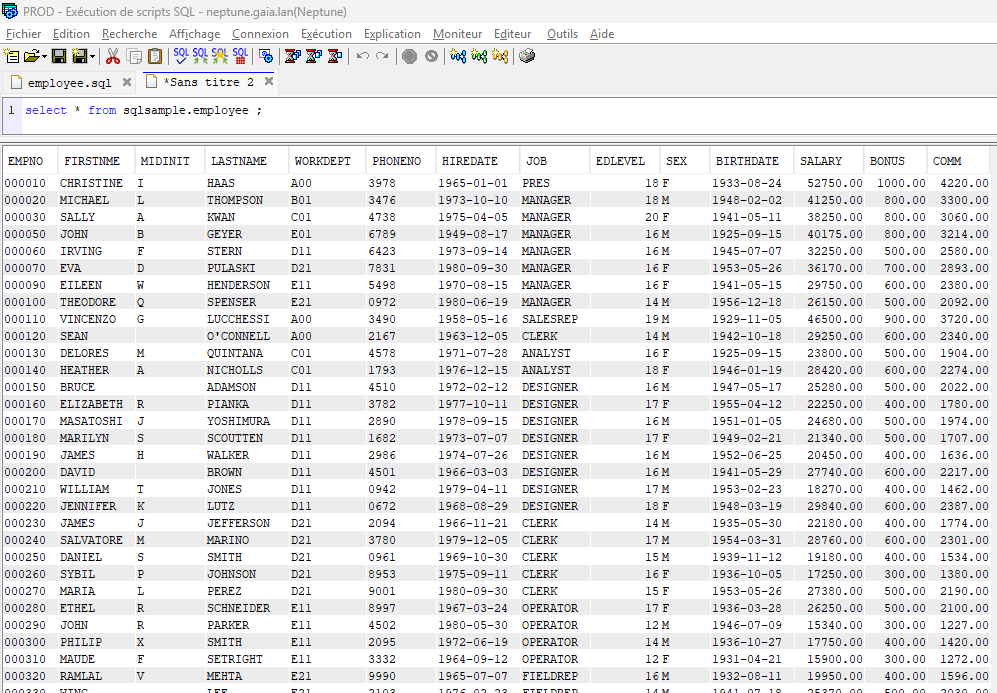
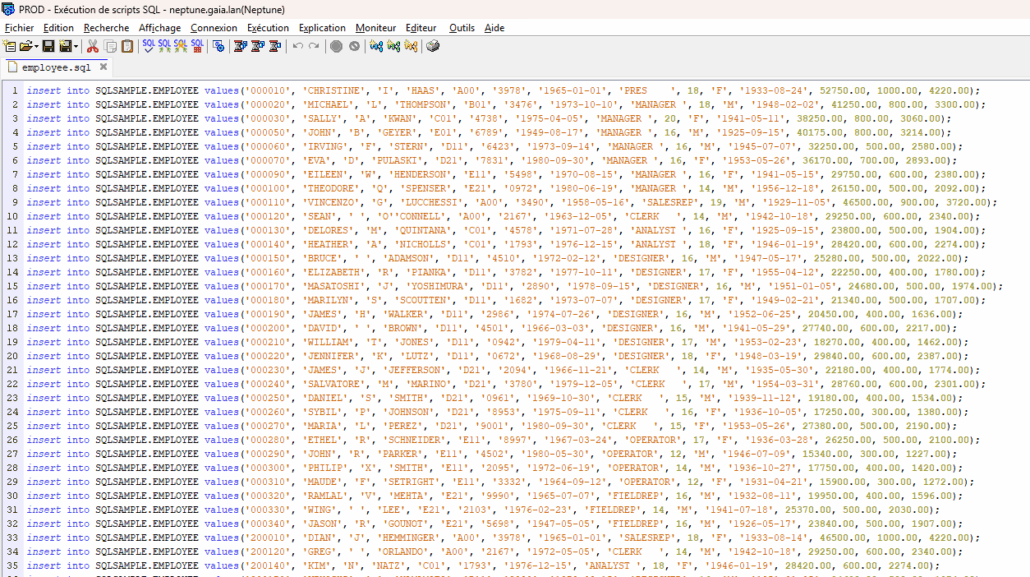
Suite à des demandes multiples, je propose une implémentation de « DUMP » des enregistrements d’une table (plutôt d’un objet *FILE / PF-DTA, que ce soit un PF ou une table).
L’idée est d’obtenir u script SQL contenant les instructions INSERT permettant de reproduire les données dans une autre base.
Premièrement, la réplication de données sans utiliser les commandes de sauvegarde/restauration. Ces dernières nécessitent des droits élevés, alors qu’ici nous ne faisons que manipuler de la donnée.
Deuxièmement, dans le cadre de traitement de journaux (initialement en vue d’une fonction de type CDC), pour permettre d’isoler un enregistrement que l’on souhaite répliquer (avec ou sans transformation) dans une autre table.
Vous trouverez certainement d’autres usages !
Limites
Le code est fourni « as is », pour démonstration.
Quelques limites d’usage actuellement
Types de colonnes non supportées actuellement : CLOB, BLOB, DATALINK, XML, GRAPHIC, VARGRAPHIC, {VAR}CHAR CCSID 65535
Pas plus de 16Mo par enregistrement
On ne gère pas les alias, partitions, IASP
250 colonnes maximum
En cas de multi-membres, seul le premier membre est traité
On peut bien évidemment ajouter de nouvelles fonctionnalités !
N’hésitez pas à donner un feedback, améliorer le code
Dans une base de données bien définie, nos enregistrements sont identifiés par des clés (ie unique). Il existe toutefois différentes façon de matérialiser ces clés en SQL.
Première bonne résolution : on ne parlera pas ici des DDS (PF/LF) !
Quelques rappels
je n’insiste pas, mais une base de donnée relationnelle, DB2 for i dans notre cas, fonctionne à la perfection, à condition de pouvoir identifier nos enregistrements par des clés.
Une normalisation raisonnable pour une application de gestion est la forme normale de Boyce-Codd (dérivée de la 3ème FN).
Clés
Vous pouvez implémenter vos clés de différentes façons, voici une synthèse :
Type
Où
Support valeur nulle ?
Support doublon ?
Commentaire
Contrainte de clé primaire
Table
Non
Non
Valeur nulle non admise, même si la colonne clé le supporte
Contrainte d’unicité
Table
Oui
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Index unique
Index
Oui
Non
Gère des clés uniques. La valeur NULL est supportée pour 1 unique occurrence
Index unique where not null
Index
Ouis
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Attention donc à la définition de UNIQUE : à priori ce qui n’est pas NULL est UNIQUE.
Concrètement ?
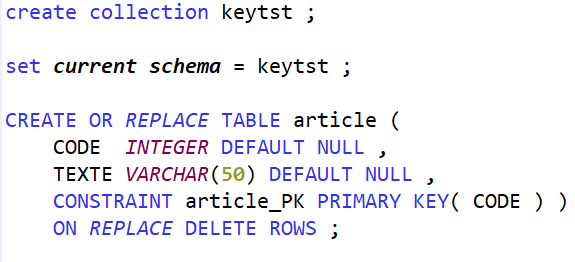
Prenons un cas de test simpliste pour montrer la mécanique : un fichier article avec une clé et un libellé
Clé primaire
La colonne CODE admet des valeurs nulles, mais est fait l’objet de la contrainte de clé primaire.
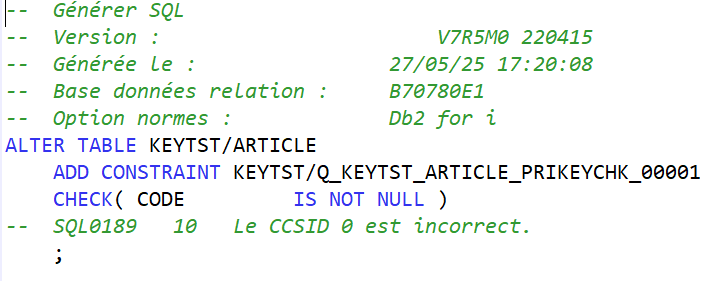
A la création de la contrainte de clé primaire, le système créé automatiquement une contrainte de type CHECK pour interdire l’utilisation de valeur nulle dans cette colonne :
Avec :
La clé primaire joue son rôle avec des valeurs non nulles :
Et des valeurs nulles :
On retrouve ici le nom de la contrainte générée automatiquement !
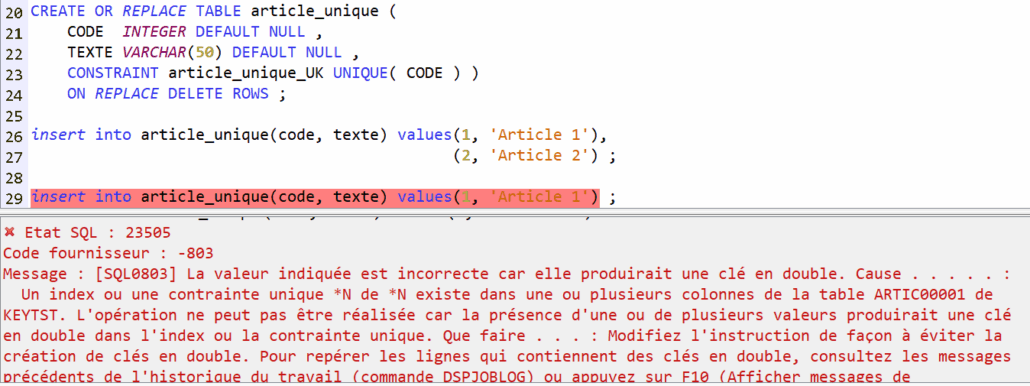
Avec une contrainte de clé unique ?
Le comportement est identique sur une clé non nulle.
