https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-01-03 09:50:482025-01-04 10:12:10PRUV et le cloud
Vous avez souvent sur vos machines de développements beaucoup d’objets à l’intérieur
Vous avez sans doute remarqué que quand vous compiler un objet et qu’il a des erreurs , il vous remet l’ancienne version.
Comment cela est il possible ?
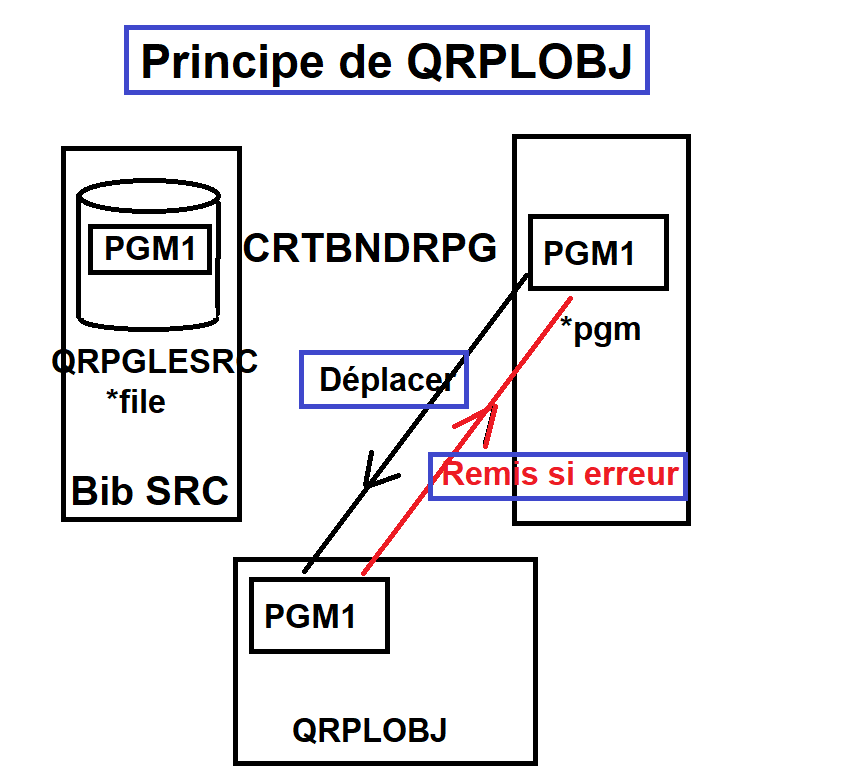
A chaque compile l’objet est renommé est placé dans une bibliothèque qui s’appelle QRPLOBJ
Voici un schéma pour vous expliquer
Cette bibliothèque est clearée à chaque IPL
Pour connaitre la taille de la bibliothèque vous pouvez par exemple utiliser cette requête :
SELECT LIBRARY_SIZE FROM TABLE(QSYS2.LIBRARY_INFO(‘QRPLOBJ’))
Si elle grossit trop vous devrez faire un coup de ménage, attention elle est interdite par défaut il faut être *ALLOBJ pour faire cette opération
PS :
Vous avez aussi à l’intérieur des objets de type USRQ, USRSPC, c’est souvent sur les CRTxx ou vous pouvez indiquer REPLACE(*YES) sur l’API ou la commande …
Attention Vérifiez bien votre résultat de compile avant de relancer votre programme sinon vous lancez une vielle version !
Au verrouillage , mais normalement vous ne devriez pas avoir d’objets verrouillés à l’intérieur ca peut indiquer un autre dysfonctionnement puisque cet objet sera effacé à l’IPL !
