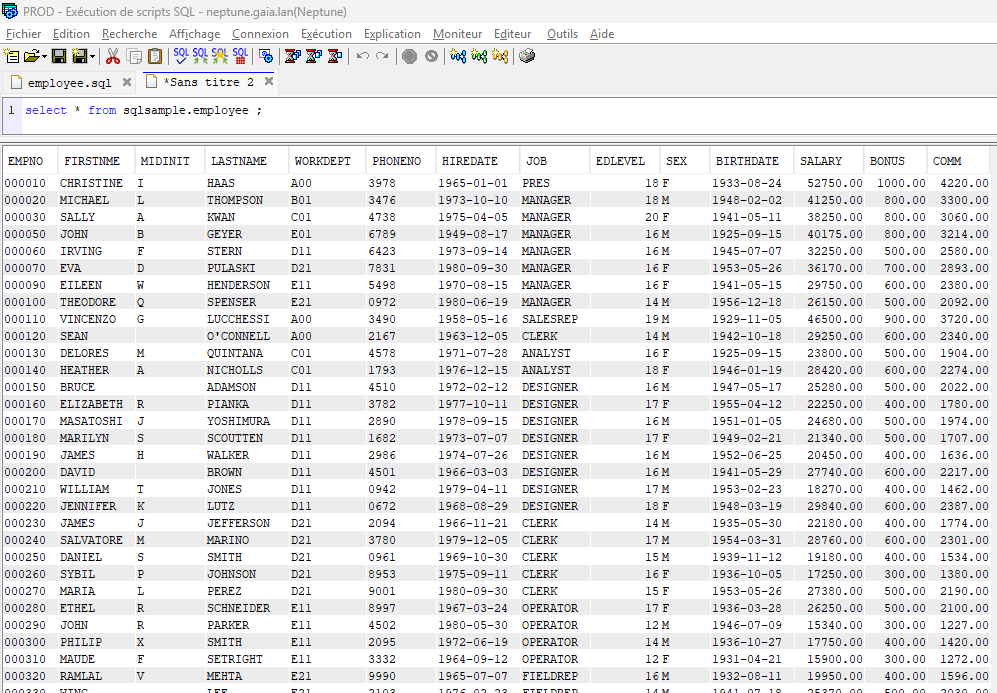
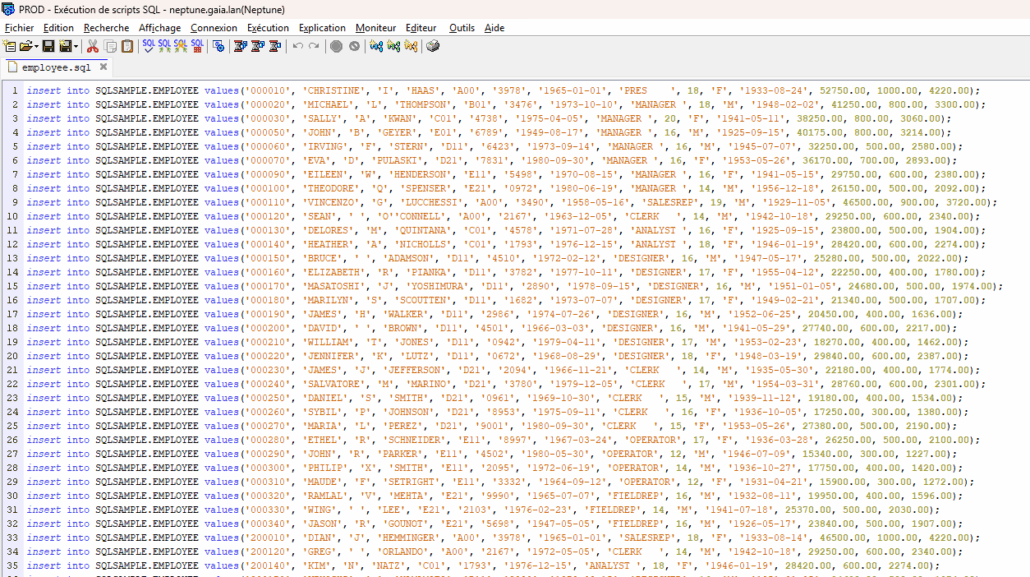
Suite à des demandes multiples, je propose une implémentation de « DUMP » des enregistrements d’une table (plutôt d’un objet *FILE / PF-DTA, que ce soit un PF ou une table).
L’idée est d’obtenir u script SQL contenant les instructions INSERT permettant de reproduire les données dans une autre base.
Premièrement, la réplication de données sans utiliser les commandes de sauvegarde/restauration. Ces dernières nécessitent des droits élevés, alors qu’ici nous ne faisons que manipuler de la donnée.
Deuxièmement, dans le cadre de traitement de journaux (initialement en vue d’une fonction de type CDC), pour permettre d’isoler un enregistrement que l’on souhaite répliquer (avec ou sans transformation) dans une autre table.
Vous trouverez certainement d’autres usages !
Limites
Le code est fourni « as is », pour démonstration.
Quelques limites d’usage actuellement
Types de colonnes non supportées actuellement : CLOB, BLOB, DATALINK, XML, GRAPHIC, VARGRAPHIC, {VAR}CHAR CCSID 65535
Pas plus de 16Mo par enregistrement
On ne gère pas les alias, partitions, IASP
250 colonnes maximum
En cas de multi-membres, seul le premier membre est traité
On peut bien évidemment ajouter de nouvelles fonctionnalités !
N’hésitez pas à donner un feedback, améliorer le code
Dans une base de données bien définie, nos enregistrements sont identifiés par des clés (ie unique). Il existe toutefois différentes façon de matérialiser ces clés en SQL.
Première bonne résolution : on ne parlera pas ici des DDS (PF/LF) !
Quelques rappels
je n’insiste pas, mais une base de donnée relationnelle, DB2 for i dans notre cas, fonctionne à la perfection, à condition de pouvoir identifier nos enregistrements par des clés.
Une normalisation raisonnable pour une application de gestion est la forme normale de Boyce-Codd (dérivée de la 3ème FN).
Clés
Vous pouvez implémenter vos clés de différentes façons, voici une synthèse :
Type
Où
Support valeur nulle ?
Support doublon ?
Commentaire
Contrainte de clé primaire
Table
Non
Non
Valeur nulle non admise, même si la colonne clé le supporte
Contrainte d’unicité
Table
Oui
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Index unique
Index
Oui
Non
Gère des clés uniques. La valeur NULL est supportée pour 1 unique occurrence
Index unique where not null
Index
Ouis
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Attention donc à la définition de UNIQUE : à priori ce qui n’est pas NULL est UNIQUE.
Concrètement ?
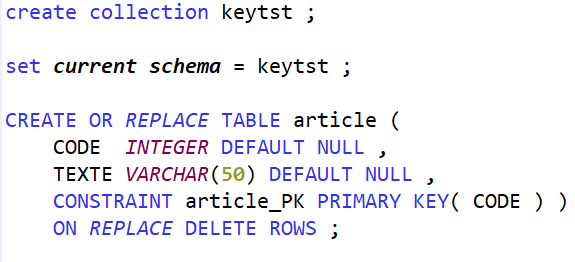
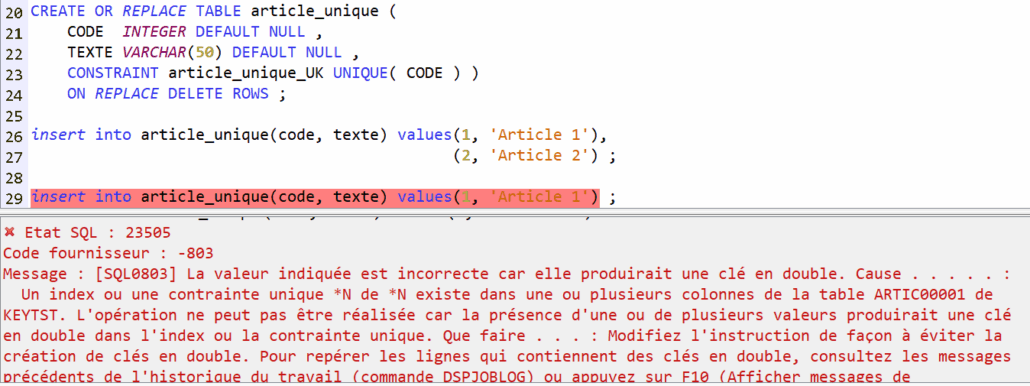
Prenons un cas de test simpliste pour montrer la mécanique : un fichier article avec une clé et un libellé
Clé primaire
La colonne CODE admet des valeurs nulles, mais est fait l’objet de la contrainte de clé primaire.
