Grafana est une plateforme logicielle open-source de visualisation et d’analyse de données. Son rôle principal est de collecter des informations provenant de sources variées (bases de données, outils de monitoring (Manzan), systèmes cloud) et de les centraliser dans une interface unique.
(Si ce n’est pas déjà fait, veuillez consulter le blog précédent sur Manzan pour réaliser et mieux comprendre celui ci)
Nous allons prendre l’exemple des messages INQ dans QSYSOPR pour les retranscrire dans Grafana à l’aide de Manzan
Voici d’abord comment configurer Manzan :
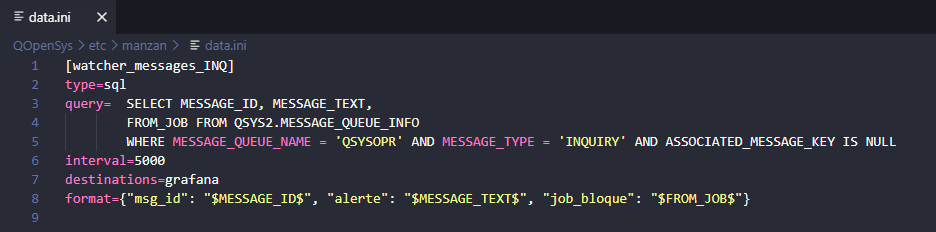
Tout se fait principalement dans le fichier data.ini :
[watcher_messages_INQ]
type=sql
query=SELECT MESSAGE_ID, MESSAGE_TEXT, FROM_JOB FROM QSYS2.MESSAGE_QUEUE_INFO WHERE MESSAGE_QUEUE_NAME = 'QSYSOPR' AND MESSAGE_TYPE = 'INQUIRY' AND ASSOCIATED_MESSAGE_KEY IS NULL
interval=5000
destinations=grafana
format={"msg_id": "$MESSAGE_ID$", "alerte": "$MESSAGE_TEXT$", "job_bloque": "$FROM_JOB$"}
Dans data.ini nous retrouvons le même format JSON du blog précédent. En effet Grafana gère mieux les données en JSON notamment pour le tri des différentes sources qui lui sont envoyées.
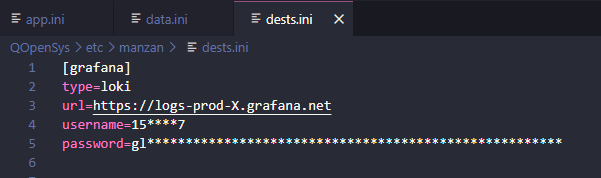
Puis voici votre dests.ini
Cette destination pointe vers une logs Grafana dans laquelle vous pouvez y passer toutes les données que vous voulez pour ensuite les trier grâce au format que vous avez défini dans votre data.ini :
