https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-01-01 19:39:152023-01-03 09:47:09Informations sur les commandes
Lorsque l’on crée un programme de service il est intéressant de classer les procédures utilisées dans différents modules afin de faciliter une maintenance future. On peut regrouper par exemple les procédures par fonctionnalité métier (prise de commandes, rangement, calculs de taux,… ) ou par proximité technique (manipulation de chaines de caractères, calcul d’un modulo, manipulation de dates,… ). Dans l’article intitulé « CONTROLER IBAN & RIB » on regroupe les deux fonctions bancaires au sein d’une même procédure.
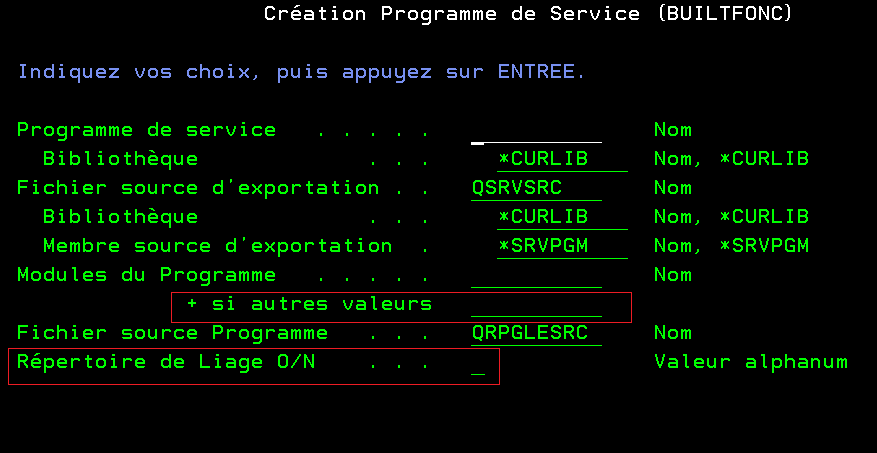
Lorsque l’on veut créer un programme de service il faut procéder en deux temps :
Créer les modules contenant les procédures et fonctions
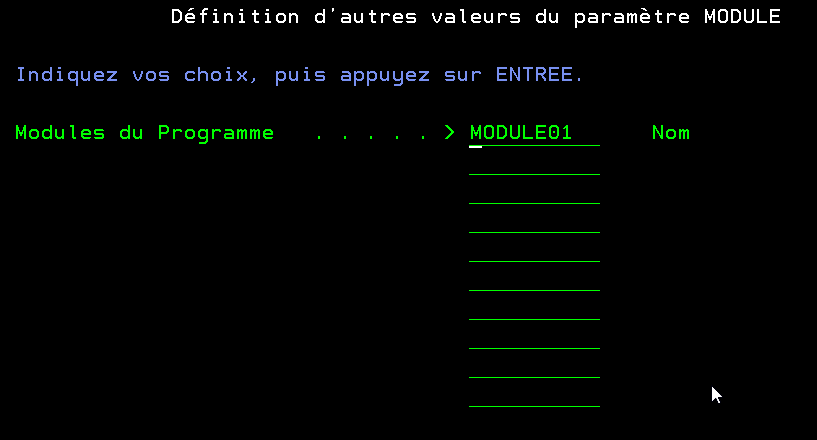
Nous vous proposons donc de créer une fonction qui permettra d’enchainer ces deux opérations (nous nous limiterons à la possibilité d’agréger 10 modules dans un programme de service)
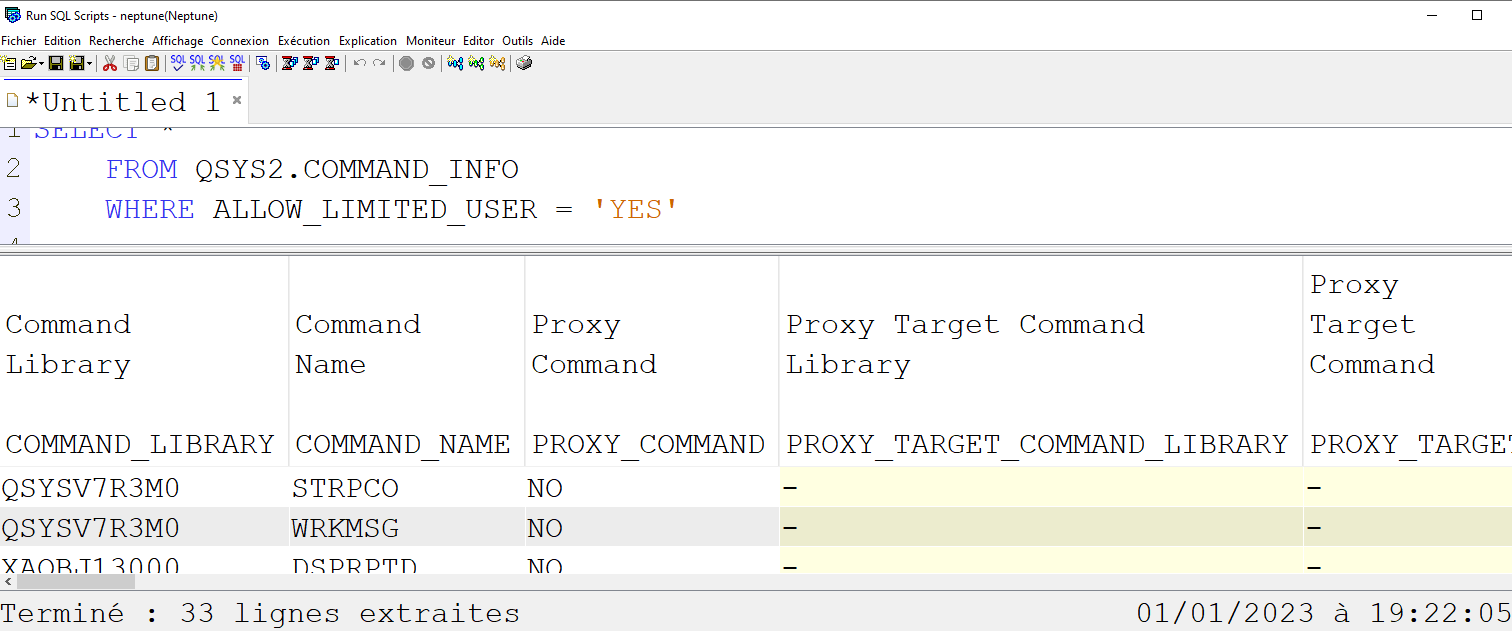
Présentation de la commande
Cette commande permet de saisir plusieurs modules et de les intégrer directement dans un programme de service
On peut également ajouter un répertoire de liage, si besoin
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2022-12-06 09:53:472022-12-06 11:15:48Création de programmes de service
Vous connaissez tous les notions de cette bibliothèque :
Elle n’est pas sauvegardée à la fin d’un travail et chaque travail a sa QTEMP.
Elle est généralement dans votre liste de bibliothèque.
Maintenant imaginez que vous utilisez un logiciel et que vous voulez être sûr que QTEMP soit la première bibliothèque de votre liste :
Vous pouvez l’enlever et la remettre en entête mais attention, l’enlever revient à la supprimer. Si vous avez des données par exemple des fichiers à l’intérieur, ils seront donc perdus, je propose donc un petit programme qui pourra réaliser ça pour vous :
PGM
/* MISE EN PLACE QTEMP EN TETE DE LISTE */
dcl &time *char 6
DCL VAR(&NBR) TYPE(*DEC) LEN(10)
dcl &libl *char 2750
dcl &req *char 512
/* Recherche si QTEMP est entete on ne fait rien */
RTVJOBA USRLIBL(&LIBL)
IF COND(%sst(&libl 1 10) = 'QTEMP') THEN(DO)
goto fin
ENDDO
/* Recherche si QTEMP est pas en tete de liste */
ELSE
DSPOBJD OBJ(QTEMP/*ALL) OBJTYPE(*ALL) +
OUTPUT(*OUTFILE) OUTFILE(QTEMP/WRESULT)
MONMSG MSGID(CPF2123) exec(do)
/* si bibliothèque vide */
RMVLIBLE LIB(QTEMP)
ADDLIBLE LIB(QTEMP) POSITION(*FIRST)
GOTO CMDLBL(FIN)
ENDDO
/* Si bibliothèque QTEMP remplie */
CRTLIB LIB('W' *TCAT &TIME) TYPE(*TEST) TEXT('Bib +
sauvegarde qtemp')
monmsg CPF2111 exec(do)
CLRLIB LIB('W' *TCAT &TIME)
ENDDO
CRTDUPOBJ OBJ(*ALL) FROMLIB(QTEMP) OBJTYPE(*FILE) +
TOLIB('W' *TCAT &TIME) DATA(*YES)
monmsg CPF2130
rmvlible qtemp
addlible qtemp *first
CRTDUPOBJ OBJ(*ALL) FROMLIB('W' *TCAT &TIME) +
OBJTYPE(*FILE) TOLIB(QTEMP) DATA(*YES)
monmsg CPF2130
DLTLIB LIB('W' *TCAT &TIME)
/* fin du programme */
fin:
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA('Bibliothèque Qtemp placée en tête +
de liste') MSGTYPE(*COMP)
ENDPGM
Voila, vous avez une exemple tout en CLP , qui permet de mettre QTEMP en tête de liste sans perdre les informations à l’intérieur.
