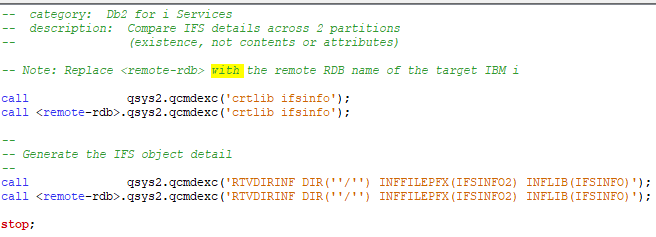
Vous indiquer le nom de votre base de données distantes et vous exécuter votre requête sur le système distant.
derrière cette requête ce cache un protocole nommé DRDA , comme ODBC il permet de ce connecté à une base de donnée distante.
Nous allons voir comment le mettre en œuvre .
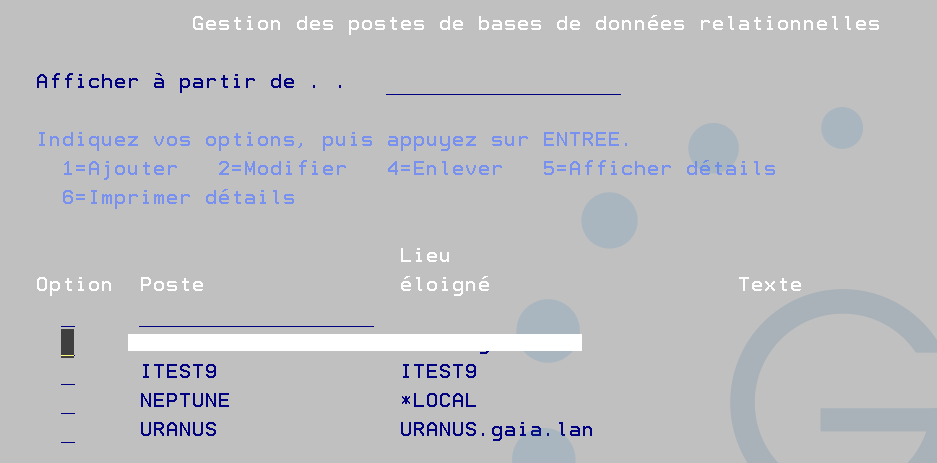
sur le système source Vous devez créer une entrée pour la base de données
le plus simple c’est de passer par la commande WRBRDBDIRE , vous ajouterez une connexion IP à votre système distant.
Sur le système cible Vous devez paramétrer le service par la commande CHGDDMTCPA , il faut avoir le même mode d’authentification que la base de données distante, par défaut user + mot de passe vous devez démarrer le service STRTCPSVR *DDM
voila c’est tout vous pouvez à partir de votre système source faire un connect SQL sur votre système cible si vous avez un mot de passe.
Si vous ne voulez pas renseigner de mot de passe comme dans les exemples ACS vous allez devoir utiliser sur votre système source les postes poste d’authentification serveur. Pour les ajouter vous avez la commande ADDSVRAUTE, vous devrez également avoir mis la valeur système QRETSVRSEC à ‘1’ pour que vos mots de passe soit enregistrés
il est conseillé d’ajouter un poste générique, par exemple QDDMDRDASERVER en indiquant un user et un mot de passe du système cible !
il n’y a pas de commande WRKSRVAUTE mais vous pouvez en trouver une ici https://github.com/Plberthoin/PLB/tree/master/GTOOLS/
Exemple :
A partir de ce moment la mot de passe sera passé directement.
Vous pouvez facilement, par des services sql comparer 2 partitions (valeurs systèmes, fonctions , etc …)
Remarques
Les noms doivent être en majuscule il est conseillé de mettre un programme d’exit de contrôle Attention, vous pouvez vous connecter avec un utilisateur *disabled Les fichier DDM sur IP s’appuient sur cette technologie
Nous allons voir comment l’utiliser NFS sur l’IBMi qui peut être client et serveur par exemple pour partager un fichier d’installation ou de paramétrage.
Sur le serveur
Vous devez démarrer le serveur.
