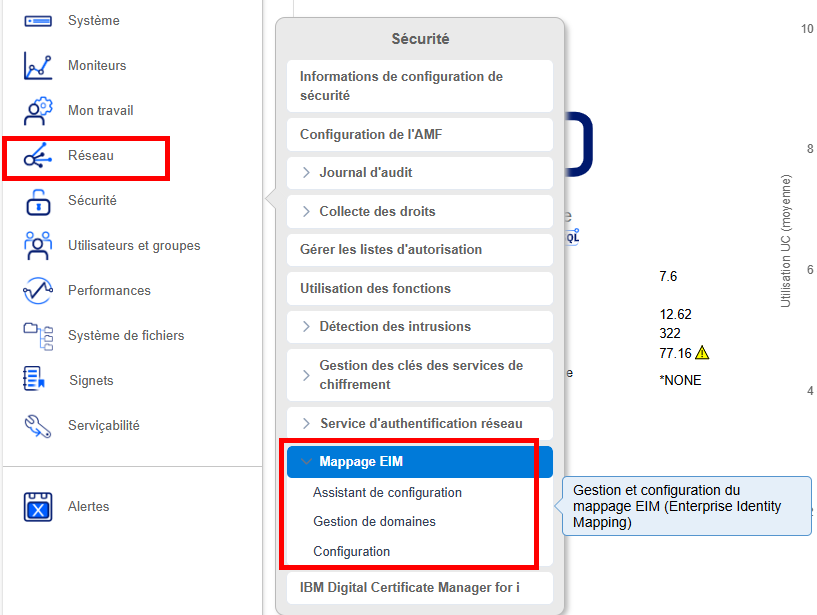
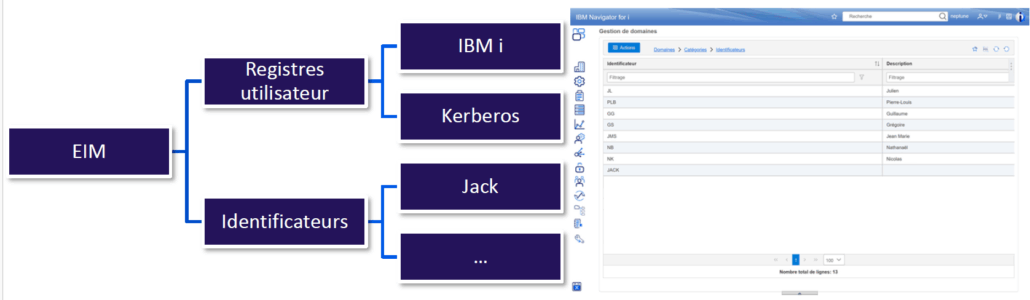
Si vous êtes utilisateur de SSO (Single Sign On) sur l’IBM i, alors vous utilisez l’EIM (Enterprise Identity Mapping).
Pour rappel (en très simplifié), le SSO vous permet de propager votre authentification Windows jusqu’à l’IBM i de sorte que n’avez pas besoin de saisir votre profil/mot de passe : une association entre vos comptes Windows et IBM i est réalisée et prise en compte automatiquement.
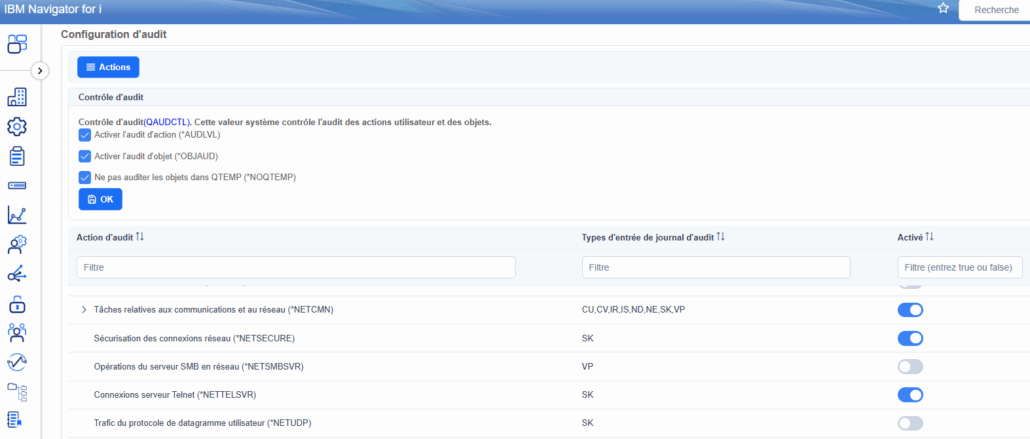
Pour gérer ces associations, vous pouvez utiliser IBM Navigator for i :
A partir de là vous avez accès à toute la gestion de l’annuaire (nécessite une authentification).
Bien entendu, ces fonctions sont critiques d’un point de vue de la sécurité : une modification de la configuration peut empêcher toute connexion, ou au contraire permettre une connexion avec un profil IBM i élevé !
IBM a donc délivré une nouvelle fonction d’usage QIBM_NAV_SECURITY_EIM (EIM related security) à cet effet : limiter l’accès aux fonctions EIM via Navigator for i.
La valeur par défaut est *ALLOWED pour tous -> vous devriez la passer à *DENIED !
