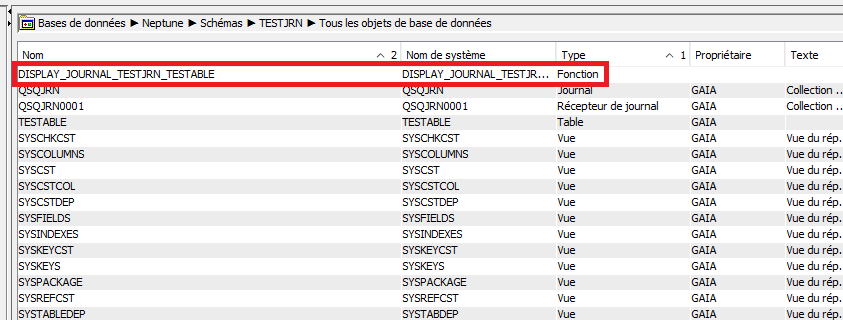
Pour analyser des journaux la difficulté est de traiter le poste *entry data qui est spécifique à chaque fichier
La tr2 de la v7R6 et la tr8 de la v7r5 permet de résoudre cette problématique en créant une fonction spécifique sur un fichier pour analyser les postes de TYPE R
Voici un petit protocole de test
— création d’un schéma
create schema testjrn ;
création d’une table journalisée par défaut sur qdftjrn
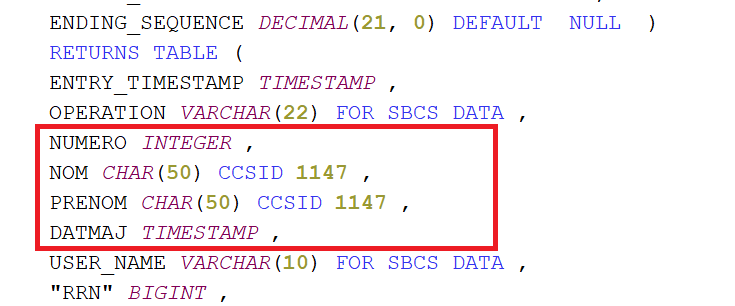
CREATE TABLE TESTJRN/TESTABLE ( NUMERO INT NOT NULL WITH DEFAULT, NOM CHAR ( 50) NOT NULL WITH DEFAULT, PRENOM CHAR ( 50) NOT NULL WITH DEFAULT, DATMAJ TIMESTAMP NOT NULL WITH DEFAULT) ;
— génération de modifications dans le journal
INSERT INTO TESTJRN/TESTABLE VALUES(1, ‘Berthoin’, ‘Pierre-Louis’, current timestamp);
INSERT INTO TESTJRN/TESTABLE VALUES(2, ‘Berthoin’, ‘Younes’, current timestamp) ;
INSERT INTO TESTJRN/TESTABLE VALUES(3, ‘Mbappé’, ‘Kilian’, current timestamp) ;
INSERT INTO TESTJRN/TESTABLE VALUES(4, ‘Chombier’, ‘Patrice’, current timestamp) ;
UPDATE TESTJRN/TESTABLE SET PRENOM = ‘Robert’ WHERE NUMERO = 4;
DELETE FROM TESTJRN/TESTABLE WHERE NUMERO =3 :
— génération de la fonction table spécifique à votre fichier
C’est un projet qui a eu plusieurs Vies, il existe même un plugin RDI et une extension vscode
C’est un projet qui permet de faire des tests unitaires sur des fonctions ILE
Il est basé sur les « assertions »
En informatique c’est une vérification intégrée dans le code qui s’assure qu’une condition spécifique est vraie à un moment donné de l’exécution du programme
D’abord vous devez installer une version de la bibliothèque RPGUNIT sur votre systéme, cette bibliothèque contient le Framework qui va permettre de mettre en œuvre vos tests
Vous devrez avoir un programme service et connaitre la fonction à tester
Vous allez créer un programme de service spécifique qui va créer des surcouche à vos fonction
Exemple : Fonction calcul dans votre application deviendra Fonction test_calcul dans le programme de service RPGUNIT
Votre programme CALCUL ici dans la bibliothèque DEMOUNIT
**free
ctl-opt nomain;
dcl-proc Addition export;
dcl-pi *n int(10);
a int(10) const;
b int(10) const;
end-pi;
return a + b;
end-proc;
Vous avez pouvez faire des choses plus évoluées et VSCODE vous offre un assistant pour générer le programme RPGUNIT de Test, mais je pense qu’il est important de comprendre ce qu’on fait
Les assertions sont inclues en standard dans la TR2 en V7R6 pour le RPGLE
On a parfois besoin d’envoyer pour différentes raisons des messages en RPGLE
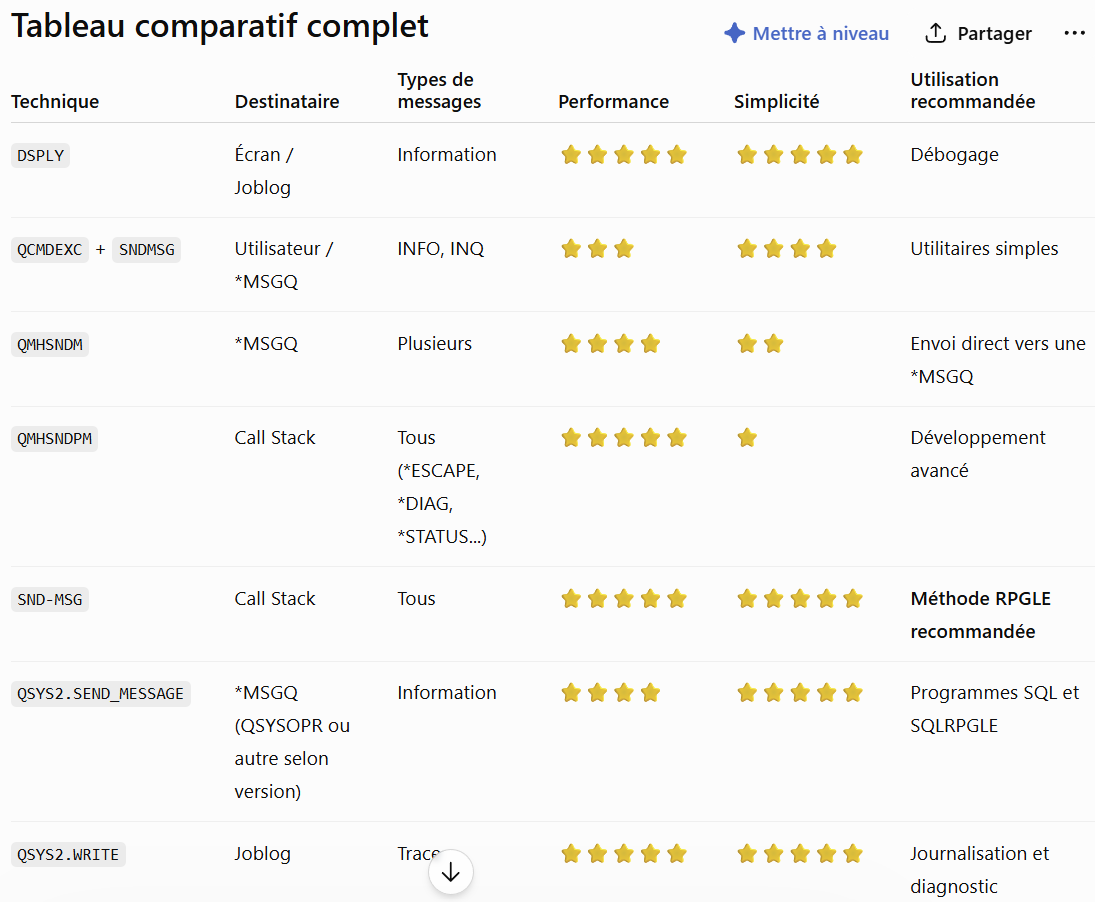
Voici un tableau comparatif des solutions existantes :
Conclusions
Pour un développement moderne sur IBM i 7.5 ou plus voici nos préconisations :
SND-MSG pour les messages applicatifs en RPGLE (notamment *ESCAPE, *DIAG, *STATUS) , pour du SQLRPGLE il remplace avantageusement le dsply
QSYS2.SEND_MESSAGE lorsqu’on est principalement en SQL ou SQLRPGLE, il permet par exemple de choisir une file de messages
QSYS2.WRITE pour remplacer les DSPLY de débogage par des traces propres dans la joblog
QMHSNDPM pour les développements avancés , par exemple pour échanger vers des files de messages programmes
Remarques
Pour des actions particulières, par exemple refus de trigger, erreur de données dans un cgi, il peut être plus judicieux de créer un fichier de log. Il devra contenir les informations sur la nature de l’erreur et le contexte d’exécution à minima user, job, date heure, programme
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-18 10:45:332026-07-19 20:10:04Envoyer un message en RPGLE
Vous voulez savoir le droit qu’un utilisateur aura quand il tentera d’accéder à un fichier IFS
Voici un script avec les requêtes qui vous aidera à déterminer le droit que vous obtiendrez.