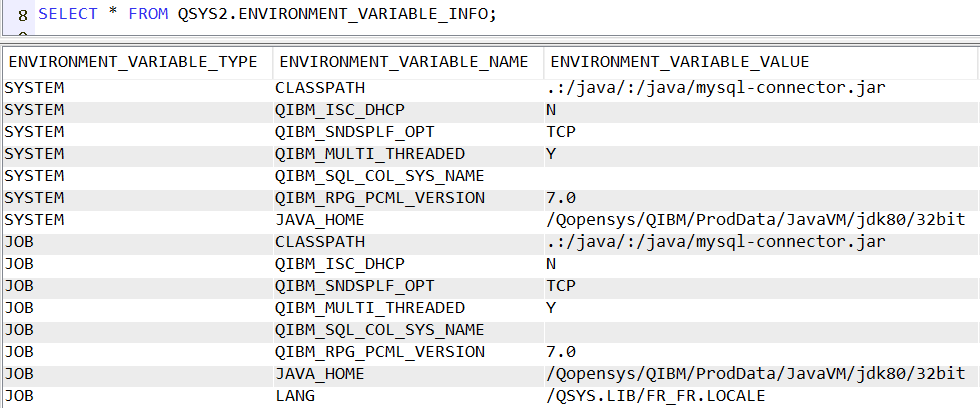
Nous utilisons de plus en plus les services SQL pour de nombreuses actions : accès aux *DTAQ, *DTAARA, travaux etc …
Par exemple, pour accéder au contenu d’une variable d’environnement, la vue QSYS2.ENVIRONMENT_VARIABLE_INFO est très simple à utiliser :
Dans un programme RPG, il est très simple d’effectuer une lecture SQL.
Mais dans certains cas, nous préférerons utiliser les APIs système : pour la performance, ou dans le CL ! En CL, il est possible d’exécuter une instruction SQL, mais pas de récupérer un result sets (en tout cas pas simplement et avec une bonne performance).
L’appel d’API depuis le CL ne pose pas de soucis, principalement depuis les évolutions permettant de maitriser l’allocation mémoire des variables (variables autonomes, basées sur un pointeur, ou basée sur une autre variable – équivalent OVERLAY du RPG) :
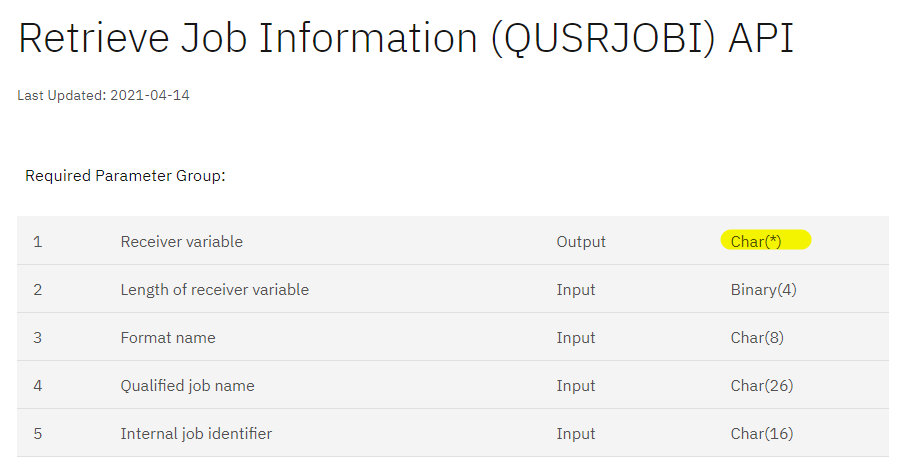
Maintenant, lorsque l’on utilise des API, il est (souvent) nécessaire de passer par des pointeurs, de façon explicite ou non. Par exemple, c’est le cas pour QUSRJOBI même si l’on a pas déclaré de pointeur dans notre programme CL :
En réalité, lors d’un appel de programme ou procédure, les paramètres sont transmis par défaut par référence : concrètement on passe un pointeur sur le début de la valeur, mais pas la valeur elle-même !
Il faut commencer à interpréter les prototypes des API en fonction du langage d’appel …
Le système étant écrit en C, certaines API utilisent la définition C d’une chaine de caractères : un pointeur sur le premier caractère, la fin de la chaîne étant marquée par le premier octet null !
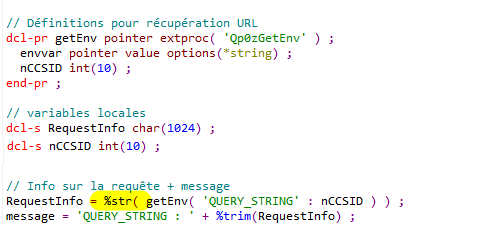
En RPG, nous avons la fonction %str() qui permet de gérer ceci :
En CL, pas de fonction équivalent pour gérer cela.
Prenons par exemple l’API getEnv() (en fait une fonction de la bibliothèque standard C) :
Il faut fournir en entrée le nom de la variable d’environnement, au format C String, c’est à dire à terminaison nulle.
De même, la valeur de retour est un pointeur sur le début de la valeur. La fin se situe au premier octet null rencontré …
Voici un exemple d’appel :
Nous déclarons simplement une variable de type CHAR(1) initialisée à x’00’ :
Cela nous sert à créer la valeur pour l’appel : chaine à terminaison nulle contenant le nom de la variable d’environnement recherchée (ici CLASSPATH) :
CHGVAR &ENVVAR ( 'CLASSPATH' *CAT &SPC_INIT )
Pour décoder la valeur de retour, il nous faut parcourir la valeur reçue jusqu’à trouver la terminaison nulle. On utilise simplement %SCAN pour trouver la position et redécouper :
Au final, très peu de code à ajouter, mais nécessite une compréhension de la documentation des APIs, des types de données dans les différents langages, et des mécanismes de transmission de paramètres !
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2022-11-07 16:52:172025-02-17 14:46:56Réinitialisation des tableaux en free form
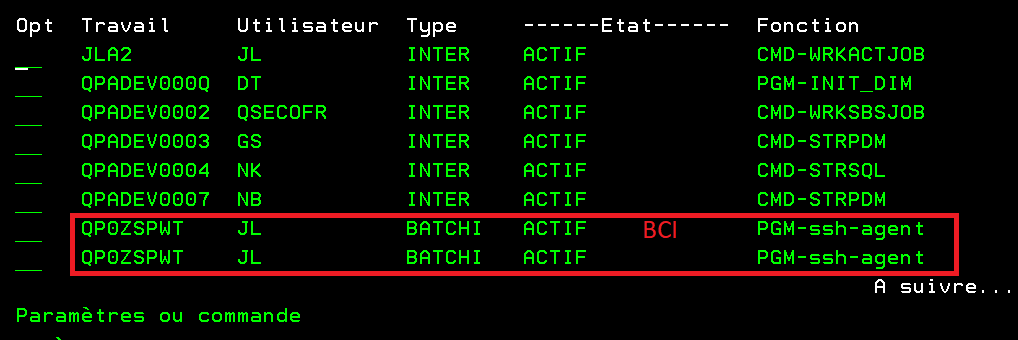
Si vous commencez à faire du SSH (en tant que client), par exemple pour faire du GitHub, vous avez des jobs qui vont rester et que vous devrez tuer par un kill ou un ENDJOB.
C’est des jobs BCI qui restent après avoir arrêté vos JOBs interactifs.
Voici un petit script CLP qui permet de faire ça, il vous suffit de le planifier tous les soirs à 23 heures par exemples.
