Rappel
Les pools partagés sont des espaces mémoire dans lequel les sous-systèmes place des travaux.
*MACHINE Utilisé par les fonctions internes du pool machine
liste des pools
*BASE Pool système par défaut
*INTERACT Travail interactif
*SPOOL Impression
*SHRPOOL1 à *SHRPOOL60 pools spécifiques
et sur ces pools il y a 2 valeurs importantes à ajuster, la taille et le niveau d’activité.
Ajustement
Il existe une valeur système pour ajuster automatiquement ces pools
La valeur système QPFRADJ à 2 ou à 3 permet de mettre en place cet ajustement automatique la différence étant un ajustement à l’IPL avec la valeur 2.
Ce mécanisme fonctionne très bien …
l’ajustement par défaut est fait toutes les 60 secondes ce qui la plupart temps convient bien.
Si vous voulez ajuster ce temps vous pouvez créer une dtaara :
CRTDTAARA DTAARA(QUSRSYS/QPFRADJWT) TYPE(*DEC) LEN(3 0) VALUE(60) vous pouvez indiquer une valeur en seconde de 20 à 120.
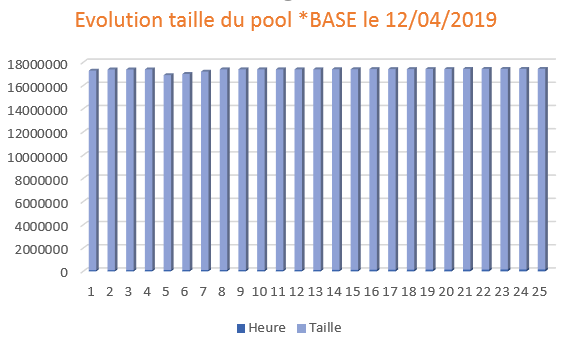
Mais on a aucune visibilité sur l’ajustement sur une période données, exemple mon pool de base une journée.
Voici comment on peut faire :
Il faut créer un récepteur de journal, il peut être dans une bibliothèque privée, et vous pouvez choisir son nom
CRTJRNRCV JRNRCV(QUSRSYS/QPFRADJ)
Il faut créer le journal QPFRADJ qui pointe sur votre récepteur
CRTJRN JRN(QSYS/QPFRADJ) JRNRCV(QUSRSYS/QPFRADJ)
Il vous faut un fichier pour faire votre analyse, le fichier qui contient la structure est QAWCTPJE
CRTDUPOBJ OBJ(QAWCTPJE) FROMLIB(QSYS) OBJTYPE(FILE) TOLIB(votrebib) NEWOBJ(QPFRADJ) récupérer les informations du journal DSPJRN JRN(QSYS/QPFRADJ) ENTTYP(TP) OUTPUT(OUTFILE) OUTFILE(votrebib/votrefic)
Créer un fichier à exporter.
create table qtemp/analyse as(
SELECT TPTIME as heure , TPCSIZ as taille
FROM votrebib/votrefic WHERE
TPPNAM = ‘*BASE ‘ and tpdate = ‘070320’
) with data
dans notre cas le pool de base, le 7 mars 2020
vous devez ensuite exporter ce fichier pour faire un diagramme, par exemple sous excel .
Remarque :
Il ne faut pas utiliser des pools privés qui ne seront pas ajustés.
Vous devez faire le ménage sur les récepteurs de journaux que vous créez.
Et règle fondamentale, si on fait de l’ajustement, on fait une mesure avant et une mesure après sur des périodes significatives !