Dès lors, si vous tentez d’accéder aux fonctions EIM, vous obtenez :
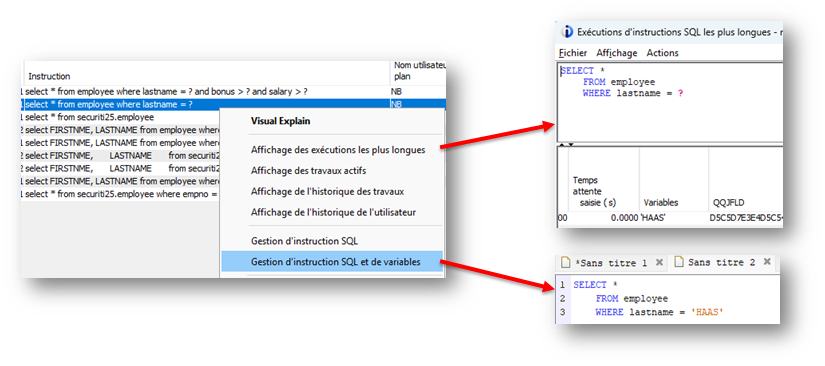
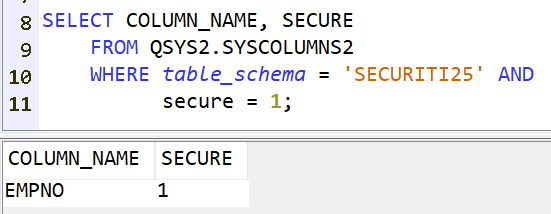
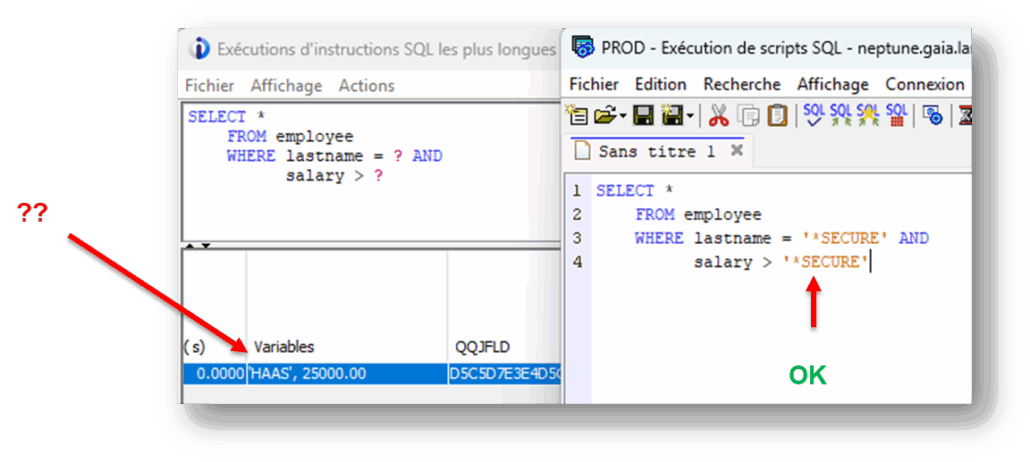
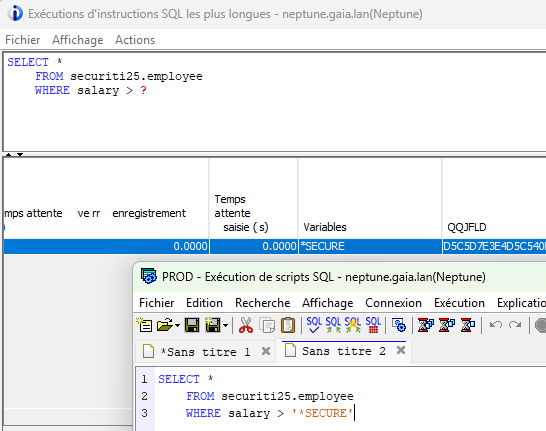
Si vous avez assisté à l’événement Securiti 2025 organisé par i.gayte.it, nous avions présenté une fonctionnalité SQL permettant de limiter l’accès aux informations du plan cache SQL.
En effet, ce dernier contient de nombreuses informations nécessaires à l’adaptation du moteur SQL. Mais il contient aussi les données utilisées dans vos requêtes : constantes littérales, valeurs de comparaisons …
Bien entendu, certaines valeurs sont à protéger, y compris des utilisateurs ayant les droits de consulter le plan cache.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-12-23 09:50:002025-12-16 08:44:24Sécurité du plan Cache SQL
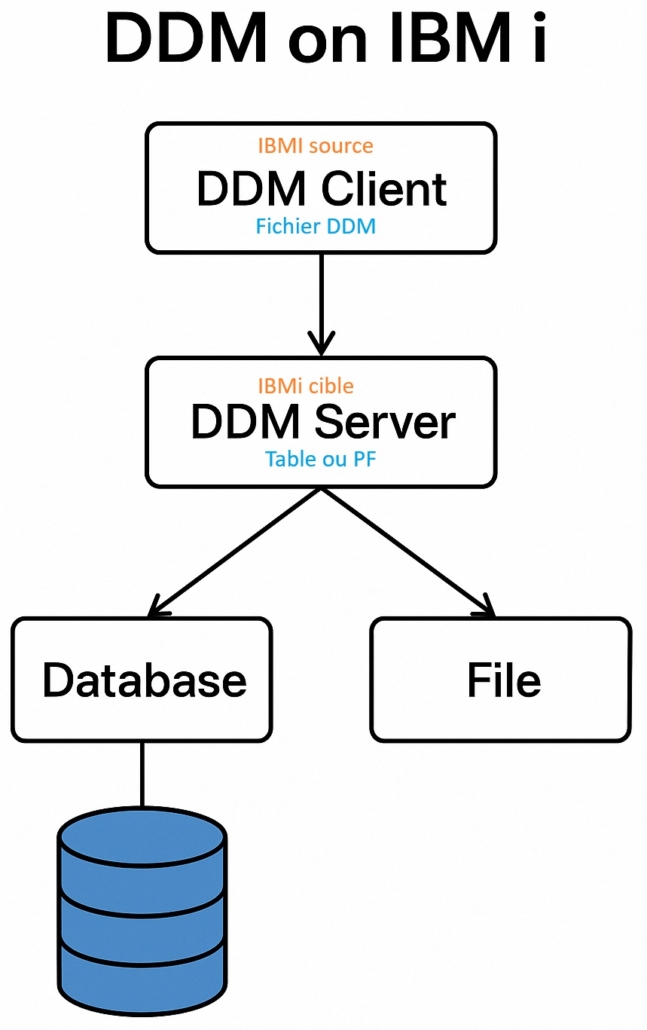
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-12-15 10:36:362025-12-15 11:14:49Copier vos données VIA DDM/DRDA
DéveloppementPassage d’un paramètre à l’état Null de SQL à RPGLE
Voici un petit retour d’expérience sur un cas d’usage où on doit transmettre l’état Null d’un paramètre depuis une procédure SQL vers une procédure de service RPGLE.