Vous aurez 8 étapes possibles , et il s’arrêtera à la première correspondance.
--
-- Voici une liste de commande SQL pour trouver le droit d'un utilisateur
-- Sur un fichier IFS
-- ici l'utilisateur PLB
-- tente d'accéder au fichier
--/home/plb/Controle_demarrage_SBS.csv
-- 1 si user *ALLOBJ
-- Si oui tous les droits
--
SELECT SPECIAL_AUTHORITIES,
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 2 si user sur l'objet
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 3 si utilisateur dans liste d'autorisations
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = 'PLB'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
-- 4 si groupe all obj
-- Si oui tous les droits
--
SELECT
SPECIAL_AUTHORITIES
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = ( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
-- 5 si groupe sur l'objet
--
SELECT * FROM TABLE(QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv'))
where AUTHORIZATION_NAME =
( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
--6 Si groupe dans la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = (SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB')
AND AUTHORIZATION_LIST = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
--7 Si public
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND DATA_AUTHORITY <> '*AUTL';
--
--8 Si public reporté sur la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
Remarque :
Ce mécanisme peut être complété par des groupe additionnels , les droits proposés devenant complétifs (‘Ajouter au droit existant’)
Il est conseillé de les utiliser modérément , on peut avoir un système de droit assez efficace juste avec le mécanisme historique
Dans l’IFS l’adoption de droit ne s’applique pas, mais dans vos sript sh vous pouvez utiliser la notion de SETUID
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-03 10:13:032026-07-03 10:13:04Droit d’utilisateur sur un fichier IFS
Aujourd’hui vous verrez comment créer un programme capable de convertir un fichier html en PDF depuis votre IBM i à l’aide d’un appel d’API externe.
Rappel sur l’IBMi vous pouvez générer du PDF en utilisant :
Transform Services produit sous licence IBM mais très sommaire
Une solution open source que vous installez sur votre partition
Exemple:
wkhtmltopdf (outil de conversion) qui n’est en fait plus du tout maintenu.
On va donc présenter une autre solution qui se base sur les API
Nous avons choisi l’API qui s’appelle PDFSPARK. Cette solution vous permet de tester notre outil, vous avez jusqu’à 20 requêtes/minute sans clé alors que la plupart des autres API demandent une inscription et proposent environ que 15 requêtes/jour avec un forfait gratuit.
Normalement l’API reçoit une page en ligne en html puis la convertie, mais ici on voulait un .html depuis l’IFS donc j’ai demandé à l’IA (claude) de me faire juste un mini programme pour l’utiliser avec un fichier local et il m’a donné ça :
#!/QOpenSys/usr/bin/bash
export PATH=/QOpenSys/pkgs/bin:/QOpenSys/usr/bin:/usr/bin:$PATH
HTML_FILE=$(echo -n "$1" | tr -d ' ')
PDF_FILE="${HTML_FILE%.html}.pdf"
if [ ! -f "$HTML_FILE" ]; then
echo "ERROR: HTML file not found"
exit 1
fi
HTML_CONTENT=$(cat "$HTML_FILE" | jq -Rs .)
curl -s -X POST "https://pdfspark.dev/api/v1/pdf/from-html" \
-H "Content-Type: application/json" \
-d "{\"html\": $HTML_CONTENT, \"options\": {\"format\": \"A4\"}}" \
-o "$PDF_FILE"
echo "DONE : $PDF_FILE"
echo "Your file is located in : $HTML_FILE"
Le programme fait, dans l’ordre :
Récupère le chemin du fichier à convertir en paramètre
Crée un PDF du même nom (que le nom du fichier)
Vérifie si le fichier existe vraiment
Lis le .html passé en paramètre et le converti en JSON pour ensuite l’injecter dans l’API (jq -Rs)
Et ensuite la requête curl donnée par le site de l’API
Puis il y a le programme CL qui appelle le .sh depuis 5250 :
PGM PARM(&FILE)
/* début de la construction de la commande bash */
DCL VAR(&NULL) TYPE(*CHAR) LEN(1) VALUE(X'00')
DCL VAR(&BASH) TYPE(*CHAR) LEN(100) +
VALUE('/QOpenSys/usr/bin/bash')
DCL VAR(&CONVERT) TYPE(*CHAR) LEN(100) +
VALUE('/chemin/vers/votre/fichier/html2pdf.sh')
/* fin de la construction de la commande bash */
/* Création de la variable FILE pour rentrer en paramètre
le chemin vers le fichier à convertir depuis 5250 */
DCL VAR(&FILE) TYPE(*CHAR) LEN(256)
DCL VAR(&FILETRIM) TYPE(*CHAR) LEN(100)
/* concaténation des variables
pour former la commande bash final */
CHGVAR VAR(&FILETRIM) VALUE(&FILE)
CHGVAR VAR(&BASH) VALUE(&BASH *TCAT &NULL)
CHGVAR VAR(&CONVERT) VALUE(&CONVERT *TCAT &NULL)
CHGVAR VAR(&FILETRIM) VALUE(&FILETRIM *TCAT &NULL)
/*Appel de QP2SHELL pour l'exécution de la commande*/
CALL PGM(QP2SHELL) PARM(&BASH &CONVERT &FILETRIM)
ENDIT:
ENDPGM
Après compilation et ajout de la librairie, il suffit d’appeler ce programme via l’interface 5250 avec en paramètre le chemin vers le fichier .html que vous voulez convertir en PDF :
Pour l’instant, le nouveau fichier .PDF sera enregistré au même endroit que le .html
Et pour vous faciliter encore plus la tâche,
vous pouvez créer une commande à appeler depuis 5250 en créant un fichier CONVERSION.CMD comme ceci :
CMD PROMPT('Conversion html vers pdf')
PARM KWD(FICHIER) TYPE(*CHAR) LEN(256) MIN(1) +
PROMPT('Fichier à convertir')
puis la compiler.