Vous pouvez installer Grafana en local sur une partition linux ou sur un linux externe, mais pour le moment pas sur l’ibmi… Pour notre test nous allons utiliser une version de Grafana en ligne accessible en webservice .
Dans Grafana :
Comment récupérer votre username et password dans Grafana ?
Premièrement pour l’username
Vous devez, une fois votre compte Grafana créé, vous dirigez vers la section Connection puis Data sources :
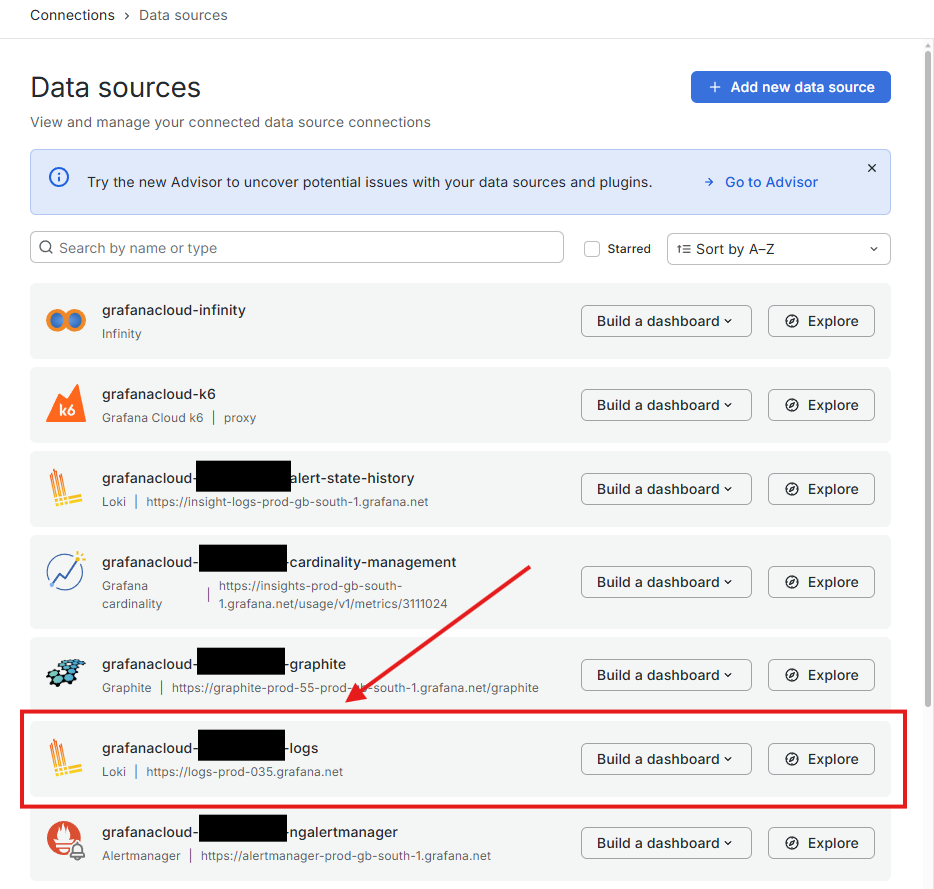
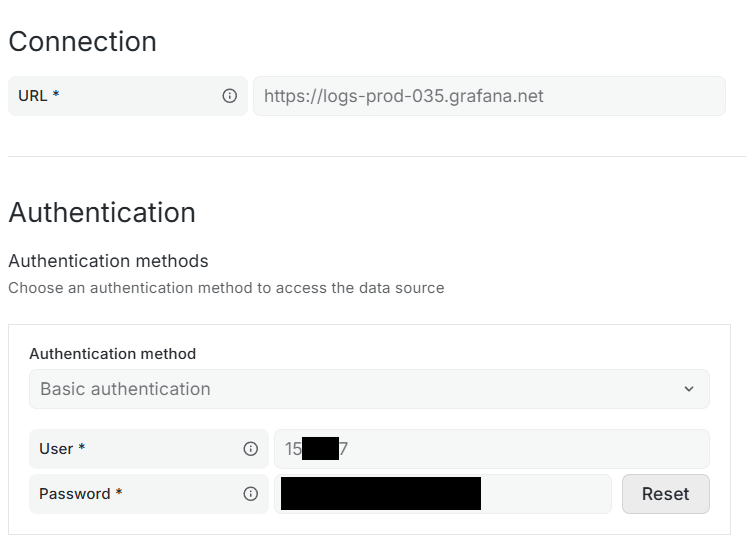
Puis vous atterrirez sur cette page :
(les rectangles noirs seront votre nom dans Grafana)
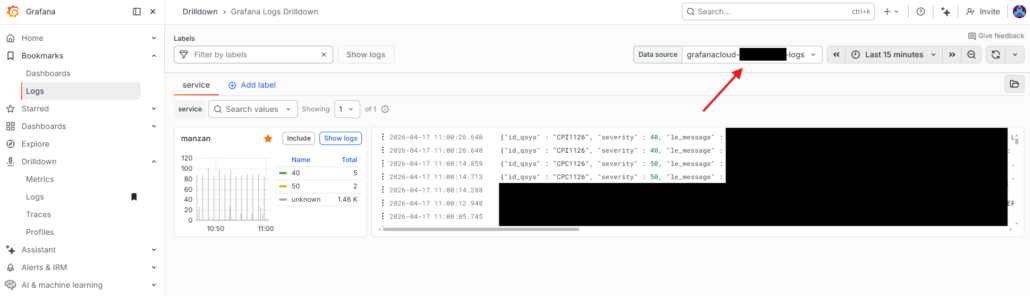
Une fois sur la page des logs (via loki qui est le service de log de Grafana) vous descendrez un petit peu pour trouver ces 2 sections :
Ce qui va nous intéresser ici est l’URL de la Connexion que vous mettrez dans votre dests.ini dans le champ url= Mais aussi le User qui est l’identifiant de votre logs. Vous le mettrez aussi dans dests.ini dans le champ username=
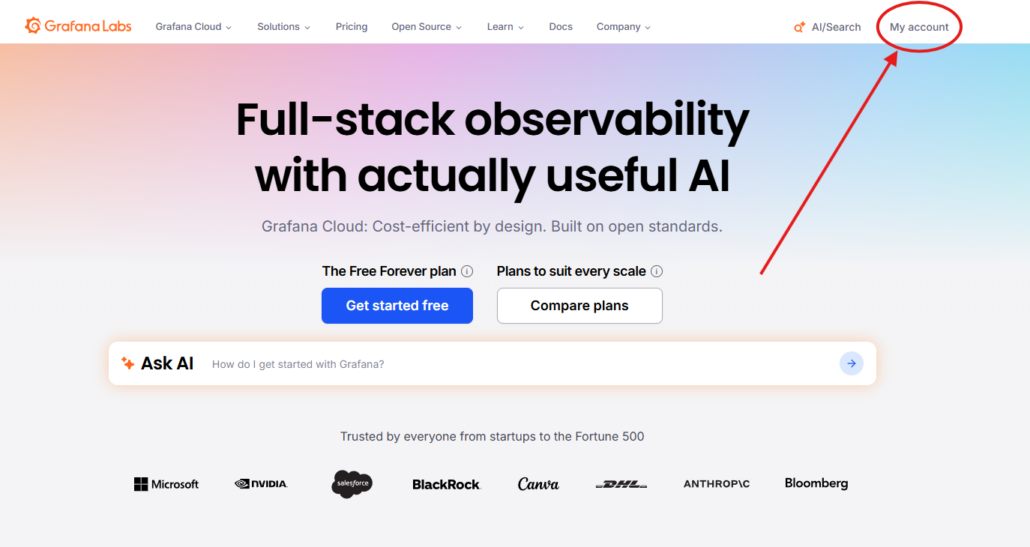
Maintenant comment trouver votre password ?
Vous devez vous rendre sur la page d’acceuil de Grafana en étant connecté à votre compte puis cliquer sur My account en haut à droite
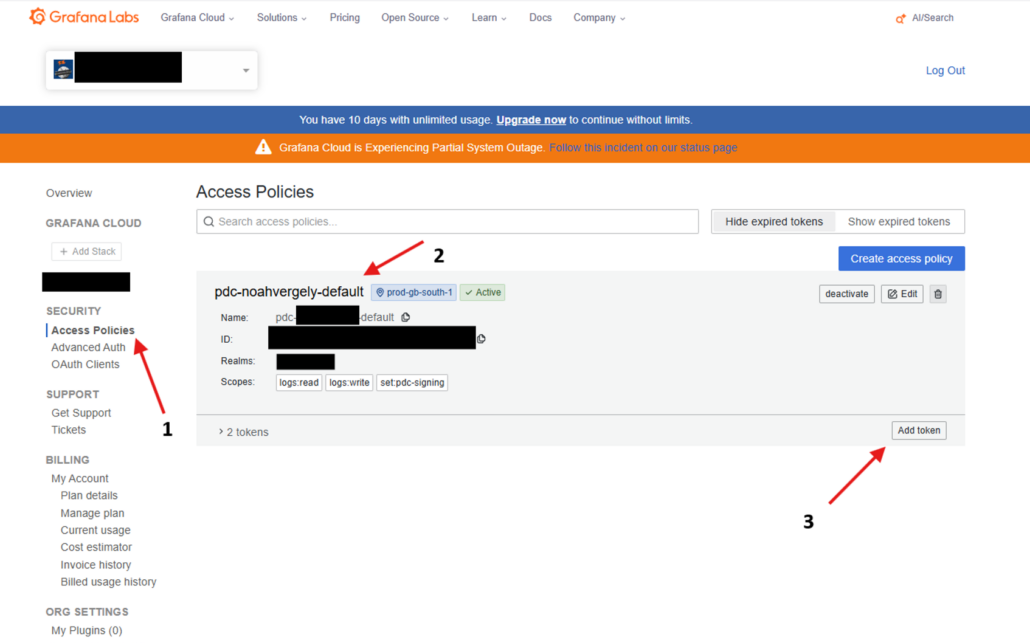
Vous atterrirez sur cette page :
2.