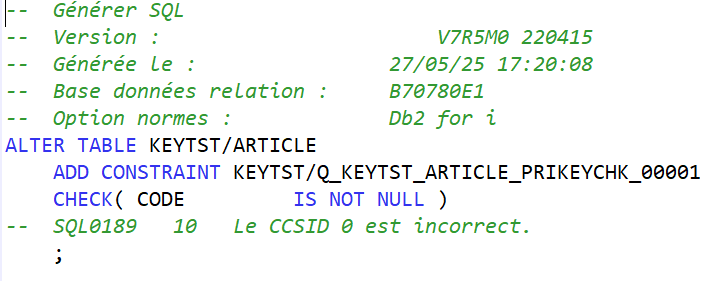
A la création de la contrainte de clé primaire, le système créé automatiquement une contrainte de type CHECK pour interdire l’utilisation de valeur nulle dans cette colonne :
Avec :
La clé primaire joue son rôle avec des valeurs non nulles :
Et des valeurs nulles :
On retrouve ici le nom de la contrainte générée automatiquement !
Avec une contrainte de clé unique ?
Le comportement est identique sur une clé non nulle.
Mais avec une clé nulle (ou dont une partie est nulle si elle composée) :
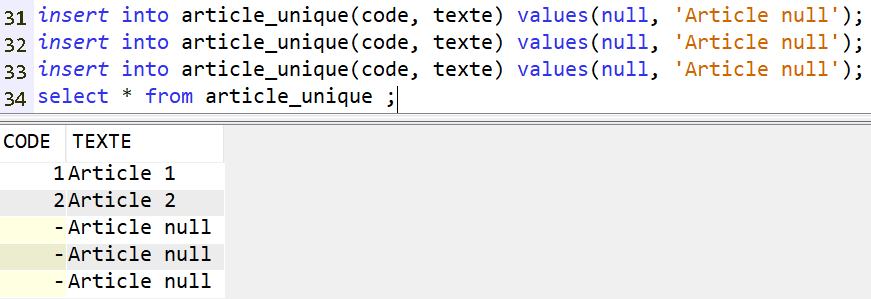
On peut ajouter un index unique pour gérer le problème. Dans ce cas, une et une seule valeur nulle sera acceptée :
Mais dans ce cas pourquoi ne pas utiliser une clé primaire ??
Clé étrangère, jointure
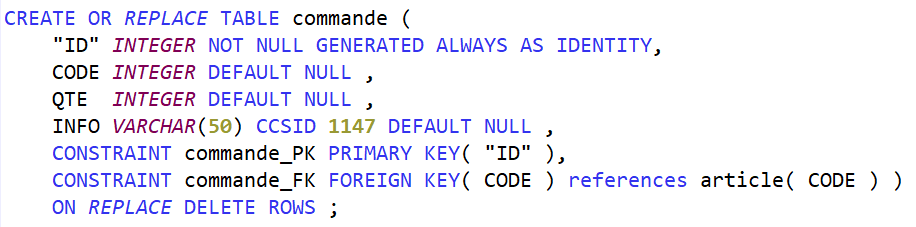
Ajoutons un fichier des commandes, ici une simplification extrême : 1 commande = 1 article.
On ajoute une contrainte de clé étrangère qui matérialise la relation entre les tables commande et article. Pour cette contrainte commande_FK, il doit exister une contrainte de clé primaire ou de clé unique sur la colonne CODE dans la table article.
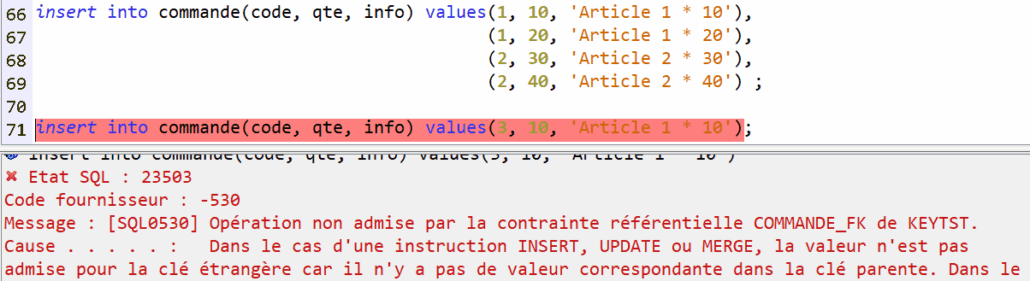
La contrainte se déclenche si l’article référencé n’existe pas :
Cas identique mais en s’appuyant sur la table article_unique qui dispose d’une clé unique et non primaire :
Dans ce cas les valeurs nulles sont supportées, en multiples occurrences (sauf à ajouter encore une fois un index unique au niveau de la commande).
Récapitulons ici nos données pour comprendre les jointures :
Démarrons par ARTICLE & COMMANDE :
La table ARTICLE ne peut pas avoir de clé nulle, donc pas d’ambiguïté ici
Avec right join ou full outer join nous accèderons au lignes de commande pour lesquelles CODE = null.
C’est le comportement attendu.
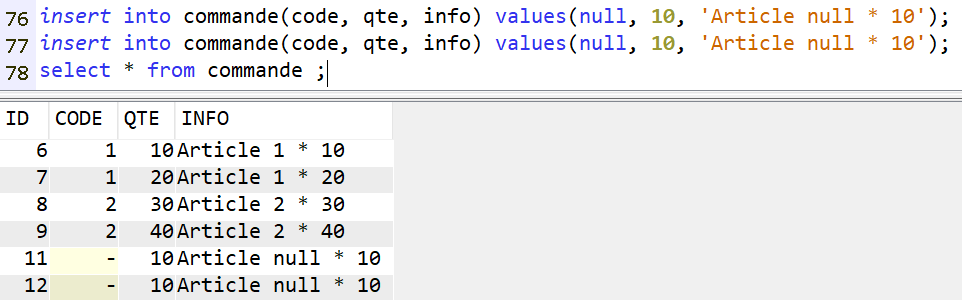
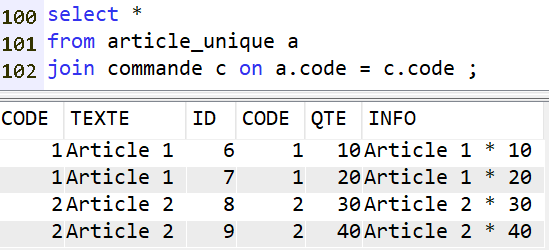
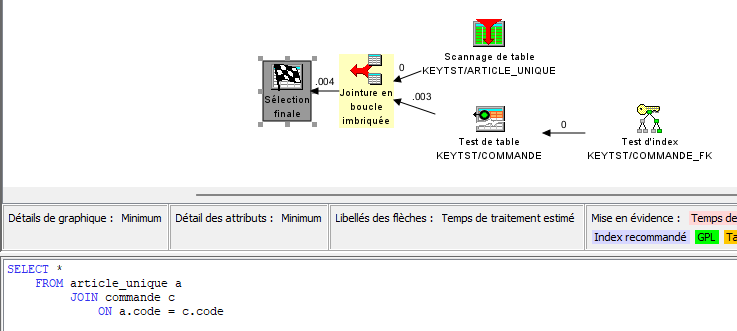
Voyons avec ARTICLE_UNIQUE et COMMANDE :
Ici on pourrait s’attendre à obtenir également les lignes 11 et 12 de la table COMMANDE : le CODE est nulle pour celles-ci, mais il existe une ligne d’ARTICLE pour laquelle le code est null. Il devrait donc y avoir égalité.
En réalité les jointures ne fonctionnent qu’avec des valeurs non nulles
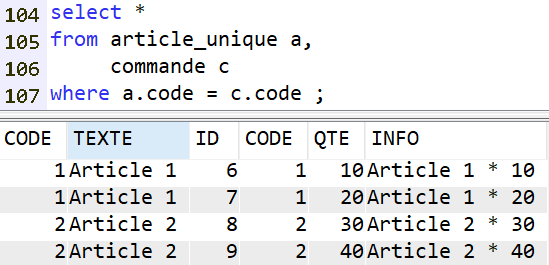
De même que la clause WHERE :
Il faut donc utiliser ce style de syntaxe :
C’est à dire :
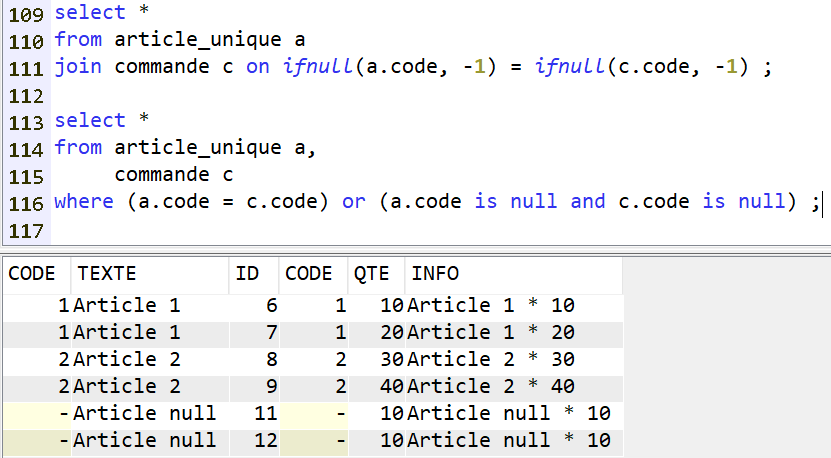
soit remplacer les valeurs nulles par des valeurs inexistantes dans les données réelles
soit explicitement indiquer la condition de nullité conjointe
Bref, syntaxiquement cela va rapidement se complexifier dans des requêtes plus évoluées.
