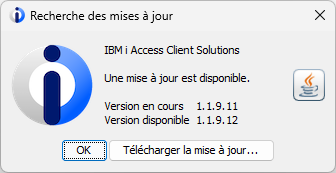
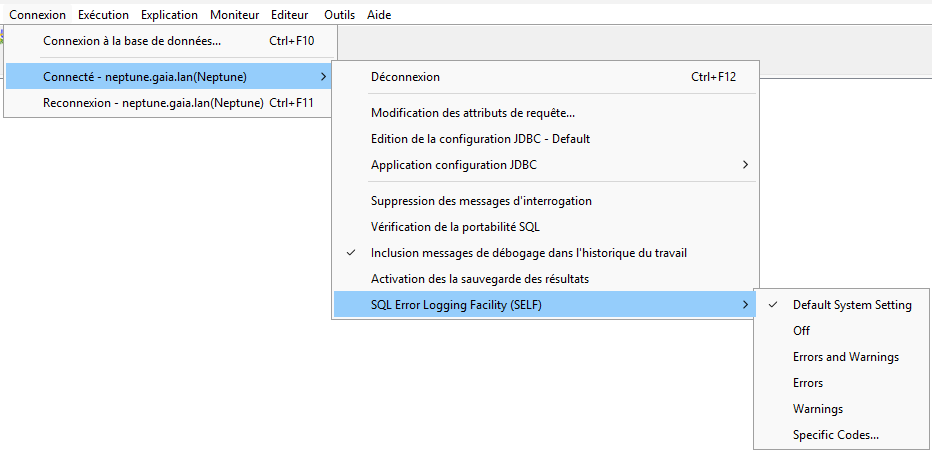
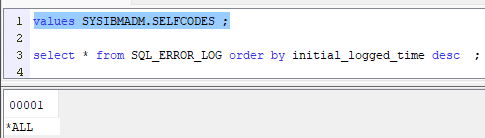
Concrètement, cela modifie la liste des erreurs qui sont tracées dans la vue SQL_ERROR_LOG. Cette liste est stockée dans la variable globale SYSIBMADM.SELFCODES, avec quelques valeurs spéciales (*ALL, *ERROR, *WARN, *NONE).
Fichiers physiques source
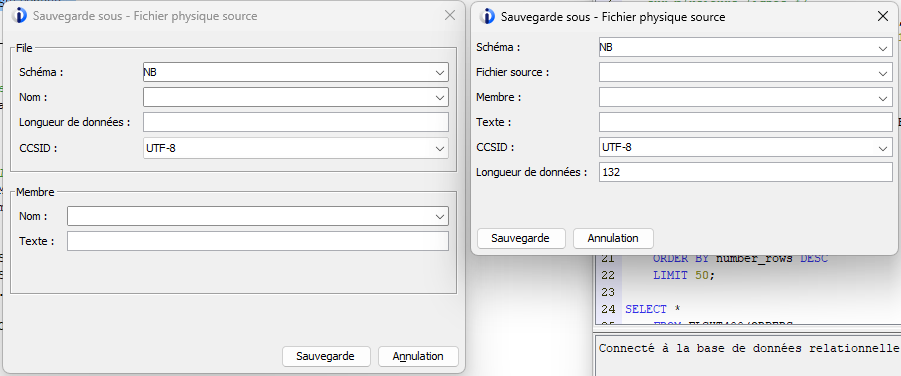
Amélioration de la fenêtre de dialogue pour la sauvegarde en fichiers sources :
Gestion des fins de ligne
Les caractères LF (x’25’) ne sont plus insérés en fin de ligne dans le cas d’une sauvegarde en fichier source :
Il n’y pas d’impact à l’éxecution (RUNSQLSTM), mais plus de confort !
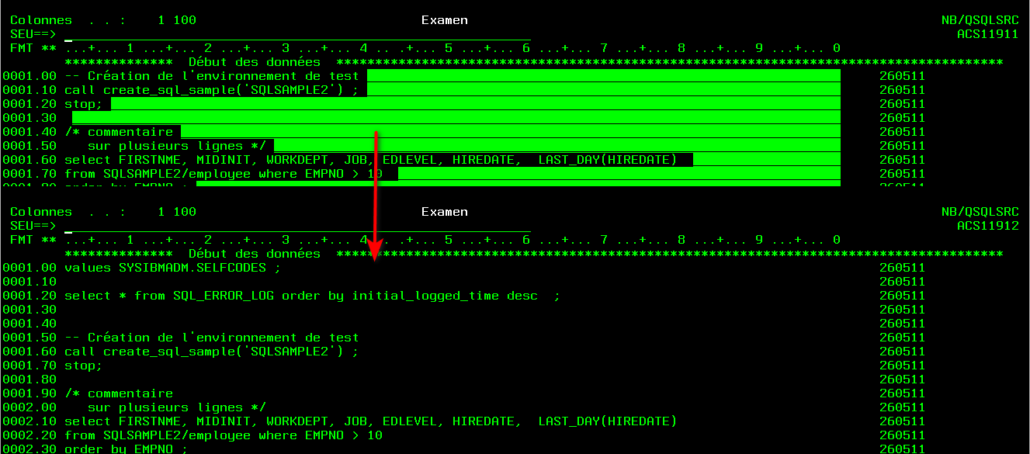
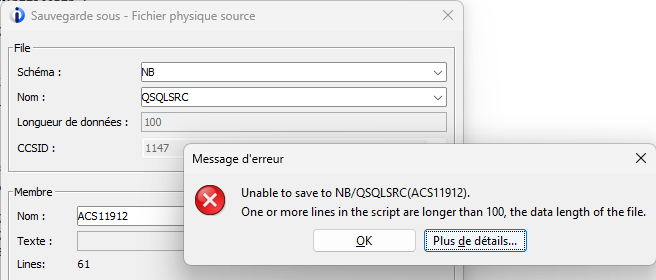
Gestion de la taille des lignes
Lors de l’enregistrement, au lieu de tronquer les lignes, un message permet d’avertir :
Exemples SQL
13 nouveaux exemples pour les services SQL :
SELF – System-wide controls
SELF – Job-level controls
SELF – Log Queries
SELF – Removing historical rows
SELF – Initial Stack
SELF – Top occurrences
SELF – QA use case exampleSecurity – Who is creating objects in the IFS root
Security – Who is creating objects in the /QOpenSys subdirectory
Security – IFS first-level directories that are open to attack
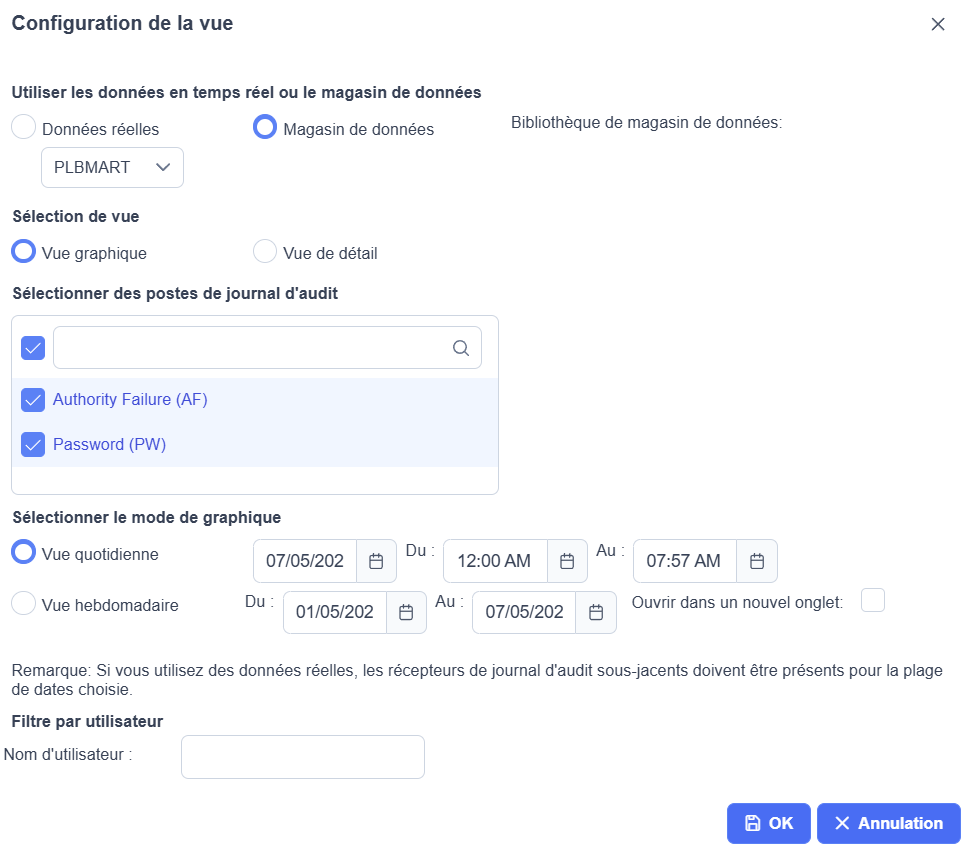
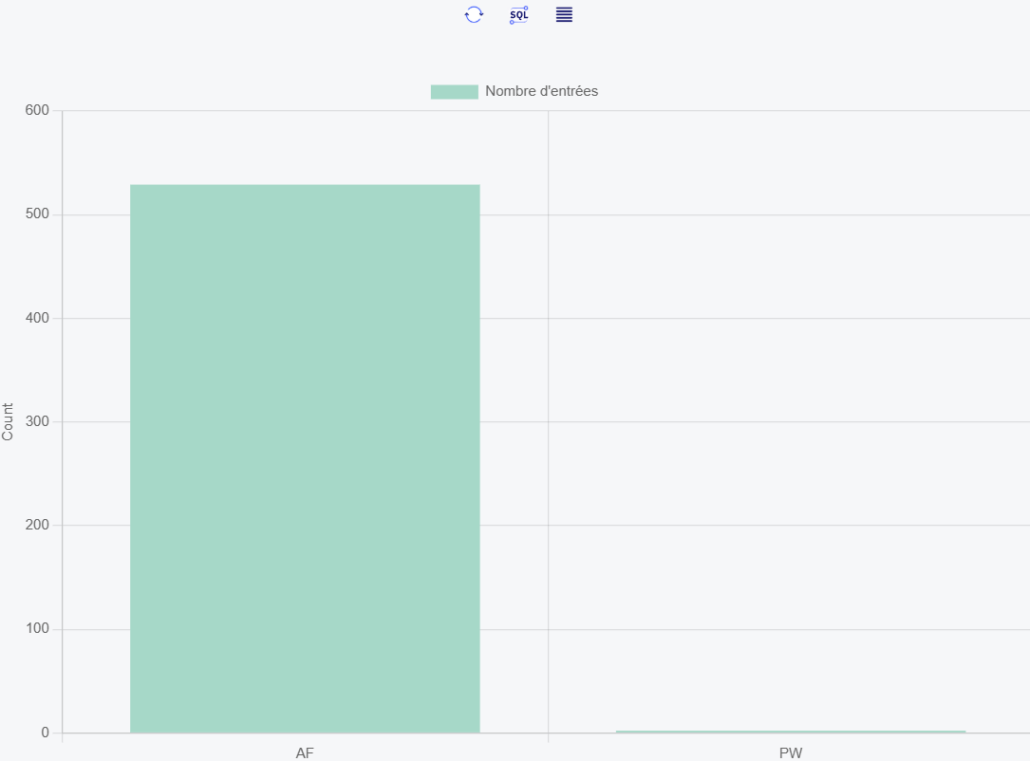
un petit rappel, il existe depuis quelque temps un mini ETL qui permet de mettre en place un suivi des codes d’audit pour avoir des statistiques et même un visuel dans Navigator for i
Vous voulez créer un datamart sur plusieurs code exemple PW et AF
et avoir un rafraichissement régulier sur la journée
Vous devez créer vos datamarts avant de commencer
En SQL
CALL QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART( JOURNAL_ENTRY_TYPE => ‘Votre code’, DATA_MART_LIBRARY => ‘Votre bib’, STARTING_TIMESTAMP => CURRENT DATE – 30 DAYS, ENDING_TIMESTAMP => CURRENT TIMESTAMP, DATA_MART_ACTION => ‘CREATE’ );
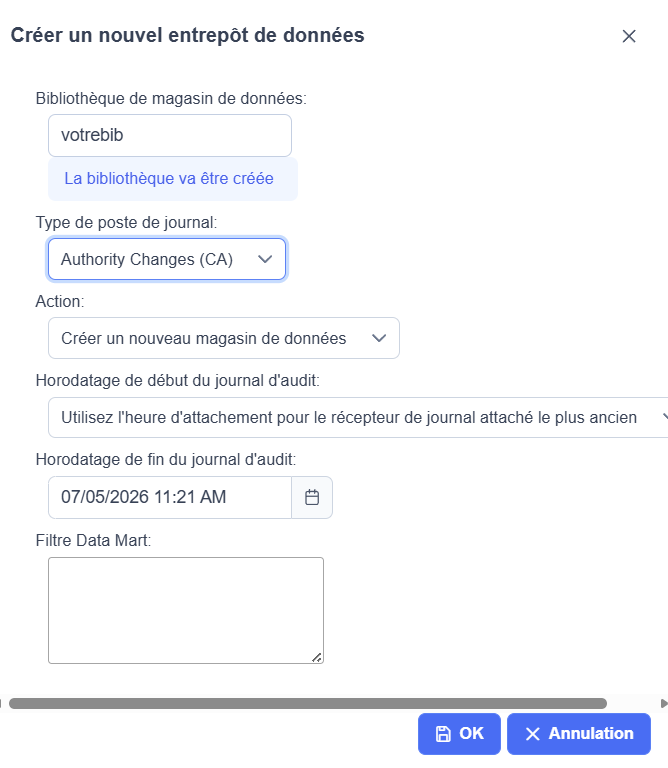
ou dans l’interface Navigator for i Journal d’audit
Gérer magasin de donnée
Ca va créer des fichiers dans la bibliothèque choisie
AUDIT_JOURNAL_XX nom SQL AJ_XX en nom systéme
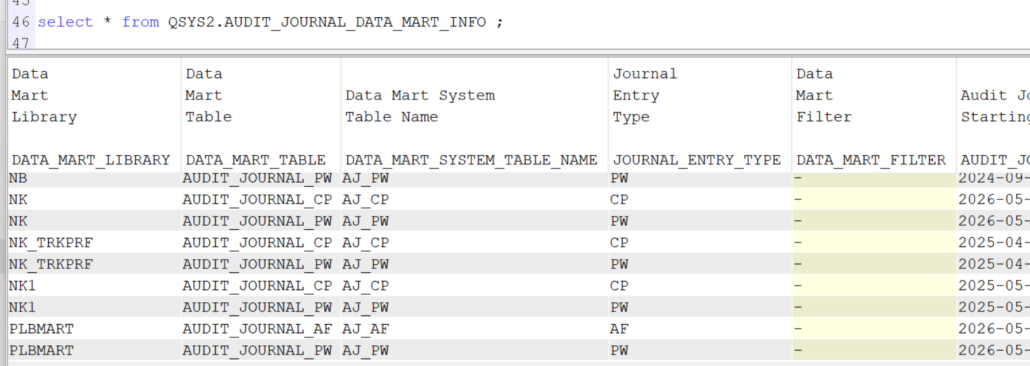
Vous pouvez les interroger par SQL
exemple:
SELECT
ENTRY_TIMESTAMP,
USER_PROFILE_NAME,
OBJECT_NAME
FROM votrebib.AUDIT_JOURNAL_DO
ORDER BY ENTRY_TIMESTAMP DESC;
Nous allons donc créer un fichier de paramétrage qui contiendra les informations de votre datamart code, bibliothèque, type de rafraichissement , et durée de rétention
Création de la table
CREATE TABLE votrebib/PARMART ( CODE_SUIVI CHAR ( 2) NOT NULL WITH DEFAULT, BIBLIO CHAR ( 10) NOT NULL WITH DEFAULT, MISEAJOUR CHAR (10) NOT NULL WITH DEFAULT duree CHAR ( 03) NOT NULL WITH DEFAULT )
Exemple insertion data dans cette table
INSERT INTO GDATA/PARMART VALUES(‘AF’, ‘PLBMART’, ‘*CONTINUE’, ‘030’)
Nous allons créer un programme AUDITREF
PGM PARM(&TIMa &timlim)
/*--------------------------------------------------------*/
/* Ce programme sert de robot pour rafraichir un datamart */
/* exemple toutes les 2 heures, 120 minutes */
