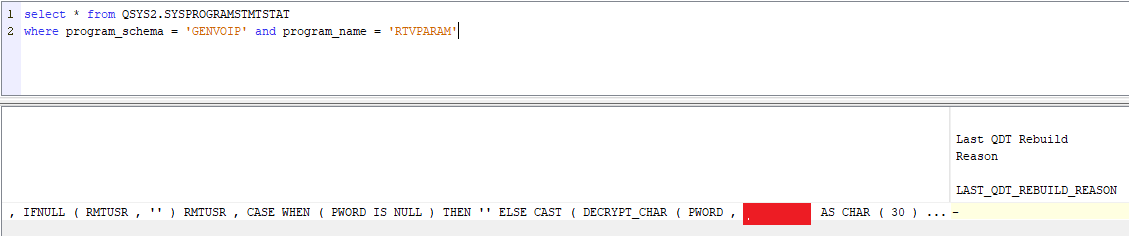
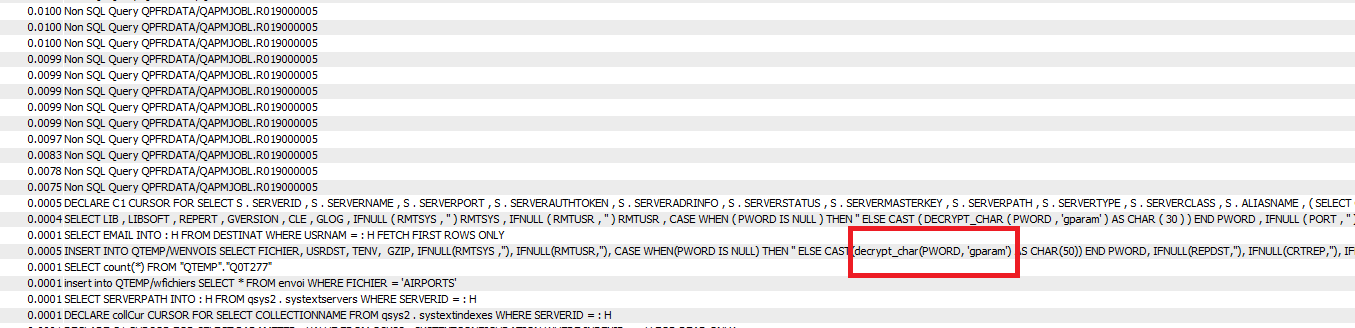
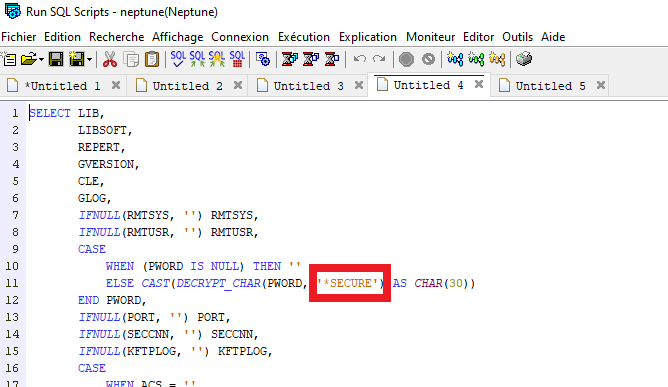
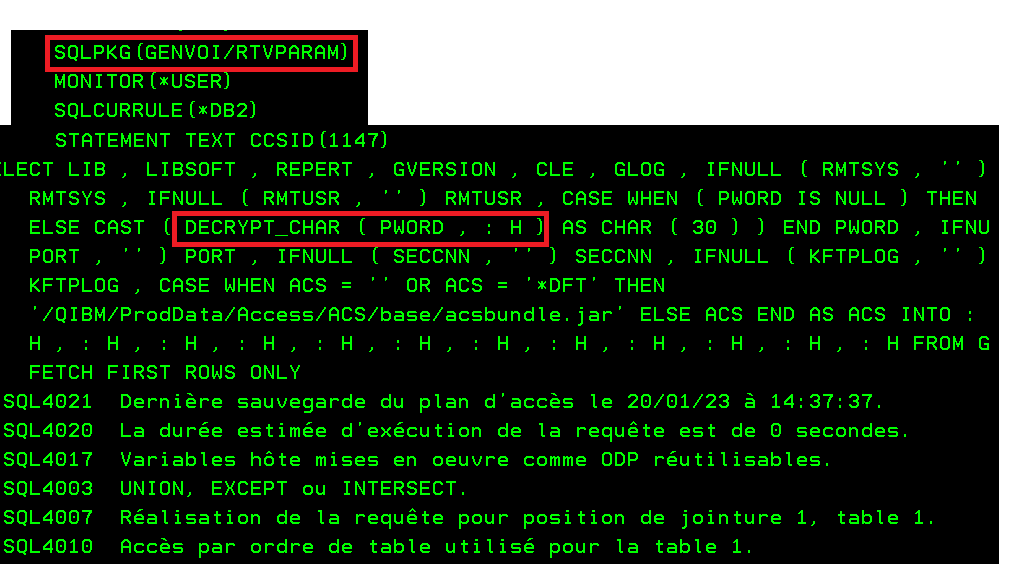
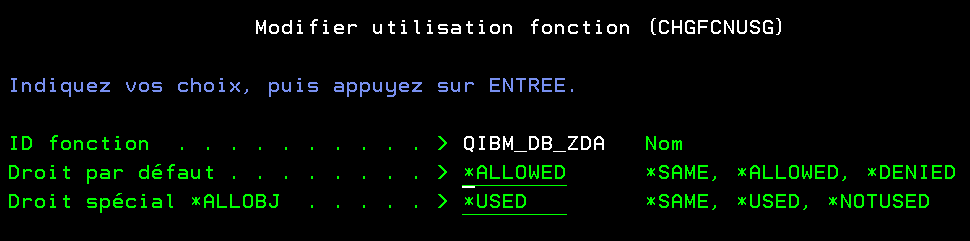
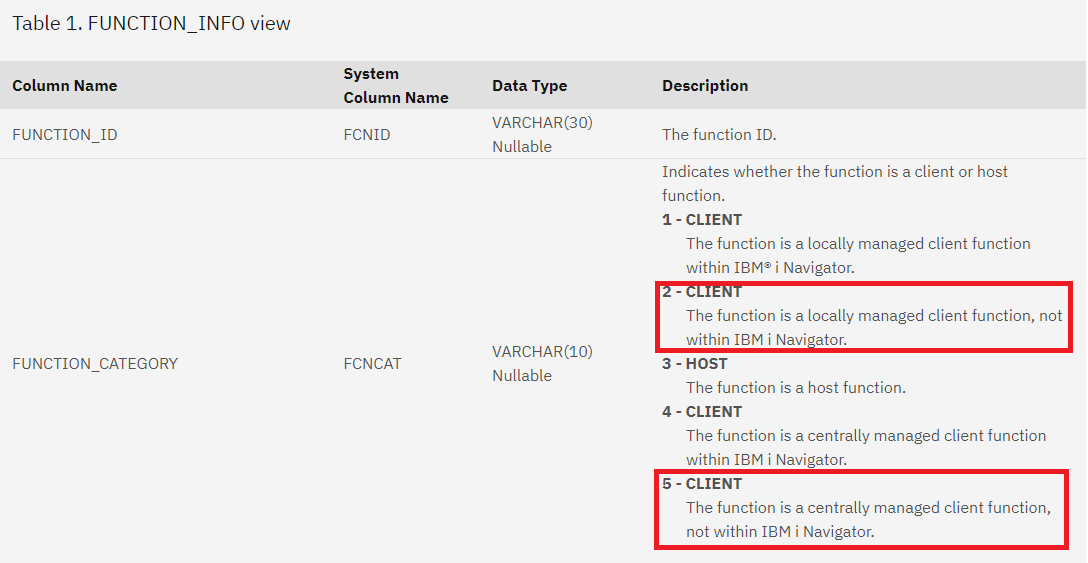
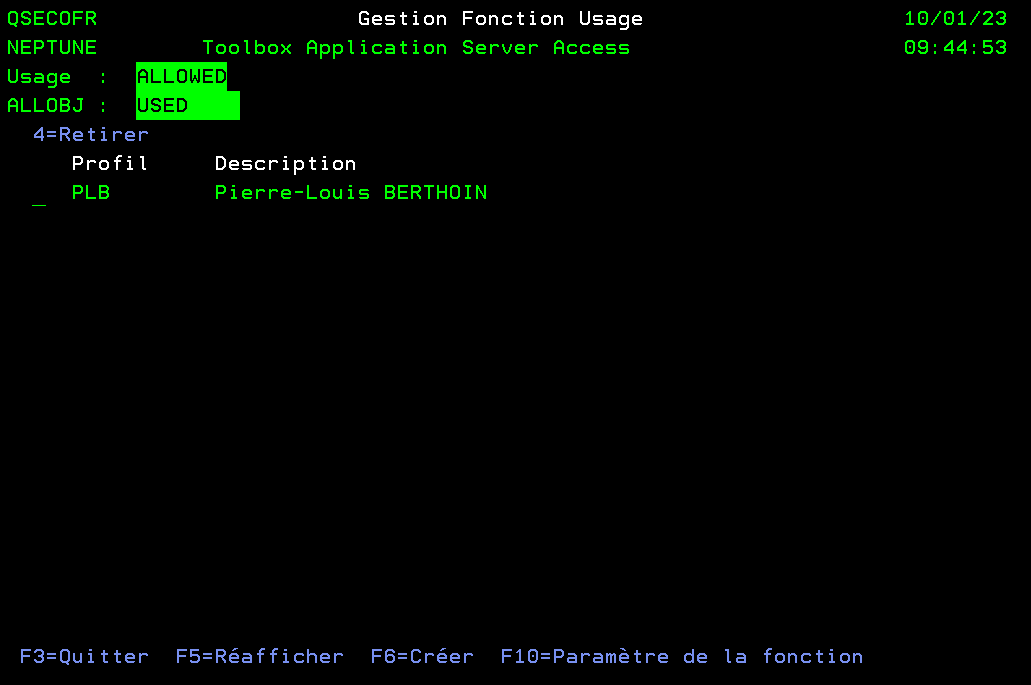