Mais avec une clé nulle (ou dont une partie est nulle si elle composée) :
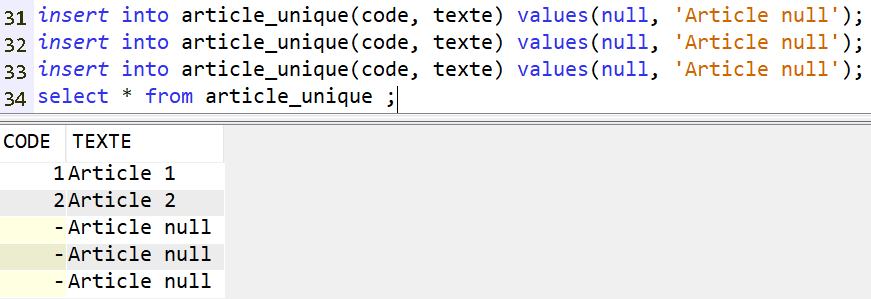
On peut ajouter un index unique pour gérer le problème. Dans ce cas, une et une seule valeur nulle sera acceptée :
Mais dans ce cas pourquoi ne pas utiliser une clé primaire ??
Clé étrangère, jointure
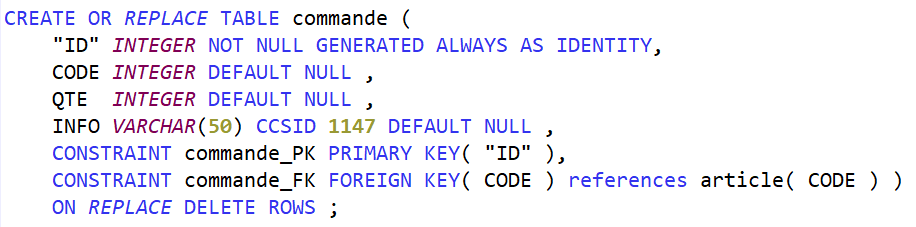
Ajoutons un fichier des commandes, ici une simplification extrême : 1 commande = 1 article.
On ajoute une contrainte de clé étrangère qui matérialise la relation entre les tables commande et article. Pour cette contrainte commande_FK, il doit exister une contrainte de clé primaire ou de clé unique sur la colonne CODE dans la table article.
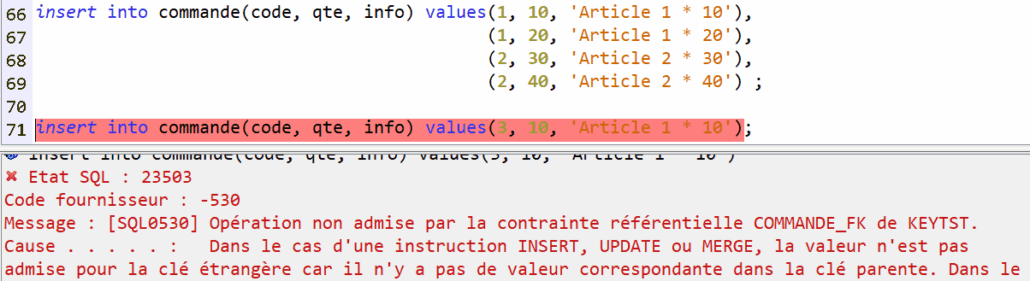
La contrainte se déclenche si l’article référencé n’existe pas :
Cas identique mais en s’appuyant sur la table article_unique qui dispose d’une clé unique et non primaire :
Dans ce cas les valeurs nulles sont supportées, en multiples occurrences (sauf à ajouter encore une fois un index unique au niveau de la commande).
Récapitulons ici nos données pour comprendre les jointures :
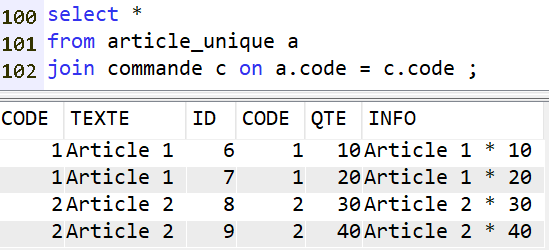
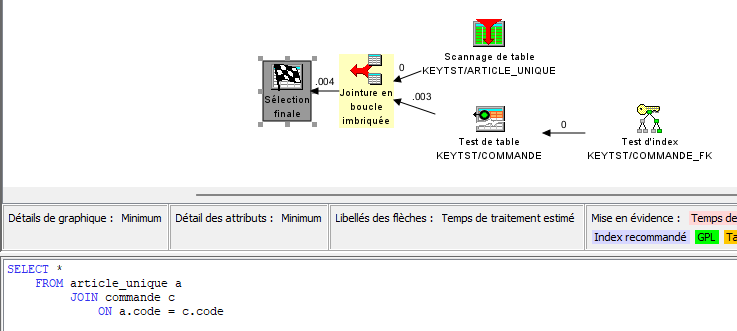
Démarrons par ARTICLE & COMMANDE :
La table ARTICLE ne peut pas avoir de clé nulle, donc pas d’ambiguïté ici
Avec right join ou full outer join nous accèderons au lignes de commande pour lesquelles CODE = null.
C’est le comportement attendu.
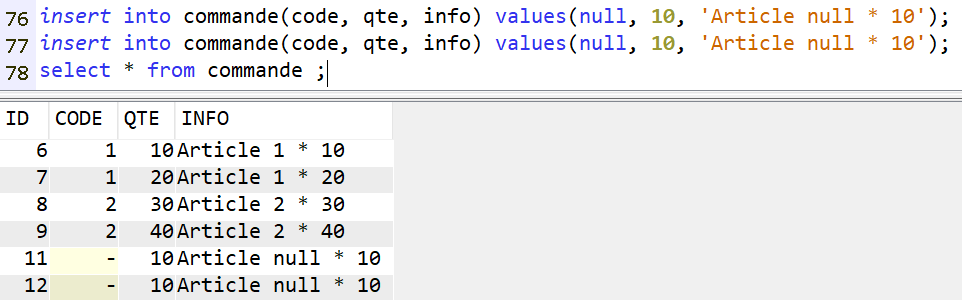
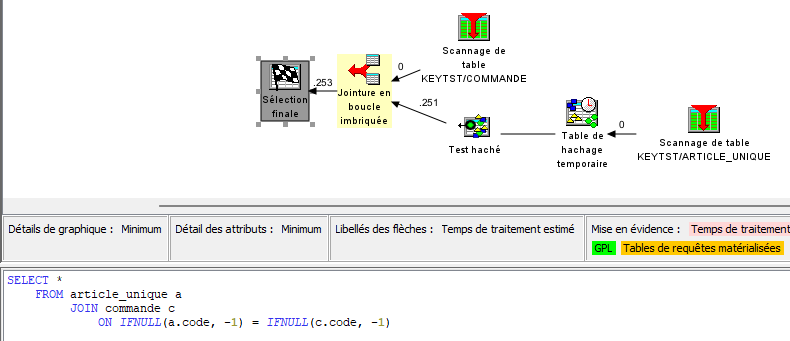
Voyons avec ARTICLE_UNIQUE et COMMANDE :
Ici on pourrait s’attendre à obtenir également les lignes 11 et 12 de la table COMMANDE : le CODE est nulle pour celles-ci, mais il existe une ligne d’ARTICLE pour laquelle le code est null. Il devrait donc y avoir égalité.
En réalité les jointures ne fonctionnent qu’avec des valeurs non nulles
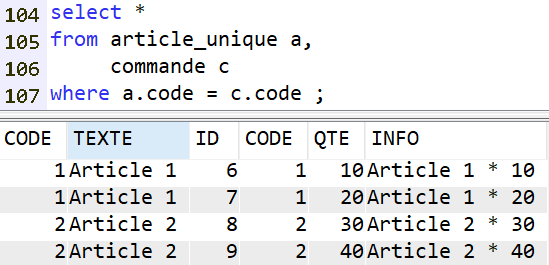
De même que la clause WHERE :
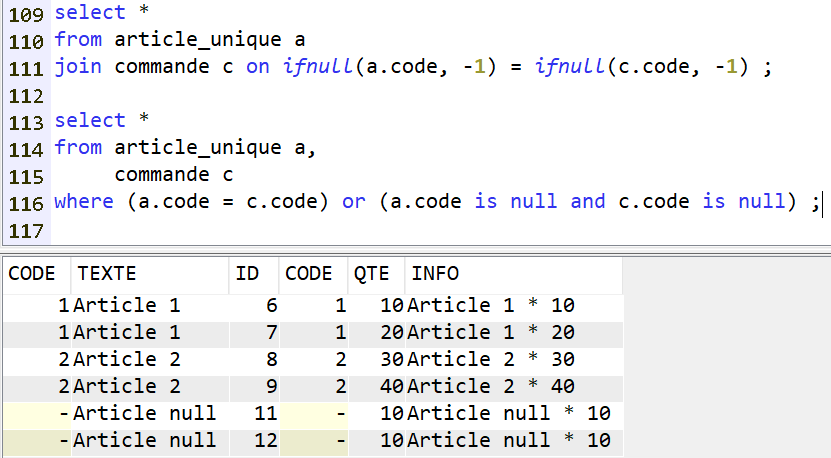
Il faut donc utiliser ce style de syntaxe :
C’est à dire :
soit remplacer les valeurs nulles par des valeurs inexistantes dans les données réelles
soit explicitement indiquer la condition de nullité conjointe
Bref, syntaxiquement cela va rapidement se complexifier dans des requêtes plus évoluées.
Clé composée
Evidemment, c’est pire ! Imaginons que l’on ait une clé primaire/unique dans la table ARTICLE composée de 2 colonnes (CODE1, CODE2), et donc présentes toutes les deux dans la table COMMANDE :
Et les performances ?
En utilisant la jointure, l’optimiseur est capable de prendre en charge des accès par index :
Mais en utilisant IFNULL/COALESCE, ces valeurs deviennent des valeurs calculées, ce qui invalide l’usage des index :
Ce n’est donc pas viable sur des volumes plus importants. Il existe des solutions (index dérivés par exemple) mais la mécanique se complique encore !