Clé composée
Evidemment, c’est pire ! Imaginons que l’on ait une clé primaire/unique dans la table ARTICLE composée de 2 colonnes (CODE1, CODE2), et donc présentes toutes les deux dans la table COMMANDE :
Et les performances ?
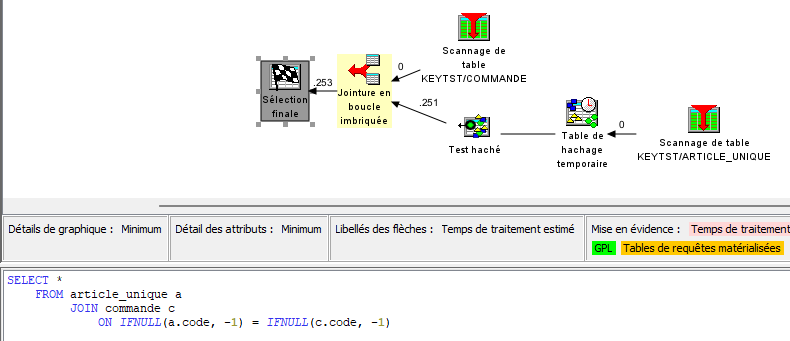
En utilisant la jointure, l’optimiseur est capable de prendre en charge des accès par index :
Mais en utilisant IFNULL/COALESCE, ces valeurs deviennent des valeurs calculées, ce qui invalide l’usage des index :
Ce n’est donc pas viable sur des volumes plus importants. Il existe des solutions (index dérivés par exemple) mais la mécanique se complique encore !
Préconisations
De façon générale pour vos données de gestion, en excluant les fichier de travail (QTEMP a d’autres propriétés), les fichiers de logs, les fichier d’import/export …
Pas de valeur NULL dans vos clés
Pour les clés atomique c’est une évidence, pour les clés composées c’est beaucoup plus simple
Une contrainte de clé primaire pour toutes vos tables !
N’hésitez pas à utiliser des clés auto-incrémentées
Des contraintes d’unicités ou des index uniques pour vos autres contraintes d’unicité, techniques ou fonctionnelles
Pas d’excès, sinon il y a un défaut de conception (cf les formes normales)
Si possible des contraintes de clé étrangère pour matérialiser les relations entre les tables
Délicat sur l’existant, les traitements doivent tenir compte du sens de la relation
Favorisez l’usage des clés, contraintes et index par l’optimiseur
Scalabilité entre vos environnements de développement/test et la production
Cela permet de revenir sur le principe de l’implémentation via du code RPG :
Le code est basé sur les APIs QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
Le moteur DB2 appelle l’implémentation :
1 appel initial
1 appel par poste de liste à retourner
1 appel final
Nous utilisons __errno pour retrouver les codes erreur de l’APIs. Les différentes valeurs sont déclarées sous forme de constante.
La fonction SQL retourne les SQL STATE suivants :
02000 lorsque l’on attend la fin des données (fin normale)
38999 pour les erreurs. Cette valeur est arbitraire
Si possible, nous retrouvons le libellé de l’erreur retournée par l’API via strerror et on le retourne à DB2.
Code RPG :
**free
// Compilation / liage :
// CRTRPGMOD MODULE(NB/VLDLUDTF) SRCFILE(NB/QRPGLESRC)
// OPTION(*EVENTF) DBGVIEW(*SOURCE)
// CRTSRVPGM SRVPGM(NB/VLDLUDTF) EXPORT(*ALL) ACTGRP(*CALLER)
// Implémentation de la fonction UDTF VALIDATION_LIST_ENTRIES
// Liste les entrées d'une liste de validation
// Utilise l'API QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
// @todo :
// - ajouter le support de la conversion de CCSID
// - améliorer la gestion des erreurs
ctl-opt nomain option(*srcstmt : *nodebugio) ;
// Déclarations pour APIs : QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
dcl-ds Qsy_Qual_Name_T qualified template ;
name char(10) inz ;
lib char(10) inz ;
end-ds ;
dcl-ds Qsy_Entry_ID_Info_T qualified template ;
Entry_ID_Len int(10) inz ;
Entry_ID_CCSID uns(10) inz ;
Entry_ID char(100) inz ;
end-ds ;
dcl-ds Qsy_Rtn_Vld_Lst_Ent_T qualified template ;
dcl-ds Entry_ID_Info likeds( Qsy_Entry_ID_Info_T) inz ;
dcl-ds Encr_Data_Info ;
Encr_Data_len int(10) inz;
Encr_Data_CCSID uns(10) inz;
Encr_Data char(600) inz ;
end-ds ;
dcl-ds Entry_Data_Info ;
Entry_Data_len int(10) ;
Entry_Data_CCSID uns(10) ;
Entry_Data char(1000) ;
end-ds ;
Reserved char(4) inz ;
Entry_More_Info char(100) inz ;
end-ds ;
dcl-pr QsyFindFirstValidationLstEntry int(10) extproc('QsyFindFirstValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
dcl-pr QsyFindNextValidationLstEntry int(10) extproc('QsyFindNextValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
entryIdInfo likeds(Qsy_Entry_ID_Info_T) ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
// Retrouver le code erreur de l'API
dcl-pr getErrNo int(10) ;
end-pr ;
// Code erreur
dcl-c EACCES 3401 ;
dcl-c EAGAIN 3406 ;
dcl-c EDAMAGE 3484 ;
dcl-c EINVAL 3021 ;
dcl-c ENOENT 3025 ;
dcl-c ENOREC 3026 ;
dcl-c EUNKNOWN 3474 ;
// Retrouver le libellé du code erreur
dcl-pr strError pointer extproc(*CWIDEN : 'strerror') ;
errNo int(10) value ;
end-pr ;
// gestion UDTF
dcl-c CALL_OPEN -1;
dcl-c CALL_FETCH 0;
dcl-c CALL_CLOSE 1;
dcl-c PARM_NULL -1;
dcl-c PARM_NOTNULL 0;
// Liste les entrées de la liste de validation
// ==========================================================================
dcl-proc vldl_list export ;
// Déclarations globales
dcl-s ret int(10) inz ;
dcl-s errno int(10) inz ;
dcl-ds vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) inz static ;
dcl-ds vldlname likeds(Qsy_Qual_Name_T) inz static ;
dcl-s first ind inz(*on) static ;
dcl-pi *n ;
// input parms
pvldl_lib varchar(10) const ;
pvldl_name varchar(10) const ;
// output columns
pEntry_ID varchar(100) ;
pEntry_Data varchar(1000) ;
// null indicators
pvldl_lib_n int(5) const ;
pvldl_name_n int(5) const ;
pEntry_ID_n int(5) ;
pEntry_Data_n int(5) ;
// db2sql
pstate char(5);
pFunction varchar(517) const;
pSpecific varchar(128) const;
perrorMsg varchar(1000);
pCallType int(10) const;
end-pi ;
// Paramètres en entrée
if pvldl_name_n = PARM_NULL or pvldl_lib_n = PARM_NULL;
pstate = '38999' ;
perrorMsg = 'VALIDATION_LIST_LIBRARY ou VALIDATION_LIST_NAME est null' ;
return ;
endif ;
select;
when ( pCallType = CALL_OPEN );
// appel initial : initialisation des variables statiques
vldlname.name = pvldl_name ;
vldlname.Lib = pvldl_lib ;
clear vldListEntry ;
first = *on ;
when ( pCallType = CALL_FETCH );
// retrouver l'entrée suivante
exsr doFetch ;
when ( pCallType = CALL_CLOSE );
// rien à faire
endsl;
// traitement de l'entrée suivante
begsr doFetch ;
if first ;
ret = QsyFindFirstValidationLstEntry( vldlname : vldListEntry);
first = *off ;
else ;
ret = QsyFindNextValidationLstEntry( vldlname :
vldListEntry.Entry_ID_Info : vldListEntry);
endif ;
if ret = 0 ;
// Entrée trouvée
monitor ;
pEntry_ID = %left(vldListEntry.Entry_ID_Info.Entry_ID :
vldListEntry.Entry_ID_Info.Entry_ID_Len);
pEntry_Data = %left(vldListEntry.Entry_Data_Info.Entry_Data :
vldListEntry.Entry_Data_Info.Entry_Data_len) ;
pEntry_ID_n = PARM_NOTNULL ;
pEntry_Data_n = PARM_NOTNULL ;
on-error ;
// Erreur de conversion
pstate = '38999' ;
perrorMsg = 'Erreur de conversion' ;
endmon ;
else ;
// Entrée non trouvée : erreur ou fin de lecture
errno = getErrNo() ;
select ;
when errno in %list( ENOENT : ENOREC ) ; // fin de lecture
pstate = '02000' ;
return ;
other ; // Erreur
pstate = '38999' ;
perrorMsg = %str(strError(errno)) ;
endsl ;
endif ;
endsr ;
end-proc ;
// Retrouver le code erreur de l'API
dcl-proc getErrNo ;
dcl-pr getErrNoPtr pointer ExtProc('__errno') ;
end-pr ;
dcl-pi *n int(10) ;
end-pi;
dcl-s errNo int(10) based(errNoPtr) ;
errNoPtr = getErrNoPtr() ;
return errNo ;
end-proc;
Code SQL :
set current schema = NB ;
set path = 'NB' ;
Create or replace Function VALIDATION_LIST_ENTRIES (
VALIDATION_LIST_LIBRARY varchar(10),
VALIDATION_LIST_NAME varchar(10) )
Returns Table
(
VALIDATION_USER varchar(100),
ENTRY_DATA varchar(1000)
)
external name 'VLDLUDTF(VLDL_LIST)'
language rpgle
parameter style db2sql
no sql
not deterministic
disallow parallel;
cl: DLTVLDL VLDL(NB/DEMO) ;
cl: CRTVLDL VLDL(NB/DEMO) TEXT('Démo VALIDATION_LIST_ENTRIES') ;
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 1',
PASSWORD => 'MDP user 1',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 2',
PASSWORD => 'MDP user 2',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 3',
PASSWORD => 'MDP user 3',
ENTRY_DATA => 'Client 2'));
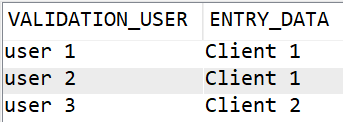
select * from table(VALIDATION_LIST_ENTRIES( VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO' )) ;
Cela produit :
Libre à vous maintenant d’utiliser ce résultat pour jointer avec vos fichiers de log HTTP (autorisation basique sur une liste de validation par exemple), avec le service USER_INFO_BASIC, croiser les profils présents dans vos différentes listes …
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-05-26 11:45:252025-05-26 11:45:26Gérer vos listes de validation avec SQL !