Pour rappel, Null est un état, pas une valeur. Il permet justement d’indiquer qu’une variable ne possède pas de valeur définie.
Dans le cas d’usage traité ici, je dois exposer une procédure de service RPGLE en procédure SQL, et gérer l’état Null pour l’un des paramètres seulement.
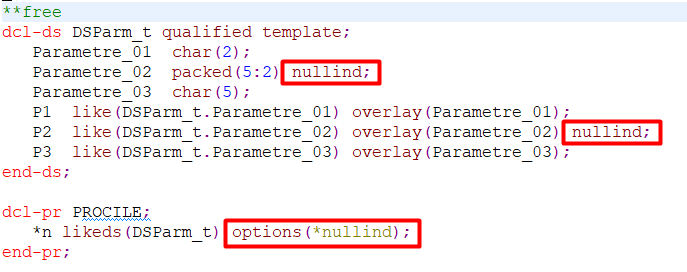
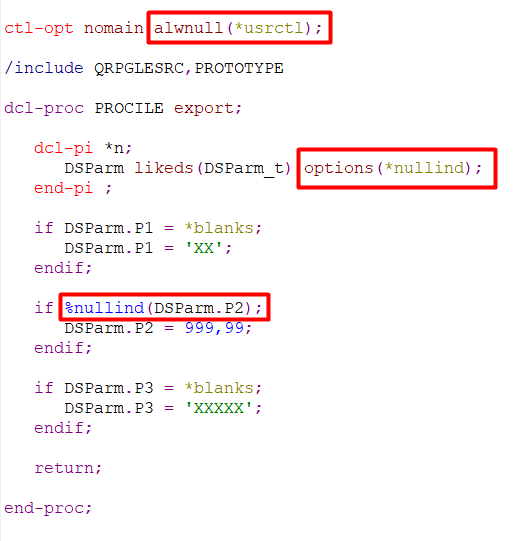
La procédure de service RPGLE reçoit en paramètre une DS qui contient 3 sous-zones, chacune ayant été définie avec 2 noms (un nom long et un nom court) grâce à un overlay. La procédure de service RPGLE doit pouvoir gérer l’état Null de la deuxième sous-zone.
Template de la DS et Prototype de la procédure de service RPGLE :
Le mot-clé NULLIND permet de définir l’état Null pour les sous-zones Parametre_02 et P2.
Le stockage de la sous-zone P2 est superposé à celui de la sous-zone Parametre_02. Lorsque l’une des deux sous-zones prend une valeur, l’autre prend la même valeur.
En revanche, ce n’est pas le cas pour l’état Null. Chaque sous-zone possède son propre indicateur Null. Si on veut pouvoir tester indifféremment l’indicateur Null pour l’une ou l’autre des deux sous-zones, il faudra gérer l’état Null pour les deux noms de sous-zones. J’ai donc défini le mot-clé NULLIND pour les deux sous-zones.
OPTION(*NULLIND) permet de transmettre à la procédure de service, l’état Null des sous-zones de la DS.
En RPG, l’état Null d’un paramètre est transmis sous forme d’un INDICATEUR. Il pourra être testé avec la fonction intégrée %NULLIND() : *ON (état Null) ou *OFF (état non Null).
Procédure de service :
Le mot-clé ALWNULL(*USRCTL) est indiqué dans la déclaration de contrôle pour permettre de gérer l’état Null des paramètres.
OPTION(*NULLIND) permet de transmettre à la procédure de service, l’état Null des sous-zones de la DS.
%NULLIND(DSParm.P2) est l’indicateur de l’état Null du paramètre DSParm.P2. Il sera transmis à la procédure.
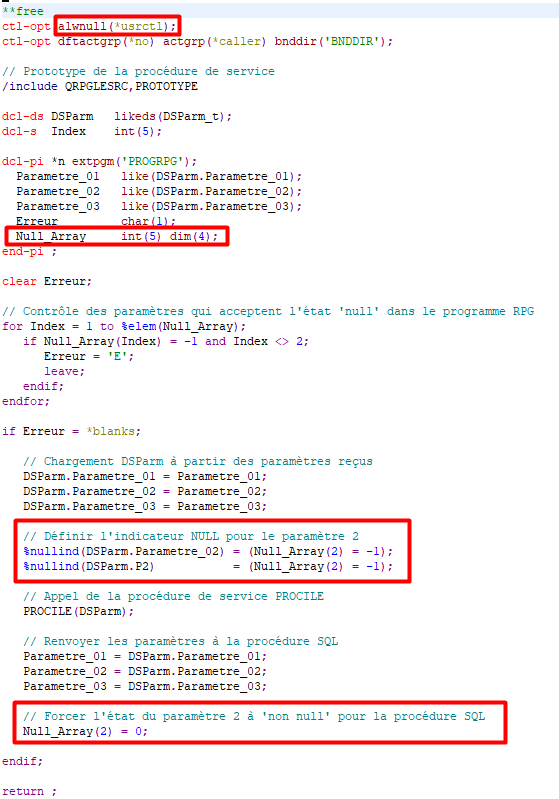
Procédure SQL avec programme externe RPGLE qui appellera la procédure de service :
Les paramètres 1 à 3 sont INOUT car ils peuvent être modifiés par la procédure de service et retournés à la procédure SQL.
WITH NULLS permet de transmettre au programme externe les indicateurs d’état Null pour tous les paramètres de la procédure.
Les indicateur Null sont transmis au programme externe sous forme de valeurs numériques :
-1 -> le paramètre est à l’état Null avec une valeur indéfinie
0 -> le paramètre possède une valeur définie
Procédure SQL avec programme externe RPGLE qui appellera la procédure de service :
Programme externe RPGLE
Programme PROGRPG :
Le mot-clé ALWNULL(*USRCTL) est indiqué dans la déclaration de contrôle pour permettre de gérer l’état Null des paramètres.