/*--------------------------------------------------------*/
dcl &tima *char 3 /* Fréquence de rafraichissement en minutes */
dcl &timlim *char 6 /* Heure d'arret du robot */
/* Fichier de paramétrage des datamart à rafraichir */
DCLF FILE(PARMART)
/* Variable préformatée pour service sql */
DCL VAR(&SQL) TYPE(*CHAR) LEN(512) VALUE('CALL +
QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART(JOURNA+
L_ENTRY_TYPE => ''XX'', +
DATA_MART_LIBRARY => ''0123456789'', +
STARTING_TIMESTAMP => ''0123456789'', +
ENDING_TIMESTAMP => CURRENT TIMESTAMP, +
DATA_MART_ACTION => ''ADD'')')
dcl &finfichier *lgl
dcl &timsys *char 6 /* Heure système */
dcl &timn *dec 3 /* conversion numérique */
/* Boucle de lecture */
chgvar &timn &tima
boucle:
DOUNTIL COND(&FINFICHIER)
rcvf
MONMSG MSGID(CPF0864) EXEC(LEAVE)
CHGVAR %sst(&SQL 66 2) VALUE(&code_suivi)
CHGVAR %sst(&SQL 94 10) VALUE(&Biblio)
CHGVAR %sst(&SQL 130 10) VALUE(&miseajour)
RUNSQL SQL(&SQL) COMMIT(*NONE)
monmsg sql0000 exec(do)
SNDUSRMSG MSG('Raffraichissement impossible pour,' +
*BCAT &CODE_SUIVI *BCAT 'dans le +
datamart' *BCAT &BIBLIO) MSGTYPE(*INFO)
enddo
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA('Raffraichisement des datamarts +
terminé') MSGTYPE(*COMP)
/* on boucle jusqu'a l'heure limite */
rtvsysval qtime &timsys
IF COND(&TIMLIM > &TIMSYS) THEN(do)
dlyjob &timn
GOTO CMDLBL(BOUCLE)
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) MSGDTA('Robot +
de Raffraichisement arrêté') MSGTYPE(*COMP)
endpgm
Voici la commande pour démarrer le robot ici toute les heures jusqu’à 22 h Vous pouvez le mettre dans un scheduler
Vous devrez si vous utilisez le mode continue faire le ménage dans le datamart Exemple DELETE FROM PLBMART/AJ_AF WHERE ENTRY_TIMESTAMP < current timestamp – 30 days
voici un programme de ménage qui se basera sur la zone durée du fichier
PGM
/*--------------------------------------------------------*/
/* Ce programme sert à épurer les datamarts */
/* qui travaillent *CONTINUE */
/*--------------------------------------------------------*/
/* Fichier de paramétrage des datamart à rafraichir */
DCLF FILE(PARMART)
/* Variable préformatée pour service sql */
DCL VAR(&SQL) TYPE(*CHAR) LEN(512)
dcl &finfichier *lgl
/* Boucle de lecture */
DOUNTIL COND(&FINFICHIER)
rcvf
MONMSG MSGID(CPF0864) EXEC(LEAVE)
CHGVAR VAR(&SQL) VALUE('DELETE FROM' *BCAT &BIBLIO +
*TCAT '/' *TCAT 'AJ_' *TCAT &CODE_SUIVI +
*BCAT 'WHERE ENTRY_TIMESTAMP < current +
timestamp - ' *BCAT &DUREE *BCAT 'days')
SNDUSRMSG MSG(&sql ) MSGTYPE(*INFO)
RUNSQL SQL(&SQL) COMMIT(*NONE)
monmsg sql0000 exec(do)
SNDUSRMSG MSG('épuration impossible pour,' +
*BCAT &CODE_SUIVI *BCAT 'dans le +
datamart' *BCAT &BIBLIO) MSGTYPE(*INFO)
enddo
enddo
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) +
MSGDTA('Epuration des datamarts +
terminé') MSGTYPE(*COMP)
endpgm
Pour automatiser, lancer le une fois par semaine par exemple vous pouvez le mettre dans un scheduler
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-05-07 11:43:482026-05-07 16:39:17Automatiser les datamarts
SecuritéSSO (Single Sign-On) sur IBM i : Gérer les associations avec G-EIM
Qu’est-ce que le SSO ?
