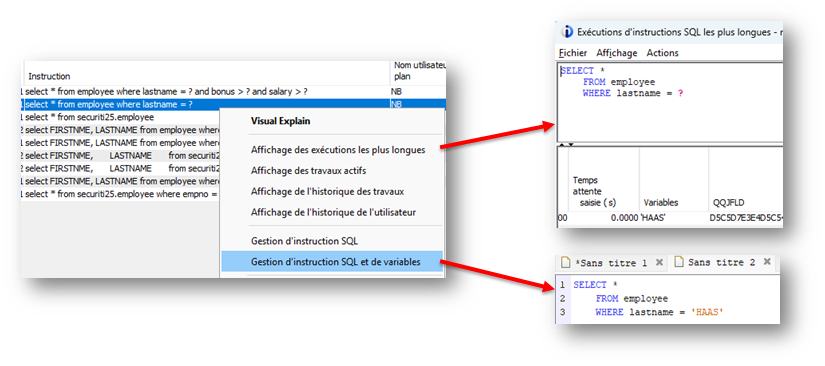
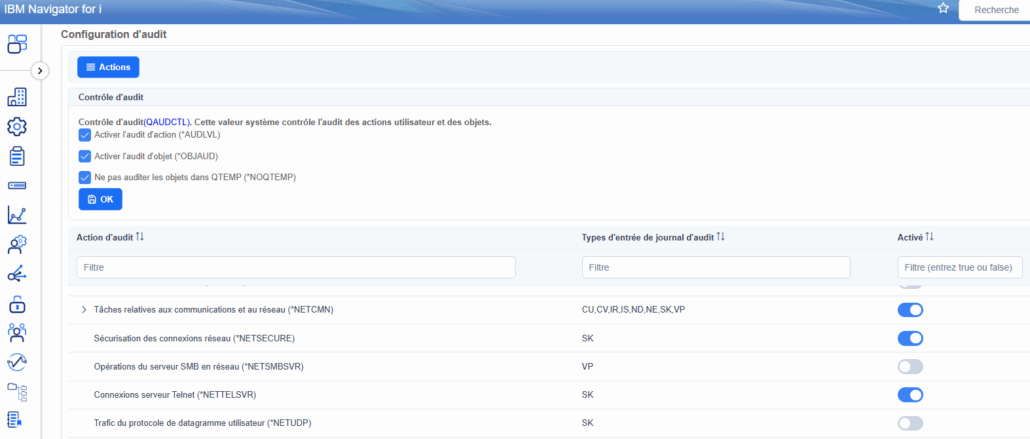
Si vous avez assisté à l’événement Securiti 2025 organisé par i.gayte.it, nous avions présenté une fonctionnalité SQL permettant de limiter l’accès aux informations du plan cache SQL.
En effet, ce dernier contient de nombreuses informations nécessaires à l’adaptation du moteur SQL. Mais il contient aussi les données utilisées dans vos requêtes : constantes littérales, valeurs de comparaisons …
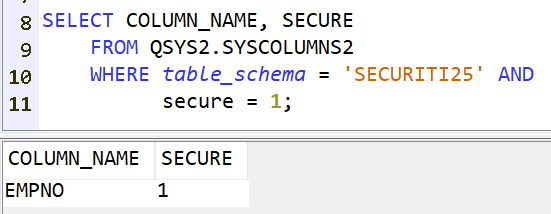
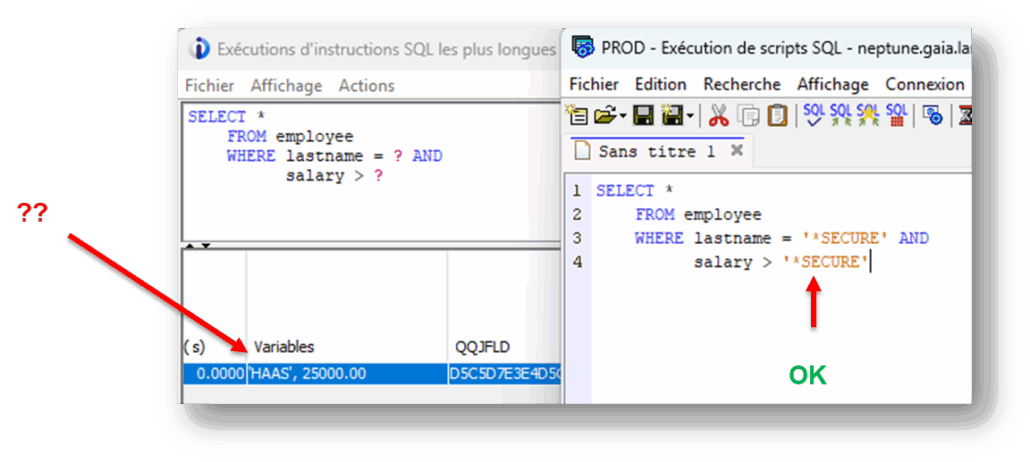
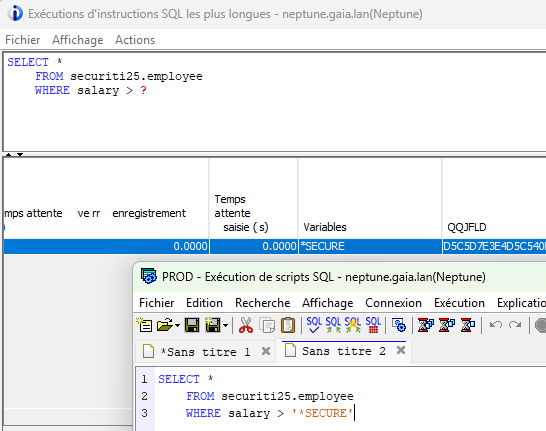
Bien entendu, certaines valeurs sont à protéger, y compris des utilisateurs ayant les droits de consulter le plan cache.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-12-23 09:50:002025-12-16 08:44:24Sécurité du plan Cache SQL
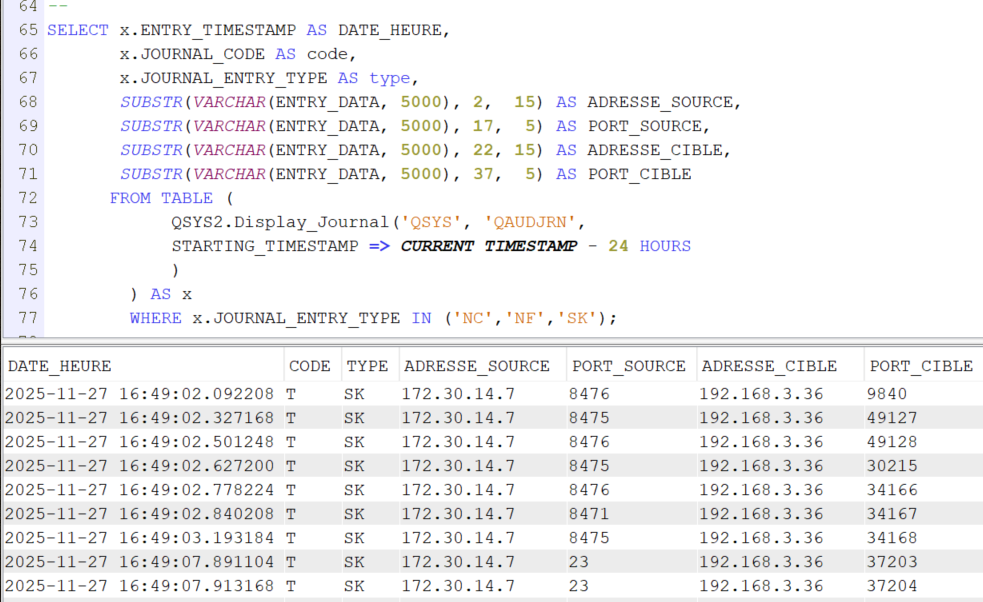
Les 3 codes à analyser sur les dernières 24 heures