Au final
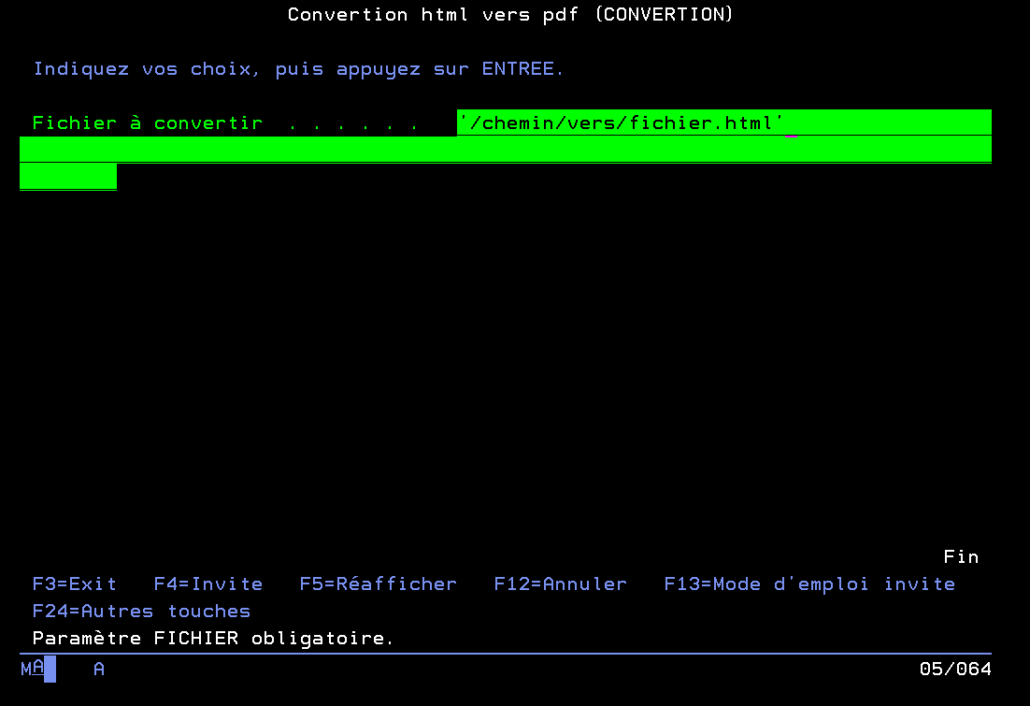
Vous pourrez appeler votre programme de conversion depuis 5250 juste avec la commande : conversion puis en appuyant sur F4, tomber sur cet écran qui vous permettra de renseigner (entre simple quote ‘ ) le chemin vers le fichier à convertir (également utilisable en batch):
Remarques :
Votre IBMi devra sortir vers l’URL https://pdfspark.dev sur le port 443 , ou vers le provider que vous aurez choisi
Vous pourrez faire des PDF plus évolués que par Transformer, et il est assez facile de générer du HTML.
Vous devrez choisir votre partenaire surtout si vous voulez traiter des données confidentielles
Ici nous avons choisi de faire du CURL , mais vous pouvez utiliser si vous le préférez un programme SQLRPGLE
Vous pouvez bien sur améliorer ce code à votre guise.
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-06-09 09:16:082026-06-09 09:16:10Html vers pdf dans l’IBM i
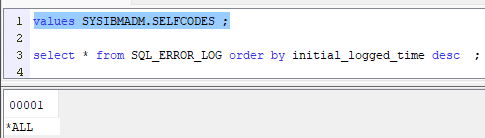
Concrètement, cela modifie la liste des erreurs qui sont tracées dans la vue SQL_ERROR_LOG. Cette liste est stockée dans la variable globale SYSIBMADM.SELFCODES, avec quelques valeurs spéciales (*ALL, *ERROR, *WARN, *NONE).
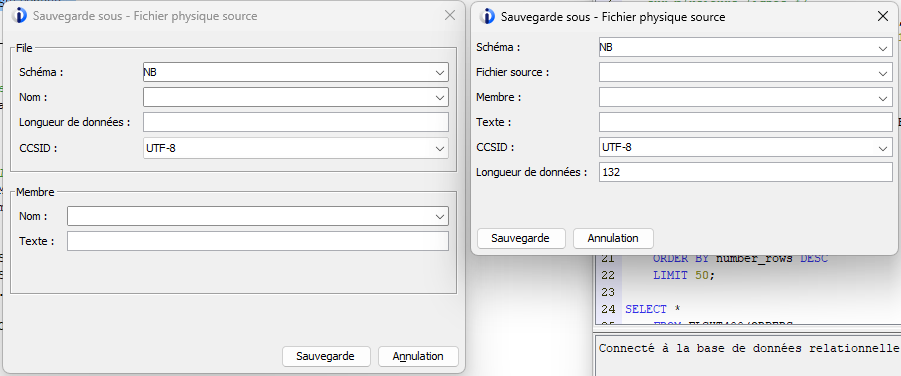
Fichiers physiques source
Amélioration de la fenêtre de dialogue pour la sauvegarde en fichiers sources :
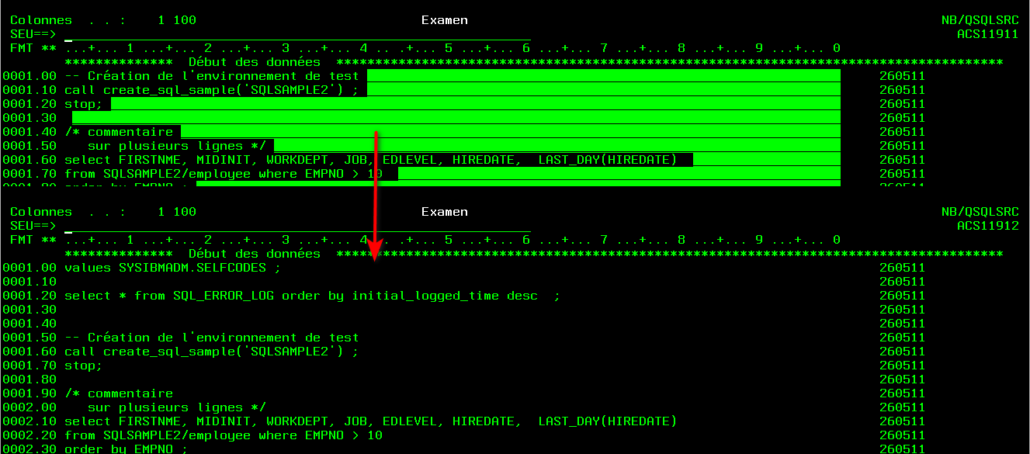
Gestion des fins de ligne
Les caractères LF (x’25’) ne sont plus insérés en fin de ligne dans le cas d’une sauvegarde en fichier source :
Il n’y pas d’impact à l’éxecution (RUNSQLSTM), mais plus de confort !