STRNFSSVR SERVER(*ALL)
Vous devez créer le répertoire à exporter
CRTDIR (‘/SHARE_NFS’)
Vous devez monter l’export
Paramétrage dans exports vous avez un fichier
EDTF STMF(‘/etc/exports’) /SHARE_NFS/URANUS -ro
pour exporter
EXPORTFS
Si tout se passe bien vous aurez ce message :
Demande d’exportation exécutée. 1 postes exportés, 0 postes non exportés.
Vous pouvez être obligé de rajouter des droits sur votre partage :
MOUNT TYPE(*NFS) MFS(‘NEPTUNE:/SHARE_NFS/URANUS’) MNTOVRDIR(‘/MNT/NEPTUNE’)
Si tout va bien vous aurez ce message :
Système de fichiers monté.
Vous pouvez contrôler par :
DSPMFSINF OBJ(‘/MNT/NEPTUNE’)
Objet . . . . . . . . . . . . : /MNT/NEPTUNE
Type de système de fichiers . : Syst. de fichiers réseau (NFS)
Taille de bloc . . . . . . . . : 32768 Nombre total de blocs . . . . : 23303175 Blocs libres . . . . . . . . . : 5182808 Nombre maximal de liens à des objets . . . . . . . . . . . : 32767 Nombre maximal de liens à un répertoire . . . . . . . . . : 1000000 Longueur maximale d’un composant de nom de chemin . : 255 Longueur maximale de nom de chemin . . . . . . . . . . . : Pas de maximum
Pour accéder au fichier par exemple :
wrklnk (‘/mnt/NEPTUNE/*’)
Répertoire . . . . : /mnt/NEPTUNE
Vous pourrez voir votre fichier par 5
Remarque :
Vous pouvez l’utiliser que en serveur ou en client avec un système distant sous Linux le plus souvent.
C’est un protocole très connu par les administrateurs Unix.
Pour échanger entre IBMi, vous pouvez également utiliser QFileSvr.400
Vous voulez nommer votre groupe d’activation pour toute une application donc sans indiquer d’option dans le source qui seraient prioritaires par rapport à votre commande de compile
On va parler ici des BIND c’est l’opération que fait une commande pour compiler le module et l’assembler pour en faire un programme
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-29 09:05:152024-08-29 09:05:16Nommer un groupe d’activation pour des programmes RPGLE
Vous voulez connaitre la bibliothèque d’un programme en cours d’exécution, pour ajouter cette bibliothèque par exemple, pour contextualiser un exit programme, un watcher, un trigger ou pour limiter un environnement prod, versus dev. Le tout, sans harcoder une bibliothèque qui figera votre code et vos environnements.
Voici 2 exemples
En RPGLE
dcl-ds *N PSDS ;
bibli_du_pgm CHAR(10) POS(81);
nom_du_pgm CHAR(10) POS(1);
End-ds ;
dcl-s present ind ;
// on tente d'ajouter la bibliothèque
exec sql
call qcmdexc('Addlible ' concat :bibli_du_pgm concat ' *FIRST') ;
if sqlcode = 0 ;
present = *on ;
endif ;
// votre traitement ici
// on enlève si on a ajouté
if present = *on ;
exec sql
call qcmdexc('Rmvlible ' concat :bibli_du_pgm ) ;
endif ;
En CLLE
PGM
DCL VAR(&DATA) TYPE(*CHAR) LEN(80)
DCL VAR(&LIB) TYPE(*CHAR) LEN(10)
DCL VAR(&PGM) TYPE(*CHAR) LEN(10)
DCL VAR(&TEMOIN) TYPE(*LGL)
/* Paramétrage de l'appel */
CHGVAR VAR(%BIN(&DATA 1 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 5 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 9 4)) VALUE( 0)
CHGVAR VAR(%BIN(&DATA 13 4)) VALUE( 0)
/* Appel de la procédure */
CALLPRC PRC('_MATPGMNM') PARM(&DATA)
/* Extraction des informations */
chgvar &pgm %SST(&DATA 51 10)
chgvar &lib %SST(&DATA 19 10)
/* ajout de la bibliothèque */
ADDLIBLE &LIB *FIRST
monmsg cpf2103 exec(do)
chgvar &temoin '1'
enddo
/* Votre traitement ici */
/* on enlève si on a ajouté */
if cond(*not &temoin) then(do)
RMVLIBLE &LIB
enddo
ENDPGM
Remarque :
On a mis également le programme en cours dans les exemples
On a mis le code pour enlever la bibliothèque après le traitement, uniquement si c’est notre programme qui l’a ajouté.
