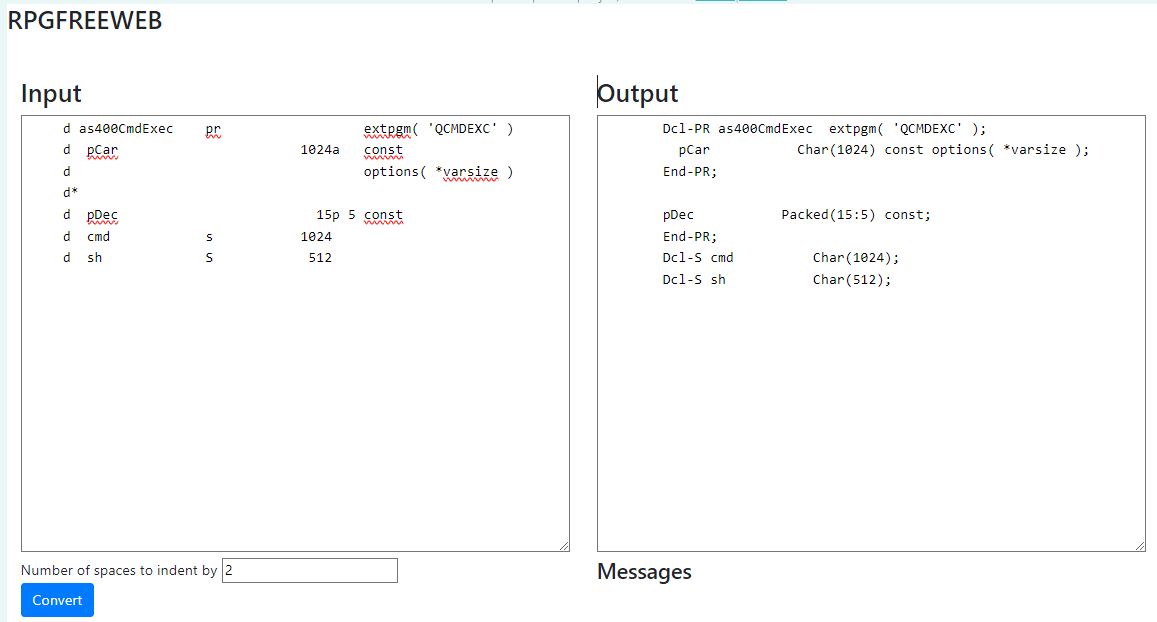
Contrôler le nombre de paramètres passés à un programme CL – %PARMS() / CEETSTA
Il arrive parfois d’avoir moins de paramètres passés à un programme CL que le nombre attendu, par exemple si on ajoute un paramètre à ce dernier mais que pour diverses raisons on ne souhaite pas modifier et recompiler tous les programmes qui y font appel.
Il existe deux solutions relativement simples à implémenter pour contrôler le nombre de paramètres transmis afin d’adapter en conséquence le comportement du programme : La fonction intégrée %PARMS et l’API CEETSTA.
%PARMS() – V7R4 et ultérieures
À partir de la V7R4, rien de plus simple, il suffit d’utiliser la fonction intégrée %PARMS(), qui retourne le nombre de paramètres :
PGM PARM(&PARAM1 &PARAM2)
/* Paramètres */
DCL VAR(&PARAM1) TYPE(*CHAR) LEN(10)
DCL VAR(&PARAM2) TYPE(*CHAR) LEN(10)
/* Corps du programme en fonction du passage du paramètre */
IF COND(%PARMS() *EQ 2) THEN(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 est renseigné')
ENDDO
ELSE CMD(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 n''est pas renseigné')
ENDDO
ENDPGMMalheureusement, si on est confrontés à une contrainte de version, %PARMS ne descend pas en dessous de la V7R4 :
CEETSTA – V7R3 et antérieures
Dans ce cas, la solution la plus propre (je ne parlerai donc pas de monitoring sur un CHGVAR) est l’utilisation de l’API CEETSTA.
Il suffit de lui passer en paramètre :
– Une variable qui contiendra la valeur de retour, 1 si le paramètre est transmis, 0 s’il n’est pas transmis
– Une variable indiquant la position du paramètre à contrôler
| presence_flag | Sortie | *INT | Variable de retour : 1 ou 0 |
| arg_num | Entrée | *INT | Position de la variable à tester |
PGM PARM(&PARAM1 &PARAM2)
/* Paramètres */
DCL VAR(&PARAM1) TYPE(*CHAR) LEN(10)
DCL VAR(&PARAM2) TYPE(*CHAR) LEN(10)
/* Déclaration des variables nécessaires à l'utilisation de l'API */
DCL VAR(&PRESENCE) TYPE(*INT) /* Variable de retour : 1 ou 0 */
DCL VAR(&ARG_NUM) TYPE(*INT) VALUE(2) /* Position de la variable à tester */
/* Appel de l'API */
CALLPRC PRC('CEETSTA') PARM((&PRESENCE) (&ARG_NUM))
/* Corps du programme en fonction du passage du paramètre */
IF COND(&PRESENCE *EQ 1) THEN(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 est renseigné')
ENDDO
ELSE CMD(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 n''est pas renseigné')
ENDDO
ENDPGMRemarques
Le compte des paramètres pour la arg_num commence à 1
La valeur de retour est un *INT pas un *LGL
Pour plus de détails
Documentation IBM – %PARMS() : https://www.ibm.com/docs/en/i/7.5?topic=procedure-parms-built-in-function
Documentation IBM – CEETSTA : https://www.ibm.com/docs/api/v1/content/ssw_ibm_i_75/apis/CEETSTA.htm