SELECT x.ENTRY_TIMESTAMP AS DATE_HEURE, x.JOURNAL_CODE AS code, x.JOURNAL_ENTRY_TYPE AS type, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 2, 15) AS ADRESSE_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 17, 5) AS PORT_SOURCE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 22, 15) AS ADRESSE_CIBLE, SUBSTR(VARCHAR(ENTRY_DATA, 5000), 37, 5) AS PORT_CIBLE FROM TABLE ( QSYS2.Display_Journal(‘QSYS’, ‘QAUDJRN’, — JOURNAL_ENTRY_TYPES => ‘SK’ , STARTING_TIMESTAMP => CURRENT TIMESTAMP – 24 HOURS ) ) AS x WHERE x.JOURNAL_ENTRY_TYPE IN (‘NC’, ‘NF’, ‘SK’)
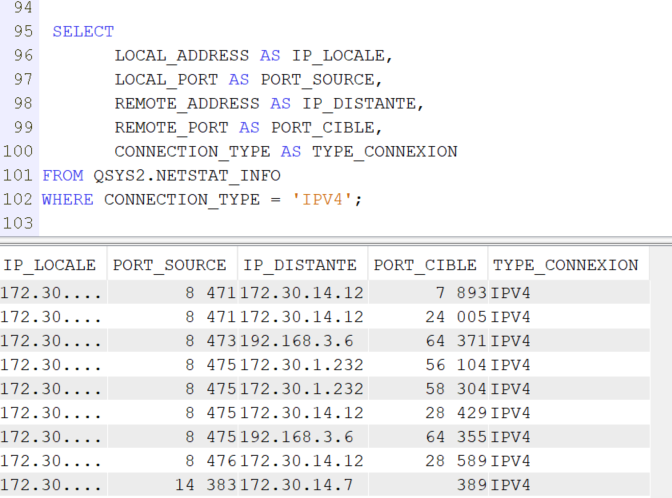
A la différence du NETSTAT suivant qui vous donne à l’information à l’instant T
SELECT LOCAL_ADDRESS AS IP_LOCALE, LOCAL_PORT AS PORT_SOURCE, REMOTE_ADDRESS AS IP_DISTANTE, REMOTE_PORT AS PORT_CIBLE, CONNECTION_TYPE AS TYPE_CONNEXION FROM QSYS2.NETSTAT_INFO WHERE CONNECTION_TYPE = ‘IPV4’;
Remarque :
Il n’existe pas encore de service dans SYSTOOLS AUDIT_JOURNAL_SK() dommage
Vous pourrez cibler des ports, des adresses ou des plages etc.
Log du système
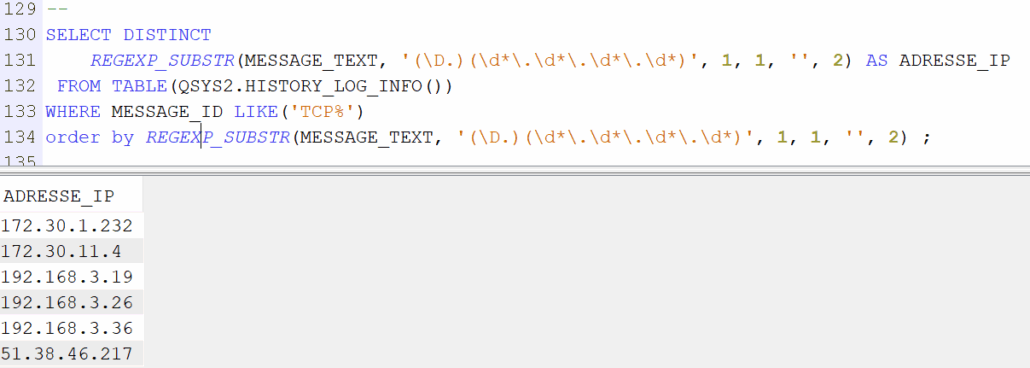
Vous pouvez également utiliser l’historique du système pour analyser certaines choses, par exemple connaitre les adresses ip.