La préconisation d’IBM et de faire IPL à chaque application de PTFs pour ne pas perdre le cache SQL par exemple
Mais, il y a quand même un point, pour vous inviter à en faire plus, c’est la mémoire qui est perdu sur certain travaux
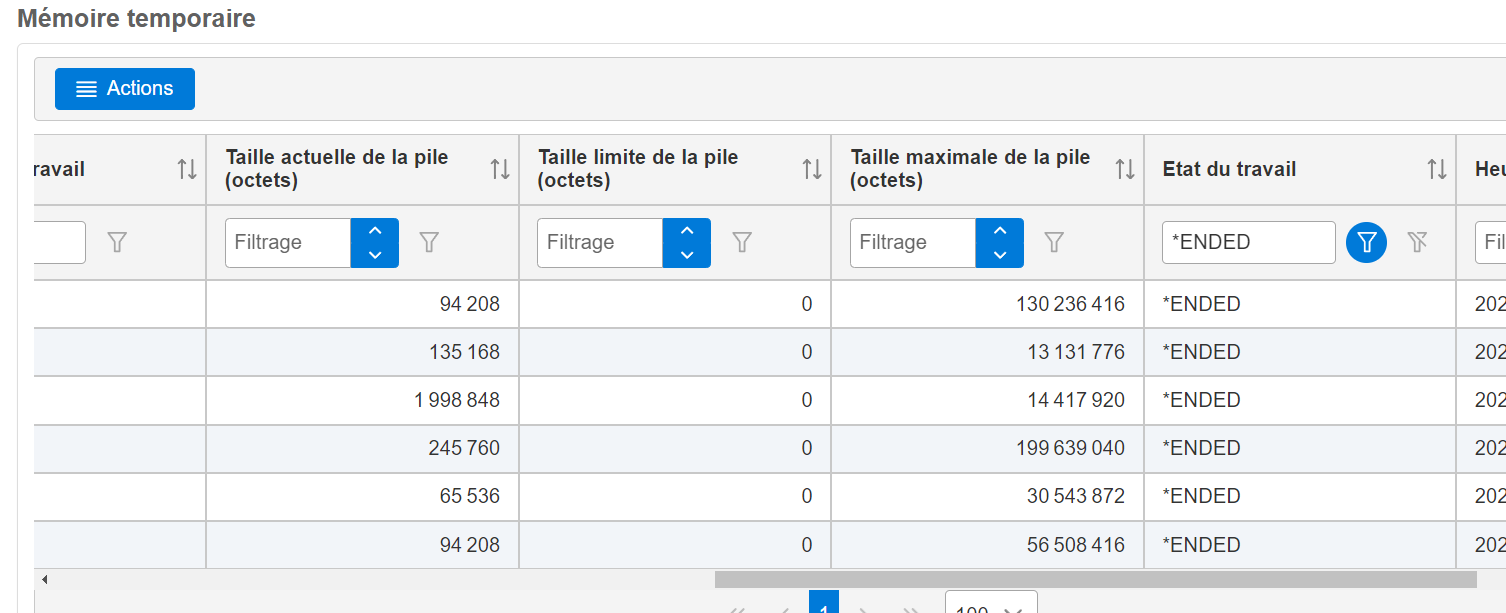
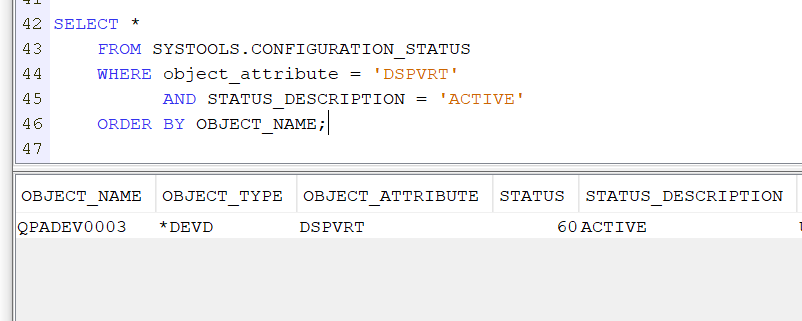
Vous avez une vue QSYS2.SYSTMPSTG qui permet de voir les buckets
La vue SYSTMPSTG contient une ligne pour chaque espace de stockage temporaire qui contient une quantité de stockage temporaire sur le système. Le stockage temporaire est un stockage qui ne persiste pas lors d’un redémarrage du système d’exploitation. on parle de « BUCKET »
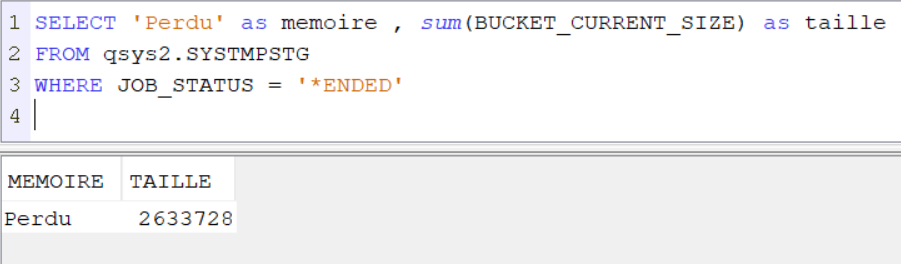
Voici une requête qui montre l’espace perdu par les jobs terminés
SELECT ‘Perdu’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’
le détail
SELECT JOB_NAME, JOB_USER_NAME, JOB_NUMBER , BUCKET_CURRENT_SIZE FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’ order by BUCKET_CURRENT_SIZE desc
Voici une requête qui donne la taille totale
SELECT ‘Total’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG ;
Vous pouvez faire un ratio et si il est important 10 % par exemple
Vous devrez faire une IPL, pour récupérer cette mémoire
Vue dans Navigator For I
Ps: A ce jour il n’y a pas d’autres solutions pour récupérer cette mémoire
pour en savoir plus : https://www.ibm.com/support/pages/how-often-ipl-should-be-performed
Voici comment visualiser l’historique d’une macro-commande Arcad
Objectifs :
Lorsqu’une macro-commande se termine en anomalie, la joblog peut ne pas être toujours évidente à décrypter ou pire elle peut avoir été supprimée.
