Suite de notre premier article sur IWS 3.0, cf https://www.gaia.fr/open-api-avec-iws-3-0/
IWS (Integrated Web Services) 3.0
En novembre 2025, IBM a introduit la version 3.0 de IWS. La version précédente était 2.6, elle-même remplaçant la 1.5.
Les principales nouveautés :
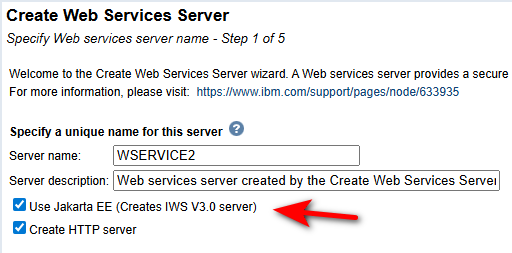
- Stack technique basée sur Jakarta EE au lieu de Java EE
- Integration de openapi
openapi
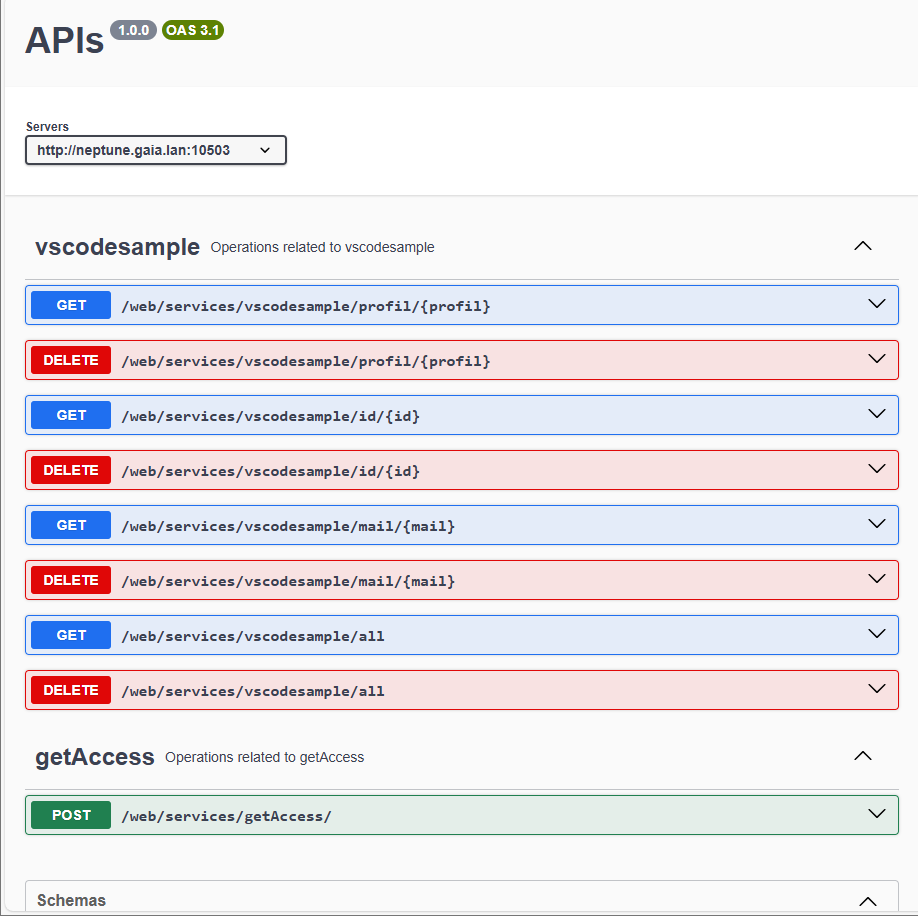
Par défaut, l’interface openapi est disponible à cette URL : http[s]://{system}:{port}/openapi/ui/
Où :
- system : votre partition
- port : correspondant à l’instance IWS pour laquelle vous souhiatez afficher les services
openapi est un standard de facto dans la conception des APIs REST : OpenAPI Initiative – The OpenAPI Initiative provides an open source, technical community, within which industry participants may easily contribute to building a vendor-neutral, portable and an open specification for providing technical metadata for REST APIs – the “OpenAPI Specification” (OAS).
C’est en réalité l’évolution du Swagger qui permet de décrire les web services et leurs interfaces. L’interface produit désormais une page, personnalisable, epxosant la description des services, et permettant leur test !