Le tableau Null_Array est déclaré à la fin des paramètres, en plus des paramètres de la procédure SQL. Il contient les indicateur d’état Null transmis par la procédure SQL sous forme de valeurs numériques :
0 -> le paramètre possède une valeur définie
-1 -> le paramètre est à l’état Null avec une valeur indéfinie
Tous les paramètres peuvent être transmis à l’état Null par la procédure SQL, mais seul l’état Null de Parametre_02 est géré par la procédure de service. J’ai donc rajouté une boucle de contrôle de l’état Null des paramètres pour retourner une erreur à la procédure SQL si un autre paramètre était transmis à l’état Null.
Avant d’appeler PROCILE, il faut définir l’indicateur Null %nullind pour Parametre_02 et P2 en convertissant l’indicateur numérique envoyé par SQL (0 ou -1) en indicateur booléen *ON/*OFF pour la procédure de service. Nous avons vu plus haut que, même si P2 a été définie comme overlay de Parametre_02, il existe un indicateur état Null distinct attaché à chaque nom de zone.
Appel de la procédure PROCILE
On a vu que PROCILE retourne la valeur 999,99 pour le paramètre 2 s’il a été transmis à l’état Null. Pour que la procédure SQL retourne à son tour cette valeur 999,99 il faut forcer l’état Non Null pour PARM2 de la procédure SQL en affectant la valeur numérique 0 à l’indicateur SQL état Null de PARM2.
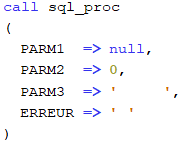
Test de la procédure SQL
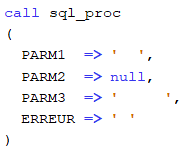
Test 1
Si l’état Null est envoyé pour un PARM1 au lieu de PARM2, un code E est retournée dans le paramètre ERREUR
.
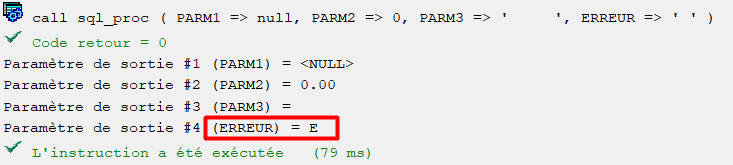
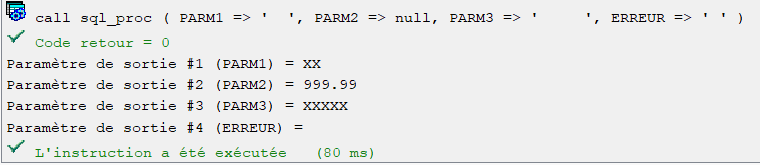
Test 2
PARM2 envoyé à Null, retourné à 999.99.
Sans Null_Array(2) = 0 dans le programme externe, la valeur affichée pour PARM2 au retour aurait été <NULL> au lieu de la valeur réelle retournée 999.99
.
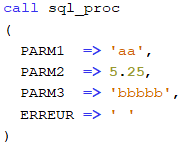
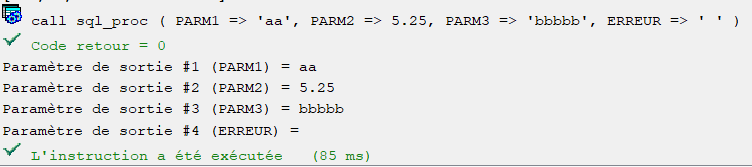
Test 3
PARM2 envoyé avec une valeur définie, retourné avec la même valeur
https://www.gaia.fr/wp-content/uploads/2025/12/Laurent_Chavanel.png321322Laurent Chavanel/wp-content/uploads/2017/05/logogaia.pngLaurent Chavanel2025-12-08 12:15:472025-12-08 12:15:48Passage d’un paramètre à l’état Null de SQL à RPGLE
La durée de rétention est indiquée en jour dans la valeur système QPRBHLDITV
par défaut c’est 30 jours
il est possible que des problèmes proviennent de requêtes DRDA non conformes c’est le cas pour les outils d’analyse de securité, NESSUS, OpenVAS, Rapid7, Nexpose, Greenbone etc..