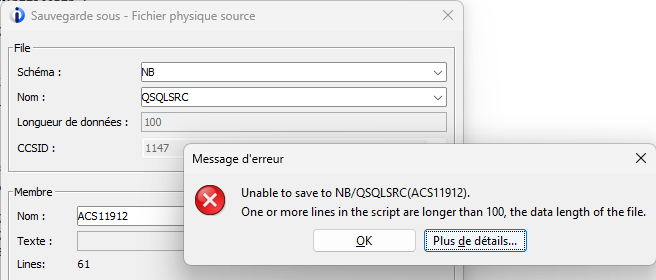
Gestion de la taille des lignes
Lors de l’enregistrement, au lieu de tronquer les lignes, un message permet d’avertir :
Exemples SQL
13 nouveaux exemples pour les services SQL :
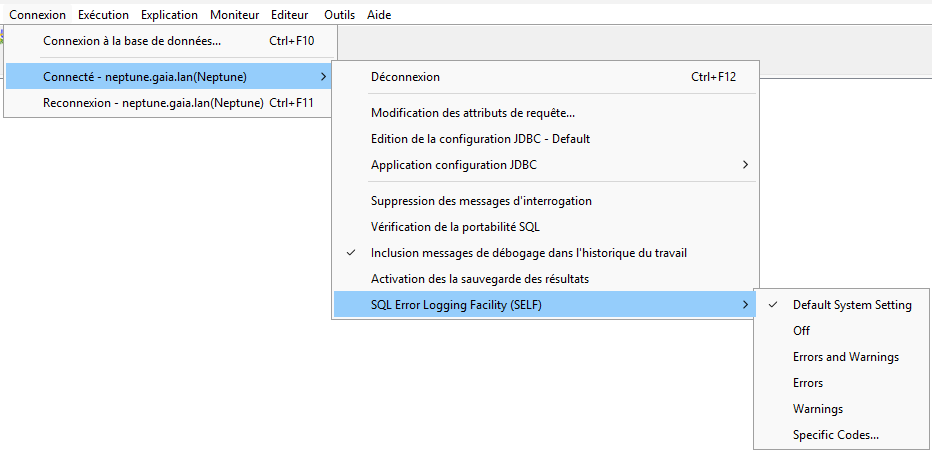
SELF – System-wide controls
SELF – Job-level controls
SELF – Log Queries
SELF – Removing historical rows
SELF – Initial Stack
SELF – Top occurrences
SELF – QA use case exampleSecurity – Who is creating objects in the IFS root
Security – Who is creating objects in the /QOpenSys subdirectory
Security – IFS first-level directories that are open to attack
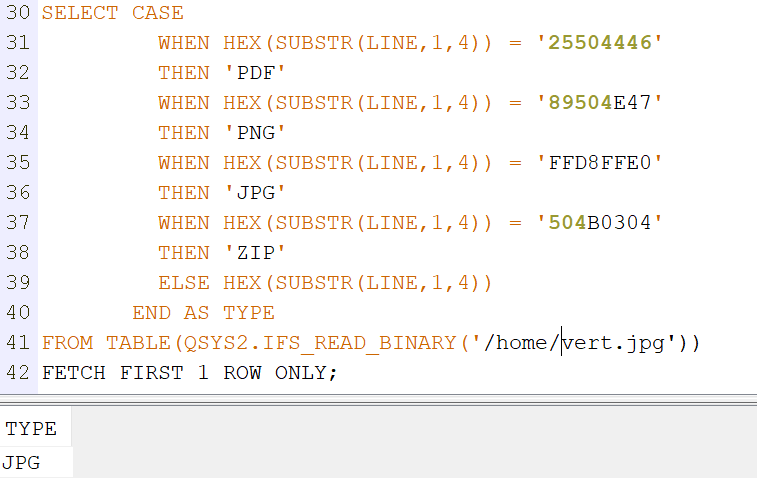
Pour connaitre le type d’un fichier, vous pouvez vous baser sur le type du Fichier .PDF, .JPG, etc …
Ou vous baser sur le nombre magique , ou signature binaire soit les 4 premiers octets en Hexa
SELECT HEX(SUBSTR(LINE, 1, 4)) AS SIGNATURE FROM TABLE(QSYS2.IFS_READ_BINARY(‘/home/test.pdf’)) FETCH FIRST 1 ROW ONLY;
Voici un exemple sur 4 fichiers que vous pouvez trouver sur votre partition
SELECT CASE
WHEN HEX(SUBSTR(LINE,1,4)) = '25504446'
THEN 'PDF'
WHEN HEX(SUBSTR(LINE,1,4)) = '89504E47'
THEN 'PNG'
WHEN HEX(SUBSTR(LINE,1,4)) = 'FFD8FFE0'
THEN 'JPG'
WHEN HEX(SUBSTR(LINE,1,4)) = '504B0304'
THEN 'ZIP'
ELSE 'Autre' // inconnu
END AS TYPE
FROM TABLE(QSYS2.IFS_READ_BINARY('/home/vert.jpg'))
FETCH FIRST 1 ROW ONLY;
Résultat :
Conclusion :
C’est simple, et efficace, il y a sans doute d’autres manières de faire
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-05-11 14:42:272026-05-11 14:42:28Trouver le type d’un fichier
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2026-05-04 18:47:272026-05-04 18:56:14Problème de conversion avec CVTRPGSRC
Grafana est une plateforme logicielle open-source de visualisation et d’analyse de données. Son rôle principal est de collecter des informations provenant de sources variées (bases de données, outils de monitoring (Manzan), systèmes cloud) et de les centraliser dans une interface unique.
(Si ce n’est pas déjà fait, veuillez consulter le blog précédent sur Manzan pour réaliser et mieux comprendre celui ci)
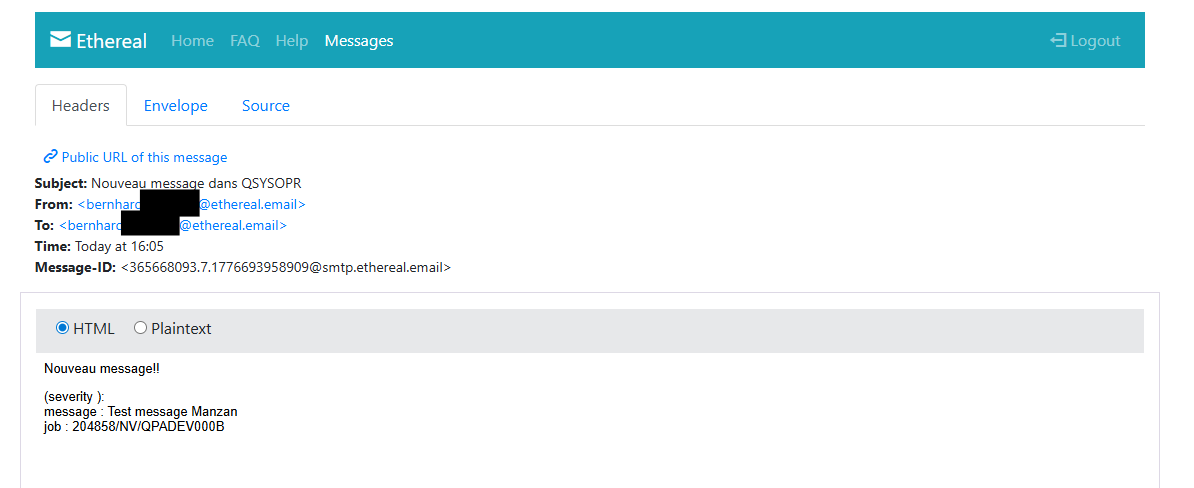
Nous allons prendre l’exemple des messages INQ dans QSYSOPR pour les retranscrire dans Grafana à l’aide de Manzan
Voici d’abord comment configurer Manzan :
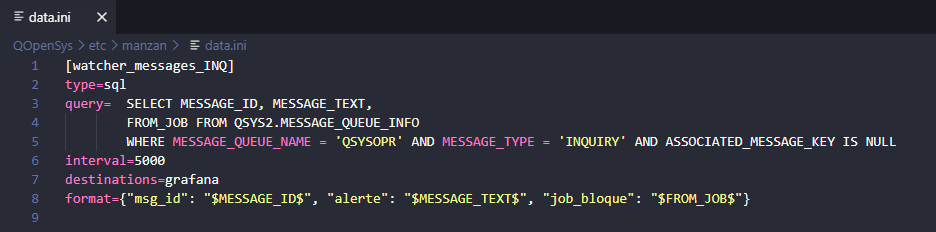
Tout se fait principalement dans le fichier data.ini :
[watcher_messages_INQ]
type=sql
query=SELECT MESSAGE_ID, MESSAGE_TEXT, FROM_JOB FROM QSYS2.MESSAGE_QUEUE_INFO WHERE MESSAGE_QUEUE_NAME = 'QSYSOPR' AND MESSAGE_TYPE = 'INQUIRY' AND ASSOCIATED_MESSAGE_KEY IS NULL
interval=5000
destinations=grafana
format={"msg_id": "$MESSAGE_ID$", "alerte": "$MESSAGE_TEXT$", "job_bloque": "$FROM_JOB$"}
Dans data.ini nous retrouvons le même format JSON du blog précédent. En effet Grafana gère mieux les données en JSON notamment pour le tri des différentes sources qui lui sont envoyées.