Retour sur une problématique récurrente et souvent mal comprise, donc mal gérée … Et qui pourrait bien s’amplifier avec l’usage plus intensif de l’Open Source.
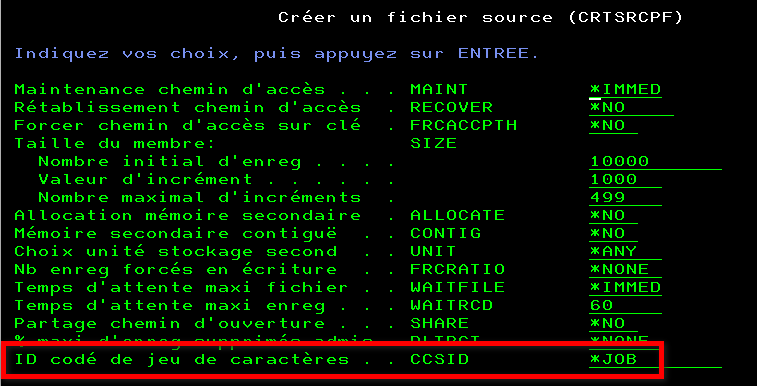
Vous utilisez historiquement des fichiers sources (objet *FILE attribut PF-SRC) pour stocker vos sources : ces fichiers sont créés avec un CCSID, par défaut le CCSID du job dans lequel vous exécutez la commande CRTSRCPF
Usuellement vous obtiendrez des fichiers sources avec un CCSID 297 ou 1147 pour la France. Si vos machines sont « incorrectement » réglées, un CCSID 65535 (hexadécimal).
Mais également, par restauration d’autres produits, certainement des fichiers avec un CCSID 37 (US).
Pour les langages de programmation (dont le SQL), le CCSID du fichier source est important pour les constantes, qui peuvent par définition êtres des caractères nationaux quelconques. Quant aux instructions, la grammaire des langages les définis sans ambiguïtés.
Caractères spéciaux / nationaux
Pour toutes les commandes, instructions, éléments du langage, pas de soucis d’interprétation
A la compilation, les constantes sont interprétées suivant le CCSID du job, pas celui du source !
En général, les deux CCSID sont identiques.
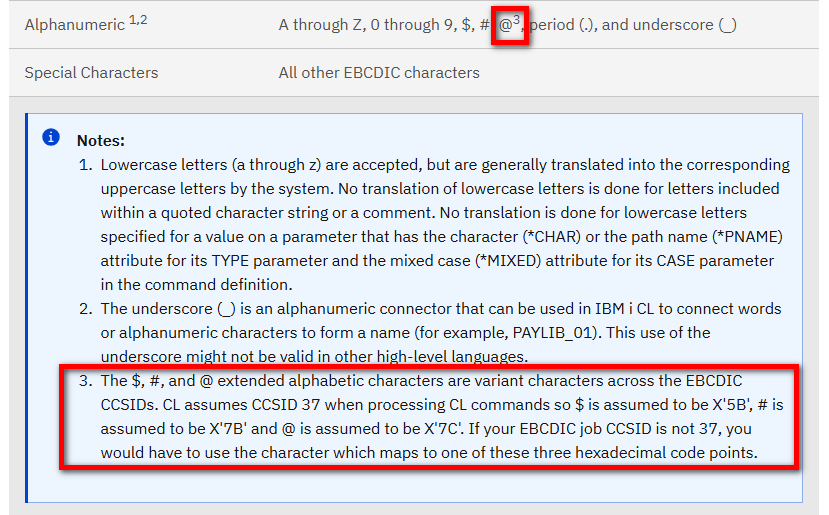
Par contre, pour les caractères spéciaux utilisés, si l’on regarde de plus près le cas du CL, la documentation indique :
Voilà qui explique les fameuses transformations de @ en à !
En synthèse : le compilateur considère tous les éléments du langage comme étant en CCSID 37, hors les constantes alphanumériques et les quelques caractères listés ici.
Pour le CL : impossible d’utiliser les opérateurs symboliques |> (*BCAT), |< (*TCAT) et || (*CAT)
Le caractère | est mal interprété. Vous devez le remplacer par un !, ou utiliser les opérateurs non symboliques (*BCAT, *TCAT et *CAT).
Pour le SQL : impossible d’utiliser l’opérateur || (même raison).
Vous devez le remplacer par un !!, ou utiliser l’opérateur concat.
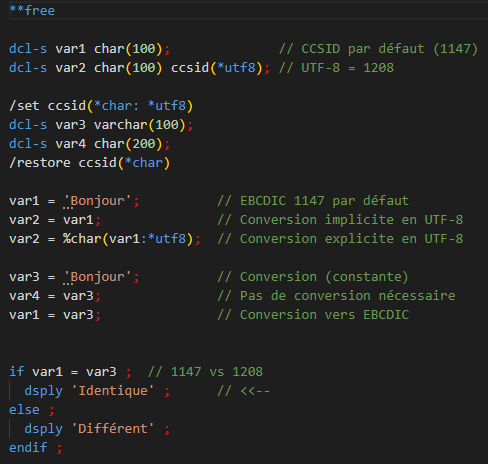
Evolution du RPG
Le principe est le même.
Toutefois le langage vous permet également de contrôler le CCSID des variables déclarées. Et depuis la 7.2, de nouvelles directives de pré-compilation permettent d’indiquer des valeurs de CCSID par défaut par bloc de source :
Et pour l’IFS ?
Sur l’IFS, chaque fichier (source ou non) dispose également d’un CCSID. Sa valeur dépend principalement de la façon de créer le fichier (par un éditeur type RDi/VSCode, partage netserver, transfert FTP …).
Premier point d’attention : l’encodage du contenu du fichier doit correspondre à son attribut *CCSID !
