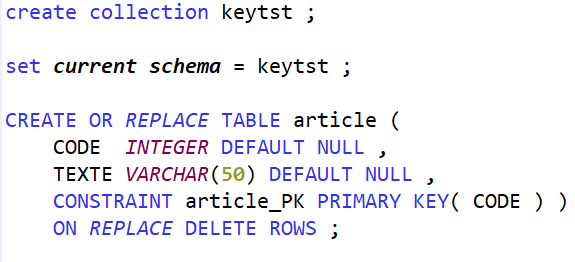
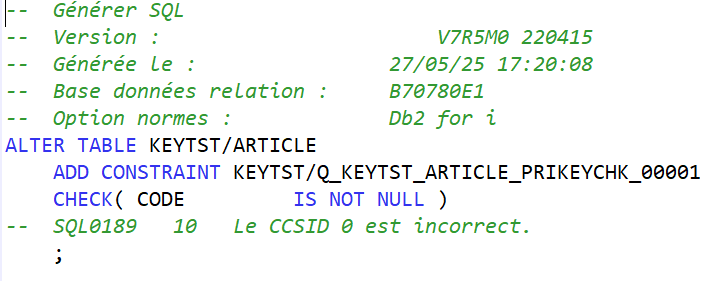
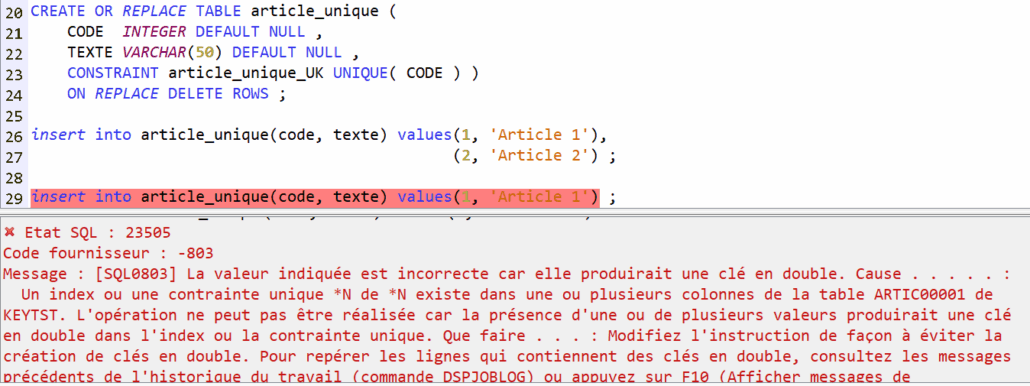
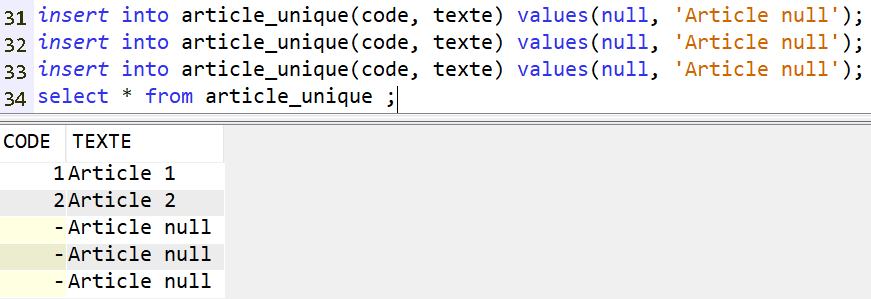
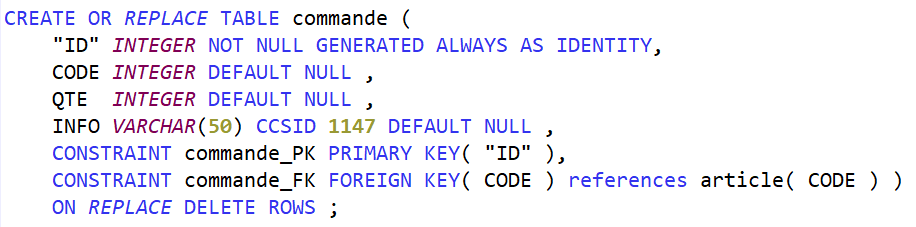
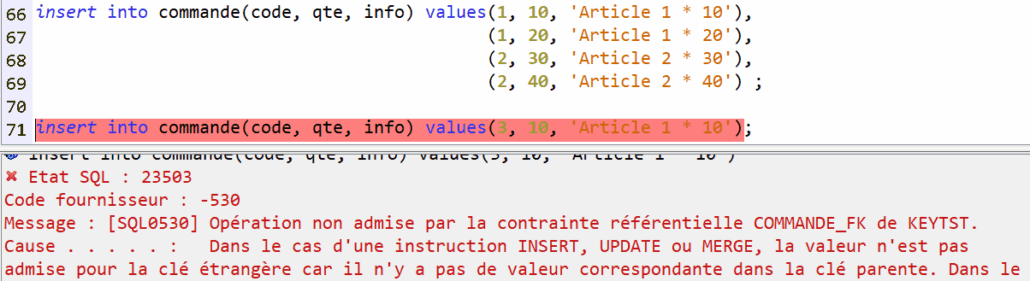
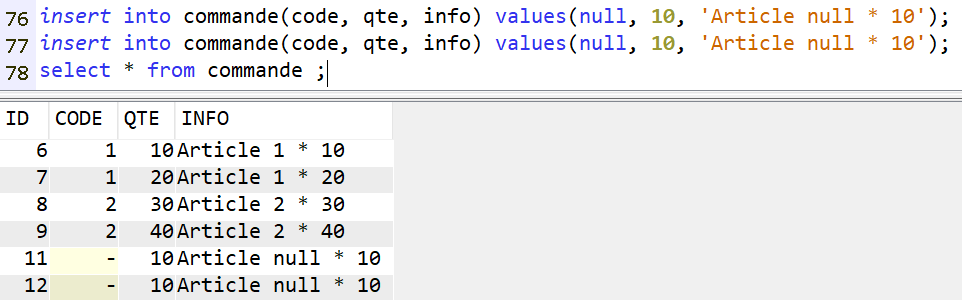
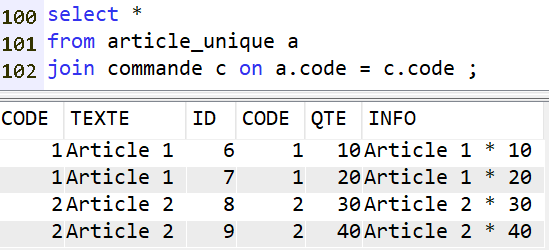
Access Client Solutions 1.1.9.8, disponible depuis avril 2025, amène son lot d’évolutions. Une m’a particulièrement intéressée : l’affichage des index considérés.
Visual Explain, les index ?
Visual Explain permet d’afficher le plan d’exécution de la requête SQL : l’ensemble des étapes nécessaires à l’obtention du résultat, de la façon la plus optimisée possible.
