


Nous sommes de plus en plus nombreux à utiliser Code for IBM i !
Nous avons de nombreuses questions sur cet outil, en constante évolution.
Cette semaine, nous avons choisi de parler des profils, et de la confusion entre le profiles Visual Studio Code et les profils Code for IBM i.
Nous n’en parlerons pas ici !
Un profil IBM vous permet de vous connecter à la machine et n’existe que côté serveur.
La notion de profils dans Visual Studio Code (noté VSCode pour la suite) concerne la configuration des environnements de travail dans l’IDE.
A la connexion à votre IBM i, VSCode établi une communication via un job SSH. Ensuite, l’interface propose plusieurs éléments de configuration et de navigation :
Une fois connecté, la liste de bibliothèque affichée est celle utilisée à votre dernière connexion.
Vous pouvez modifier la bibliothèque en cours par click droit sur current library (ouvre un prompt) ou sur click droit sur une bibliothèque à définir comme en cours :
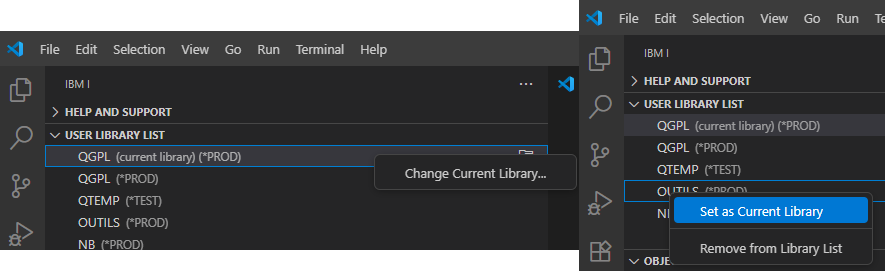
De même pour la liste de bibliothèque : ajout / suppression / réorganisation :
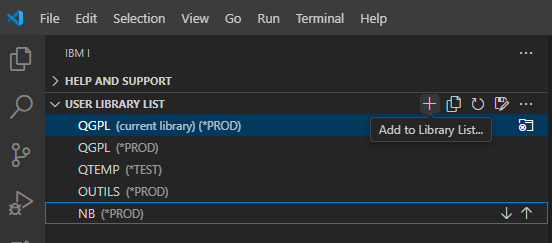
Une fois votre environnement configuré, la sauvegarde sous forme de profil vous permet de mémoriser cette configuration et de pouvoir revenir dessus plus rapidement par la suite :
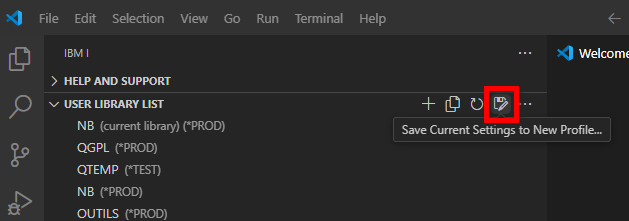
Donner un nom à l’enregistrement :

Une nouvelle option de gestion des profils est alors affichée :
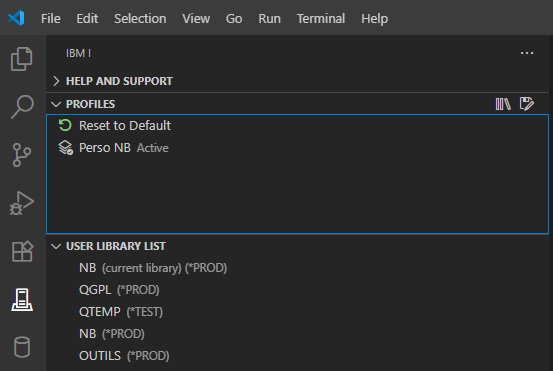
Elle vous permet de revenir à la situation d’origine de votre profil (si vous avez ajouter/supprimer des bibliothèques par exemple) :