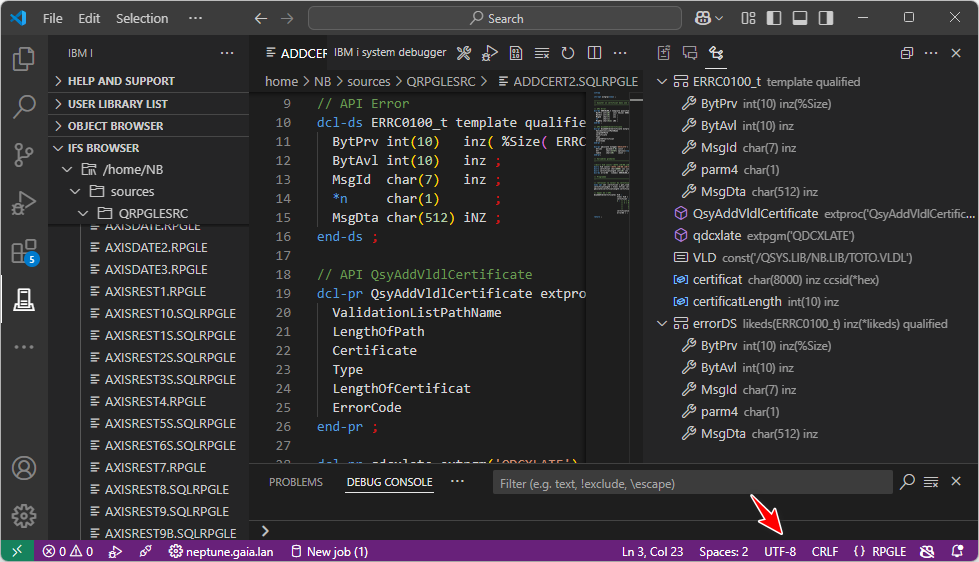
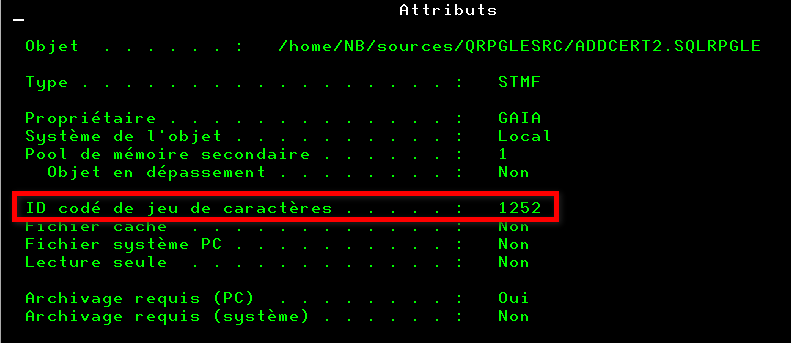
VSCode vous indique le CCSID de la donnée, par exemple :
Mais :
1252 = Windows occidental (proche de l’UTF-8 mais pas identique). La raison est que VSCode travaille naturellement en UTF-8.
RDi gère correctement l’encodage/décodage par rapport à la description du fichier.
Pour les autres outils, à voir au cas par cas !
Evolution des compilateurs
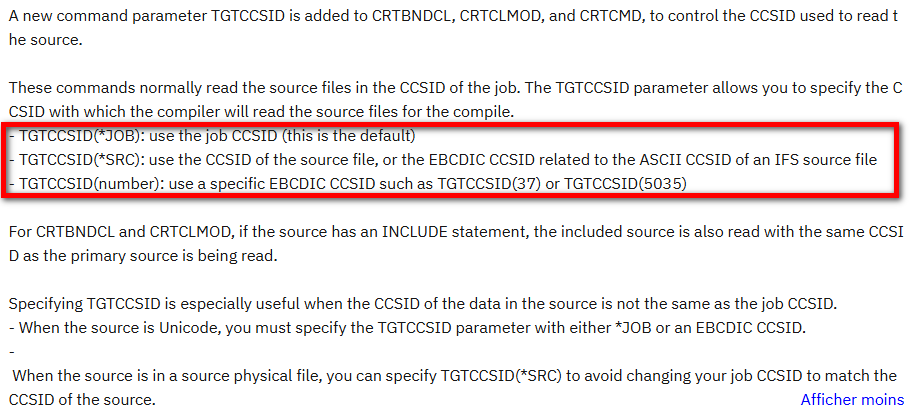
Les compilateurs C, CPP, CL, RPG, COBOL supportent désormais (PTF en fonction des compilateurs) un paramètre TGTCCSID :
En réalité ce paramètre a été ajouté pour permettre la compilation plus facilement depuis l’IFS, principalement depuis des fichiers IFS en UTF-8.
Cela ne règle pas nos problèmes précédents, les éléments du langage n’étant pas concernés : nous auront toujours le problème d’interprétation du |
Par contre, c’est utile pour la bonne interprétation des constantes lorsque le job de compilation a un CCSID du source. Et cela permet une meilleure intégration dans les outils d’automatisation.
Le script propose d’indiquer un CCSID pour les fichiers sources. Mais la seule solution viable est de compiler avec un job en CCSID 37 :
soit CHGJOB CCSID(37) avant de lancer le script
soit vous pouvez vous créer un profil dédié en CCSID 37 si ces opérations sont récurrentes
Tant que vous n’avez pas de caractères nationaux dans le codes !
Retrouver le CCSID de ses fichiers sources
SELECT f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA, c."CCSID" FROM qsys2.systables f JOIN qsys2.syscolumns c ON (c.SYSTEM_TABLE_NAME, c.SYSTEM_TABLE_SCHEMA) = (f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA) WHERE f.file_type = 'S' AND LEFT(f.system_table_name, 8) <> 'EVFTEMPF' AND c.SYSTEM_COLUMN_NAME = 'SRCDTA' ORDER BY c."CCSID", f.SYSTEM_TABLE_SCHEMA, f.SYSTEM_TABLE_NAME;
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2025-02-17 14:38:202025-02-17 14:44:48Gestion de l’état null dans les SQLRPGLE
Lorsque l’on doit tester l’existence d’un objet dans QSYS.LIB la question ne se pose pas, on utilise la commande prévue à cet effet CHKOBJ. Pour l’IFS par contre il n’y a pas de commande toute faite.
Voici donc trois exemples de solutions pour tester l’existence d’un fichier dans l’IFS en CL et en SQLRPGLE. (Il existe d’autres méthodes, mais celles-ci sont les plus simples).
CHKOUT / CHKIN (clle)
La commande CHKOUT permet de verrouiller un objet, ainsi les autres utilisateurs et travaux ne peuvent plus que le lire ou le copier. Il suffit de monitorer cette commande en attendant le message CPFA0A9 qui indique que le fichier n’existe pas.
Cette méthode est donc utile lorsque l’on souhaite par la même occasion verrouiller l’objet recherché.
Il ne faut pas oublier de déverrouiller l’objet une fois votre opération terminée avec la commande CHKIN.
PGM PARM(&FILEPATH)
DCL VAR(&FILEPATH) TYPE(*CHAR) LEN(256)
DCL VAR(&EXISTS) TYPE(*LGL)
CHGVAR VAR(&EXISTS) VALUE('1')
/* Verrouillage de l'objet */
CHKOUT OBJ(&FILEPATH)MONMSG MSGID(CPFA0A9) EXEC(DO)
/* Fichier non trouvé */
/* Traitement de l'exception... */
CHGVAR VAR(&EXISTS) VALUE('0')
SNDPGMMSG MSG('Fichier inexistant')
ENDDO
/* Libération de l'objet si existant */
IF COND(&EXISTS) THEN(DO)
CHKIN OBJ(&FILEPATH)
ENDDO
ENDPGM
MOV (clle)
Une solution plus simple encore, lorsque l’on n’a pas besoin de gérer le verrouillage de l’objet, est l’utilisation de la commande MOV. Initialement, elle permet de déplacer un objet, mais en indiquant le chemin de l’objet d’origine comme objet de destination, aucune action ne sera effectuée sur l’objet (pas de changement de la date de dernière modification) et on pourra encore une fois tester le message CPFA0A9.
En SQL et SQLRPGLE, le plus simple reste d’utiliser la fonction table IFS_OBJECT_STATISTICS. Pour s’assurer ne pas tomber sur un répertoire portant le nom du fichier ou autre, il est préférable de renseigner les paramètres subtree_directories et object_type_list (bien entendu en renseignant *DIR si on cherche un répertoire).
Il suffit ensuite de tester le sqlCode, s’il est égal à 100 cela signifie que le fichier est inexistant.
Il faut tout de même prendre en compte les droits de l’utilisateur qui réalise ces tests, en fonction de la méthode utilisée, un autre message pourrait être émit ou le fichier pourrait lui apparaitre comme inexistant.
Sur le site https://adresse.data.gouv.fr/ En cliquant sur l’item « Outils et API », on accède librement à la documentation des API en rapport avec les adresses. Nous choisissons donc celle sobrement intitulée « API Adresse ». La documentation montre différentes manières d’utiliser cette API. Le retour est un geojson FeatureCollection respectant la spec GeoCodeJSON.