Pour déterminer la façon la plus optimisée, le moteur SQL va réécrire la requête, considérer les index/LF existants, exploiter les statistiques de chaque table, index ou clé sous-jacents aux tables utilisées dans la requête.
Dans le plan affiché, pour une première analyse macroscopique, on cherche en général les éléments suivants :
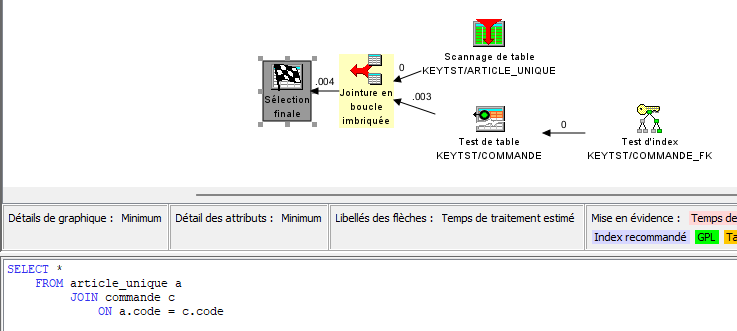
- Scan de table : on préfère utiliser des accès par index plutôt que parcourir l’ensemble de la table. Il s’agit d’analyser pourquoi aucun index ne satisfait les conditions de la requête
- Les index utilisés : même si l’on se félicite de l’utilisation d’index, il est souvent possible de faire mieux
- Les index recommandés : justement pour faire mieux !