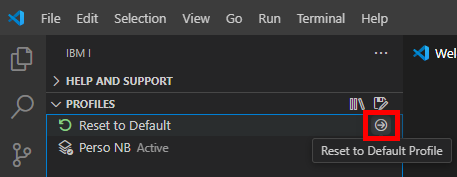
Mais surtout vous pouvez créer d’autres profils, correspondants à d’autres situations :
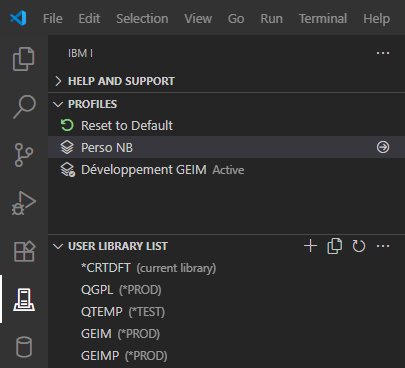
Vous pouvez aussi créer un profil directement en indiquant une commande de mise en place de l’environnement, basiquement un CHGLIBL :
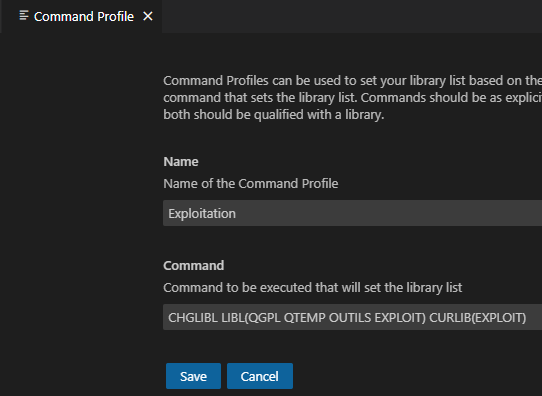
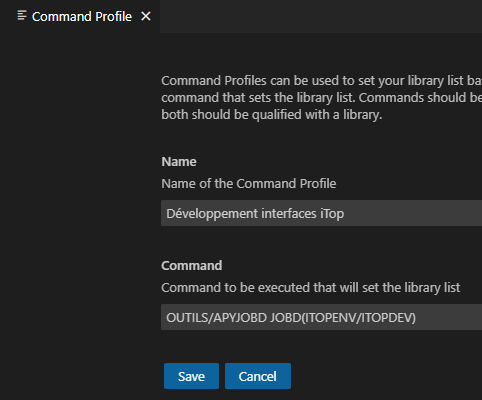
Pour plus de souplesse, surtout lors de travail en équipe, nous vous conseillons de créer une *JOBD par « projet » côté serveur, avec une commande qui met en place les bibliothèque de la *JOBD. Cela vous permet de modifier la *JOBD sans intervenir sur l’ensemble des clients :
En réalité, le profil permet de stocker l’ensemble des éléments suivants :
N’oubliez pas d’aller voir la documentation : https://codefori.github.io/docs/
Le profil Visual Studio Code vous permet d’avoir plusieurs configurations de VSCode avec une installation unique : des attributs de l’environnement peuvent être modifiés via un fichier de configuration.
Depuis le menu des paramètres, aller dans les profils :
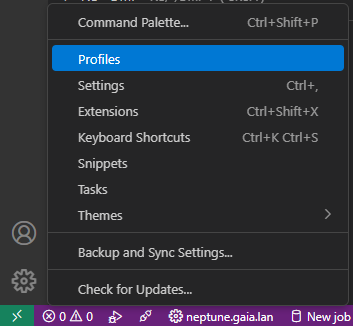
Nous pouvons alors gérer les profils, en créer/supprimer, modifier les attributs :
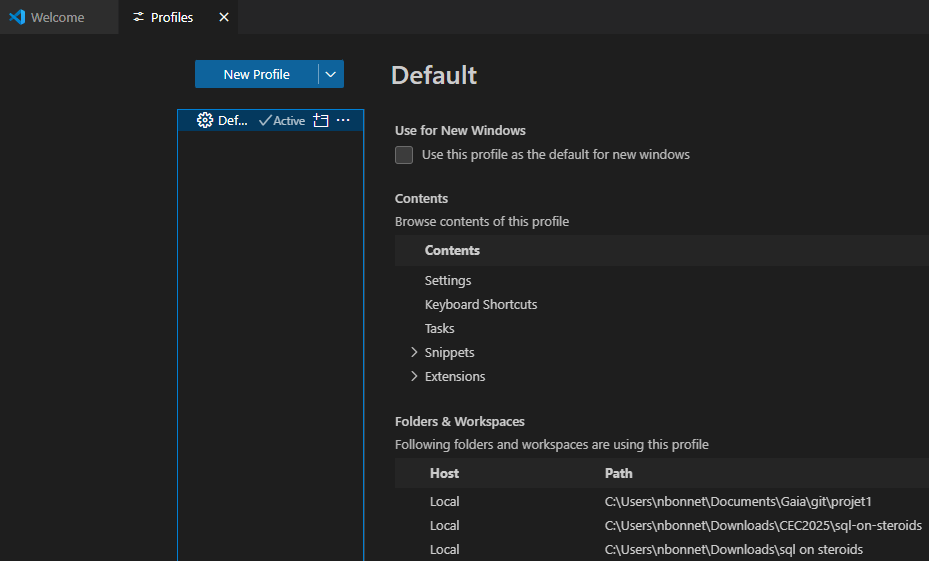
Il est par exemple possible de créer un profil :
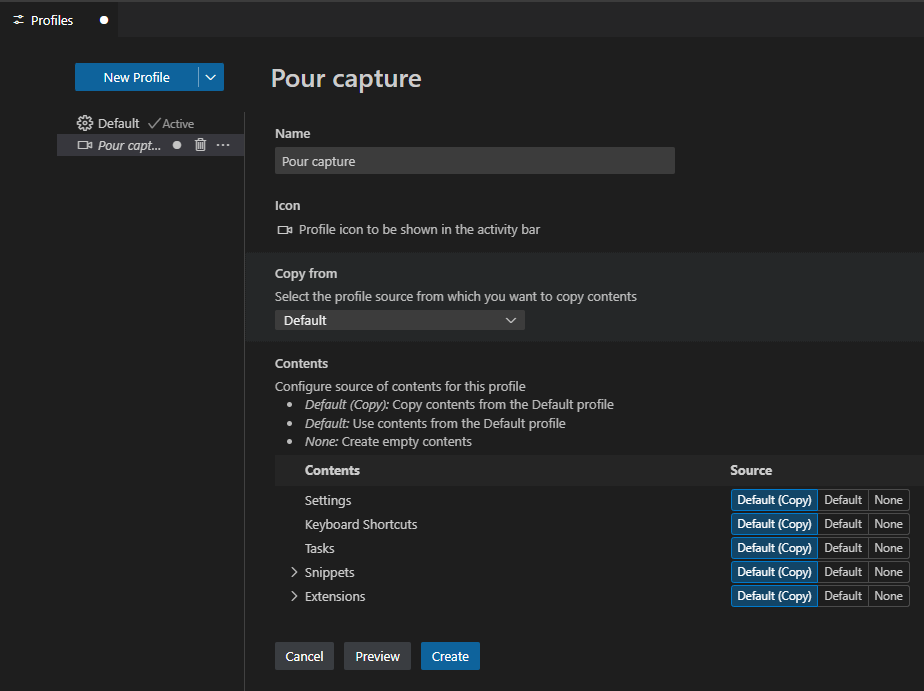
Par copie d’un profil existant, ou totalement vide. Et lors de la copie, vous choisissez les éléments de paramétrages, de personnalisation de clavier etc … Une icône spécifique peut être attribuée pour identifier rapidement les profils.