En RPGLE si vous avez un fichier vous devrez déclarer votre fichier en USROPN et ouvrir le fichier par un OPEN, après avoir ajouté la bibliothèque
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-17 09:22:572024-08-20 10:47:56Connaitre la bibliothèque du programme en cours
Que se passe-t-il si on définit soi-même une zone IDENTITY lors de la mise à jour d’une table ?
Ce n’est évidemment pas la meilleure des idées qu’on puisse avoir, mais parfois dans l’urgence d’une correction de données …
Commençons par créer une table de tests avec une zone identité de type bigint :
CREATE TABLE NK.IDENT
(
ID BIGINT GENERATED BY DEFAULT AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER),
NOM_SQL_ZONE_CHAR FOR COLUMN ZONECHAR CHAR(20) NOT NULL DEFAULT '',
CONSTRAINT IDENT_PK PRIMARY KEY( ID)
)
RCDFMT RIDENT ;
RENAME TABLE NK.IDENT TO TESTS_IDENTITY
FOR SYSTEM NAME IDENT;
Les zones qui nous intéressent dans la vue syscolumns de QSYS2 ressemblent à ça :
select column_name,
is_identity,
identity_generation,
identity_minimum,
identity_maximum
from qsys2.syscolumns
where system_table_name ='IDENT'
and system_table_schema ='NK'
order by ordinal_position;
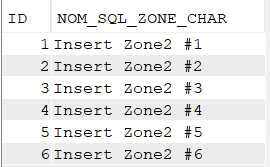
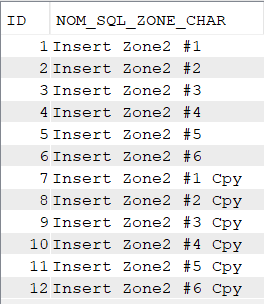
Alimentation de la table avec quelques enregistrements
insert into nk.ident (Zonechar) values ('Insert Zone2 #1');
insert into nk.ident (Zonechar) values ('Insert Zone2 #2');
insert into nk.ident (Zonechar) values ('Insert Zone2 #3');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #4');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #5');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #6');
On peut ignorer ID ou le renseigner en DEFAULT, la table est alimentée :
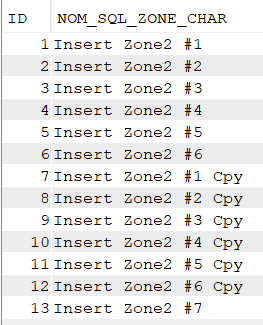
select * from nk.ident;
Que se passe-t-il si je définis moi-même ID lors d’un insert ?
Si l’identity est déjà occupée par un enregistrement : SQL n’accepte pas l’instruction, il fait ce qu’on lui a demandé !
insert into nk.ident (ID, Zonechar) values (1, 'Insert KO');
Si je fais des insertions de données dans IDENT en définissant moi-même des ID libres :
insert into nk.ident
select id+6, trim(zonechar) || ' Cpy' from nk.ident;
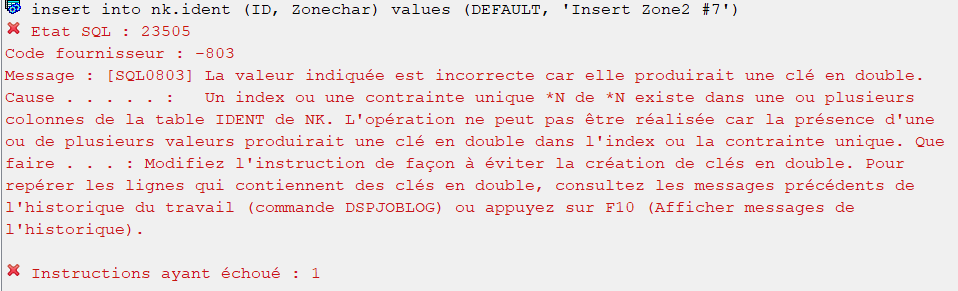
Mais si je refais une insertion de données en laissant à nouveau SQL gérer l’identity :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
On consulte la log du travail comme le message d’erreur nous invite :
select message_second_level_text
from table(qsys2.joblog_info('111778/QUSER/QZDASOINIT'))
where message_id = 'CPF5009';
Deux enregistrements sont trouvés :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti.Le membre numéro 1 (enregistrement numéro 1, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 7, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Le premier message est relatif à la tentative d’insertion « insert into nk.ident (ID, Zonechar) values (1, ‘Insert KO’); » tentée plus haut et pour laquelle l’erreur était attendue.