Une information est disponible mais difficilement exploitable : l’optimiseur explique pour chaque index trouvé pourquoi il a été utilisé, ou pourquoi il ne l’a pas été.
Un exemple
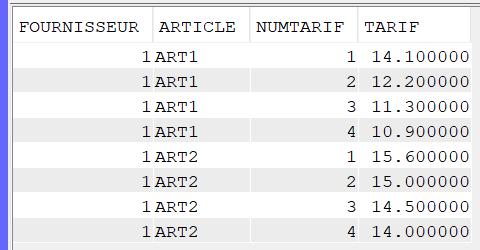
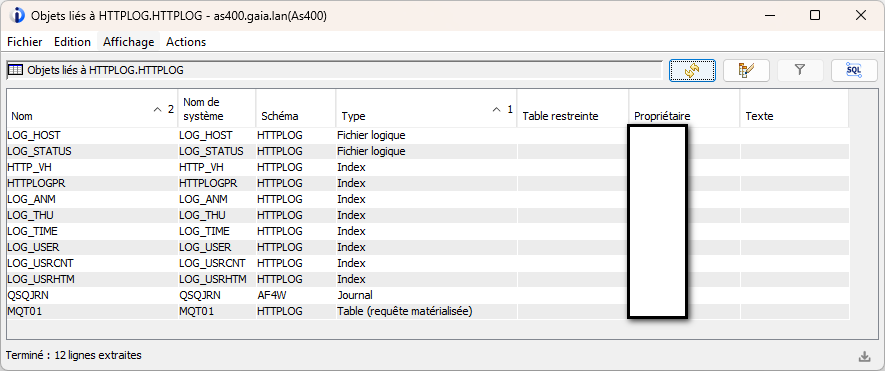
Nous avons une table dans laquelle nous consolidons certains événements logués par nos serveurs web (access_log générés par Apache). Aujourd’hui cette table HTTPLOG contient environ 240 millions d’entrées, et dispose bien évidemment d’un certains nombres d’index existants :
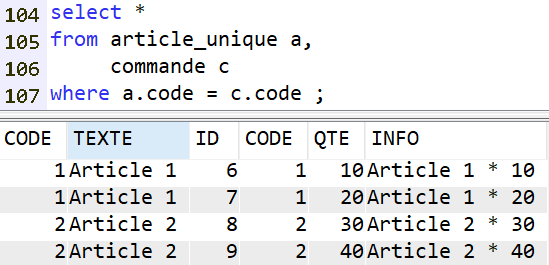
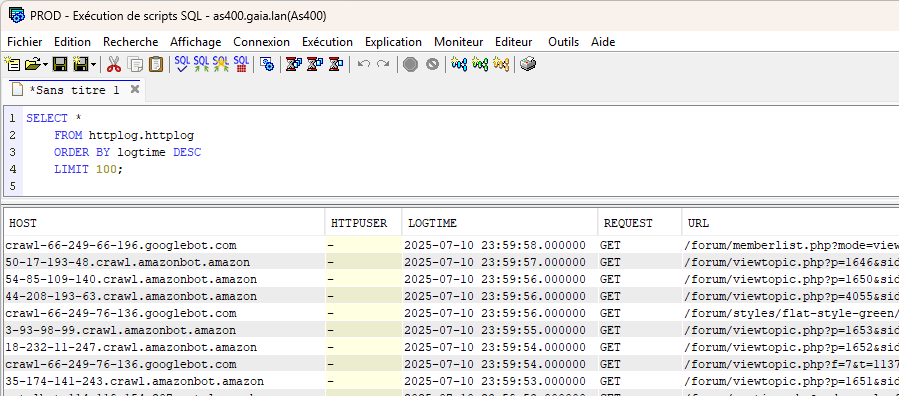
Prenons une requête basique :
L’affichage de Visual Explain nous montre :
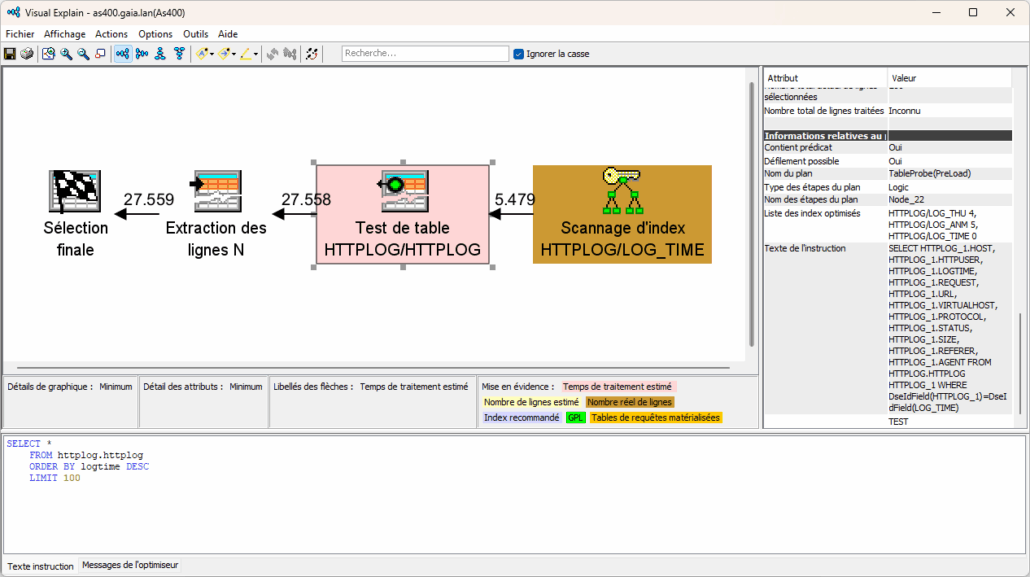
