Vous êtes nombreux à utiliser les scripts SQL pour les facilités offertes. Et nombreux également à demander comment rendre leur utilisation plus souple et adaptable pour ne pas rester bloquer à la première erreur.
Voici quelques astuces techniques qui vous permettront d’améliorer vos scripts sans avoir besoin de devenir un expert de DB2 for i !
Un exemple de scripts classiques que nous voyons sur ACS :
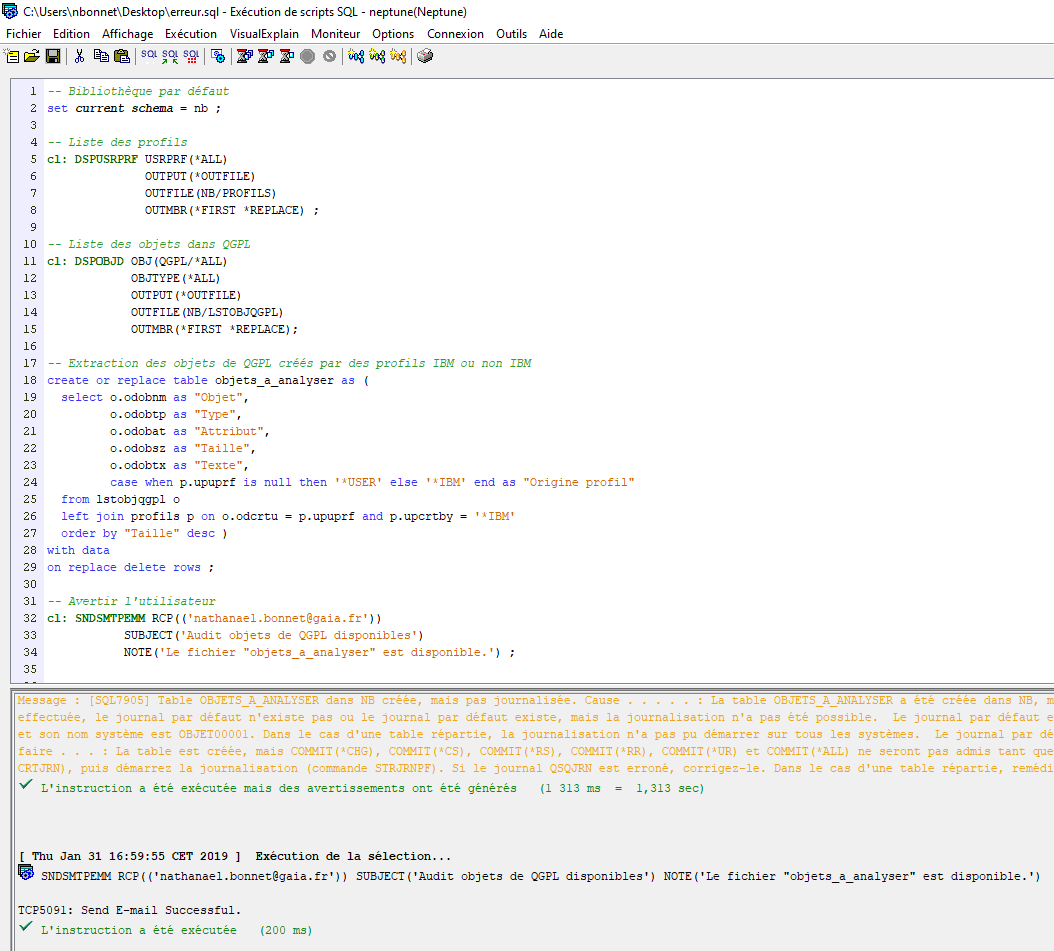
L’éditeur nous offre la possibilité de mélanger instructions CL et instructions SQL.
De plus, le même script est utilisable avec RUNSQLSTM :
RUNSQLSTM SRCSTMF('/home/NB/sql/script.sql') COMMIT(*NONE) NAMING(*SQL)
Vous pouvez donc le mettre dans un CL, le planifier dans le scheduler …
Le principal problème qui se pose ici est la gestion des erreurs : à la moindre erreur, le traitement s’arrête.
