

Gestion des logs SHELL dans un CLLE
Pierre-Henry avait déjà abordé la problématique de récupération des logs SHELL par la soumission de la commande QSH.
Un très bon article, que je vous conseille, si vous ne l’avez pas encore lu.
https://www.gaia.fr/recuperer-les-logs-dune-commande-shell-qsh/
Cependant pour des raisons d’organisation des traitements, on peut ne pas souhaiter débrancher la commande QSH, en la soumettant, du reste de notre programme.
Dans ce cas l’appel à QSH se fait dans le CLLE. Le log SHELL ne se retrouve pas dans les spools du job.
On peut néanmoins les récupérer par l’intermédiaire de variable d’environnements.
Les variables d’environnement et l’exécution de script SHELL
Je profite de cet article pour rappeler l’usage de quelques variables d’environnement pour l’exécution d’un script SHELL dans un CLLE. Ce ne sont que des exemples, il y en a beaucoup d’autres de possible !
- QIBM_MULTI_THREADED
Cette variable d’environnement est essentielle pour le fonctionnement des scripts SHELL. Il faut être multi-threadé pour que la commande s’exécute.
Par exemple, dans l’image ci-dessous, j’ai lancé via la commande SHELL, un script SFTP.
En dernière ligne nous trouvons le job lançant la commande shell, et au dessus 3 jobs de type BCI, « Batch immediate jobs », qui sont activés pour l’exécution d’un job multi-threadé.

ADDENVVAR ENVVAR(QIBM_MULTI_THREADED) VALUE(Y)
- QIBM_QSH_CMD_ESCAPE_MSG
L’exécution de la commande QSH dans un programme entraine un message QSH0005, QSH0006 ou QSH0007. Le message QSH0005 contient un code statut, allant de 0 à 255. 0 pour une exécution complète, les autres codes pour renvoyer un avertissement ou une erreur.
Par défaut, ces messages sont envoyés avec un type d’achèvement complétion (*COMP), circulez, y’a rien à voir ! Seule une lecture du log du job, pour trouver le statut du message QSH0005, permettra de dire si l’exécution de la commande QSH s’est bien passée.
En ajoutant la variable d’environnement avec la valeur Y, le type d’achèvement dépendra du statut du message QSH0005.- Si le statut est 0 : message en complétion
- Autre valeur du statut, message en *ESCAPE. Ca veut dire qu’il faudra monitorer les messages QSH dans votre CL et gérer ces erreurs, sinon votre programme plantera.
Message sans la variable d’environnement

Message avec la variable d’environnement

ADDENVVAR ENVVAR(QIBM_QSH_CMD_ESCAPE_MSG) VALUE(Y)
- QIBM_QSH_CMD_OUPUT
Cette variable définit le mode de sortie lors de l’exécution du script SHELL.
NONE : exécution du script en mode silencieux
STDOUT : affiche le terminal C avec le déroulé du script. En interactif, possibilité de répondre à une question en cours de script.
FILE : génération d’un fichier log dans l’IFS. Si le fichier existe déjà, il sera remplacé.
FILEAPPEND : génération d’un fichier dans l’IFS en ajout. Le fichier sera créé, s’il n’existe pas.
Attention : Pour les options « File » et « Fileappend », si le chemin IFS n’existe pas ou s’il n’est pas atteignable, problème de droit par exemple, le terminal C s’affichera.
ADDENVVAR ENVVAR(QIBM_QSH_CMD_OUTPUT) VALUE(‘FILE=/Monrepertoire/MonFichierlog’)
Attention : Entre le « = « et le début du chemin pour le fichier log, il n’y a pas d’espace.
Dans votre programme, vous pouvez générer un nom de fichier log en dynamique, avant de générer votre variable d’environnement. Pour cela, il faudra que votre variable contienne ‘FILE=’ suivi du nom de votre fichier log, et passer la variable dans le paramètre VALUE de la commande.
Récupération du log
La variable d’environnement QIBM_QSH_CMD_ESCAPE_MSG permet de dissocier les fins OK des fins KO de QSH.
Mais sans la moindre information sur ce qui s’est passé.
Par la récupération du log dans l’IFS, vous pourrez interroger par SQL le fichier et gérer les problèmes. Au moins les cas les plus fréquents, et laisser les cas rares en gestion humaine.
La génération d’une log, peut aussi avoir de l’intérêt en cas de création de script en dynamique dans votre programme, pour garder une trace de ce qui a été exécuté… Pensez à la maintenance, et aux recherches en cas d’anomalie…
Prenons un exemple :
Un asynchrone qui scrute, via SFTP dans un répertoire réseau, la présence de fichier xml.
Télécharger ces fichiers dans l’IFS et laisser un traitement d’intégration dans l’ERP.
Ce traitement se lance à intervalle régulier, temporisation de 15 secondes.
Il peut ne pas y avoir de fichier à récupérer, répertoire distant vide.
C’est un cas classique d’interface asynchrone entre un logiciel externe à l’IBM i et la partie legacy de l’applicatif.
Dans cette exemple, je fais le choix d’effectuer directement un mget /repertoiredistant/*.xml, sans passer par un listing du répertoire suivi d’une lecture de ce listing pour charger fichier par fichier.
Je récupère directement tous les fichiers xml présents.
Problème, s’il n’y a aucun fichier xml dans le répertoire, le script SFTP renvoie une erreur, via le message QSH0005 qui a un statut 1. Pour moi ce n’est pas une erreur. C’est ce qu’on pourrait appeler un faux positif !
Pour déterminer si le message d’échappement reçu est une « vrai » erreur, ou l’absence de fichier à récupérer, je dois pouvoir récupérer la log.
Via la variable d’environnement, QIBM_QSH_CMD_OUPUT, en ‘FILE=’, je génère mes logs dans l’IFS, sans mode verbose sur le SFTP.
Quand tout se passe bien j’ai le log ci-dessous :
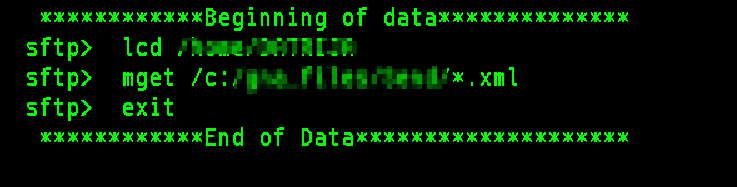
Le fichier contient la liste des commandes passées. Toutes les commandes de mon script se retrouvent dans la log.
Quand le mget ne trouve aucun fichier à ramener, j’ai le log :
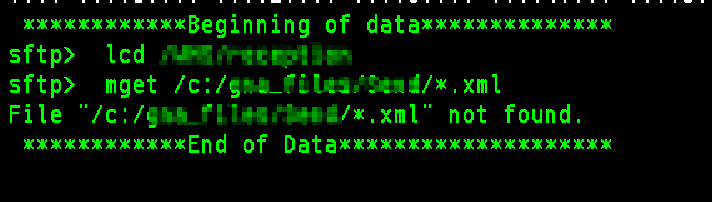
À la suite du mget, je reçois un message d’erreur, pour fichier not found. Le script n’est pas allé plus loin, la commande « exit » n’a pas été passée.
Autre exemple, j’ai généré un problème de connexion, voici le log que j’ai reçu :