Le Single Sign-On (SSO) est un mécanisme qui permet à un utilisateur de se connecter une seule fois pour accéder à plusieurs applications. Il simplifie l’authentification sur IBM i.
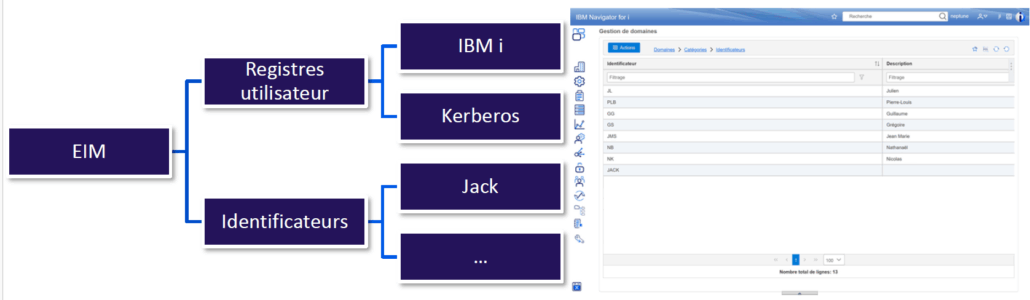
Qu’est-ce que l’EIM sur IBM i ?
L’Enterprise Identity Mapping (EIM) est un mécanisme permettant d’associer différents identifiants provenant de systèmes ou de domaines distincts. Cette association est notamment utilisée pour mettre en place des mécanismes d’authentification simplifiés et centralisés.
Qu’est-ce que G-EIM ?
G-EIM est une solution innovante développée par GAIA MINI SYSTEMES pour rendre la gestion des identifiants EIM sur votre IBM i beaucoup plus simple et sécurisée. Grâce à sa centralisation des associations EIM, il fait gagner un temps considérable à vos administrateurs !
Les avantages de G-EIM sur IBM i
Grâce à la solution, vous pouvez :
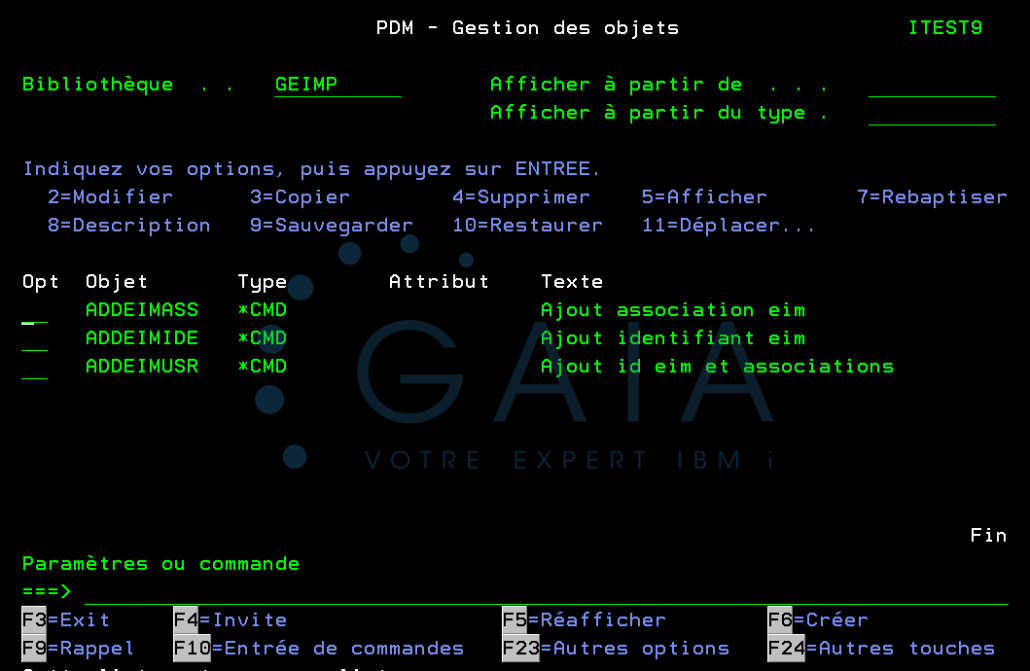
Visualiser facilement les associations existantes entre profils IBM i
Créer et modifier les associations entre profils IBM i et identifiant de domaine
Tester la configuration EIM de votre environnement afin de vérifier son bon fonctionnement
Charger l’ensemble des associations initiales en une seule commande
Dans de nombreux environnements IBM i, la création de profils utilisateurs est déjà automatisée via des programmes CL ou des procédures internes.
G-EIM s’intègre directement à ces processus afin d’automatiser également la création des associations EIM nécessaires au SSO.
Résultat : moins d’opérations manuelles, une réduction des erreurs et une gestion plus cohérente des identités.
Grâce à cette intégration par commandes, vous pouvez :
Intégrer la création des associations EIM dans vos programmes CL existants
Automatiser l’association des profils dès leur création
Garantir la cohérence entre les profils IBM i et les identifiants du domaine
Réduire significativement le temps consacré aux tâches d’administration
Vos équipes gagnent ainsi en efficacité tout en sécurisant la gestion des identités sur IBM i.
Dans de nombreuses architectures IBM i, plusieurs partitions coexistent et partagent des profils similaires : production, secours, environnements applicatifs, test ou encore développement.
G-EIM facilite la réplication des identifiants et des associations EIM entre ces différentes partitions.
Vous pouvez ainsi garantir une cohérence parfaite des configurations sur l’ensemble de votre infrastructure.
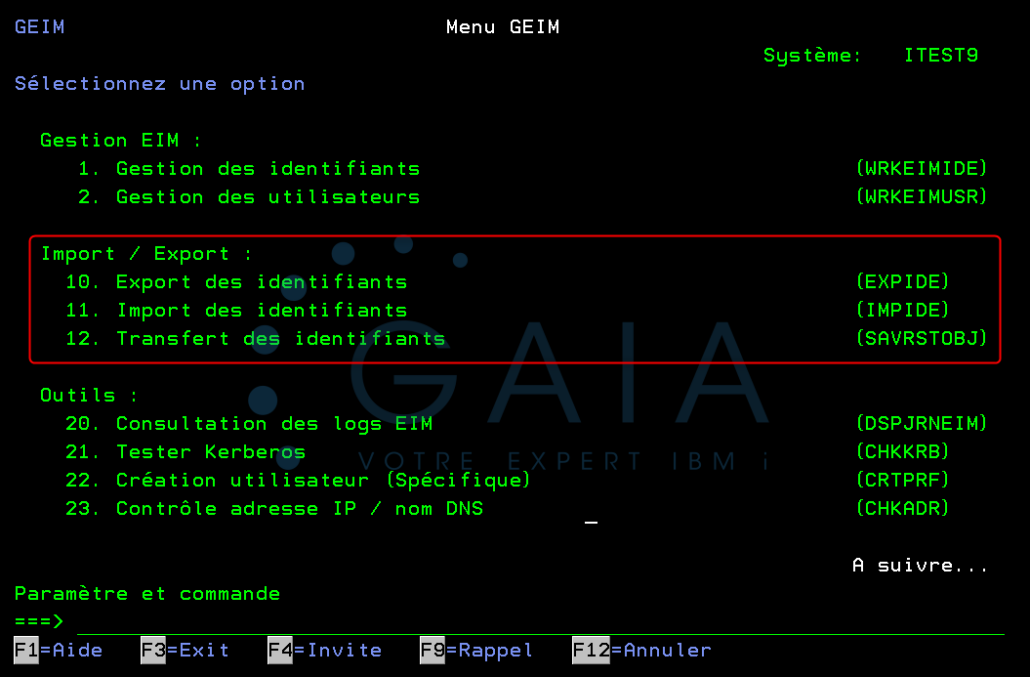
Grâce aux fonctions d’export / import de G-EIM, vous pouvez :
Exporter les identifiants et les associations depuis une partition IBM i
Importer rapidement ces données sur une autre partition
Répliquer facilement une configuration entre un environnement de production et un environnement de secours
Simplifier la gestion de plusieurs partitions IBM i
Cette fonctionnalité permet de sécuriser vos architectures tout en réduisant fortement le temps nécessaire aux opérations de bascule et de maintenance.
