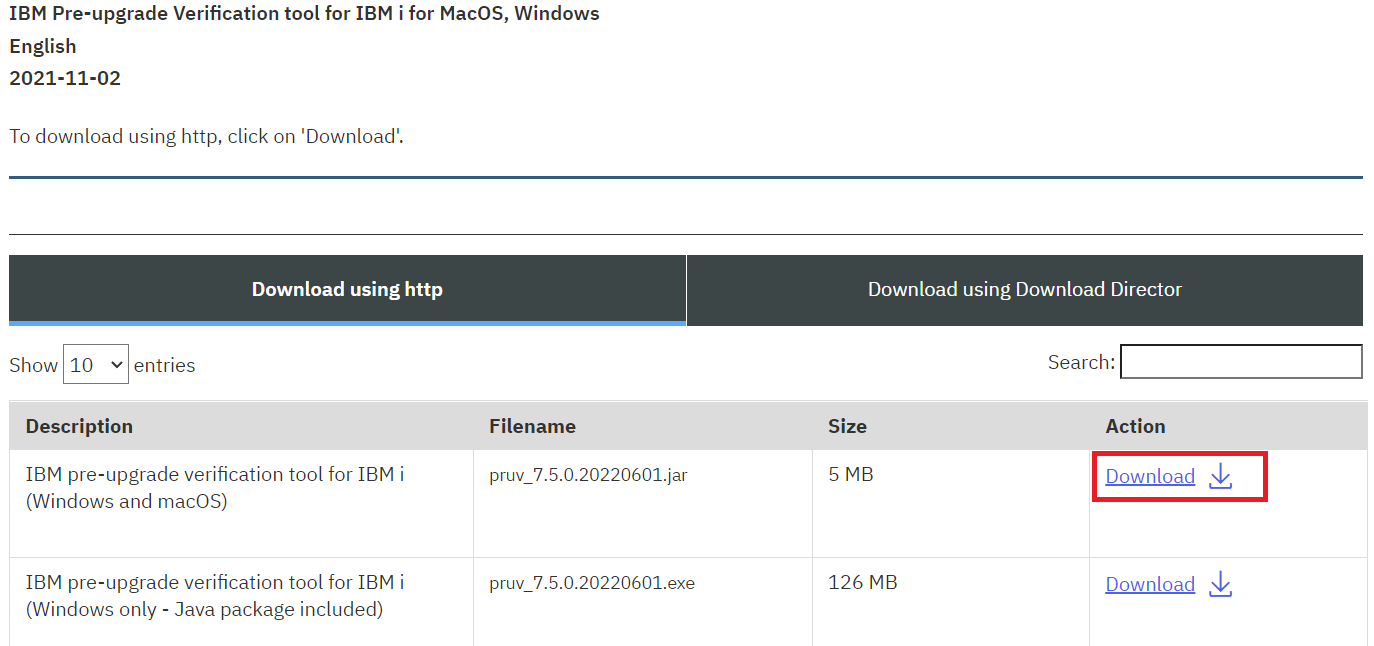
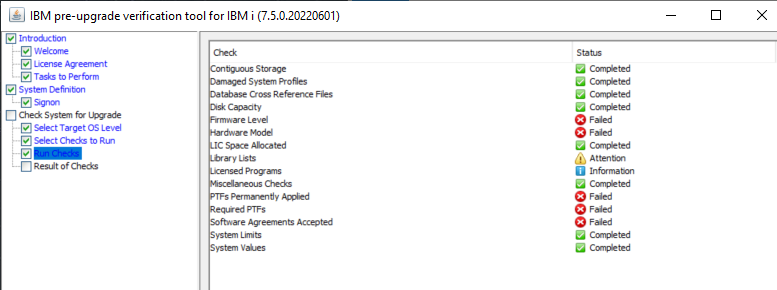
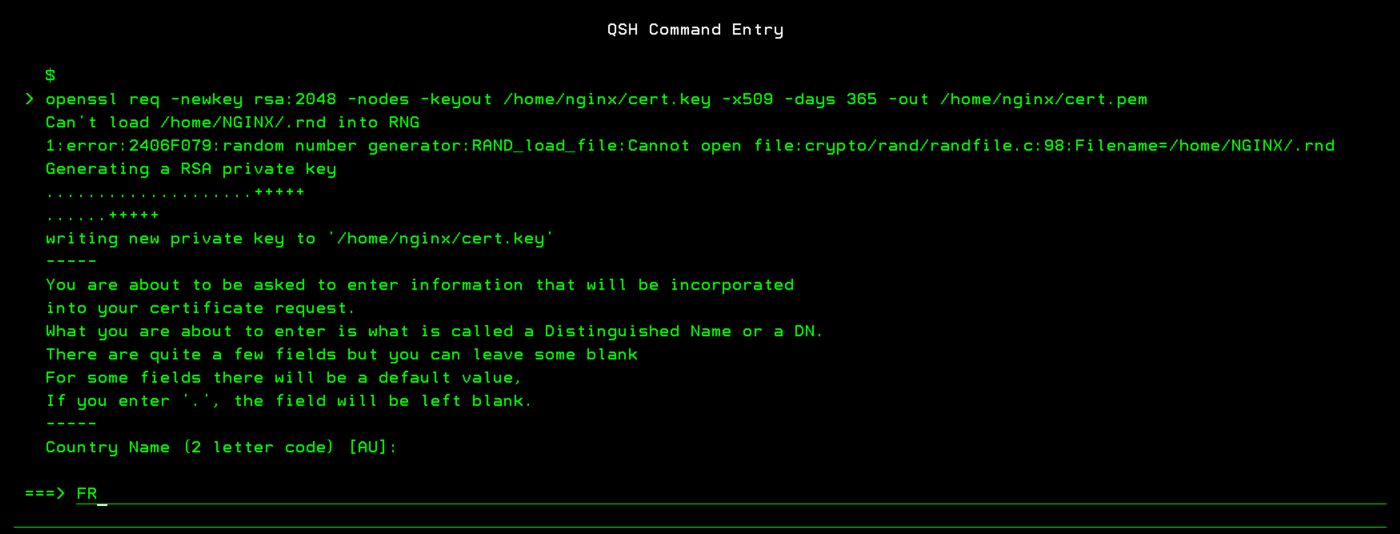
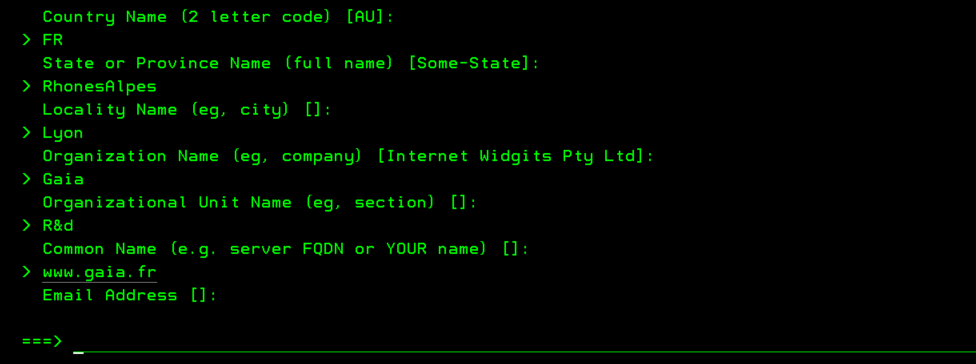