Cette solution ne nécessite pas de paramétrage , et vous avez en principe 1 mois en ligne
— Toutes les connexions
SELECT MESSAGE_TIMESTAMP, MESSAGE_ID, REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP, MESSAGE_TEXT FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) ORDER BY MESSAGE_TIMESTAMP DESC; — Les différentes adresses SELECT DISTINCT REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) AS ADRESSE_IP FROM TABLE(QSYS2.HISTORY_LOG_INFO()) WHERE MESSAGE_ID LIKE(‘TCP%’) order by REGEXP_SUBSTR(MESSAGE_TEXT, ‘(\D.)(\d*\.\d*\.\d*\.\d*)’, 1, 1, », 2) ;
Divers :
Vous pouvez également utilisez une commande TRCCNN et générer un fichier PCAP que vous pourrez analyser ensuite , avec Wireshark
Mais également installer utiliser le FW de l’ibmi en mode journalisation pour historiser vos connexions, vous devrez installer et configurer 5769FW1
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-11-27 17:38:402025-11-28 18:21:18Analyser le Trafic TCP/IP avec le journal d’audit
Vous avez assisté, ou non, à la Power Week coorganisée par IBM France et Common France :
Gaia-Volubis a été très heureux de participer à cette édition, riche en annonces. Avant de reprendre une vie normale, de retourner à notre quotidien, voici le retour de nos speakers !
Damien
C’est toujours un moment particulier pour nous dans notre calendrier, et cette année n’aura pas dérogée aux autres : beaucoup de participants, d’échanges que ce soit avec des clients ou des IBMers, quelques dépannages en direct ! 3 jours intenses.
Merci aux participants à nos sessions et à leurs retours. Il est toujours appréciables de savoir que nos choix de sujets correspondent à des attentes des participants à l’évènement. Prochain évènement de masse : le Common Europe à Lyon en juin 2026…
Florian
Trois jours intenses et passionnants pour cette édition de la Power Week 2025 !
Au-delà du programme officiel, ce sont surtout les échanges directs avec nos clients, partenaires, IBMers et l’ensemble des participants qui ont marqué l’événement. Ces discussions spontanées, souvent en marge des sessions, sont celles qui font grandir notre réseau, ouvrent des perspectives et apportent des idées concrètes pour aller plus loin.
J’ai également pu présenter COMMON France et toutes les actions que nous avons menées cette année, notamment la Battle Dev que j’ai eu le plaisir de coorganiser avec Philippe Bourgeois et Jérôme Clément. J’espère que nous pourrons organiser une 4ᵉ édition l’année prochaine !
Merci à tous d’être venus !
Julien
Merci à toutes et à tous pour ces trois journées intenses à la Power Week 2025 !
J’ai particulièrement apprécié la qualité des échanges avec nos clients, partenaires et IBMers. Ces moments informels, toujours très enrichissants, sont essentiels pour nourrir notre réseau et nos perspectives.
J’ai également été heureux de présenter deux sessions orientées sécurité et bonnes pratiques sur IBM i, des sujets au cœur des préoccupations de nombreux clients. Merci pour votre participation et vos questions !
L’événement a une nouvelle fois confirmé sa convivialité, et la troisième édition de la Battle Dev a été remarquablement organisée.
Ravi de vous avoir retrouvés en nombre, et déjà impatient de vous revoir au Common Europe à Lyon en juin 2026 !
Betty
Ces trois jours au cœur de la communauté IBM étaient d’une richesse incroyable.
Ils m’ont permis d’avoir une vue plus globale et plus synthétique de la puissance, des possibilités et de l’avenir du power et de ses applications.
Mais le futur s’écrit aussi avec la jeune génération de programmeurs, et la présence des participants à la pépinière de cette année m’a permis de voir que la relève était assurée grâce à ces formations.
J’ai eu l’occasion de faire une première présentation qui concernait la modernisation via SQL, et je n’ai aucun doute que les équipes hybrides qui se construisent actuellement avec des jeunes et des personnes plus expérimentées sauront trouver des méthodes de travail permettant d’aller vers cette modernisation, nécessaire, et souhaitée.
Eric
3 jours intenses de rencontres, des visages connus et des nouveaux venus. 3 jours de sessions intéressantes. Toutes les personnes rassemblées ont en commun un grand intérêt, voire même une passion pour leur système favori. Une communauté IBMi toujours aussi active.
J’ai pu cette année présenter la session « Modernisation avec SQL : comment Intégrer l’existant », avec BETTY et LUCAS. Notre première session. Ce fut intense à préparer, et à présenter.
Les outils open source ont suscité mon intérêt cette année. La présentation de BOB a été très instructive, bien qu’il reste de nombreuses questions encore sans réponse.
Merci à tous pour votre énergie et votre participation!
Pierre Louis
C’est avec plaisir que comme chaque année, on retrouve la communauté IBMi, cette année pour la première fois les gens du monde Power nous ont rejoint.
On a pu assister à des présentations techniques intéressantes, beaucoup était basées sur l’IA, comme BOB , dont la présentation a été très prometteuse …
Pour ma part j’ai trouvé très intéressant le produit MANZAN qui permet de supervisé votre IBMi et qui a l’air simple et efficace.
Cette année, j’ai présenté 2 sessions en duo avec Gautier Dumas, sur le chemin de modernisation et avec Florian Gradot sur, comment donner une seconde vie à vos application 5250, merci a eux de m’avoir supporté, ce fut une expérience intéressante.
J’ai pu échangé sur des thèmes différents, avec des clients et des partenaires, ce qui est toujours enrichissant.
Merci à IBM et à Common pour cette organisation, merci à ceux qui sont venus, et l’année prochaine !
Nathanaël
3 jours très intenses pour ma part, mais très enrichissants !
Les meilleurs moments : ceux que l’on ne peut pas mettre en photo 😉
J’ai particulièrement apprécié de pouvoir échanger de façon libre et informelle avec nos clients, partenaires, IBMers et de façon plus globale toutes les personnes présentes. C’est important, c’est la construction d’un réseau, un réseau qui apporte des perspectives, des solutions.
