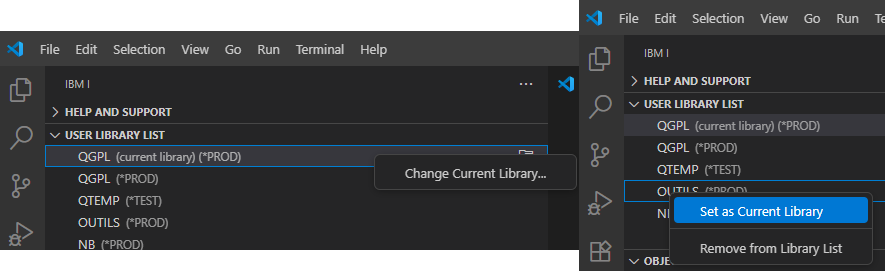
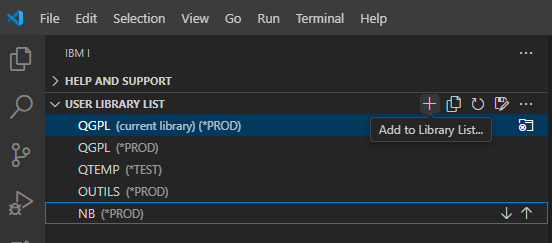
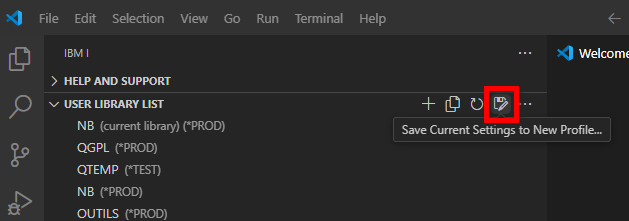
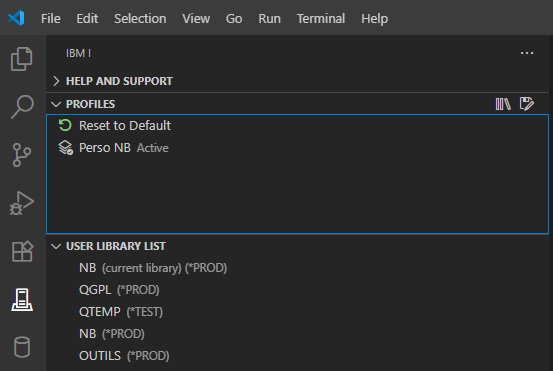
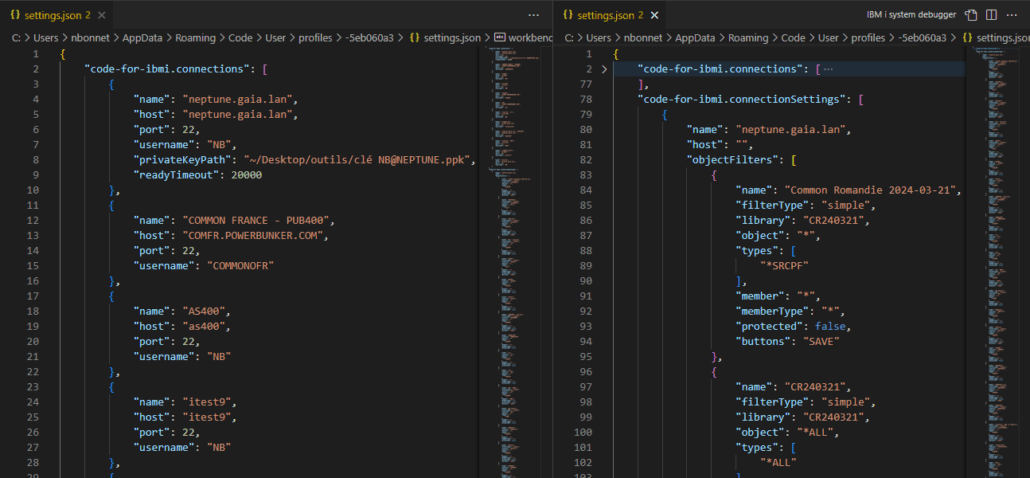
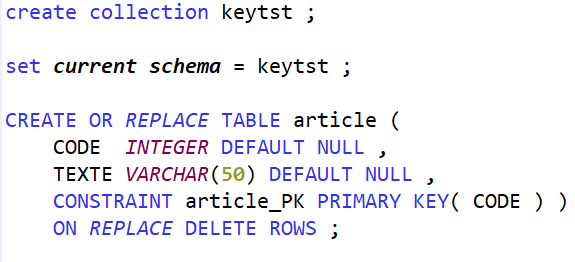
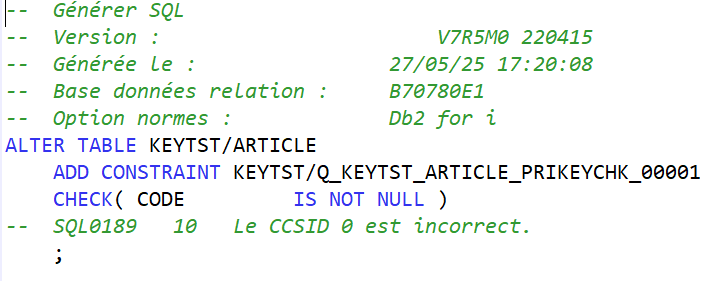
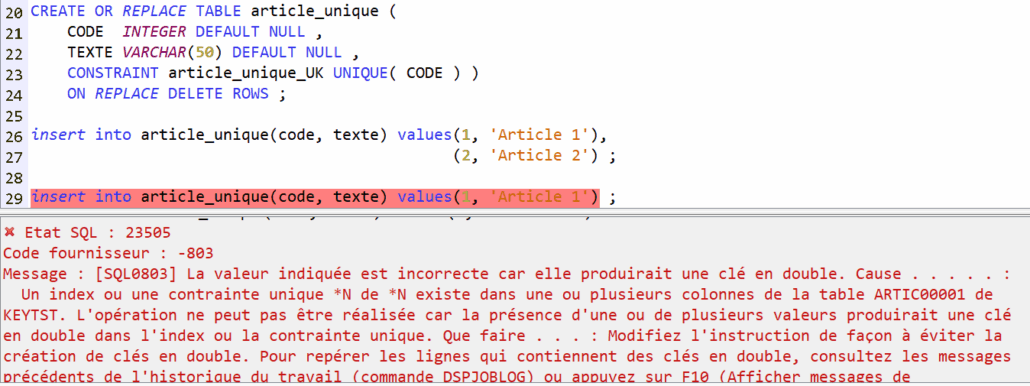
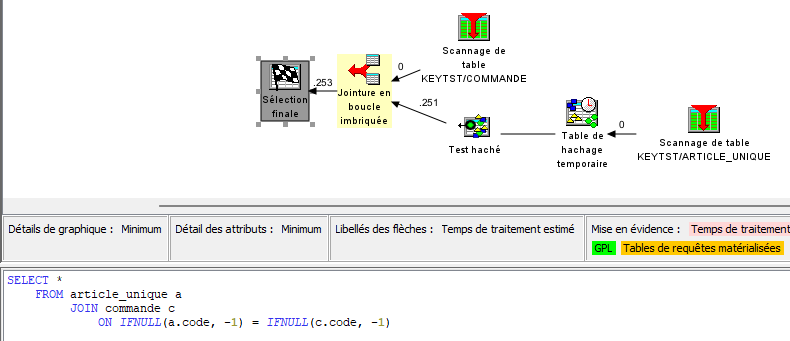
Franchement un titre à attirer les clics ! Quel rapport entre des sports où des gens se mettent des coups, s’étranglent, se projettent et notre métier, si valorisant, si doux, dur parfois mais moins sanglant et brutal ?
Rien…et beaucoup quand même.
Pour ceux qui me connaissent, vous n’apprendrez rien mais pour les autres, j’ai passé beaucoup de temps sur les tatamis et autres salles à pratiquer des sports de combat. Et ce, depuis plus longtemps que je ne pratique l’informatique, bien que tombé dedans tout petit, avec les TO7, Amstrad CPC6128, Sinclair ZX81 Spectrum et autres avant de succomber aux sirènes du marché de l’emploi et à celles moins connues à l’époque des AS400 (eh oui, cela s’appelait bien des AS400 !).
Et une comparaison s’impose.