Aucune commande SFTP n’a été passée, normal, la connexion a été interrompu pendant la phase d’authentification.
Ce log n’est bien entendue qu’un exemple parmi beaucoup de problèmes de connexion.
Lecture du fichier par SQL
Je dispose de log dans l’IFS, je peux donc par SQL lire ces fichiers via la fonction table IFS_READ.
Voici ce que ça donne pour les 3 logs :
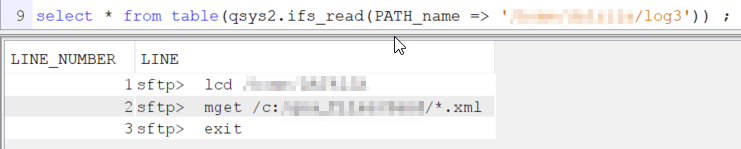
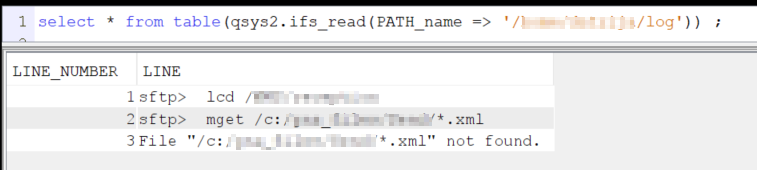
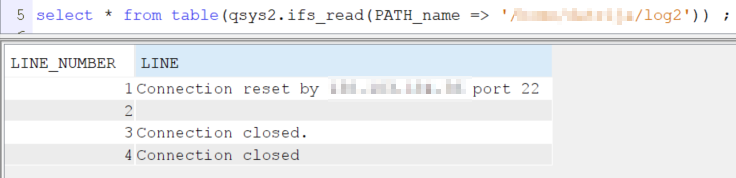
Le log ne disposant pas de code erreur ou de statut de fin, si je veux exploiter ces fichiers, je dois utiliser des recherches textuelles dans le champ LINE. Ce n’est pas l’ideal, mais faute de mieux…
Je peux par exemple rechercher « exit », pour savoir si mon script est allé au bout :

Je peux au contraire rechercher le problème de connexion interrompue :

Je peux aussi rechercher le « not found » pour détecter la fausse anomalie :

Dans notre programme, suite à l’exécution du script SHELL, plusieurs possibilités :
- Avec la variable d’environnement QIBM_QSH_CMD_ESCAPE_MSG, monitorer les messages QSH0000 et donc en cas de problème lire les fichiers log. Dans ce cas la chaîne « exit » n’a pas besoin d’être testée, dans ce cas le message de retour est en complétion.
- Sans la variable d’environnement QIBM_QSH_CMD_ESCAPE_MSG. Dans ce cas, je dois lire le log systématiquement et si je trouve « exit » ou « not found », la fin est normale, sinon il y a une erreur.
Les fichiers log, surtout sans mode verbose, comportent très peu de ligne, les SQL utilisés même s’ils sont « gourmands » par l’utilisation de like sur un fichier IFS, restent rapide. Mais attention à ne pas utiliser sur un fichier IFS contenant un log en cumul sur un mois !
L’idée est de gérer en automatique les retours les plus simples qui ne nécessitent pas d’intervention humaine.
Encore une fois, ce n’est pas l’idéal, mais si on peut alléger les alertes pour les équipes de maintenance, surtout pour un traitement lancé plusieurs fois par minute, il ne faut pas hésiter.
En cas de récupération des logs dans l’IFS, si vous générez un fichier distinct par appel, n’oubliez pas la base : durée de rétention des fichiers, script d’épuration des log obsolètes. Par SHELL, vous avez les outils pour gérer votre stratégie facilement.
Ca évitera un IFS qui enfle. Pour rappel, la volumétrie de données n’est pas la seule responsable des temps de sauvegarde / restauration de l’IFS, le nombre de fichiers aussi. Il vaut mieux un seul fichier de 1 Mo que 1000 fichiers de 1 ko