Récupération et manipulation des données
But du programme
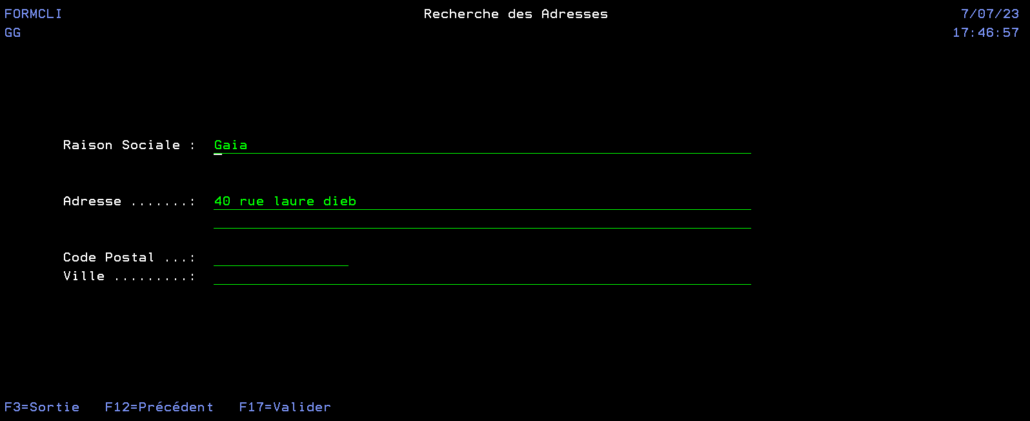
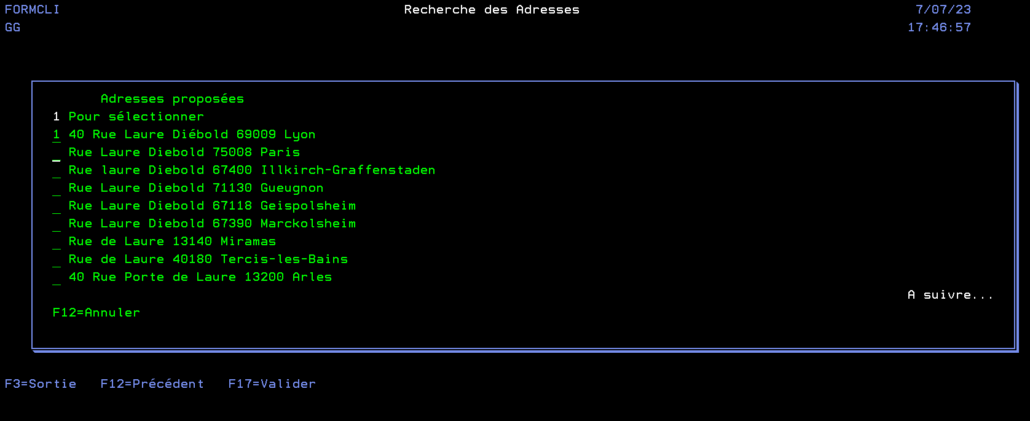
Nous allons réaliser un programme qui permettra, en écrivant partiellement une adresse, de récupérer une adresse complète d’après une liste déroulante de 50 occurrences.
Nous choisirons pour notre programme une interrogation relativement simple et nous n’extrairons qu’une partie des données du geojson.
Nous écrirons les adresses dans un fichier, sous forme d’une fiche client contenant les éléments suivants :
Identifiant (integer auto incrémenté)
Raison Sociale (varchar)
Adresse (varchar)
Code Postal (varchar)
Ville (varchar)
Coordonnées géographiques (ST_POINT)
Préparation du fichier
create table GGEOLOC.MESCLIENTS
(ID int GENERATED ALWAYS AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER
CACHE 20 ),
RAISOC varchar(64),
ADRESSE varchar(128),
CODEPOS varchar(16),
VILLE varchar(64),
COORDGEO QSYS2.ST_POINT);
Programme de saisie
**free
ctl-opt dftactgrp(*no) ;
// Fichiers
dcl-f FORMCLIE workstn indds(DS_Ind) usropn;
// Procédures
dcl-pr Touche_F4 EXTPGM('TOUCHE_F4');
p_Sql char(1024) ;
p_Titre char(35);
p_Ret char(116);
end-pr;
// Variables
dcl-s reqSqlDelete varchar(2000);
dcl-s reqSqlCreate varchar(2000);
dcl-s reqSqlDrop varchar(2000);
dcl-s coordonees varchar(64) ;
dcl-s queryapi varchar(64);
dcl-s httpText varchar(256);
dcl-s pIndicators Pointer Inz(%Addr(*In));
// Pour F4 : liste des fichiers
dcl-s w_Sql char(1024) ;
dcl-s w_Titre char(35);
dcl-s w_Ret char(116);
// DS Informations Programme
dcl-ds *N PSDS;
nom_du_pgm CHAR(10) POS(1);
nom_du_prf CHAR(10) POS(358);
end-ds;
// Déclaration des indicateurs de l'écran
Dcl-DS DS_Ind based(pIndicators);
Ind_Sortie ind pos(3);
Ind_Liste ind pos(4);
Ind_Annuler ind pos(12);
Ind_Valider ind pos(17);
Ind_SFLCLR ind pos(40);
Ind_SFLDSP ind pos(41);
Ind_SFLDSPCTL ind pos(42);
Ind_SFLEnd ind pos(43);
Ind_DisplayCoord ind pos(80);
Ind_RaisonS ind pos(81);
Ind_5Lettres ind pos(82);
Ind_CodePos ind pos(84);
Ind_Ville ind pos(85);
Indicators char(99) pos(1);
End-DS;
// Paramètres en entrée
dcl-pi *N;
end-pi;
// SQL options --------------------------------------------- //
Exec SQL
Set Option
Naming=*Sys,
Commit=*None,
UsrPrf=*User,
DynUsrPrf=*User,
Datfmt=*iso,
CloSqlCsr=*EndMod;
//--------------------------------------------------------- //
// Contrôle taille écran
Monitor;
Open FORMCLIE;
On-Error;
Dsply 'Nécessite un écran 27 * 132';
*inlr=*on;
Return;
EndMon;
Dou Ind_Sortie or Ind_Annuler;
znompgm = nom_du_pgm;
znomprf = nom_du_prf;
Exfmt FMT01;
select ;
when Ind_Sortie ;
leave;
when Ind_Annuler;
leave;
when Ind_Liste;
if %len(%trim(zadresse)) <= 4 ;
Ind_5Lettres = *on;
iter;
endif;
traitementListe();
when Ind_Valider;
if zraisoc = *blanks;
Ind_RaisonS = *on ;
endif;
if zcodpos = *blanks;
Ind_CodePos= *on ;
endif;
if zville = *blanks;
Ind_Ville = *on ;
endif;
if %subst(indicators:81:4) <> '0000';
iter ;
endif;
Exec SQL
insert into MESCLIENTS (RAISOC, ADRESSE, CODEPOS, VILLE, COORDGEO)
values (:zraisoc, :zadresse, :zcodpos, :zville,
QSYS2.ST_POINT(:zlongit, :zlatit)) ;
Ind_DisplayCoord = *off;
clear FMT01;
endsl ;
Enddo;
*inlr = *on;
//======================================================================== //
// Procédures //
//======================================================================== //
//------------------------------------------------------------------------ //
// Nom : rechercheAdresse //
// But : lister des adresses recueillies via une API //
// à partir d'une chaine de plus de 4 caractères //
// Retour : N/A //
//------------------------------------------------------------------------ //
dcl-proc rechercheAdresse ;
dcl-pi *n ;
l_httpText varchar(256) value;
end-pi;
reqSqlDrop = 'drop table QTEMP/WADRESSE' ;
Exec sql Execute immediate :reqSqlDrop ;
reqSqlCreate = 'create table QTEMP/WADRESSE' +
' (address varchar(128), numero varchar(8), street varchar(128), ' +
'postcode varchar(16), city varchar(64), coordinates blob)' ;
Exec sql Execute immediate :reqSqlCreate ;
reqSqlDelete = 'delete from QTEMP/WADRESSE' ;
Exec sql Execute immediate :reqSqlDelete ;
Exec sql
insert into QTEMP/WADRESSE
(select ltrim(ifnull(numero, '') || ' ' ||
coalesce(street, locality, '') || ' ' ||
postcode || ' ' || city),
ifnull(numero, ''), coalesce(street, locality, ''),
postcode,
city,
QSYS2.ST_POINT(longitude, latitude)
from json_table(QSYS2.HTTP_GET(:l_httpText, ''), '$.features[*]'
COLUMNS
(numero varchar(8) PATH '$.properties.housenumber',
street varchar(128) PATH '$.properties.street',
locality varchar(128) PATH '$.properties.locality',
name varchar(128) PATH '$.properties.name',
municipality varchar(128) PATH '$.properties.municipality',
postcode varchar(8) PATH '$.properties.postcode',
city varchar(64) PATH '$.properties.city',
longitude float PATH '$.geometry.coordinates[0]',
latitude float PATH '$.geometry.coordinates[1]'))
);
end-proc ;
//------------------------------------------------------------------------ //
// Nom : traitementListe //
// But : Affichage d'une liste de 50 adresses maximum //
// Retour : N/A //
//------------------------------------------------------------------------ //
dcl-proc traitementListe ;
queryapi = %scanrpl(' ':'+':%trim(zadresse)) ;
httpText ='https://api-adresse.data.gouv.fr/search/?q=' +
queryapi + '&limit=50' ;
rechercheAdresse(httpText);
clear w_ret ;
w_sql =
'select address from QTEMP/WADRESSE' ;
w_titre = 'Adresses proposées';
touche_f4(W_Sql: W_titre : w_ret) ;
if (w_ret <> ' ') ;
clear zadresse;
clear zcodpos;
clear zville;
Exec SQL
select
ltrim(ifnull(numero, '') || ' ' || street), postcode, city,
REPLACE(
REPLACE(QSYS2.ST_asText(COORDINATES), 'POINT (', ''), ')', '')
into :zadresse, :zcodpos, :zville, :coordonees
from QTEMP.WADRESSE
where address = :w_ret ;
if sqlcode = 0 ;
Ind_DisplayCoord = *on ;
zlongit = %dec(%subst(coordonees: 1 : %scan(' ':coordonees)):15:12) ;
zlatit = %dec(%subst(coordonees: %scan(' ':coordonees) + 1
: %len(%trim(coordonees)) - %scan(' ':coordonees)):15:12) ;
endif;
endif ;
end-proc ;
Quelques explications sur les fonctions SQL utilisées
Tout d’abord nous choisissons de ne pas utiliser la propriété « label » proposée par l’API Adresse. En effet, si celle-ci semble pratique de prime abord, elle n’est pas toujours significative (voir photo du milieu qui où elle ne contient que le nom de la municipalité)
Nous, préférerons donc reconstituer cette adresse en concaténant des zones que l’on retrouve dans chaque occurrence du fichier JSON.
