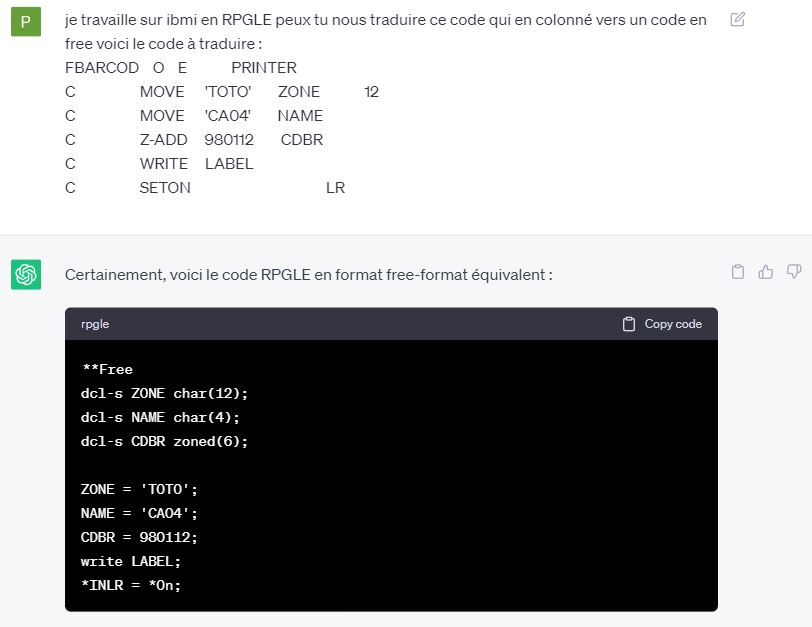
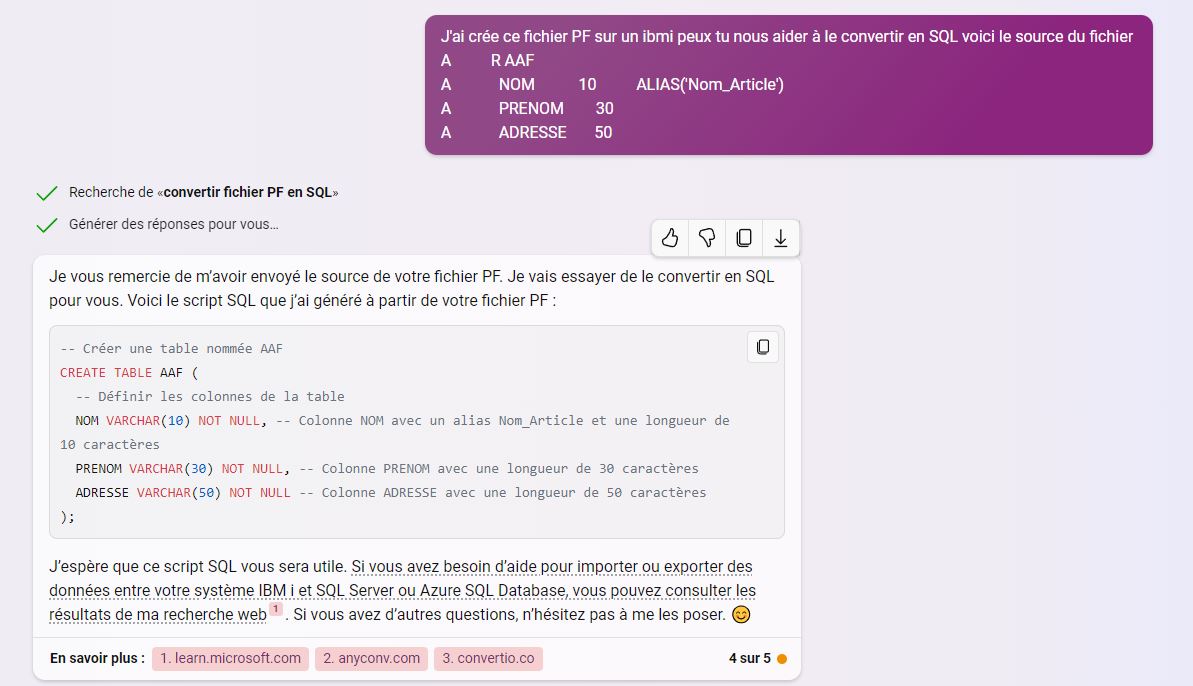
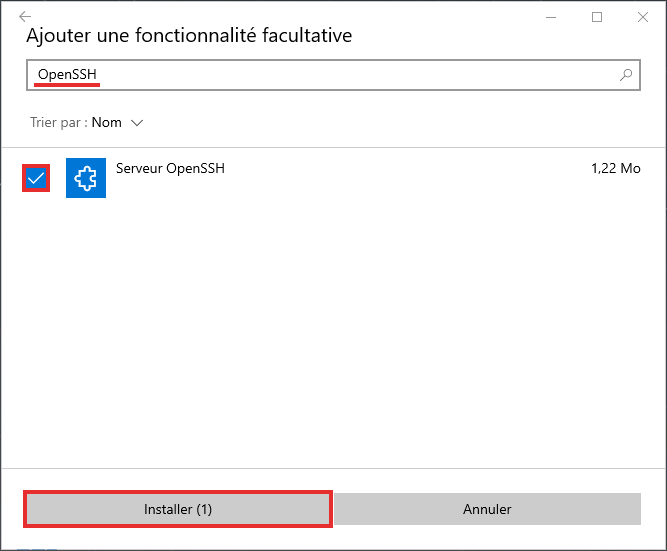
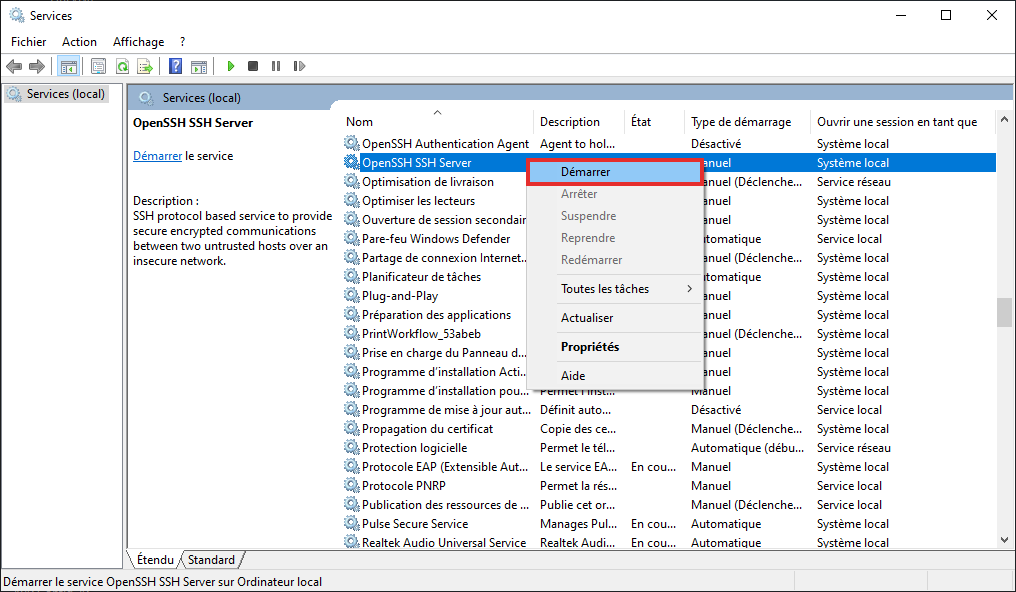
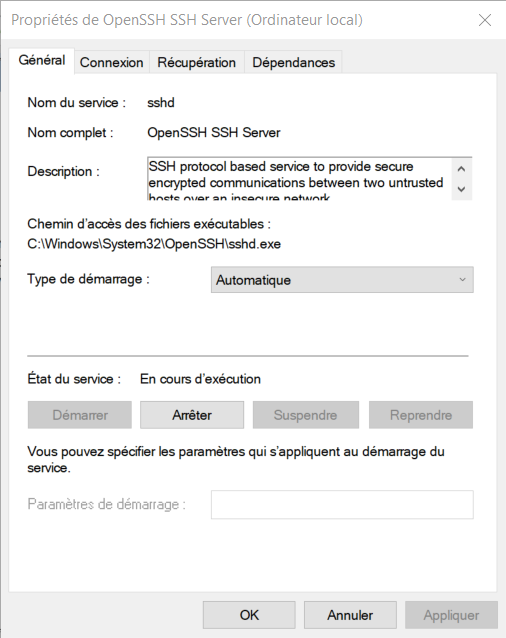
Vous avez encore des développements en 5250 avec des DSPF et vous vous posez la question : dois je utiliser une touche CA ou CF ?