Le second message est relatif à «insert into nk.ident (ID, Zonechar) values (DEFAULT, ‘Insert Zone2 #7’); »
SQL a tenté d’utiliser la valeur suivante de la dernière identity qu’il a lui-même géré, mais a échoué car la valeur IDENT.ID=7 existe déjà.
Si on retente l’insertion qui vient juste d’échouer :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
Elle échoue de la même façon, sauf que cette fois SQL a tenté d’utiliser l’ID = 8 :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 8, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Comment corriger la situation ?
La solution pour se sortir de là si on a fait 3000 insertions ne va pas être de tenter 3000 insertions bidons pour que la table ait son compteur interne gérant l’identity à jour (d’ailleurs, si quelqu’un sait où il se cache je suis preneur).
On récupère la dernière ID utilisée dans la table :
select max(ID) from nk.ident ;
Et on ajoute 1 pour mettre à jour la table :
alter table nk.ident
alter column id restart with 13;
L’instruction précédente :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
se passe bien maintenant et la numérotation de IDENT.ID a bien repris normalement :
select * from nk.ident;
Pour se prémunir de tout ceci, il suffit de vérifier la nature de la clé primaire d’une table avant de commencer à y insérer des enregistrements.
Sur DB2 l’usage d’IDENTITY dans une table SQL n’est pas très répandu, il est donc nécessaire de comprendre la structure d’une table avant de l’utiliser. L’IDENTITY se révèle alors pratique tant qu’on laisse le système la gérer. On peut bien sûr, dans des cas exceptionnels, la gérer soi-même si on fait attention…
