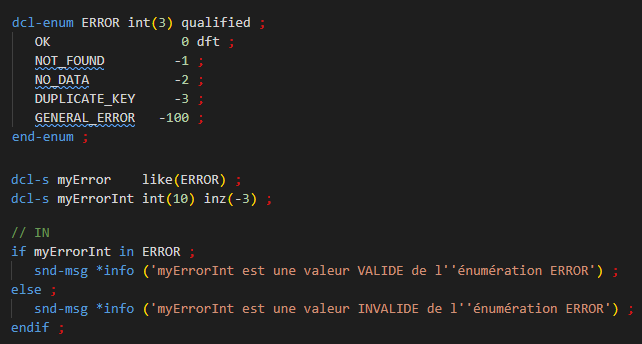
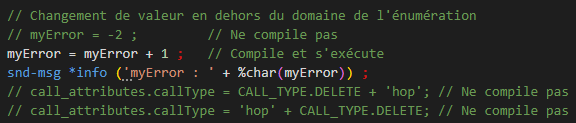
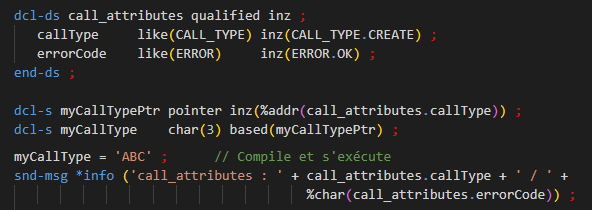
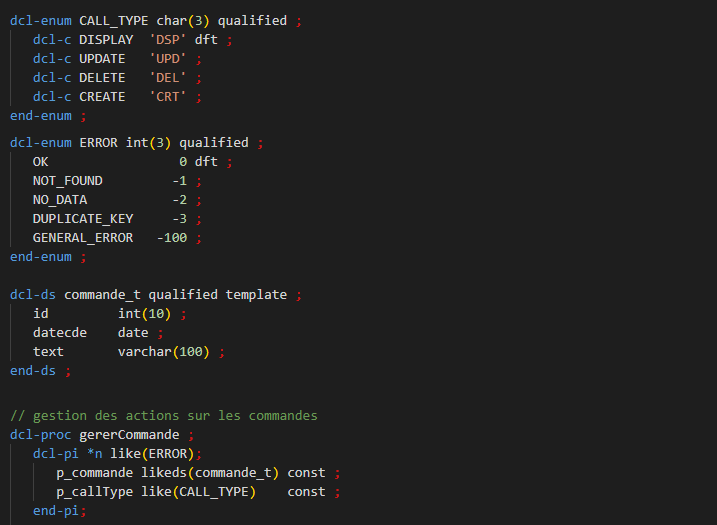
Sur IBM i, les groups d’activation sont au cœur de l’architecture ILE. Ils permettent de mutualiser efficacement les ressources tout en offrant un cadre d’exécution structuré et performant.
Dans la majorité des cas, le mécanisme de nettoyage automatique fourni par le système suffit largement. Mais dès que l’on travaille avec des service programs persistants, des ressources externes ou des APIs dont le cycle de vie dépasse un simple appel de programme, il devient nécessaire de reprendre la main.
C’est précisément là qu’intervient l’API CEE4RAGE.
CEE4RAGE signifie Register Activation Group Exit Procedure.
Son rôle est très simple mais fondamental : elle permet d’enregistrer une procédure qui sera appelée automatiquement lorsque l’activation group est détruit. Cette procédure est exécutée après les exit procedures des langages de haut niveau, mais avant le nettoyage final effectué par le système. On peut la voir comme un équivalent conceptuel d’un destructeur dans les langages orientés objet.