Certains profils types sont également fournis :
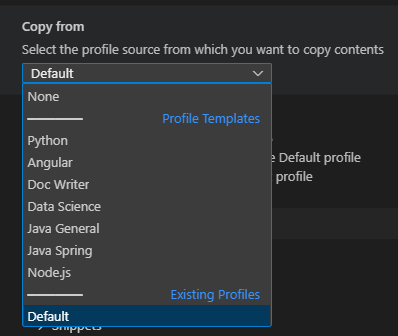
Une fois le profil créé, vous pouvez passer de l’un à l’autre :
Ou bien ouvrir une autre fenêtre avec un profil différent :
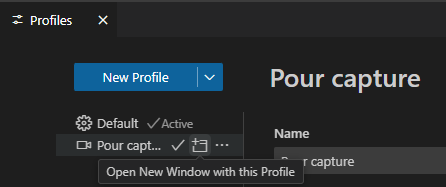
Depuis les propriétés du profil, les différentes catégories (Settings, keyboard shortcuts etc …) correspondent à des fichiers de configuration différents. Lorsque vous double-cliquer sur « Settings » :
Vous pouvez modifier les propriétés en direct, le changement est pris en compte à l’enregistrement du fichier :
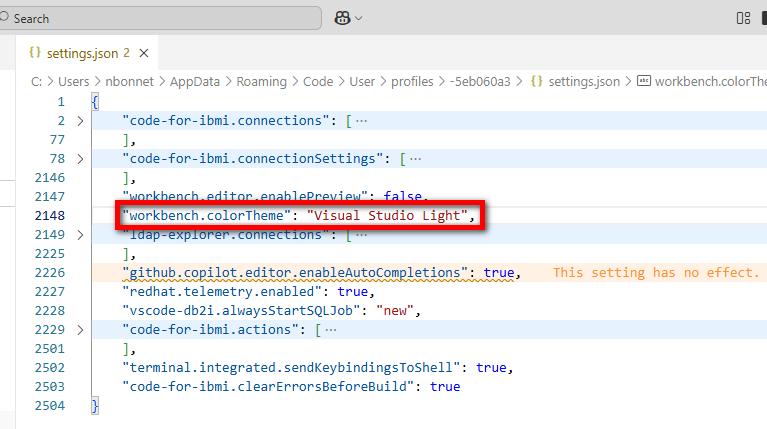
Vous remarquez que l’ensemble des informations des profils Code for IBM i sont stockés ici, dans les profils Visual Studio Code :
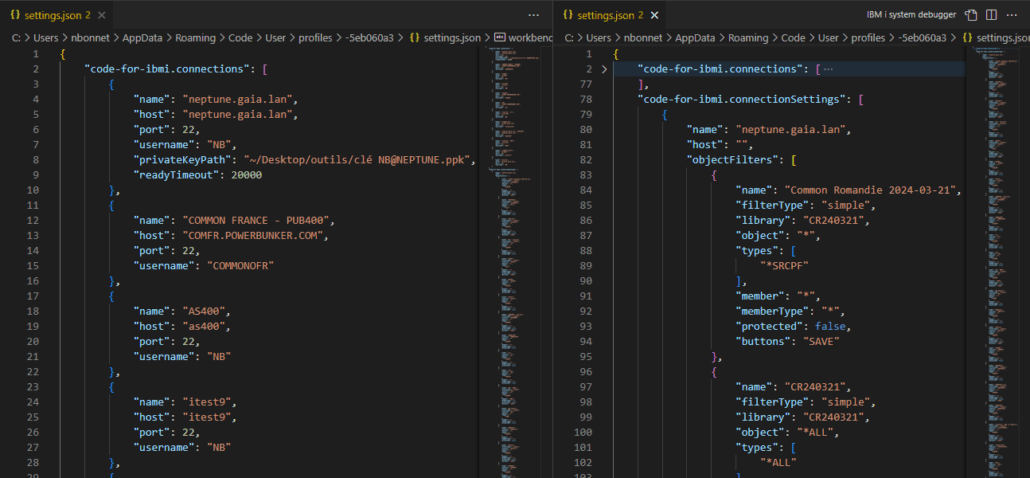
Vous pouvez donc facilement éditer, modifier, échanger (regarder les options d’import/export) toutes les configurations afférentes.
Avec un peu d’habitude, vous pouvez ouvrir différentes instances pour différents usage.
Franchement un titre à attirer les clics ! Quel rapport entre des sports où des gens se mettent des coups, s’étranglent, se projettent et notre métier, si valorisant, si doux, dur parfois mais moins sanglant et brutal ?
Rien…et beaucoup quand même.
Pour ceux qui me connaissent, vous n’apprendrez rien mais pour les autres, j’ai passé beaucoup de temps sur les tatamis et autres salles à pratiquer des sports de combat. Et ce, depuis plus longtemps que je ne pratique l’informatique, bien que tombé dedans tout petit, avec les TO7, Amstrad CPC6128, Sinclair ZX81 Spectrum et autres avant de succomber aux sirènes du marché de l’emploi et à celles moins connues à l’époque des AS400 (eh oui, cela s’appelait bien des AS400 !).