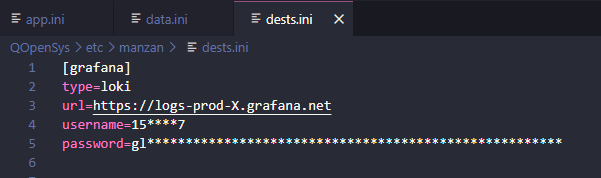
Puis voici votre dests.ini
Cette destination pointe vers une logs Grafana dans laquelle vous pouvez y passer toutes les données que vous voulez pour ensuite les trier grâce au format que vous avez défini dans votre data.ini :
Vous pouvez installer Grafana en local sur une partition linux ou sur un linux externe, mais pour le moment pas sur l’ibmi… Pour notre test nous allons utiliser une version de Grafana en ligne accessible en webservice .
Dans Grafana :
Comment récupérer votre username et password dans Grafana ?
Premièrement pour l’username
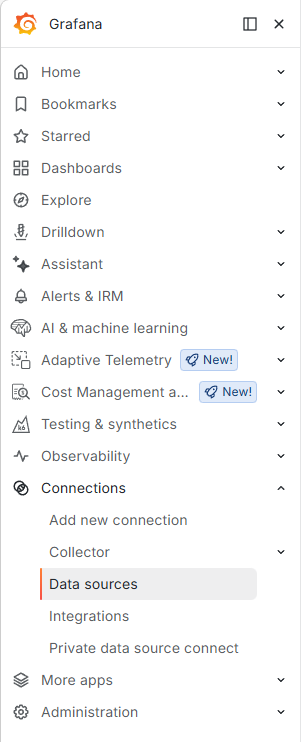
Vous devez, une fois votre compte Grafana créé, vous dirigez vers la section Connection puis Data sources :
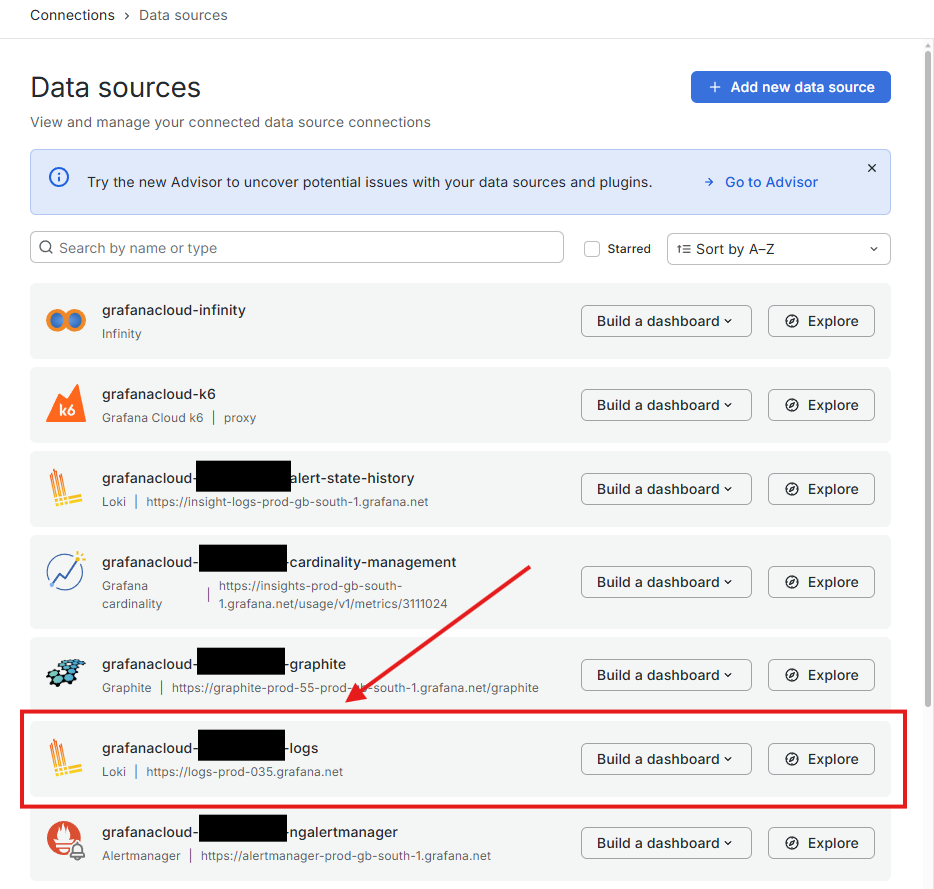
Puis vous atterrirez sur cette page :
