuvent par définition êtres des caractères nationaux quelconques. Quant aux instructions, la grammaire des langages les définis sans ambiguïtés.
Pour toutes les commandes, instructions, éléments du langage, pas de soucis d’interprétation
A la compilation, les constantes sont interprétées suivant le CCSID du job, pas celui du source !
En général, les deux CCSID sont identiques.
Par contre, pour les caractères spéciaux utilisés, si l’on regarde de plus près le cas du CL, la documentation indique :

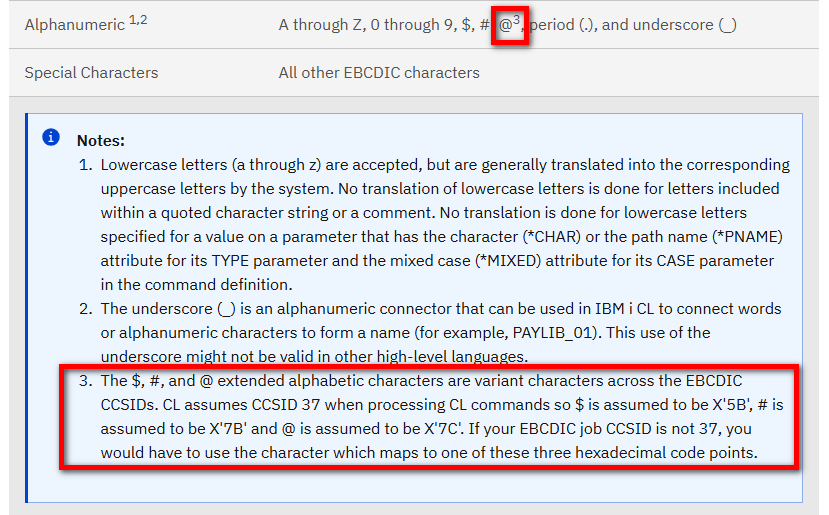
Voilà qui explique les fameuses transformations de @ en à !
En synthèse : le compilateur considère tous les éléments du langage comme étant en CCSID 37, hors les constantes alphanumériques et les quelques caractères listés ici.
Pour le CL : impossible d’utiliser les opérateurs symboliques |> (*BCAT), |< (*TCAT) et || (*CAT)
Le caractère | est mal interprété. Vous devez le remplacer par un !, ou utiliser les opérateurs non symboliques (*BCAT, *TCAT et *CAT).
Pour le SQL : impossible d’utiliser l’opérateur || (même raison).
Vous devez le remplacer par un !!, ou utiliser l’opérateur concat.
Le principe est le même.
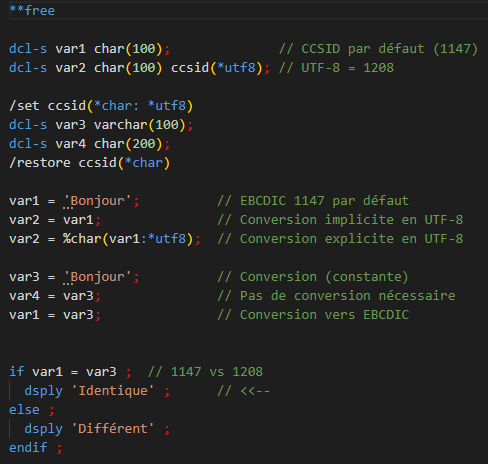
Toutefois le langage vous permet également de contrôler le CCSID des variables déclarées. Et depuis la 7.2, de nouvelles directives de pré-compilation permettent d’indiquer des valeurs de CCSID par défaut par bloc de source :
Sur l’IFS, chaque fichier (source ou non) dispose également d’un CCSID. Sa valeur dépend principalement de la façon de créer le fichier (par un éditeur type RDi/VSCode, partage netserver, transfert FTP …).
Premier point d’attention : l’encodage du contenu du fichier doit correspondre à son attribut *CCSID !
