Date source de vos programmes
On est amené quand on fait des analyses à regarder les dates de source, on constate que ces dates sont à null pour tous les objets de type ILE.
Vous avez une vue QSYS2.PROGRAM_INFO qui permet d’avoir ces informations sur les programmes, un peu comme la commande DSPPGM.
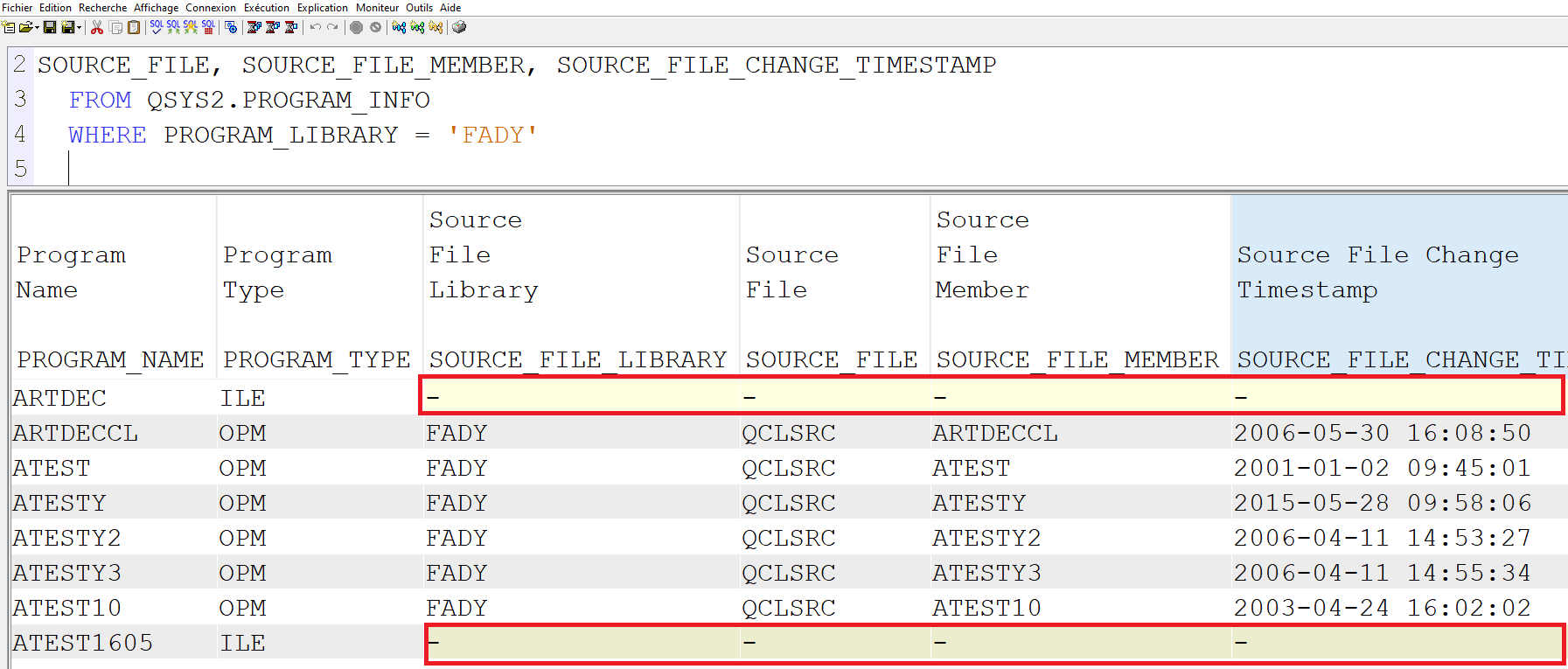
Voici pourquoi : quand vous travaillez en OPM vous compilez des sources qui deviennent des programmes; quand vous travaillez en ILE, vous compilez des sources qui deviennent des modules, puis vous les assemblez pour créer des programmes et du coup une date de source sur un programme ILE ne veut rien dire.
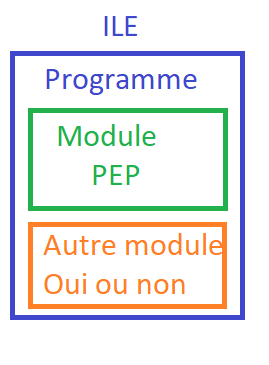
En réalité un programme a un module qui s’appelle point d’entrée programme qui, quand on travaille en BND (CRTBND*), est le seul module placé dans qtemp qui est assemblé pour créer votre programme.