3.
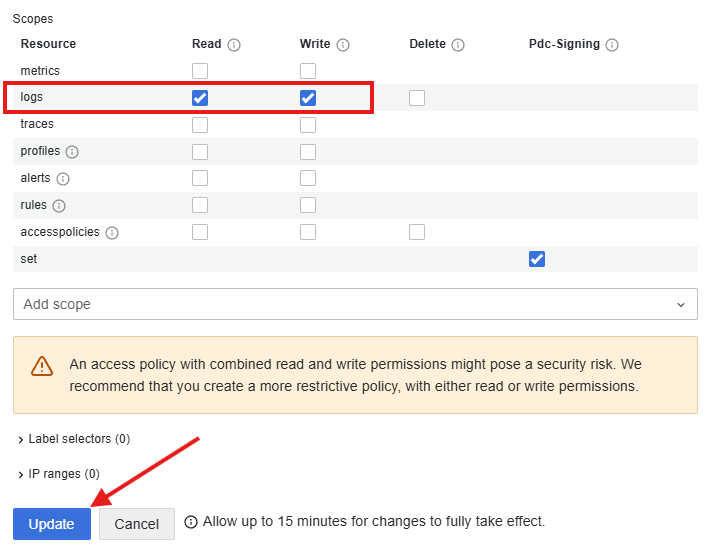
Suite à ça vous devez copier et garder ce token pour l’utiliser dans le fichier dests.ini
Puis vous n’aurez qu’à regarder dans votre logs en pensant à surveiller que vous avez bien sélectionné vos logs loki comme montré ci dessous :
Vous pouvez ensuite créer un Dashboard dans lequel vous surveillerez tout ce que vous voudrez en créant plusieurs sources avec les données que vous enverrez dans Grafana en format JSON
Exemple :
Voici la commande en 5250 pour vous envoyer un message INQ et faire vos tests de votre côté :
Le message restera visible même s’il a réçu une réponse, vous devrez l’enlever manuellement depuis 5250 pour qu’il disparaisse de Manzan et Grafana
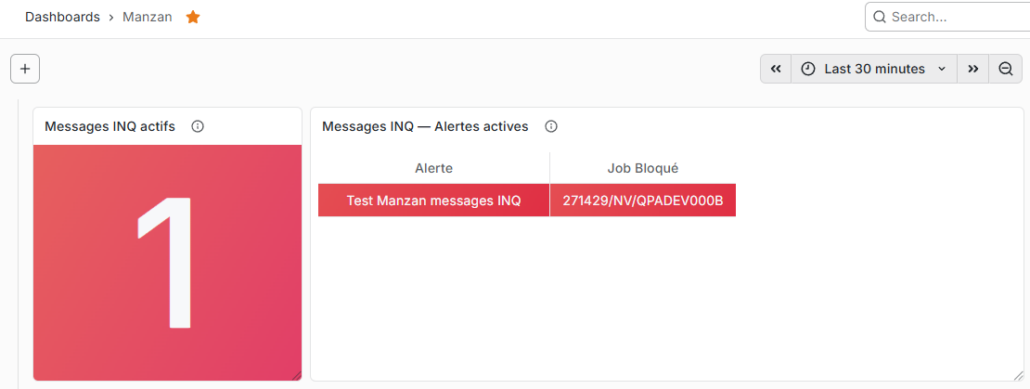
Exemple du rendu dans le dashboard
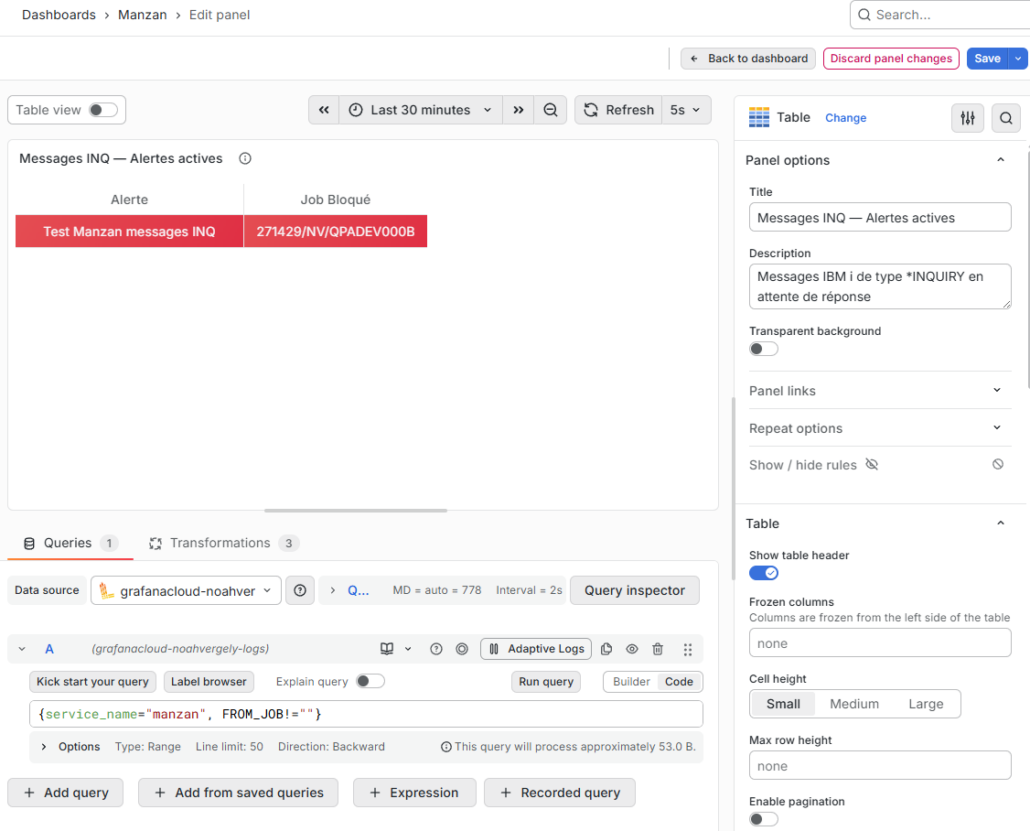
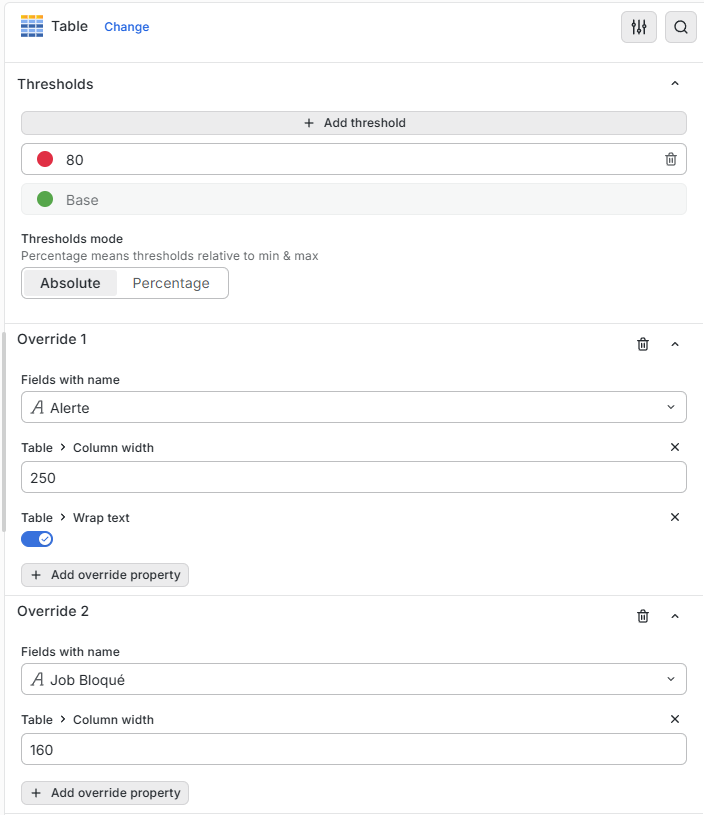
Détail de la configuration de la table de messages INQ, quand il y en a 1 et les paramètres du dashboard:
Conclusion:
Vous pouvez utiliser Manzan , pour capter les événements souhaités sur partition IBMi, le paramétrage reste assez simple (Seulement 2 fichiers à mettre à jour)
Grafana est devenu un standard de restitution d’information, il semblait donc naturel de brancher manzan sur cette solution pour avoir un outil fiable et robuste.
A noter que dans grafana, il exite un assistant IA pour vous aider à configurer votre dasboard.
Bon tests à tous, n’hésitez pas à nous contacter pour de plus amples informations, ou à contacter https://cfd-innovation.fr/ dont on s’est librement inspiré pour cet article.
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-04-28 10:05:002026-04-29 15:00:21Comment lier Manzan à Grafana ?
SecuritéSSO (Single Sign-On) sur IBM i : Gérer les associations avec G-EIM
Qu’est-ce que le SSO ?