QSYS2.ST_POINT : Cette fonction est utilisée lors de la collecte des données fournie par l’API Adresse.
Elle permet de transformer les coordonnées longitude, latitude en une variable de type BLOB qui représente un point précis et qui est utilisable par les fonctions Géospatiales du SQL.
QSYS2.ST_ASTEXT : Cette fonction permet de transformer un champ géométrique (ST_POINT, ST_LINESTRING, ST_POLYGON, …) en un champ WKT (well-known-text) qui nous sera plus compréhensible.
Cinématique du programme
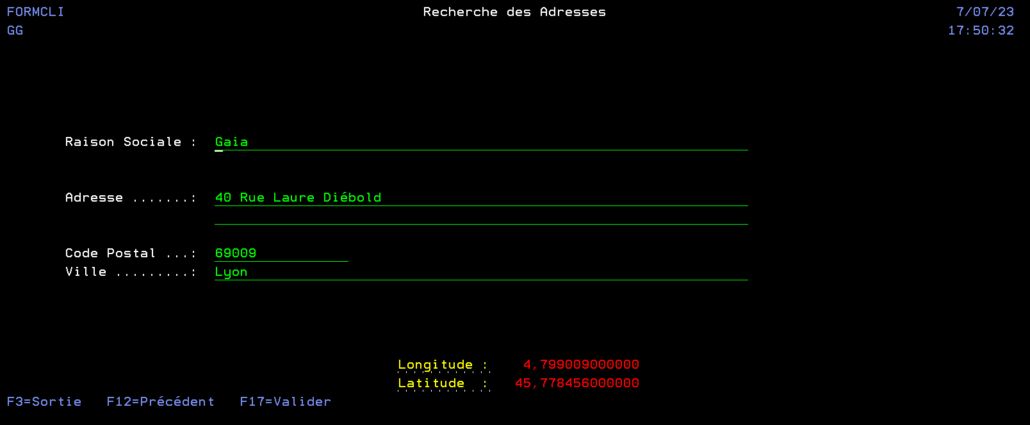
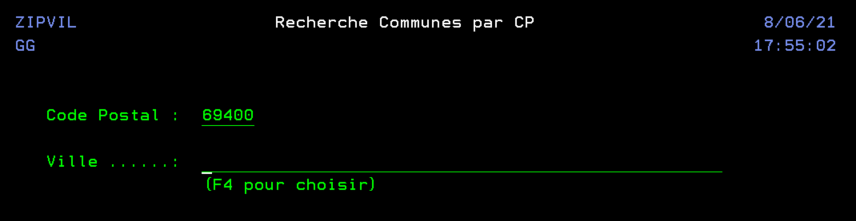
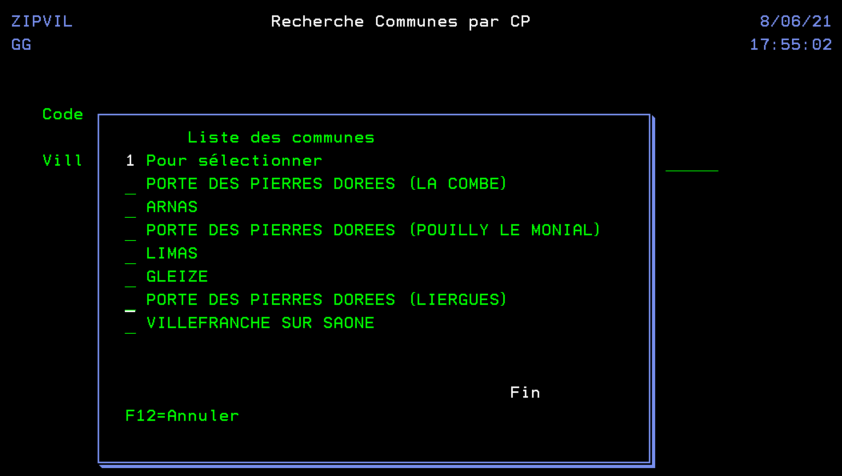
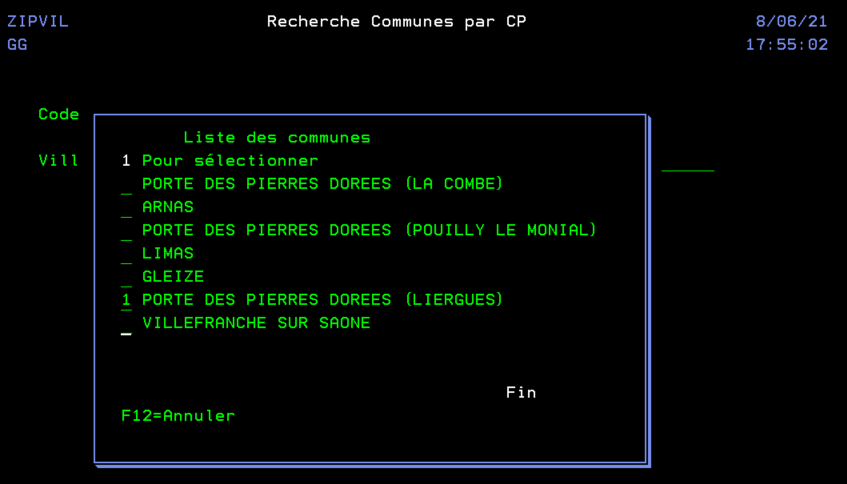
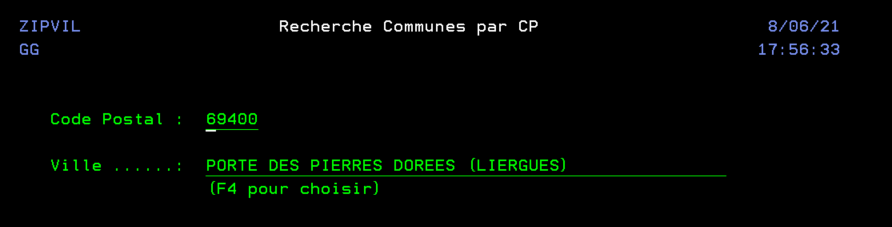
Ce programme est un simple écran qui nous permet la saisie d’un formulaire avec la possibilité de rechercher ou compléter une adresse en utilisant la touche F4 (la fonction externe appelée n’est pas décrite dans cet article). Une fois le formulaire validé, on l’efface.
Tout d’abord on commence à remplir le formulaire mais on ne connait pas précisément l’adresse.
Donc, après avoir tapé un morceau d’adresse on presse F4
On valide, le formulaire est alors complétement rempli
On presse F17 pour valider celui-ci (et réinitialiser l’écran).
Vérification des données enregistrées
Version BLOB
Version WKT (well-known-text)
Conclusion
Nous avons montré ici un exemple simple de l’utilisation d’une API couplée avec les fonctions géospatiales proposées par IBM. Il est possible d’envisager des requêtes plus complexes incluant le code postal, la ville ou encore le type de donnée (rue, lieu-dit ou municipalité). On peut aussi envisager des requêtes d’après les coordonnées géographiques pour retrouver une adresse. Le champ des possibles, comme le monde, est vaste …
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2023-07-10 08:34:102023-08-11 16:38:36RETROUVER UNE ADRESSE GRACE AUX API
Bien que le MD5 ne soit plus utilisé pour l’encryption, il est toujours utilisé pour valider l’authenticité et la conformité des fichiers.
Qu’est-ce qu’un MD5
Un md5 est une chaine de 16 caractères composée de symboles hexadécimaux. Il s’agit en réalité du nom de l’algorithme utilisé pour générer la chaine.
Comme indiqué précédemment son usage est le contrôle d’intégrité des fichier, par exemple lors du partage d’un fichier, on peut mettre à disposition le MD5 afin de contrôler que le téléchargement du fichier s’est bien passé ou que le fichier n’a pas été modifié entre temps.
Pour la suite nous aurons besoin d’un fichier, par simplicité j’utiliserai un simple .txt qui contient la phrase « This is not a test! » présent dans mon répertoire de l’ifs.