Et une comparaison s’impose.
Le Judo
Je me souviens de moi, jeune judoka, m’entraînant à Lyon, 10 heures ou plus par semaine. En pleine poussée de testostérone mes camarades et moi-même regardions en nous moquant un peu quand même, Jacky et Raymond. Deux vieux judokas qui s’époumonaient dans le fond lors des échauffements, qui commençaient la séance par faire du sol avec des petits jeunes et qui peinaient à reprendre leur souffle après mais qui immanquablement recommençaient, séance après séance, à prendre ces petits jeunes pour les faire forcer au sol, au risque de se provoquer un infarctus. Bon, certaines de leurs techniques n’étaient plus d’actualités, dépassées et même dangereuses ou interdites.
Et de l’autre côté, nous, les ceintures noires, nous l’élite du club, ensemble en train de discuter, de s’entraîner entre nous. Bon, je n’ai jamais été très « élitiste ». L’entre-soi n’est pas ce que je préfère. Mais en ces temps pas si reculés, quand vous obteniez votre ceinture noire au prix de nombreuses souffrances, de fractures, de sacrifices personnels et de déceptions maintes fois répétées devant l’échec, il semblait justifié de savourer ce moment de gloire.
Etant très proche de mon professeur de l’époque, Maître Roger Bourgery, j’appris que Raymond, pour ne parler que de lui, avait été mainte fois champion d’Algérie en Judo. Après l’indépendance, Raymond était venu en France poursuivre sa vie et continuer le Judo en gagnant encore quelques titres de gloire.