Donc merci à vous d’être venu, nombreux, y compris dans non sessions, de poser des questions. C’est ce qui nous donne l’énergie pour les mois à venir jusqu’au prochain grand rassemblement !
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
https://www.gaia.fr/wp-content/uploads/2025/11/Media-xx-7.jpg12001600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-25 10:04:172025-11-25 10:05:02Power Week 2025 : retour à la maison !
Cela n’a pas pu vous échapper, la semaine prochaine c’est (déjà) la Power Week, événement gratuit coorganisé par IBM France et Common France :
Durant ces 3 jours dédiés au Power Systems, au stockage, au Power11, à l’IA, à l’IBM i, AIX, Linux, la modernisation … retrouvez l’ensemble des speakers, des partenaires et des clients qui font la force de notre plateforme.
Un programme riche (et international)
Pendant trois jours, les participants auront accès à des sessions animées par les meilleurs experts, venus de France, d’Allemagne, des États-Unis … Parmi eux, des IBM Champions, reconnus pour leur expertise et leur engagement auprès de la communauté, partageront leurs connaissances sur des sujets variés : modernisation, sécurité, SQL, DevOps, IA, cloud hybride, et bien plus encore.
La Power Week est 100 % gratuite et ouverte à tous les professionnels de l’IBM i : développeurs, architectes, DSI, chefs de projet, consultants… C’est une opportunité rare de bénéficier de contenus de qualité sans contrainte logistique ni financière.
La force de la communauté
Au-delà des conférences, la Power Week est un lieu de rencontre et d’échange. Elle permet de :
Réseauter avec d’autres professionnels confrontés aux mêmes enjeux
Confronter les points de vue, partager des bonnes pratiques
Découvrir les clubs utilisateurs comme Common France, qui jouent un rôle dans l’animation de la communauté en France, mais aussi au niveau Européen.
Ces moments d’échange sont essentiels pour faire évoluer les pratiques, identifier des solutions concrètes, et tisser des liens durables.
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
Les speakers de Gaia et Volubis sont très heureux de participer à cette célébration : échange, partage, connaissance.
En tant que sociétés liées à la formation, il est dans notre ADN de participer à ces initiatives, comme nous le faisons depuis longtemps : les Universités IBM i depuis 2011, Pause Café en physique ou en ligne, articles de blogs …
N’hésitez pas à solliciter nos speakers sur place !
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-11-11 10:00:002025-11-10 19:37:40Power Week 2025 : 3 jours pour se connecter, apprendre et faire rayonner la communauté IBM i
Si comme nous vous avez de nombreux certificats sur vos systèmes, le ménage peut s’avérer compliqué. En effet, au fur et à mesure des renouvellements, les nouveaux certificats sont installés, les nouvelles autorités également.
Mais les suppressions de certificats sont souvent remises à plus tard. Et l’on se retrouve avec un nombre importants de certificats pour lesquels il est préférable de contrôler la non utilisation avant suppression.
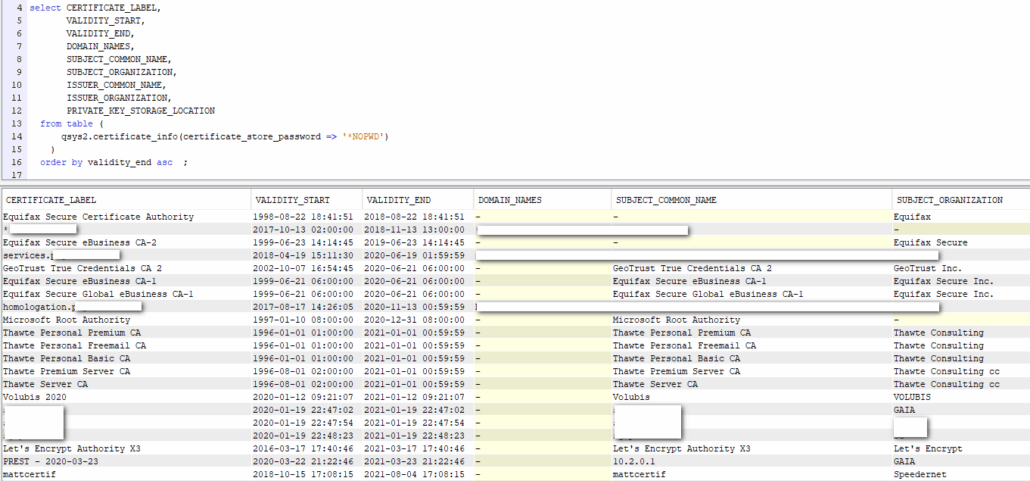
Permet d’obtenir facilement les principales informations sur les certificats et autorités de certification du magasin *SYSTEM :
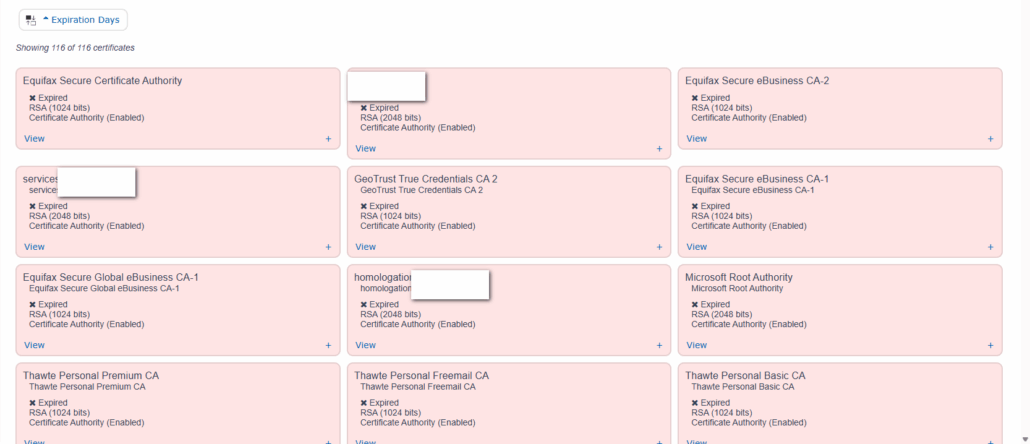
La même vue dans DCM :
Et on remarque donc la nécessité du ménage (dans mon cas).