Nous utilisons de plus en plus de certificats pour crypter nos communications. Leur gestion via DCM sur l’IBM i devient donc de plus en plus nécessaire et « subtile ».
Les outils standards
Interface web de DCM (Digital Certificate Manager)
Accès par http://partition:2001/dcm
Beaucoup plus pratique et réactive depuis sa réécriture, elle comprend l’ensemble des fonctions (presque en réalité) : création des autorités, création des certificats, gestion des applications (au sens DCM), affectation, renouvellement, importation et exportation :
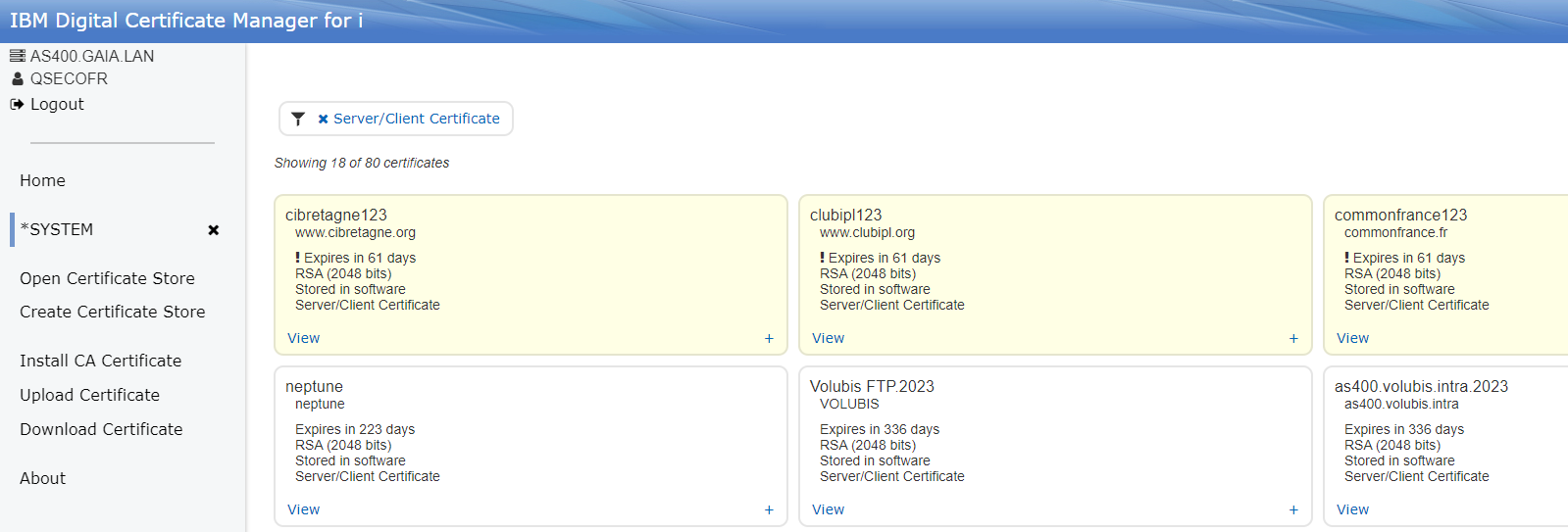
C’est propre, pratique.