Le Single Sign-On (SSO) est un mécanisme qui permet à un utilisateur de se connecter une seule fois pour accéder à plusieurs applications. Il simplifie l’authentification sur IBM i (AS400).
Qu’est-ce que l’EIM sur IBM i ?
L’Enterprise Identity Mapping (EIM) est un mécanisme permettant d’associer différents identifiants provenant de systèmes ou de domaines distincts. Cette association est notamment utilisée pour mettre en place des mécanismes d’authentification simplifiés et centralisés.
Qu’est-ce que G-EIM ?
G-EIM est une solution innovante développée par GAIA MINI SYSTEMES pour rendre la gestion des identifiants EIM sur votre IBM i (AS400) beaucoup plus simple et sécurisée. Grâce à sa centralisation des associations EIM, il fait gagner un temps considérable à vos administrateurs !
Les avantages de G-EIM sur IBM i
Grâce à la solution, vous pouvez :
Visualiser facilement les associations existantes entre profils IBM i
Créer et modifier les associations entre profils IBM i et identifiant de domaine
Tester la configuration EIM de votre environnement afin de vérifier son bon fonctionnement
Charger l’ensemble des associations initiales en une seule commande
Dans de nombreux environnements IBM i, la création de profils utilisateurs est déjà automatisée via des programmes CL ou des procédures internes.
G-EIM s’intègre directement à ces processus afin d’automatiser également la création des associations EIM nécessaires au SSO.
Résultat : moins d’opérations manuelles, une réduction des erreurs et une gestion plus cohérente des identités.
Grâce à cette intégration par commandes, vous pouvez :
Intégrer la création des associations EIM dans vos programmes CL existants
Automatiser l’association des profils dès leur création
Garantir la cohérence entre les profils IBM i et les identifiants du domaine
Réduire significativement le temps consacré aux tâches d’administration
Vos équipes gagnent ainsi en efficacité tout en sécurisant la gestion des identités sur IBM i.