Premièrement, comment faire la distinction entre les certificats et les autorités de certifications ? En utilisant la colonne PRIVATE_KEY_STORAGE_LOCATION.
Autorité de certification
select CERTIFICATE_LABEL, VALIDITY_START, VALIDITY_END, DOMAIN_NAMES, SUBJECT_COMMON_NAME, SUBJECT_ORGANIZATION, ISSUER_COMMON_NAME, ISSUER_ORGANIZATION, PRIVATE_KEY_STORAGE_LOCATION from table ( qsys2.certificate_info(certificate_store_password => '*NOPWD') ) where( PRIVATE_KEY_STORAGE_LOCATION <> 'SOFTWARE' or PRIVATE_KEY_STORAGE_LOCATION is null)
Le premier élément trivial : quels sont les certificats périmés :
select CERTIFICATE_LABEL, VALIDITY_START, VALIDITY_END, DOMAIN_NAMES, SUBJECT_COMMON_NAME, SUBJECT_ORGANIZATION, ISSUER_COMMON_NAME, ISSUER_ORGANIZATION, PRIVATE_KEY_STORAGE_LOCATION from table ( qsys2.certificate_info(certificate_store_password => '*NOPWD') ) where validity_end <= current timestamp order by validity_end asc ;
Lien
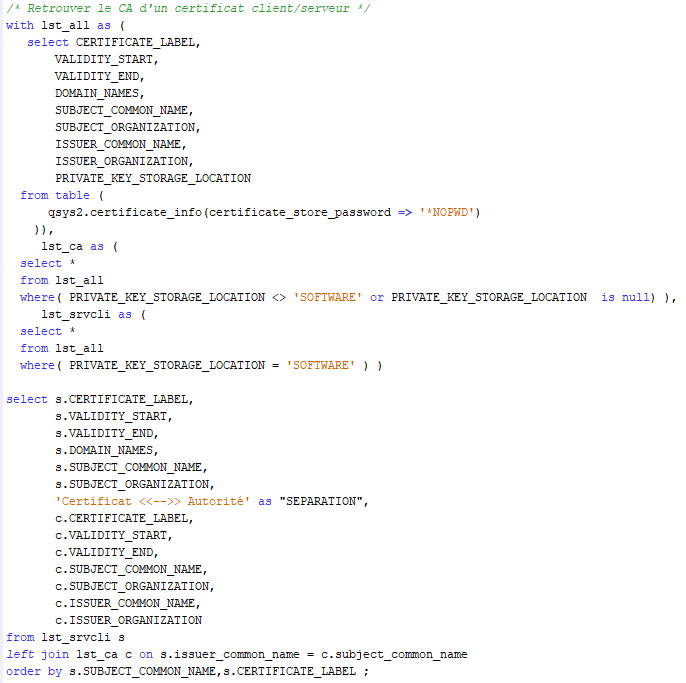
Les certificats sont émis (signés) par des autorités de certification, le lien entre les deux est donc un élément indispensable.
Nous pouvons donc maintenant répondre aux questions suivantes :
Pour chaque certificat client/serveur, quel est l’autorité de certification ?
Mais cela génère des doublons :
En effet, nous faisons le lien via le Common Name de l’autorité. Mais celui-ci n’est pas obligatoirement unique, et c’est bien le cas sur les autorités locales créées via les assistants de configuration IBM i.
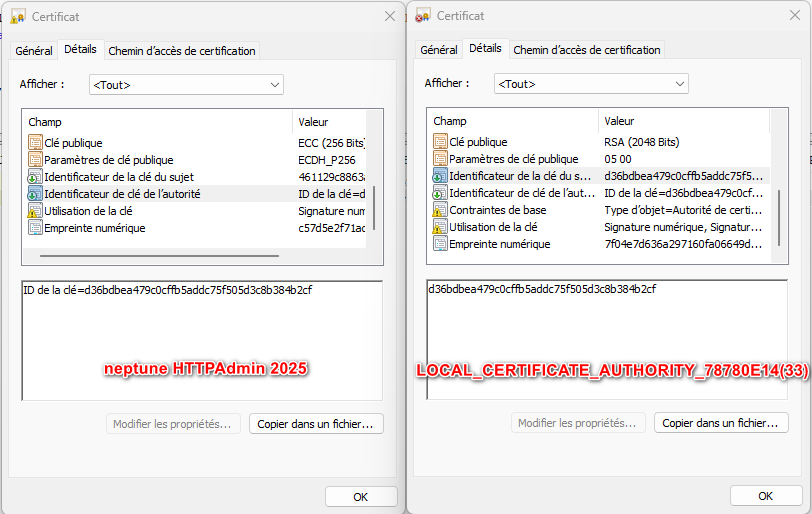
Pour avoir un identifiant unique, il nous faut utiliser les identifiants de clés, qui elles sont distinctes :
Mais cette information est absente de la fonction table qsys2.certificate_info.
Nous donnerons une solution (pas si simple) lors d’un prochain article dédié.
Malgré tout, ce problème ne concerne « que » les certificats générés depuis une autorité locale, elle même créée via les assistants IBM i, les autorités publiques ayants des noms uniques.
Si l’on prend un certificat acheté via Gandi :
On obtient bien une information unique et exploitable.