On voit donc que si on veut, on peut assimiler la date du source du programme à la date du module PEP, qui dans plus de 99 % des cas a le même nom que le programme.
On a une deuxième vue permet d’avoir les modules par programme, QSYS2.BOUND_MODULE_INFO.
Il faudra donc combiner les 2 vues.
par exemple :
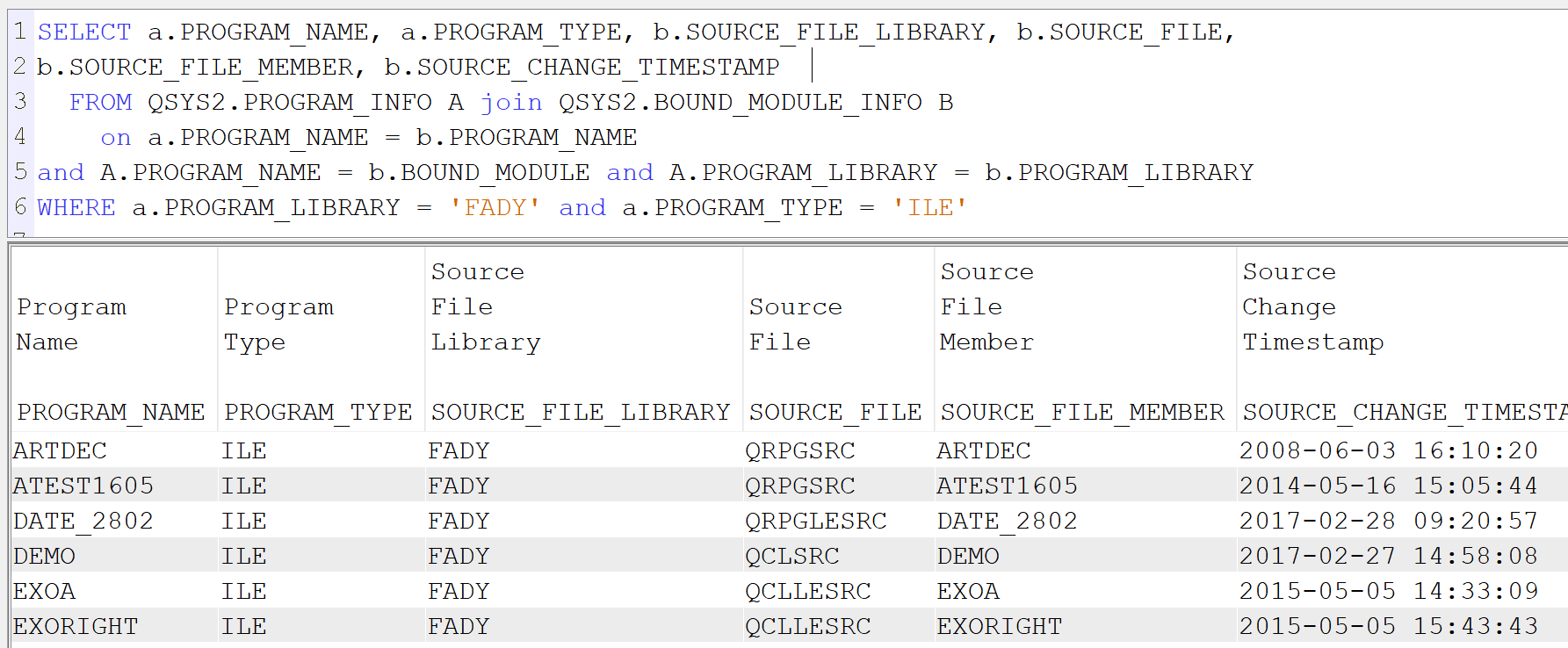
- Pour les programmes ILE
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, b.SOURCE_FILE_LIBRARY, b.SOURCE_FILE,
b.SOURCE_FILE_MEMBER, b.SOURCE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A join QSYS2.BOUND_MODULE_INFO B
on a.PROGRAM_NAME = b.PROGRAM_NAME
and A.PROGRAM_NAME = b.BOUND_MODULE and A.PROGRAM_LIBRARY = b.PROGRAM_LIBRARY
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘ILE’
- Pour les programmes OPM
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, A.SOURCE_FILE_LIBRARY, A.SOURCE_FILE, A.SOURCE_FILE_MEMBER,
A.SOURCE_FILE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘OPM’
en faisant l’union des deux requêtes vous aurez les dates de tous vos programmes ILE et OPM.
