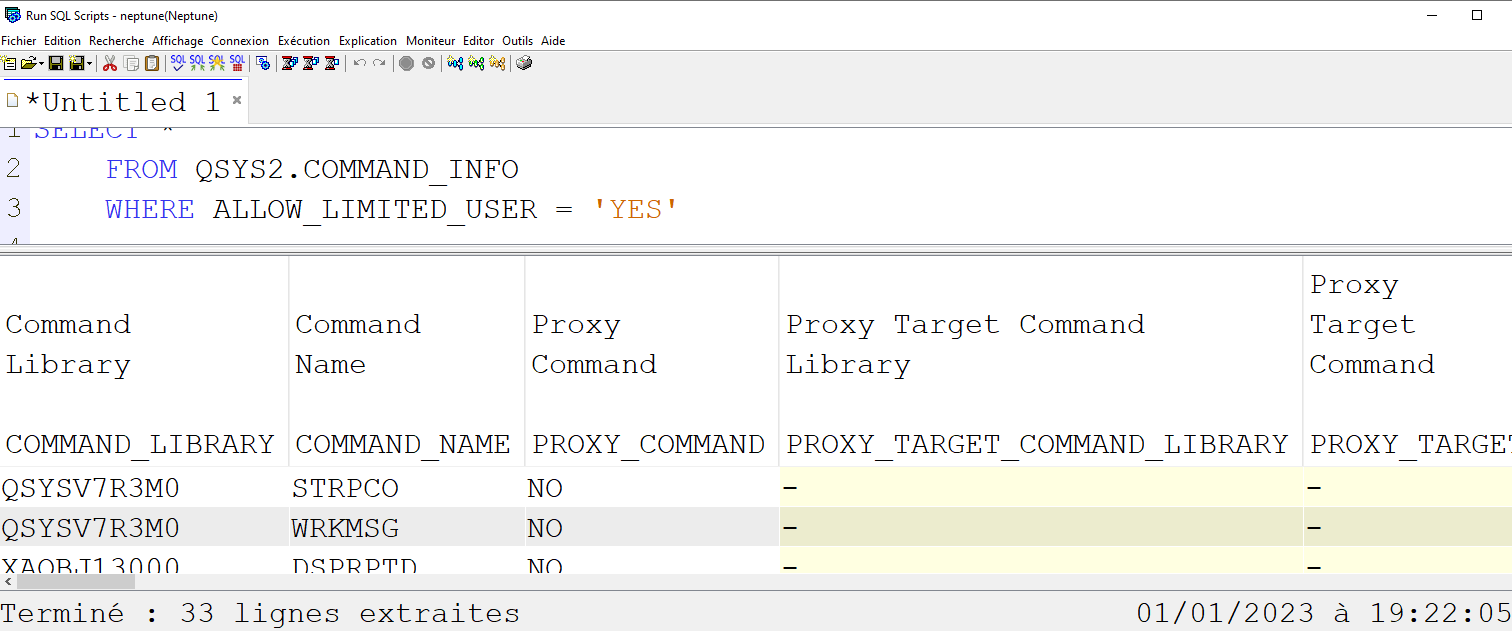
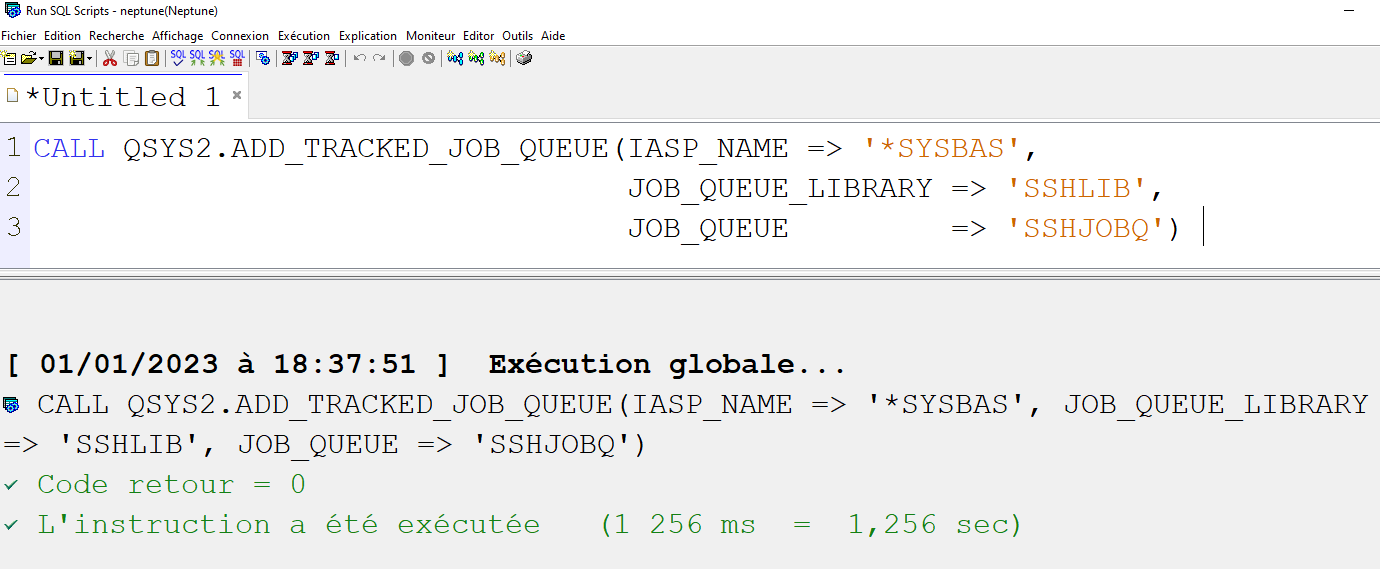
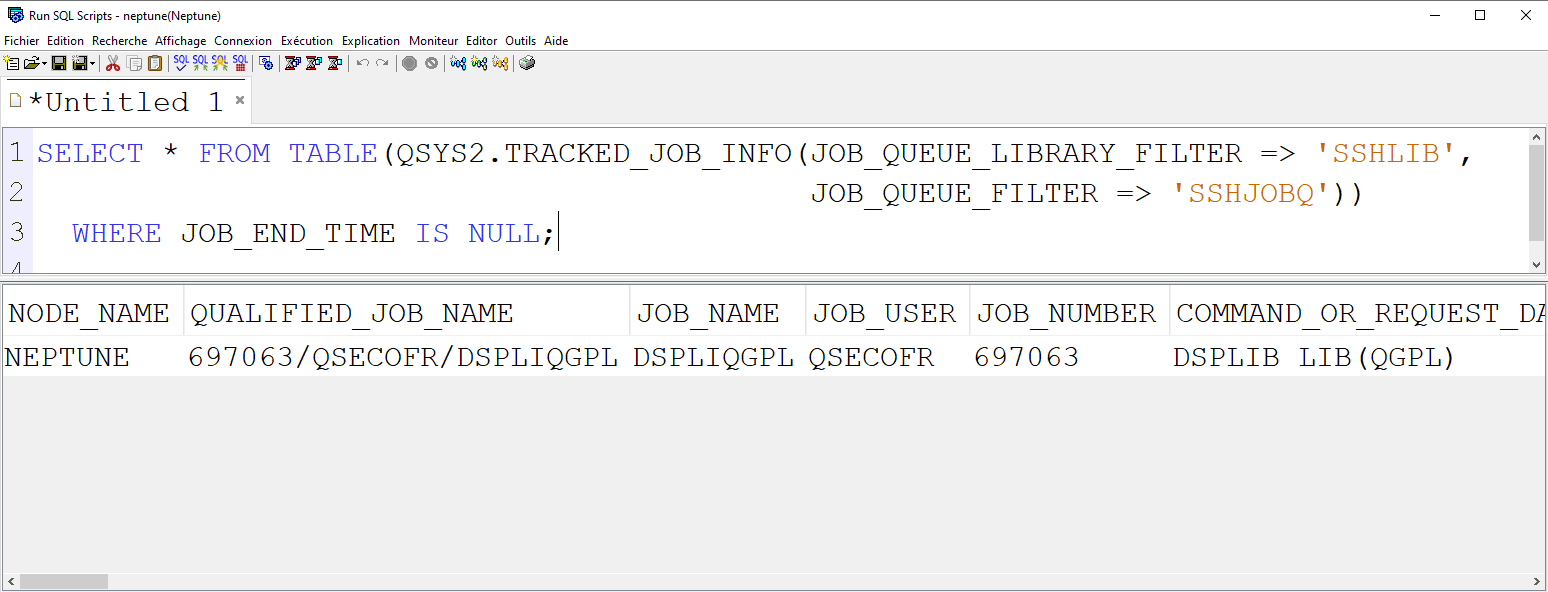
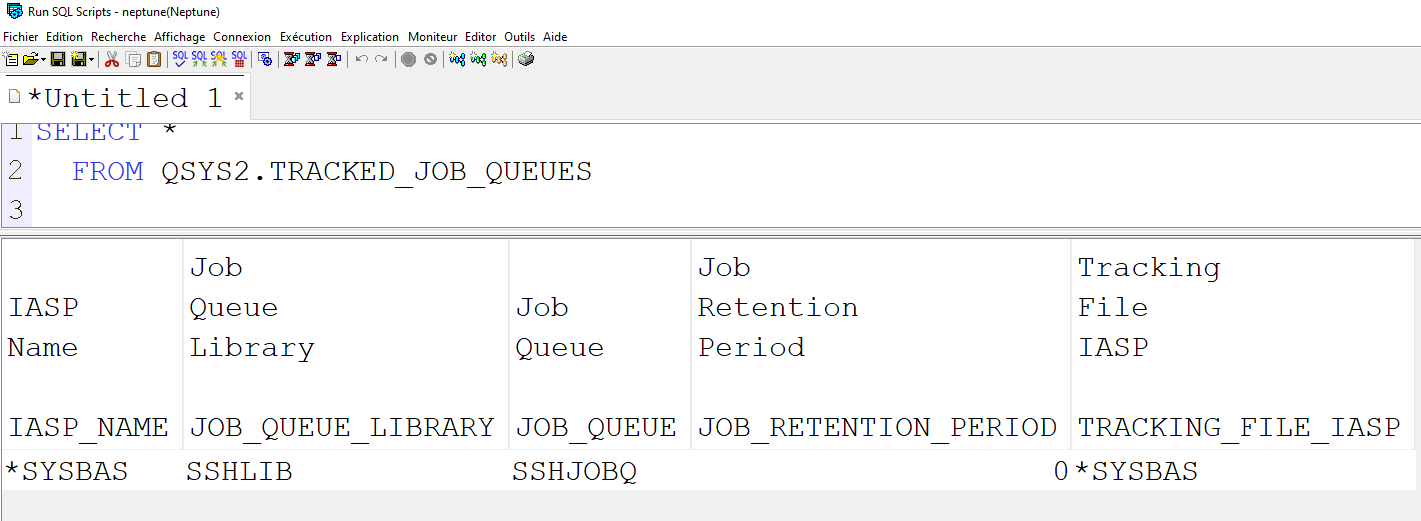
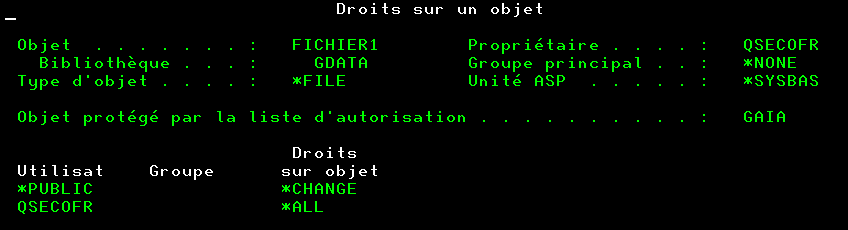
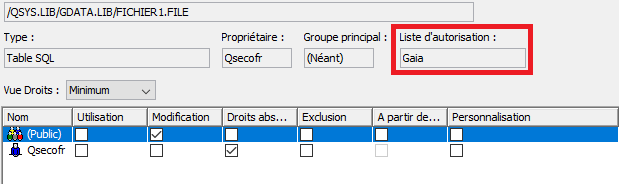
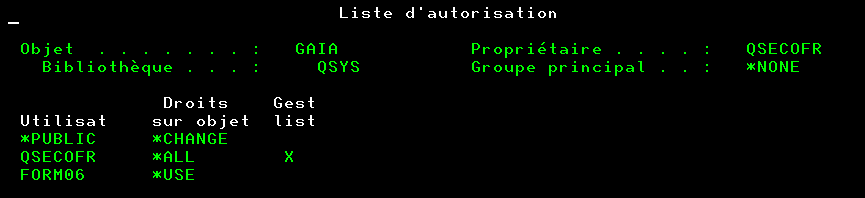
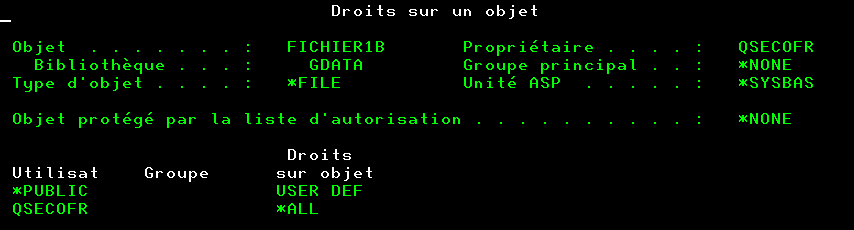
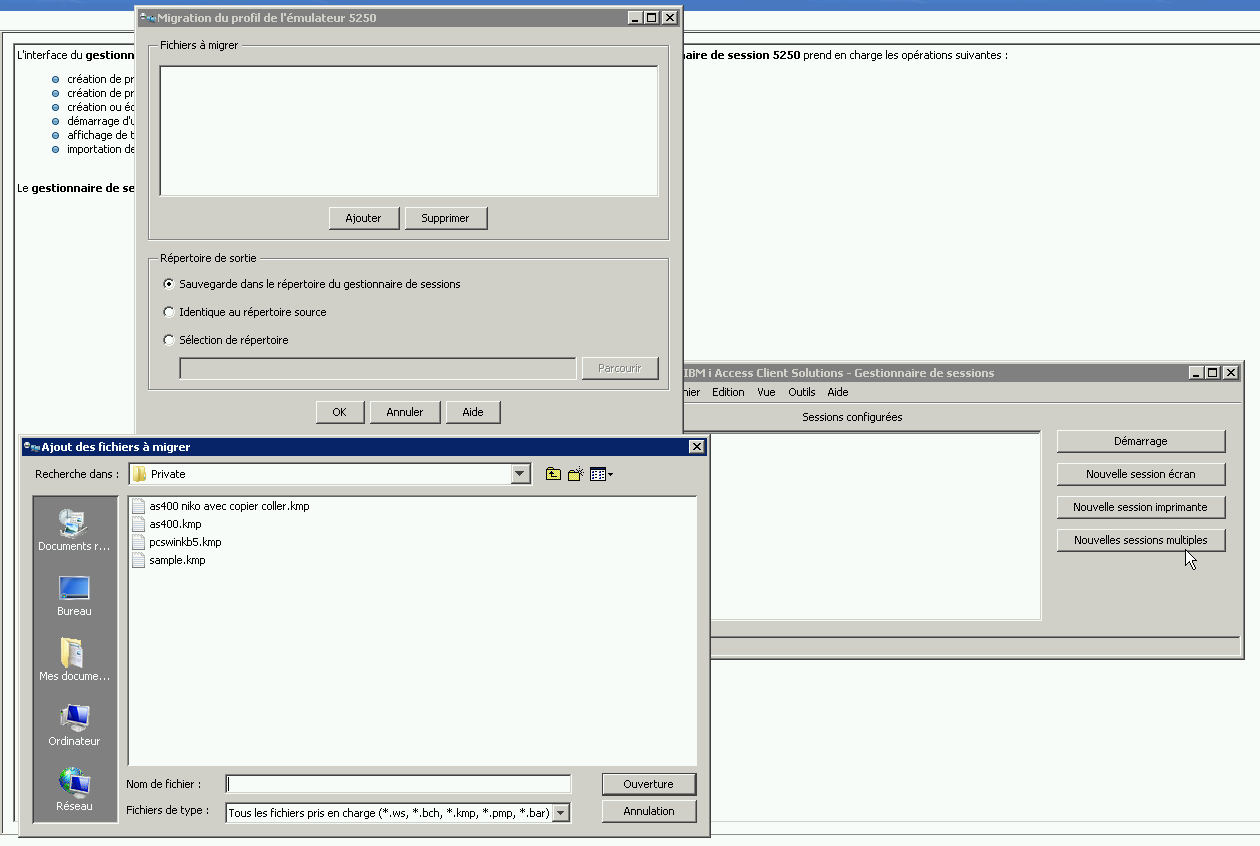
Il existe de nombreuses tables dans QSYS qui constituent le catalogue DB2,