Cet article a pour objectif de présenter process à suivre pour pouvoir visualiser chaque étape d’exécution d’une macro-commande Arcad.
Pour cela il faut :
Retrouver l’instance de la macro commande à analyser
Afficher l’historique de l’instance à analyser
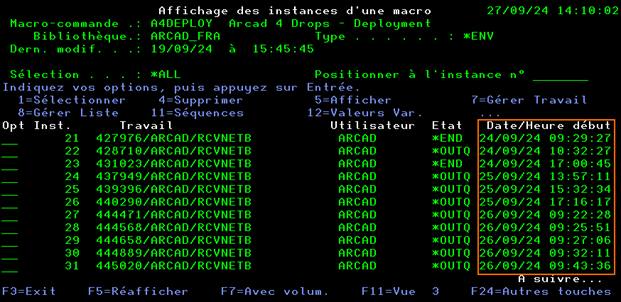
1) Recherche de l’instance de la macro-commande à analyser :
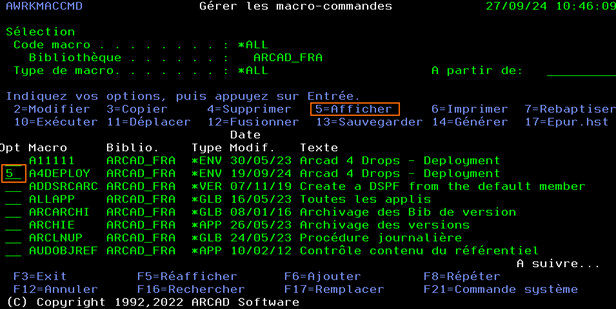
Lancer la commande AWRKMACCMD pour accéder à la liste des macro-commandes Arcad.
Lancer l’option 5 AFFICHER sur la macro-commande concernée.
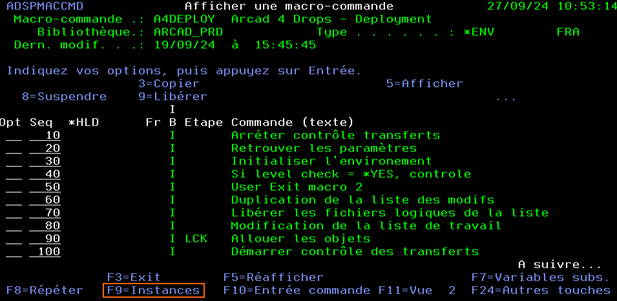
Une fois la macro-commande affichée :
Faire F9 pour afficher toutes les instances de lancement de la macro-commande
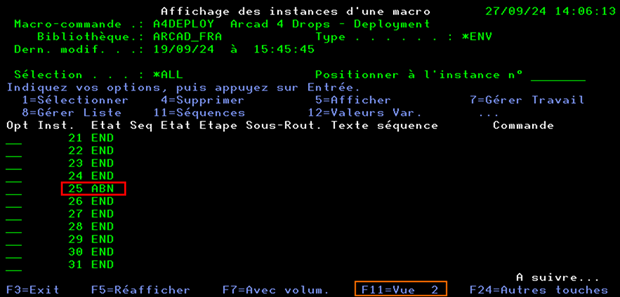
La liste des instances d’exécution de la macro-commande s’affiche.