Mettre en place le SSO avec GEIM
La mise en place du SSO avec G-EIM permet une transition progressive vers une gestion centralisée des identités sur IBM i.
La solution s’intègre naturellement à l’existant, sans remettre en cause vos applications ou vos processus en place.
Elle permet également d’améliorer rapidement l’expérience utilisateur grâce à une authentification simplifiée et plus fluide.
Pour aller plus loin, contactez nos équipes afin de bénéficier d’une démonstration adaptée à votre environnement.
Quelle version d’IBM i est nécessaire pour utiliser G-EIM ?
G-EIM est compatible avec toutes les versions d’IBM i à partir de la version V7R3. Il s’intègre nativement aux environnements existants sans nécessiter de modification majeure de l’infrastructure.
G-EIM permet-il de gérer plusieurs identifiants pour un même utilisateur ?
Oui. G-EIM permet d’associer plusieurs profils sources à un même identifiant EIM. Cela facilite la gestion des environnements complexes et des correspondances entre utilisateurs et domaines.
Peut-on utiliser Navigator for i en parallèle de G-EIM pour la gestion EIM ?
Oui. GEIM peut être utilisé en parallèle de IBM Navigator for i. La solution est conçue pour fonctionner sans dépendance et s’intégrer aux outils IBM i déjà en place.
Peut-on automatiser la création des associations EIM avec GEIM ?
Oui. G-EIM s’intègre aux programmes CL existants afin d’automatiser la création des associations EIM dès la création des profils utilisateurs.
/wp-content/uploads/2017/05/logogaia.png00Florian Gradot/wp-content/uploads/2017/05/logogaia.pngFlorian Gradot2026-04-27 15:15:552026-05-05 11:00:57SSO (Single Sign-On) sur IBM i : Gérer les associations avec G-EIM
Sur IBM i, les groups d’activation sont au cœur de l’architecture ILE. Ils permettent de mutualiser efficacement les ressources tout en offrant un cadre d’exécution structuré et performant.
Dans la majorité des cas, le mécanisme de nettoyage automatique fourni par le système suffit largement. Mais dès que l’on travaille avec des service programs persistants, des ressources externes ou des APIs dont le cycle de vie dépasse un simple appel de programme, il devient nécessaire de reprendre la main.
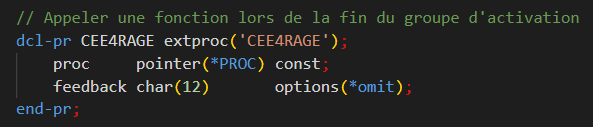
C’est précisément là qu’intervient l’API CEE4RAGE.
CEE4RAGE signifie Register Activation Group Exit Procedure.
Son rôle est très simple mais fondamental : elle permet d’enregistrer une procédure qui sera appelée automatiquement lorsque l’activation group est détruit. Cette procédure est exécutée après les exit procedures des langages de haut niveau, mais avant le nettoyage final effectué par le système. On peut la voir comme un équivalent conceptuel d’un destructeur dans les langages orientés objet.
En effet, certains « nettoyages » ne peuvent pas, ou ne doivent pas, être laissés au seul mécanisme système. Certains composants nécessitent une fermeture explicite : mémoire allouée dynamiquement, connexions réseau persistantes, APIs externes, sockets, workers auxiliaires ou encore structures partagées. CEE4RAGE garantit que votre code de nettoyage sera exécuté quelle que soit la manière dont l’activation group se termine : retour normal, reclaim, exception ou même ENDJOB.
Le besoin dépend clairement du code ILE produit.
Usage
Un cas d’usage très courant concerne les service programs persistants. Lorsqu’un service program est chargé dans un activation group nommé ou avec *ACTGRP(CALLER), il peut rester actif longtemps, parfois pendant toute la durée de vie d’un job interactif. Dans ce contexte, il est essentiel de disposer d’un point fiable pour libérer proprement les ressources lorsque l’activation group disparaît enfin. CEE4RAGE fournit exactement ce point d’ancrage.
Une approche éprouvée consiste à mettre en place un pattern « constructeur / destructeur ». L’idée est simple : initialiser les ressources lors du premier appel effectif au service program, puis enregistrer une exit procedure via CEE4RAGE pour garantir le nettoyage automatique à la fin de l’activation group.
Exemple
Voyons maintenant un exemple concret en RPGLE free format, typique d’un service program.
Le service program est défini sans programme principal, hors DFTACTGRP, et dans un activation group persistant :
Le cœur du pattern repose sur une procédure d’initialisation, appelée systématiquement par les procédures métier exportées, mais dont le contenu réel ne s’exécute qu’une seule fois :
dcl-proc InzSrvPgm;
if Initialized;
return;
endif;
// Initialisation des ressources (exemple simulé)
ResourceHandle = 12345;
// Enregistrement de l'activation group exit procedure
CEE4RAGE(%paddr(EndSrvPgm): *omit);
Initialized = *on;
end-proc;
Cette procédure effectue trois choses essentielles :
elle initialise les ressources
enregistre l’exit procedure
mémorise le fait que l’initialisation est désormais réalisée
La procédure de terminaison, elle, sera appelée automatiquement par le système lorsque l’activation group prendra fin. Elle doit impérativement être exportée et respecter la signature attendue par l’ILE :
Enfin, toutes les procédures métier exportées commencent par appeler la procédure d’initialisation. Cela garantit que l’environnement est prêt avant toute logique fonctionnelle :
Une procédure d’exit d’activation group repose sur une interface composée de quatre paramètres standards, transmis automatiquement par le runtime lors de la terminaison de l’activation group :
agMark, correspond au marqueur interne de l’activation group. Il s’agit d’un identifiant numérique unique dans le job, principalement utile à des fins diagnostiques ou pour des scénarios avancés impliquant plusieurs activation groups simultanés. Dans la majorité des cas, ce paramètre est simplement ignoré, mais il permet théoriquement de corréler une terminaison précise à un contexte donné.
reason, indique la raison de la fin de l’activation group : retour normal, reclaim, fin de job, exception non interceptée, etc. Ce code est particulièrement précieux pour adapter le comportement du cleanup, par exemple en évitant certaines opérations coûteuses lors d’une fin brutale.
result et userRC, sont des champs en entrée/sortie permettant respectivement au système et au programme de communiquer un code de résultat et une information spécifique utilisateur. En pratique, ils sont rarement exploités, mais ils offrent un mécanisme de retour standardisé permettant à une exit procedure de signaler son état ou d’influencer légèrement le déroulement du traitement global. L’ensemble de ces paramètres est optionnel côté RPG, ce qui explique l’usage fréquent de options(*nopass) ; toutefois, leur présence formalise le contrat entre le runtime ILE et la procédure d’exit, et rappelle que cette dernière s’exécute dans un contexte très particulier, où la logique doit être minimale, robuste et parfaitement maîtrisée.
Multiples procédures
Dans certains cas plus avancés, il peut être tout à fait légitime d’enregistrer plusieurs procédures d’exit pour un même activation group.
CEE4RAGE ne limite ni le nombre de procédures enregistrées, ni leur nature : chaque appel ajoute une entrée dans la pile des exit procedures, qui seront exécutées dans l’ordre inverse de leur enregistrement lors de la fin de l’activation group.
Cette capacité est particulièrement utile lorsque plusieurs composants indépendants partagent le même activation group : chaque service program peut alors enregistrer sa propre procédure de nettoyage, sans dépendre d’un point centralisé.
Il est cependant essentiel de concevoir ces exit procedures comme autonomes, simples et robustes, car une défaillance dans l’une d’elles empêche l’exécution des suivantes. Dans ce contexte, l’ordre d’enregistrement devient un véritable élément d’architecture : on veillera par exemple à enregistrer en dernier les procédures critiques, ou à utiliser une procédure « chef d’orchestre » qui appelle explicitement plusieurs routines de cleanup internes.
L’utilisation de procédures d’exit multiples est donc un mécanisme puissant, mais qui impose une discipline stricte : absence d’effets de bord, opérations idempotentes, et compréhension claire du cycle de vie global de l’activation group.
Conclusion
Ce pattern est robuste, simple et parfaitement aligné avec les mécanismes de l’ILE.
Il fonctionne aussi bien en batch qu’en interactif, résiste aux fins de job brutales et assure un comportement prévisible dans les architectures persistantes. Il est particulièrement adapté aux environnements modernisés où des composants RPG sont exposés comme briques partagées, parfois appelées par des couches Java, C ou web.