En effet, certains « nettoyages » ne peuvent pas, ou ne doivent pas, être laissés au seul mécanisme système. Certains composants nécessitent une fermeture explicite : mémoire allouée dynamiquement, connexions réseau persistantes, APIs externes, sockets, workers auxiliaires ou encore structures partagées. CEE4RAGE garantit que votre code de nettoyage sera exécuté quelle que soit la manière dont l’activation group se termine : retour normal, reclaim, exception ou même ENDJOB.
Le besoin dépend clairement du code ILE produit.
Usage
Un cas d’usage très courant concerne les service programs persistants. Lorsqu’un service program est chargé dans un activation group nommé ou avec *ACTGRP(CALLER), il peut rester actif longtemps, parfois pendant toute la durée de vie d’un job interactif. Dans ce contexte, il est essentiel de disposer d’un point fiable pour libérer proprement les ressources lorsque l’activation group disparaît enfin. CEE4RAGE fournit exactement ce point d’ancrage.
Une approche éprouvée consiste à mettre en place un pattern « constructeur / destructeur ». L’idée est simple : initialiser les ressources lors du premier appel effectif au service program, puis enregistrer une exit procedure via CEE4RAGE pour garantir le nettoyage automatique à la fin de l’activation group.
Exemple
Voyons maintenant un exemple concret en RPGLE free format, typique d’un service program.
Le service program est défini sans programme principal, hors DFTACTGRP, et dans un activation group persistant :
**free
ctl-opt nomain
dftactgrp(*no)
actgrp('MYACTGRP');On commence par définir quelques variables globales servant à contrôler l’état d’initialisation et à représenter une ressource persistante :
dcl-s Initialized ind inz(*off);
dcl-s ResourceHandle int(10);Ensuite, on déclare le prototype de l’API CEE4RAGE :
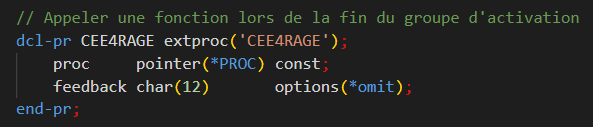
dcl-pr CEE4RAGE extproc('CEE4RAGE');
procedure pointer(*proc) const;
feedback char(12) options(*omit);
end-pr;Le cœur du pattern repose sur une procédure d’initialisation, appelée systématiquement par les procédures métier exportées, mais dont le contenu réel ne s’exécute qu’une seule fois :
dcl-proc InzSrvPgm;
if Initialized;
return;
endif;
// Initialisation des ressources (exemple simulé)
ResourceHandle = 12345;
// Enregistrement de l'activation group exit procedure
CEE4RAGE(%paddr(EndSrvPgm): *omit);
Initialized = *on;
end-proc;Cette procédure effectue trois choses essentielles :
- elle initialise les ressources
- enregistre l’exit procedure
- mémorise le fait que l’initialisation est désormais réalisée
La procédure de terminaison, elle, sera appelée automatiquement par le système lorsque l’activation group prendra fin. Elle doit impérativement être exportée et respecter la signature attendue par l’ILE :
dcl-proc EndSrvPgm export;
dcl-pi *n;
agMark uns(10) const;
reason uns(10) const;
result uns(10) ;
userRC uns(10) ;
end-pi;
if Initialized;
// Nettoyage explicite des ressources
// fermeture de fichiers
// libération mémoire
// arrêt d’APIs persistantes
ResourceHandle = 0;
Initialized = *off;
endif;
end-proc;Enfin, toutes les procédures métier exportées commencent par appeler la procédure d’initialisation. Cela garantit que l’environnement est prêt avant toute logique fonctionnelle :
dcl-proc DoSomething export;
dcl-pi *n;
value int(10);
end-pi;
InzSrvPgm();
return ;
end-proc;Paramètres de la procédure d’exit
Une procédure d’exit d’activation group repose sur une interface composée de quatre paramètres standards, transmis automatiquement par le runtime lors de la terminaison de l’activation group :
- agMark, correspond au marqueur interne de l’activation group. Il s’agit d’un identifiant numérique unique dans le job, principalement utile à des fins diagnostiques ou pour des scénarios avancés impliquant plusieurs activation groups simultanés. Dans la majorité des cas, ce paramètre est simplement ignoré, mais il permet théoriquement de corréler une terminaison précise à un contexte donné.