VSCode vous indique le CCSID de la donnée, par exemple :
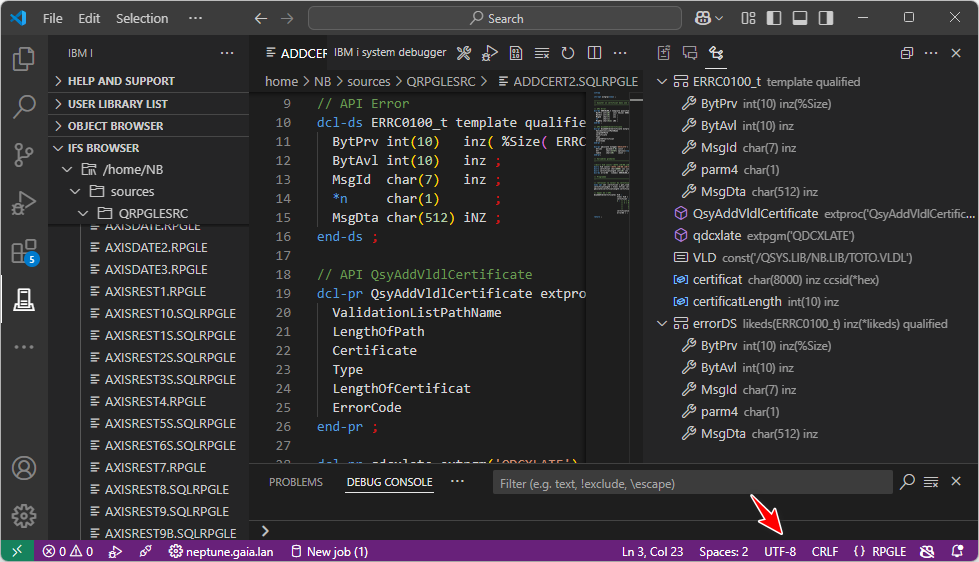
Mais :
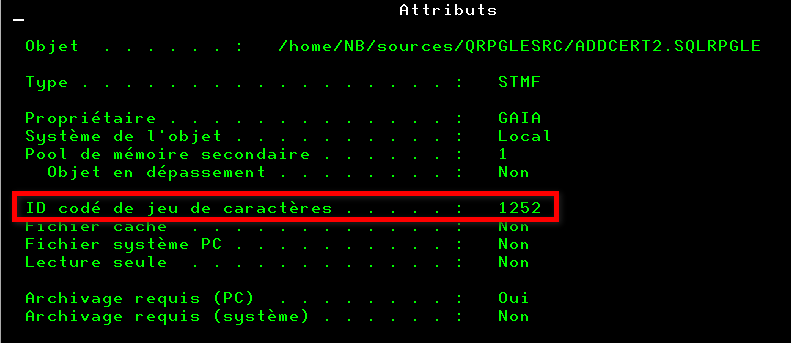
1252 = Windows occidental (proche de l’UTF-8 mais pas identique). La raison est que VSCode travaille naturellement en UTF-8.
RDi gère correctement l’encodage/décodage par rapport à la description du fichier.
Pour les autres outils, à voir au cas par cas !
Les compilateurs C, CPP, CL, RPG, COBOL supportent désormais (PTF en fonction des compilateurs) un paramètre TGTCCSID :
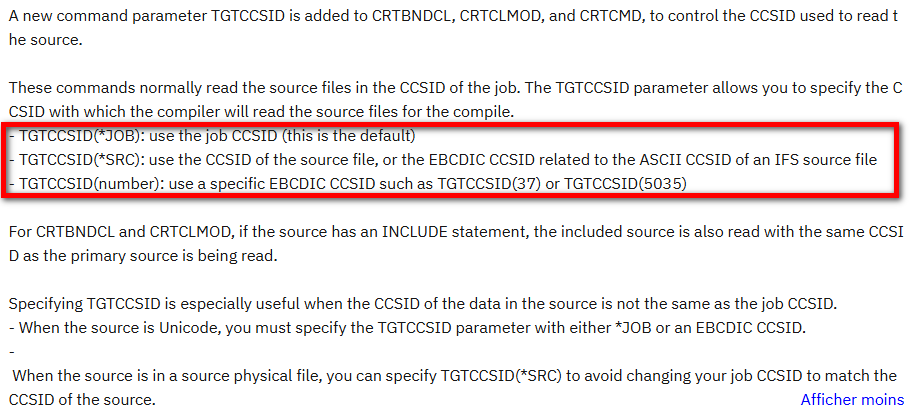
En réalité ce paramètre a été ajouté pour permettre la compilation plus facilement depuis l’IFS, principalement depuis des fichiers IFS en UTF-8.