Il convient toutefois de garder quelques points en tête. CEE4RAGE n’est jamais appelée tant que l’activation group reste actif ; si celui-ci est volontairement maintenu pendant toute la durée du job, le nettoyage n’aura lieu qu’à la toute fin. De plus, si une exit procedure échoue, les suivantes ne seront pas exécutées. Il est donc essentiel d’y écrire un code simple, robuste et sans dépendances fragiles.
En conclusion, CEE4RAGE est une API discrète mais fondamentale. Elle ne sert pas à gérer des erreurs ni à intercepter des messages système ; elle sert à maîtriser la fin de vie d’un activation group.
Dès que l’on conçoit des service programs persistants et que l’on vise une architecture propre et professionnelle sur IBM i, CEE4RAGE devrait faire partie des outils de base de tout concepteur ILE.
C’est en réalité l’évolution du Swagger qui permet de décrire les web services et leurs interfaces. L’interface produit désormais une page, personnalisable, epxosant la description des services, et permettant leur test !
Modifications de l’interface
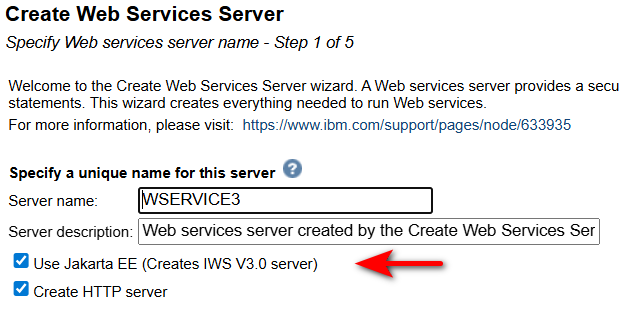
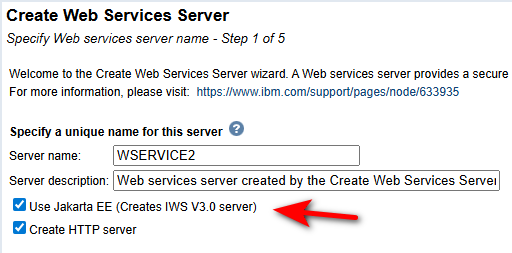
Lors de la création d’une instance IWS :
Les propriétés openapi ne sont pas affichables ou modifiables par l’interface, mais pas fichier de configuration et commande shell.
Remarque : seuls les services démarrés apparraissent dans l’interface openapi.
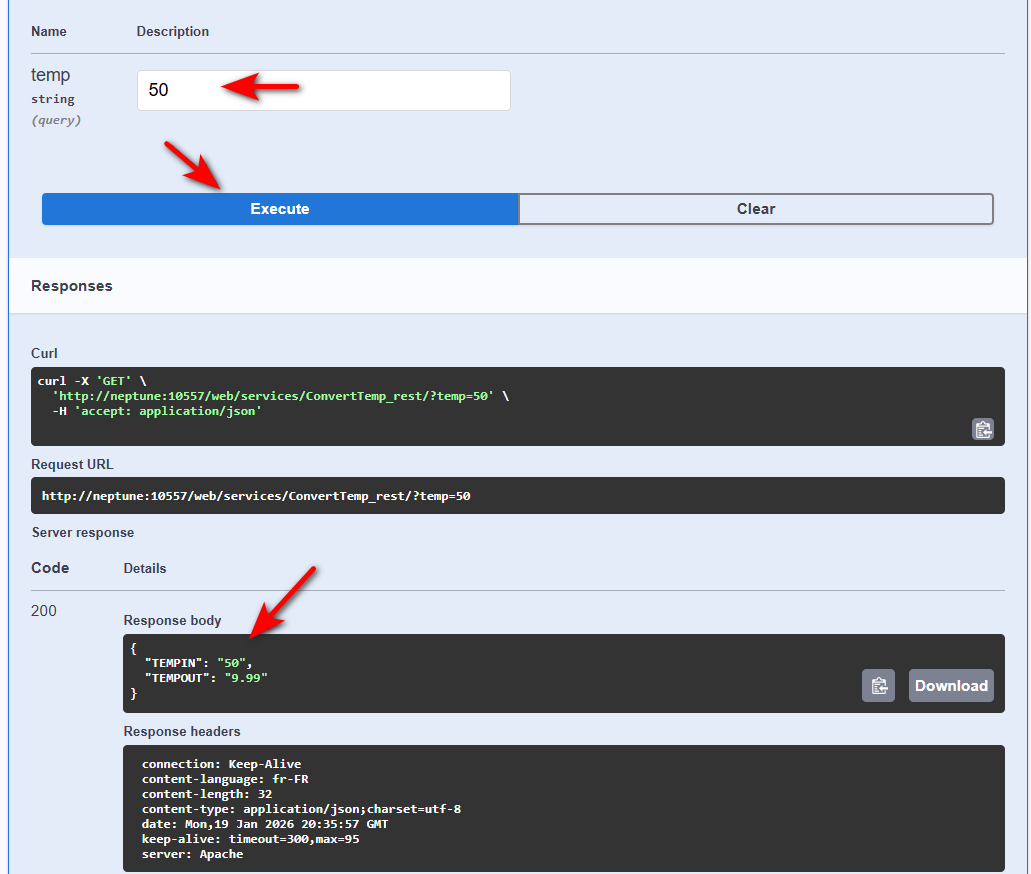
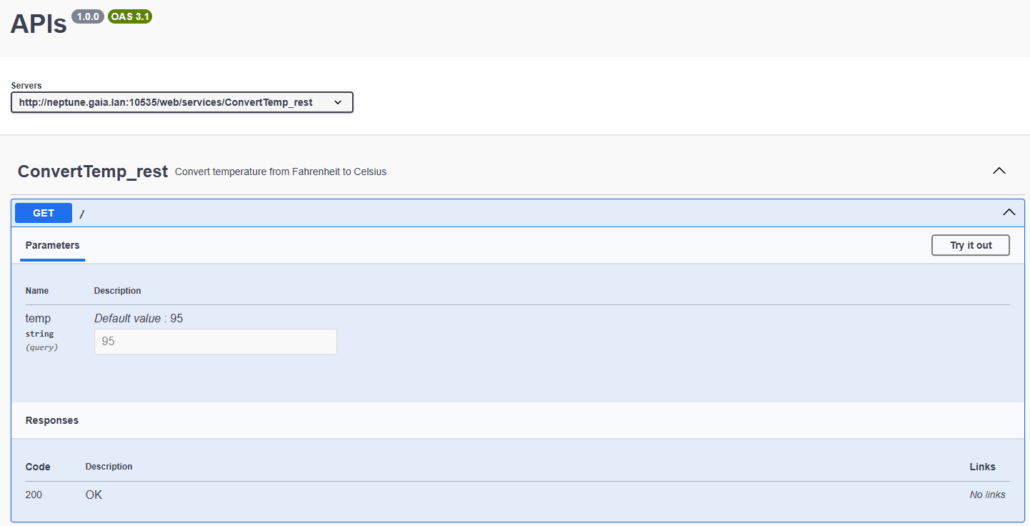
Tester un service REST
Puis indiquez vos valeurs de paramètres :
Des options sont disponibles pour les situations plus avancées (authentification basique etc …)
Modifications des commandes shell
Depuis la documentation IBM, création d’un fichier :
#server.iws.gen.httpport=52000 #server.iws.gen.httpsport=52499 #server.iws.gen.adminport=52005 #server.iws.gen.contextroot=/api #server.iws.gen.defaultkeystore=*NONE #server.iws.gen.defaultkeystorepassword= #server.iws.gen.verifyhostname=false #server.iws.gen.trace=none
# Following are OpenAPI properties - IWS 3.0 only properties
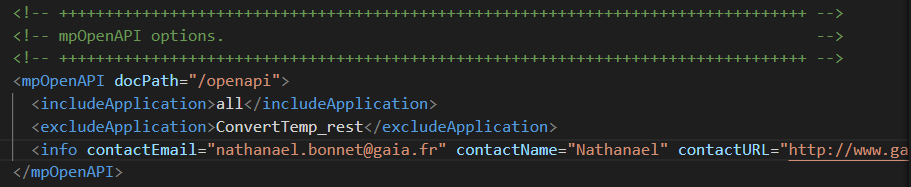
server.iws.openapi.enable=true
server.iws.openapi.docpath=/openapi
server.iws.openapi.contactemail=nathanael.bonnet@gaia.fr
server.iws.openapi.contactname=Nathanael
server.iws.openapi.contacturl=http://www.gaia.fr/contact
server.iws.openapi.description=Description : test NB pour IWS 3.0
server.iws.openapi.licensename=License Gaia 2.0
server.iws.openapi.licenseurl=https://www.gaia.fr/license
server.iws.openapi.summary=Summary : test NB pour openAPI
server.iws.openapi.termsofservice=https://www.gaia.fr/terms
server.iws.openapi.title=Titres : APIs for IWS 3.0
server.iws.openapi.version=9.8.7
server.iws.openapi.excludelist=ConvertTemp_rest
Vous pouvez ensuite demander la mise à jour des propriétés de l’instance :
qsh
cd /qibm/proddata/os/webservices/bin
setWebServicesServerProperties.sh -server 'vsc_sndbox' -propertiesFile '/www/vsc_sndbox/conf/server.properties'
Affiche :
IWS00106I - Command completed successfully. Restart of web service or server may be required for changes to take affect.