(les rectangles noirs seront votre nom dans Grafana)
Une fois sur la page des logs (via loki qui est le service de log de Grafana) vous descendrez un petit peu pour trouver ces 2 sections :
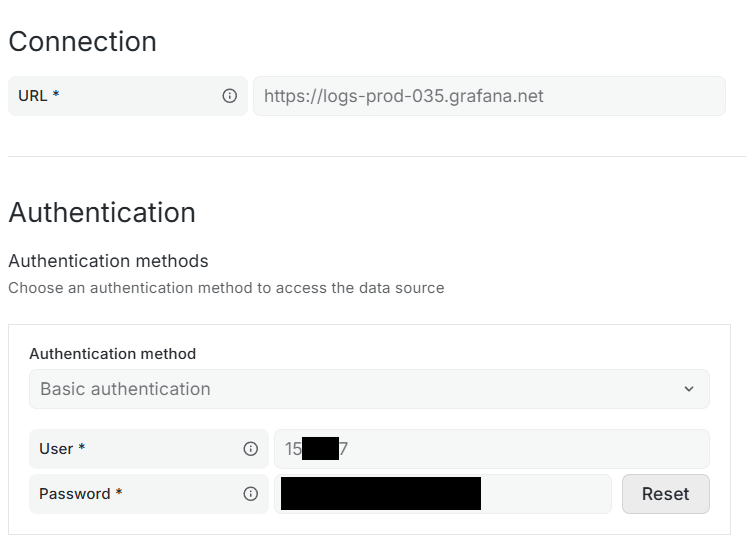
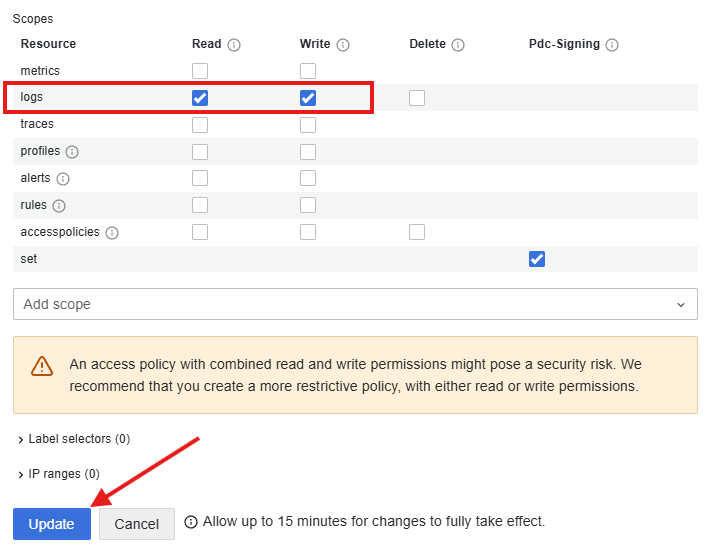
Ce qui va nous intéresser ici est l’URL de la Connexion que vous mettrez dans votre dests.ini dans le champ url= Mais aussi le User qui est l’identifiant de votre logs. Vous le mettrez aussi dans dests.ini dans le champ username=
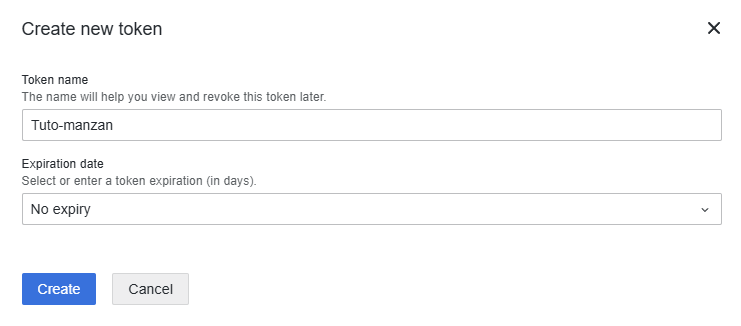
Maintenant comment trouver votre password ?
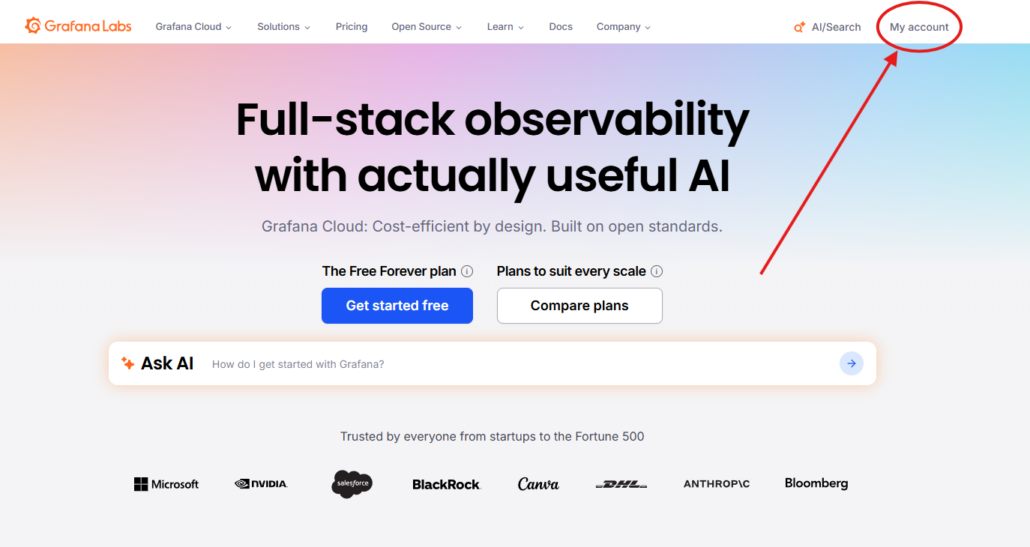
Vous devez vous rendre sur la page d’acceuil de Grafana en étant connecté à votre compte puis cliquer sur My account en haut à droite
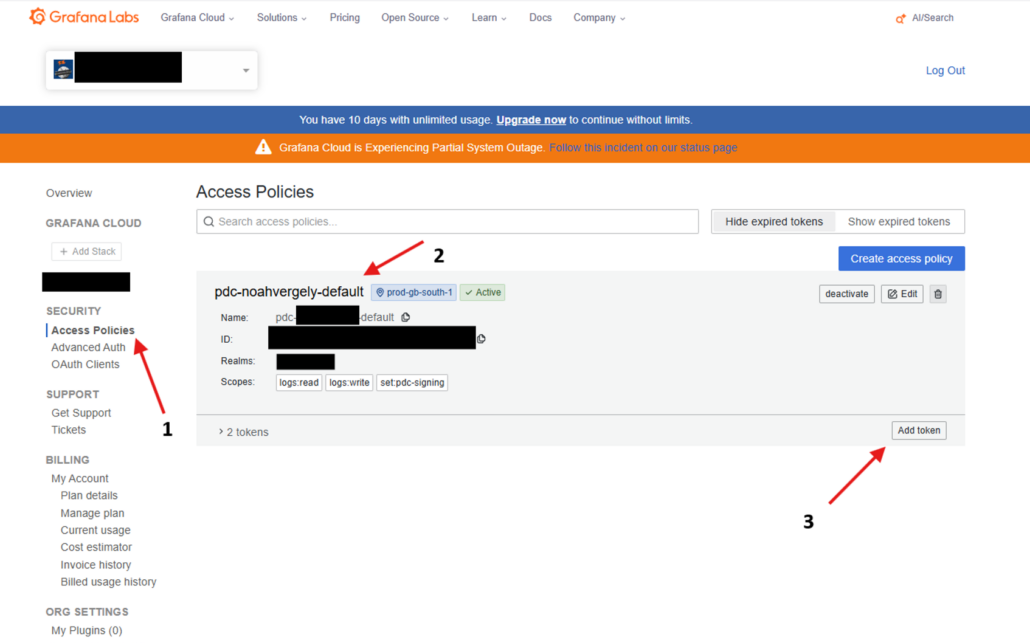
Vous atterrirez sur cette page :
2.
3.