ca génèrera un dump FFDC (First Failure Data Capture) vous pouvez éviter la génération de ce dump en utilisant une variable d’environnement, QIBM_SKIP_PRSDUMP
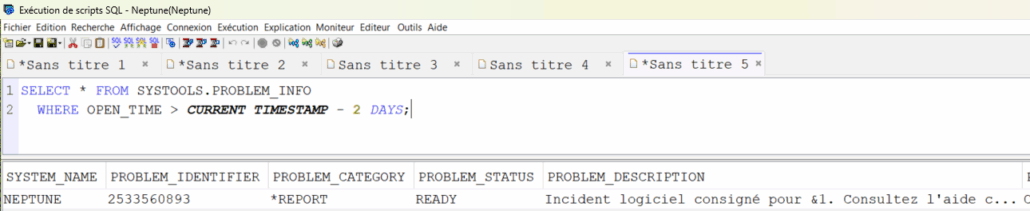
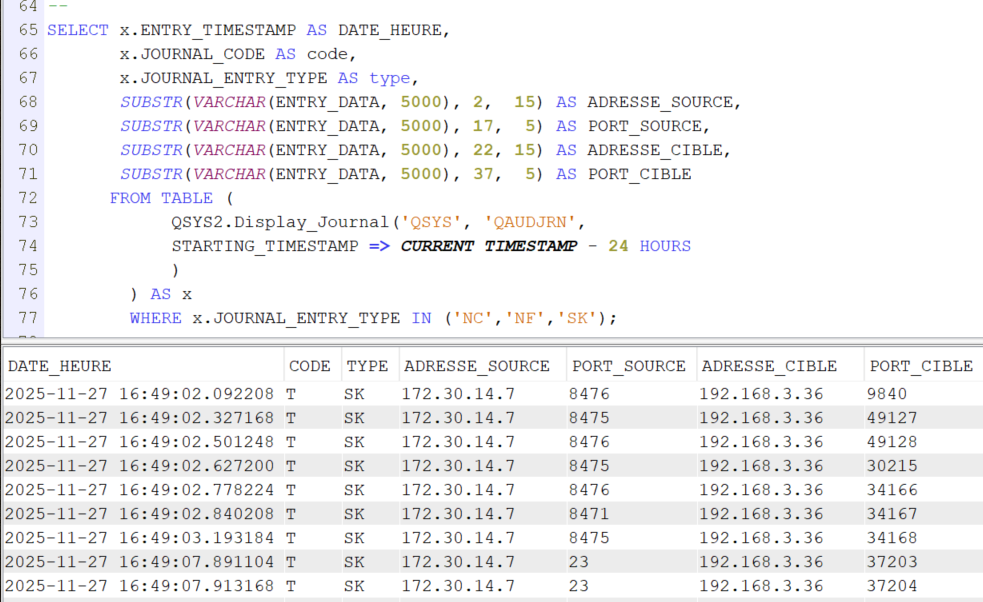
Les 3 codes à analyser sur les dernières 24 heures
SELECT x.ENTRY_TIMESTAMP AS DATE_HEURE, x.JOURNAL_CODE AS code, x.JOURNAL_ENTRY_TYPE AS type, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 2, 15) AS ADRESSE_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 17, 5) AS PORT_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 22, 15) AS ADRESSE_CIBLE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 37, 5) AS PORT_CIBLE FROM TABLE ( QSYS2.Display_Journal(‘QSYS’, ‘QAUDJRN’, — JOURNAL_ENTRY_TYPES => ‘SK’ , STARTING_TIMESTAMP => CURRENT TIMESTAMP – 24 HOURS ) ) AS x WHERE x.JOURNAL_ENTRY_TYPE IN (‘NC’, ‘NF’, ‘SK’)
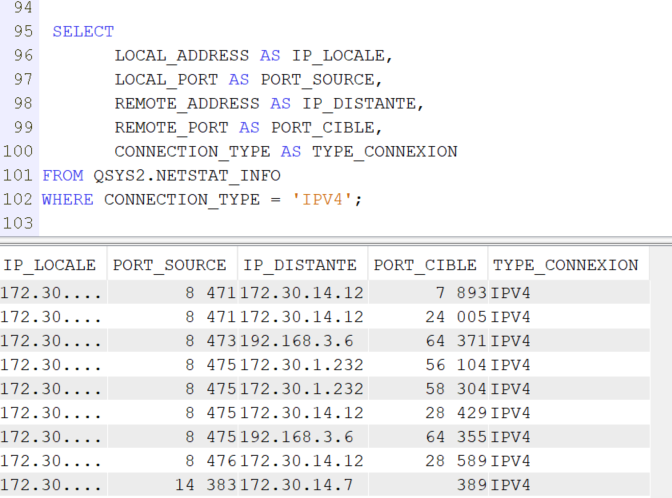
A la différence du NETSTAT suivant qui vous donne à l’information à l’instant T
SELECT LOCAL_ADDRESS AS IP_LOCALE, LOCAL_PORT AS PORT_SOURCE, REMOTE_ADDRESS AS IP_DISTANTE, REMOTE_PORT AS PORT_CIBLE, CONNECTION_TYPE AS TYPE_CONNEXION FROM QSYS2.NETSTAT_INFO WHERE CONNECTION_TYPE = ‘IPV4’;
Remarque :
Il n’existe pas encore de service dans SYSTOOLS AUDIT_JOURNAL_SK() dommage
Vous pourrez cibler des ports, des adresses ou des plages etc.
Log du système
Vous pouvez également utiliser l’historique du système pour analyser certaines choses, par exemple connaitre les adresses ip.
Cette solution ne nécessite pas de paramétrage , et vous avez en principe 1 mois en ligne
— Toutes les connexions
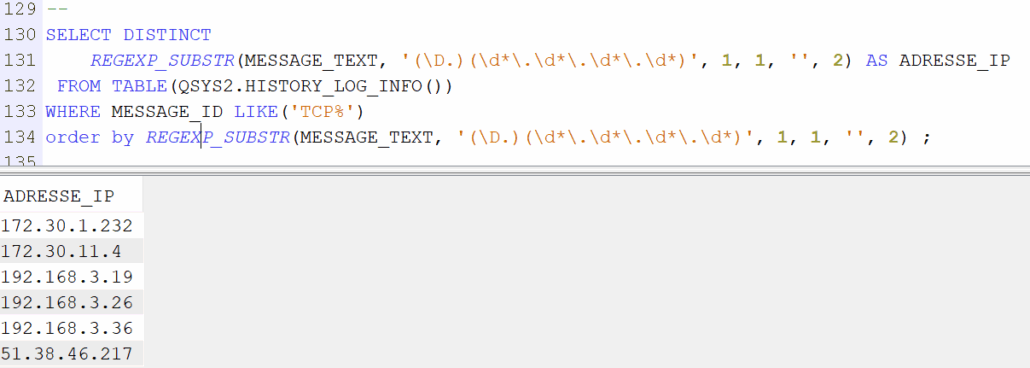
SELECT MESSAGE_TIMESTAMP, MESSAGE_ID, REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP, MESSAGE_TEXT FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) ORDER BY MESSAGE_TIMESTAMP DESC; — Les différentes adresses SELECT DISTINCT REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) order by REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) ;
Divers :
Vous pouvez également utilisez une commande TRCCNN et générer un fichier PCAP que vous pourrez analyser ensuite , avec Wireshark
Mais également installer utiliser le FW de l’ibmi en mode journalisation pour historiser vos connexions, vous devrez installer et configurer 5769FW1
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-11-27 17:38:402025-11-28 18:21:18Analyser le Trafic TCP/IP avec le journal d’audit
Vous avez assisté, ou non, à la Power Week coorganisée par IBM France et Common France :
Gaia-Volubis a été très heureux de participer à cette édition, riche en annonces. Avant de reprendre une vie normale, de retourner à notre quotidien, voici le retour de nos speakers !