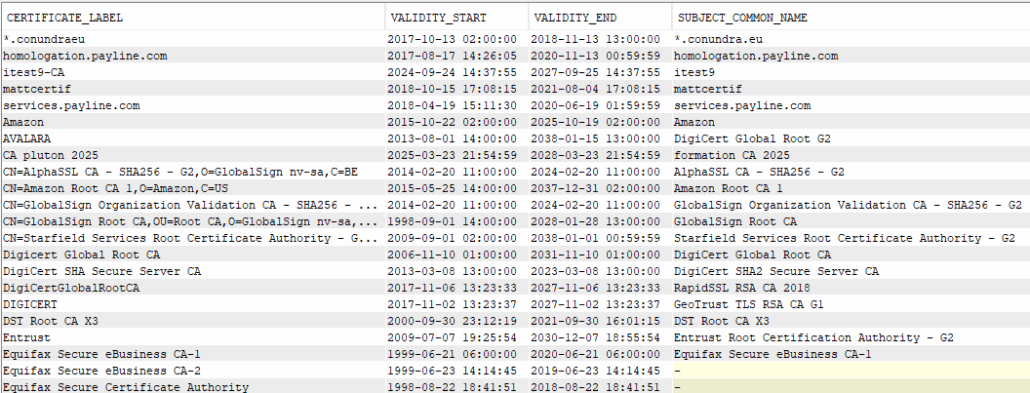
Pour chaque autorité, quels sont les certificats émis ?
Par exemple :
Extrait du résultat :
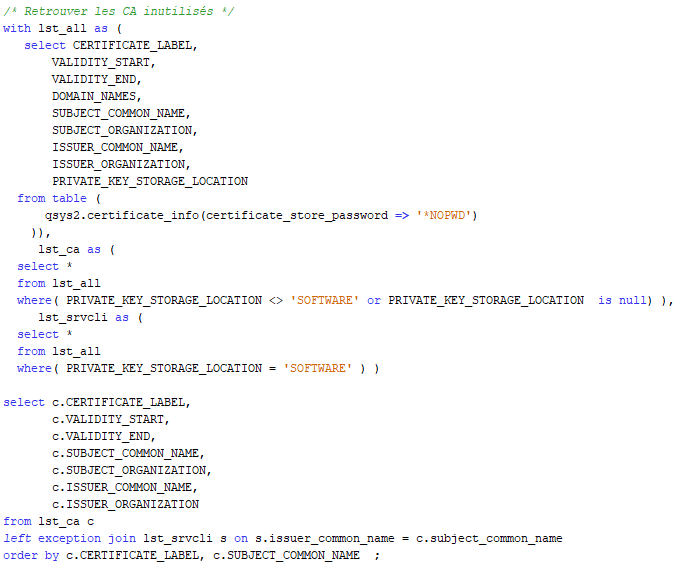
Par extension, quelles sont les autorités inutilisées ?
Produit :
Et le ménage ?
Avec les requêtes précédentes, vous pouvez isoler les certificats et autorités périmés ou les autorités inutilisés (dans notre cas les autorités n’ayant pas généré de certificat). Et vous pouvez donc les supprimer de façon ciblée.
Attention : les autorités et certificats peuvent être utiles et utilisés en dehors des liens vus ici. Ces requêtes permettent donc d’aider à la décision, mais ce n’est pas un automatisme !
Pour aller plus loin
Nous pouvons inclure l’analyse des applications DCM : liens applications/certificats.
Et également utiliser les API RSE pour automatiser la suppression des certificats.
Et rendre nos requêtes récursives pour permettre de suivre une hiérarchie à plus d’un niveau
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-09-09 09:55:002025-09-08 12:08:31Analyser les certificats TLS par SQL
Vous connaissez les programmes en adoption de droit, ce sont des programmes qui s’exécutent avec le droit du propriétaire et non celui du job en cours.
C’est relativement clair sur les accès natifs, mais sur SQL et sur des instructions mixtes c’est pas toujours évident à comprendre
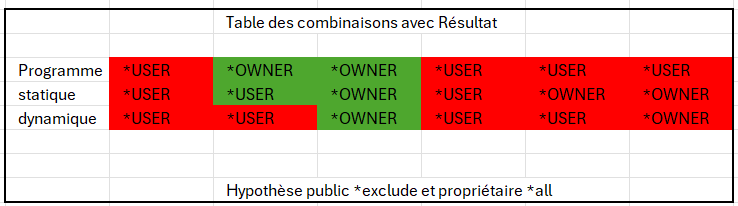
Voici un détail sur les fichiers, on peut agir sur 3 paramètres un sur la commande de compile ou d’assemblage USRPRF() 2 qui peuvent être fixés par la commande compile ou par les options SQL EXEC SQL Set Option .. UsrPrf = *USER, DynUsrPrf = *USER, .. ;
On va donc essayer de voir les combinaisons possibles de ces 3 options
Voici notre protocole un programme sqlrpgle et une table en *exclude et la convention *SYS
Opération non autorisée sur fichier ATSTADOPT de *LIBL, membre, ou unité *N. DSPLY 1217 ouverture native ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL statique ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL dynamique ko
Test 2
USRPRF(*owner) UsrPrf = *User, DynUsrPrf = *User,
call atstadopt DSPLY 0 accès natif ok DSPLY 0 SQL statique ok Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL dynamique ko
call atstadopt DSPLY 0 accès natif ok DSPLY 0 SQL statique ok DSPLY 0 SQL dynamique ok
Test 4
USRPRF(*USER) UsrPrf = *OWNER, DynUsrPrf = *USER,
call atstadopt Opération non autorisée sur fichier ATSTADOPT de *LIBL, membre, ou unité *N. DSPLY 1217 ouverture native ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL statique ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL dynamique ko
Opération non autorisée sur fichier ATSTADOPT de *LIBL, membre, ou unité *N. DSPLY 1217 ouverture native ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL statique ko Non autorisé à l’objet ATSTADOPT de GDATA type *FILE. Non autorisé à l’objet ATSTADOPT dans GDATA, de type *FILE. DSPLY -551 SQL dynamique ko
Remarques
2 petites particularités sur
1) sur Usrprf SQL
*NAMING (la valeur par défaut) Le profil utilisateur est déterminé par la convention d’appellation. S’il s’agit de la convention *SQL, USRPRF(*OWNER) est utilisé. S’il s’agit de la convention *SYS, USRPRF(*USER) est utilisé.