Préconisations
De façon générale pour vos données de gestion, en excluant les fichier de travail (QTEMP a d’autres propriétés), les fichiers de logs, les fichier d’import/export …
Pas de valeur NULL dans vos clés
Pour les clés atomique c’est une évidence, pour les clés composées c’est beaucoup plus simple
Une contrainte de clé primaire pour toutes vos tables !
N’hésitez pas à utiliser des clés auto-incrémentées
Des contraintes d’unicités ou des index uniques pour vos autres contraintes d’unicité, techniques ou fonctionnelles
Pas d’excès, sinon il y a un défaut de conception (cf les formes normales)
Si possible des contraintes de clé étrangère pour matérialiser les relations entre les tables
Délicat sur l’existant, les traitements doivent tenir compte du sens de la relation
Favorisez l’usage des clés, contraintes et index par l’optimiseur
Scalabilité entre vos environnements de développement/test et la production
Cela permet de revenir sur le principe de l’implémentation via du code RPG :
Le code est basé sur les APIs QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
Le moteur DB2 appelle l’implémentation :
1 appel initial
1 appel par poste de liste à retourner
1 appel final
Nous utilisons __errno pour retrouver les codes erreur de l’APIs. Les différentes valeurs sont déclarées sous forme de constante.
La fonction SQL retourne les SQL STATE suivants :
02000 lorsque l’on attend la fin des données (fin normale)
38999 pour les erreurs. Cette valeur est arbitraire
Si possible, nous retrouvons le libellé de l’erreur retournée par l’API via strerror et on le retourne à DB2.
Code RPG :
**free
// Compilation / liage :
// CRTRPGMOD MODULE(NB/VLDLUDTF) SRCFILE(NB/QRPGLESRC)
// OPTION(*EVENTF) DBGVIEW(*SOURCE)
// CRTSRVPGM SRVPGM(NB/VLDLUDTF) EXPORT(*ALL) ACTGRP(*CALLER)
// Implémentation de la fonction UDTF VALIDATION_LIST_ENTRIES
// Liste les entrées d'une liste de validation
// Utilise l'API QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
// @todo :
// - ajouter le support de la conversion de CCSID
// - améliorer la gestion des erreurs
ctl-opt nomain option(*srcstmt : *nodebugio) ;
// Déclarations pour APIs : QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
dcl-ds Qsy_Qual_Name_T qualified template ;
name char(10) inz ;
lib char(10) inz ;
end-ds ;
dcl-ds Qsy_Entry_ID_Info_T qualified template ;
Entry_ID_Len int(10) inz ;
Entry_ID_CCSID uns(10) inz ;
Entry_ID char(100) inz ;
end-ds ;
dcl-ds Qsy_Rtn_Vld_Lst_Ent_T qualified template ;
dcl-ds Entry_ID_Info likeds( Qsy_Entry_ID_Info_T) inz ;
dcl-ds Encr_Data_Info ;
Encr_Data_len int(10) inz;
Encr_Data_CCSID uns(10) inz;
Encr_Data char(600) inz ;
end-ds ;
dcl-ds Entry_Data_Info ;
Entry_Data_len int(10) ;
Entry_Data_CCSID uns(10) ;
Entry_Data char(1000) ;
end-ds ;
Reserved char(4) inz ;
Entry_More_Info char(100) inz ;
end-ds ;
dcl-pr QsyFindFirstValidationLstEntry int(10) extproc('QsyFindFirstValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
dcl-pr QsyFindNextValidationLstEntry int(10) extproc('QsyFindNextValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
entryIdInfo likeds(Qsy_Entry_ID_Info_T) ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
// Retrouver le code erreur de l'API
dcl-pr getErrNo int(10) ;
end-pr ;
// Code erreur
dcl-c EACCES 3401 ;
dcl-c EAGAIN 3406 ;
dcl-c EDAMAGE 3484 ;
dcl-c EINVAL 3021 ;
dcl-c ENOENT 3025 ;
dcl-c ENOREC 3026 ;
dcl-c EUNKNOWN 3474 ;
// Retrouver le libellé du code erreur
dcl-pr strError pointer extproc(*CWIDEN : 'strerror') ;
errNo int(10) value ;
end-pr ;
// gestion UDTF
dcl-c CALL_OPEN -1;
dcl-c CALL_FETCH 0;
dcl-c CALL_CLOSE 1;
dcl-c PARM_NULL -1;
dcl-c PARM_NOTNULL 0;
// Liste les entrées de la liste de validation
// ==========================================================================
dcl-proc vldl_list export ;
// Déclarations globales
dcl-s ret int(10) inz ;
dcl-s errno int(10) inz ;
dcl-ds vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) inz static ;
dcl-ds vldlname likeds(Qsy_Qual_Name_T) inz static ;
dcl-s first ind inz(*on) static ;
dcl-pi *n ;
// input parms
pvldl_lib varchar(10) const ;
pvldl_name varchar(10) const ;
// output columns
pEntry_ID varchar(100) ;
pEntry_Data varchar(1000) ;
// null indicators
pvldl_lib_n int(5) const ;
pvldl_name_n int(5) const ;
pEntry_ID_n int(5) ;
pEntry_Data_n int(5) ;
// db2sql
pstate char(5);
pFunction varchar(517) const;
pSpecific varchar(128) const;
perrorMsg varchar(1000);
pCallType int(10) const;
end-pi ;
// Paramètres en entrée
if pvldl_name_n = PARM_NULL or pvldl_lib_n = PARM_NULL;
pstate = '38999' ;
perrorMsg = 'VALIDATION_LIST_LIBRARY ou VALIDATION_LIST_NAME est null' ;
return ;
endif ;
select;
when ( pCallType = CALL_OPEN );
// appel initial : initialisation des variables statiques
vldlname.name = pvldl_name ;
vldlname.Lib = pvldl_lib ;
clear vldListEntry ;
first = *on ;
when ( pCallType = CALL_FETCH );
// retrouver l'entrée suivante
exsr doFetch ;
when ( pCallType = CALL_CLOSE );
// rien à faire
endsl;
// traitement de l'entrée suivante
begsr doFetch ;
if first ;
ret = QsyFindFirstValidationLstEntry( vldlname : vldListEntry);
first = *off ;
else ;
ret = QsyFindNextValidationLstEntry( vldlname :
vldListEntry.Entry_ID_Info : vldListEntry);
endif ;
if ret = 0 ;
// Entrée trouvée
monitor ;
pEntry_ID = %left(vldListEntry.Entry_ID_Info.Entry_ID :
vldListEntry.Entry_ID_Info.Entry_ID_Len);
pEntry_Data = %left(vldListEntry.Entry_Data_Info.Entry_Data :
vldListEntry.Entry_Data_Info.Entry_Data_len) ;
pEntry_ID_n = PARM_NOTNULL ;
pEntry_Data_n = PARM_NOTNULL ;
on-error ;
// Erreur de conversion
pstate = '38999' ;
perrorMsg = 'Erreur de conversion' ;
endmon ;
else ;
// Entrée non trouvée : erreur ou fin de lecture
errno = getErrNo() ;
select ;
when errno in %list( ENOENT : ENOREC ) ; // fin de lecture
pstate = '02000' ;
return ;
other ; // Erreur
pstate = '38999' ;
perrorMsg = %str(strError(errno)) ;
endsl ;
endif ;
endsr ;
end-proc ;
// Retrouver le code erreur de l'API
dcl-proc getErrNo ;
dcl-pr getErrNoPtr pointer ExtProc('__errno') ;
end-pr ;
dcl-pi *n int(10) ;
end-pi;
dcl-s errNo int(10) based(errNoPtr) ;
errNoPtr = getErrNoPtr() ;
return errNo ;
end-proc;
Code SQL :
set current schema = NB ;
set path = 'NB' ;
Create or replace Function VALIDATION_LIST_ENTRIES (
VALIDATION_LIST_LIBRARY varchar(10),
VALIDATION_LIST_NAME varchar(10) )
Returns Table
(
VALIDATION_USER varchar(100),
ENTRY_DATA varchar(1000)
)
external name 'VLDLUDTF(VLDL_LIST)'
language rpgle
parameter style db2sql
no sql
not deterministic
disallow parallel;
cl: DLTVLDL VLDL(NB/DEMO) ;
cl: CRTVLDL VLDL(NB/DEMO) TEXT('Démo VALIDATION_LIST_ENTRIES') ;
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 1',
PASSWORD => 'MDP user 1',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 2',
PASSWORD => 'MDP user 2',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 3',
PASSWORD => 'MDP user 3',
ENTRY_DATA => 'Client 2'));
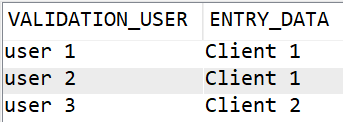
select * from table(VALIDATION_LIST_ENTRIES( VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO' )) ;
Cela produit :
Libre à vous maintenant d’utiliser ce résultat pour jointer avec vos fichiers de log HTTP (autorisation basique sur une liste de validation par exemple), avec le service USER_INFO_BASIC, croiser les profils présents dans vos différentes listes …
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-05-26 11:45:252025-05-26 11:45:26Gérer vos listes de validation avec SQL !
SQL_DB2Contrôler la liste des utilisateurs inscrits à SMTP via sql
Petits rappels en préambule :
SNA n’est plus à utiliser, on le retrouve pourtant encore très souvent en usage sur de nombreux IBM i. Il faut passer au SMTP.
Les utilisateurs SMTP sont inscrits à un registre.
Pour accéder à ce registre on peut passer par la commande 5250 : WRKSMTPUSR – Work with All SMTP Users.