Dans de nombreuses architectures IBM i, plusieurs partitions coexistent et partagent des profils similaires : production, secours, environnements applicatifs, test ou encore développement.
G-EIM facilite la réplication des identifiants et des associations EIM entre ces différentes partitions.
Vous pouvez ainsi garantir une cohérence parfaite des configurations sur l’ensemble de votre infrastructure.
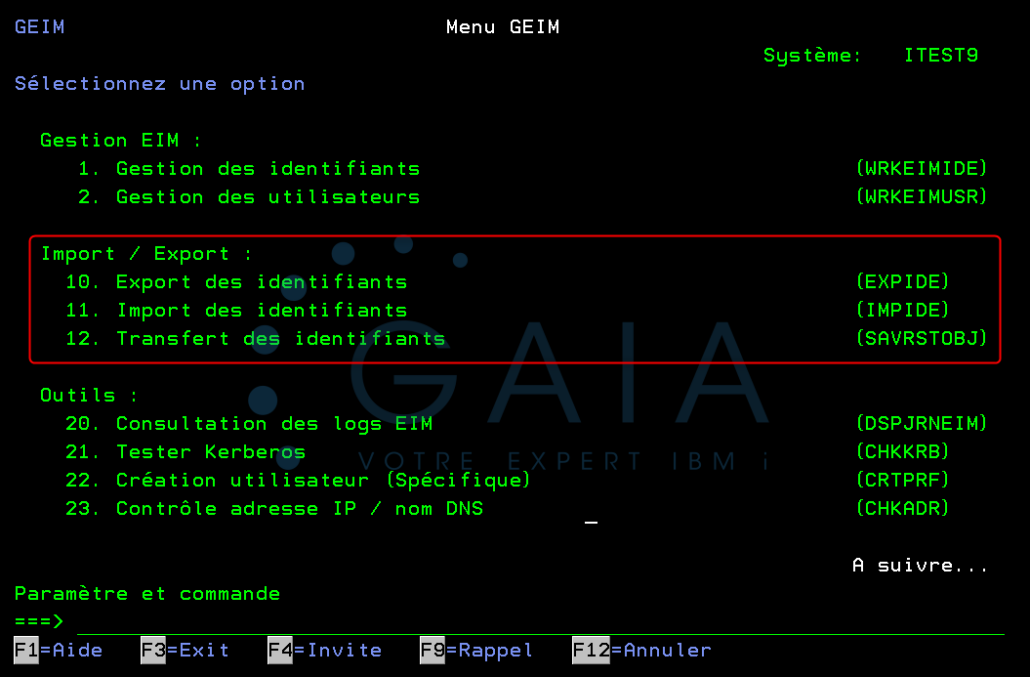
Grâce aux fonctions d’export / import de G-EIM, vous pouvez :
Exporter les identifiants et les associations depuis une partition IBM i
Importer rapidement ces données sur une autre partition
Répliquer facilement une configuration entre un environnement de production et un environnement de secours
Simplifier la gestion de plusieurs partitions IBM i
Cette fonctionnalité permet de sécuriser vos architectures tout en réduisant fortement le temps nécessaire aux opérations de bascule et de maintenance.
Mettre en place le SSO avec GEIM
La mise en place du SSO avec G-EIM permet une transition progressive vers une gestion centralisée des identités sur IBM i.
La solution s’intègre naturellement à l’existant, sans remettre en cause vos applications ou vos processus en place.
Elle permet également d’améliorer rapidement l’expérience utilisateur grâce à une authentification simplifiée et plus fluide.
Pour aller plus loin, contactez nos équipes afin de bénéficier d’une démonstration adaptée à votre environnement.
Quelle version d’IBM i est nécessaire pour utiliser G-EIM ?
G-EIM est compatible avec toutes les versions d’IBM i à partir de la version V7R3. Il s’intègre nativement aux environnements existants sans nécessiter de modification majeure de l’infrastructure.
G-EIM permet-il de gérer plusieurs identifiants pour un même utilisateur ?
Oui. G-EIM permet d’associer plusieurs profils sources à un même identifiant EIM. Cela facilite la gestion des environnements complexes et des correspondances entre utilisateurs et domaines.
Peut-on utiliser Navigator for i en parallèle de G-EIM pour la gestion EIM ?
Oui. GEIM peut être utilisé en parallèle de IBM Navigator for i. La solution est conçue pour fonctionner sans dépendance et s’intégrer aux outils IBM i déjà en place.
Peut-on automatiser la création des associations EIM avec GEIM ?
Oui. G-EIM s’intègre aux programmes CL existants afin d’automatiser la création des associations EIM dès la création des profils utilisateurs.
/wp-content/uploads/2017/05/logogaia.png00Florian Gradot/wp-content/uploads/2017/05/logogaia.pngFlorian Gradot2026-04-27 15:15:552026-06-23 16:20:46SSO (Single Sign-On) sur IBM i : Gérer les associations avec G-EIM
Aujourd’hui vous verrez comment installer, configurer et superviser les messages INQ de QSYSOPR avec Manzan pour les envoyer par mail.
Qu’est ce que Manzan ?
Manzan est un observability stack* (codé en Java) permettant de faciliter la supervisation d’une plateforme IBMi en interceptant des messages systèmes puis en les envoyant sur un serveur qui s’occupe de les rédiriger vers les destinations configurées.
*C’est un ensemble d’outils qui permettent de comprendre en profondeur ce qui se passe dans un système informatique en collectant, stockant et analysant ses métriques, logs et événements.
Il permet entre autre de :
surveiller les messages système (QSYSOPR, QSYSMSG, QHST)
surveiller les jobs (MSGW, CPU, statut, durée…)
surveiller les sous‑systèmes
surveiller les queue spools
surveiller les ressources système (CPU, mémoire, disques)
et bien d’autres…
déclencher des alertes
exécuter des actions automatiques (commandes CL, programmes CL/RPG)
exposer les données à Grafana, Prometheus, InfluxDB, etc.