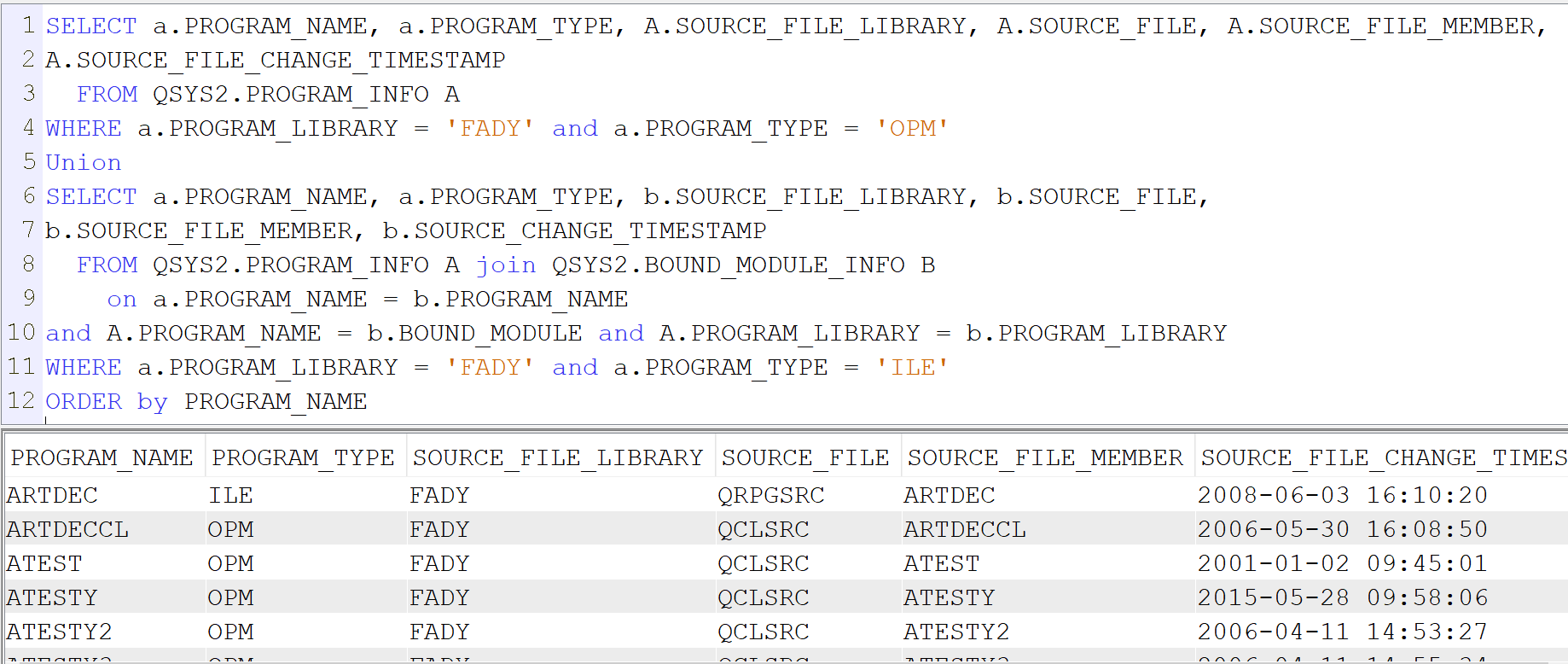
Il y a sans doute d’autres solutions mais celle-ci est très simple à utiliser.

Verrouiller vos sources pour VSCODE
Une des difficultés, quand on développe avec VSCE sur IBMi ,
C’est que si on est 2 deux à modifier le même source, c’est le dernier qui a raison avec perte de modification du premier même s’il a sauvegardé
Voici comment on peut améliorer les choses.
On va créer un fichier base de données qui liste les sources qui sont en cours de maintenance, un peu comme un ALM.