Par exemple :
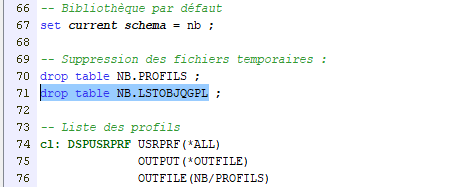
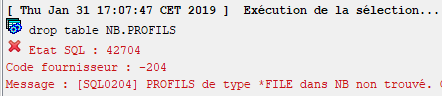
Provoque l’erreur suivante :
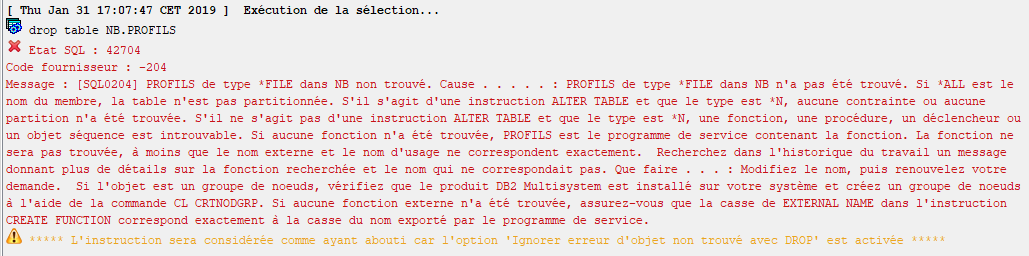
On voudrait bien pourvoir continuer dans ce cas précis (supprimer un objet qui n’existe pas) !
Pour gérer les erreurs dans SQL, il faut utiliser deux notions :
- Les conditions, c’est-à-dire les identifiants d’erreur
- Les handlers, c’est-à-dire les traitements d’erreur
En ce sens la mécanique est proche de celle du CL bien que les syntaxes soient différentes.
Il existe des conditions prédéfinies :
- SQLWARNING : classe ’01’
- NOT FOUND : classe ’02’
- SQLEXCEPTION : correspond aux classes de SQLSTATE autres que ’00’ (OK), ’01’ , et ’02’
De même, 3 types de handlers :
- CONTINUE : faire un traitement d’erreur et continuer à la suite
- EXIT : faire un traitement d’erreur et arrêter le script
- UNDO : faire un traitement d’erreur et défaire ce qui a été fait
Exemple, pour ignorer notre précédente erreur :
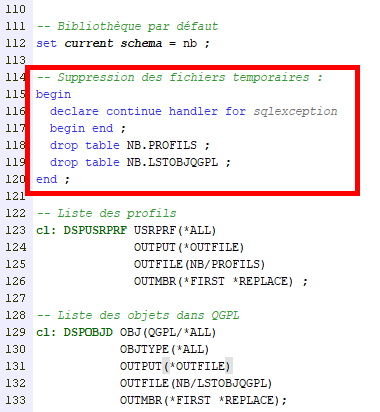
Ici nous interceptions toutes les exceptions SQL pour les instructions DROP TABLE. En cas d’erreur : le code situé entre begin et end est exécuté et le script reprend son exécution. Ici, nous n’avons aucun traitement, c’est-à-dire que nous ignorons purement et simplement l’erreur.
La syntaxe fonctionne également avec RUNSQLSTM !
Maintenant, vous pouvez affiner encore la gestion des erreurs, pour plus de lisibilité et de plus grandes capacités d’adaptation de votre script à prendre en charge des événements différents.
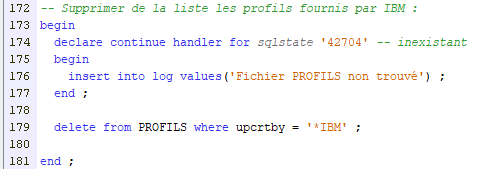
Par exemple, pour gérer une erreur identifiée par son SQLSTATE :

Seule cette erreur sera interceptée. N’importe quelle autre erreur fera s’arrêter le script.