Si vous ne souhaitez pas inscrire tous vos profils au registre SMTP, il est d’usage de créer un profil NOREPLY afin de l’ajouter au registre, puis de soumettre les envois de mail, exemple :
SBMJOB CMD(SNDSMTPEMM RCP(('julien.laurier@gaia.fr')) SUBJECT(TEST) NOTE('This is not a test.')) USER(NOREPLY)
Lors de l’utilisation de la commande SNDSMTPEMM dans un programme, il est préférable de commencer par contrôler la présence du profil dans le registre SMTP. Ce registre est stocké non pas dans une table mais dans un fichier de configuration dans l’ifs : ‘/QTCPTMM/CONFIG/USERS.DAT’. C’est cette liste qui est affichée par WRKSMTPUSR, malheureusement, ces informations ne sont pas adressables directement via SQL. Il nous revient alors de créer nous même de quoi accéder à ces informations pour simplifier ces usages.
Voici une requête SQL qui permet de parser les informations présentes dans le fichier :
SELECT MAX(CASE WHEN entries.ordinal_position = 1 THEN entries.element END) AS "User profile",
MAX(CASE WHEN entries.ordinal_position = 2 THEN entries.element END) AS "SMTP mailbox alias",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 1 THEN details.element END) AS "Domain index",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 2 THEN details.element END) AS "Domain Name",
MAX(CASE WHEN entries.ordinal_position = 4 THEN entries.element END) AS "SDD name compatibility",
MAX(CASE WHEN entries.ordinal_position = 5 THEN entries.element END) AS "SDD address compatibility",
MAX(CASE WHEN entries.ordinal_position = 6 THEN entries.element END) AS "Forwarding to",
MAX(CASE WHEN entries.ordinal_position = 7 THEN entries.element END) AS "Originating from",
MAX(CASE WHEN entries.ordinal_position = 8 THEN entries.element END) AS "Data1",
MAX(CASE WHEN entries.ordinal_position = 9 THEN entries.element END) AS "Data2"
FROM TABLE (qsys2.ifs_read_utf8(path_name => '/QTCPTMM/CONFIG/USERS.DAT',
maximum_line_length => 1024)) AS lines,
TABLE (systools.split(input_list => CAST(lines.line AS VARCHAR(1024)),
delimiter => ' ')) AS entries,
TABLE (systools.split(input_list => CAST(entries.element AS VARCHAR(1024)),
delimiter => ':')) AS details
WHERE line_number > 1
GROUP BY lines.line_number);
Voici un exemple de résultat obtenu :
User profile
SMTP mailbox alias
Domain index
Domain Name
SDD name compatibility
SDD address compatibility
Forwarding to
Originating from
Data1
Data2
FORM01
*NONE
00
*NONE
FORM01
NEPTUNE
*NONE
*NONE
Y
9132
FORM02
*NONE
00
*NONE
FORM02
NEPTUNE
*NONE
*NONE
Y
9134
Pour simplifier encore plus votre usage, je vous propose une vue, ainsi qu’une fonction table :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2025-04-07 21:27:092025-04-08 09:47:08Contrôler la liste des utilisateurs inscrits à SMTP via sql
Retour sur une problématique récurrente et souvent mal comprise, donc mal gérée … Et qui pourrait bien s’amplifier avec l’usage plus intensif de l’Open Source.
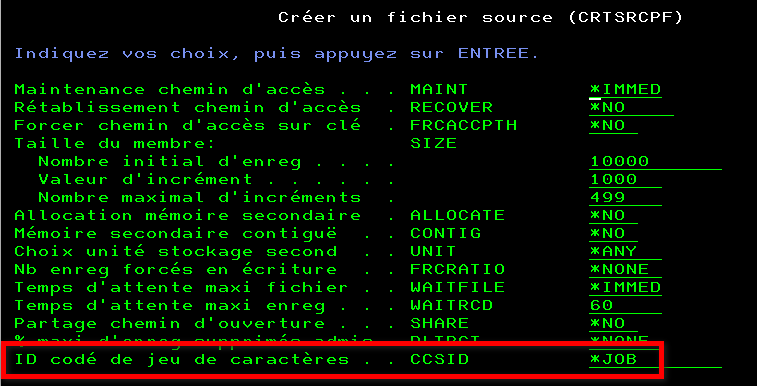
Vous utilisez historiquement des fichiers sources (objet *FILE attribut PF-SRC) pour stocker vos sources : ces fichiers sont créés avec un CCSID, par défaut le CCSID du job dans lequel vous exécutez la commande CRTSRCPF
Usuellement vous obtiendrez des fichiers sources avec un CCSID 297 ou 1147 pour la France. Si vos machines sont « incorrectement » réglées, un CCSID 65535 (hexadécimal).
Mais également, par restauration d’autres produits, certainement des fichiers avec un CCSID 37 (US).
Pour les langages de programmation (dont le SQL), le CCSID du fichier source est important pour les constantes, qui peuvent par définition êtres des caractères nationaux quelconques. Quant aux instructions, la grammaire des langages les définis sans ambiguïtés.
Caractères spéciaux / nationaux
Pour toutes les commandes, instructions, éléments du langage, pas de soucis d’interprétation
A la compilation, les constantes sont interprétées suivant le CCSID du job, pas celui du source !
En général, les deux CCSID sont identiques.
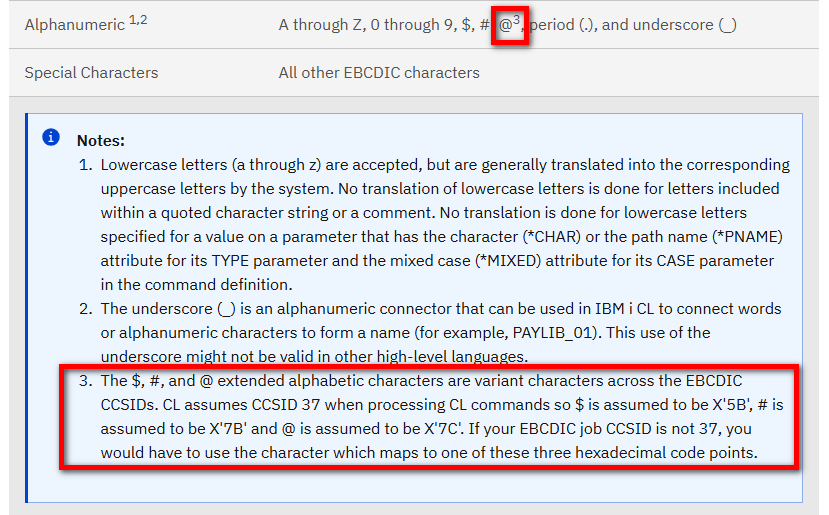
Par contre, pour les caractères spéciaux utilisés, si l’on regarde de plus près le cas du CL, la documentation indique :
Voilà qui explique les fameuses transformations de @ en à !
En synthèse : le compilateur considère tous les éléments du langage comme étant en CCSID 37, hors les constantes alphanumériques et les quelques caractères listés ici.
Pour le CL : impossible d’utiliser les opérateurs symboliques |> (*BCAT), |< (*TCAT) et || (*CAT)
Le caractère | est mal interprété. Vous devez le remplacer par un !, ou utiliser les opérateurs non symboliques (*BCAT, *TCAT et *CAT).
Pour le SQL : impossible d’utiliser l’opérateur || (même raison).
Vous devez le remplacer par un !!, ou utiliser l’opérateur concat.
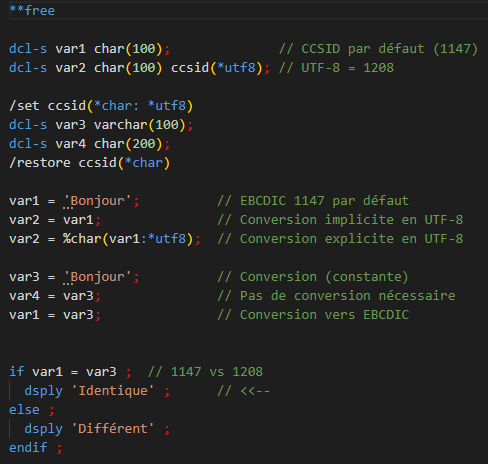
Evolution du RPG
Le principe est le même.
Toutefois le langage vous permet également de contrôler le CCSID des variables déclarées. Et depuis la 7.2, de nouvelles directives de pré-compilation permettent d’indiquer des valeurs de CCSID par défaut par bloc de source :
Et pour l’IFS ?
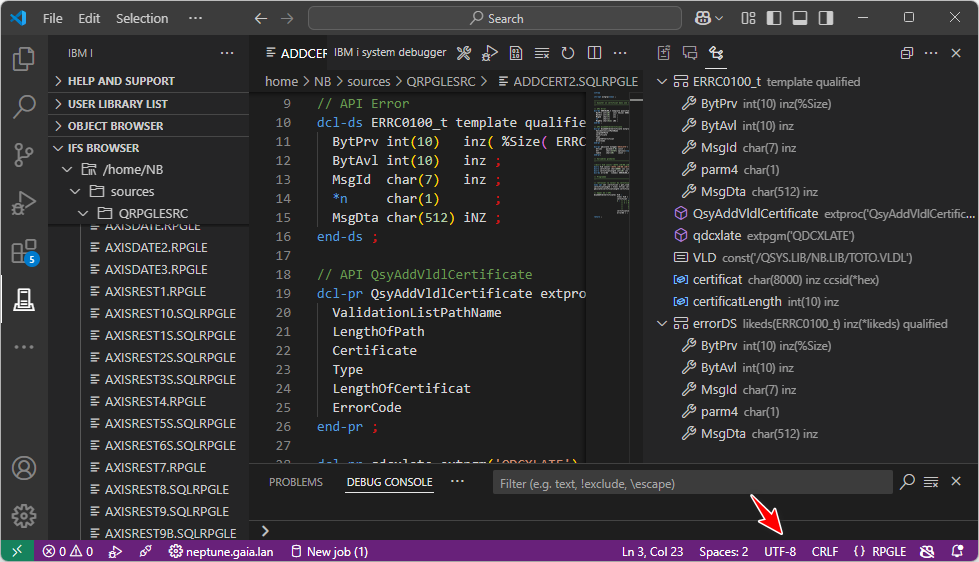
Sur l’IFS, chaque fichier (source ou non) dispose également d’un CCSID. Sa valeur dépend principalement de la façon de créer le fichier (par un éditeur type RDi/VSCode, partage netserver, transfert FTP …).