Installation de Manzan
Créer un répertoire « download » sur IBM i (Pour y mettre votre installeur)
Télécharger la dernière version du manzan-installer-v#.jar ou avec la commande ci dessous : wget https://github.com/ThePrez/Manzan/releases/download/v0.0.X/manzan-installer-v0.0.X.jar
Si vous ne l’avez pas fait directement, transférer le .jar vers IBM i
Lancez l’installeur avec : java -jar manzan-installer-v0.0.X.jar
Configurez vos fichiers .ini
(Vous aurez surement besoin de Service commander si vous ne l’avez pas déjà)
Fichiers de configuration:
Il en existe 3 :
app.ini pour la configuration générale de Manzan (rien à toucher généralement)
data.ini pour configurer les sources et les données à traiter
Vous n’aurez rien besoin de faire particulièrement sur celui ci à part les lignes ci dessous ci ce n’est pas déjà fait :
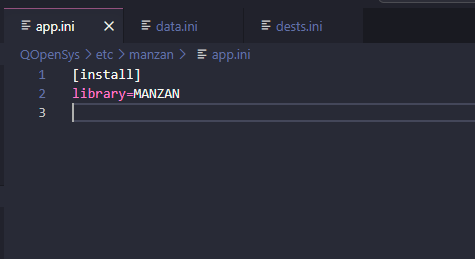
Vous indiquez ici la bibliothèque d’installation de Manzan
[install]
library=MANZAN
data.ini
Ce fichier contiendra toutes les sources que vous voudrez surveiller avec le choix du format
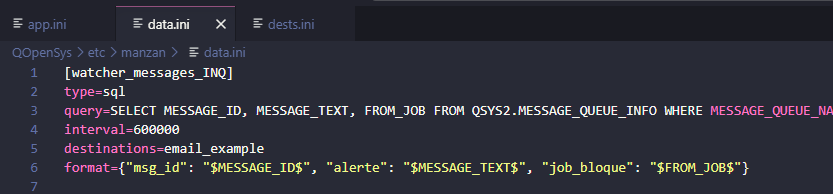
exemple de surveillance des messages INQ de la message queue QSYSOPR:
fichier data.ini :
[watcher_messages_INQ]
type=sql
query=SELECT MESSAGE_ID, MESSAGE_TEXT, FROM_JOB FROM QSYS2.MESSAGE_QUEUE_INFO WHERE MESSAGE_QUEUE_NAME = 'QSYSOPR' AND MESSAGE_TYPE = 'INQUIRY' AND ASSOCIATED_MESSAGE_KEY IS NULL
interval=600000
destinations=email_example
format={"msg_id": "$MESSAGE_ID$", "alerte": "$MESSAGE_TEXT$", "job_bloque": "$FROM_JOB$"}
[watcher_messages_INQ] : un id complètement arbitraire, vous pouvez le renommer comme bon vous semble
type : le type est sélectionné en fonction de la donnée à analyser. Au dessus par exemple on souhaite faire une requête pour récupérer les bonnes lignes à regarder c’est donc SQL.
query : requête SQL pour regarder les messages INQUIRY dans QSYSOPR
interval : l’interval (en ms) qui séparera chaque itération de votre requête (ici toutes les 10 minutes)
destinations : un lien vers votre fichier dests.ini dans lequel vous configurerez comment envoyer les données sélectionnées vers la/les sources que vous préciserez ici. Gardez aussi en mémoire qu’il peux y avoir plusieurs destinations séparées par des virugles.
format : Ce format de message sera son « corps ». Ce sera la façon dont vous verrez les données une fois transmises.
(à noter que toutes vos données doivent être bornées par des $)
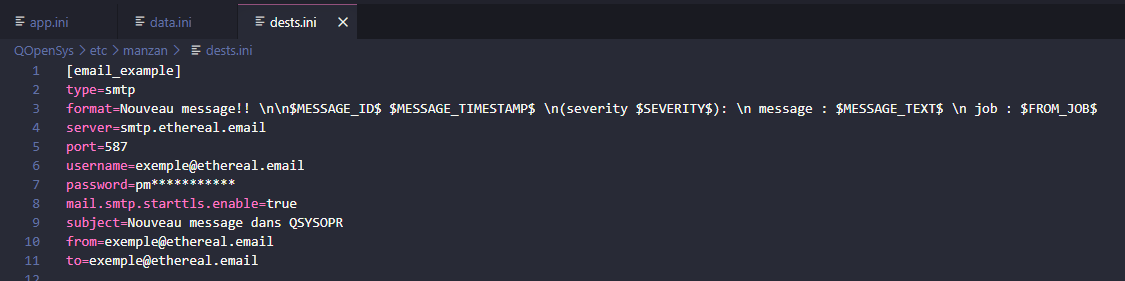
dests.ini
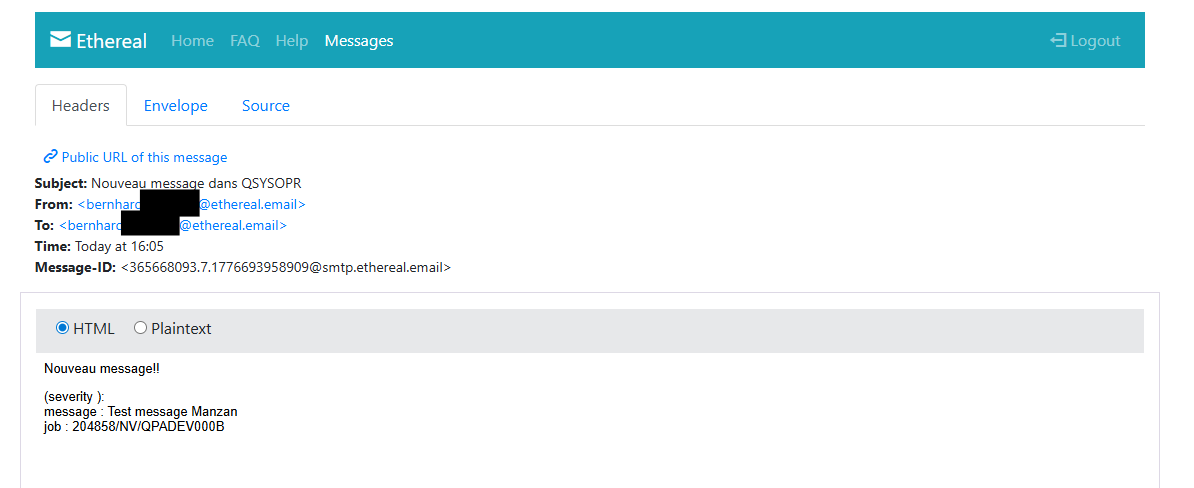
Ce fichier est composé de nombreuses sections qui définissent des destinations de données. Une destination est en fait un emplacement (comme un service) vers lequel les données peuvent être envoyées. Dans cet exemple j’utilise Ethereal Email qui permet d’avoir une boite mail jetable, utile pour les tests
type : même fonctionnement que dans data.ini mais cette fois ce sera la méthode d’envoi de données. Tous les types sont répertoriés ici : Types de destinations
format : même principe que dans data.ini sauf qu’ici, le format n’est pas à envoyer à destinations mais sera le format final que vous verrez, ce sera le formattage de votre « log » personnalisé (exemple en dessous)
serveur : explicitement le serveur vers lequel vous voulez envoyer votre message (ici Ethereal Email)
username : votre adresse mail
password : un identifiant propre à votre mail, vous est donnée directement à la connexion sur des services comme Ethereal Email, sinon à chercher dans vos paramètres de sécurité sur les domaine comme gmail ou hotmail.