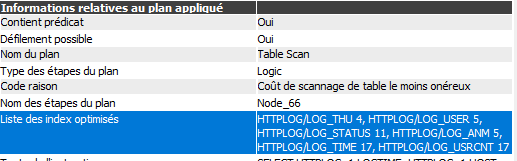
En sélectionnant l’étape « Test de table », le volet de droite indique :
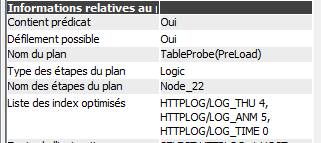
Ce sont la liste des index que l’optimiseur a regardé et le chiffre correspond au code qui indique pourquoi il n’a pas été utilisé. Il est possible d’aller chercher le détail des codes dans les messages (il faut activer les messages de débogage).
Cette information est accessible pour chaque étape du plan, dans le cas de jointure ou de sous-requête.
Index considérés
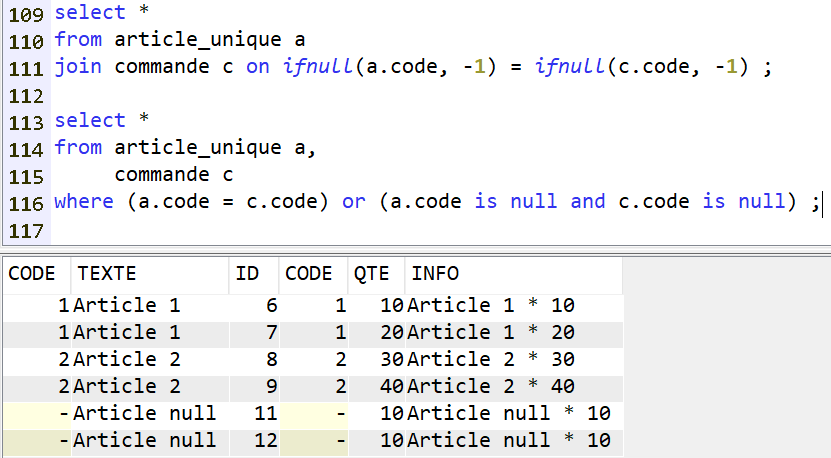
Prenons une autre requête SQL permettant d’analyser toutes les requêtes HTTP authentifiées et dont le retour provoque un warning ou une erreur (autre que code HTTP 200 OK).