Cela ne règle pas nos problèmes précédents, les éléments du langage n’étant pas concernés : nous auront toujours le problème d’interprétation du |
Par contre, c’est utile pour la bonne interprétation des constantes lorsque le job de compilation a un CCSID du source. Et cela permet une meilleure intégration dans les outils d’automatisation.
Eviter les caractères spéciaux !
Mais on ne peut pas toujours : nous avons voulu compiler QSHONI depuis le build fourni (https://github.com/richardschoen/QshOni?tab=readme-ov-file#installing-and-building-qshoni-via-git-clone-and-buildsh)
Le script propose d’indiquer un CCSID pour les fichiers sources. Mais la seule solution viable est de compiler avec un job en CCSID 37 :
Tant que vous n’avez pas de caractères nationaux dans le codes !
SELECT f.SYSTEM_TABLE_NAME,
f.SYSTEM_TABLE_SCHEMA,
c."CCSID"
FROM qsys2.systables f
JOIN qsys2.syscolumns c
ON (c.SYSTEM_TABLE_NAME, c.SYSTEM_TABLE_SCHEMA) = (f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA)
WHERE f.file_type = 'S' AND
LEFT(f.system_table_name, 8) <> 'EVFTEMPF' AND
c.SYSTEM_COLUMN_NAME = 'SRCDTA'
ORDER BY c."CCSID",
f.SYSTEM_TABLE_SCHEMA,
f.SYSTEM_TABLE_NAME;
https://www.ibm.com/support/pages/ifs-stmf-ccsids-1252-437-and-819
https://www.ibm.com/docs/en/i/7.4?topic=languages-language-compilers-ccsid
https://www.ibm.com/mysupport/s/fix-information/aDrKe000000PE0UKAW/fi0132711?language=en_US
https://www.ibm.com/mysupport/s/defect/aCIKe000000XohkOAC/dt418562?language=en_US
https://www.ibm.com/docs/en/i/7.5?topic=elements-cl-character-sets-values
https://www.ibm.com/docs/en/i/7.5?topic=values-symbolic-operators
https://www.ibm.com/docs/fr/i/7.5?topic=languages-language-compilers-ccsid
https://www.ibm.com/support/pages/have-you-heard-set-and-restore-directives
/
Nouveau venu dans les bibliothèques middleware pour IBMi, MAPEPIRE est un outil simple pour récupérer des données de votre serveur et les travailler sur de applications tierces, telles que des outils d’analyse de données, de la bureautique, etc.
Nous allons vous présenter la possibilité d’installer et d’utiliser le produit simplement
Ici, l’exemple détaillé sera effectué avec le langage PYTHON.
Nous n’intervenons pas dans cet article sur les différents paramétrages de l’outil. Nous y reviendrons dans un article suivant. (exit points, ports, etc.)