/wp-content/uploads/2017/05/logogaia.png00Nicolas kintz/wp-content/uploads/2017/05/logogaia.pngNicolas kintz2024-08-13 09:51:272024-08-13 09:51:28Gestion de l’IDENTITY d’une table
Vous avez des sources SQLRPGLE qui sont différents des tailles par défaut de 100
Vous pouvez avoir ce message à la compile RNF0733 C’est le fichier, QTEMP/QSQLPRE de pré-compilation qui est trop court QTEMP/QSQLPRE Ce fichier est utilisé dans les commandes CRTBNDRPG , CRTRPGMOD, ou CRTSQLRPGI
Vous avez une variable d’environnement QIBM_RPG_PPSRCFILE_LENGTH qui permet de changer la valeur par défaut qui est de 112. Elle doit avoir la longueur de votre donnée + 12 Exemple SRCDTA = 140 Vous devrez indiquer 152
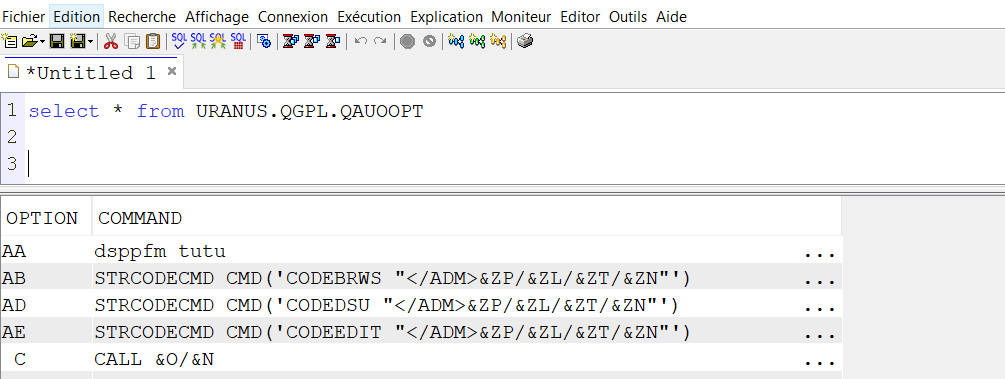
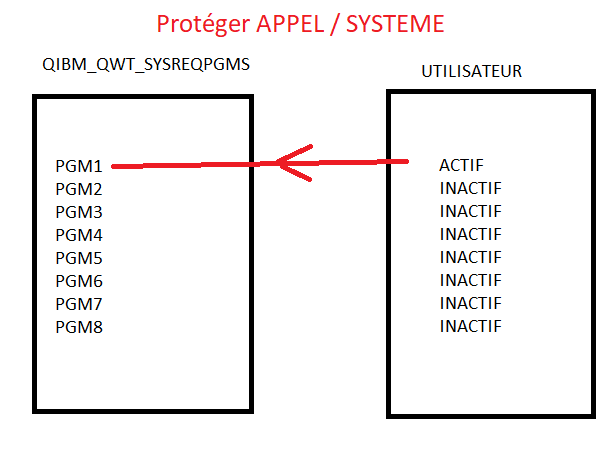
Vous voulez protéger vos sessions 5250 de la possibilité de faire un Appel systéme
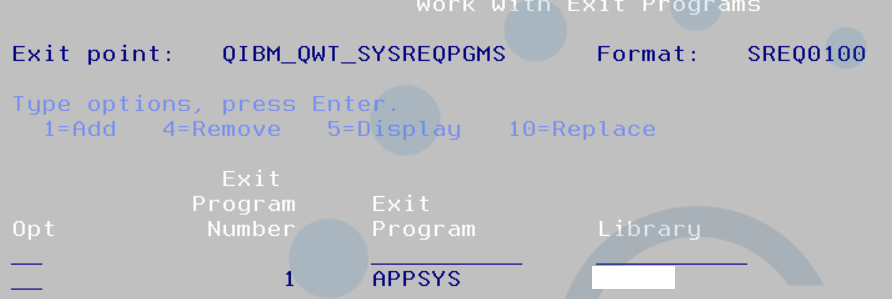
Vous devez mettre en place un programme d’exit (8 possibles)
QIBM_QWT_SYSREQPGMS
Vous devez ensuite indiquer sur chaque profil les programmes à utiliser
Schéma ci dessous
L’utilisateur quand il appuiera sur APP SYST le programme PGM1 sera appelé
Programme Exit ici le 1 , nom du programme APPSYS
**free
// programme QIBM_QWT_SYSREQPGMS contrôle d'accès à la touche
// ATTN REQUEST
// l'utilisateur à ce programme de contrôle son profil il s'exécute
// et il n'a pas le droit
ctl-opt
DFTACTGRP(*NO) ;
Dcl-Pi *N;
Reponse int(10);
// 1 ok
// 0 ko
data Char(128);
End-Pi;
//
Reponse = 0;
*inlr = *on ;
GDATA_QRPGLESRC_APPSYS.TXT
Affichage de GDATA_QRPGLESRC_APPSYS.TXT en cours...