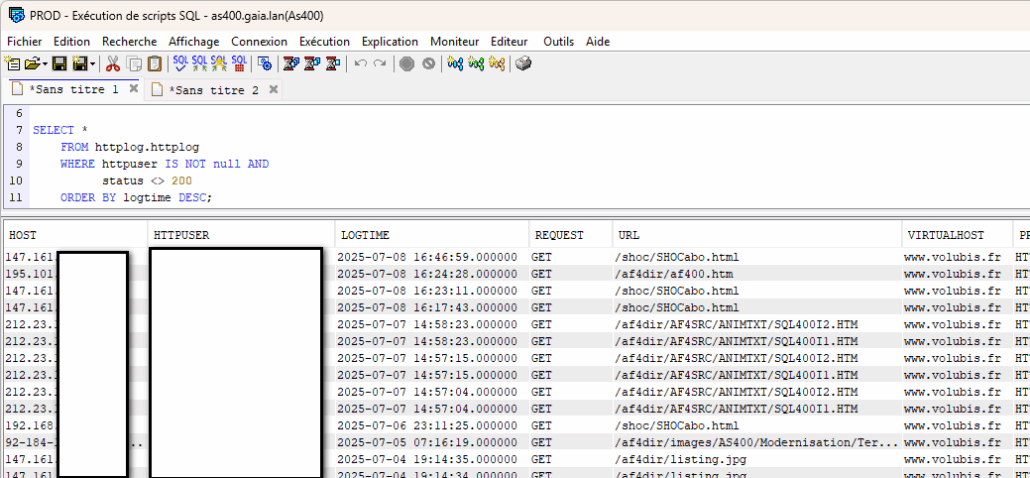
Visual Explain nous donne :
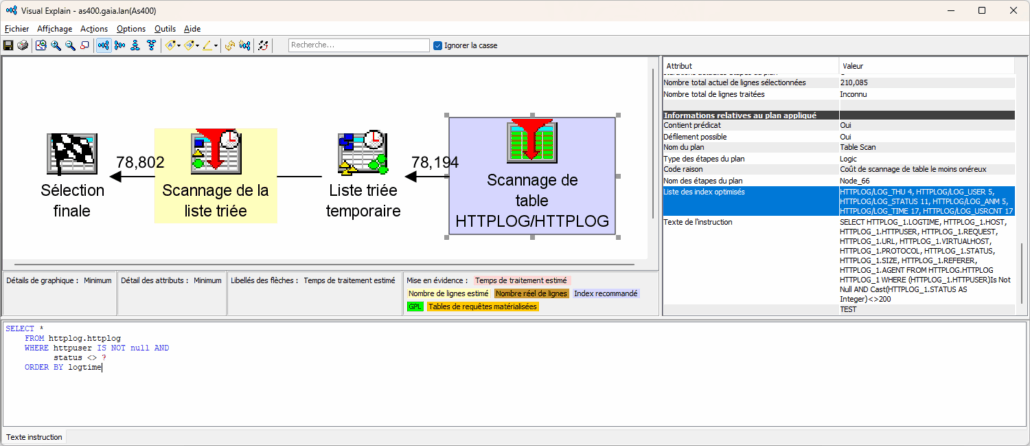
Nous retrouvons bien entendu nos informations sur les index :
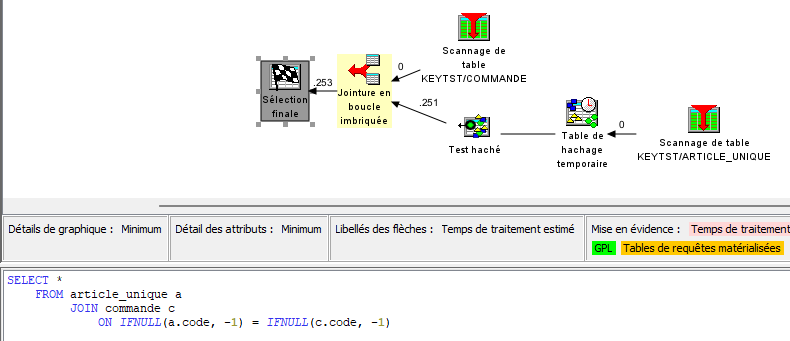
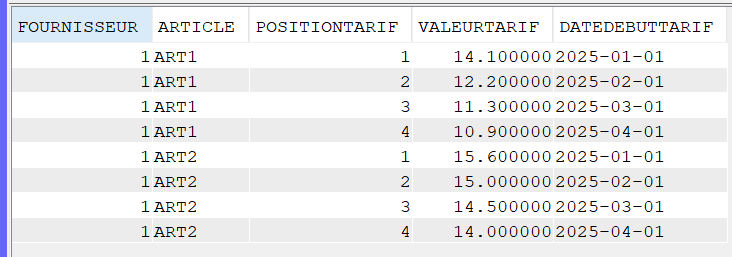
Mais il est maintenant possible de demander ces informations pour l’ensemble de la requête :
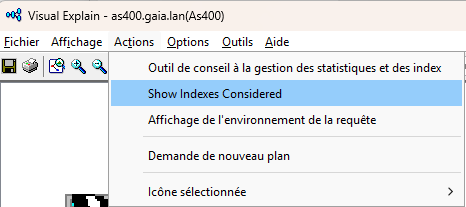