Dans l’exemple ci-dessus on voit que la 25eme instance n’a pas abouti (Etat à ABN = Abandon).
La touche F11 permet de changer de vue et ainsi afficher les dates de traitement, cela facilite l’identification précise de l’instance à analyser.
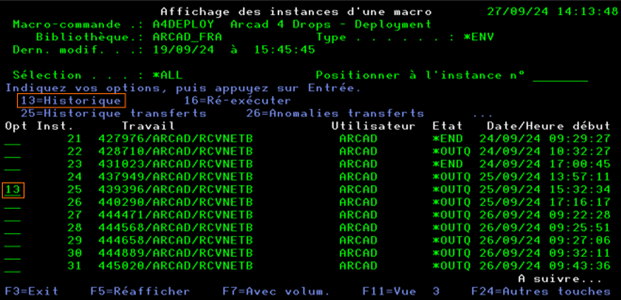
2) Afficher l’historique de l’instance à analyser
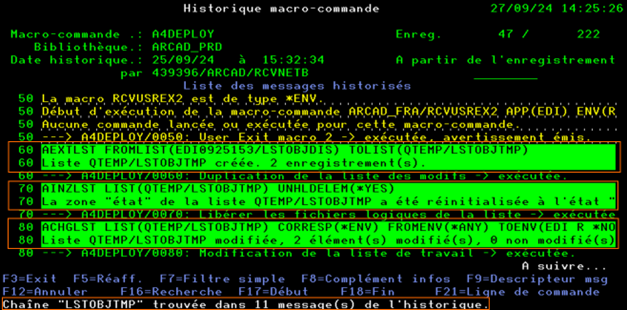
Lancer l’option 13 (Historique) sur l’instance à analyser
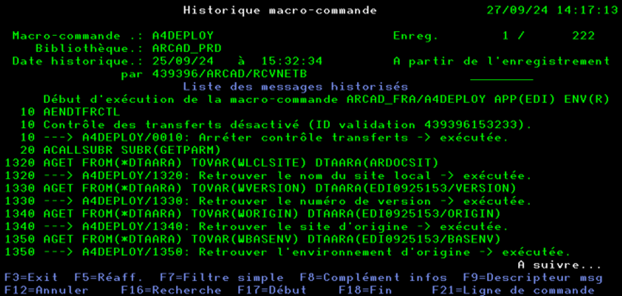
L’historique des commandes de la macro-commande sera alors affiché
Pour rappel :
Les lignes en rouge correspondent aux alertes Arcad Attention : ce ne sont pas toujours des anomalies.
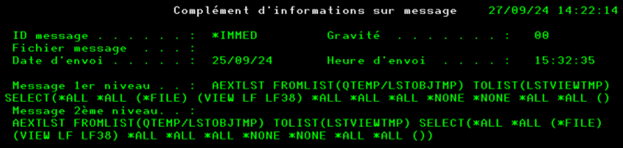
La touche F8 permet d’afficher l’intégralité de la commande Arcad sur laquelle est positionné le curseur. Cela permet de visualiser toute la commande avec tous ses paramètres
La touche F16 permet de rechercher une chaine de caractères dans l’ensemble des commandes affichées. Les lignes contenant la chaine de caractères recherchées seront affichées en surbrillance.
Le nombre d’occurrences trouvées sera affiché en bas de l’écran.
En convertissant vos programmes par la commande CVTRPGSRC, vous pouvez avoir un petit effet de bord sur les DS qui ne sont pas initialisées par défaut.
Vous avez 2 solutions :
la première ne marche que pour les zones étendues, à la compile vous pouvez indiquer
FIXNBR(*ZONED *INPUTPACKED)
Mais la meilleure solution est d’ajouter INZ sur votre Data structure
Exemple
D JOUR DS INZ <—– ici D AN£ 1 4 D MO£ 6 7 0 D JR£ 9 10
Les zones seront initialisées avec la valeur par défaut du type déclaré, dans notre cas 0
Voici une petite requête pour vous aider, derrière un CVTRPGSRC par exemple
Faites un alias sur votre membre
CREATE ALIAS QTEMP/INPUT FOR GDATA/QRPGLESRC (votre source RPGLE)
Ensuite passer cette requête :
update input set SRCDTA = substr(srcdta, 1, 59) concat ‘INZ’ where substr(srcdta, 6, 1) = ‘D’ and substr(srcdta, 23, 3) = ‘ DS’
INZ est ajouté en position 59, au cas où il y ait un autre mot clé avant
PS : Attention à l’ordre des overlays et l’INFDS qui ne peut pas être initialisé
Un nouvel article proposé par Jérôme Clément qui est un spécialiste de la modernisation d’applications #ibmi , merci à lui pour ces informations éclairées
Objectifs
Cet article a pour objectif de montrer quels sont les avantages qu’offrent la mise en place d’un dictionnaire de services. Je présenterai également un exemple de dictionnaire de services afin de mettre en évidence les différentes possibilités qu’il met à disposition des équipes de développements.