Suite à ça vous devez copier et garder ce token pour l’utiliser dans le fichier dests.ini
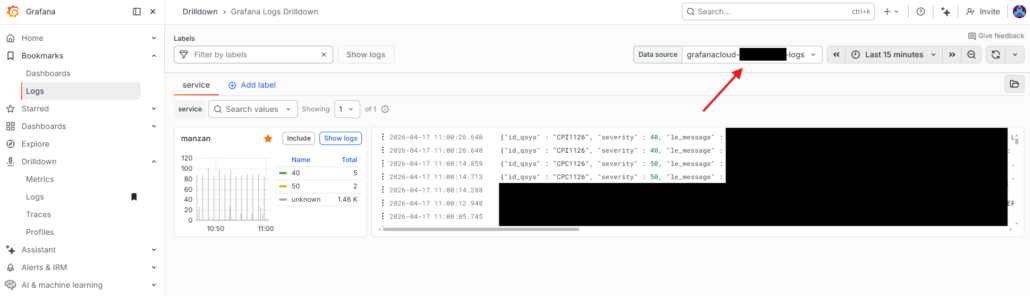
Puis vous n’aurez qu’à regarder dans votre logs en pensant à surveiller que vous avez bien sélectionné vos logs loki comme montré ci dessous :
Vous pouvez ensuite créer un Dashboard dans lequel vous surveillerez tout ce que vous voudrez en créant plusieurs sources avec les données que vous enverrez dans Grafana en format JSON
Exemple :
Voici la commande en 5250 pour vous envoyer un message INQ et faire vos tests de votre côté :
Le message restera visible même s’il a réçu une réponse, vous devrez l’enlever manuellement depuis 5250 pour qu’il disparaisse de Manzan et Grafana
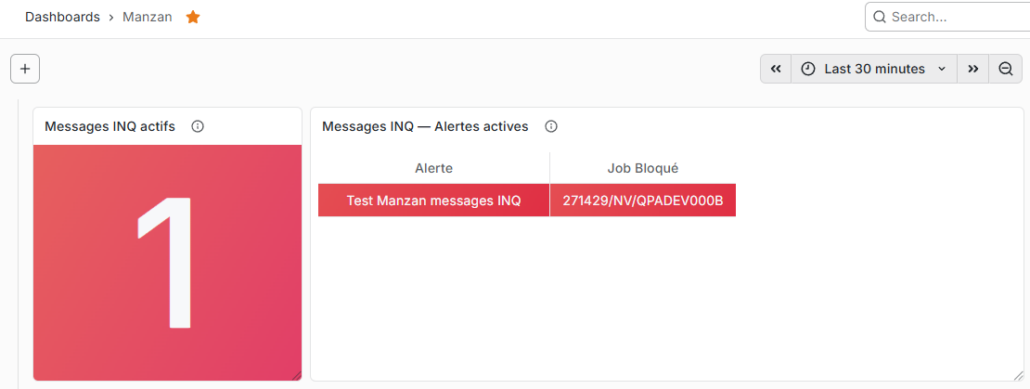
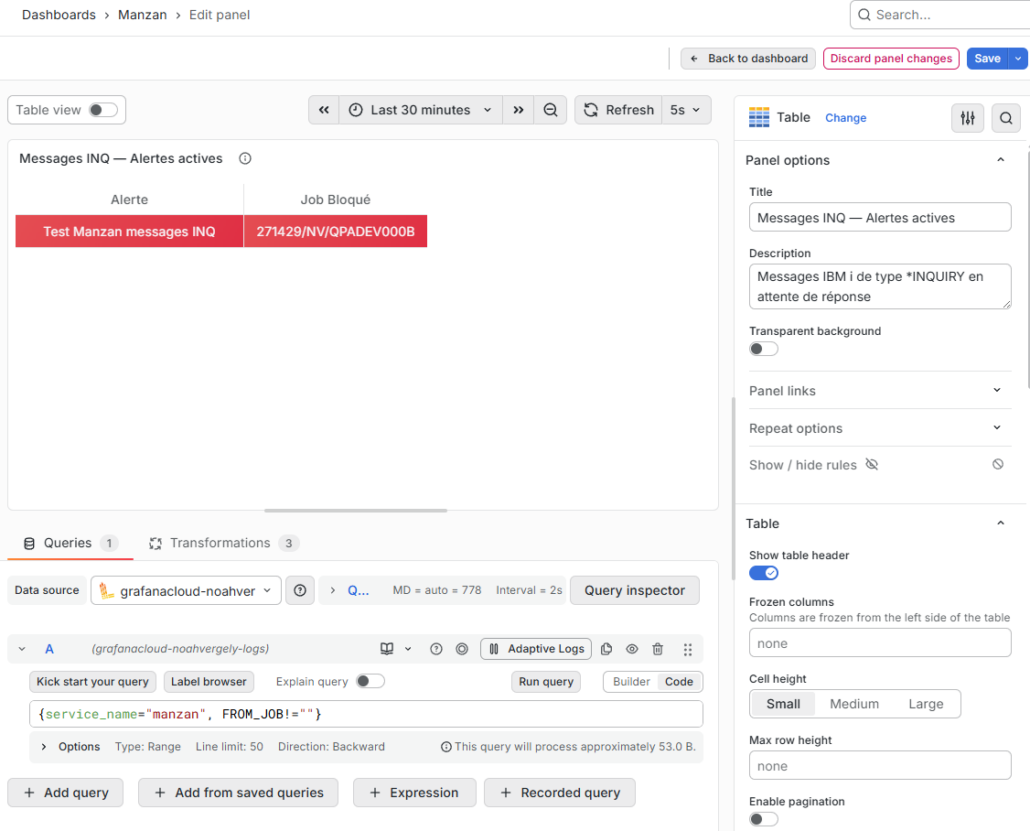
Exemple du rendu dans le dashboard
Détail de la configuration de la table de messages INQ, quand il y en a 1 et les paramètres du dashboard:
Conclusion:
Vous pouvez utiliser Manzan , pour capter les événements souhaités sur partition IBMi, le paramétrage reste assez simple (Seulement 2 fichiers à mettre à jour)
Grafana est devenu un standard de restitution d’information, il semblait donc naturel de brancher manzan sur cette solution pour avoir un outil fiable et robuste.
A noter que dans grafana, il exite un assistant IA pour vous aider à configurer votre dasboard.
Bon tests à tous, n’hésitez pas à nous contacter pour de plus amples informations, ou à contacter https://cfd-innovation.fr/ dont on s’est librement inspiré pour cet article.
Aujourd’hui vous verrez comment installer, configurer et superviser les messages INQ de QSYSOPR avec Manzan pour les envoyer par mail.
Qu’est ce que Manzan ?
Manzan est un observability stack* (codé en Java) permettant de faciliter la supervisation d’une plateforme IBMi en interceptant des messages systèmes puis en les envoyant sur un serveur qui s’occupe de les rédiriger vers les destinations configurées.
*C’est un ensemble d’outils qui permettent de comprendre en profondeur ce qui se passe dans un système informatique en collectant, stockant et analysant ses métriques, logs et événements.
Il permet entre autre de :
surveiller les messages système (QSYSOPR, QSYSMSG, QHST)
surveiller les jobs (MSGW, CPU, statut, durée…)
surveiller les sous‑systèmes
surveiller les queue spools
surveiller les ressources système (CPU, mémoire, disques)
et bien d’autres…
déclencher des alertes
exécuter des actions automatiques (commandes CL, programmes CL/RPG)
exposer les données à Grafana, Prometheus, InfluxDB, etc.