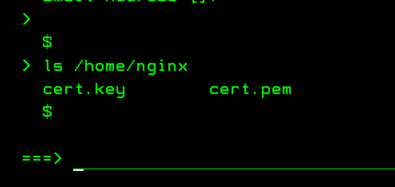
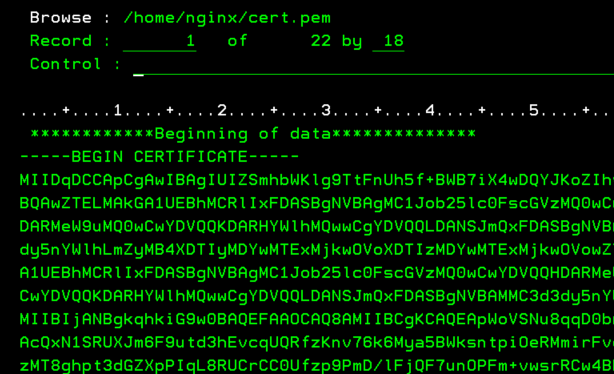
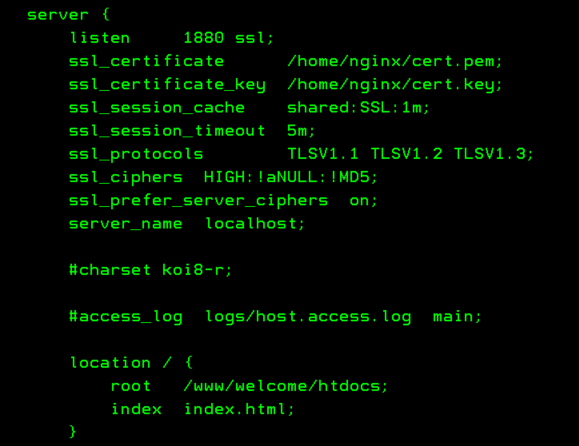