yum install mapepiremapepire sera installé dans le répertoire
/qOpenSys/pkgs/bin
Note : dans cet article, on ne détaille ps le démarrage automatique
nohup /qopensys/pkgs/bin/mapepire &Notre exemple consiste à lister tous les travaux actifs en cours, les répertorier dans une trame PANDAS, puis de sauvegarder les données dans une feuille EXCEL
sous l’environnement virtuel (si configuré) ou sur l’environnement global
pip install mapepire-python#mapepire
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
#--------------------------------------------------
creds = DaemonServer(
host="serveuràcontacter",
port=8076,
user="utilisateur",
password='motdepasse',
ignoreUnauthorized=True,
)
job = SQLJob()
res = job.connect(creds)
#
# Travaux actifs
#
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
countjobs = result['data'][0]['TOTALTRAVAUX']
startT = datetime.now()
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
endT = datetime.now()
delta = endT - startT
print(f"travaux actifs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframActj = pd.DataFrame(result['data'])
#print(dframActj)
#
#récupération des utilisateurs dans une 2ème Frame (dframUsesrs)
#
startT = datetime.now()
result = job.query_and_run("""
WITH USERS AS (
SELECT
CASE GROUP_ID_NUMBER
WHEN 0 THEN 'USER'
ELSE 'GROUP'
END AS PROFILE_TYPE,
A.*,
CAST(TEXT_DESCRIPTION AS VARCHAR(50) CCSID 1147)
AS TEXT_DESCRIPTION_CASTED
FROM (
SELECT *
FROM QSYS2.USER_INFO
) AS A
)
SELECT *
FROM USERS
""",
rows_to_fetch=500)
endT = datetime.now()
delta = endT - startT
print(f"Utilisateurs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframUsers = pd.DataFrame(result['data'])
#print(dframUsers)
print("Sauvegarde vers Excel")
with pd.ExcelWriter('/users/ericfroehlicher/Documents/donnes_dataframe.xlsx') as writer:
dframActj.to_excel(writer, sheet_name='ACTjobs')
dframUsers.to_excel(writer, sheet_name='Utilisateurs')#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pdCONSEIL: pour l’instant, toujours laisser le port 8076
#--------------------------------------------------
creds = DaemonServer(
host="serveuràcontacter",
port=8076,
user="utilisateur",
password='motdepasse',
ignoreUnauthorized=True,
)P
job = SQLJob()
res = job.connect(creds)Ici, on crée un travail simple, synchrone (SQLJob)
#comptage des travaux (pour l'exemple de l'utilisation du json)
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
# je récupère directement la valeur lue
countjobs = result['data'][0]['TOTALTRAVAUX']
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)A
Les données obtenues sont au format JSON. (voir plus bas les données brutes)
#insertion des résultats dans un Frame PANDAS
dframe = pd.DataFrame(result['data'])
print(dframe)
print("Sauvegarde vers Excel")
dframe.to_excel(
"/users/ericfroehlicher/Documents/travaux_actifs.xlsx",
sheet_name="Travaux actifs",
index=False
)Le flux de données renvoyé par MAPEPIRE contient l’ensemble des données et méta données au format JSON.
Voici un extrait du flux retourné (exemple sur 5 travaux)
{
'id': 'query4',
'has_results': True,
'update_count': -1,
'metadata':
{
'column_count': 6,
'job': '488835/QUSER/QZDASOINIT',
'columns':[
{
'name': 'JOB_NAME',
'type': 'VARCHAR',
'display_size': 28,
'label': 'JOB_NAME'
},
{
'name': 'JOB_TYPE',
'type': 'VARCHAR',
'display_size': 3,
'label': 'JOB_TYPE'
},
{
'name': 'JOB_STATUS',
'type': 'VARCHAR',
'display_size': 4,
'label': 'JOB_STATUS'
},
{
'name': 'SUBSYSTEM',
'type': 'VARCHAR',
'display_size': 10,
'label': 'SUBSYSTEM'
},
{
'name': 'MEMORY_POOL',
'type': 'VARCHAR',
'display_size': 9,
'label': 'MEMORY_POOL'
},
{
'name': 'THREAD_COUNT',
'type': 'INTEGER',
'display_size': 11,
'label': 'THREAD_COUNT'
}
]
},
'data':[
{
'JOB_NAME': '216350/QSYS/ARCAD',
'JOB_TYPE': 'SBS',
'JOB_STATUS': 'DEQW',
'SUBSYSTEM': 'ARCAD',
'MEMORY_POOL': 'BASE',
'THREAD_COUNT': 2
},
{
'JOB_NAME': '216369/ARCAD_NET/ARCAD',
'JOB_TYPE': 'ASJ',
'JOB_STATUS': 'MSGW',
'SUBSYSTEM': 'ARCAD',
'MEMORY_POOL': 'BASE',
'THREAD_COUNT': 1
},
{
'JOB_NAME': '216349/QSYS/CONTROL4I',
'JOB_TYPE': 'SBS',
'JOB_STATUS': 'DEQW',
'SUBSYSTEM': 'CONTROL4I',
'MEMORY_POOL': 'BASE',
'THREAD_COUNT': 2
},
{
'JOB_NAME': '216373/CTL4I/CTAGENTSPW',
'JOB_TYPE': 'PJ',
'JOB_STATUS': 'PSRW',
'SUBSYSTEM': 'CONTROL4I',
'MEMORY_POOL': 'BASE',
'THREAD_COUNT': 1
},
{
'JOB_NAME': '216377/CTL4I/CTAGENTSPW',
'JOB_TYPE': 'PJ',
'JOB_STATUS': 'PSRW',
'SUBSYSTEM': 'CONTROL4I',
'MEMORY_POOL': 'BASE',
'THREAD_COUNT': 1
}
],
'is_done': False,
'success': True
}

Vous devez surveiller l’IFS de votre partition et plus particulièrement la partie /home/ ou vous retrouvez les fichiers générés par vos utilisateurs et y faire le ménage régulièrement est une bonne pratique.