Maître Bourgery, mon professeur, nous rappela un précepte fondateur du judo : Jita Kyoei « entraide et prospérité mutuelle ». Et j’avoue que je pris comme mes camarades ceintures noires une bonne claque. L’entre-soi égoïste des jeunes coqs versus l’entraide des anciens, la transmission du savoir.
J’ai été ce que vous êtes, vous serez ce que je suis. Nos vies n’ont pas changé du jour au lendemain, je donnais déjà des cours de judo aux enfants et ados, pratiquement tous les soirs, mais certaines règles furent instaurées à l’entraînement : interdiction de refuser l’invitation d’une ceinture moins élevée, pour les combats ou pour l’entraînement. Il faut aussi donner pour recevoir et redonner ce que nous avions reçu.
L’humilité c’est aussi de reconnaître que l’on ne sait pas tout et que l’on peut aussi apprendre de ces ceintures moins élevées. En y repensant, maintenant que je suis moins frais et moins sportif, j’ai un autre regard sur ces vieux qui traînent dans un coin du bureau, qui font encore du GAP II ou du COBOL, qui se coltinent du colonné, du Matching, des fichiers Primaires et secondaires, voir du 36 ! Je dois me rappeler que ces vieux (et vieilles) ont été par le passé, souvent, des précurseurs de l’AS400 en remplaçant le cycle gap, en créant des sous-fichiers, en mettant de la couleur sur leurs écrans, que sais-je encore.
Ce sont ces mêmes personnes qui ne sont plus up-to-date, mais qui transmettent encore des notions. On a eu récemment un client qui est passé d’un environnement 36 à du plus…moderne. Nos « vieux briscards » ont retroussé les manches, et leur connaissance de « l’ancien temps » et des ponts pour arriver aux « temps modernes » ont été mis à contribution. Ils ont été utiles pour faire le lien et montrer « leur » métier.
Mais ils savent nous rappeler que si on bâtit sur le passé, cela reste « le passé ». On ne vit pas dans le passé, on vit avec. Il n’y a pas de « c’était mieux avant ». Il y a du « c’était comme cela avant mais maintenant on fait autrement et peut-être mieux ».
Pour finir, nous ne sommes pas tous des ceintures noires de l’IBM i, loin de là. Et certains anciens pensent encore que « c’était mieux avant » et deviennent des spécialistes…du passé.
Mais même si nous sommes des ceintures marrons, noires des années 90 ou des années 2000, 2010, 2020… il y a plein de ceintures blanches qui frappent à nos portes, qui peuvent et doivent apprendre.
Pas apprendre que c’était mieux avant, mais qu’il y avait un « avant » et surtout un « après » et que cet « après » ne soit pas une fin en soi. Que cet « après » deviendra un « c’était le bon temps » pour ceux qui sont les jeunes ceintures noires d’aujourd’hui. A nous de transformer notre pouvoir en un savoir à dispenser.
Attention, ce n’est pas un chant du cygne. C’est juste un rappel, comme dans mes années de judoka, que notre communauté est composée de ceintures de tous niveaux, de tous âges et que « l’entraide et la prospérité mutuelle » est une très belle notion à mettre en pratique.
C’est aussi un rappel aux anciens de leurs devoirs : transmettre et continuer à apprendre.
Dans une base de données bien définie, nos enregistrements sont identifiés par des clés (ie unique). Il existe toutefois différentes façon de matérialiser ces clés en SQL.
Première bonne résolution : on ne parlera pas ici des DDS (PF/LF) !
je n’insiste pas, mais une base de donnée relationnelle, DB2 for i dans notre cas, fonctionne à la perfection, à condition de pouvoir identifier nos enregistrements par des clés.
Cf https://fr.wikipedia.org/wiki/Forme_normale_(bases_de_donn%C3%A9es_relationnelles)
Une normalisation raisonnable pour une application de gestion est la forme normale de Boyce-Codd (dérivée de la 3ème FN).
Vous pouvez implémenter vos clés de différentes façons, voici une synthèse :
| Type | Où | Support valeur nulle ? | Support doublon ? | Commentaire |
| Contrainte de clé primaire | Table | Non | Non | Valeur nulle non admise, même si la colonne clé le supporte |
| Contrainte d’unicité | Table | Oui | non : valeurs non nulles oui : valeurs nulles | Gère des clés uniques uniquement si non nulles |
| Index unique | Index | Oui | Non | Gère des clés uniques. La valeur NULL est supportée pour 1 unique occurrence |
| Index unique where not null | Index | Ouis | non : valeurs non nulles oui : valeurs nulles | Gère des clés uniques uniquement si non nulles |
Attention donc à la définition de UNIQUE : à priori ce qui n’est pas NULL est UNIQUE.