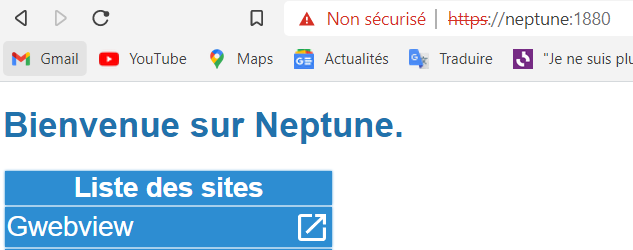
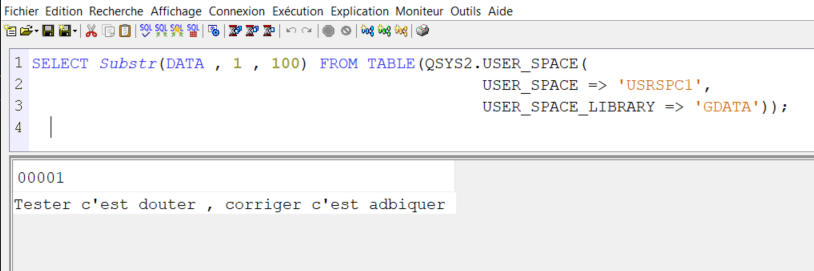
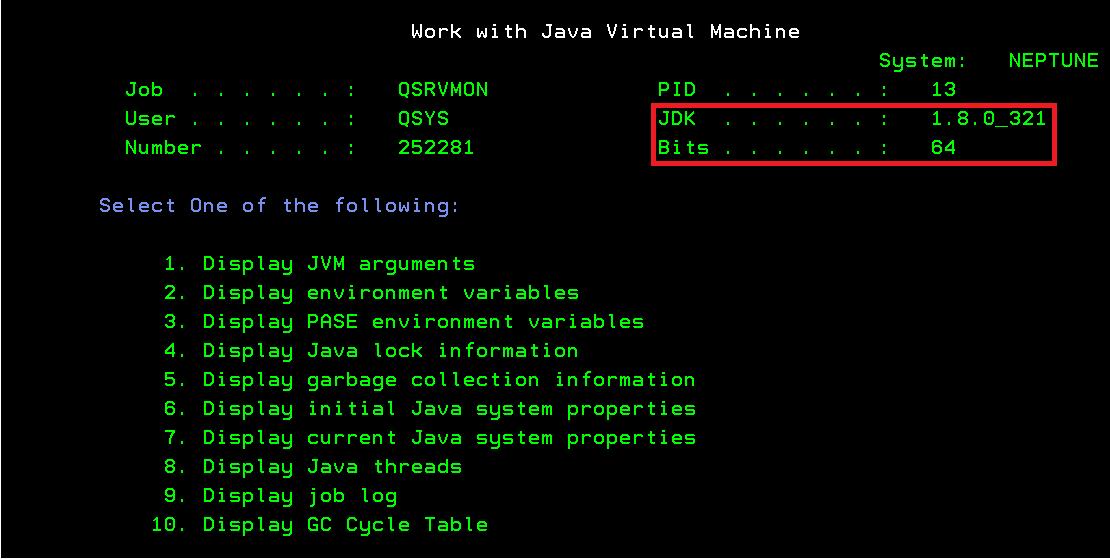
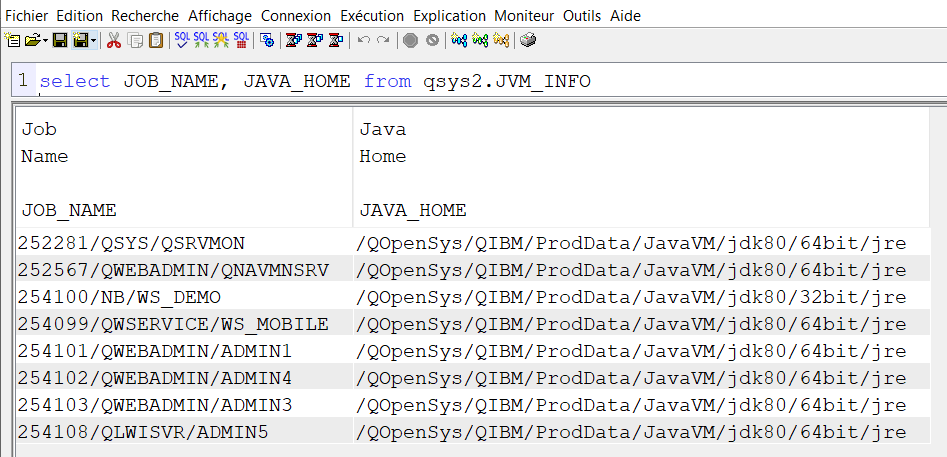