Pourquoi mettre en place un dictionnaire de services
La mise en place d’un dictionnaire a pleinement sa place dans la démarche de modernisation comme nous avons pu le voir dans mon article précédent : https://lnkd.in/ecDXQQPZ
En effet, l’un des objectifs de l’utilisation de programmes de services étant d’éviter la redondance de code, il faut aussi éviter d’avoir plusieurs programmes de services répondant à la même fonctionnalité.
Et il faut également inciter les développeurs à réutiliser les programmes de services déjà existants.
Pour cela, il faut que les développeurs puissent, facilement :
– Consulter la liste des procédures exportées déjà présentes sur le système.
– Rechercher quels services peuvent être utilisés pour répondre à leurs besoins.
– Identifier les paramètres en entrée et en sortie de chaque procédure exportée.
– Vérifier que le service qu’ils souhaitent mettre ne place n’existe pas déjà.
Le rôle du dictionnaire de services est de répondre à chacun de ces besoins.
Exemple de dictionnaire de services
Voici un exemple de dictionnaire de services mis en place chez un de mes clients.
Il ressemble beaucoup, dans ses fonctionnalités à celui que mes collègues et amis Anass EL HADEF et Eric D’INGRANDO ont mis en œuvre chez un autre client.
Bien sûr, ceci reste un exemple, à vous de mettre en place le dictionnaire de données qui correspondra le mieux à votre entreprise.
Dans cet exemple je tiens compte de l’application ARCAD car mon client utilise ARCAD et a mis en place de nombreuses applications bien spécifiques, vous n’aurez peut-être pas à gérer cette information sur votre dictionnaire.
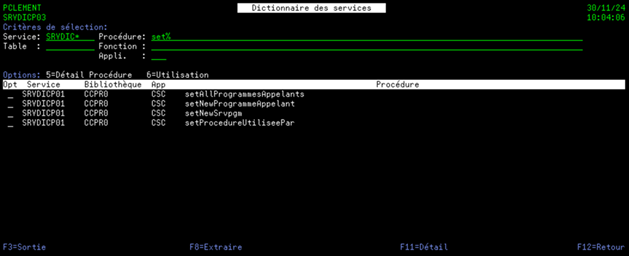
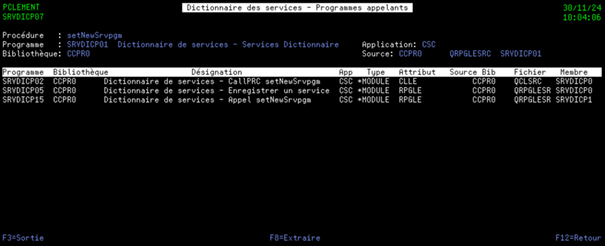
1) Liste des procédures exportées
Cet écran liste toutes les procédures exportées par les programmes de service.
Afin de permettre aux développeurs de rechercher si une procédure exportée répondant à leurs besoins existe déjà, sans avoir à parcourir l’intégralité de la liste affichée, des critères de sélections sont mis à disposition.
Ils permettent de filtrer les procédures affichées et donc de faciliter la recherche d’une procédure exportée en particulier.
Cette recherche peut se faire :
Sur le nom du programme de service exportant des procédures
Sur le nom des procédures exportées
Sur le nom d’une table utilisée par dans les procédures exportées
Sur les fonctionnalités couvertes par les procédures exportées
Sur l’application ARCAD qui contient les programmes de service
A noter que ces recherches peuvent se faire avec des caractères génériques « * » et « % » afin de ne pas les limiter aux termes exacts des critères de sélection.