Nous allons essayer de vous apporter quelques éclaircissements sur les usages et les bonnes pratiques
Première chose, vous pouvez utiliser une touche de fonction de 2 manières
CA03(03)
ou
CA03 uniquement
Avec CA03(03), vous testerez *IN03 dans vos programmes RPGLE et &IN03 en CLLE.
Avec CA03, vous testerez *INKC dans vos programmes RPGLE et c’est plus compliqué à gérer en CLLE.
Jusque la on utilisait les indicateurs *inka … pour économiser les indicateurs de 01 à 24 (99 disponibles),
sur les nouveaux développement on utilise moins d’indicateurs et plus de fonctions intégrées comme %EOF(). Il est donc conseillé d’utiliser les indicateurs *IN01 à *IN24 ; de plus vous pouvez les renommer pour rendre plus lisible dans les programmes !
Pour ce faire, vous devez déclarer votre écran en INDARA pour indiquer que les indicateurs sont séparés du flux des données.
A* Niveau fichier dans le dds :
A INDARA
Dans le source du programme RPG :
dcl-f
MONECR WORKSTN
indds(DS_Ind)
;
Dans les déclaration :
Dcl-DS DS_Ind len(99);
// Touches de fonctions
Sortie ind pos(3);
Liste ind pos(4);
Reaffichage ind pos(5);
Creer ind pos(6);
Valider ind pos(10);
Annuler ind pos(12);
…
End-DS;
Conseil
Comme vous devez vous baser sur la NORME AUA , vous pouvez faire un include avec ces touches de fonction.
dans le code vous pouvez indiquer :
IF SORTIE ;
Comment déclarer les touches dans vos DDS ?
Vous pouvez les déclarer
- au niveau du fichier, votre touche sera utilisable dans tous les formats.
C’est le cas par exemple de CA03 pour sortir.
- au niveau du format, on ne peut pas redéclarer une touche déjà décrite au niveau fichier
Exemple :
A* niveau fichier
A CA03(03)
A R PREMIER
A
A R DEUXIEME
A* niveau du format
A CA12(12)
vous pourrez utiliser :
CA03 sur le format PREMIER
CA03 et CA12 sur le DEUXIEME
Plus vous serez précis dans vos déclarations, plus vos programmes serons clairs et précis.
Toutes les touches déclarées dans les formats doivent être traitées dans le code.
Si vous utilisez une touche dans un programme et qu’elle n’est pas traitée … ça peut poser problème, du genre mise à jour sans lecture de l’écran.
Pourquoi CA et pas CF !?