Ce programme est simple , il interdit s’il est appelé
Analyse par les fichiers supports ( c’est des fichiers modèles qui sont dans QSYS ) CRTDUPOBJ OBJ(QAWCTPJE) FROMLIB(QSYS) OBJTYPE(*FILE) TOLIB(Votrebib) NEWOBJ(QPFRADJTP)
pour analyser le suivi ici du pour des travaux interactifs
SELECT TPPNAM, TPFLG1, TPCSIZ, TPCRES, TPCACT, TPDFLT, TPNFLT, TPWI, TPAW, TPCJOB, TPAJOB, TPNSIZ, TPNACT FROM Votrebib/QPFRADJTP WHERE TPPNAM = ‘*INTERACT’ order by TPDATE, TPTIME
Deuxième exemple, voir les ports filtrés sur votre partition
Analyse par services SQL
create table votrebib.analyse as( WITH Log_Port AS ( SELECT CAST(ENTRY_DATA AS VARCHAR(1000)) AS entry FROM TABLE ( QSYS2.DISPLAY_JOURNAL(‘QUSRSYS’, ‘QIPFILTER’, JOURNAL_ENTRY_TYPES => ‘TF’) ) ) SELECT SUBSTR(entry, 1, 10) AS line, SUBSTR(entry, 29, 15) AS AdrSrcIp, SUBSTR(entry, 44, 5) AS SrcPort, SUBSTR(entry, 49, 15) AS AdrDestIp, SUBSTR(entry, 64, 5) AS DestPort FROM Log_Port ) WITH DATA;
Remarques
Certains journaux sont en standard , d’autres devront être démarrés Si vous n’analysez pas ne les démarrer pas Pensez à faire le ménage dans les récepteurs si vous les démarrez
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-02 09:13:592024-08-14 15:49:25Utilisez les journaux Système
Open sourceMise en place d’une documentation Sphinx sur IBM i
Introduction
Introduction
Cet article à pour but de présenter la possibilité d’exploiter diverses solutions libres et gratuites très répandues dans le monde OpenSource. L’objectif est de découvrir Sphinx, un outil de génération de documentation sous forme de site web. Il est notamment utilisé pour réaliser les documentations suivantes :
La référence de l’OpenSource sur IBM i, IBM i OSS Docs – ici
Nous allons donc voir en quelques étapes simples comment publier et maintenir votre documentation directement sur votre IBM i.
Prérequis
PASE (IBM Portable Application Solutions Environment for i)
Environnement OpenSource sur l’IBM i
Python sur votre IBM i (Pour rappel, les modules OpenSource comme python sont compilés et mis à disposition par IBM spécialement pour l’IBM i, il n’y a pas plus de risque à les utiliser qu’à utiliser des logiciels sous licence)
Etape 1 – Mise en place de l’environnement
Cette section est réalisée via qsh, qp2term ou ssh.
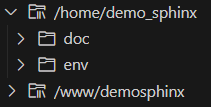
Le projet sera structuré comme suit :
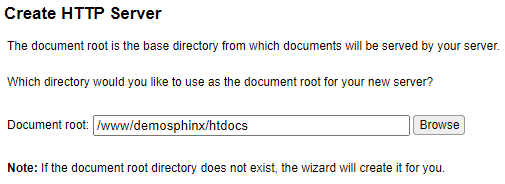
/home/demosphinx sera le répertoire du projet, il contiendra les sources (doc/) et l’environnement de travail python (env/). /www/demosphinx sera le répertoire du serveur Apache permettant de publier localement la documentation
Une fois l’arborescence créée, on installe ou met à jour Python 3.9 :
$ yum install python39
On crée ensuite un environnement virtuel pour python afin d’éviter d’être impacté par des changements de versions et pour isoler notre environnement de travail :
// Création de l'environnement virtuel Python
$ python3.9 -m venv --system-site-packages /home/demosphinx/env
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Mise à jour du gestionnaire de paquets python (pip)
(env) $ pip install --upgrade pip
// Installation et mise à jour de Sphinx
(env) $ pip install --upgrade sphinx
// Installation du thème ReadTheDocs (Facultatif)
(env) $ pip install sphinx-rtd-theme
D’autres modules peuvent être intéressant, comme myst-parser (qui permet notamment d’utiliser du MarkDown pour rédiger sa documentation) et sphinx-jinja (qui permet l’usage de variables dans les pages). Il existe également une grande quantité de thèmes natifs présentés ici et des thèmes tiers présentés ici.
Etape 2 – Création du projet
Cette section est réalisée via qsh, qp2term ou ssh.
L’environnement en place on peut très simplement créer notre documentation.
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Positionnement dans le répertoire du projet
$ cd /home/demosphinx/doc
// Génération du projet
$ sphinx-quickstart
On arrive ensuite sur un assistant qui va nous guider pour saisir les informations de base nécessaires à la documentation (qui seront toujours modifiables dans les sources de la documentation) : Le nom du projet, ceux des auteurs, la version, la langue de la documentation, etc… Voici un exemple :
Bienvenue dans le kit de démarrage rapide de Sphinx 7.3.7.