port : port de sortie (pour envoyer) du service de mail choisi, en général ce sera toujours 587
mail.smtp.starttls.enable : sert à activer ou non le chiffrage de vos données sur le serveur
subject : l’objet du mail
from et to : respectivement l’email de l’envoyeur et du destinataire (peut être le même)
les paramètres changent en fonction de la destination, ils sont très explicites et bien documentés avec beaucoup d’exemples dans la documentation dans la catégorie des Destinations.
🚨Faites attention !
La QSYSOPR envoie beaucoup de messages qui ne sont pas INQUIRY donc pensez bien à faire la requête sur les messages INQ (comme dans les exemples ici). Sinon si vous utilisez votre boite mail, vous serez surement spam, c’est pourquoi dans cet exemple nous utilisons un email jetable en ligne.
Comment lancer Manzan ?
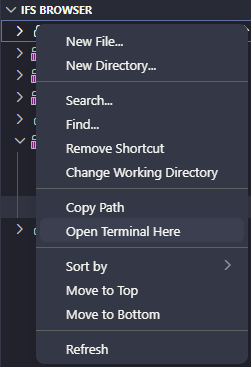
Il faut se mettre au bon endroit sur votre IFS, dans le répertoire où vous avez effectué l’installation de manzan en général. Soit vous y naviguez manuellement soit par VSCode vous avez cette option « Open Terminal Here » :
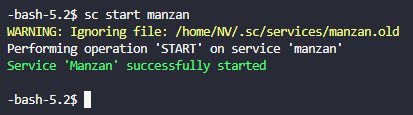
Ensuite une fois sur votre terminal vous taperez : sc start manzan
Vous devriez avoir ce message en vert s’afficher au bout de quelques secondes vous indiquant que c’est lancé.
(Mon Warning est dû au fait que j’ai gardé mon ancien .yaml en .old en tant que backup, vous ne devriez pas avoir ce message)
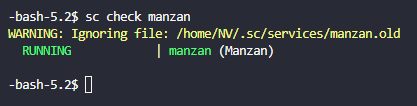
Pour être sûr que Manzan est lancé, tapez : sc check manzan et vous devriez voir cela :
Si vous avez des problèmes ou que le serveur vous fait des timeout regardez les .yaml
le premier se trouve dans ./.sc/services/manzan.yaml
le 2e se trouve dans /opt/manzan/bin/manzan.yaml
Pensez à déclarer vos variables d’environnements comme :
MANZAN_MESSAGING_PREFERENCE=SQLMANZAN_SOCKET_PORT=8888 (prenez un port qui n’est pas déjà pris) export LC_ALL=FR_FR.UTF-8 à mettre dans votre .profile
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-04-21 10:34:002026-05-05 11:31:22Premiers pas vers Manzan
Sur IBM i, les groups d’activation sont au cœur de l’architecture ILE. Ils permettent de mutualiser efficacement les ressources tout en offrant un cadre d’exécution structuré et performant.
Dans la majorité des cas, le mécanisme de nettoyage automatique fourni par le système suffit largement. Mais dès que l’on travaille avec des service programs persistants, des ressources externes ou des APIs dont le cycle de vie dépasse un simple appel de programme, il devient nécessaire de reprendre la main.
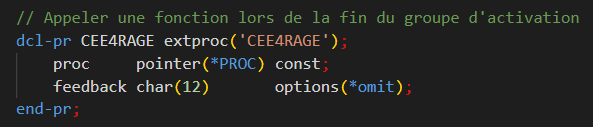
C’est précisément là qu’intervient l’API CEE4RAGE.
CEE4RAGE signifie Register Activation Group Exit Procedure.
Son rôle est très simple mais fondamental : elle permet d’enregistrer une procédure qui sera appelée automatiquement lorsque l’activation group est détruit. Cette procédure est exécutée après les exit procedures des langages de haut niveau, mais avant le nettoyage final effectué par le système. On peut la voir comme un équivalent conceptuel d’un destructeur dans les langages orientés objet.
En effet, certains « nettoyages » ne peuvent pas, ou ne doivent pas, être laissés au seul mécanisme système. Certains composants nécessitent une fermeture explicite : mémoire allouée dynamiquement, connexions réseau persistantes, APIs externes, sockets, workers auxiliaires ou encore structures partagées. CEE4RAGE garantit que votre code de nettoyage sera exécuté quelle que soit la manière dont l’activation group se termine : retour normal, reclaim, exception ou même ENDJOB.