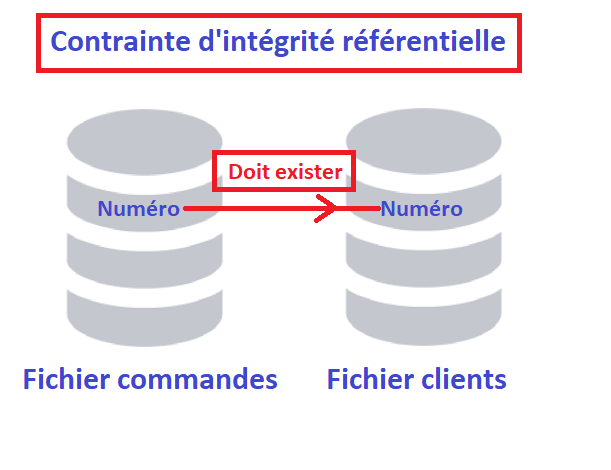
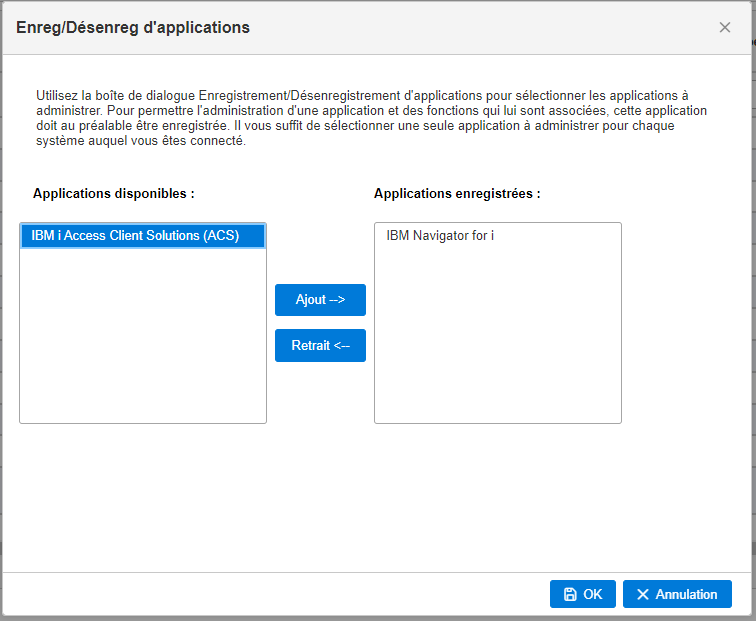
Pour rappel, le principe : DCM permet de gérer les certificats (stocker, renouveler etc …), mais également de les affecter à une ou plusieurs applications IBM i. La notion d’application dans DCM est proche d’une notion de service : serveur telnet, serveur http, serveur ou client FTP et bien d’autres.