Premier point d’attention : l’encodage du contenu du fichier doit correspondre à son attribut *CCSID !
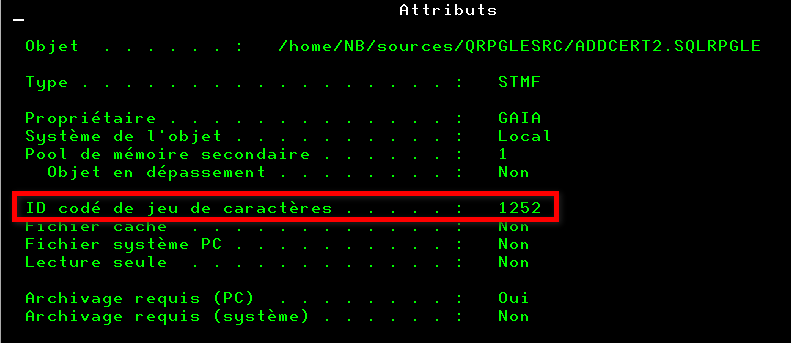
VSCode vous indique le CCSID de la donnée, par exemple :
Mais :
1252 = Windows occidental (proche de l’UTF-8 mais pas identique). La raison est que VSCode travaille naturellement en UTF-8.
RDi gère correctement l’encodage/décodage par rapport à la description du fichier.
Pour les autres outils, à voir au cas par cas !
Evolution des compilateurs
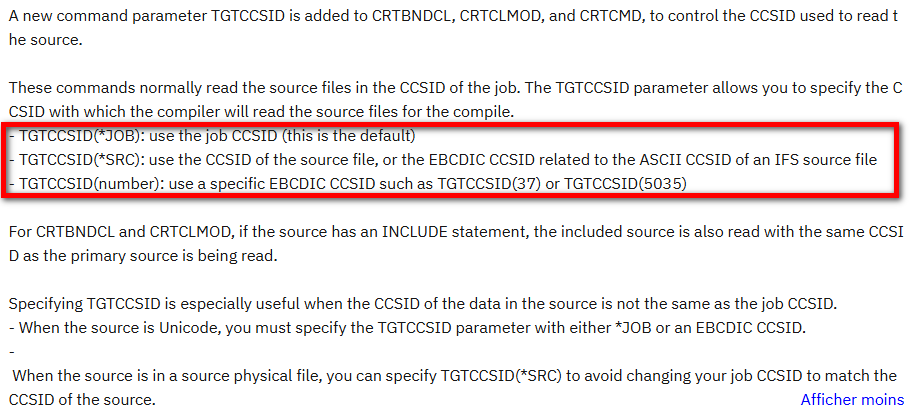
Les compilateurs C, CPP, CL, RPG, COBOL supportent désormais (PTF en fonction des compilateurs) un paramètre TGTCCSID :
En réalité ce paramètre a été ajouté pour permettre la compilation plus facilement depuis l’IFS, principalement depuis des fichiers IFS en UTF-8.
Cela ne règle pas nos problèmes précédents, les éléments du langage n’étant pas concernés : nous auront toujours le problème d’interprétation du |
Par contre, c’est utile pour la bonne interprétation des constantes lorsque le job de compilation a un CCSID du source. Et cela permet une meilleure intégration dans les outils d’automatisation.
Le script propose d’indiquer un CCSID pour les fichiers sources. Mais la seule solution viable est de compiler avec un job en CCSID 37 :
soit CHGJOB CCSID(37) avant de lancer le script
soit vous pouvez vous créer un profil dédié en CCSID 37 si ces opérations sont récurrentes
Tant que vous n’avez pas de caractères nationaux dans le codes !
Retrouver le CCSID de ses fichiers sources
SELECT f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA, c."CCSID" FROM qsys2.systables f JOIN qsys2.syscolumns c ON (c.SYSTEM_TABLE_NAME, c.SYSTEM_TABLE_SCHEMA) = (f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA) WHERE f.file_type = 'S' AND LEFT(f.system_table_name, 8) <> 'EVFTEMPF' AND c.SYSTEM_COLUMN_NAME = 'SRCDTA' ORDER BY c."CCSID", f.SYSTEM_TABLE_SCHEMA, f.SYSTEM_TABLE_NAME;
Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Présentation
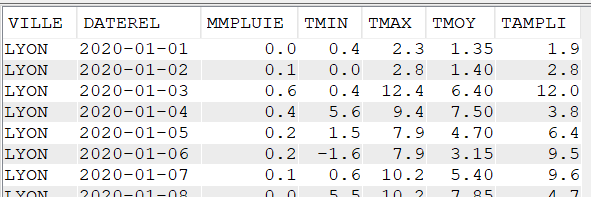
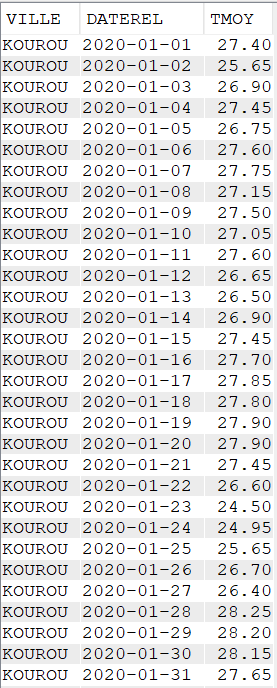
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
La ville
Le jour (AAAA-MM-JJ)
Les précipitations en mm
La température minimale du jour (en °C)
La température maximale du jour (en °C)
La température moyenne du jour (en °C)
L’amplitude de température du jour (en °C)
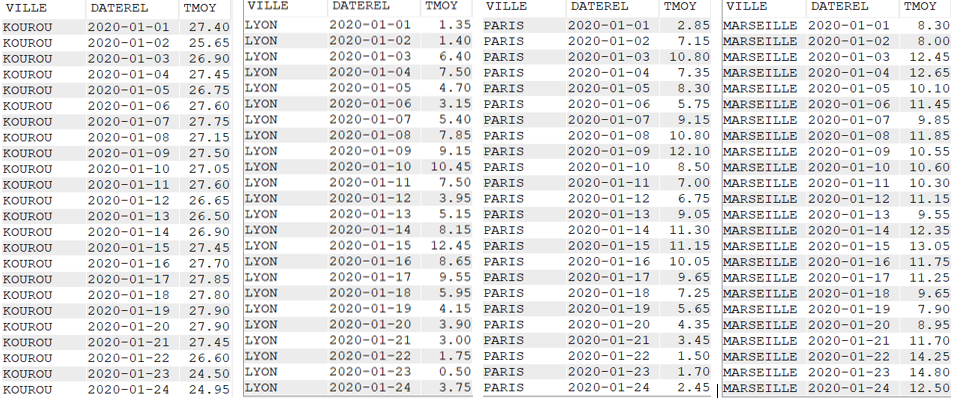
Agréger les données avec LISTAGG
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)
Données brutes
Données avec la fonction LISTAGG
Agréger les données avec GROUP BY
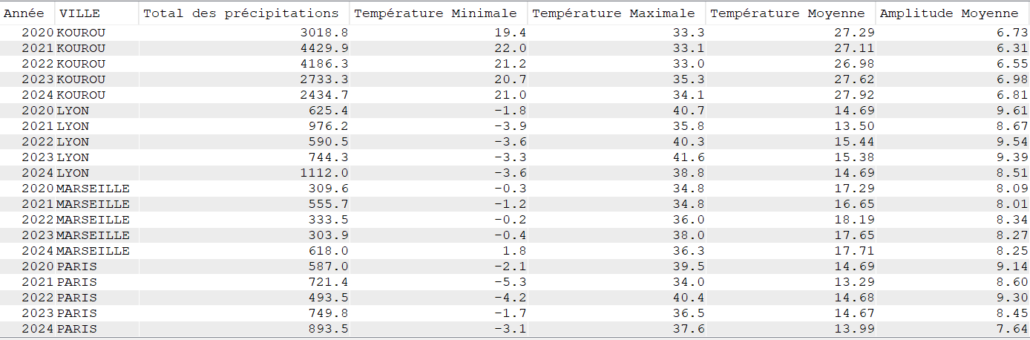
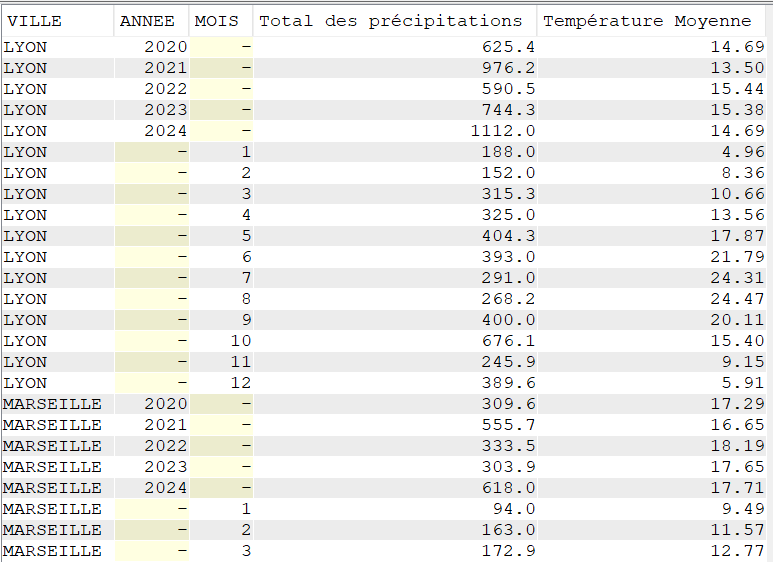
Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
SUM qui va nous permettre de faire le total des précipitations
MIN pour extraire la température minimale
MAX pour extraire la température maximale
AVG pour faire une moyenne (de la température ainsi que de l’amplitude des températures)
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