Bien sur, vous pouvez effectuer une action dans le traitement d’erreur :
Vous pouvez mettre plusieurs instructions. Attention à ce qu’elles ne provoquent pas elle-même d’erreur …
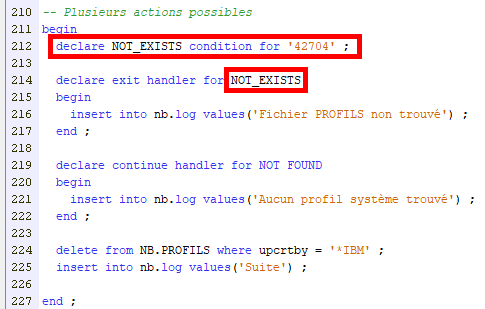
Pour gérer des actions sur plusieurs erreurs possibles, indiquez plusieurs handlers !
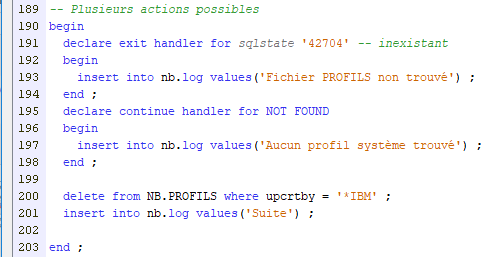
Dans ce cas :
- si le fichier n’est pas trouvé : on log et on arrête
- si aucun enregistrement à supprimer : on log et on continue
Enfin vous pouvez rendre plus lisible vos SQLSTATE en déclarant vos conditions personnalisées. Il vous faut alors déclarer des noms de condition correspondant à vos SQLSTATE :
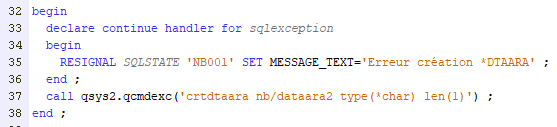
Par contre, toute cette mécanique ne fonctionne plus avec les instructions CL: … Sauf à utiliser une syntaxe alternative :
![]()
QSYS2.QCMDEXC est une procédure cataloguée (SQL) qui appelle l’interpréteur de commande.
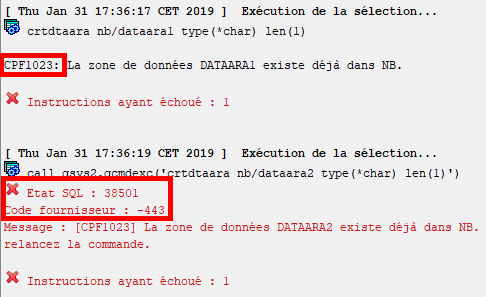
Une différence de comportement :
- CL: renvoie des messages d’erreur de la commande (CPFxxxx généralement)
- call qsys2.qcmdexc() : renvoie des messages SQL
Par exemple :
Remplacer vos instructions CL: par call qsys2.qcmdexc et le tour est joué :
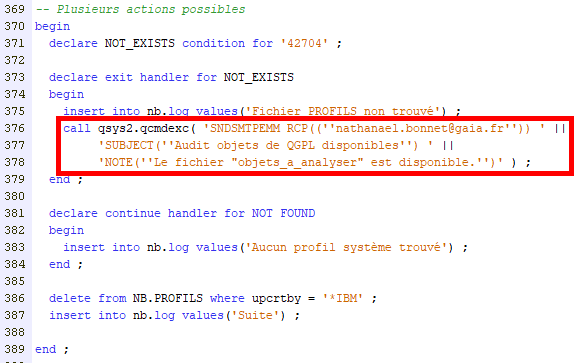
Attention à doubler les cotes !
Dernier point : vous pouvez attraper vos erreurs, pour en renvoyer une autre :