Ici on a utiliser la fonction table QSYS2.ACTIVE_JOB_INFO et la fonction QSYS2.QCMDEXC et on packagé le tout dans un CLP …
PGM
/* Suppression des jobs SSH dans QINTER */
dcl &NBRCURRCD *dec 10
/* Exécution de la requete SQL */
RUNSQL SQL('Create table qtemp/sortie as(SELECT +
QSYS2.QCMDEXC(''ENDJOB '' CONCAT +
JOB_NAME) as resultat FROM +
TABLE(QSYS2.ACTIVE_JOB_INFO(SUBSYSTEM_LIST_+
FILTER => ''QINTER'')) X where job_type +
= ''BCI'') with data') COMMIT(*NONE)
MONMSG MSGID(SQL0000) exec(do)
SNDUSRMSG MSG('Erreur dans l''exécution de la requête +
SQL d''épuration des jobs SSH') +
MSGTYPE(*INFO)
Return
enddo
/* Envoi d'un message de fin */
RTVMBRD FILE(QTEMP/SORTIE) NBRCURRCD(&NBRCURRCD)
if cond(&NBRCURRCD > 0) then(do)
SNDUSRMSG MSG(%CHAR(&NBRCURRCD) *TCAT ', job(s) SSH +
arrêté(s)') MSGTYPE(*INFO)
enddo
else do
SNDUSRMSG MSG('Pas de Job SSH à Supprimer ') +
MSGTYPE(*INFO)
enddo
ENDPGM
Sur les job de ssh-agent vous pouvez demander le kill directement comme ceci, merci à Julien …
La commande QSH lancer par votre CL qui vous permet de soumettre se présente donc comme ça :
eval "$(ssh-agent -s)" ; // Démarrage de l'agent
SSH ssh-add /home/jl/.ssh/github ; // Ajout de la clé à l'agent
ssh -T git@github.com ; // Test de connexion à GitHub
ssh-agent -k // Arrêter l'agent
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-11-04 17:07:312022-11-06 09:30:49Tuez les jobs SSH dans QINTER
Vous connaissez tous, au moins de nom l’extension « code for i » qui vous permet d’éditer vos sources RPGLE dans votre éditeur favori qui est publié par notre Ami Liam Allan
Si voulez en savoir plus une vidéo très bien faite de notre ami de Yvon est disponible sur la chaine youtube de Volubis ici
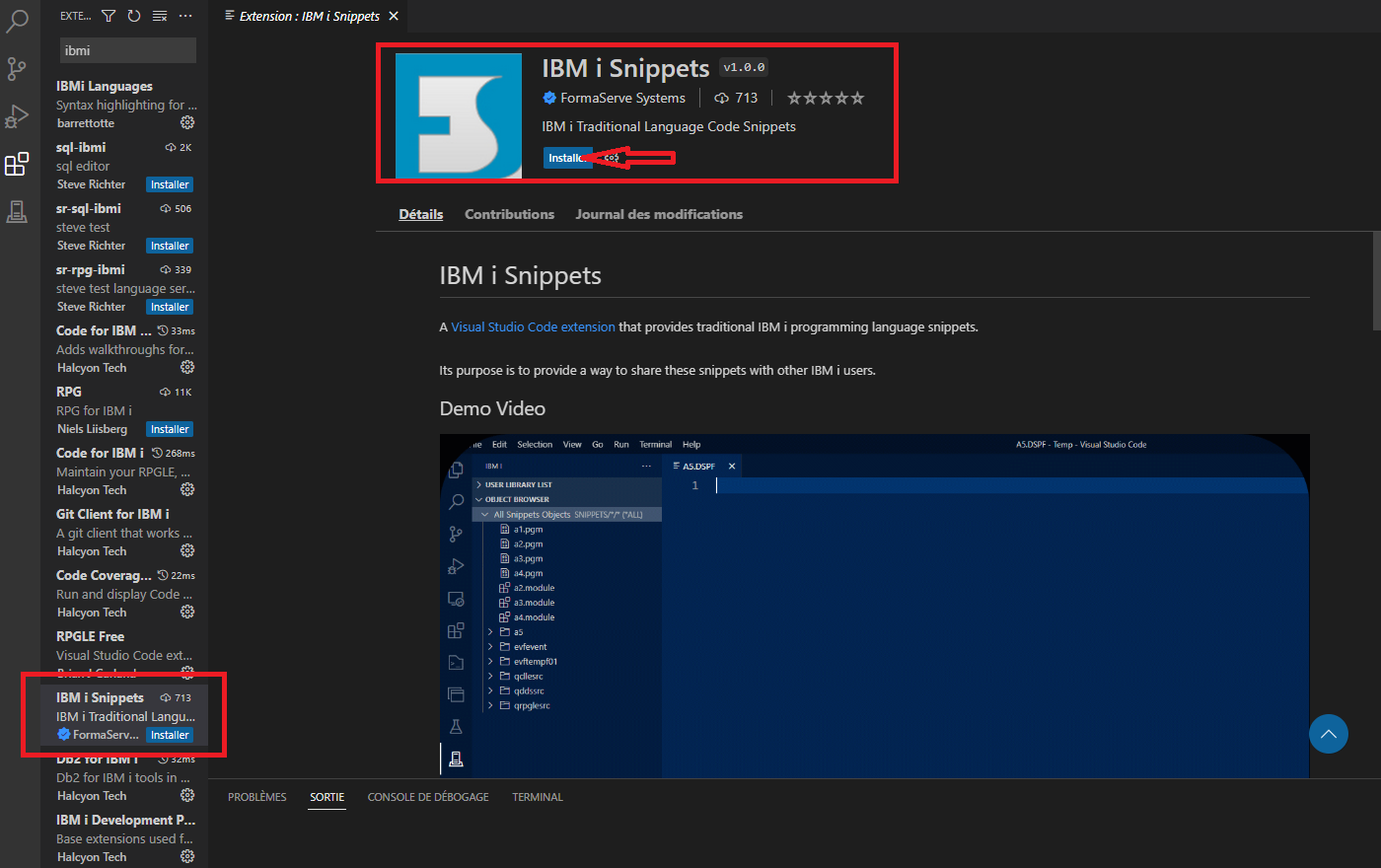
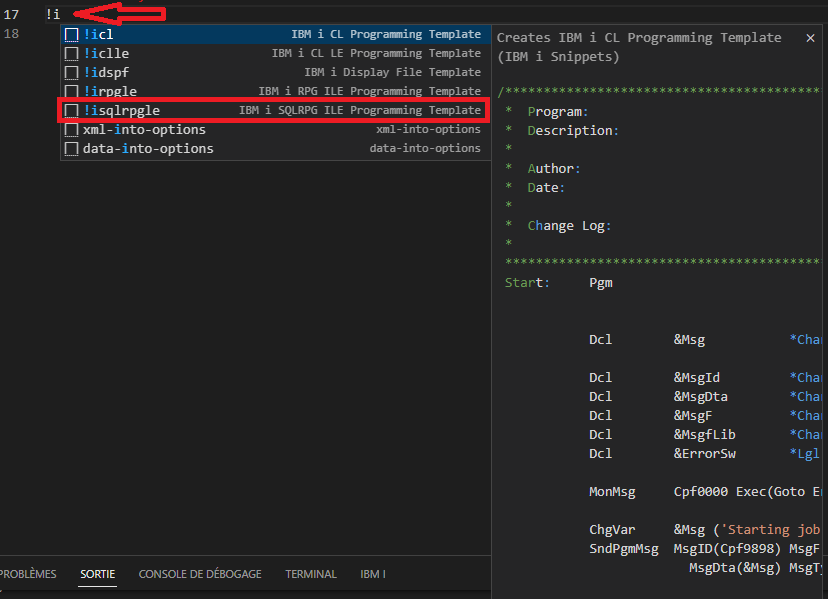
Mais il existe également des extensions créé par d’autres contributeurs en voici une qui est apparu en 2022 « IBM i Snippets », elle a été créée par Andy Youens.
L’installation est très simple à partir de la gestion des extensions
Le principe de cette extension est de vous proposer des exemples de codes (par exemple des squelettes pour du RPGLE ou CLLE).
Son usage est très simple vous devez saisir « !i » dans votre éditeur favori .
Cette extension bouge beaucoup depuis sa sortie et les dernières contributions sont récentes, n’hésitez pas à proposer des exemples de codes si vous en avez qui soit présentable
Nous pensons qu’il y aura de plus en plus de extensions disponibles pour l’IBMI et une amélioration de celle exitantes extensions existantes, il est donc important d’avoir un œil ce mode de développement , en sachant que les « JEUNNNNES » connaissent déjà cet interface
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-11-01 09:31:152022-11-01 09:31:16Visual studio code IBM i Snippets
/wp-content/uploads/2017/05/logogaia.png00Habib Saad/wp-content/uploads/2017/05/logogaia.pngHabib Saad2022-10-13 12:45:402022-10-14 16:52:34Obtenir la définition de son écran
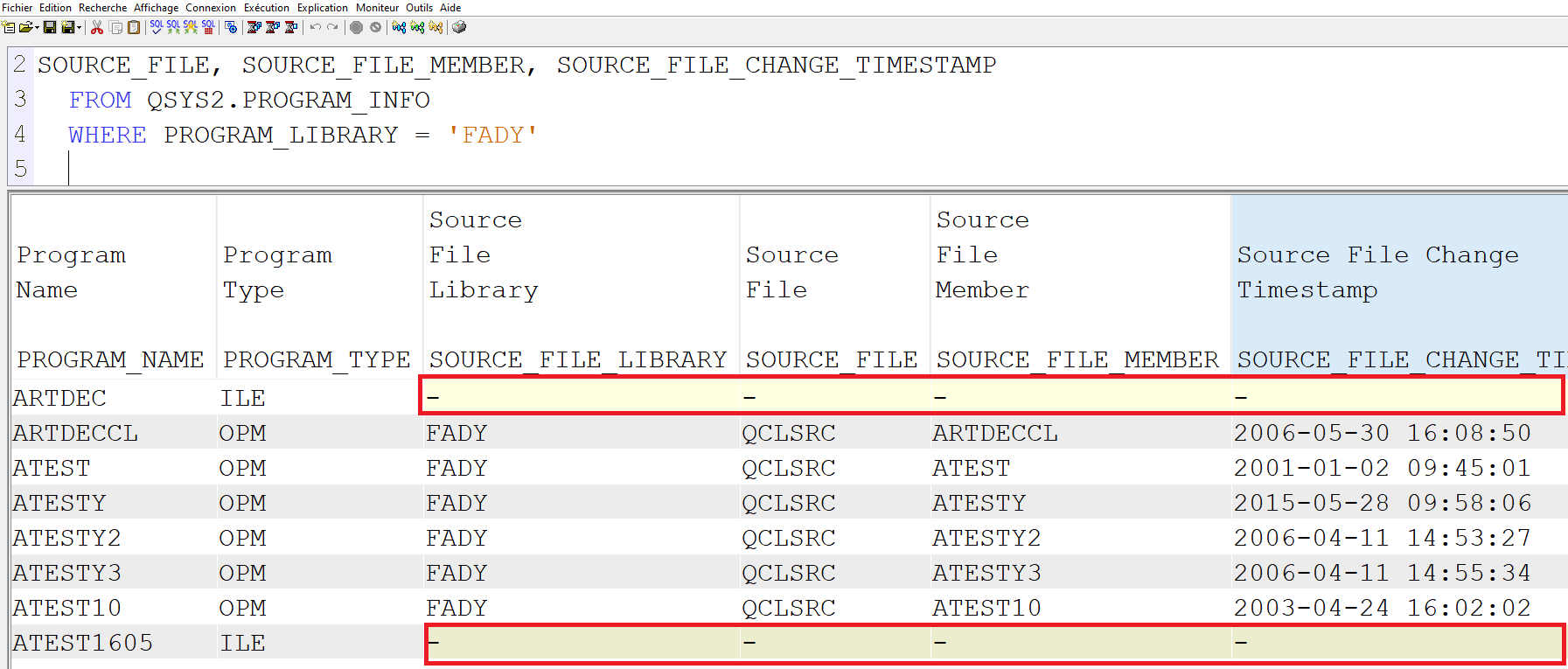
On est amené quand on fait des analyses à regarder les dates de source, on constate que ces dates sont à null pour tous les objets de type ILE.