Modifications de l’interface
Lors de la création d’une instance IWS :
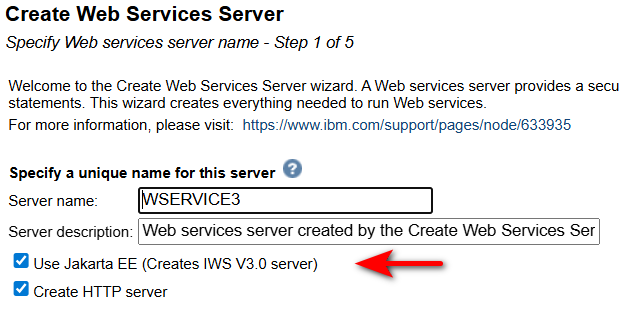
Les propriétés openapi ne sont pas affichables ou modifiables par l’interface, mais pas fichier de configuration et commande shell.
Remarque : seuls les services démarrés apparraissent dans l’interface openapi.
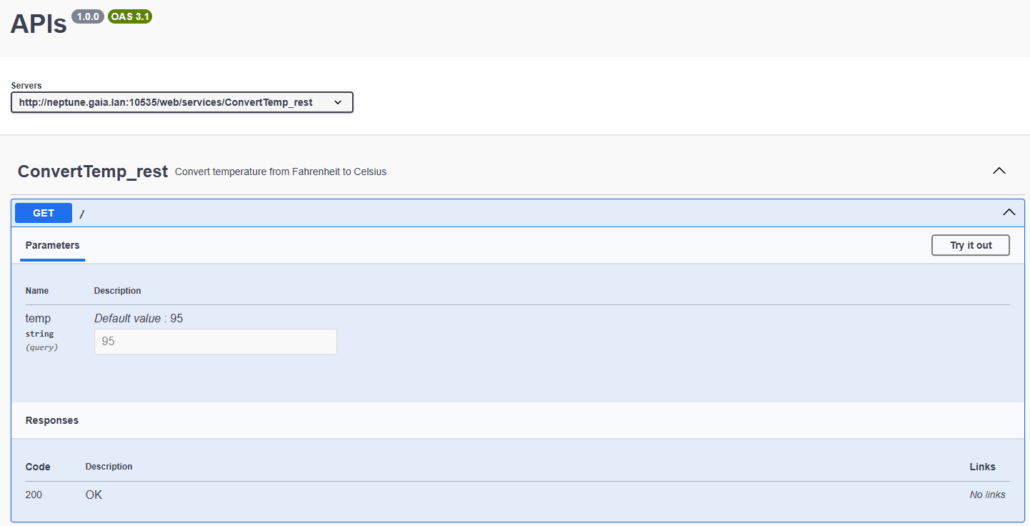
Tester un service REST

Puis indiquez vos valeurs de paramètres :
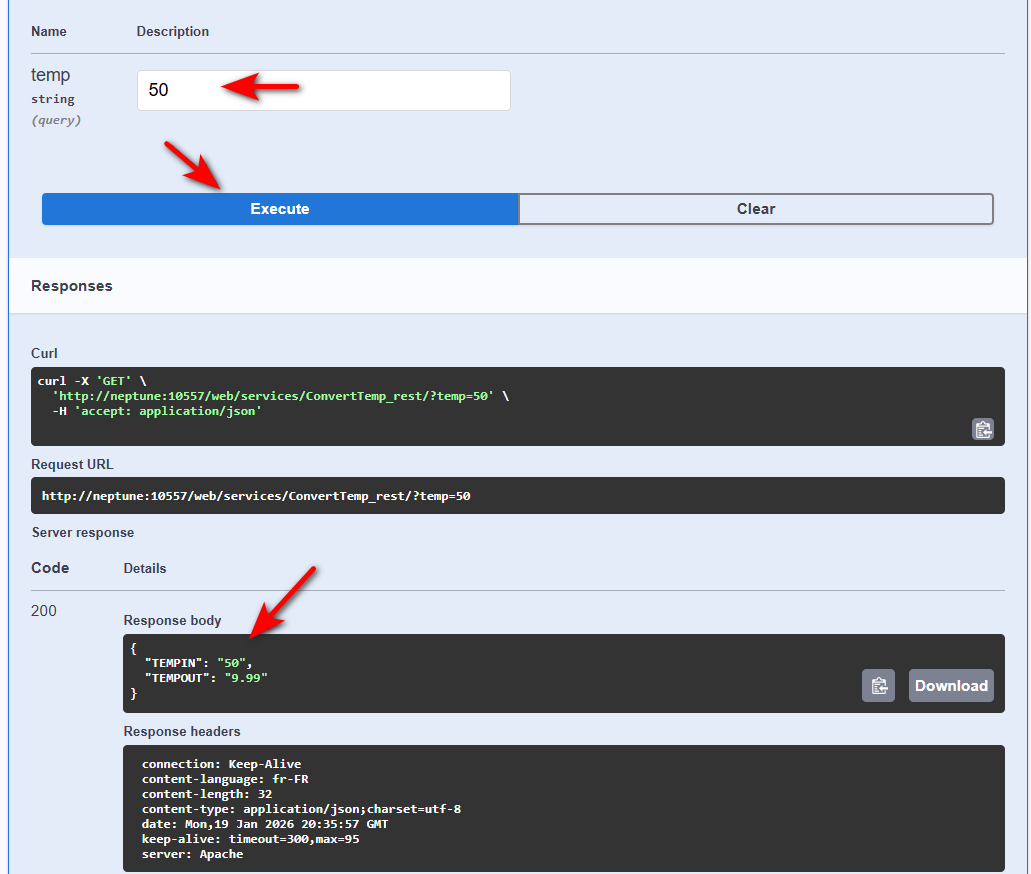
Des options sont disponibles pour les situations plus avancées (authentification basique etc …)
Modifications des commandes shell
Depuis la documentation IBM, création d’un fichier :
#server.iws.gen.httpport=52000
#server.iws.gen.httpsport=52499
#server.iws.gen.adminport=52005
#server.iws.gen.contextroot=/api
#server.iws.gen.defaultkeystore=*NONE
#server.iws.gen.defaultkeystorepassword=
#server.iws.gen.verifyhostname=false
#server.iws.gen.trace=none
# Following are OpenAPI properties - IWS 3.0 only properties
server.iws.openapi.enable=true
server.iws.openapi.docpath=/openapi
server.iws.openapi.contactemail=nathanael.bonnet@gaia.fr