2) Option SQL souvent inutile
Si vous n’êtes pas en adoption de droit sur le programme UsrPrf et DynUsrPrf sont sans effet
Si le programme est en adoption de droit UsrPrf = *OWNER est implicite à l’inverse de DynUsrPrf qui doit être à *OWNER pour fonctionner
Une petite requête pour analyser une bibliothèque :
// liste des programmes avec les users d’exécution d’une bibliothèque
SELECT A.PROGRAM_SCHEMA,
a.PROGRAM_NAME,
a.PROGRAM_TYPE,
IFNULL(a.NAMING, ‘*NOSQL’) AS convention,
a.PROGRAM_OWNER,
b.user_profile AS user_program,
IFNULL(A.USER_PROFILE, ‘*NOSQL’) AS user_static,
IFNULL(A.DYNAMIC_USER_PROFILE, ‘*NOSQL’) AS usre_dynamic
FROM qsys2.sysprogramstat a
JOIN QSYS2.PROGRAM_INFO b
ON a.PROGRAM_SCHEMA = b.Program_library
AND a.PROGRAM_NAME = b.PROGRAM_NAME
where A.PROGRAM_SCHEMA = ‘votre bib’;
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-20 10:45:092025-08-26 17:59:35Détail sur l’adoption de droits sur les programmes
Vous voulez changer le groupe d’activation d’un programme. Contrairement à une idée reçue, on peut dans certains cas renommer le groupe d’activation d’un programme ILE
Si vous créez un programme
CRTPGM
Ou
CRTBNDRPG
Vous allez indiquer le groupe d’activation d’exécution de votre programme
Vous ne pouvez pas changer le groupe d’activation par CHGPGM !
Mais vous pouvez le faire par la commande UPDPGM
avant ==> DSPPGM AATSTRET
Attribut du groupe d’activation . . . . . . . : PLB1
UPDPGM PGM(AATSTRET) MODULE(*NONE) ACTGRP(PLB45)
Valeurs des paramètres AUT et USRPRF ignorées.
L’objet remplacé AATSTRET type *PGM a été déplacé dans QRPLOBJ.
Programme AATSTRET créé dans la bibliothèque GDATA.
Programme AATSTRET mis à jour dans GDATA.
après ==>DSPPGM AATSTRET
Attribut du groupe d’activation . . . . . . . : PLB45
la seule limitation est que le groupe doit être nommé
Pour interdir ce changement à l’assemblage vous devez indiquer
CRTPGM … ALWUPD(*NO)
PS :
Cette option n’existe pas sur le CRTBNDRPG donc modifiable par défaut
Vous devez avoir le droit *change sur programme.
Rappel:
En batch on essaye d’avoir le premier programme qui crée le groupe d’activation et les programmes appelés s’exécuteront en *caller
Dans les autres cas, webservice, interactif, etc il peut être préférable d’avoir un groupe d’activation par programme
Pour analyser les groupes actifs, vous pouvez utiliser le service : QSYS2.ACTIVATION_GROUP_INFO
— Liste des groupes par Travail
SELECT A.JOB_NAME,
count(*)
FROM TABLE (
QSYS2.ACTIVE_JOB_INFO()
) AS A
LEFT JOIN TABLE (
QSYS2.ACTIVATION_GROUP_INFO(JOB_NAME => A.JOB_NAME)
) AS G
ON 1 = 1
group by A.JOB_NAME
ORDER BY count(*) desc
;
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-13 11:29:572025-08-19 13:54:43Changer le groupe d’activation d’un programme
En bons élèves, nous profitons de l’été pour faire nos devoirs de vacances. Entre autre, installation de la version 7.6 sur plusieurs de nos partitions.
D’abord une partition de test, bac à sable, puis nos partitions de production i(vous avez peut être vu une interruption de service sur nos sites web).
J’en profite pour faire un petit retour d’expérience sur ces installations.
Et pour finir ce préambule, je remercie l’équipe du support !
Une mise à jour comme les autres ?
Oui, je ne détaille pas ici le processus de mise à jour, c’est classique : téléchargement des images et clés sur ESS, PRUV pour les contrôle etc …
Quelques points d’attention
DST/SST
Le mot de passe de QSECOFR ne doit pas être celui par défaut (sinon il sera inutilisable)
Les profils 11111111 et 22222222 sont supprimés pendant l’installation
Bonne pratique : créer au moins un autre profil avec tous les droits pour DST, changer le mot de passe de QSECOFR. Les profils 11111111 et 22222222 ne devraient déjà plus être utilisés depuis longtemps
Java 11 64 bit non supporté
Anticiper les changement de configuration si vous l’utilisez
Impossible de saisir le mot de passe de QSECOFR au démarrage
Après l’installation de la 7.6 sur la partition, et fort satisfait, je tentes de me loguer avec QSECOFR : informations d’authentification incorrectes !
Après vérification dans mon gestionnaire de mots de passe, nouvelle tentative : idem.
A la 3ème, profil désactivé …
Heureusement, j’ai toujours un profil clone de QSECOFR pour remédier à ces situations : je change le mot de passe de QSECOFR, et là cela fonctionne !
Bonne pratique : changer le mot de passe de QSECOFR avant la migration pour un mot de passe simple (quitte à déroger aux règles le temps de l’installation).
Problème de connexion sur tous les serveurs hôtes en TLS
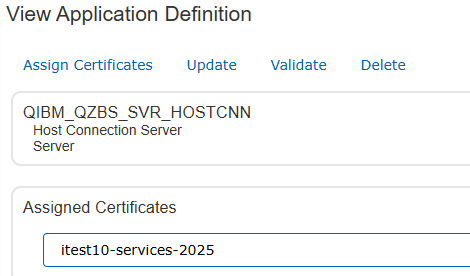
Après installation de la 7.6, impossible de se connecter en telnet sécurisé, ni aux autres services
Dans DCM, allez dans le magasin *SYSTEM, puis gérer « Manage Applications Definitions », sélectionner l’application QIBM_QZBS_SVR_HOSTCNN et associez un certificat (en général le même pour l’ensemble des serveurs hôtes) :
Dès validation la connexion TLS fonctionne, pas besoin d’arrêter/redémarrer des services.