Ainsi un certificat peut être assigné à aucune, une ou plusieurs applications :
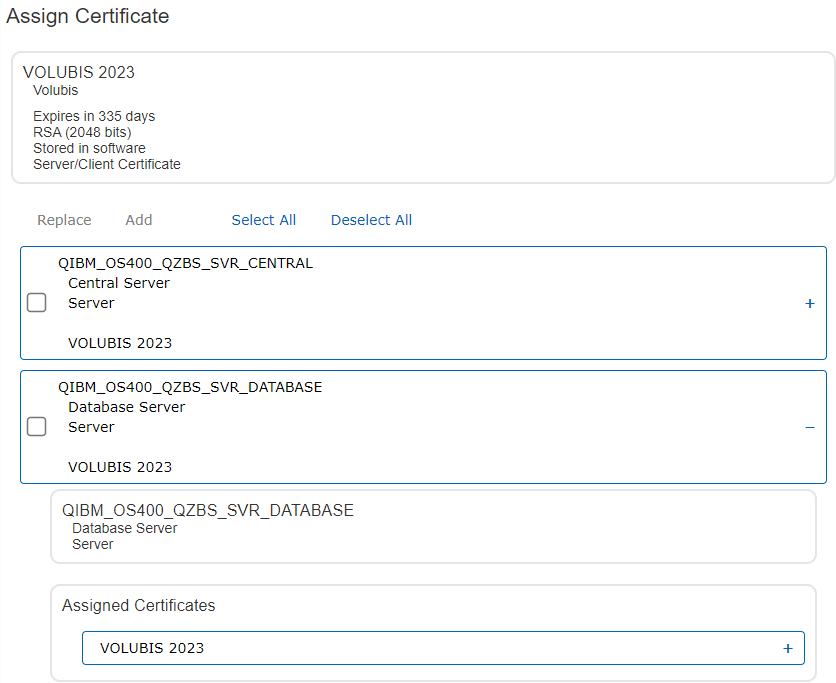
Et chaque application dispose de ses propres attributs, permettant par exemple de choisir les niveaux de protocoles :
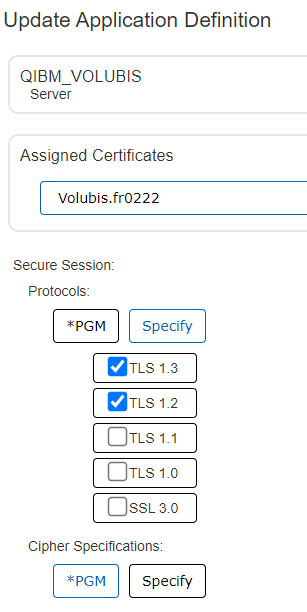
A priori, on a pas de raison d’aller modifier ces attributs très souvent, l’interface web est parfaite pour ces actions
Services SQL
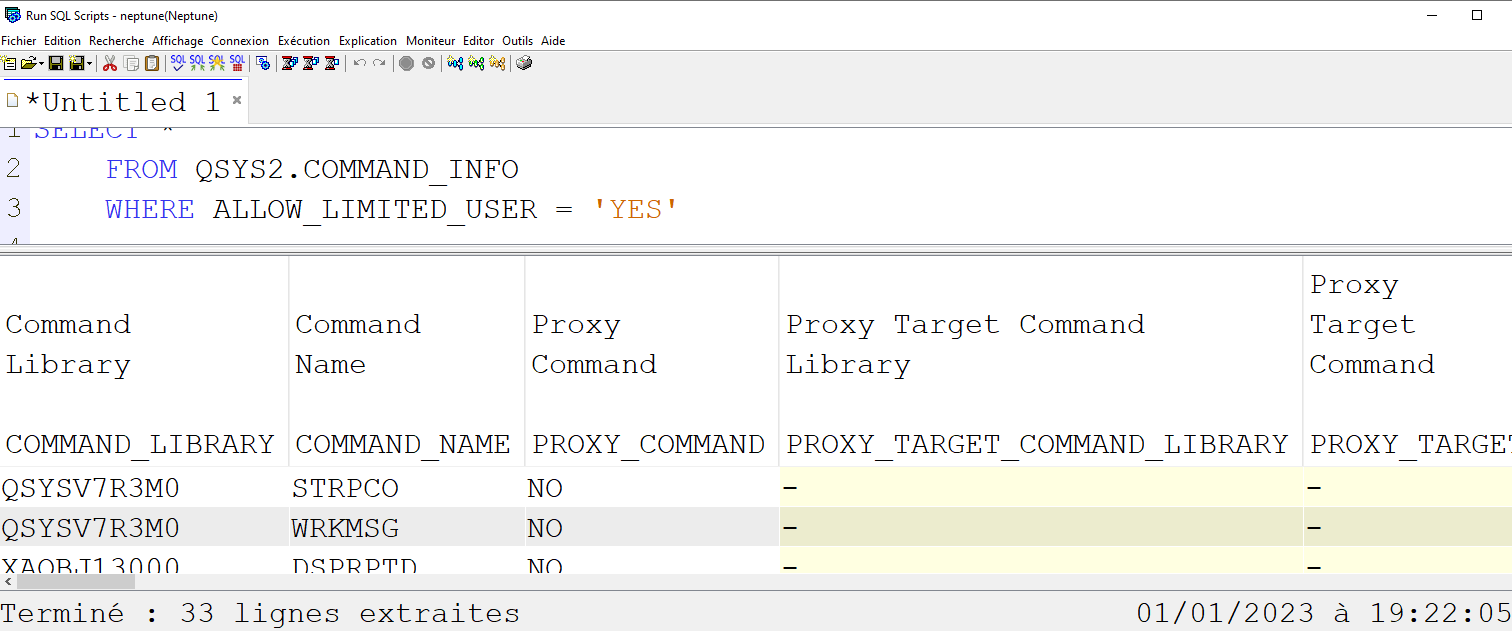
Pour plus de facilité, et de capacité d’automatisation, IBM délivre une fonction table (UTDF) : qsys2.certificate_info
Documentation : https://www.ibm.com/docs/en/i/7.5?topic=services-certificate-info-table-function