Les données affichées sont :
Le nom du programme de service
La bibliothèque du programme de service
L’application ARCAD du programme de service
Le nom de la procédure exportée
La touche F11 permet d’afficher d’autres d’informations, telles que :
Le texte descriptif du programme de service
Les informations relatives au source du programme de service
La bibliothèque du fichier source
Le fichier source
Le membre source
La touche F18 permet d’envoyer par mail, au(x) destinataire(s) de notre choix, un fichier Excel contenant l’ensemble des lignes affichées. J’utilise ce principe sur les sous-fichiers que je mets en place, elle repose, bien sûr, sur un programme de service et utilise les fonctions SQL : GENERATE_SPREADSHEET et SEND_EMAIL. Je pense rédiger un prochain article pour détailler cette fonctionnalité…
L’option 5 permet d’afficher le détail de la procédure exportée sélectionnée.
L’option 6 permet d’afficher la liste des programmes qui utilisent la procédure exportée sélectionnée.
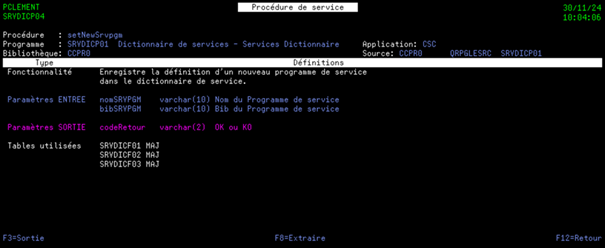
2) Détail d’une procédure exportée
C’est cet écran qui permettra aux développeurs de vérifier si la procédure exportée sélectionnée répond ou non à leurs besoins. Il leur permettra également de prendre connaissance des paramètres utilisés par cette procédure.
Cet écran affiche :
Les caractéristiques de la procédure exportée sélectionnée
Nom de la procédure
Nom et texte descriptif du programme de service qui l’exporte
Bibliothèque du programme de service
Application ARCAD qui gère le programme de service
La bibliothèque, le fichier et le membre source du programme de service. Ceci permettra aux développeurs de retrouver facilement le prototype du programme de service à utiliser si la procédure exportée correspond à leurs besoins.
La description de la fonctionnalité couverte par la procédure exportée
La liste des paramètres en entrée avec pour chaque paramètre :
Le nom du paramètre
Le format du paramètre
La description du paramètre avec si besoin la listes des valeurs autorisées
La liste des paramètres en sortie avec pour chaque paramètre :
Le nom du paramètre
Le format du paramètre
La description du paramètre avec si besoin la listes des valeurs autorisées
La liste des tables utilisées dans la procédure exportée avec le type d’utilisation (Lecture/MAJ/Ecriture/Suppression…)
3) Listes des programmes utilisant une procédure exportée
Cet écran liste les programmes qui utilisent la procédure stockée sélectionnée. il permet aux développeurs de trouver des exemples d’utilisation de cette procédure dont ils peuvent s’inspirer.
Cet écran affiche :
Les caractéristiques de la procédure exportée sélectionnée
Nom de la procédure
Nom et texte descriptif du programme de service qui l’exporte
Bibliothèque du programme de service
Application ARCAD qui gère le programme de service
La bibliothèque, le fichier et le membre source du programme de service ce qui permettra aux développeurs de retrouver facilement le prototype du programme de service à utiliser si la procédure exportée correspond à leurs besoins.
Les caractéristiques de chaque programme qui fait appel à la procédure exportée sélectionnée :
Nom du programme
Bibliothèque du programme
Description du programme
Application ARCAD du programme
Type du programme
Attribut
Bibliothèque du source du programme
Fichier source du programme
Membre source du programme
Comment mettre en place un dictionnaire de services
Le dictionnaire de services pris pour exemple repose sur :
un modèle de données relationnel assez simple constitué de 4 tables
un programmes de service d’alimentation et de mise à jour des données du dictionnaire de services
les 3 programmes interactifs décrits précédemment :
Liste des procédures exportées
Détail d’une procédure exportée donnée
Liste des programmes utilisant une procédure exportée donnée
1) Le modèle de données du dictionnaire
Le modèle de données relationnel utilisé dans ce dictionnaire de services est le suivant :
3 tables composant le dictionnaire de services à proprement parlé :
La table des programmes de service
La table des procédures exportées
La table des informations relatives à chaque procédure exportée
1 table faisant le lien entre les procédures exportées du dictionnaire de services et les programmes qui les utilisent :
Table des programmes utilisant une procédure exportée
2) Alimentation du dictionnaire de services
Pour alimenter les 3 premières tables du dictionnaire de services, 2 solutions sont envisageables :
Soit une alimentation manuelle reposant sur des programmes interactifs permettant d’alimenter chacune des tables du dictionnaire :
Table des programmes de service,
Table des procédures exportées,
Table des informations relatives à chaque procédure.