Vous avez une vue QSYS2.PROGRAM_INFO qui permet d’avoir ces informations sur les programmes, un peu comme la commande DSPPGM.
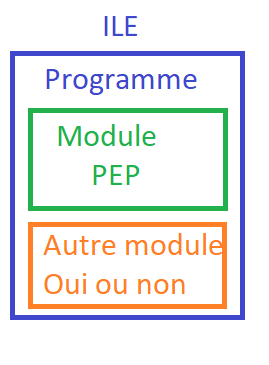
Voici pourquoi : quand vous travaillez en OPM vous compilez des sources qui deviennent des programmes; quand vous travaillez en ILE, vous compilez des sources qui deviennent des modules, puis vous les assemblez pour créer des programmes et du coup une date de source sur un programme ILE ne veut rien dire.
En réalité un programme a un module qui s’appelle point d’entrée programme qui, quand on travaille en BND (CRTBND*), est le seul module placé dans qtemp qui est assemblé pour créer votre programme.
On voit donc que si on veut, on peut assimiler la date du source du programme à la date du module PEP, qui dans plus de 99 % des cas a le même nom que le programme. On a une deuxième vue permet d’avoir les modules par programme, QSYS2.BOUND_MODULE_INFO.
Il faudra donc combiner les 2 vues.
par exemple :
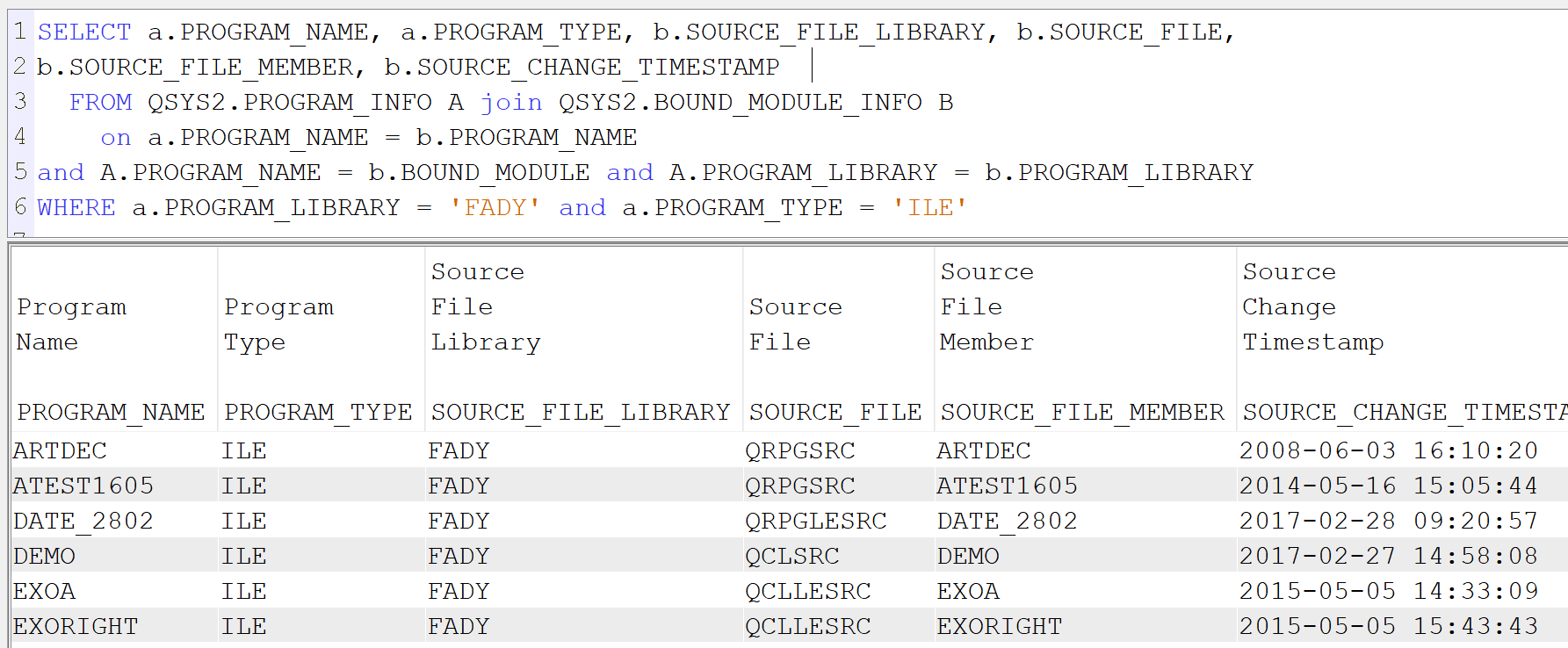
Pour les programmes ILE
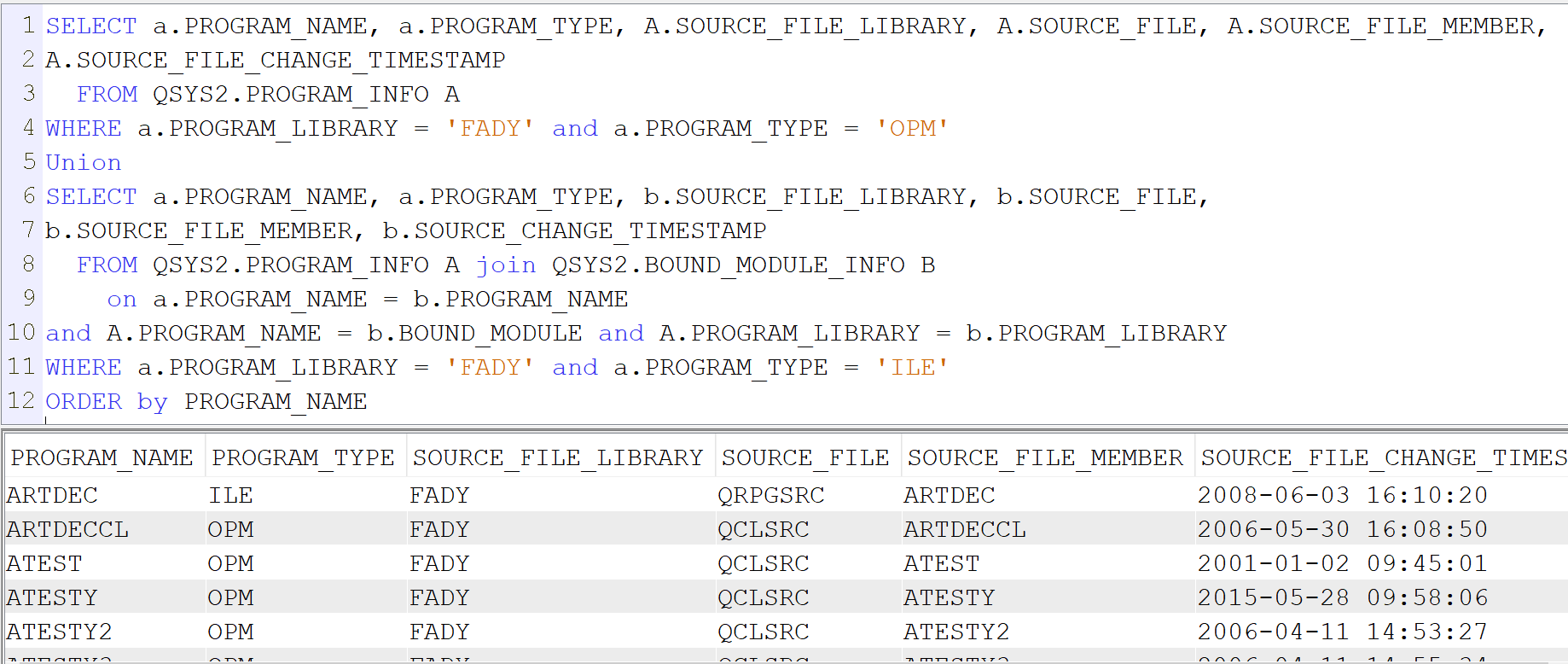
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, b.SOURCE_FILE_LIBRARY, b.SOURCE_FILE, b.SOURCE_FILE_MEMBER, b.SOURCE_CHANGE_TIMESTAMP FROM QSYS2.PROGRAM_INFO A join QSYS2.BOUND_MODULE_INFO B on a.PROGRAM_NAME = b.PROGRAM_NAME and A.PROGRAM_NAME = b.BOUND_MODULE and A.PROGRAM_LIBRARY = b.PROGRAM_LIBRARY WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘ILE’
Pour les programmes OPM
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, A.SOURCE_FILE_LIBRARY, A.SOURCE_FILE, A.SOURCE_FILE_MEMBER, A.SOURCE_FILE_CHANGE_TIMESTAMP FROM QSYS2.PROGRAM_INFO A WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘OPM’
en faisant l’union des deux requêtes vous aurez les dates de tous vos programmes ILE et OPM.