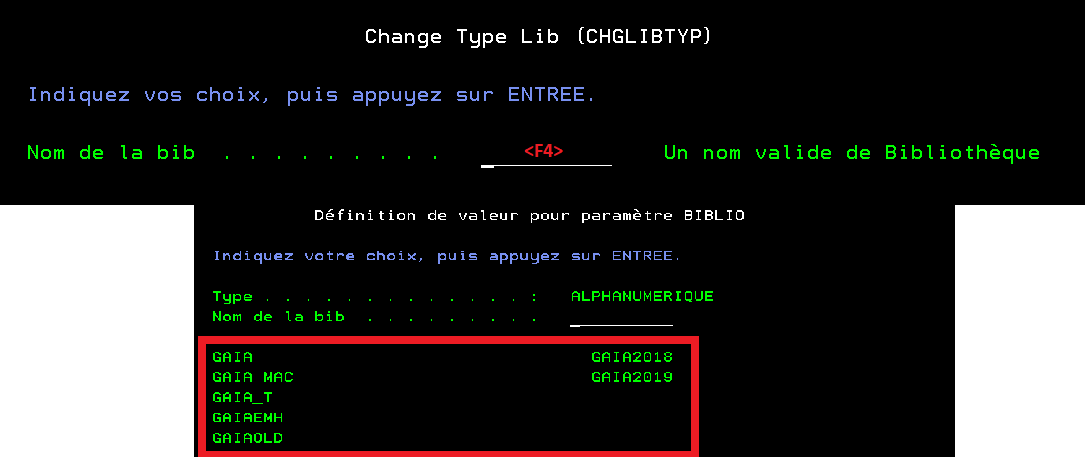
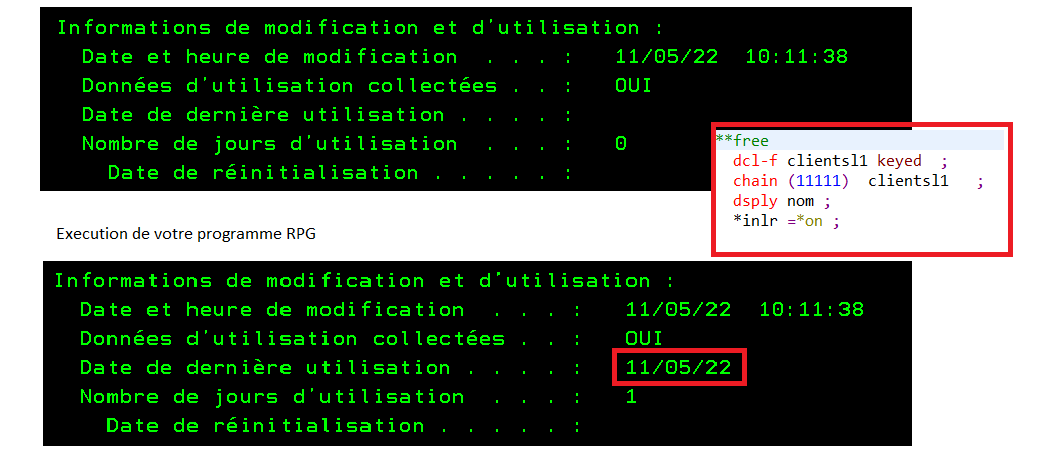
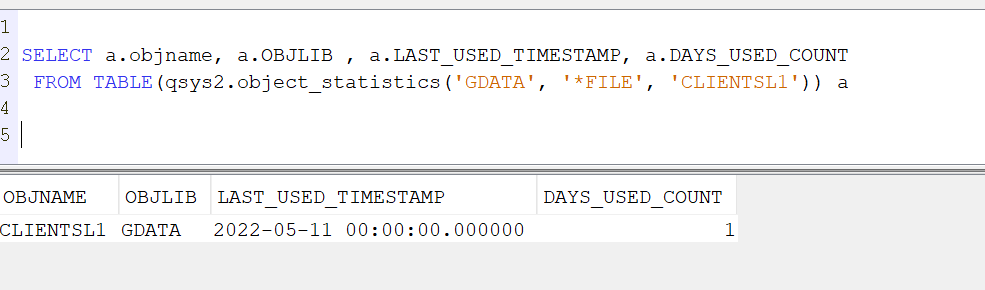
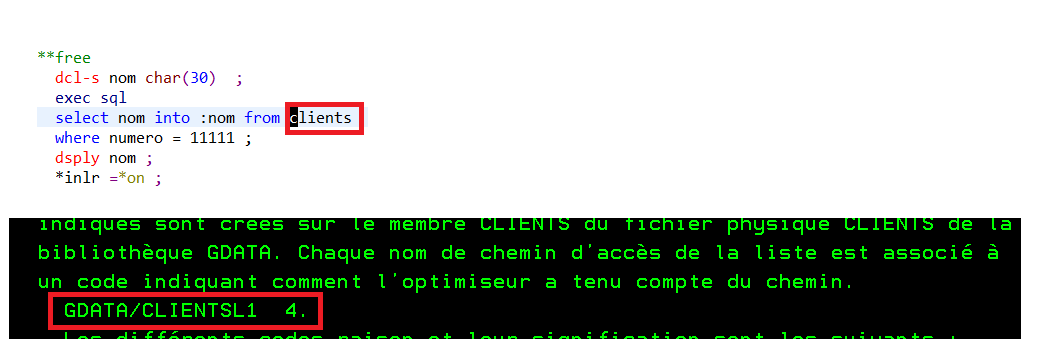