Veuillez saisir des valeurs pour les paramètres suivants (tapez Entrée pour accepter la valeur par défaut, lorsque celle-ci est indiquée entre crochets).
Chemin racine sélectionné : .
Vous avez deux options pour l'emplacement du répertoire de construction de la sortie de Sphinx.
Soit vous utilisez un répertoire "_build" dans le chemin racine, soit vous séparez les répertoires "source" et "build" dans le chemin racine.
> Séparer les répertoires source et de sortie (y/n) [n]: y
Le nom du projet apparaîtra à plusieurs endroits dans la documentation construite.
> Nom du projet: SphinxOnIBMi
> Nom(s) de(s) l'auteur(s): Gaia Mini Systèmes
> Version du projet []: v0
Si les documents doivent être rédigés dans une langue autre que l'anglais, vous pouvez sélectionner une langue ici grâce à son id entifiant. Sphinx utilisera ensuite cette langue pour traduire les textes que lui-même génère.
Pour une liste des identifiants supportés, voir
https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language.
> Langue du projet [en]: fr
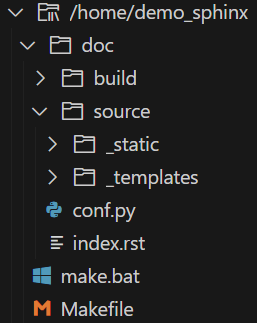
Fichier en cours de création /home/demosphinx/doc/source/conf.py.
Fichier en cours de création /home/demosphinx/doc/source/index.rst.
Fichier en cours de création /home/demosphinx/doc/Makefile.
Fichier en cours de création /home/demosphinx/doc/make.bat.
Terminé : la structure initiale a été créée.
Vous devez maintenant compléter votre fichier principal /home/demosphinx/source/index.rst et créer d'autres fichiers sources de documentation. Utilisez le Makefile pour construire la documentation comme ceci :
make builder
où « builder » est l'un des constructeurs disponibles, tel que html, latex, ou linkcheck.
Le projet de documentation est maintenant généré !
Les différentes pages sont à ajouter dans le répertoire source/ :
index.rst (ou index.md si le module MarkDown est installé) – Il s’agit du point d’entrée de la documentation.
conf.py contient les informations de création de la documentation comme le thème, la langue, les différents format interprétés, etc…
Voici un exemple de fichier de configuration :
# Configuration file for the Sphinx documentation builder.
#
# For the full list of built-in configuration values, see the documentation:
# https://www.sphinx-doc.org/en/master/usage/configuration.html
# -- Project information -----------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
project = 'SphinxOnIBMi'
copyright = '2024, Gaia'
author = 'Gaia'
# -- General configuration ---------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
extensions = []
templates_path = ['_templates']
exclude_patterns = []
language = 'fr'
# -- Options for HTML output -------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
html_theme = 'alabaster'
html_static_path = ['_static']
Les différents fichiers sources peuvent être édités directement sur l’IBM i via VSCode, RDi…
Etape 3 – Création de la page Apache via HTTPAdmin
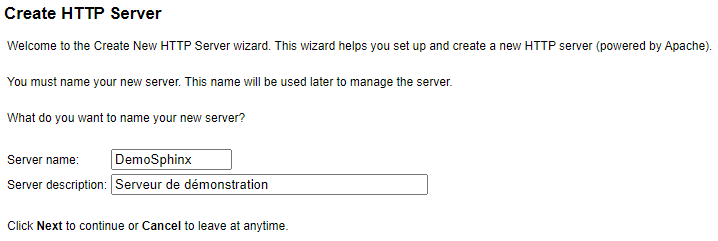
Cette section est réalisée via HTTPAdmin.
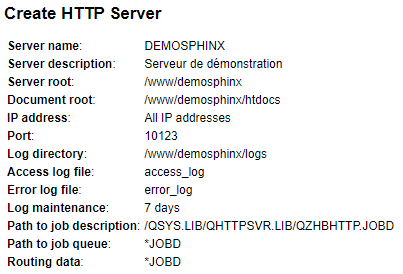
Avant de générer la documentation en tant que telle, créons un petit serveur Apache basique (on pourrait tout à fait utiliser une instance nginx). Pour se faire nous allons passer par HTTPAdmin afin d’exploiter l’assistant de configuration pour créer le serveur :
L’instance Apache est maintenant créée :
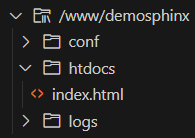
Pour éviter les problèmes de CCSID, il est préférable de supprimer au préalable le fichier index.html qui sera regénéré par Sphinx.