server.iws.openapi.contactname=Nathanael
server.iws.openapi.contacturl=http://www.gaia.fr/contact
server.iws.openapi.description=Description : test NB pour IWS 3.0
server.iws.openapi.licensename=License Gaia 2.0
server.iws.openapi.licenseurl=https://www.gaia.fr/license
server.iws.openapi.summary=Summary : test NB pour openAPI
server.iws.openapi.termsofservice=https://www.gaia.fr/terms
server.iws.openapi.title=Titres : APIs for IWS 3.0
server.iws.openapi.version=9.8.7
server.iws.openapi.excludelist=ConvertTemp_rest
Vous pouvez ensuite demander la mise à jour des propriétés de l’instance :
qsh
cd /qibm/proddata/os/webservices/bin
setWebServicesServerProperties.sh -server 'vsc_sndbox' -propertiesFile '/www/vsc_sndbox/conf/server.properties'
Affiche :
IWS00106I - Command completed successfully. Restart of web service or server may be required for changes to take affect.
Après redémarrage de votre instance, accès à http[s]//…./openapi/ui :
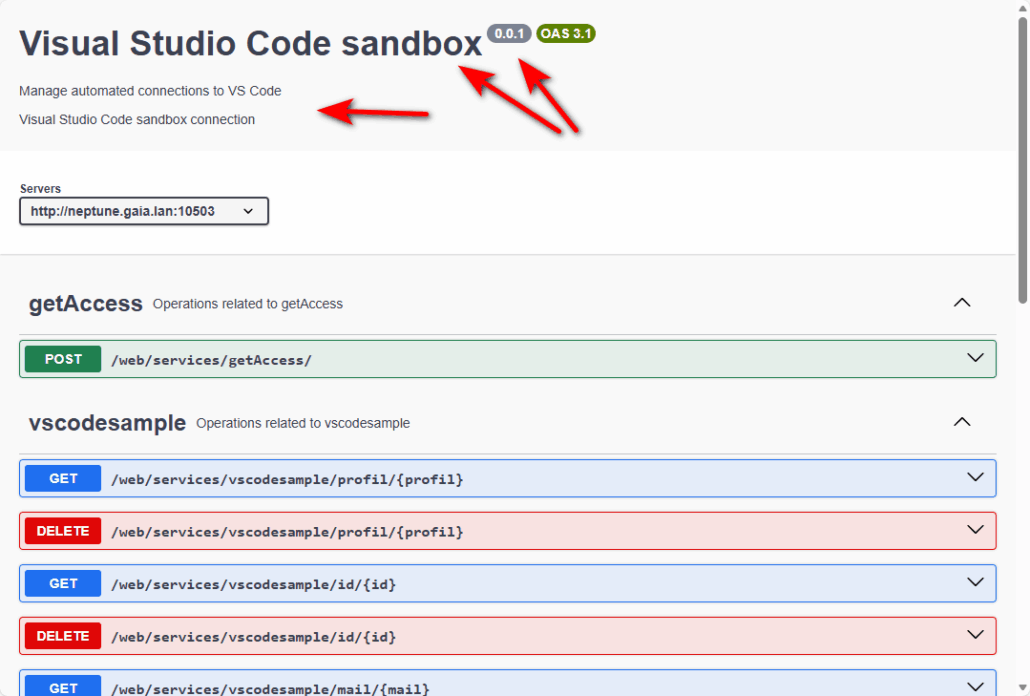
Remarque : il est aujourd’hui impossible de générer un fichier de configuration pour un serveur existant.