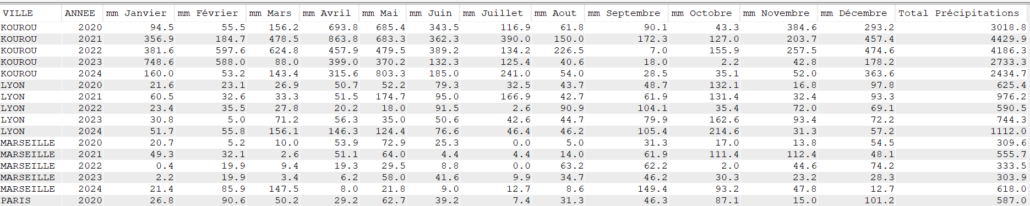
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";
Utilisation de ROLLUP
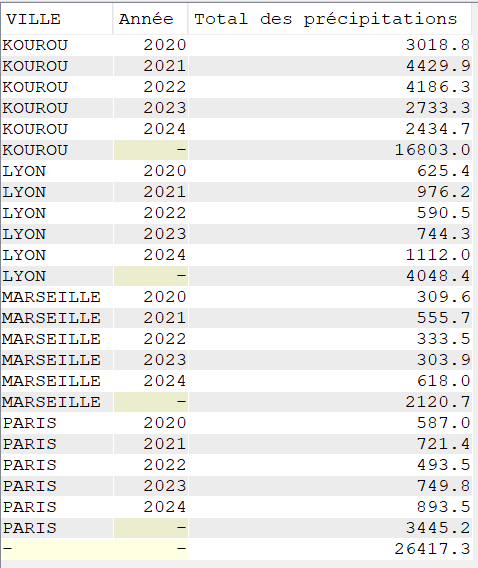
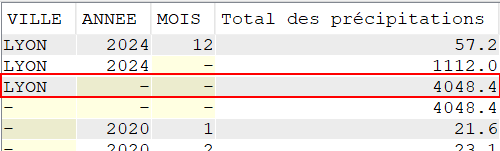
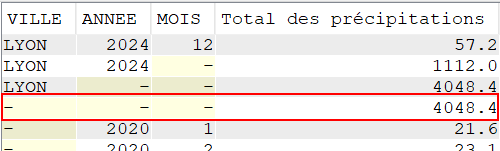
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";
L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
VILLE / ANNEE
VILLE
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
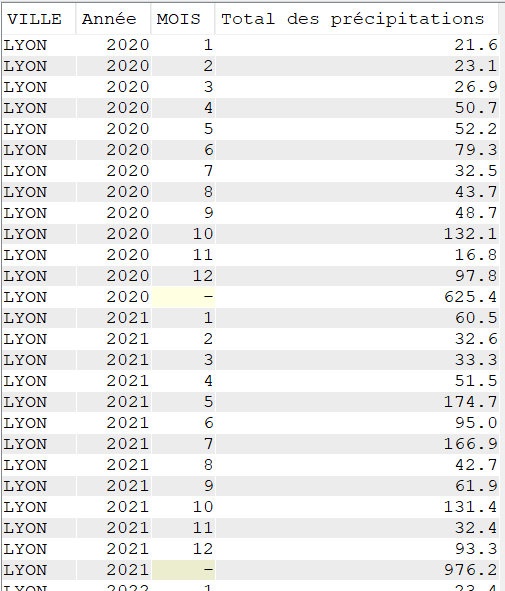
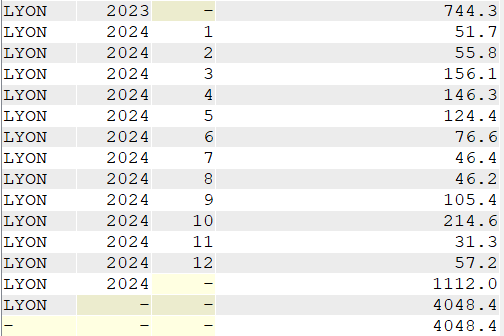
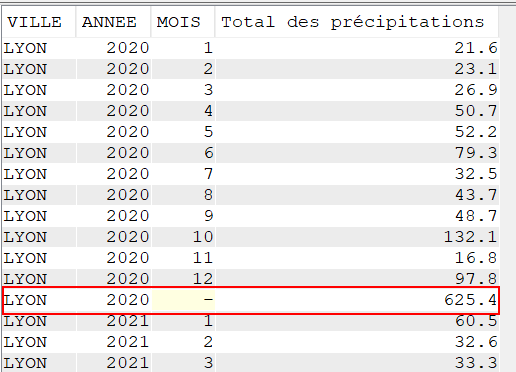
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));
…
…
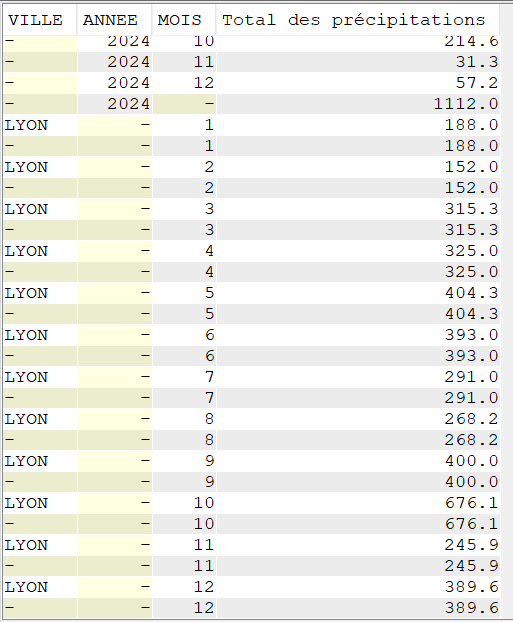
Utilisation de CUBE
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
SELECT VILLE, YEAR(DATEREL) Annee, MONTH(DATEREL) Mois, SUM(MMPLUIE) "Total des précipitations" FROM CLIMAT WHERE VILLE = 'LYON' GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
Par VILLE et ANNEE
Par VILLE et sur la période de mesure
Sur la période de mesure (valeur identique à la précédente car une seule ville sélectionnée ici)
Par VILLE pour chaque mois de la période sélectionnée (ou simplement pour chaque mois de la période sélectionnée)
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Utilisation de GROUPING SETS
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);
Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
Tableau Croisé avec Agrégation et CASE
Avec SUM
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
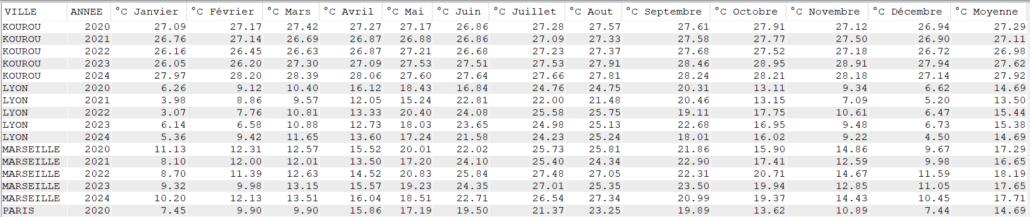
Avec AVG
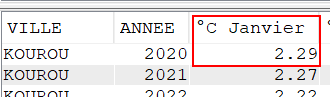
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Note sur l’utilisation de SUM vs AVG dans un tableau croisé
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
Avec ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.
NULL est ignoré par AVG, garantissant une moyenne correcte.
Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)
Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)
Utiliser SQL pour faire une analyse
Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
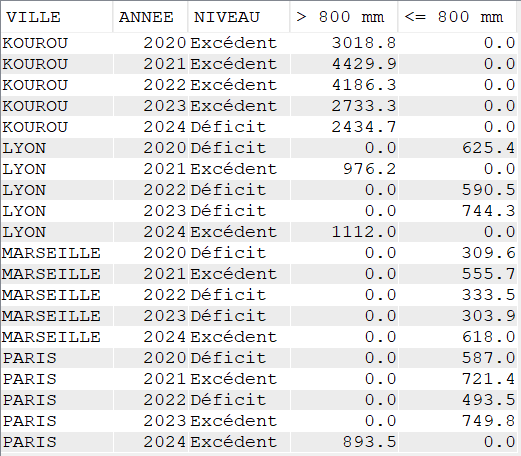
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL);
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2025-03-04 09:03:202025-03-04 09:28:33Regroupements et Analyses avec SQL
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2025-02-17 14:38:202025-02-17 14:44:48Gestion de l’état null dans les SQLRPGLE
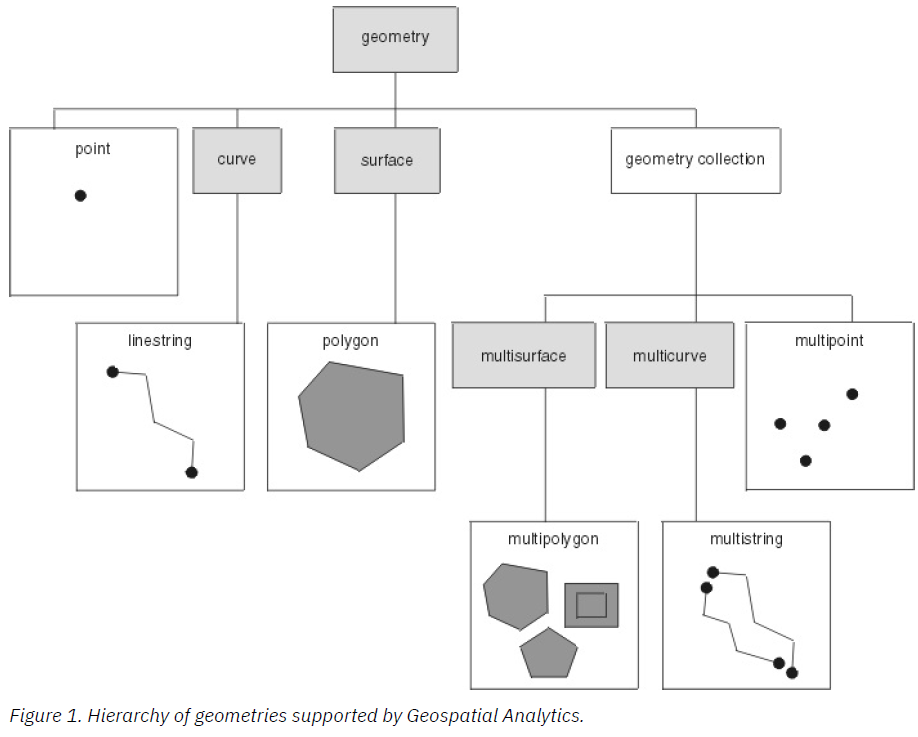
Concernant les fichiers JSON, on observe plusieurs types de géométries, principalement POLYGON et MULTIPOLYGON. C’est pourquoi il nous faut définir dans nos fichiers, une colonne qui puisse englober plusieurs types de géométries. Pour ce faire, le document Database Geospatial Analytics nous fournit quelques informations …
Nous choisirons donc, pour nos fichiers, une colonne basée sur la fonction ST_GEOMETRY, qui nous permet d’englober les deux type nommés ci-dessus. Voici donc comment nous constituerons nos tables.