Damien
C’est toujours un moment particulier pour nous dans notre calendrier, et cette année n’aura pas dérogée aux autres : beaucoup de participants, d’échanges que ce soit avec des clients ou des IBMers, quelques dépannages en direct ! 3 jours intenses.
Merci aux participants à nos sessions et à leurs retours. Il est toujours appréciables de savoir que nos choix de sujets correspondent à des attentes des participants à l’évènement. Prochain évènement de masse : le Common Europe à Lyon en juin 2026…
Florian
Trois jours intenses et passionnants pour cette édition de la Power Week 2025 !
Au-delà du programme officiel, ce sont surtout les échanges directs avec nos clients, partenaires, IBMers et l’ensemble des participants qui ont marqué l’événement. Ces discussions spontanées, souvent en marge des sessions, sont celles qui font grandir notre réseau, ouvrent des perspectives et apportent des idées concrètes pour aller plus loin.
J’ai également pu présenter COMMON France et toutes les actions que nous avons menées cette année, notamment la Battle Dev que j’ai eu le plaisir de coorganiser avec Philippe Bourgeois et Jérôme Clément. J’espère que nous pourrons organiser une 4ᵉ édition l’année prochaine !
Merci à tous d’être venus !
Julien
Merci à toutes et à tous pour ces trois journées intenses à la Power Week 2025 !
J’ai particulièrement apprécié la qualité des échanges avec nos clients, partenaires et IBMers. Ces moments informels, toujours très enrichissants, sont essentiels pour nourrir notre réseau et nos perspectives.
J’ai également été heureux de présenter deux sessions orientées sécurité et bonnes pratiques sur IBM i, des sujets au cœur des préoccupations de nombreux clients. Merci pour votre participation et vos questions !
L’événement a une nouvelle fois confirmé sa convivialité, et la troisième édition de la Battle Dev a été remarquablement organisée.
Ravi de vous avoir retrouvés en nombre, et déjà impatient de vous revoir au Common Europe à Lyon en juin 2026 !
Betty
Ces trois jours au cœur de la communauté IBM étaient d’une richesse incroyable.
Ils m’ont permis d’avoir une vue plus globale et plus synthétique de la puissance, des possibilités et de l’avenir du power et de ses applications.
Mais le futur s’écrit aussi avec la jeune génération de programmeurs, et la présence des participants à la pépinière de cette année m’a permis de voir que la relève était assurée grâce à ces formations.
J’ai eu l’occasion de faire une première présentation qui concernait la modernisation via SQL, et je n’ai aucun doute que les équipes hybrides qui se construisent actuellement avec des jeunes et des personnes plus expérimentées sauront trouver des méthodes de travail permettant d’aller vers cette modernisation, nécessaire, et souhaitée.
Eric
3 jours intenses de rencontres, des visages connus et des nouveaux venus. 3 jours de sessions intéressantes. Toutes les personnes rassemblées ont en commun un grand intérêt, voire même une passion pour leur système favori. Une communauté IBMi toujours aussi active.
J’ai pu cette année présenter la session « Modernisation avec SQL : comment Intégrer l’existant », avec BETTY et LUCAS. Notre première session. Ce fut intense à préparer, et à présenter.
Les outils open source ont suscité mon intérêt cette année. La présentation de BOB a été très instructive, bien qu’il reste de nombreuses questions encore sans réponse.
Merci à tous pour votre énergie et votre participation!
Pierre Louis
C’est avec plaisir que comme chaque année, on retrouve la communauté IBMi, cette année pour la première fois les gens du monde Power nous ont rejoint.
On a pu assister à des présentations techniques intéressantes, beaucoup était basées sur l’IA, comme BOB , dont la présentation a été très prometteuse …
Pour ma part j’ai trouvé très intéressant le produit MANZAN qui permet de supervisé votre IBMi et qui a l’air simple et efficace.
Cette année, j’ai présenté 2 sessions en duo avec Gautier Dumas, sur le chemin de modernisation et avec Florian Gradot sur, comment donner une seconde vie à vos application 5250, merci a eux de m’avoir supporté, ce fut une expérience intéressante.
J’ai pu échangé sur des thèmes différents, avec des clients et des partenaires, ce qui est toujours enrichissant.
Merci à IBM et à Common pour cette organisation, merci à ceux qui sont venus, et l’année prochaine !
Nathanaël
3 jours très intenses pour ma part, mais très enrichissants !
Les meilleurs moments : ceux que l’on ne peut pas mettre en photo 😉
J’ai particulièrement apprécié de pouvoir échanger de façon libre et informelle avec nos clients, partenaires, IBMers et de façon plus globale toutes les personnes présentes. C’est important, c’est la construction d’un réseau, un réseau qui apporte des perspectives, des solutions.
Donc merci à vous d’être venu, nombreux, y compris dans non sessions, de poser des questions. C’est ce qui nous donne l’énergie pour les mois à venir jusqu’au prochain grand rassemblement !
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
https://www.gaia.fr/wp-content/uploads/2025/11/Media-xx-7.jpg12001600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-25 10:04:172025-11-25 10:05:02Power Week 2025 : retour à la maison !
Cela n’a pas pu vous échapper, la semaine prochaine c’est (déjà) la Power Week, événement gratuit coorganisé par IBM France et Common France :
Durant ces 3 jours dédiés au Power Systems, au stockage, au Power11, à l’IA, à l’IBM i, AIX, Linux, la modernisation … retrouvez l’ensemble des speakers, des partenaires et des clients qui font la force de notre plateforme.
Un programme riche (et international)
Pendant trois jours, les participants auront accès à des sessions animées par les meilleurs experts, venus de France, d’Allemagne, des États-Unis … Parmi eux, des IBM Champions, reconnus pour leur expertise et leur engagement auprès de la communauté, partageront leurs connaissances sur des sujets variés : modernisation, sécurité, SQL, DevOps, IA, cloud hybride, et bien plus encore.