Et d’obtenir des libellés plus parlants :
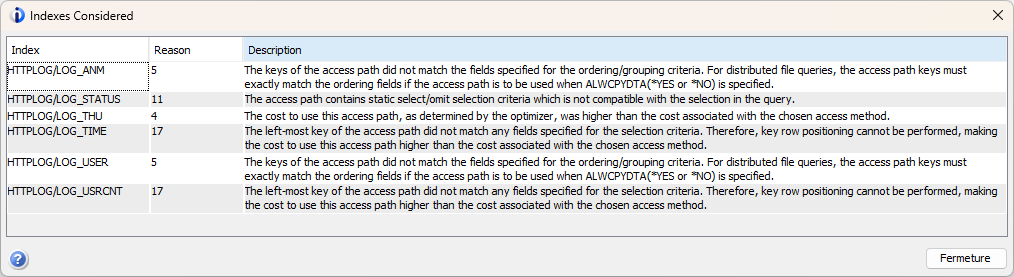
Cela vous donne plus d’informations quant à l’usage des index. Pour compléter, l’index advisor nous donne :
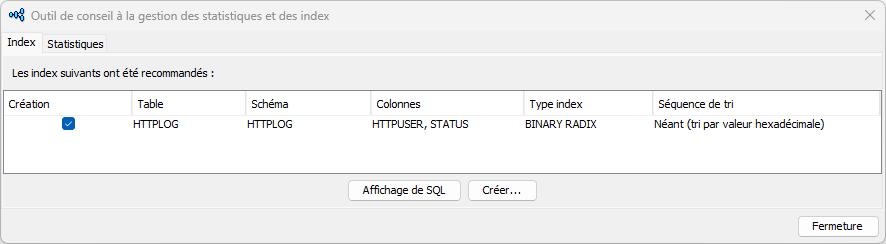
A noter que l’optimiseur ne propose pas d’index dérivé par exemple, ou difficilement les index EVI … Gardez donc un œil critique sur ces informations, mais leur compréhension est nécessaire.