-- Table des états américains
CREATE TABLE GGEOLOC.US_STATES (
STATE_ID CHAR(2) PRIMARY KEY,
STATE_FULL_NAME VARCHAR(50),
STATE_GEO QSYS2.ST_GEOMETRY);
-- Table des pays
CREATE TABLE GGEOLOC.COUNTRIES (
CODE_ISO VARCHAR(3) PRIMARY KEY,
NAME VARCHAR(50),
CNTRY_GEO QSYS2.ST_GEOMETRY);
-- Table des villes
CREATE TABLE GGEOLOC.MYCITIES (
CTY_NAME VARCHAR(50) ,
CTY_GEO QSYS2.ST_GEOMETRY);
Cet article étant dédié aux fonctions géospatiales, nous n’expliciterons pas la récupération des données.
Bienvenue à bord
ST_ISSIMPLE & ST_GEOMETRYTYPE …
… attachez vos ceintures
ST_ISSIMPLE nous permet de savoir si la géométrie de la figure sélectionnée est simple (valeur 1) ou bon (valeur 0).
SELECT STATE_FULL_NAME,
CASE QSYS2.ST_ISSIMPLE(STATE_GEO)
WHEN 0 THEN 'Geometry is not simple'
WHEN 1 THEN 'Geometry is simple'
END
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
Geometry is not simple
Hawaii
Geometry is simple
Illinois
Geometry is simple
Indiana
Geometry is simple
Wisconsin
Geometry is simple
ST_GEOMETRYTYPE nous permet de savoir de quel type de géométrie nous parlons, et nous pouvons donc constater que la simplicité de la géométrie n’a pas de lien avec le caractère « MULTI » de la figure.
SELECT STATE_FULL_NAME, QSYS2.ST_GEOMETRYTYPE(STATE_GEO)
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
ST_MULTIPOLYGON
Hawaii
ST_MULTIPOLYGON
Illinois
ST_POLYGON
Indiana
ST_POLYGON
Wisconsin
ST_POLYGON
ST_ASTEXT & ST_ASBINARY …
… briefing avant décollage
Si nous exécutons une extraction brute de nos données, on ne comprend pas immédiatement
select STATE_ID, STATE_FULL_NAME, STATE_GEO
from GGEOLOC.US_STATES where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'CO');
ST_AREA nous donne la surface en m² d’une aire géographique (POLYGON ou MULTIPOLYGON)
on ajoute une colonne ici pour avoir une idée de l’aire en km²
select STATE_ID, STATE_FULL_NAME, QSYS2.ST_AREA(STATE_GEO), integer(QSYS2.ST_AREA(STATE_GEO)/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'HI');
AL
Alabama
1.3409800288446873E11
134098
AR
Arkansas
1.3838751120399905E11
138387
HI
Hawaii
1.4748657954505682E10
14748
OK
Oklahoma
1.8250255202012402E11
182502
TX
Texas
6.886199875225208E11
688619
ST_BUFFER nous donne les coordonnées d’une surface élargie du nombre de mètres voulus
voici un exemple de calcul de surfaces en élargissant de 1000 m les frontières de deux états
select STATE_ID, STATE_FULL_NAME, integer(QSYS2.ST_AREA(STATE_GEO)/1000000), integer(QSYS2.ST_AREA(QSYS2.ST_BUFFER(STATE_GEO, 1000))/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'AL');
AL
Alabama
134098
135822
OK
Oklahoma
182502
184806
ST_DISJOINT & ST_WITHIN …
… garder le cap
ST_DISJOINT retourne 1 si deux figures n’ont rien en commun.
select CTY_NAME, CODE_ISO
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where QSYS2.ST_DISJOINT(CTY_GEO, CNTRY_GEO) = 0 ;
HELSINKI
FIN
TEGUCIGALPA
HND
NAIROBI
KEN
GUADALAJARA
MEX
COPENHAGEN
DNK
LYON
FRA
NANTES
FRA
OSLO
NOR
ROCHESTER
USA
ST_WITHIN retourne 1 si la première figure est complètement dans la seconde.
Exemple : Une ville est-elle contenue dans un pays ? Un pays est-il contenu dans une ville ?
select CTY_NAME, CODE_ISO, QSYS2.ST_WITHIN(CTY_GEO, CNTRY_GEO), QSYS2.ST_WITHIN(CNTRY_GEO, CTY_GEO)
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where CTY_NAME in ('LYON', 'ROCHESTER') and CODE_ISO in ('FRA', 'USA') ;
LYON
FRA
1
0
ROCHESTER
FRA
0
0
LYON
USA
0
0
ROCHESTER
USA
1
0
ST_INTERSECTS & ST_INTERSECTION …
… passer la frontière
ST_INTERSECTS nous permet de savoir si deux figures ont une intersection (la fonction retourne 1 si tel est le cas)
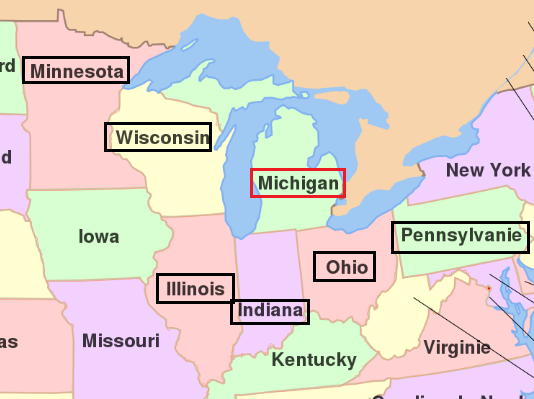
Dans l’exemple suivant, on cherche parmi une liste d’états, à savoir si ceux-ci sont directement voisins du Michigan
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN') ;
Michigan
Illinois
Etats éloignés
Michigan
Indiana
Etats Voisins
Michigan
Minnesota
Etats éloignés
Michigan
Ohio
Etats Voisins
Michigan
Pennsylvania
Etats éloignés
Michigan
Wisconsin
Etats Voisins
Il suffisait de voir la carte pour s’en rendre compte !! Heureusement, ST_INTERSECTION nous en dit beaucoup plus puisqu’elle nous indique la forme de l’intersection entre deux figures géométriques.
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_ASTEXT(QSYS2.ST_INTERSECTION(t1.STATE_GEO, t2.STATE_GEO)),
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
ST_DISTANCE va retourner la distance entre deux points, mais il est intéressant de l’utiliser sur des figures de type POLYGON …
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_DISTANCE(t1.STATE_GEO, t2.STATE_GEO)/1000
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
Michigan
Illinois
58.493941547601004
Michigan
Indiana
0.0
Michigan
Minnesota
33.60195301382611
Michigan
Ohio
0.0
Michigan
Pennsylvania
179.1488383130458
Michigan
Wisconsin
0.0
… pour lesquelles on se rend compte que la fonction retourne la distance (ramenée en km ici) entre les points les plus proches des deux figures comparées.
Atterrissage
Nous n’avons exploré ici qu’une partie des fonctions géospatiales disponibles. Il en existe bien d’autres pour savoir si une figure recouvre complètement une autre, si une figure est contenue dans une autre si une figure en traverse une autre, … Il existe également des fonctions de manipulation des GEOHASHES (système de géocodage basé sur la division d’une zone géographique en cellules).
Bref, tout une panoplie de fonctions que l’on peut combiner à l’infini et au-delà !