La Power Week est 100 % gratuite et ouverte à tous les professionnels de l’IBM i : développeurs, architectes, DSI, chefs de projet, consultants… C’est une opportunité rare de bénéficier de contenus de qualité sans contrainte logistique ni financière.
La force de la communauté
Au-delà des conférences, la Power Week est un lieu de rencontre et d’échange. Elle permet de :
Réseauter avec d’autres professionnels confrontés aux mêmes enjeux
Confronter les points de vue, partager des bonnes pratiques
Découvrir les clubs utilisateurs comme Common France, qui jouent un rôle dans l’animation de la communauté en France, mais aussi au niveau Européen.
Ces moments d’échange sont essentiels pour faire évoluer les pratiques, identifier des solutions concrètes, et tisser des liens durables.
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
Les speakers de Gaia et Volubis sont très heureux de participer à cette célébration : échange, partage, connaissance.
En tant que sociétés liées à la formation, il est dans notre ADN de participer à ces initiatives, comme nous le faisons depuis longtemps : les Universités IBM i depuis 2011, Pause Café en physique ou en ligne, articles de blogs …
N’hésitez pas à solliciter nos speakers sur place !
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-11 10:00:002025-11-10 19:37:40Power Week 2025 : 3 jours pour se connecter, apprendre et faire rayonner la communauté IBM i
QSYSOPR est une file d’attente de message qui reçoit, les messages nécessitants une réponse pour les travaux batchs Voici une petite requête qui permet de connaitre l’utilisateur, qui a répondu à un message dans QSYSOPR
SELECT A.MESSAGE_TIMESTAMP, A.MESSAGE_ID, A.FROM_USER, A.FROM_JOB, A.MESSAGE_TEXT, B.MESSAGE_TIMESTAMP, SUBSTR(B.MESSAGE_TEXT, 1, 10) AS RESPONSE FROM TABLE ( QSYS2.MESSAGE_QUEUE_INFO(QUEUE_LIBRARY => ‘QSYS’, QUEUE_NAME => ‘QSYSOPR’, SEVERITY_FILTER => 99) ) A, LATERAL ( SELECT MESSAGE_TIMESTAMP, MESSAGE_TEXT, FROM_USER FROM TABLE ( QSYS2.MESSAGE_QUEUE_INFO(QUEUE_LIBRARY => ‘QSYS’, QUEUE_NAME => ‘QSYSOPR’, SEVERITY_FILTER => 99) ) WHERE A.MESSAGE_TIMESTAMP >= CURRENT TIMESTAMP – 1 DAYS AND A.MESSAGE_TIMESTAMP <= CURRENT TIMESTAMP AND ASSOCIATED_MESSAGE_KEY = A.MESSAGE_KEY ) B ORDER BY a.MESSAGE_TIMESTAMP DESC ;
Dans la requête on regarde sur la veille, vous pouvez archiver ces messages
Remarque:
Pour les éditeurs le user sera toujours QSPLJOB Vous pouvez adapter la requête pour avoir par exemple les temps de réponse à chaque message
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-11-03 21:54:542025-11-03 21:54:56Qui a répondu à un message dans QSYSOPR?
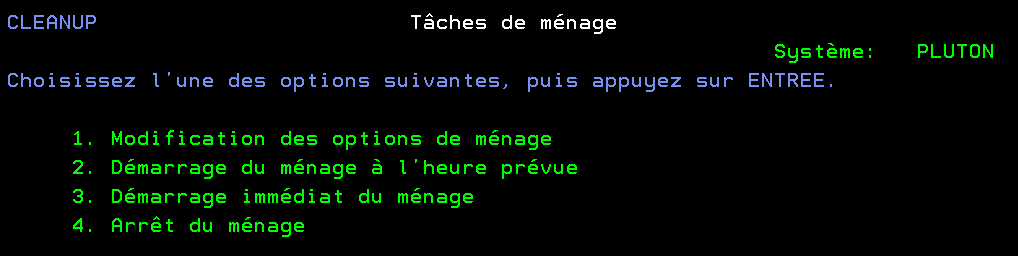
Vous voyez souvent cette commande ==> STRCLNUP dans les programmes QSTRUPPGM de vos partitions
vous voyez ce travail dans qctl
Vous avez un menu de gestion
==>go cleanup
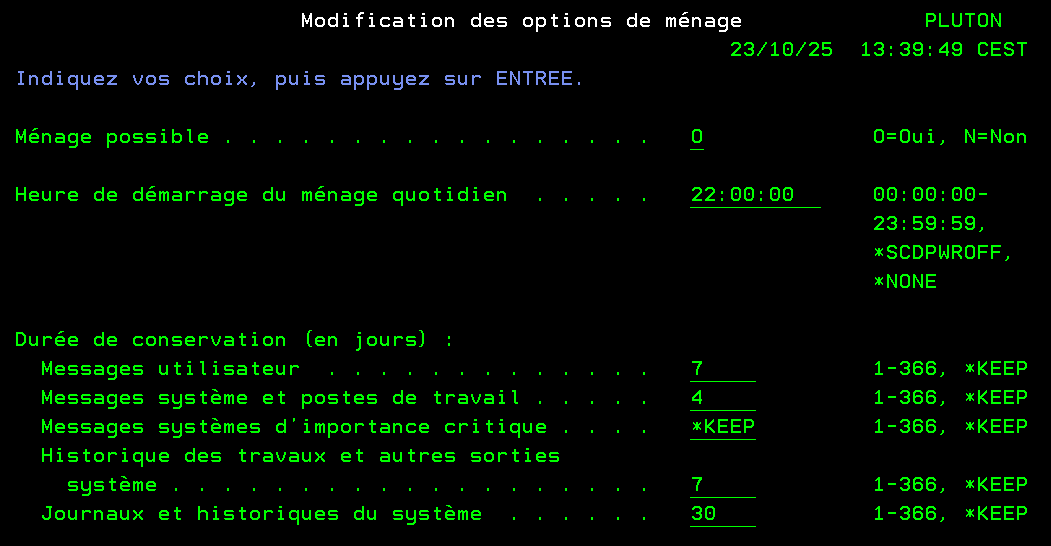
Dans l’option 2 vous pouvez choisir la durée de rétention des éléments
Voici les 4 principaux éléments : file de messages profil (par défaut 4 jours) file de messages écran (par défaut 7 jours) log des travaux (par défaut 7 jours) log du système (par défaut 30 jours)
Par défaut l’heure de planification est 22 heures, n’hésitez pas à la changer
Ce qu’on sait moins c’est que ce programme lance un autre programme pour compléter cette épuration
Il s’agit du programme QEZUSRCLNP de la bibliothèque QSYS, on parle de ménage utilisateurs
C’est un clp, vous pouvez extraire le source par la commande RTVCLSRC