Disponible avec IBM i 7.5, 7.4 avec SF99704 niveau 13 et 7.3 avec SF99703 niveau 24
Exemple (IBM) :
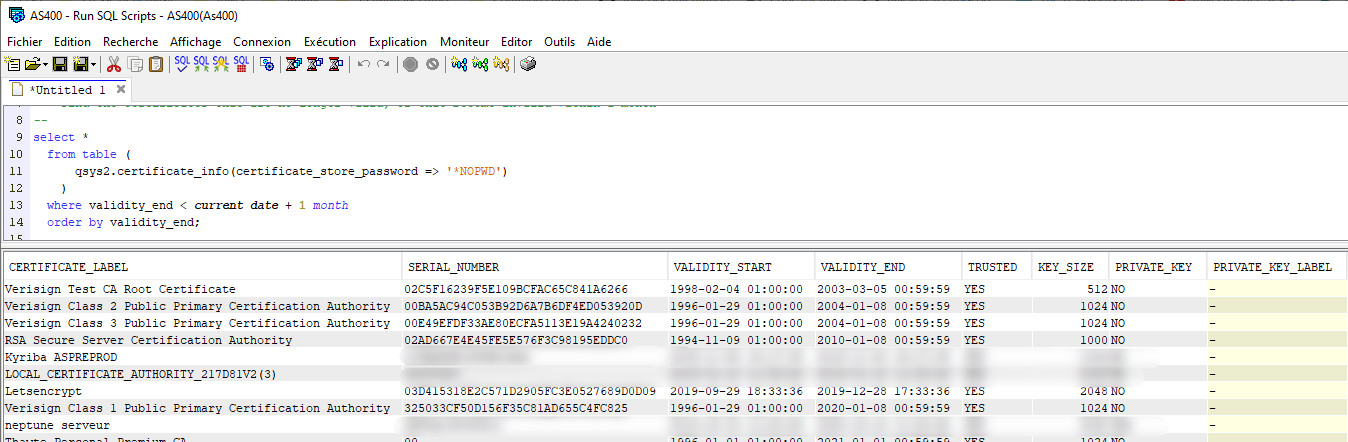
Très utile pour obtenir directement toutes les informations, les dates de péremption etc …
Si vous êtes dans des niveaux incompatibles (ce ne devrait plus être le cas), nous avions fait pour vous une commande équivalente basée sur les APIs : https://github.com/FrenchIBMi/Outils/tree/master/API%20securite

DCM-tools
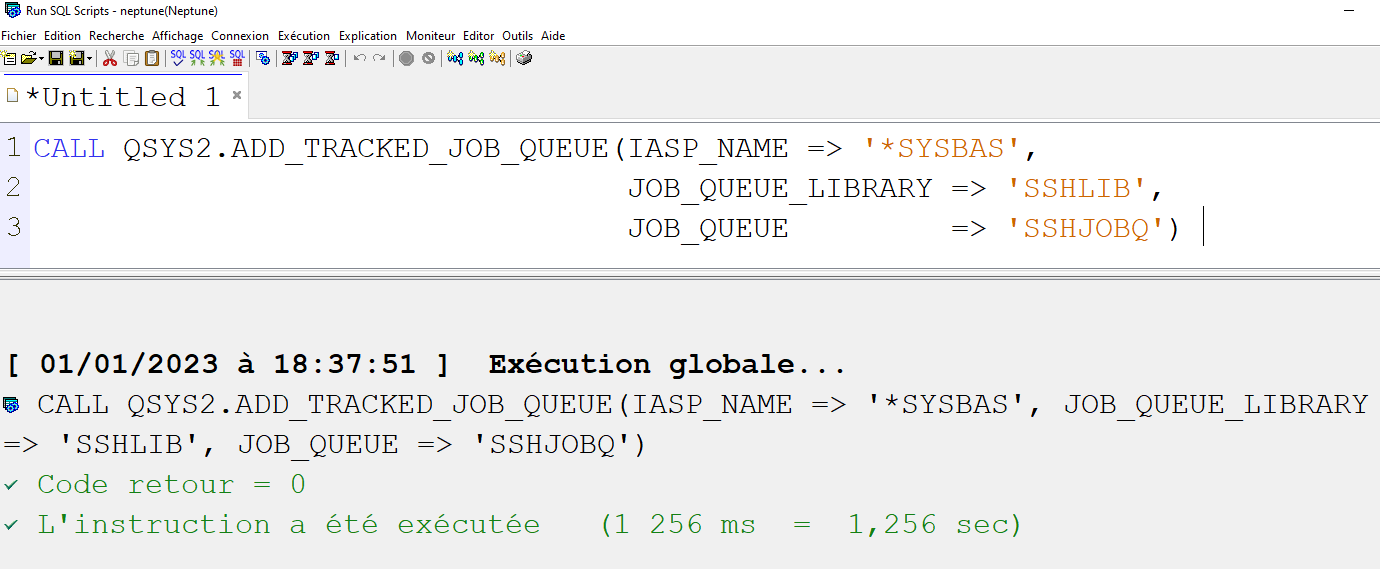
Grâce à Jesse Gorzinski (M. Open Source chez IBM), vous disposez également de commandes shell pour effectuer les principales actions de DCM : création, affectation de certificats, liste …
Voir le produit et l’installation ici : https://github.com/ThePrez/DCM-tools