Il y a sans doute d’autres solutions mais celle-ci est très simple à utiliser.
https://www.gaia.fr/wp-content/uploads/2022/08/IMG-20200712-WA0017.jpg1024768admin/wp-content/uploads/2017/05/logogaia.pngadmin2022-10-11 10:28:032022-10-14 10:15:33Date source de vos programmes
Développement, RDIRDi : configurer et déployer les Actions de l’utilisateur
Les actions utilisateur vous permettent d’exécuter des commandes préformatées sur les objets ou sur les membres de vos filtres, en utilisant le clic droit pour exécuter l’action.
Elles sont équivalentes aux options définies par l’utilisateur que l’on peut gérer par F16 sous PDM.
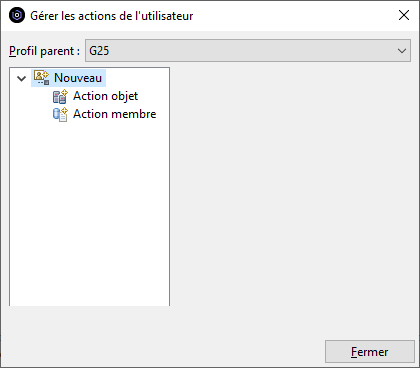
Gérer les actions de l’utilisateur
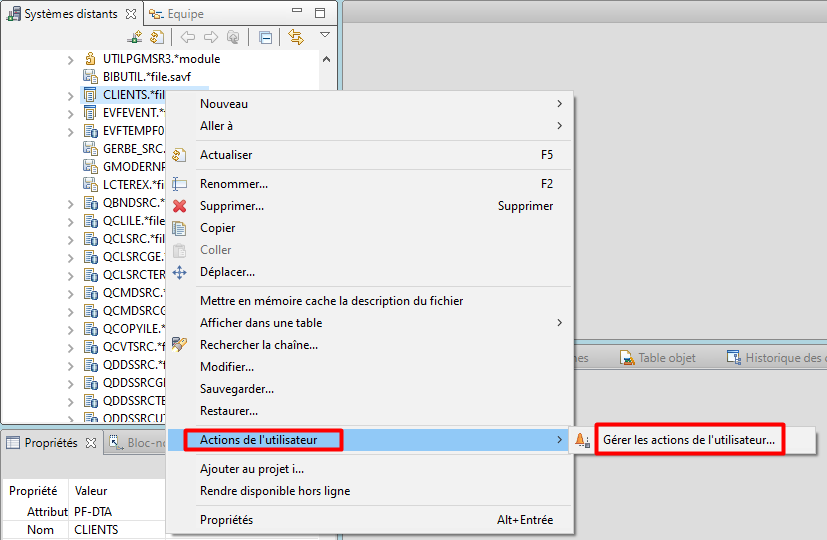
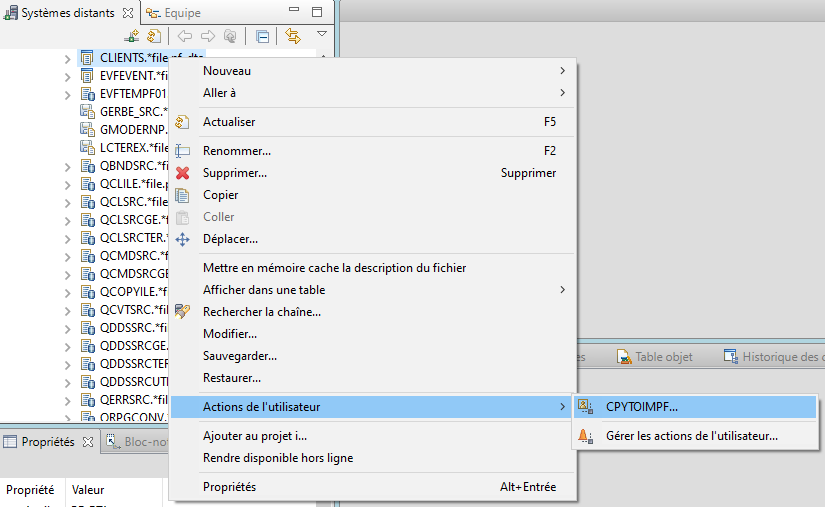
La gestion des actions utilisateur est accessible par clic droit sur les objets ou membres des filtres.
Créer une action objet
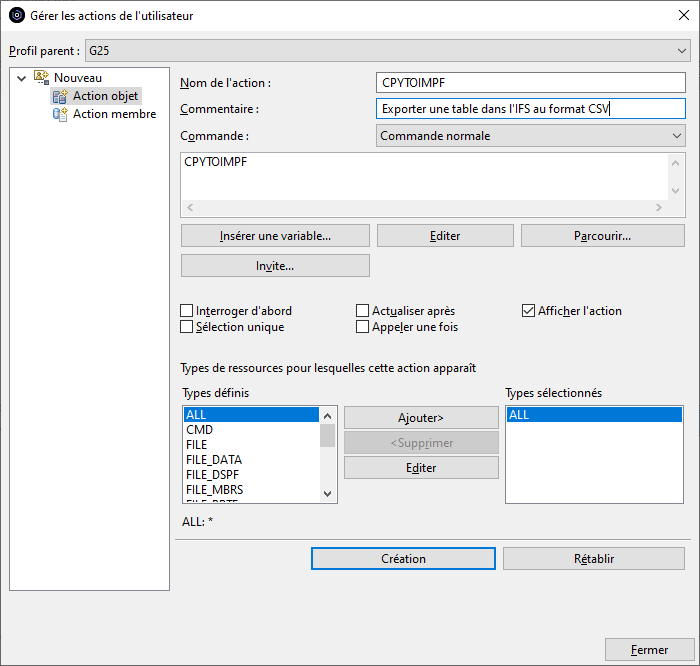
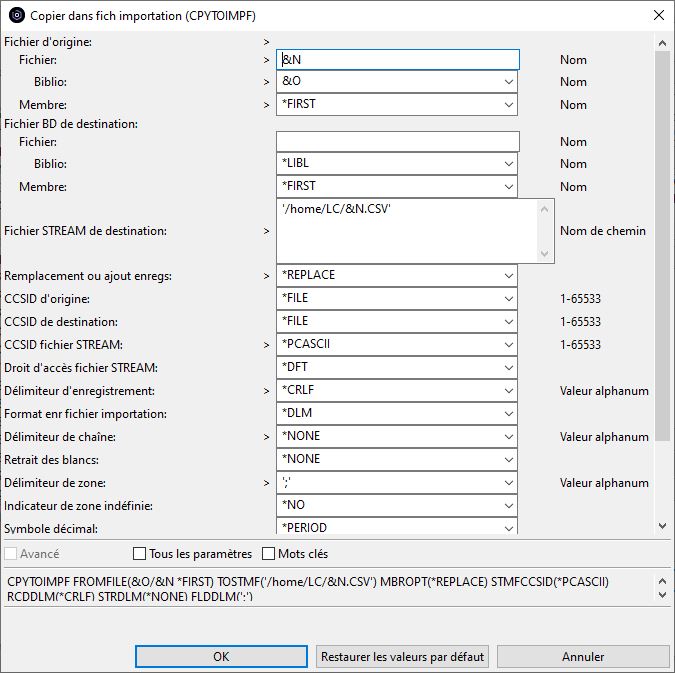
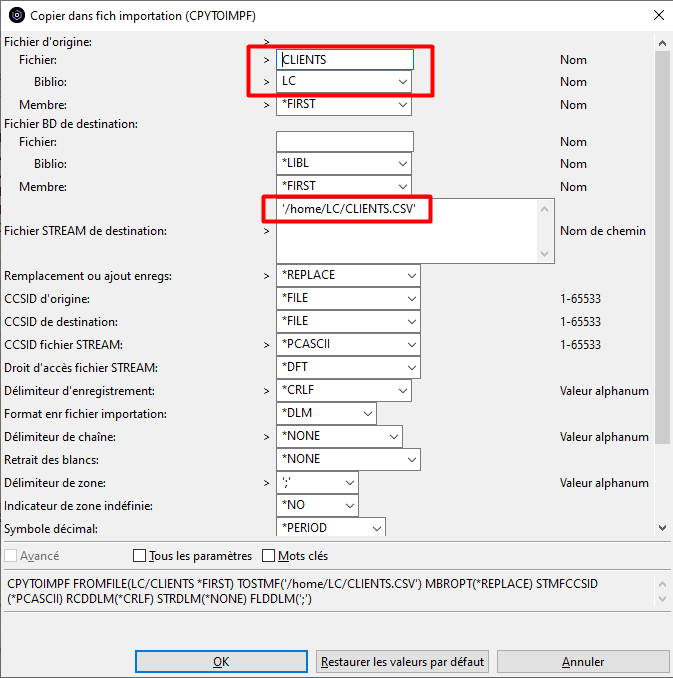
Nous allons créer une action pour exporter une table vers l’IFS au format CSV.