Ces tables sont accessibles par des vues qui se trouvent dans QSYS2 de manière globale et dans les bibliothèques de vos collections SQL.
On utilise pas assez ces informations pour analyser la base de données, elles contiennent une multitude d’informations
On va faire une petit exemple:
Imaginons que nous voulons savoir ou est utilisée une zone
Nous fixerons la database par set schema , pour éviter les qualifications
exemple de manière globale
SET SCHEMA QSYS2
On va utiliser une vue qui s’appelle SYSCOLUMNS qui contient les zones de votre database
SELECT
A.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS A
WHERE COLUMN_NAME = ‘NUMCLI’
Vous obtenez une liste de tous les fichiers (tables, vue, PF, LF) etc …
Imaginons ensuite que vous ne vouliez que les tables ou PF vous pouvez utiliser la vue SYSTABLES
SELECT a.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in(‘T’ , ‘P’)
WHERE COLUMN_NAME = ‘NUMCLI’
Vous limitez ainsi votre recherche aux tables et PF
Imaginons maintenant que vous ne vouliez que les tables et PF qui ont été utilisées sur l’année flottante (13 mois), on va utiliser la vue SYSTABLESTAT
SELECT a.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in( ‘T’ , ‘P’)
join SYSTABLESTAT c on A.SYSTEM_TABLE_NAME=c.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = c.SYSTEM_TABLE_SCHEMA and c.LAST_USED_TIMESTAMP >
(current date – 13 months)
WHERE COLUMN_NAME = ‘NUMCLI’
Cette exemple n’est pas parfait, mais il vous montre qu’avec le catalogue db2 et un peu de SQL vous pouvez avoir de nombreuses informations pertinentes sur cette dernière .
Vous pouvez par exemple avoir des informations statistiques sur vos colonnes par la vue SYSCOLUMNSTAT et une vue globale avec la vue SYSFILES qui permet d’avoir un bon résumé de vos fichiers
https://www.ibm.com/support/pages/node/6486897
Voici un lien qui vous présente les vues disponibles,
https://www.ibm.com/docs/en/i/7.5?topic=views-i-catalog-tables