Ensuite vous pouvez le customiser, par défaut, il ne fait rien. Souvent on ajoute une épuration des spools et des récepteurs de journaux Ce qui est facile avec les services SQL au jourd’hui
Voici un exemple complet
Dans ce programme, on utilise la commande RTVCLNUP pour extraire les paramétrages de ménage en cours. On utilisera également les services SQL DELETE_OLD_SPOOLED_FILES et DELETE_OLD_JOURNAL_RECEIVERS pour supprimer les spools et les récepteurs
/********************************************************************/
/* */
/* Nom du programme . . . . . . . . . . . . : QEZUSRCLNP */
/* Nom de la bibliothèque . . . . . . . . . : QSYS */
/* */
/* Le programme a été sauvegardé avant modification en QEZUSRCLNS */
/* Sinon vous pouvez également mettre une bibliothèque avant QSYS */
/* */
/* Il est appelé à la fin du programme standard de cleanup */
/* il épure les récepteurs de journaux */
/* les spools utilisateurs */
/* */
/* on se base sur les informations paramétrées dans le cleanup */
/* ==>CHGCLNUP */
/********************************************************************/
PGM
/* Variable pour RTVCLNUP extraction des informations en cours */
DCL VAR(&ALWCLNUP) TYPE(*CHAR) LEN(4)
DCL VAR(&STRTIME) TYPE(*CHAR) LEN(10)
DCL VAR(&USRMSG) TYPE(*CHAR) LEN(5)
DCL VAR(&SYSMSG) TYPE(*CHAR) LEN(5)
DCL VAR(&CRITSYSMSG) TYPE(*CHAR) LEN(5)
DCL VAR(&SYSPRT) TYPE(*CHAR) LEN(5)
DCL VAR(&SYSLOG) TYPE(*CHAR) LEN(5)
DCL VAR(&JOBQ) TYPE(*CHAR) LEN(10)
DCL VAR(&BJOBQ) TYPE(*CHAR) LEN(10)
DCL VAR(&RUNPTY) TYPE(*DEC) LEN(2 0)
DCL VAR(&JRNRCVSIZ) TYPE(*DEC) LEN(10 0)
MONMSG MSGID(CPF0000) EXEC(GOTO CMDLBL(ERREUR))
/*————————————————————*/
/* Extraction des infos du cleanup */
/*————————————————————*/
QSYS/RTVCLNUP ALWCLNUP(&ALWCLNUP) +
STRTIME(&STRTIME) +
USRMSG(&USRMSG) +
SYSMSG(&SYSMSG) +
CRITSYSMSG(&CRITSYSMSG) +
SYSPRT(&SYSPRT) +
SYSLOG(&SYSLOG) +
JOBQ(&JOBQ) +
JOBQLIB(&BJOBQ) +
RUNPTY(&RUNPTY) +
JRNRCVSIZ(&JRNRCVSIZ)
QSYS/SNDPGMMSG MSGID(CPI1E91) MSGF(QCPFMSG) TOMSGQ(*SYSOPR) –
MSGTYPE(*INFO)
QSYS/MONMSG MSGID(CPF2400)
/* Epuration des spools utilisateurs de plus SYSLOG */
RUNSQL SQL(‘CALL SYSTOOLS.DELETE_OLD_SPOOLED_FILES +
( DELETE_OLDER_THAN => CURRENT DATE – ‘ +
*BCAT &SYSLOG *BCAT ‘DAYS, PREVIEW => +
»NO »)’) COMMIT(*NONE)
monmsg sql0000 exec(do)
QSYS/SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA(‘Epuration des spools +
utilisateurs en erreur’) TOMSGQ(*SYSOPR) +
MSGTYPE(*INFO)
enddo
/* Epuration des journaux de plus SYSLOG */
RUNSQL SQL(‘ CALL +
SYSTOOLS.DELETE_OLD_JOURNAL_RECEIVERS( +
DELETE_OLDER_THAN => CURRENT_DATE – ‘ +
*BCAT &SYSLOG *BCAT ‘DAYS, PREVIEW => +
»NO ») ‘) COMMIT(*NONE)
monmsg sql0000 exec(do)
QSYS/SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA(‘Epuration des récepteurs +
de journaux en erreur’) TOMSGQ(*SYSOPR) +
MSGTYPE(*INFO)
enddo
QSYS/SNDPGMMSG MSGID(CPI1E92) MSGF(QCPFMSG) TOMSGQ(*SYSOPR) –
MSGTYPE(*INFO)
QSYS/MONMSG MSGID(CPF2400)
RETURN
ERREUR:
QSYS/SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA(‘Traitement CLEANUP Spécifique en +
erreur’) TOMSGQ(*SYSOPR) MSGTYPE(*INFO)
QSYS/MONMSG MSGID(CPF0000)
QSYS/ENDPGM
Paramétrage :
Pour que votre programme soit lancé, vous avez 2 solutions : -le mettre dans une bibliothèque avant QSYS dans partie système de la liste des bibliothèques, c’est la meilleur solution -remplacer celui de QSYS par le votre, bien sur, faire une sauvegarde du programme avant
Remarque : Vous pouvez mettre ce que vous voulez dans ce programme , exemple : épurations des fichiers IFS dans /home de plus 6 mois