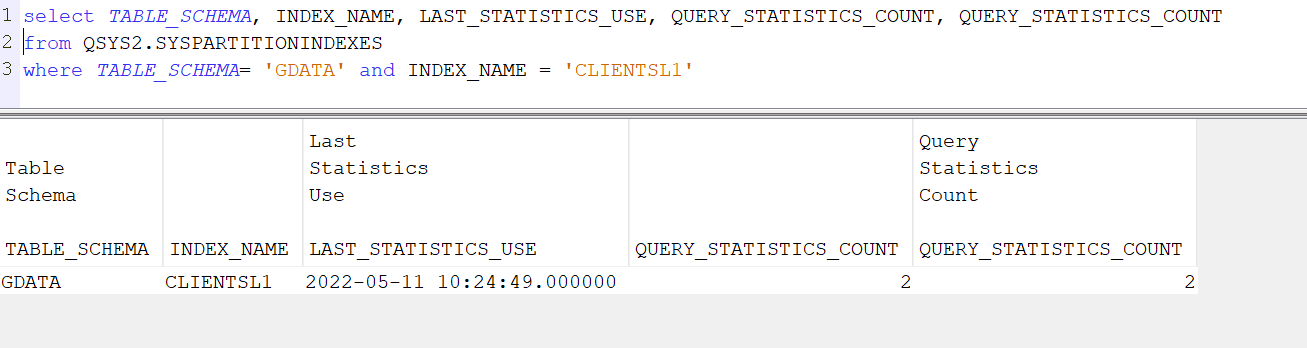
Vous voulez faire du 5250 sur votre IBMi et que vos informations ne circulent pas en claire sur le réseau.