Il faut absolument l’installer, cela vous permet d’automatiser de nombreuses actions courantes.
Exemple :
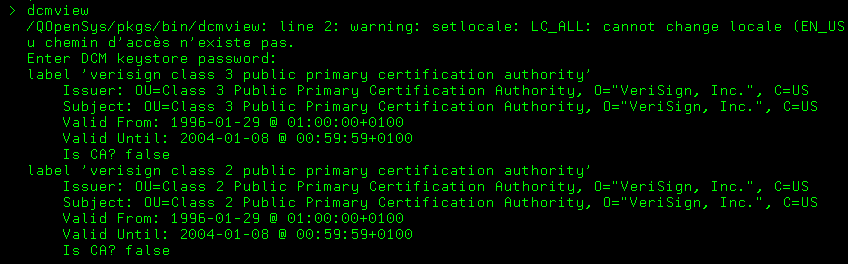
Les applications ?
« Houston, nous avons un problème ! ». Pas si grave non plus …
Il est facile de déterminer quels sont les certificats expirés ou qui vont expirer. Donc ceux à renouveler (création par DM ou importation). Par contre, seul l’interface web de DCM permet de voir les applications assignées, et donc les impacts de la péremption du certificat !
La connaissance des applications est primordiale : certaines nécessitent un arrêt/redémarrage du service (donc une interruption pour les utilisateurs), d’autres non.