Pour vous expliquer nous avons choisi de faire ce petit exemple (écran + programme RGPLE)
le programme CACF
**free
Ctl-Opt DFTACTGRP(*NO) ;
Dcl-f CACF WORKSTN ;
dou *in07 or *in08 ;
exfmt fmt01 ;
dsply zone ;
enddo ;
*inlr = *on ; Et l’écran CACF
A*%%TS SD 20230914 164942 PLB REL-V7R4M0 5770-WDS
A*%%EC
A DSPSIZ(24 80 *DS3)
A R FMT01
A*%%TS SD 20230914 164942 PLB REL-V7R4M0 5770-WDS
A CA07(07)
A CF08(08)
A 4 10'Test pour comprendre la différence-
A entre une touche CA et CF'
A DSPATR(HI)
A 9 10'Saisir une valeur ici '
A 9 33':'
A ZONE 1A B 9 35VALUES('1' '2')
A 9 38'Veuillez saisir 1 ou 2'
A DSPATR(HI)
A 20 10'CA07==> Sortir sans lecture'
A 21 10'CF08==> Sortir avec lecture' Où il est possible d’utiliser les touches de fonction 07 déclarée CA et 08 déclarée CF.
f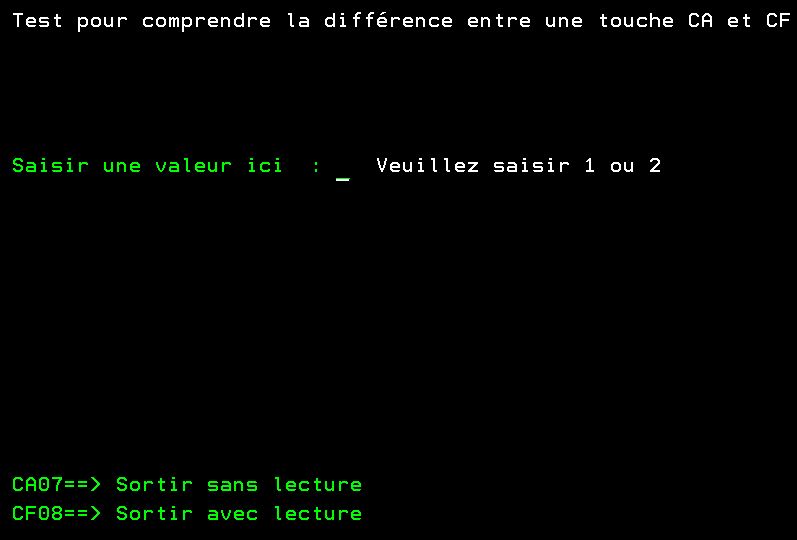
Premier test
Vous tapez directement F7 ou F8, le comportement est le même si votre buffer n’a pas été modifié, il n’y a pas de lecture.
Pour déterminer si le buffer est modifié le système se sert d’un octet attribut (dans le format ou dans la zone) dans le quel on un MDT qui sera à *ON.
Si le buffer ou la zone à été modifiée. vous devrez forcer ce tag dans le cas ou contrôlez des données.
C’est le mot clé DSPATR(MDT) dans les DDS qui permet ça, vous pouvez le conditionner par un indicateur.
Deuxième test
Vous saisissez 9 dans l’écran.
F7 sort directement et tient pas compte de la saisie, c’est ce qui convient pour les touches F3 ou F12.
F8 déclenche une lecture avant de sortir et comme on a fait le choix de contrôler la valeur saisie à 1 ou 2, on est bloqué jusqu’à ce qu’on ait renseigné la zone à la bonne valeur,
C’est ce qui convient pour les touches F6 ou F10.
On imagine bien que si vous avez 10 zones avec contrôles, ça poser problèmes quel que soit le contrôle
Rappel sur l’ordre à faire sur vos contrôles
1) Contrôle de valeurs, gérer par VALUES() ou CHECK() dans le DDS, aucun code à traiter côté programme.
2) Contrôles de dépendance exemple borne début < borne de fin (toutes les informations de l’écran sont suffisantes pour le contrôle).
3) Contrôles nécessitants une ressource externe, le plus souvent en base de données (saisie d’un numéro de client à contrôler).
La règle si la valeur saisie n’est pas bonne ce n’est pas la peine de faire le contrôle suivant !
Conseil :
Soyez précis dans vos déclarations dans le niveau format ou tous les format au fichier.
et n’utilisez les touches CF que quand vous devrez traiter les données de l’écran.
Merci à Nicolas pour son aide !