Le besoin dépend clairement du code ILE produit.
Usage
Un cas d’usage très courant concerne les service programs persistants. Lorsqu’un service program est chargé dans un activation group nommé ou avec *ACTGRP(CALLER), il peut rester actif longtemps, parfois pendant toute la durée de vie d’un job interactif. Dans ce contexte, il est essentiel de disposer d’un point fiable pour libérer proprement les ressources lorsque l’activation group disparaît enfin. CEE4RAGE fournit exactement ce point d’ancrage.
Une approche éprouvée consiste à mettre en place un pattern « constructeur / destructeur ». L’idée est simple : initialiser les ressources lors du premier appel effectif au service program, puis enregistrer une exit procedure via CEE4RAGE pour garantir le nettoyage automatique à la fin de l’activation group.
Exemple
Voyons maintenant un exemple concret en RPGLE free format, typique d’un service program.
Le service program est défini sans programme principal, hors DFTACTGRP, et dans un activation group persistant :
Le cœur du pattern repose sur une procédure d’initialisation, appelée systématiquement par les procédures métier exportées, mais dont le contenu réel ne s’exécute qu’une seule fois :
dcl-proc InzSrvPgm;
if Initialized;
return;
endif;
// Initialisation des ressources (exemple simulé)
ResourceHandle = 12345;
// Enregistrement de l'activation group exit procedure
CEE4RAGE(%paddr(EndSrvPgm): *omit);
Initialized = *on;
end-proc;
Cette procédure effectue trois choses essentielles :
elle initialise les ressources
enregistre l’exit procedure
mémorise le fait que l’initialisation est désormais réalisée
La procédure de terminaison, elle, sera appelée automatiquement par le système lorsque l’activation group prendra fin. Elle doit impérativement être exportée et respecter la signature attendue par l’ILE :
Enfin, toutes les procédures métier exportées commencent par appeler la procédure d’initialisation. Cela garantit que l’environnement est prêt avant toute logique fonctionnelle :
Une procédure d’exit d’activation group repose sur une interface composée de quatre paramètres standards, transmis automatiquement par le runtime lors de la terminaison de l’activation group :
agMark, correspond au marqueur interne de l’activation group. Il s’agit d’un identifiant numérique unique dans le job, principalement utile à des fins diagnostiques ou pour des scénarios avancés impliquant plusieurs activation groups simultanés. Dans la majorité des cas, ce paramètre est simplement ignoré, mais il permet théoriquement de corréler une terminaison précise à un contexte donné.
reason, indique la raison de la fin de l’activation group : retour normal, reclaim, fin de job, exception non interceptée, etc. Ce code est particulièrement précieux pour adapter le comportement du cleanup, par exemple en évitant certaines opérations coûteuses lors d’une fin brutale.
result et userRC, sont des champs en entrée/sortie permettant respectivement au système et au programme de communiquer un code de résultat et une information spécifique utilisateur. En pratique, ils sont rarement exploités, mais ils offrent un mécanisme de retour standardisé permettant à une exit procedure de signaler son état ou d’influencer légèrement le déroulement du traitement global. L’ensemble de ces paramètres est optionnel côté RPG, ce qui explique l’usage fréquent de options(*nopass) ; toutefois, leur présence formalise le contrat entre le runtime ILE et la procédure d’exit, et rappelle que cette dernière s’exécute dans un contexte très particulier, où la logique doit être minimale, robuste et parfaitement maîtrisée.
Multiples procédures
Dans certains cas plus avancés, il peut être tout à fait légitime d’enregistrer plusieurs procédures d’exit pour un même activation group.
CEE4RAGE ne limite ni le nombre de procédures enregistrées, ni leur nature : chaque appel ajoute une entrée dans la pile des exit procedures, qui seront exécutées dans l’ordre inverse de leur enregistrement lors de la fin de l’activation group.
Cette capacité est particulièrement utile lorsque plusieurs composants indépendants partagent le même activation group : chaque service program peut alors enregistrer sa propre procédure de nettoyage, sans dépendre d’un point centralisé.
Il est cependant essentiel de concevoir ces exit procedures comme autonomes, simples et robustes, car une défaillance dans l’une d’elles empêche l’exécution des suivantes. Dans ce contexte, l’ordre d’enregistrement devient un véritable élément d’architecture : on veillera par exemple à enregistrer en dernier les procédures critiques, ou à utiliser une procédure « chef d’orchestre » qui appelle explicitement plusieurs routines de cleanup internes.
L’utilisation de procédures d’exit multiples est donc un mécanisme puissant, mais qui impose une discipline stricte : absence d’effets de bord, opérations idempotentes, et compréhension claire du cycle de vie global de l’activation group.
Conclusion
Ce pattern est robuste, simple et parfaitement aligné avec les mécanismes de l’ILE.
Il fonctionne aussi bien en batch qu’en interactif, résiste aux fins de job brutales et assure un comportement prévisible dans les architectures persistantes. Il est particulièrement adapté aux environnements modernisés où des composants RPG sont exposés comme briques partagées, parfois appelées par des couches Java, C ou web.
Il convient toutefois de garder quelques points en tête. CEE4RAGE n’est jamais appelée tant que l’activation group reste actif ; si celui-ci est volontairement maintenu pendant toute la durée du job, le nettoyage n’aura lieu qu’à la toute fin. De plus, si une exit procedure échoue, les suivantes ne seront pas exécutées. Il est donc essentiel d’y écrire un code simple, robuste et sans dépendances fragiles.
En conclusion, CEE4RAGE est une API discrète mais fondamentale. Elle ne sert pas à gérer des erreurs ni à intercepter des messages système ; elle sert à maîtriser la fin de vie d’un activation group.
Dès que l’on conçoit des service programs persistants et que l’on vise une architecture propre et professionnelle sur IBM i, CEE4RAGE devrait faire partie des outils de base de tout concepteur ILE.