- reason, indique la raison de la fin de l’activation group : retour normal, reclaim, fin de job, exception non interceptée, etc. Ce code est particulièrement précieux pour adapter le comportement du cleanup, par exemple en évitant certaines opérations coûteuses lors d’une fin brutale.
- result et userRC, sont des champs en entrée/sortie permettant respectivement au système et au programme de communiquer un code de résultat et une information spécifique utilisateur. En pratique, ils sont rarement exploités, mais ils offrent un mécanisme de retour standardisé permettant à une exit procedure de signaler son état ou d’influencer légèrement le déroulement du traitement global. L’ensemble de ces paramètres est optionnel côté RPG, ce qui explique l’usage fréquent de options(*nopass) ; toutefois, leur présence formalise le contrat entre le runtime ILE et la procédure d’exit, et rappelle que cette dernière s’exécute dans un contexte très particulier, où la logique doit être minimale, robuste et parfaitement maîtrisée.
Multiples procédures
Dans certains cas plus avancés, il peut être tout à fait légitime d’enregistrer plusieurs procédures d’exit pour un même activation group.
CEE4RAGE ne limite ni le nombre de procédures enregistrées, ni leur nature : chaque appel ajoute une entrée dans la pile des exit procedures, qui seront exécutées dans l’ordre inverse de leur enregistrement lors de la fin de l’activation group.
Cette capacité est particulièrement utile lorsque plusieurs composants indépendants partagent le même activation group : chaque service program peut alors enregistrer sa propre procédure de nettoyage, sans dépendre d’un point centralisé.
Il est cependant essentiel de concevoir ces exit procedures comme autonomes, simples et robustes, car une défaillance dans l’une d’elles empêche l’exécution des suivantes. Dans ce contexte, l’ordre d’enregistrement devient un véritable élément d’architecture : on veillera par exemple à enregistrer en dernier les procédures critiques, ou à utiliser une procédure « chef d’orchestre » qui appelle explicitement plusieurs routines de cleanup internes.
L’utilisation de procédures d’exit multiples est donc un mécanisme puissant, mais qui impose une discipline stricte : absence d’effets de bord, opérations idempotentes, et compréhension claire du cycle de vie global de l’activation group.
Conclusion
Ce pattern est robuste, simple et parfaitement aligné avec les mécanismes de l’ILE.
Il fonctionne aussi bien en batch qu’en interactif, résiste aux fins de job brutales et assure un comportement prévisible dans les architectures persistantes. Il est particulièrement adapté aux environnements modernisés où des composants RPG sont exposés comme briques partagées, parfois appelées par des couches Java, C ou web.
Il convient toutefois de garder quelques points en tête. CEE4RAGE n’est jamais appelée tant que l’activation group reste actif ; si celui-ci est volontairement maintenu pendant toute la durée du job, le nettoyage n’aura lieu qu’à la toute fin. De plus, si une exit procedure échoue, les suivantes ne seront pas exécutées. Il est donc essentiel d’y écrire un code simple, robuste et sans dépendances fragiles.
En conclusion, CEE4RAGE est une API discrète mais fondamentale. Elle ne sert pas à gérer des erreurs ni à intercepter des messages système ; elle sert à maîtriser la fin de vie d’un activation group.
Dès que l’on conçoit des service programs persistants et que l’on vise une architecture propre et professionnelle sur IBM i, CEE4RAGE devrait faire partie des outils de base de tout concepteur ILE.
Nous continuerons dans les prochains articles avec les APIs liées à l’ILE : https://www.ibm.com/docs/en/i/7.6.0?topic=ssw_ibm_i_76/apis/ile2a1TOC.html
Références :