Une épuration à 30 jours semble un bon compromis
Voici 2 techniques pour réaliser cette opération
Voici un exemple, dans le répertoire /home/maurice/OUT on supprime les fichiers CSV de plus de 10 jours
Exemple :
find /home/maurice/OUT -type f -name « *.CSV » -mtime +10 -exec rm {} \;
Si vous voulez l’automatiser vous pouvez la mettre dans une commande ==>STRQSH
C’est une fonction, donc vous pourrez l’intégrer dans un select SQL
on prendra le même cas d’usage pour comparer
Exemple
SELECT path_name, SYSTOOLS.IFS_UNLINK(PATH_NAME)
FROM TABLE (QSYS2.IFS_OBJECT_STATISTICS(START_PATH_NAME => ‘/home/maurice/OUT’,
SUBTREE_DIRECTORIES => ‘NO’))
where ucase(Path_name) like(‘%.CSV%’)
and CREATE_TIMESTAMP < (current date – 10 days) ;
On utilise ici la fonction table QSYS2.IFS_OBJECT_STATISTICS qui permet de lister les fichiers d’un répertoire
Si vous voulez l’automatiser vous pouvez la mettre dans une commande ==>STRSQL ou dans dans du SQL embarqué
Conclusion
Il est important de surveiller L’IFS qui a tendance à grossir de manière excessive, et de supprimer les éléments inutiles
Nos solutions sont simples et efficaces vous pouvez facilement paramétrer les requêtes (répertoire, extension et périodicité)

Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
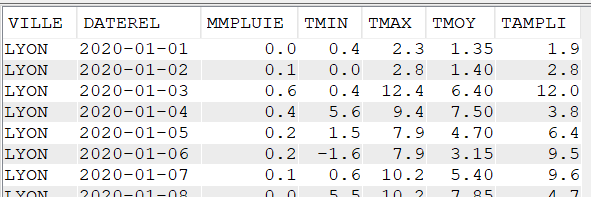
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)Données brutes
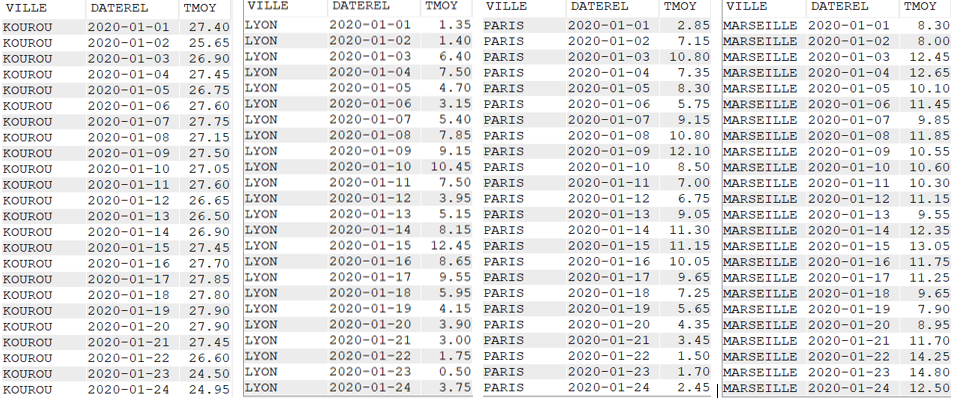
Données avec la fonction LISTAGG

Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";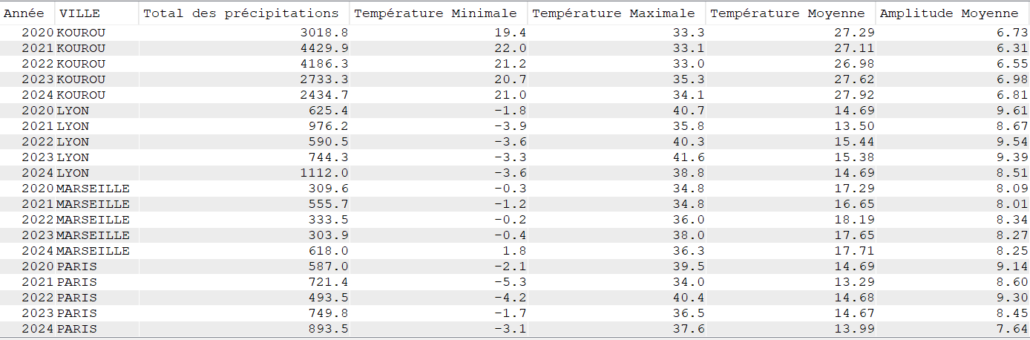
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
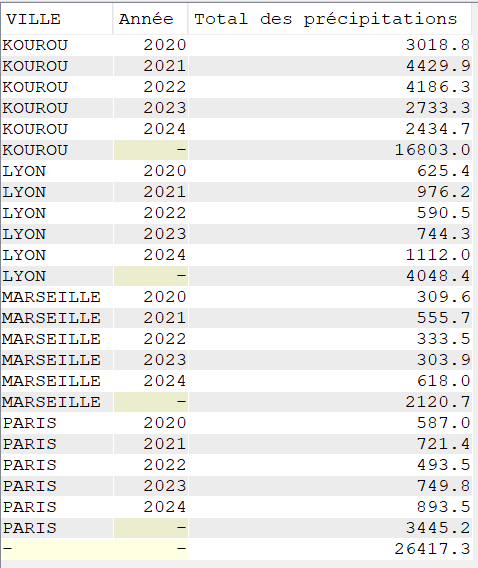
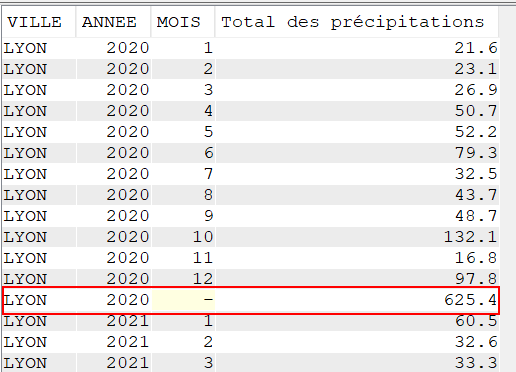
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));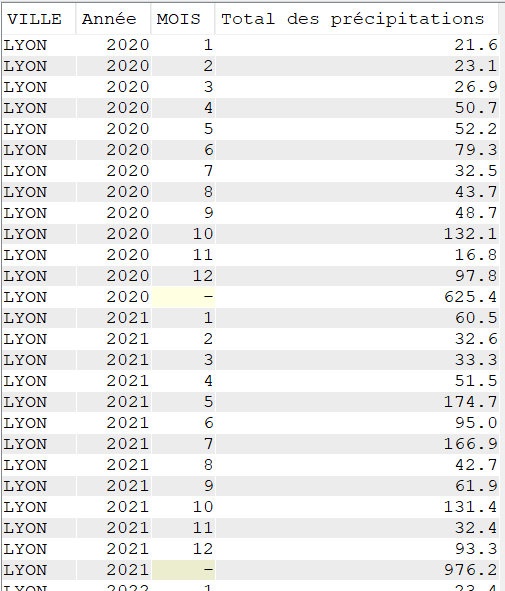
…
…
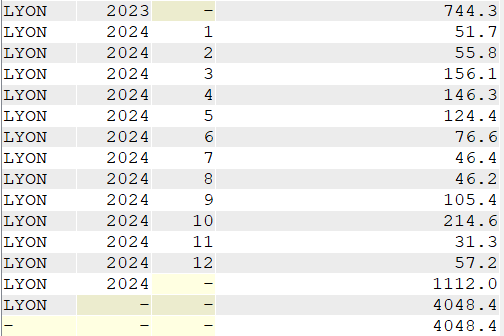