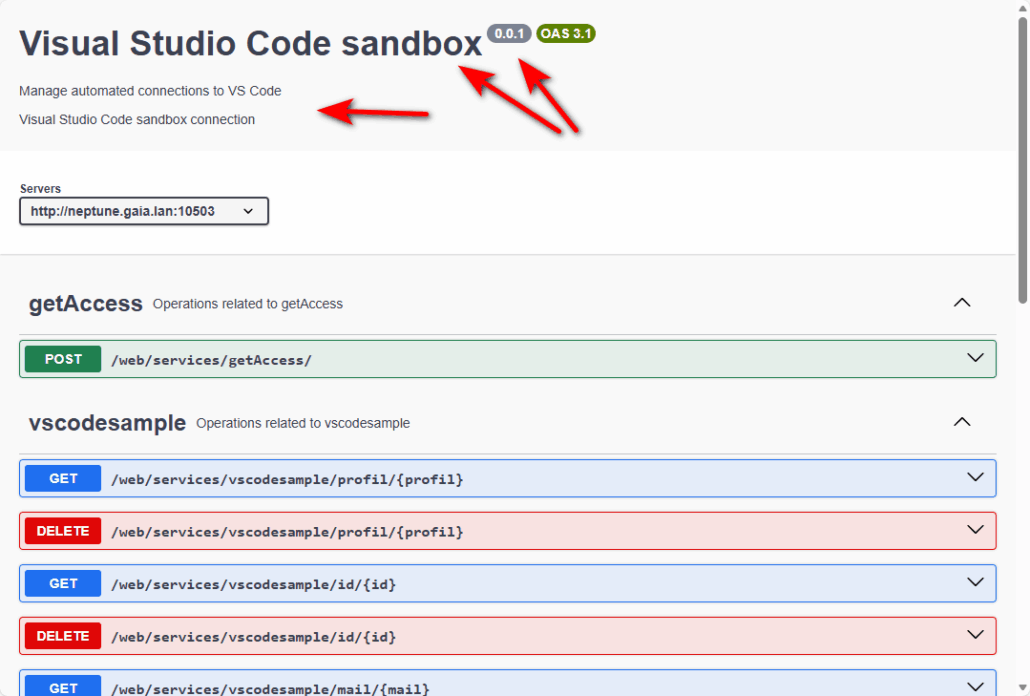
Après redémarrage de votre instance, accès à http[s]//…./openapi/ui :
Remarque : il est aujourd’hui impossible de générer un fichier de configuration pour un serveur existant.
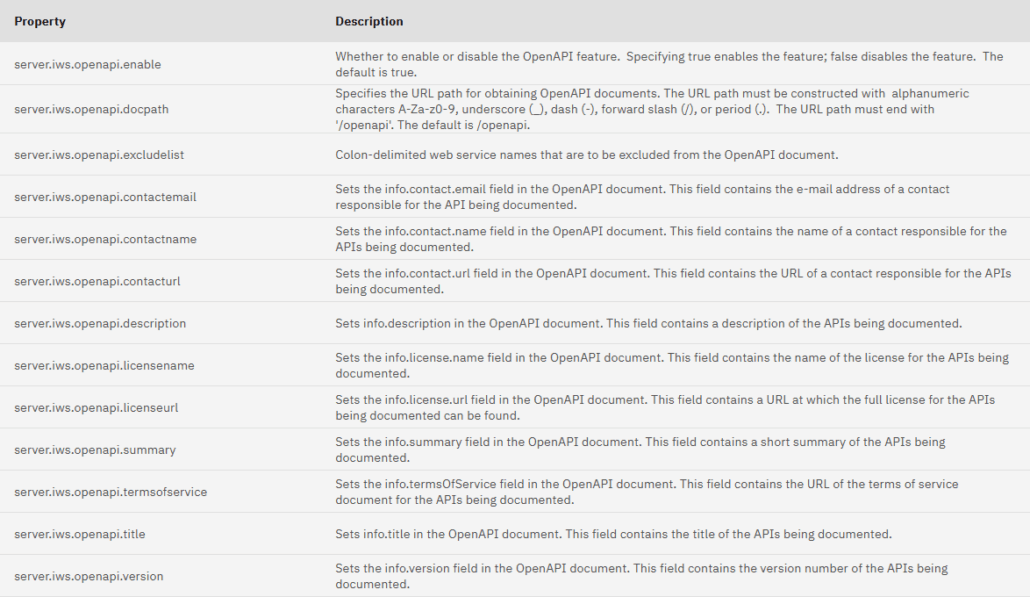
Les différentes propriétés :
server.xml
La commande sss.sh met à jour les propriétés openapi dans le fichier \www\instance\wlp\usr\servers\instance\server.xml
Migration des instances en version 2.6
Vous pouvez migrer une instance par la commande /qibm/proddata/os/webservices/bin/
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-02-24 09:50:002026-02-23 11:56:40Open api avec IWS 3.0 – partie 2
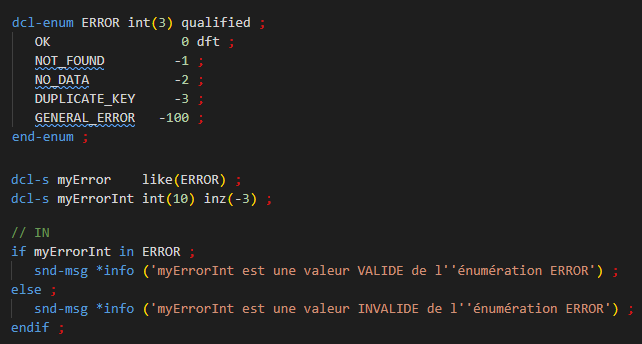
Depuis décembre 2025, le compilateur RPG permet la déclaration d’une énumération typée, ainsi que de variables de même type que l’énumération.
Prérequis
Avoir les PTFs :
7.5:
ILE RPG compiler: 5770WDS SJ08375
7.6:
ILE RPG compiler: 5770WDS SJ08384
ILE RPG compiler, TGTRLS(V7R5M0): 5770WDS SJ08394
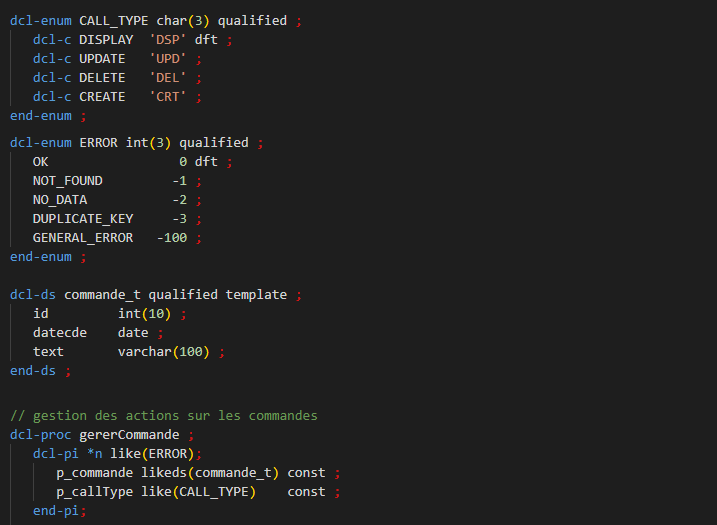
Syntaxe
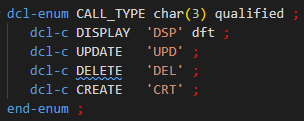
Par exemple :
Il faut indiquer le type précis de l’énumération, ici CHAR(3). Les valeurs des constantes énumérées doivent correspondre au type.
DFT indique une valeur par défaut : 1 et 1 seule, facultatif.
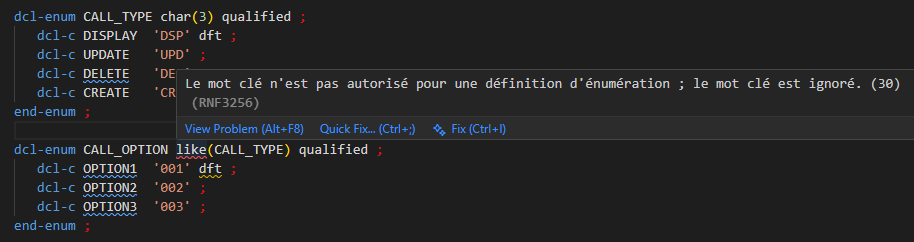
Il est impossible de définir une énumération comme une autre énumération :
Par contre, vous pouvez définir des variables comme une énumération typée :
Quelques règles
une valeur par défaut supportée par énumération
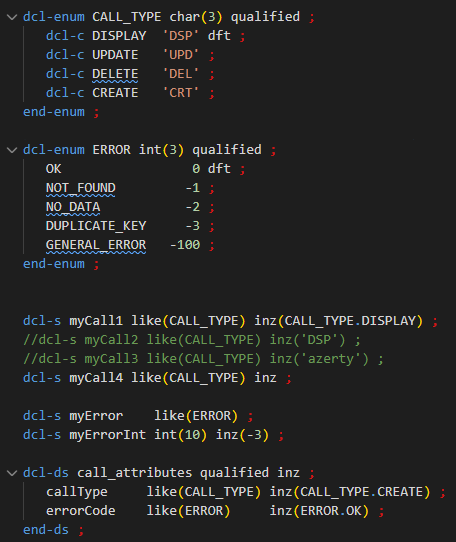
initialisation des variables ou zone de DS par une valeur de l’énumération :
dcl-s myCall1 like(CALL_TYPE) inz(CALL_TYPE.DISPLAY) : OK
dcl-s myCall2 like(CALL_TYPE) inz('DSP') : Erreur, même si la valeur existe dans l’énumération
si inz est indiqué sans valeur, la valeur par défaut de l’énumération est utilisée
de même pour l’affectation d’une nouvelle valeur, doit se faire via l’énumération, quelque soit le type de valeur :
myCall1 = CALL_TYPE.UPDATE : OK
myCall1 = 'UPD' oumyCall1 = ('U' + 'PD') : Erreur
Les fonctions %hival et %loval fonctionnent
Contrairement à*hival et*loval
En tant que tableau ou liste
Il est possible d’utiliser une énumération partout où un tableau est utilisable, sauf avec :
SORTA
%elem
%lookup
%subarr
Par exemple en tant que liste :
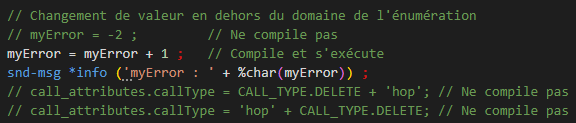
Domaine de validité
Seules les valeur de l’énumération sont utilisables, toute autre valeur provoque une erreur de compilation.