La première solution est de mettre en œuvre telnets
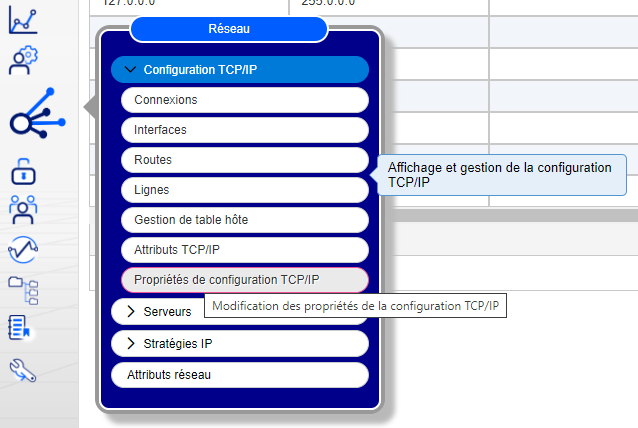
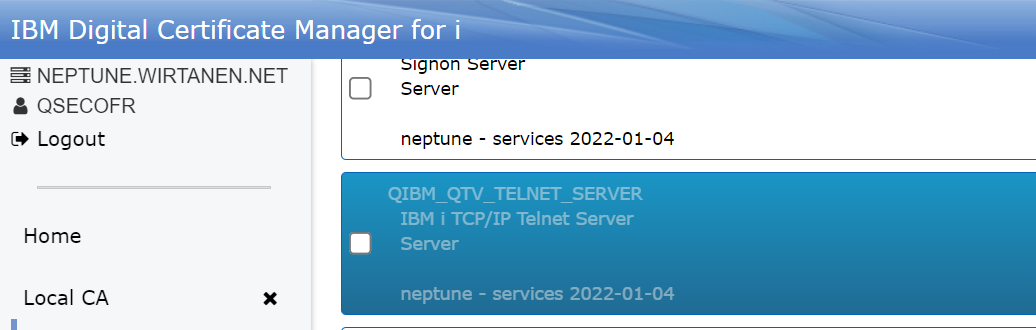
Vous devez vous connecter sur DCM
Créer un certificat ou utiliser un déjà existant
et l’associer à l’application
.
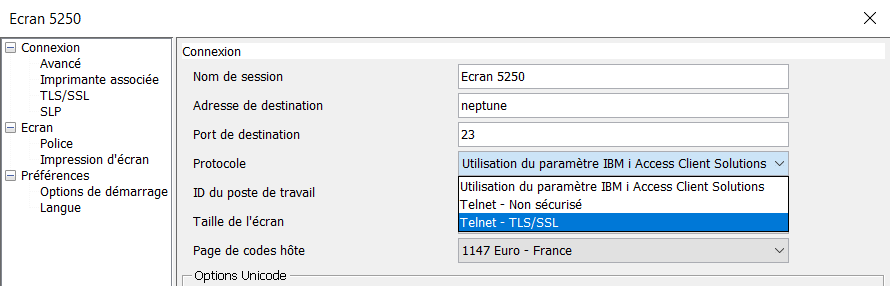
Ensuite dans votre client, en principe ACS , indiquer que vous vous connectez en sécurisé .
.
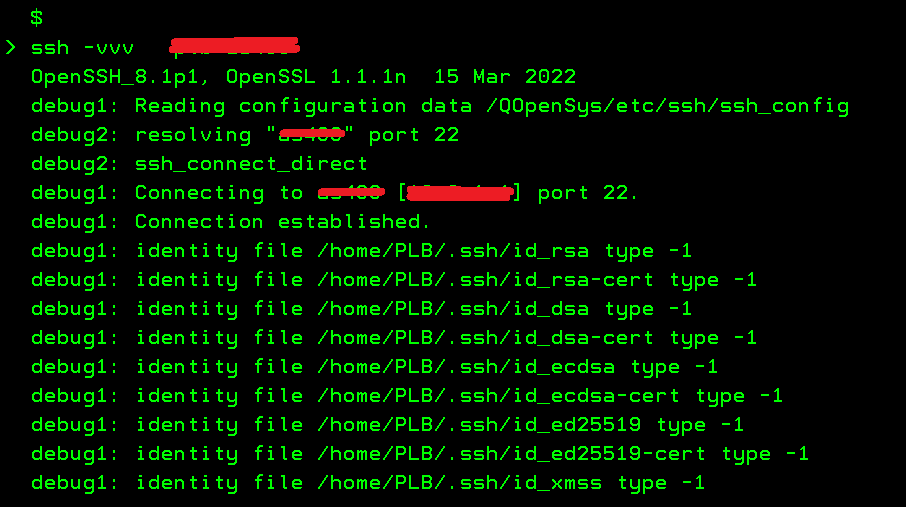
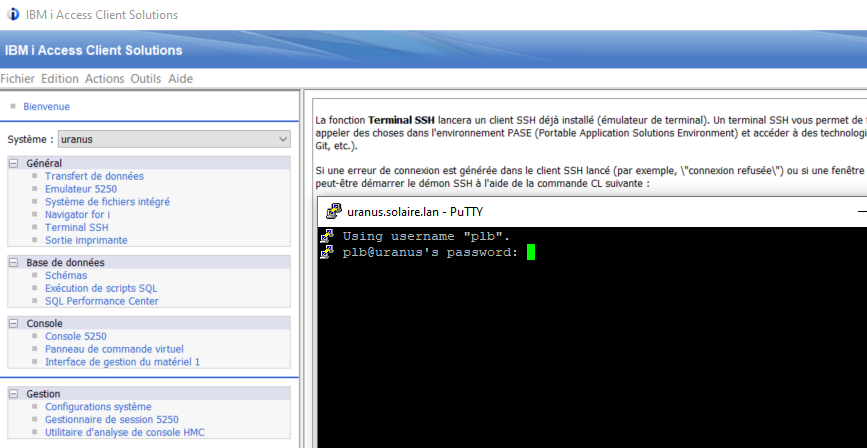
La deuxième est de passer par SSH
vous avez un client 5250 (TN5250) installable dans les packages OPEN SOURCES