Prenons un cas de test simpliste pour montrer la mécanique : un fichier article avec une clé et un libellé
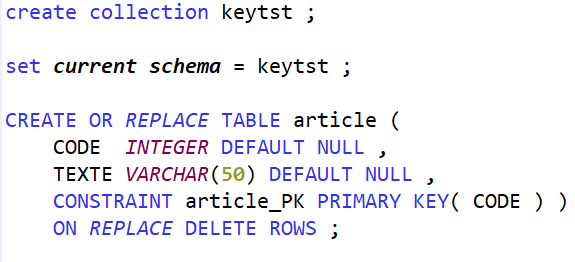
La colonne CODE admet des valeurs nulles, mais est fait l’objet de la contrainte de clé primaire.
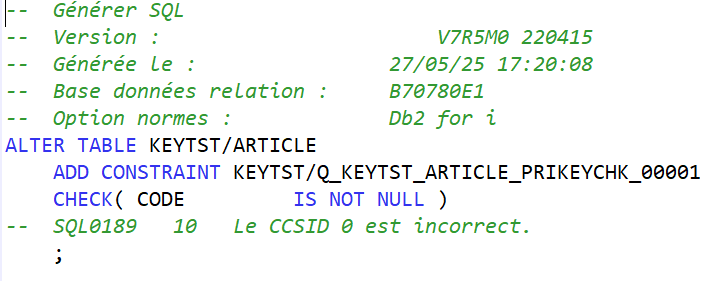
A la création de la contrainte de clé primaire, le système créé automatiquement une contrainte de type CHECK pour interdire l’utilisation de valeur nulle dans cette colonne :

Avec :
La clé primaire joue son rôle avec des valeurs non nulles :

Et des valeurs nulles :

On retrouve ici le nom de la contrainte générée automatiquement !
Le comportement est identique sur une clé non nulle.
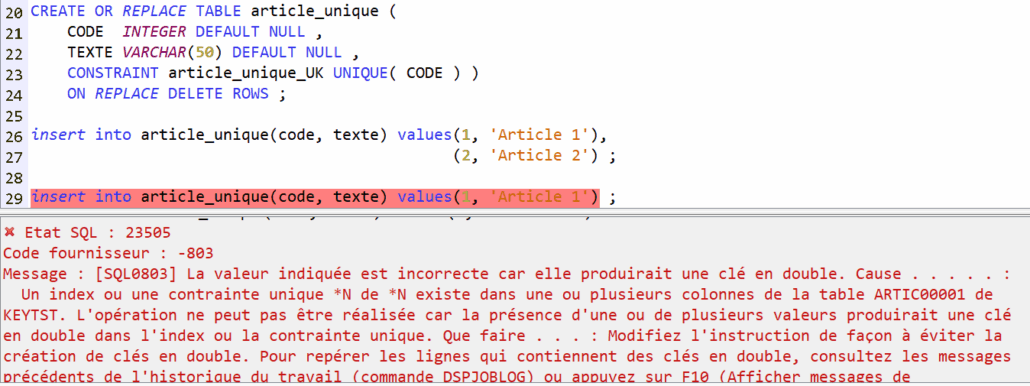
Mais avec une clé nulle (ou dont une partie est nulle si elle composée) :
On peut ajouter un index unique pour gérer le problème. Dans ce cas, une et une seule valeur nulle sera acceptée :

Mais dans ce cas pourquoi ne pas utiliser une clé primaire ??
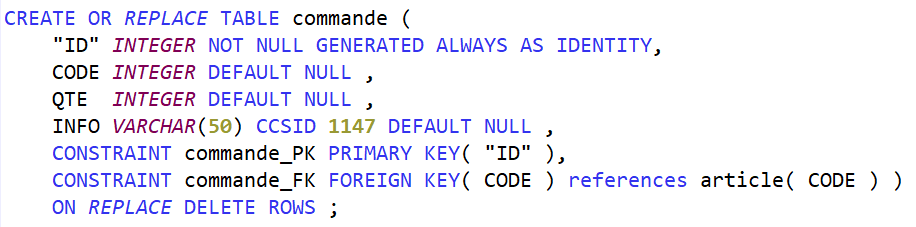
Ajoutons un fichier des commandes, ici une simplification extrême : 1 commande = 1 article.