L’action utilisera la commande CPYTOIMPF que nous allons préformater.
Le bouton « Insérer une variable » affiche la liste des variables que nous allons pouvoir utiliser dans les paramètres de la commande pour substituer les attributs de l’objet sur lequel l’action s’exécute :
Le bouton « Invite » permet d’afficher l’invite de commande pour compléter les paramètres :
La case « Interroger d’abord » permettra d’afficher l’invite de commande lors de l’utilisation de l’action.
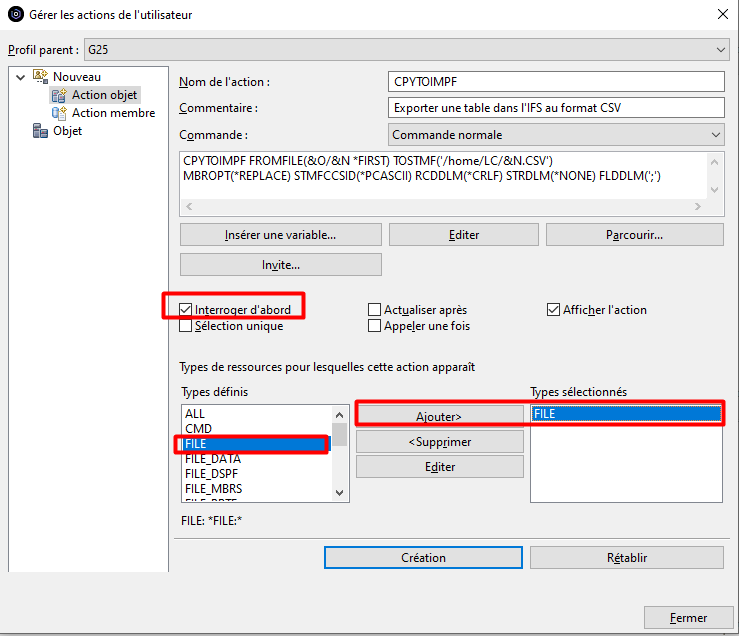
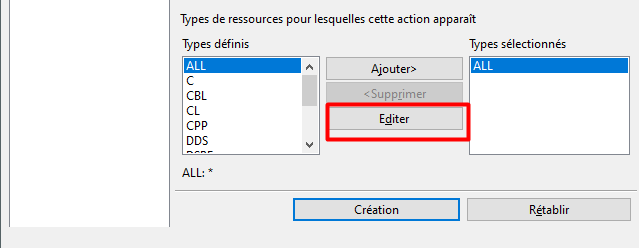
Enfin, il est conseillé d’indiquer les types de ressources pour lesquelles cette action sera proposée dans le clic droit :
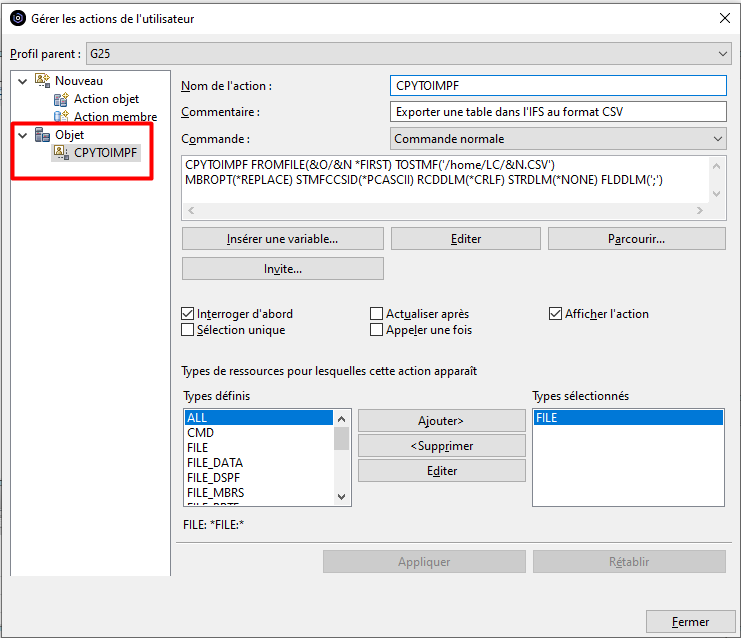
Une fois créée, l’action apparait dans le catalogue des actions Objet :
Elle peut être utilisée par clic droit sur un objet de type fichier :
L’invite de commande est affichée avec les valeurs de substitution des variables utilisées :
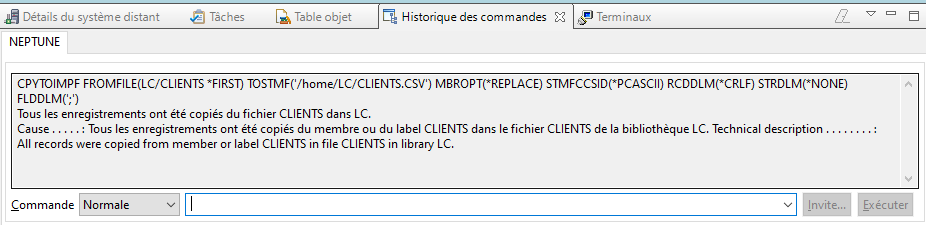
Le message d’exécution de l’action s’affiche dans l’historique des commandes de RDI :
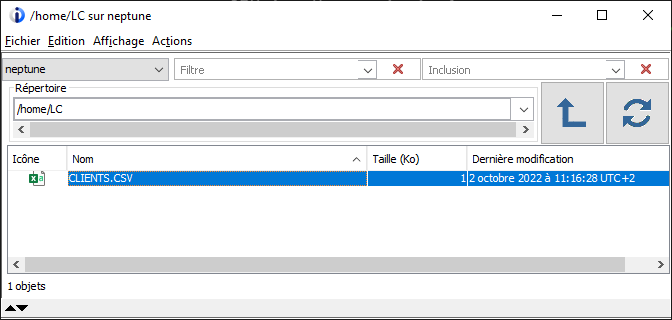
Le fichier CSV est créé dans l’IFS :
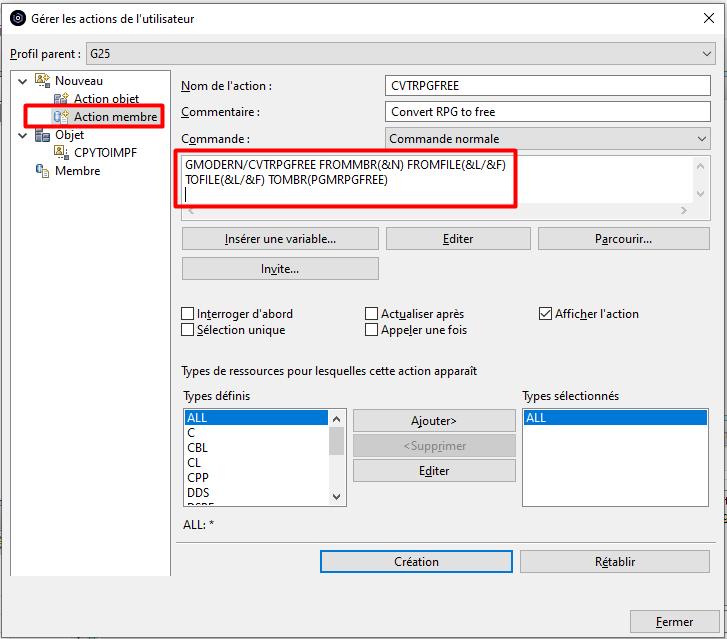
Créer une action membre
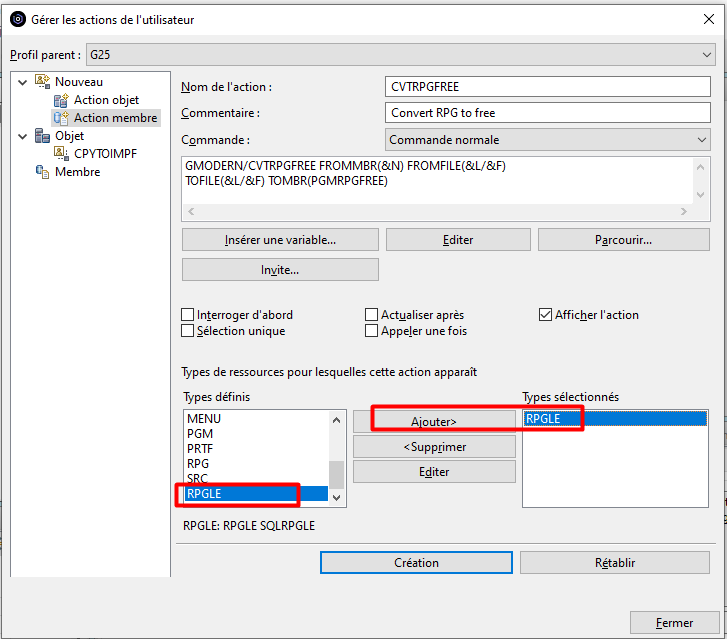
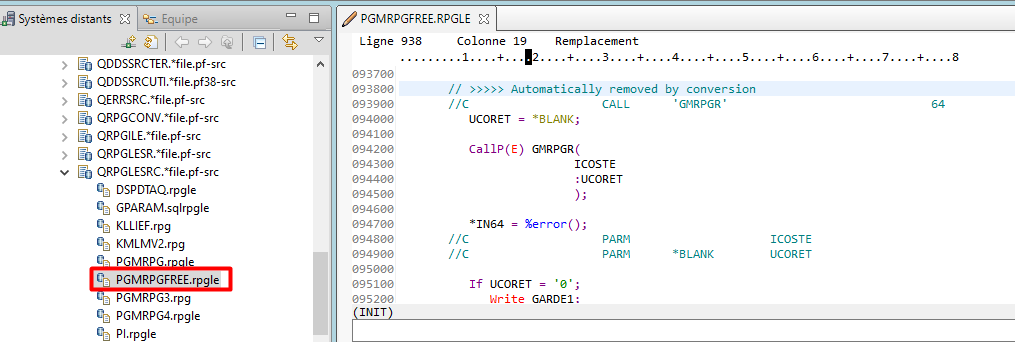
Nous allons créer une action permettant de convertir un membre source RPG 4 en RPG FREE.