Les différentes propriétés :
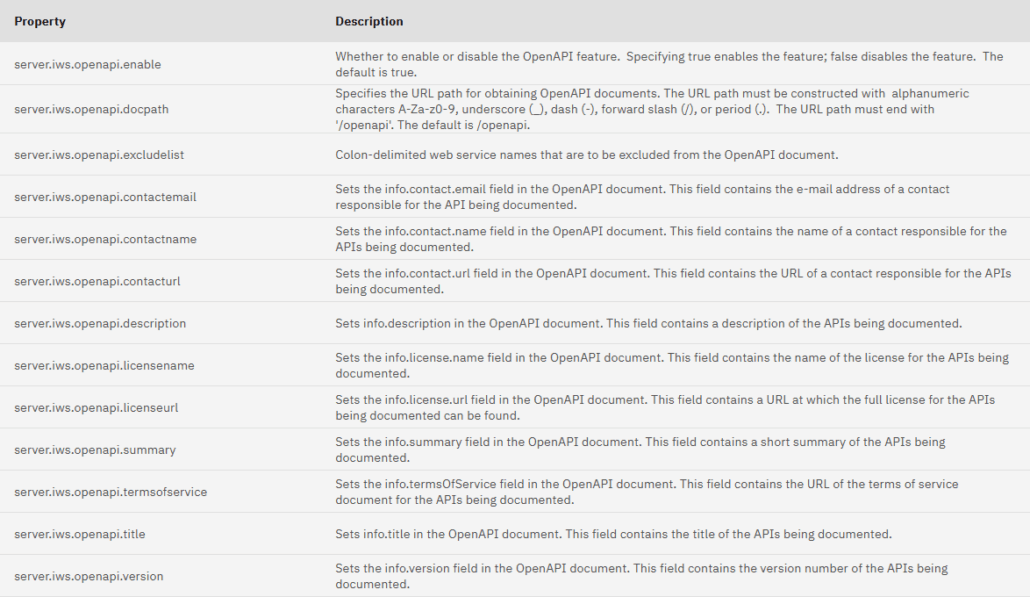
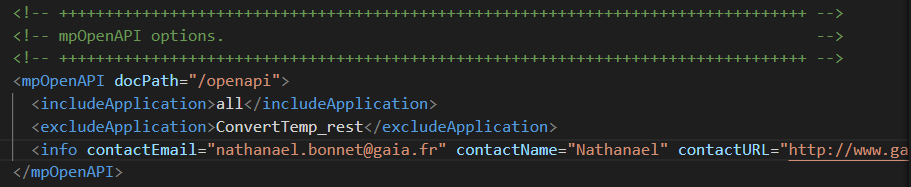
server.xml
La commande sss.sh met à jour les propriétés openapi dans le fichier \www\instance\wlp\usr\servers\instance\server.xml
Migration des instances en version 2.6
Vous pouvez migrer une instance par la commande /qibm/proddata/os/webservices/bin/
stopWebServicesServer.sh -server 'demo26'
updateWebServicesServer.sh -server 'demo26' -version '*CURRENT'
startWebServicesServer.sh -server 'demo26'
Si IWS 3.0 est disponible sur votre système (version et group PTF à partir de 7.4), l’instance est migrée, ainsi que les différents services.
Le serveur doit être préalablement arrêté.
Exemple de sortie de la commande updateWebServicesServer.sh :

Vous pouvez également demander la migration de services, principalement dans le cas où le serveur a été migré avec des services en erreur :
updateWebServices.sh -server 'demo26' -serviceList 'ConvertTemp_Soap' -printErrorDetails
Références
Enhancements to setWebServicesServerProperties.sh Qshell command