Le Judo
Je me souviens de moi, jeune judoka, m’entraînant à Lyon, 10 heures ou plus par semaine. En pleine poussée de testostérone mes camarades et moi-même regardions en nous moquant un peu quand même, Jacky et Raymond. Deux vieux judokas qui s’époumonaient dans le fond lors des échauffements, qui commençaient la séance par faire du sol avec des petits jeunes et qui peinaient à reprendre leur souffle après mais qui immanquablement recommençaient, séance après séance, à prendre ces petits jeunes pour les faire forcer au sol, au risque de se provoquer un infarctus. Bon, certaines de leurs techniques n’étaient plus d’actualités, dépassées et même dangereuses ou interdites.
Et de l’autre côté, nous, les ceintures noires, nous l’élite du club, ensemble en train de discuter, de s’entraîner entre nous. Bon, je n’ai jamais été très « élitiste ». L’entre-soi n’est pas ce que je préfère. Mais en ces temps pas si reculés, quand vous obteniez votre ceinture noire au prix de nombreuses souffrances, de fractures, de sacrifices personnels et de déceptions maintes fois répétées devant l’échec, il semblait justifié de savourer ce moment de gloire.
Etant très proche de mon professeur de l’époque, Maître Roger Bourgery, j’appris que Raymond, pour ne parler que de lui, avait été mainte fois champion d’Algérie en Judo. Après l’indépendance, Raymond était venu en France poursuivre sa vie et continuer le Judo en gagnant encore quelques titres de gloire.
Maître Bourgery, mon professeur, nous rappela un précepte fondateur du judo : Jita Kyoei « entraide et prospérité mutuelle ». Et j’avoue que je pris comme mes camarades ceintures noires une bonne claque. L’entre-soi égoïste des jeunes coqs versus l’entraide des anciens, la transmission du savoir.
J’ai été ce que vous êtes, vous serez ce que je suis. Nos vies n’ont pas changé du jour au lendemain, je donnais déjà des cours de judo aux enfants et ados, pratiquement tous les soirs, mais certaines règles furent instaurées à l’entraînement : interdiction de refuser l’invitation d’une ceinture moins élevée, pour les combats ou pour l’entraînement. Il faut aussi donner pour recevoir et redonner ce que nous avions reçu.
L’humilité c’est aussi de reconnaître que l’on ne sait pas tout et que l’on peut aussi apprendre de ces ceintures moins élevées. En y repensant, maintenant que je suis moins frais et moins sportif, j’ai un autre regard sur ces vieux qui traînent dans un coin du bureau, qui font encore du GAP II ou du COBOL, qui se coltinent du colonné, du Matching, des fichiers Primaires et secondaires, voir du 36 ! Je dois me rappeler que ces vieux (et vieilles) ont été par le passé, souvent, des précurseurs de l’AS400 en remplaçant le cycle gap, en créant des sous-fichiers, en mettant de la couleur sur leurs écrans, que sais-je encore.
Ce sont ces mêmes personnes qui ne sont plus up-to-date, mais qui transmettent encore des notions. On a eu récemment un client qui est passé d’un environnement 36 à du plus…moderne. Nos « vieux briscards » ont retroussé les manches, et leur connaissance de « l’ancien temps » et des ponts pour arriver aux « temps modernes » ont été mis à contribution. Ils ont été utiles pour faire le lien et montrer « leur » métier.
Mais ils savent nous rappeler que si on bâtit sur le passé, cela reste « le passé ». On ne vit pas dans le passé, on vit avec. Il n’y a pas de « c’était mieux avant ». Il y a du « c’était comme cela avant mais maintenant on fait autrement et peut-être mieux ».
Pour finir, nous ne sommes pas tous des ceintures noires de l’IBM i, loin de là. Et certains anciens pensent encore que « c’était mieux avant » et deviennent des spécialistes…du passé.
Mais même si nous sommes des ceintures marrons, noires des années 90 ou des années 2000, 2010, 2020… il y a plein de ceintures blanches qui frappent à nos portes, qui peuvent et doivent apprendre.
Pas apprendre que c’était mieux avant, mais qu’il y avait un « avant » et surtout un « après » et que cet « après » ne soit pas une fin en soi. Que cet « après » deviendra un « c’était le bon temps » pour ceux qui sont les jeunes ceintures noires d’aujourd’hui. A nous de transformer notre pouvoir en un savoir à dispenser.
Attention, ce n’est pas un chant du cygne. C’est juste un rappel, comme dans mes années de judoka, que notre communauté est composée de ceintures de tous niveaux, de tous âges et que « l’entraide et la prospérité mutuelle » est une très belle notion à mettre en pratique.
C’est aussi un rappel aux anciens de leurs devoirs : transmettre et continuer à apprendre.