Cette solution est la plus facile à implémenter mais oblige les développeurs à saisir ces informations en dehors du code source.
Soit une alimentation automatisée, réalisée par un traitement planifié qui sera exécuté régulièrement. Cette solution est beaucoup plus complexe à mettre en œuvre. En effet, le descriptif de la fonctionnalité et les paramètres en entrée/sortie de chaque procédure exportée ne sont pas accessibles. Ces informations doivent être préalablement stockées pour pouvoir être, ensuite, extraites. Il est possible de les stocker directement dans le code source du programme de service, en faisant, par exemple, précéder chaque procédure exportée d’un entête normalisé dans lequel devront être saisies ces informations.
Le programme d’alimentation du dictionnaire de services pourra alors les récupérer en analysant le code source du programme de service.
Personnellement, c’est cette seconde solution que je préconise car :
Le développeur n’a pas à quitter le source du programme de service qu’il est en train d’écrire pour saisir le descriptif des procédures exportées qu’il met en place. Il renseigne ces informations en même temps qu’il développe sa procédure exportée. Il peut donc aisément les mettre à jour directement sans être tenté de remettre cela à plus tard.
La documentation de la procédure exportée est « localisée » car directement présente dans le code source du programme de service. On saura donc toujours où la retrouver.
L’exécution du programme d’extraction peut être planifié de façon régulière, de façon à garantir que le dictionnaire de services est bien à jour.
Cette solution fera l’objet d’un prochain article dans lequel je développerai en détail chaque étape de sa mise en œuvre.
3) Alimentation du lien entre les procédures exportées et les programmes qui les utilisent
Extraire les procédures exportées par un programme de service donné est simple grâce aux tables de QSYS2.
SELECT PROGRAM_NAME AS "Nom Pgm de service",
PROGRAM_LIBRARY AS "Bibliotheque Pgm de service",
TRIM(SYMBOL_NAME) AS "Nom Procedure exportee"
FROM QSYS2.PROGRAM_EXPORT_IMPORT_INFO
WHERE PROGRAM_LIBRARY = 'ma_bibliotheque_de_programmes'
AND PROGRAM_NAME = 'mon_programme'
AND OBJECT_TYPE = '*SRVPGM'
AND SYMBOL_USAGE = '*PROCEXP';
Extraire les programmes qui utilisent un programme de service donné est simple aussi.
SELECT PROGRAM_NAME AS "Nom de PGM appelant",
PROGRAM_LIBRARY AS "Bib du PGM appelant",
BOUND_SERVICE_PROGRAM AS "PGM de service appelé »
FROM QSYS2.BOUND_SRVPGM_INFO
WHERE PROGRAM_LIBRARY = 'ma_bibliothèque_de_programmes';
Par contre :
Extraire les programmes qui utilisent une procédure stockée donnée est plus complexe.
En effet, ce lien n’est pas stocké dans les tables de QSYS2. Il va falloir rechercher chaque procédure exportée par un programme de service dans le code source de chaque programme qui utilise ce programme de service.
Voici, ci-dessous, un exemple de requête qui répond à cette problématique.