Pour cela, nous avons créé une commande CVTRPGFREE basée sur un convertisseur Open Source auquel GAIA contribue.
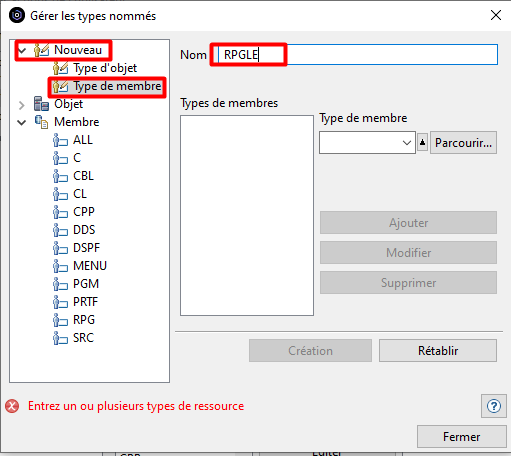
Pour limiter l’action au membres sources de type RPGLE et SQLRPGLE, nous allons Editer la liste des Types définis et créer un Type défini que nous nommerons RPGLE et qui rassemblera les types de membre RPGLE et SQLRPGLE :
Le fenêtre « Gérer les types nommés » s’ouvre :
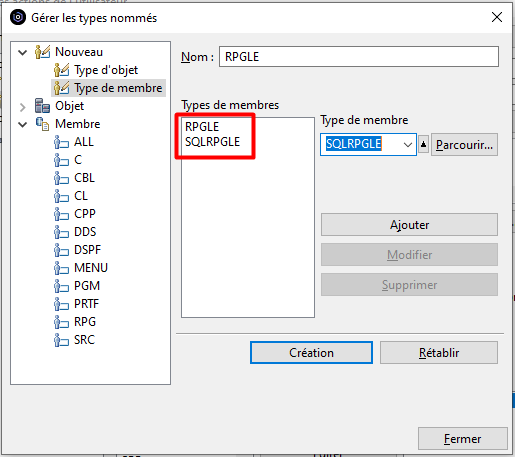
Le bouton « Parcourir » permet de choisir les types de membre existants pour les ajouter à la liste :
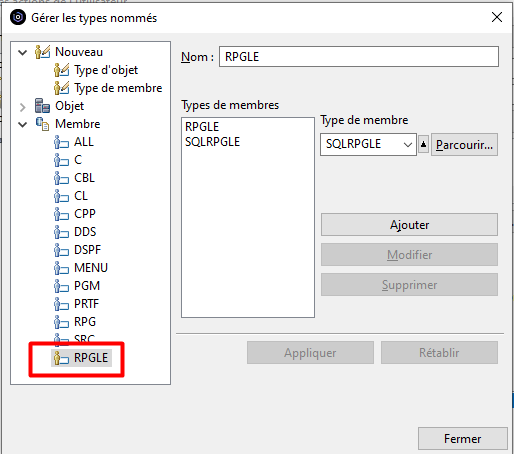
Le nouveau Type défini « RPGLE » s’affiche dans la liste des types de membres définis :On peut maintenant l’utiliser pour notre action :
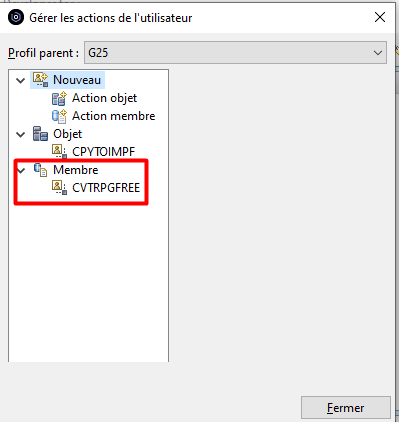
Une fois créée, l’action apparait dans le catalogue des actions Membre :
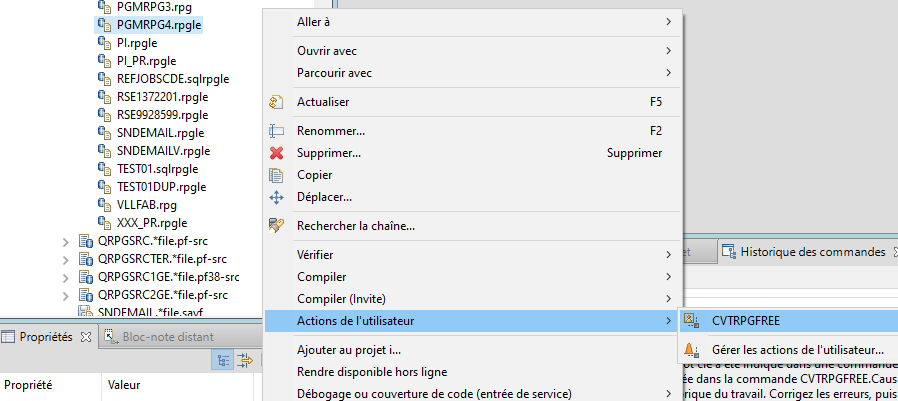
Elle peut être utilisée par clic droit sur un membre de type RPGLE ou SQLRPGLE pour le convertir en RPG FREE :
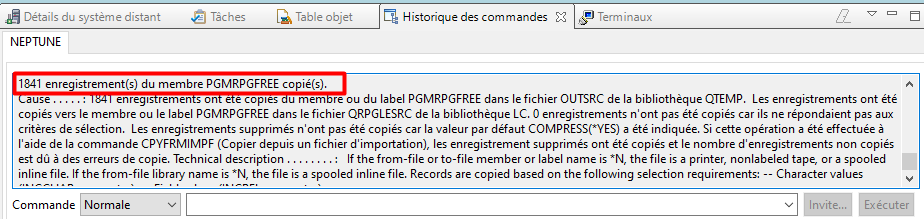
Le message d’exécution de l’action s’affiche dans l’historique des commandes de RDI :Le membre PGMRPGFREE a été créé avec la conversion en RPG FREE du membre initial PGMRPG4 :
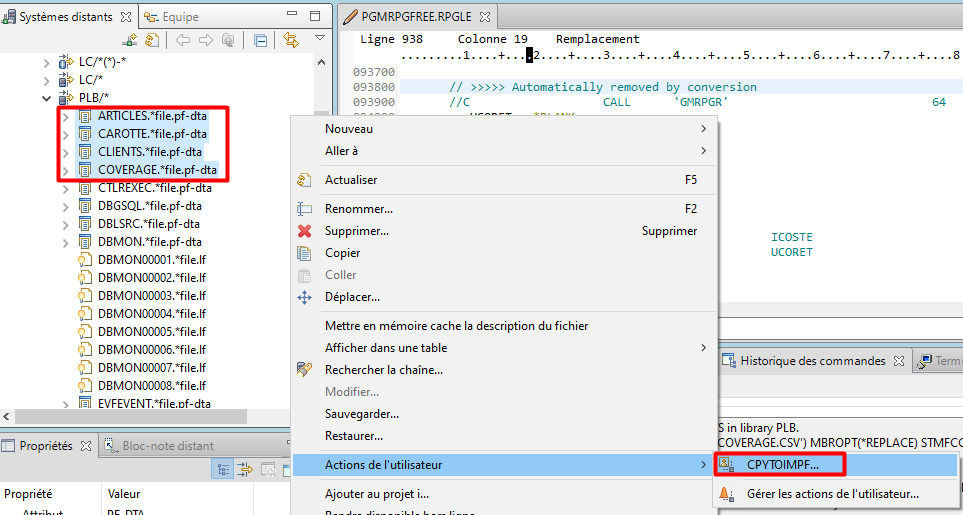
Notons qu’en effectuant une sélection de plusieurs ressources dans un filtre, on peut exécuter une action utilisateur sur toutes ces ressources par un seul clic droit.