Toutefois, il est possible de contourner ce fonctionnement.
Pour les variables de type numérique, les calculs sont autorisés :
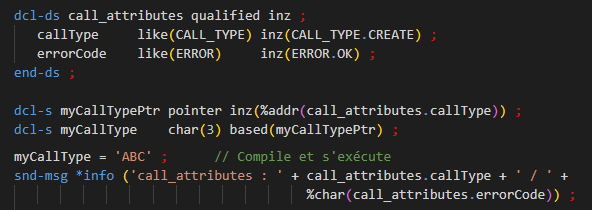
En passant avec un pointeur :
En paramètre de procédure
Cela permet d’indiquer explicitement les valeurs autorisés pour les paramètres définis comme une énumération :
la valeur de retour est définie parlike(ERROR) et ne pourra avoir que les valeurs définies
le paramètre p_callType est défini parlike(CALL_TYPE) pour lequel les valeurs sont également définies
C’est beaucoup plus pertinent qu’un commentaire, le compilateur effetuant le contrôle.
Précompilateur SQL
Les valeurs énumérées sont reconnues en tant que constantes, et les variables définies depuis une énumération sont utilisables :
Par contre, l’affectation d’une valeur non énumérée est possible :
L’utilisation en tant que liste de valeurs dans un IN SQL n’est pas supportée :
option de compilation CCSID(*EXACT)
Si votre énumération est définie en CHAR ou VARCHAR et contient des valeurs non définies par des constantes hexadécimales, c’est à dire la plupart des cas, vous devez indiquer ctl-opt ccsid(*exact).
C’est une obligation afin que le compilateur ne fasse pas de supposition incorrecte sur le CCSID des littéraux pour comparaison avec les variables de vos programmes. Aucune conversion implicite n’est effectuée et cela évote les incohérences que l’on peut avoir, particulièrement avec des fichiers source dans l’IFS, généralement encodés en UTF-8.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-01-20 09:50:002026-01-19 11:18:19Open api avec IWS 3.0
Si vous êtes utilisateur de SSO (Single Sign On) sur l’IBM i, alors vous utilisez l’EIM (Enterprise Identity Mapping).
Pour rappel (en très simplifié), le SSO vous permet de propager votre authentification Windows jusqu’à l’IBM i de sorte que n’avez pas besoin de saisir votre profil/mot de passe : une association entre vos comptes Windows et IBM i est réalisée et prise en compte automatiquement.
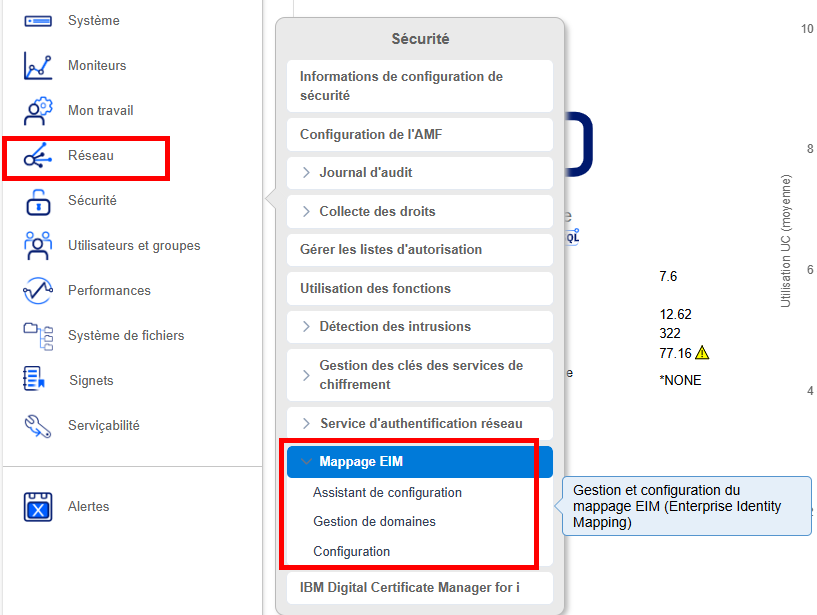
Pour gérer ces associations, vous pouvez utiliser IBM Navigator for i :
A partir de là vous avez accès à toute la gestion de l’annuaire (nécessite une authentification).
Bien entendu, ces fonctions sont critiques d’un point de vue de la sécurité : une modification de la configuration peut empêcher toute connexion, ou au contraire permettre une connexion avec un profil IBM i élevé !
IBM a donc délivré une nouvelle fonction d’usage QIBM_NAV_SECURITY_EIM (EIM related security) à cet effet : limiter l’accès aux fonctions EIM via Navigator for i.
La valeur par défaut est *ALLOWED pour tous -> vous devriez la passer à *DENIED !
Dès lors, si vous tentez d’accéder aux fonctions EIM, vous obtenez :
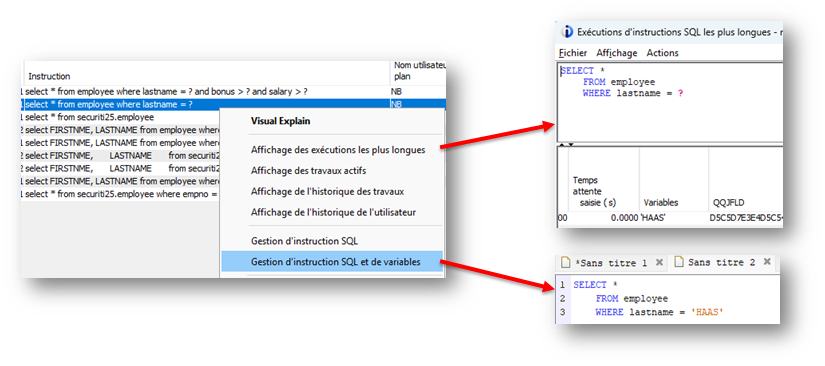
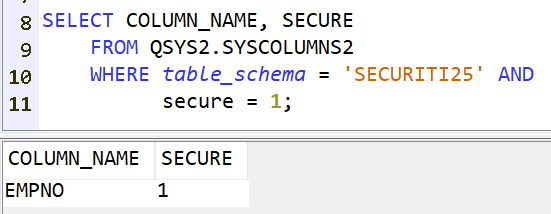
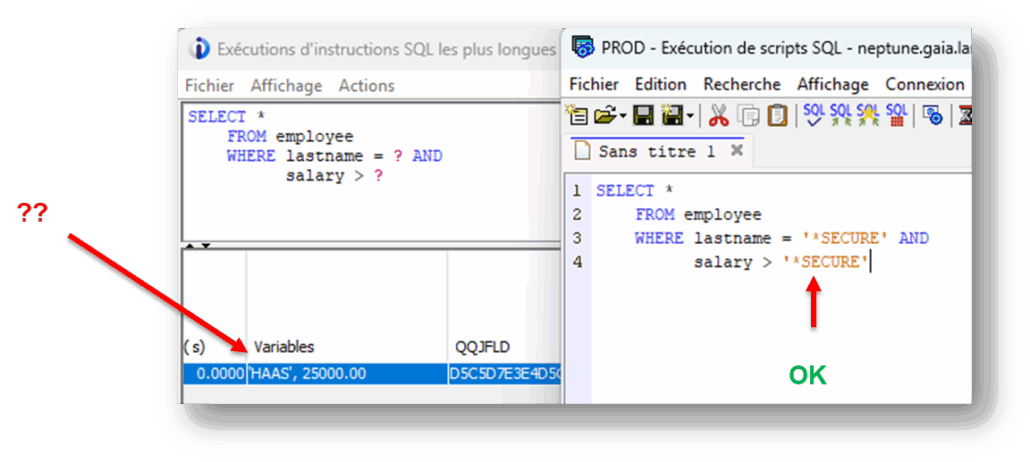
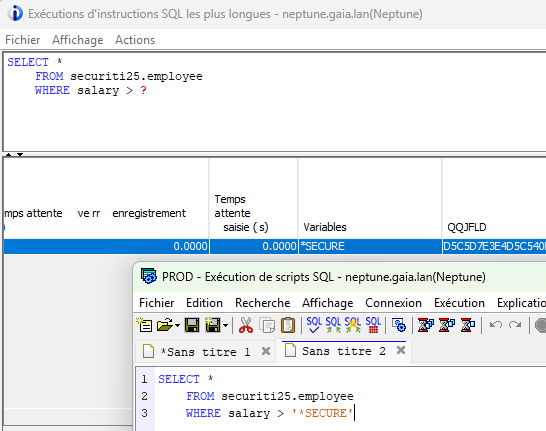
Si vous avez assisté à l’événement Securiti 2025 organisé par i.gayte.it, nous avions présenté une fonctionnalité SQL permettant de limiter l’accès aux informations du plan cache SQL.