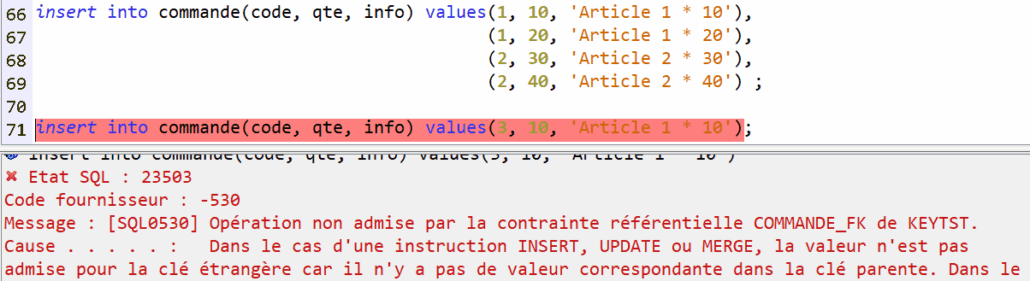
On ajoute une contrainte de clé étrangère qui matérialise la relation entre les tables commande et article. Pour cette contrainte commande_FK, il doit exister une contrainte de clé primaire ou de clé unique sur la colonne CODE dans la table article.
La contrainte se déclenche si l’article référencé n’existe pas :
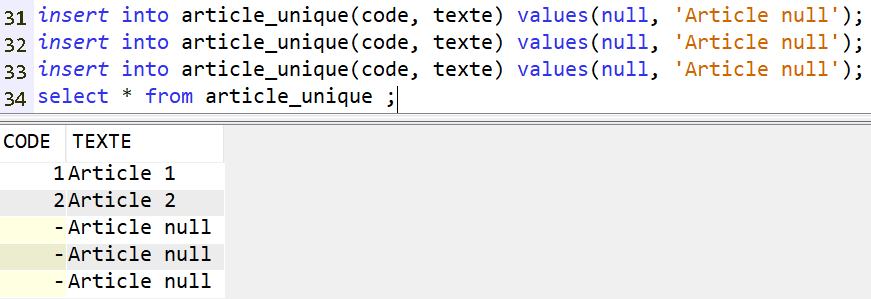
Cas identique mais en s’appuyant sur la table article_unique qui dispose d’une clé unique et non primaire :
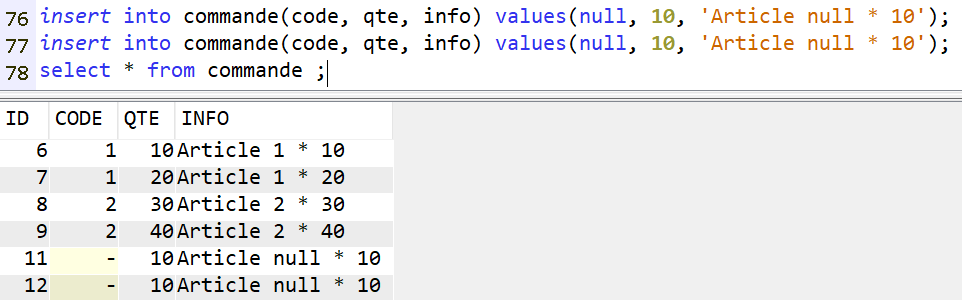
Dans ce cas les valeurs nulles sont supportées, en multiples occurrences (sauf à ajouter encore une fois un index unique au niveau de la commande).
Récapitulons ici nos données pour comprendre les jointures :

Démarrons par ARTICLE & COMMANDE :
La table ARTICLE ne peut pas avoir de clé nulle, donc pas d’ambiguïté ici

Avec right join ou full outer join nous accèderons au lignes de commande pour lesquelles CODE = null.
C’est le comportement attendu.
Voyons avec ARTICLE_UNIQUE et COMMANDE :
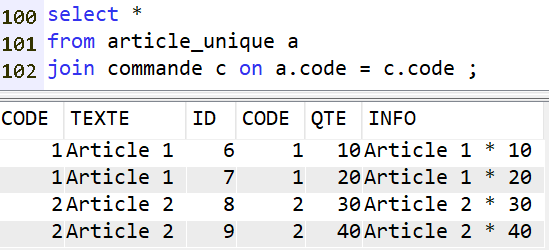
Ici on pourrait s’attendre à obtenir également les lignes 11 et 12 de la table COMMANDE : le CODE est nulle pour celles-ci, mais il existe une ligne d’ARTICLE pour laquelle le code est null. Il devrait donc y avoir égalité.