Exemple ci-dessous : on peut exporter 4 fichiers vers l’IFS au format CSV en un seul clic
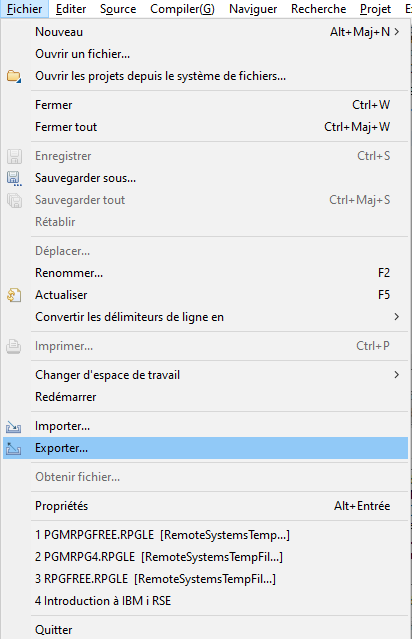
Exporter/Importer les actions utilisateur
Les actions utilisateur peuvent être exportées vers un fichier de configuration à partir du menu
Fichier > Exporter > Rational Developer for i :
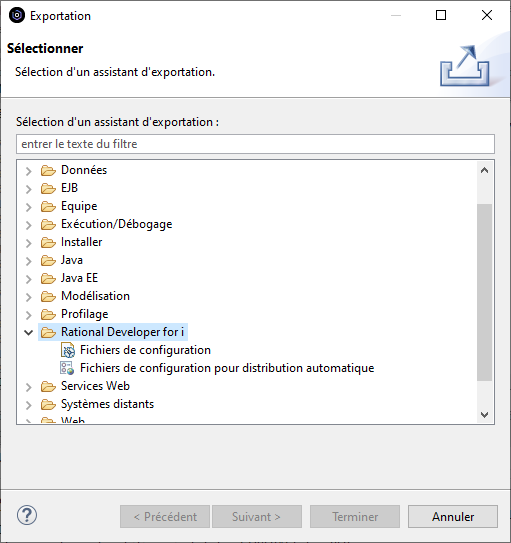
2 modes d’exportation sont possibles :
l’export « Fichier de configuration » permet d’exporter la configuration vers un fichier local, qui pourra si on le souhaite être partagé et importé par d’autres utilisateurs vers leur Workspace.
l’export « Fichier de configuration pour distribution automatique » permet d’exporter la configuration pour la distribuer automatiquement aux autres utilisateurs
Exporter Fichier de configuration pour distribution automatique
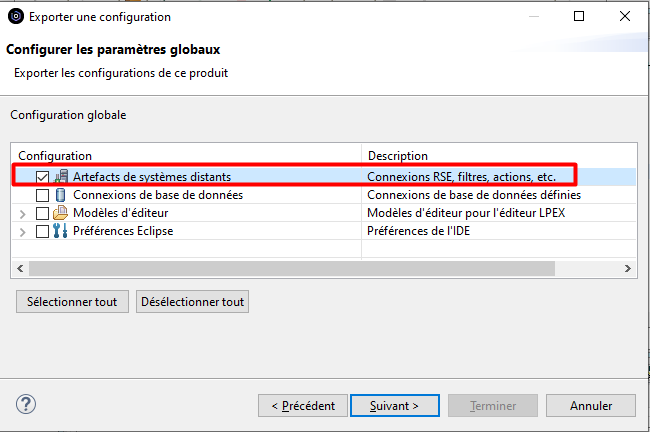
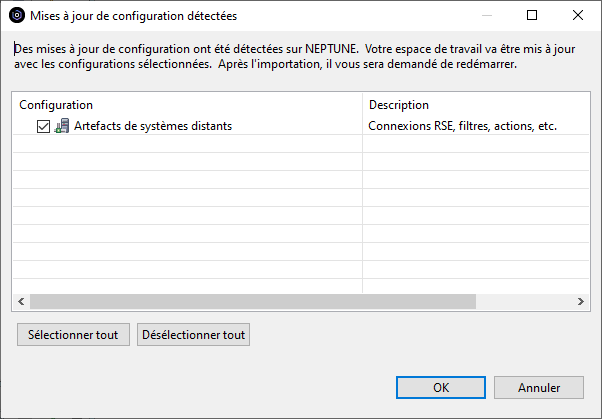
Pour exporter les actions utilisateur, décocher toutes les cases et ne conservez que la configuration « Artefacts de systèmes distants ».
Les filtres sont exportés, lors de l’import vous perdrez donc les filtres de votre Workspace.
Ca peut être gênant, mais ça peut aussi être l’occasion de faire du ménage dans vos filtres….
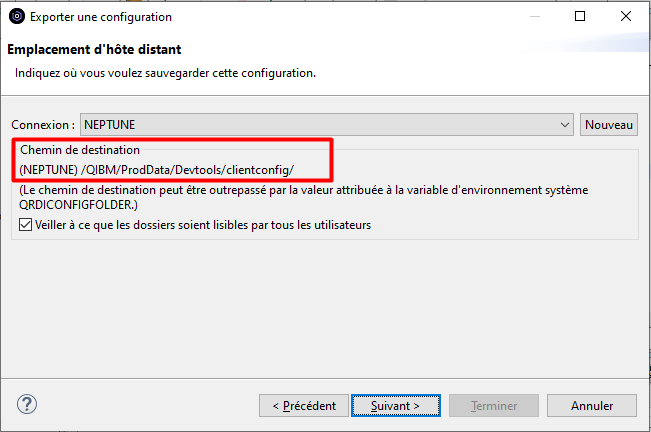
Le fichier de configuration sera généré dans le répertoire suivant de l’IFS :
/QIBM/ProdData/Devtools/clientconfig
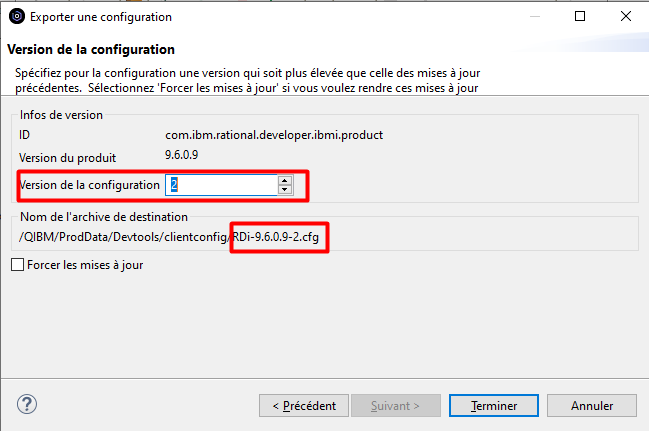
Choisissez un numéro de version pour identifier le fichier de configuration :
Avant de Terminer, assurez-vous d’avoir les droits d’écriture dans le répertoire de destination.
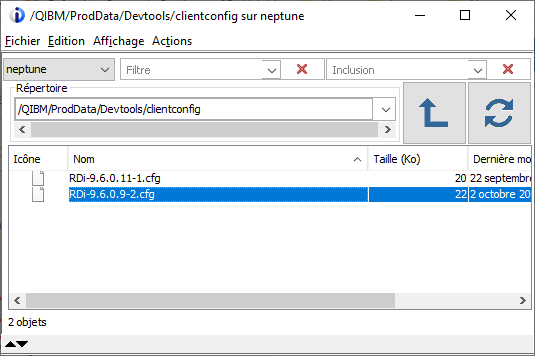
Le fichier de configuration est généré dans l’IFS pour une distribution automatique de cette configuration :
Lorsque les utilisateurs se connecteront à l’IBM i, une fenêtre d’importation leur sera automatiquement proposée :
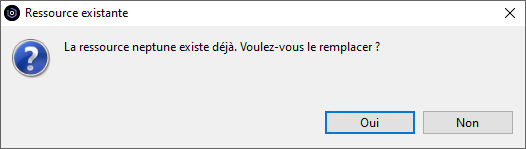
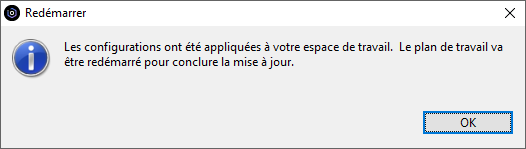
L’import peut être accepté (OK) ou pas (Annuler) mais tant qu’il n’aura pas été accepté, il sera reproposé à chaque connexion à l’IBM i par RDI.
C’est terminé !
PS :
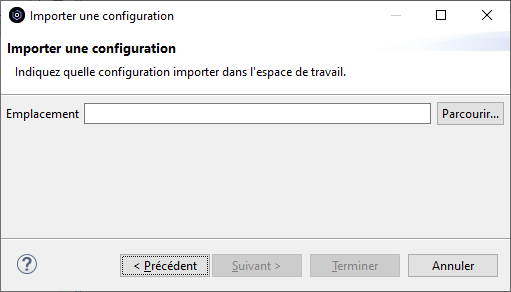
Si le fichier de configuration a été exporté vers un fichier local par l’export Fichier de configuration au lieu de Fichier de configuration pour distribution automatique, il peut être importé de la même manière par le menu Fichier > Importation > Rational Developer for i > Fichiers de configuration. Il suffit d’indiquer l’emplacement du fichier de configuration, ensuite la procédure est identique à celle de la distribution automatique :
https://www.gaia.fr/wp-content/uploads/2022/10/RDi_512x512-3.png512512Laurent Chavanel/wp-content/uploads/2017/05/logogaia.pngLaurent Chavanel2022-10-03 17:57:282022-10-04 09:39:11RDi : configurer et déployer les Actions de l’utilisateur