En effet, ce dernier contient de nombreuses informations nécessaires à l’adaptation du moteur SQL. Mais il contient aussi les données utilisées dans vos requêtes : constantes littérales, valeurs de comparaisons …
Bien entendu, certaines valeurs sont à protéger, y compris des utilisateurs ayant les droits de consulter le plan cache.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-12-23 09:50:002025-12-16 08:44:24Sécurité du plan Cache SQL
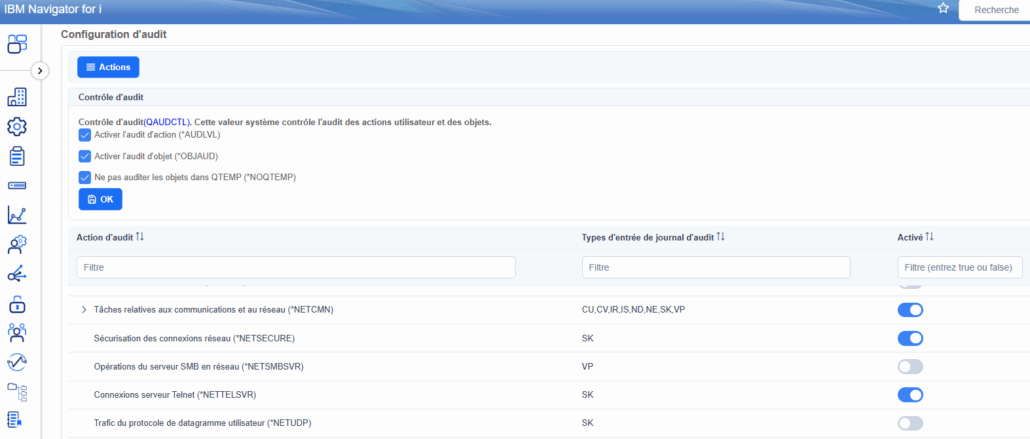
Les 3 codes à analyser sur les dernières 24 heures
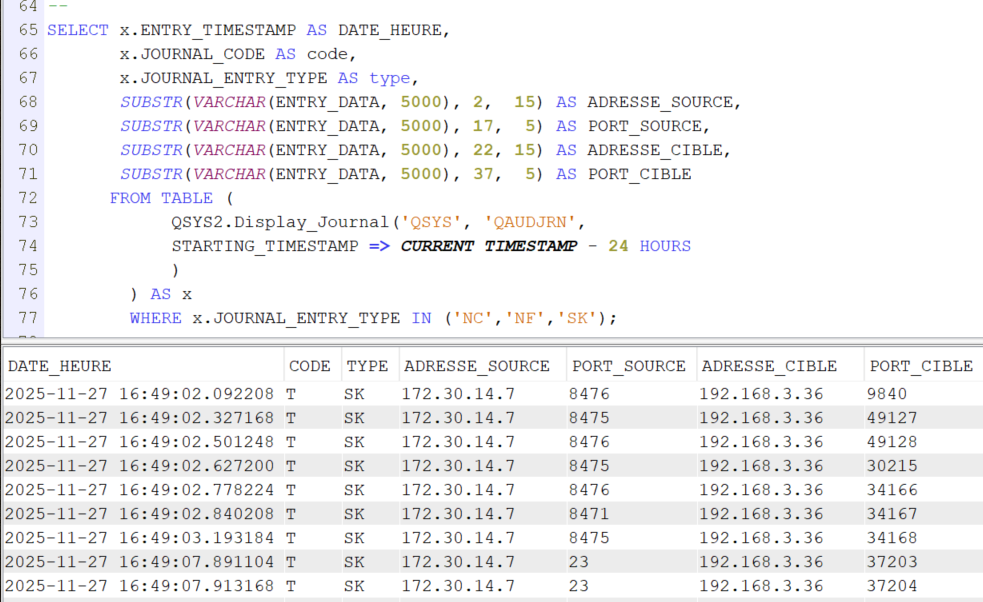
SELECT x.ENTRY_TIMESTAMP AS DATE_HEURE, x.JOURNAL_CODE AS code, x.JOURNAL_ENTRY_TYPE AS type, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 2, 15) AS ADRESSE_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 17, 5) AS PORT_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 22, 15) AS ADRESSE_CIBLE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 37, 5) AS PORT_CIBLE FROM TABLE ( QSYS2.Display_Journal(‘QSYS’, ‘QAUDJRN’, — JOURNAL_ENTRY_TYPES => ‘SK’ , STARTING_TIMESTAMP => CURRENT TIMESTAMP – 24 HOURS ) ) AS x WHERE x.JOURNAL_ENTRY_TYPE IN (‘NC’, ‘NF’, ‘SK’)
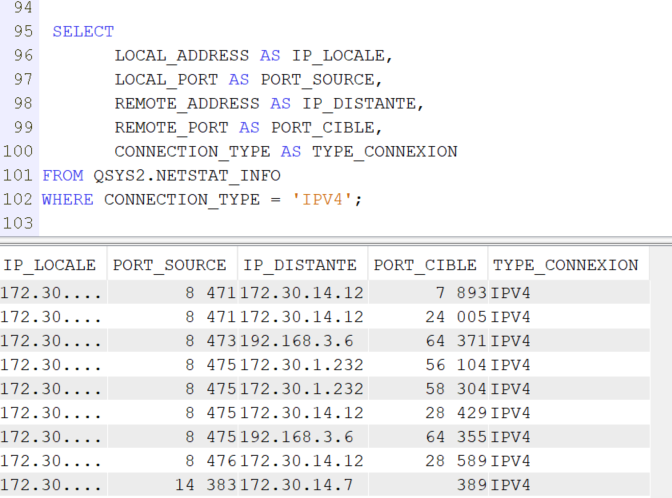
A la différence du NETSTAT suivant qui vous donne à l’information à l’instant T
SELECT LOCAL_ADDRESS AS IP_LOCALE, LOCAL_PORT AS PORT_SOURCE, REMOTE_ADDRESS AS IP_DISTANTE, REMOTE_PORT AS PORT_CIBLE, CONNECTION_TYPE AS TYPE_CONNEXION FROM QSYS2.NETSTAT_INFO WHERE CONNECTION_TYPE = ‘IPV4’;
Remarque :
Il n’existe pas encore de service dans SYSTOOLS AUDIT_JOURNAL_SK() dommage
Vous pourrez cibler des ports, des adresses ou des plages etc.
Log du système
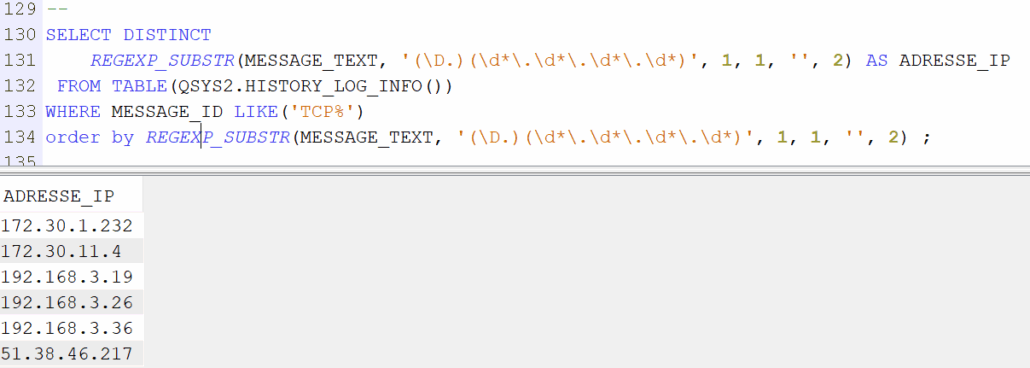
Vous pouvez également utiliser l’historique du système pour analyser certaines choses, par exemple connaitre les adresses ip.
Cette solution ne nécessite pas de paramétrage , et vous avez en principe 1 mois en ligne
— Toutes les connexions
SELECT MESSAGE_TIMESTAMP, MESSAGE_ID, REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP, MESSAGE_TEXT FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) ORDER BY MESSAGE_TIMESTAMP DESC; — Les différentes adresses SELECT DISTINCT REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) order by REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) ;
Divers :
Vous pouvez également utilisez une commande TRCCNN et générer un fichier PCAP que vous pourrez analyser ensuite , avec Wireshark
Mais également installer utiliser le FW de l’ibmi en mode journalisation pour historiser vos connexions, vous devrez installer et configurer 5769FW1
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-11-27 17:38:402025-11-28 18:21:18Analyser le Trafic TCP/IP avec le journal d’audit