SELECT
A.PROGRAM_LIBRARY AS "BIB_PGM_DE_SERVICE",
A.PROGRAM_NAME AS "PGM_DE_SERVICE",
A.OBJECT_TYPE AS "TYPE_OBJET",
A.SYMBOL_NAME AS "PROCEDURE_EXPORTEE",
B.PROGRAM_LIBRARY AS "BIB_PGM_UTILISANT_PGM_DE_SERVCIE",
B.PROGRAM_NAME AS "PGM_UTILISANT_PGM_DE_SERVCIE",
B.OBJECT_TYPE AS "TYPE_PGM_UTILISANT_PGM_DE_SERVCIE",
B.BOUND_SERVICE_PROGRAM AS "PGM_DE_SERVICE_UTILISE",
TRIM(C.SOURCE_FILE_LIBRARY) CONCAT '/' CONCAT TRIM(C.SOURCE_FILE)
CONCAT '(' CONCAT TRIM(C.SOURCE_FILE_MEMBER) CONCAT ')' AS PATH_SOURCE
FROM QSYS2.PROGRAM_EXPORT_IMPORT_INFO A
LEFT JOIN QSYS2.BOUND_SRVPGM_INFO B
ON B.BOUND_SERVICE_PROGRAM = A.PROGRAM_NAME
LEFT JOIN QSYS2.BOUND_MODULE_INFO C
ON C.PROGRAM_LIBRARY = B.PROGRAM_LIBRARY
AND C.PROGRAM_NAME = B.PROGRAM_NAME
WHERE A.PROGRAM_LIBRARY = 'ma_bib_de_programmes’
AND A.PROGRAM_NAME = 'mon_programme_de_service’
AND B.PROGRAM_LIBRARY = 'ma_bib_de_programmes’
AND LOCATE_IN_STRING(GET_CLOB_FROM_FILE(
TRIM(C.SOURCE_FILE_LIBRARY)
CONCAT '/' CONCAT TRIM(C.SOURCE_FILE) CONCAT '(' CONCAT TRIM(C.SOURCE_FILE_MEMBER) CONCAT ')', 1)
, A.SYMBOL_NAME) > 0;
Attention : la fonction GET_CLOB_FROM_FILE doit être faite sous commitment control.
Pour conclure
Le dictionnaire de services facilite la mise en œuvre de la programmation basée sur les services ILE. Il permet aux développeurs de trouver et donc de réutiliser les services déjà développés. Ce qui réduira les temps de développements, tout en garantissant l’unicité des procédures exportées.
Il permet également de disposer d’une documentation centralisée de chaque procédure exportée.
C’est en cela que le dictionnaire de services rentre pleinement dans la démarche de modernisation des applicatifs IBM-i.
N’hésitez pas à me faire part de vos remarques et/ou de vos questions, je me ferai un plaisir d’y répondre.
Je remercie :
Anass EL HADEF et Eric D’INGANDO pour les échanges que nous avons eus au sujet des dictionnaires de services et pour la source d’inspiration qu’ils m’ont apportée.
https://www.gaia.fr/wp-content/uploads/2024/11/Jerome-CLEMENT-1.jpg22311577Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-12-07 10:11:212024-12-07 19:16:55Mise en place d’un dictionnaire de services
La precaunistation d’IBM et de faire IPL à chaque appliction de PTFs pour ne pas perdre le chache SQL par exemple
Mais, il y a quand même un point inviter à en faire plus, c’est la mémoire qui est perdu sur certain travaux
Vous avez une vue QSYS2.SYSTMPSTG qui permet
La vue SYSTMPSTG contient une ligne pour chaque espace de stockage temporaire qui contient une quantité de stockage temporaire sur le système. Le stockage temporaire est un stockage qui ne persiste pas lors d’un redémarrage du système d’exploitation. on parle de « BUCKET »
Voici une requête qui montre l’espace perdu par les jobs terminés
SELECT ‘Perdu’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’
le détail
SELECT JOB_NAME, JOB_USER_NAME, JOB_NUMBER , BUCKET_CURRENT_SIZE FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’ order by BUCKET_CURRENT_SIZE desc
Voici une requête qui donne la taille totale
SELECT ‘Total’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG ;
Vous pouvez faire un ratio et si il est important 10 % par exemple
Vous devrez faire une IPL, pour récupérer cette mémoire
Vue dans Navigator For I
Ps: A ce jour il n’y a pas d’autres solutions pour récupérer cette mémoire
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-12-02 19:42:522024-12-02 19:42:52Fréquence des IPL, complément
AdministrationContrôler la taille des résultats de QUERY400
Vous utilisez encore les QUERY/400 et vous souhaitez contrôler la taille du fichier en sortie ? Cette astuce peut vous être utile.
Lorsque vous choisissez en type de sortie un fichier base de données, par défaut, le fichier est taillé en *NOMAX. Il peut arriver qu’avec une mauvaise jointure que l’on atteigne le million d’enregistrements (voir le milliard). Si vous souhaitez limiter la taille de ce fichier en sortie, il vous suffit de créer une DTAARA dans QGPL avec comme nom QQUPRFOPTS puis de définir le nombre d’enregistrements maximum.
/wp-content/uploads/2017/05/logogaia.png00Florian Gradot/wp-content/uploads/2017/05/logogaia.pngFlorian Gradot2024-11-08 08:15:392024-11-12 10:17:10Contrôler la taille des résultats de QUERY400