En réalité les jointures ne fonctionnent qu’avec des valeurs non nulles
De même que la clause WHERE :
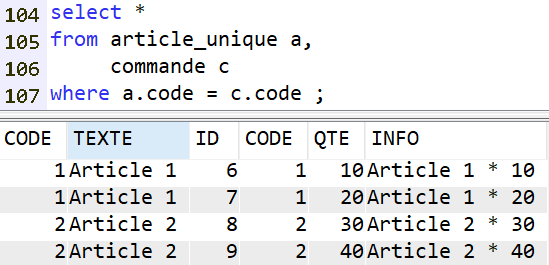
Il faut donc utiliser ce style de syntaxe :
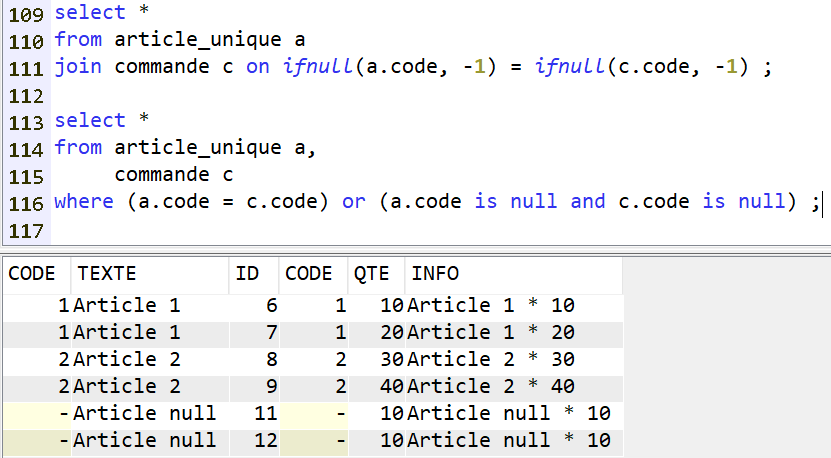
C’est à dire :
Bref, syntaxiquement cela va rapidement se complexifier dans des requêtes plus évoluées.
Evidemment, c’est pire ! Imaginons que l’on ait une clé primaire/unique dans la table ARTICLE composée de 2 colonnes (CODE1, CODE2), et donc présentes toutes les deux dans la table COMMANDE :

En utilisant la jointure, l’optimiseur est capable de prendre en charge des accès par index :
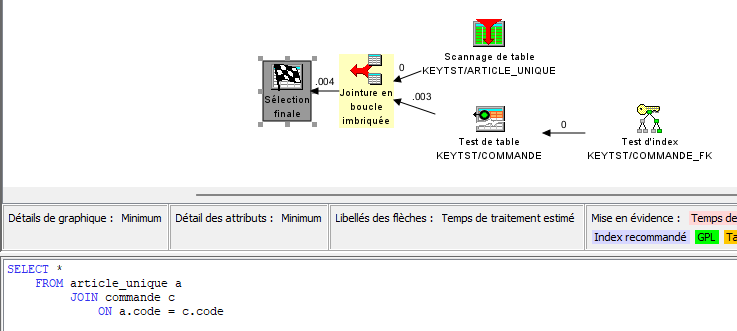
Mais en utilisant IFNULL/COALESCE, ces valeurs deviennent des valeurs calculées, ce qui invalide l’usage des index :
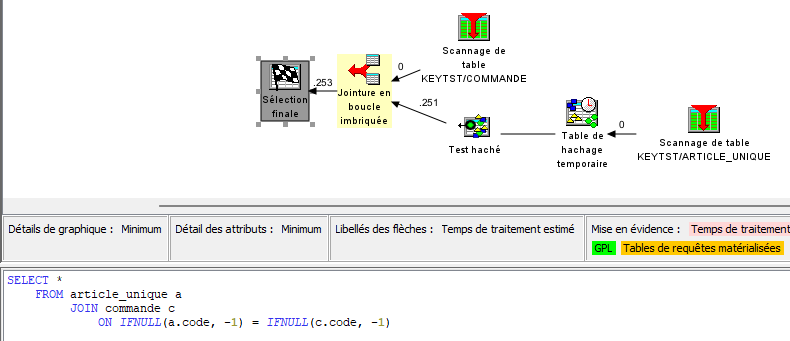
Ce n’est donc pas viable sur des volumes plus importants. Il existe des solutions (index dérivés par exemple) mais la mécanique se complique encore !
De façon générale pour vos données de gestion, en excluant les fichier de travail (QTEMP a d’autres propriétés), les fichiers de logs, les fichier d’import/export …