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
WHERE VILLE = 'LYON'
GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
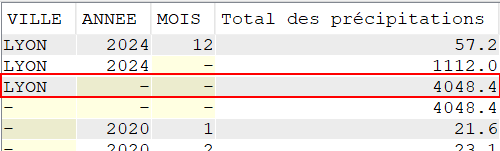
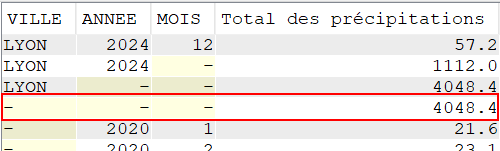
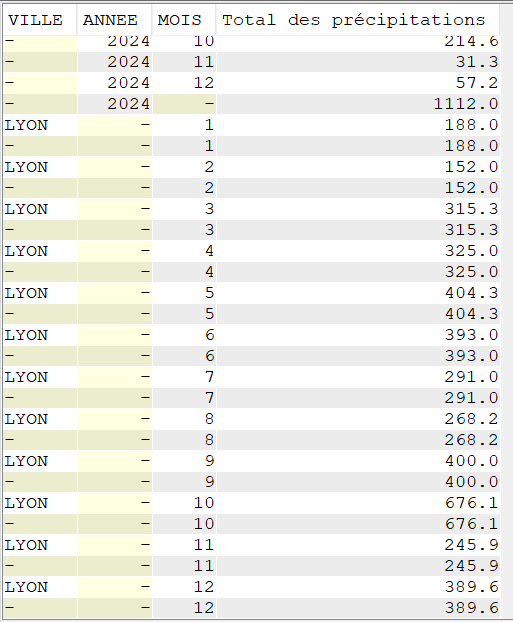
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
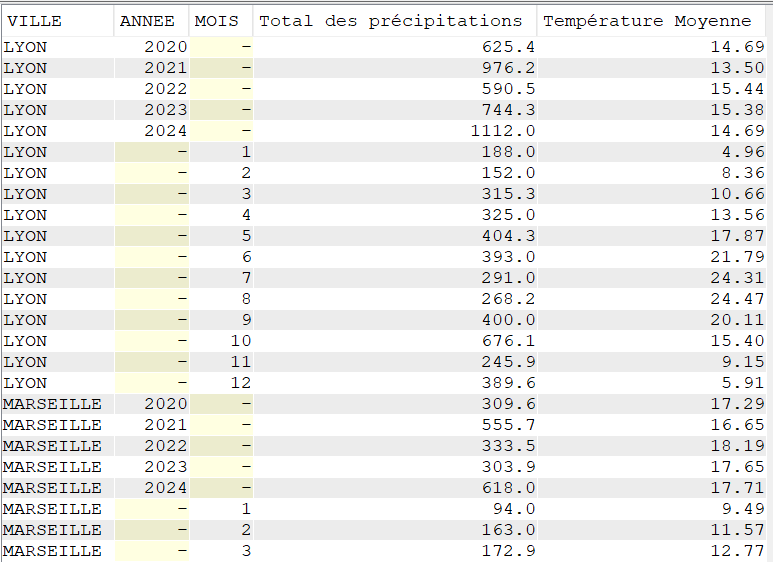
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL); 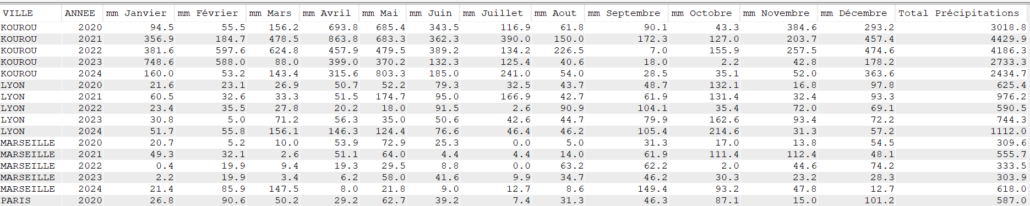
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL); 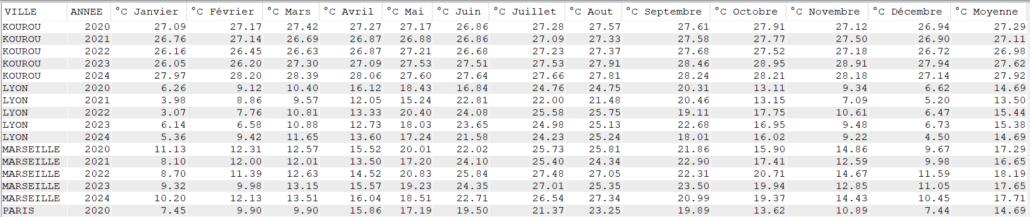
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.NULL est ignoré par AVG, garantissant une moyenne correcte.Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
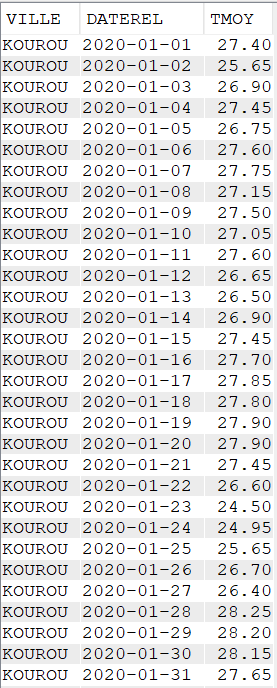
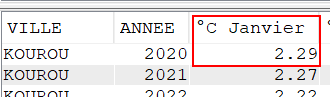
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL); 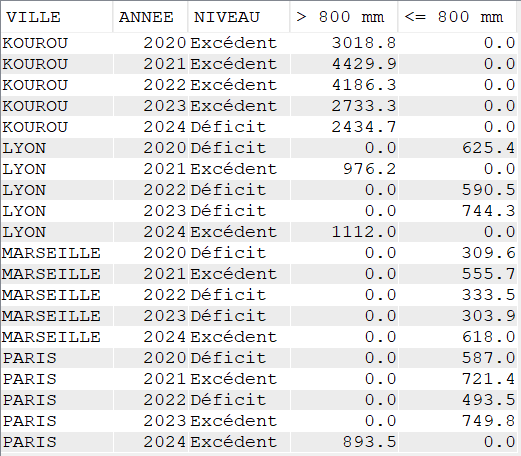
Si vous avez mis en œuvre le journal vous pouvez et même devez analyser les refus de connexion.
Le plus souvent c’est un mauvais mot de passe mais ca peut être aussi une attaque, ou un comportement douteux
Voici une requête simple qui permet cette analyse rapide
SELECT JOB_NAME, USER_NAME, FUNCTION, MESSAGE_ID, MESSAGE_TIMESTAMP
FROM TABLE(QSYS2.DISPLAY_JOURNAL(‘QSYS’, ‘QAUDJRN’))
WHERE MESSAGE_ID IN (‘CPF2234’, ‘CPF1107’, ‘CPF1393’)
ORDER BY MESSAGE_TIMESTAMP DESC;
Les messages traités ici
CPF2234 Tentative de connexion échouée.
CPF1107 Mot de passe incorrect.
CPF1393 Accès refusé.
Remarque :
Vous pouvez ajouter des filtres (plage horaire, autres messages de refus , etc …)
Vous devrez découper vous même la zone entry data, vous pouvez également utiliser les fonctions table QSYS2.DISPLAY_JOURNALxx spécialisées par TYPE
Plus d’information ici https://www.ibm.com/support/pages/qsys2displayjournal