Ce fonctionnement est nécessaire pour la mise en œuvre du MFA, mais impact les services existants.
Tous les systèmes étant sécurisés depuis de nombreuses années, vous devriez être impacté …
En synthèse
A noter que l’ensemble des éléments est bien documenté, y compris les « détails » qui nous ont posés quelques soucis (exception du mot de passe non reconnu).
Une bonne préparation permet de réaliser une migration maitrisée, l’installation elle-même se déroule très bien et rapidement.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-08-05 09:55:002025-07-30 17:59:29Retour d’expérience installation IBM i 7.6
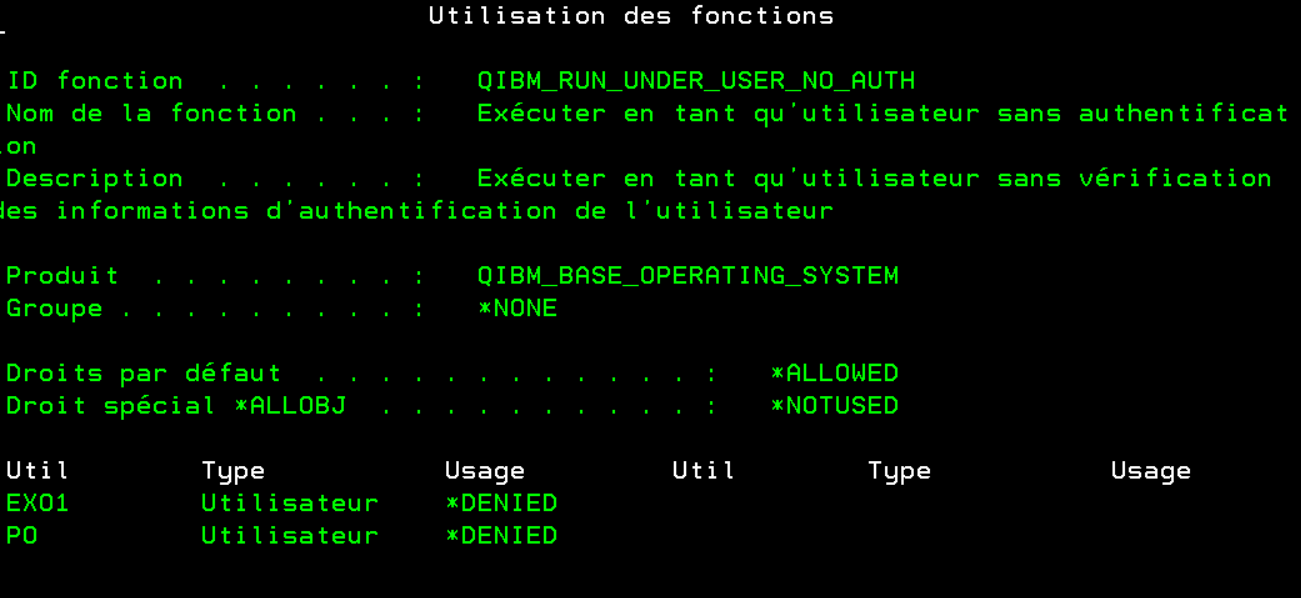
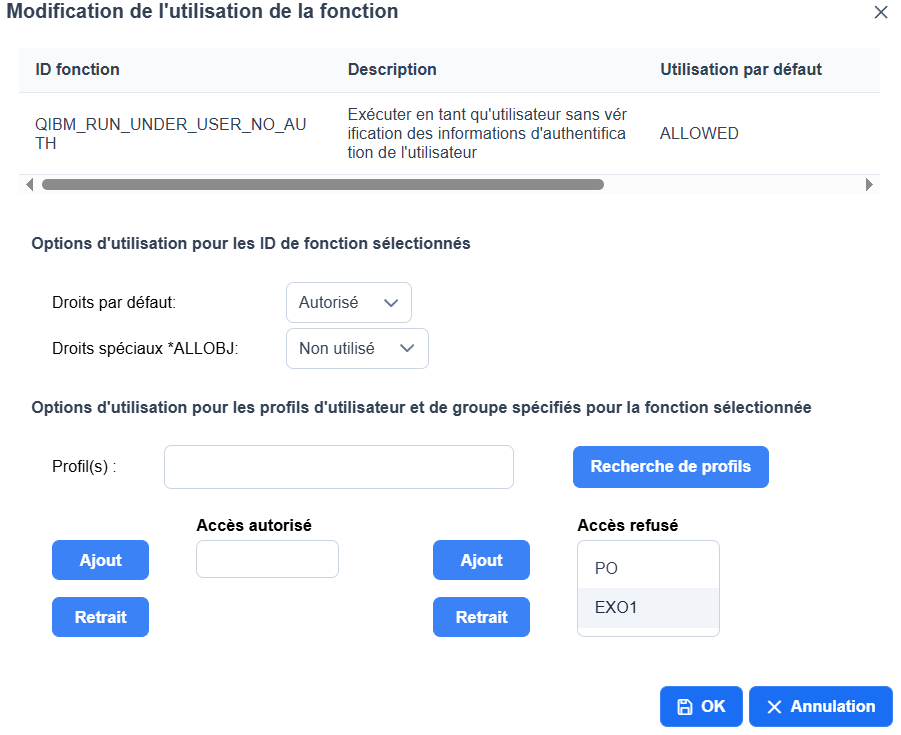
Avec la version V7R6, une nouvelle fonction usage est disponible, elle sert à éviter les soumissions pour un autre profil, paramétre USER( ) dans un SBMJOB,
Même si vous êtes autorisé au profil, vous ne pourrez pas soumettre pour lui
exemple :
Avant
Paramétrage
Sous navigator for i
Après
Conclusions :
Sur certains profils sensibles vous pouvez interdire leurs usage dans un SBMJOB , même pour des utilisateurs *ALLOBJ par exemple
Grand merci à Nathanael pour la mise à disposition de cette V7R6