Etape 4 – Génération de la documentation
Cette section est réalisée via qsh, qp2term ou ssh.
Revenons sur notre environnement PASE pour générer la documentation, pour cela, une simple commande suffit :
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Génération de la documentation vers le répertoire de l'instance Apache
$ sphinx-build -b html /home/demosphinx/doc/source /www/demosphinx/htdocs -E
Sphinx v7.4.7 en cours d'exécution chargement des traductions [fr]... fait
construction en cours [mo] : cibles périmées pour les fichiers po 0
Écriture...
construction [html] : cibles périmées pour les fichiers sources 1
mise à jour de l'environnement : [nouvelle configuration] 1 ajouté(s), 0 modifié(s), 0 supprimé(s)
lecture des sources... [100%] index
Recherche des fichiers périmés... aucun résultat trouvé
Environnement de sérialisation... fait
vérification de la cohérence... fait
documents en préparation... fait
copie des ressources...
Copie des fichiers statiques... fait
copie des fichiers complémentaires... fait
copie des ressources: fait
Écriture... [100%] index
génération des index... genindex fait
Écriture des pages additionnelles... search fait
Export de l'index de recherche en French (code: fr)... fait
Export de l'inventaire des objets... fait
La compilation a réussi.
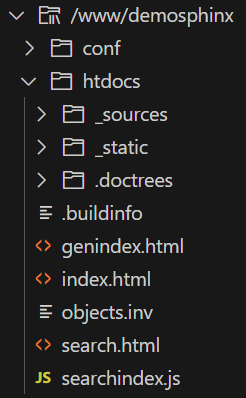
Les pages HTML sont dans /www/demosphinx/htdocs.
Voici les fichiers produits par la génération, directement dans notre instance Apache :
On voit entre autre le script Java Script, searchindex.js, un moteur de recherche intégré directement dans la documentation, l’un des gros points forts de Sphinx.
Démarrage de l’instance et résultat
On peut démarrer notre instance via HTTPAdmin :
Ou via 5250 et la commande :
STRTCPSVR SERVER(*HTTP) HTTPSVR(DEMOSPHINX)
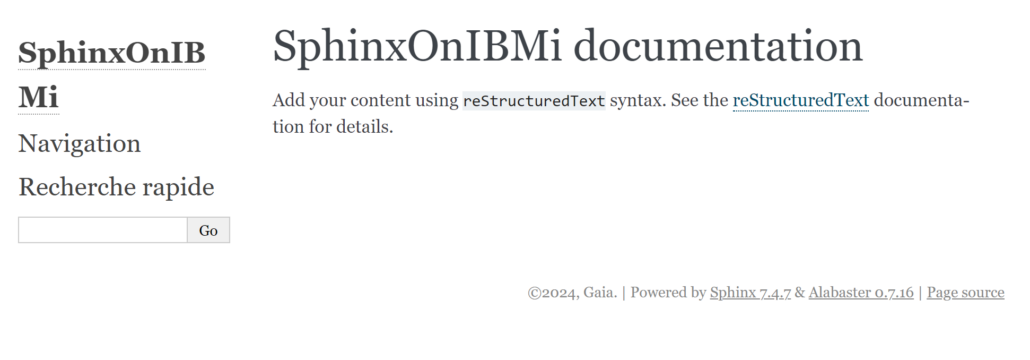
Voici le résultat avant d’avoir rédigé la documentation :
Il ne reste plus qu’à remplir la documentation et à jouer avec les différentes possibilités de Sphinx et de ses modules.
https://www.gaia.fr/wp-content/uploads/2022/09/logo128.png128128Julien/wp-content/uploads/2017/05/logogaia.pngJulien2024-07-30 02:15:122024-07-30 12:20:47Mise en place d’une documentation Sphinx sur IBM i