Fichier dans l’ifs
/home/jl/file.txt
Contenu du fichier
This is not a test!
md5
EDA20FB86FE23401A5671734E4E55A12
QSH – md5sum
La première méthode pour générer le MD5 d’un fichier est d’utiliser la commande unix md5sum via QSH :
La fonction retourne le hash et le chemin du fichier.
RPGLE – _cipher
Il est également possible de générer le MD5 via RPG en exploitant la procédure externe cipher. Je ne m’épancherai pas sur son implémentation complète ici, car bien plus complexe que les deux autres méthodes présentées. De plus, passer par cette méthode, n’est plus le sens de l’histoire.
// Déclaration de la procédure
dcl-pr cipher extproc('_cipher');
*n pointer value;
*n pointer value;
*n pointer value;
end-pr;
// Appel de la procédure
cipher(%ADDR(receiver) : %ADDR(controls) : %ADDR(source));
En sql on retrouve la fonction hash_md5, qui retourne le hash d’une chaine de caractère passée en paramètre.
❗ Attention à l’encodage de votre chaine de caractères. ❗
Pour que le résultat soit cohérent entre différents systèmes il faut commencer par convertir la chaine de caractère en UTF-8 :
VALUES CAST('This is not a test!' AS VARCHAR(512) CCSID 1208); -- 1208 = UTF-8
-- Retour : This is not a test!
Le résultat est plutôt flagrant ! D’accord pas vraiment… Par contre si on regarde la valeur hexadécimale de la chaine avec et sans conversion :
VALUES HEX('This is not a test!');
-- Retour : E38889A24089A2409596A3408140A385A2A34F
VALUES HEX(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : 54686973206973206E6F742061207465737421
Le hachage se fait en hexadécimal, donc le résultat ne serait pas le même sans conversion préalable.
Il suffit maintenant de hacher notre chaine de caractères :
VALUES HASH_MD5(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : EDA20FB86FE23401A5671734E4E55A12
On obtient donc la même valeur que celle que l’on a obtenu précédemment (puisque que le contenu de notre fichier est strictement égale à cette chaine de caractère).
La dernière étape est de générer le MD5 directement à partir du fichier, pour cela il suffit d’utiliser la fonction GET_BLOB_FROM_FILE :
VALUES HASH_MD5(GET_BLOB_FROM_FILE('/home/jl/file.txt')) WITH CS;
-- Retour : EDA20FB86FE23401A5671734E4E55A12
Autres algorithmes de hash
Il existe d’autres algorithmes de hash qui permettent de hacher du texte et des fichiers. Trois autres algorithmes sont généralement disponibles :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2022-08-18 00:30:512022-08-18 12:51:20Utilisation du MD5 sur votre IBM i
Il existe un grand nombre d’API aux fonctionnalités diverses dont certaines nous permettent de récupérer des données structurées dans différents formats (XML, JSON, …).
Grace aux fonctions SQL de l’IBMi nous pouvons récupérer ces données pour les insérer dans les fichiers de la base de données.
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=xml',''), 4096)) ws(data);
Sortie API en JSON
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}',''), 4096)) ws(data);
Sortie API en HTML
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=html',''), 4096)) ws(data);
Récupération des données
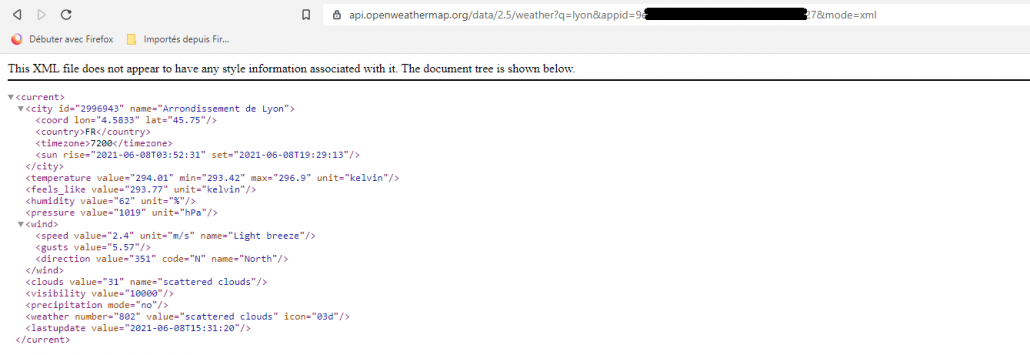
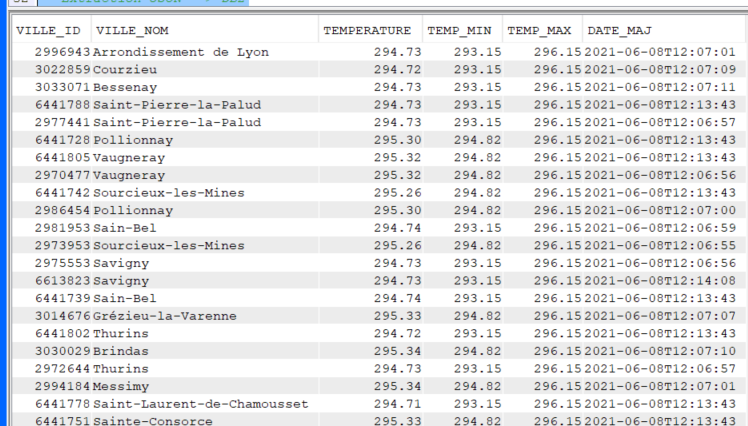
En XML
On crée un fichier qui contiendra les colonnes que l’on veut récupérer (Ville, Température en cours, date, …)
CREATE TABLE GG/METEODB (VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT, VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT, TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT, DATE_MAJ CHAR (20) NOT NULL WITH DEFAULT);
Récupérer les données de l’API dans le fichier créé :
INSERT INTO GG.METEODB select xdata.* FROM xmltable('$doc/cities/list/item' PASSING XMLPARSE(document SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/find?lat=45.75&lon=4.5833&cnt=10&appid={API key}&mode=xml','')) AS "doc" COLUMNS ville_id decimal(9, 0) PATH 'city/@id', ville_nom varchar(50) PATH 'city/@name', temperature decimal(5, 2) PATH 'temperature/@value', temp_min decimal(5, 2) PATH 'temperature/@min', temp_max decimal(5, 2) PATH 'temperature/@max', date_maj varchar(20) PATH 'lastupdate/@value' ) as xdata;
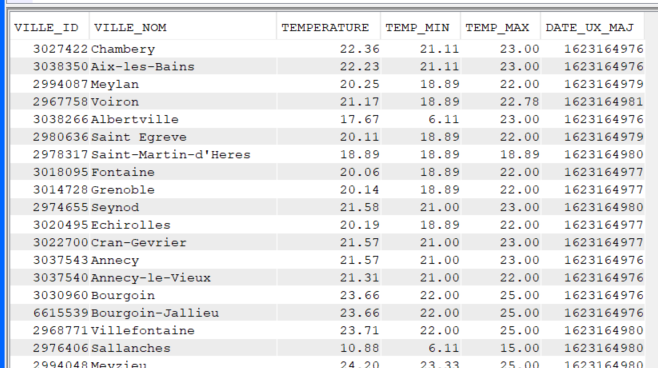
En JSON
Contrairement à XML, on peut créer tout de suite un fichier qui contiendra les colonnes que l’on veut récupérer.
CREATE TABLE GG.METEOBD (VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT, VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT, TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT, DATE_UX_MAJ DECIMAL (12, 0) NOT NULL WITH DEFAULT)
Récupérer les données de l’API dans le fichier créé :
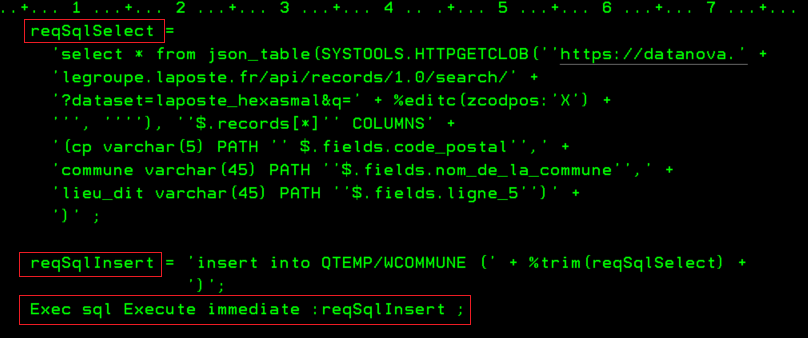
En utilisant une API de LA POSTE qui ne nécessite pas d’inscription au préalable, ni d’identification. Nous pouvons réaliser un programme qui nous aide à retrouver une commune à partir d’un code postal, dans l’optique d’aider au remplissage de certains formulaires. On crée un fichier temporaire en interrogeant directement l’API.
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2021-06-09 13:56:312022-04-12 12:28:31UTILISATION DES API EN SQL