Installation de Manzan
Créer un répertoire « download » sur IBM i (Pour y mettre votre installeur)
Télécharger la dernière version du manzan-installer-v#.jar ou avec la commande ci dessous : wget https://github.com/ThePrez/Manzan/releases/download/v0.0.X/manzan-installer-v0.0.X.jar
Si vous ne l’avez pas fait directement, transférer le .jar vers IBM i
Lancez l’installeur avec : java -jar manzan-installer-v0.0.X.jar
Configurez vos fichiers .ini
(Vous aurez surement besoin de Service commander si vous ne l’avez pas déjà)
Fichiers de configuration:
Il en existe 3 :
app.ini pour la configuration générale de Manzan (rien à toucher généralement)
data.ini pour configurer les sources et les données à traiter
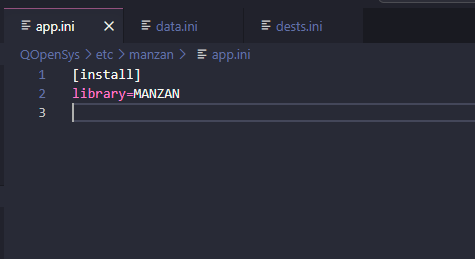
Vous n’aurez rien besoin de faire particulièrement sur celui ci à part les lignes ci dessous ci ce n’est pas déjà fait :
Vous indiquez ici la bibliothèque d’installation de Manzan
[install]
library=MANZAN
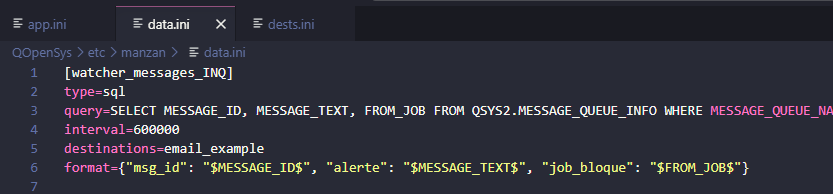
data.ini
Ce fichier contiendra toutes les sources que vous voudrez surveiller avec le choix du format
exemple de surveillance des messages INQ de la message queue QSYSOPR:
fichier data.ini :
[watcher_messages_INQ]
type=sql
query=SELECT MESSAGE_ID, MESSAGE_TEXT, FROM_JOB FROM QSYS2.MESSAGE_QUEUE_INFO WHERE MESSAGE_QUEUE_NAME = 'QSYSOPR' AND MESSAGE_TYPE = 'INQUIRY' AND ASSOCIATED_MESSAGE_KEY IS NULL
interval=600000
destinations=email_example
format={"msg_id": "$MESSAGE_ID$", "alerte": "$MESSAGE_TEXT$", "job_bloque": "$FROM_JOB$"}
[watcher_messages_INQ] : un id complètement arbitraire, vous pouvez le renommer comme bon vous semble
type : le type est sélectionné en fonction de la donnée à analyser. Au dessus par exemple on souhaite faire une requête pour récupérer les bonnes lignes à regarder c’est donc SQL.
query : requête SQL pour regarder les messages INQUIRY dans QSYSOPR
interval : l’interval (en ms) qui séparera chaque itération de votre requête (ici toutes les 10 minutes)
destinations : un lien vers votre fichier dests.ini dans lequel vous configurerez comment envoyer les données sélectionnées vers la/les sources que vous préciserez ici. Gardez aussi en mémoire qu’il peux y avoir plusieurs destinations séparées par des virugles.
format : Ce format de message sera son « corps ». Ce sera la façon dont vous verrez les données une fois transmises.
(à noter que toutes vos données doivent être bornées par des $)
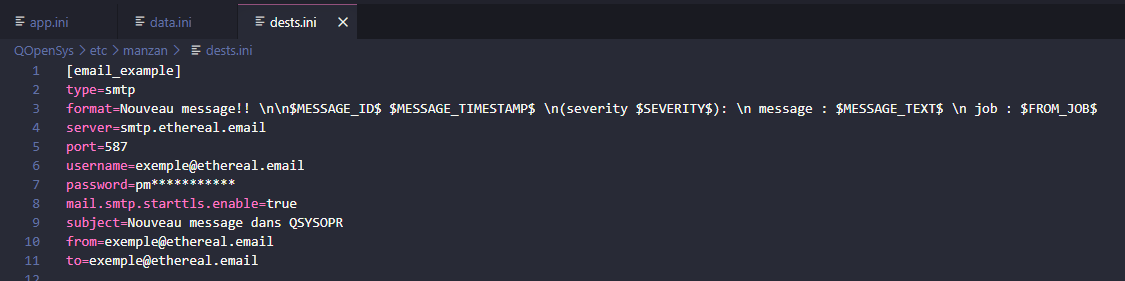
dests.ini
Ce fichier est composé de nombreuses sections qui définissent des destinations de données. Une destination est en fait un emplacement (comme un service) vers lequel les données peuvent être envoyées. Dans cet exemple j’utilise Ethereal Email qui permet d’avoir une boite mail jetable, utile pour les tests
type : même fonctionnement que dans data.ini mais cette fois ce sera la méthode d’envoi de données. Tous les types sont répertoriés ici : Types de destinations
format : même principe que dans data.ini sauf qu’ici, le format n’est pas à envoyer à destinations mais sera le format final que vous verrez, ce sera le formattage de votre « log » personnalisé (exemple en dessous)
serveur : explicitement le serveur vers lequel vous voulez envoyer votre message (ici Ethereal Email)
username : votre adresse mail
password : un identifiant propre à votre mail, vous est donnée directement à la connexion sur des services comme Ethereal Email, sinon à chercher dans vos paramètres de sécurité sur les domaine comme gmail ou hotmail.
port : port de sortie (pour envoyer) du service de mail choisi, en général ce sera toujours 587
mail.smtp.starttls.enable : sert à activer ou non le chiffrage de vos données sur le serveur
subject : l’objet du mail
from et to : respectivement l’email de l’envoyeur et du destinataire (peut être le même)
les paramètres changent en fonction de la destination, ils sont très explicites et bien documentés avec beaucoup d’exemples dans la documentation dans la catégorie des Destinations.
🚨Faites attention !
La QSYSOPR envoie beaucoup de messages qui ne sont pas INQUIRY donc pensez bien à faire la requête sur les messages INQ (comme dans les exemples ici). Sinon si vous utilisez votre boite mail, vous serez surement spam, c’est pourquoi dans cet exemple nous utilisons un email jetable en ligne.
Comment lancer Manzan ?
Il faut se mettre au bon endroit sur votre IFS, dans le répertoire où vous avez effectué l’installation de manzan en général. Soit vous y naviguez manuellement soit par VSCode vous avez cette option « Open Terminal Here » :
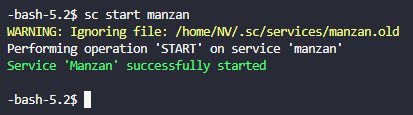
Ensuite une fois sur votre terminal vous taperez : sc start manzan
Vous devriez avoir ce message en vert s’afficher au bout de quelques secondes vous indiquant que c’est lancé.
(Mon Warning est dû au fait que j’ai gardé mon ancien .yaml en .old en tant que backup, vous ne devriez pas avoir ce message)
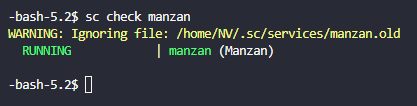
Pour être sûr que Manzan est lancé, tapez : sc check manzan et vous devriez voir cela :
Si vous avez des problèmes ou que le serveur vous fait des timeout regardez les .yaml
le premier se trouve dans ./.sc/services/manzan.yaml
le 2e se trouve dans /opt/manzan/bin/manzan.yaml
Pensez à déclarer vos variables d’environnements comme :
MANZAN_MESSAGING_PREFERENCE=SQLMANZAN_SOCKET_PORT=8888 (prenez un port qui n’est pas déjà pris) export LC_ALL=FR_FR.UTF-8 à mettre dans votre .profile
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-04-21 10:34:002026-05-05 11:31:22Premiers pas vers Manzan