Si aucune application n’est liée, on ne va peut être rien faire. Sinon, on va anticiper (sisi).
DCM permet de voir les applications, mais il vous faut aller sur le certificat et voir le détail par l’interface graphique. Donc humainement sur chacune de vos partitions.
API -> fonction table (UDTF)
Cette information est accessible par les APIs de DCM.
Pour plus de faciliter, nous vous proposons une fonction table SQL : listedcmapplication
Disponible en open source ici : https://github.com/FrenchIBMi/Outils/tree/master/dcm
L’objectif est de lister les applications ET les certificats associés :
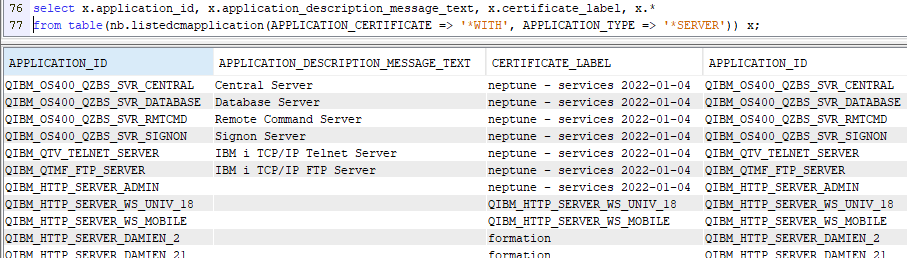
Les deux paramètres permettent de sélectionner les applications avec ou sans certificat, les applications serveur ou client.
Vous pouvez également facilement utiliser les informations conjointes de qsys2.certificate_info. Par exemple, quels certificats vont expirer dans le mois et quelles sont les applications impactées :
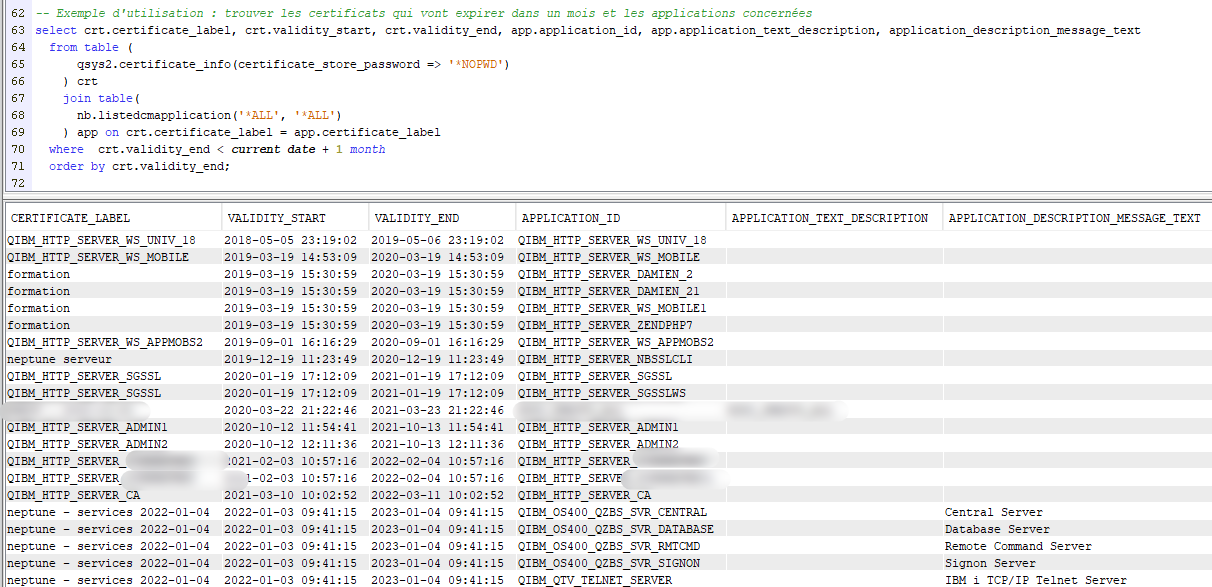
Le code est open source, il est perfectible, n’hésitez pas à participer !
Quelques idées : agrégation des informations de différentes partitions, service correspondant actif ou non …