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-10-09 18:03:122026-01-15 15:04:38LE TOUR DU MONDE EN 10 (+1) FONCTIONS GEOSPATIALES
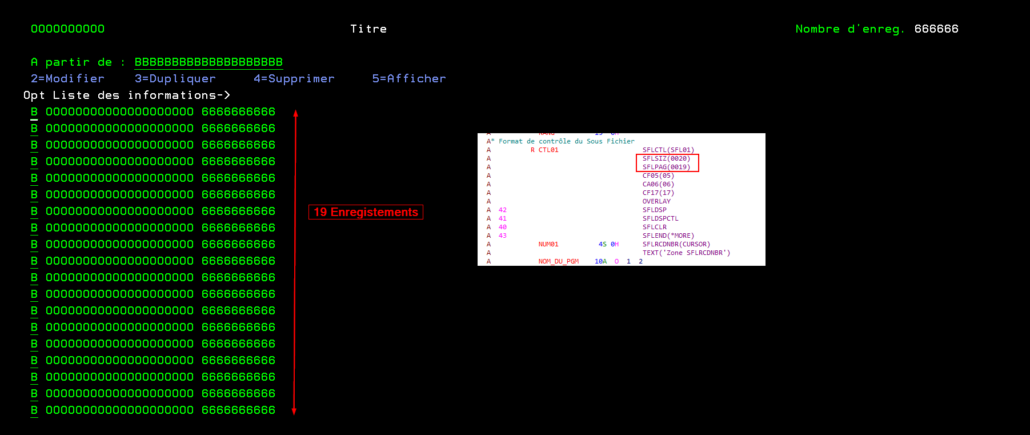
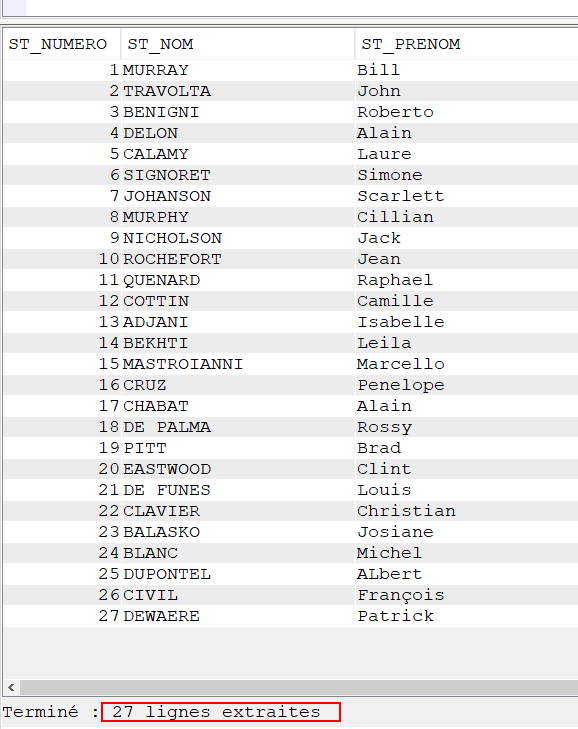
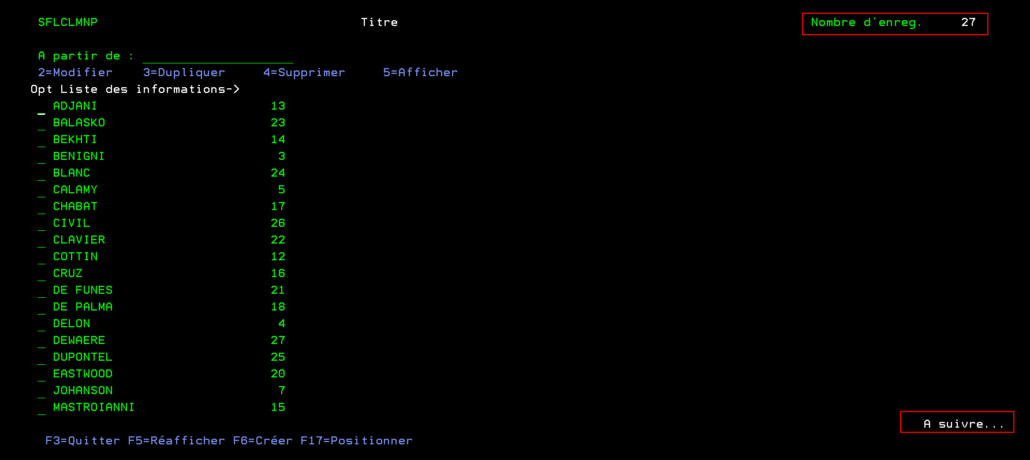
Un sous-fichier nous permet d’afficher un nombre de lignes qui est limité par la taille de l’écran. Cette taille est définie dans le script source de l’écran par le paramètre SFLPAG.
On possède un fichier que l’on souhaite afficher et qui contient plus de 19 enregistrement. Il serait donc intéressant de l’afficher sur plusieurs colonnes.
Solution
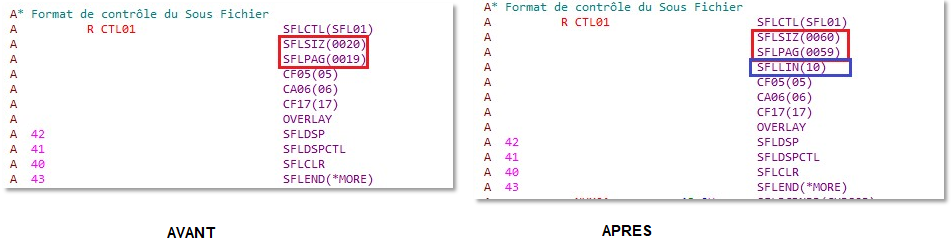
Une petite modification du script source permet de créer un sous fichier qui contient plusieurs colonnes. Il faut donc indiquer le nombre total de données que l’on souhaite voir à l’écran dans SFLPAG ainsi que le nombre de caractère qui séparent deux colonnes
La maquette se présente ainsi, le paramètre de SFLLIN correspond à l’espace (en caractères) entre deux colonnes.
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-07-16 09:38:142024-07-16 09:48:33Afficher plusieurs colonnes d’enregistrements dans un sous-fichier
Depuis la V7R1 (SF99701 – DB2 – niveau 23), on peut invoquer des web service via SQL. Les fonctions se trouvent dans SYSTOOLS.
En V7R4 TR5, sont sorties de nouvelles fonctions, elles se trouvent dans QSYS2.
Outre les fonctions HTTP, celles pour encoder / décoder en base64 et pour encoder / décoder L’URL, ont aussi été implémentées dans QSYS2.
Rappel des différences entre ces fonctions
Tout d’abord les performances. Les fonctions de QSYS2 permettent un gain non négligeable, elles sont basé sur les fonctions AXIS en C natif, contrairement à celles de SYSTOOLS qui sont basées sur des classes java.
Les paramètres dans l’entête ou le corps du message sont transmis en JSON pour les fonctions de QSYS2, à la place de XML pour celle de SYSTOOLS.
La gestion des certificats est simplifiée par l’utilisation de DCM, alors qu’avec les fonctions de SYSTOOLS, il fallait pousser le certificat dans le magasin du runtime java utilisé par les fonctions HTTP. En cas de multiple versions de java installées, il fallait s’assurer de laquelle servait pour les fonctions HTTP. L’ajout du certificat, se faisait via des commandes shell.
Les types et tailles des paramètres des fonctions ont été adaptés pour ne plus être des facteurs limitants de l’utilisation des fonctions SQL, voici quelques exemples :
Certaines utilisations ont aussi été simplifiées en automatisant des tâches.
Prenons l’exemple d’un appel à un web service avec une authentification basique. Le couple profil / mot de passe doit être séparé par « : » et l’ensemble encoder en base64. C’est la norme HTTP.
Dans le cas des fonctions de SYSTOOLS, il fallait effectuer l’ensemble des opérations, alors qu’avec les fonctions de QSYS2, il suffit de passer le profil et le mot de passe dans la propriété BasicAuth. La mise en forme et l’encodage étant faits directement par les fonctions AXIS :
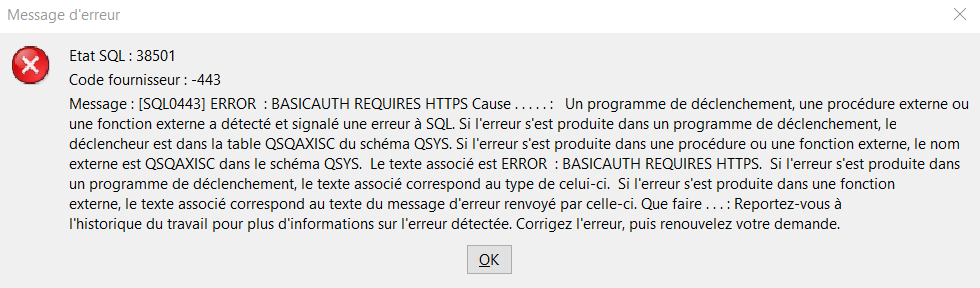
Il y a par contre un cas limitatif des fonctions QSYS2, que IBM a rajouté, alors que la norme HTTP autorise ce type d’appel.
Il s’agit d’avoir une authentification basique sur un appel en http.
Ce cas n’est pas trop contraignant, aujourd’hui le https est la norme et le http quasiment disparu…. quasiment ! Nous rencontrons encore chez nos clients des web services « interne » en http. La migration en https n’étant pas vendeur auprès des directions qui n’y voit aucun gain pour le métier. C’est l’éternel problème des changements structurels en IT.
Dans ces cas, la fonction de QSYS2, renverra une erreur, assez claire !
Le premier réflexe est de voir avec le fournisseur du service s’il ne dispose pas d’une version en https.
Maintenant, si vous n’avez pas d’autre choix que d’appeler un web service en http avec authentification basique, il faudra continuer d’utiliser les fonctions de SYSTOOLS. Dans tous les autres cas, aucune hésitation, utilisez les fonctions de QSYS2.
Mais mettons nous d’accord, de l’authentification basique en http, ce n’est pas de la sécurité, c’est une absurdité.
En http, le message passe en clair sur la trame réseau, avec votre profil / mot de passe, encodé en base 64, et non encrypté, donc en clair eux aussi.
Edit :Précision apportée par Gautier Dumas de CFD-innovation. Merci à lui. On peut contourner le problème avec les fonctions de QSYS2. Il ne faut pas utiliser la propriété BASICAUTH, mais construire l’authentification basique comme on le faisait avec celle de SYSTOOLS. VALUES QSYS2.HTTP_GET( ‘http://hostname/wscommon/api/contacts’, ‘{« header »: »Authorization, BASIC dGVzdHVzZXI6dGVzdHB3ZA== »}’); Il n’y a donc vraiment plus de raison de continuer avec les fonctions de SYSTOOLS !