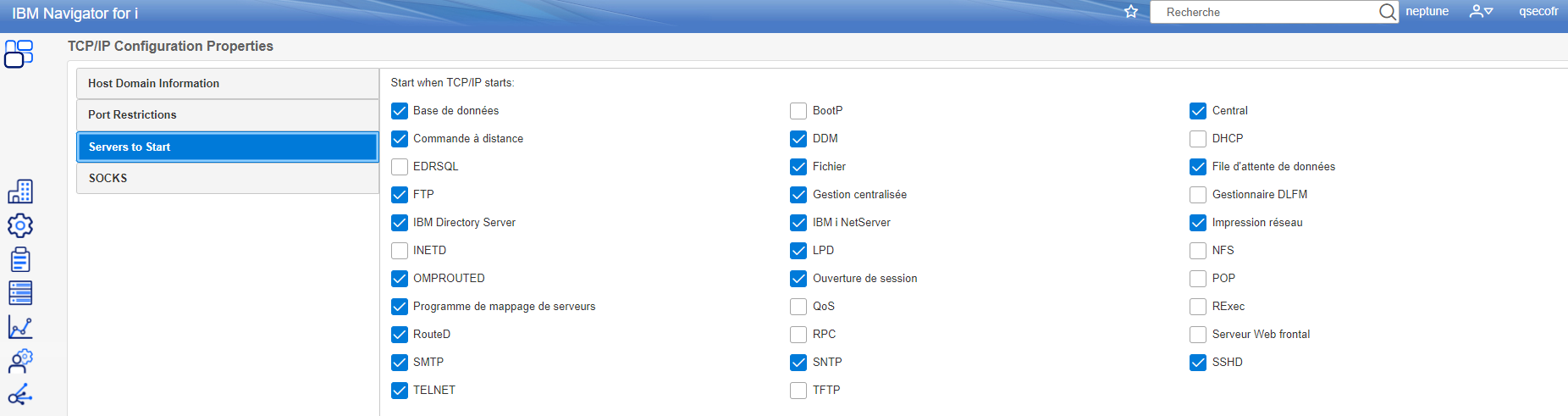
vous n’avaez rien à faire coté serveur tout va se passer sur le service ssh qui doit être démarré
d’abord vous devez vous connecter par une client SSH , putty ou celui ACS mais en principe si vous faites ca …
.
Une fois connecté il vous suffira de lancer le client 5250 par la commande tn520
par exemple
==>tn5250 env.TERM=IBM-3179-2 ssl:neptune
.
.
Conclusion :
Ce n’est pas parfait mais vous n’avez pas besoin d’installer un client sur votre poste et en principe pas d’intervention à faire coté serveur ibmi