Avec GIT on peut arriver à des mécanismes identiques, et surtout, il faut commencer à mettre vos sources dans l’IFS directement
Voila comment, vous pouvez faire pour améliorer les choses
CREATE TABLE DB_OPENLCK (FICHIER CHAR ( 10) NOT NULL WITH
DEFAULT, BIBLIO CHAR ( 10) NOT NULL WITH DEFAULT, MEMBRE CHAR ( 10)
NOT NULL WITH DEFAULT, PARTAGE CHAR ( 3) NOT NULL WITH DEFAULT,
PUSER CHAR ( 10) NOT NULL WITH DEFAULT, PDATE DATE NOT NULL WITH
DEFAULT, PTIME TIME NOT NULL WITH DEFAULT)
Pour ajouter un source à verrouiller
INSERT INTO DB_OPENLCK VALUES(‘QRPGLESRC’, ‘GDATA’, ‘AAAA’,
‘NON’, ‘PLB’, current date, current time)
Et parmi les programmes d’exit il en a un qui va nous permettre de mettre en œuvre ce contrôle
C’est le QIBM_QDB_OPEN
On va donc écrire un programme, ici en SQLRPGLE
**free
//
// ce programme permet d'éviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
DS_parm likeds(ds_parm_t) ;
reponse int(10);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
// ds format DBOP0100
Dcl-DS ds_parm_t qualified template ;
taille_entete Int(10);
format Char(8);
offset_liste Int(10);
nbr_fichiers Int(10);
taille_liste Int(10);
job Char(10);
profil Char(10);
jobnbr Char(6);
cur_profil Char(10);
reste Char(1024);
End-DS;
// liste des fichiers dans notre cas un seul
Dcl-DS liste ;
fichier Char(10);
biblio Char(10);
membre Char(10);
filler Char(2);
typefichier Int(10);
sous_jacent Int(10);
access Char(4);
End-DS;
// variable de travail
Dcl-S partage char(4);
Dcl-S puser char(10);
ds_parm.offset_liste += 1;
dsply enc_user ;
liste = %subst(ds_parm : ds_parm.offset_liste :
ds_parm.taille_liste);
ds_parm.offset_liste += ds_parm.taille_liste;
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La régle mise en oeuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on a dit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = 1 ;
else ;
reponse = 0 ;
endif ;
// fin de programme
*inlr = *on; ici notre règle est la suivante
on autorise
Si le source n’est pas présent dans le fichier
Si l’utilisateur est le même que celui en cours
Si on a accepté le partage et donc le risque
Pour ajouter votre pgm exit
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
FORMAT(DBOP0100)
PGMNBR(1)
PGM(GDATA/OPENSRC)
REPLACE(*NO)
Quand on essaye d’accéder par VSCDE à notre source
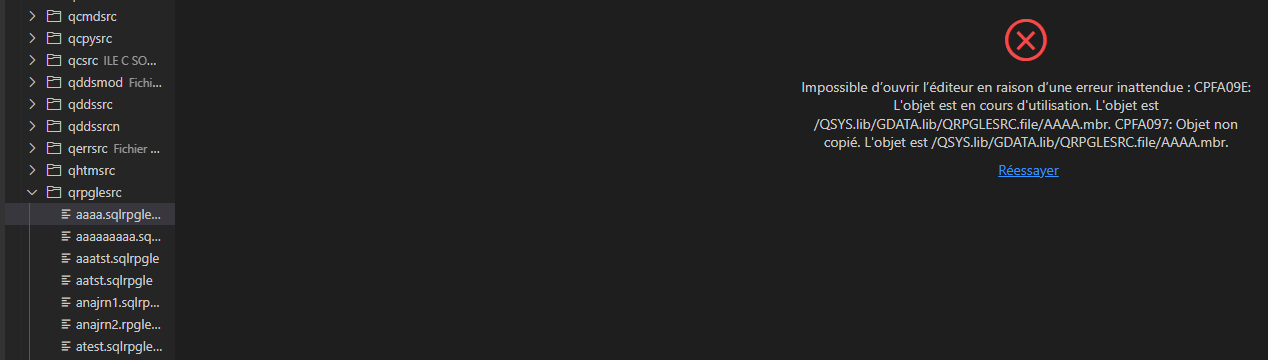
Remarque
Le contrôle marche aussi avec RDI
Il marche également pour SEU, parfois on préfère un contrôle spécifique SEU, vous devrez utiliser le programme d’exit
QIBM_QSU_ALW_EDIT en utilisant le même fichier par exemple !
**free
//
// Ce programme eviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
biblio char(10);
fichier char(10);
membre char(10);
reponse char(1);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
Dcl-S partage char(4);
Dcl-S puser char(10);
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La règle mise en œuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on adit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = '1' ;
else ;
reponse = '0' ;
endif ;
// fin de programme
*inlr = *on; On ajoute comme ca
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QSU_ALW_EDIT)
FORMAT(EXTP0100)
PGMNBR(1)
PGM(GDATA/OPENSRCE)
REPLACE(*NO)
Ca ne fait pas tout, que faire si on est 2 sur le même source ? peut être faut il avoir un source de référence pour éviter le versionnage
Remarque :
Pour diminuer le nombre d’appels du programme d’exit , vous pouvez limiter le déclenchement aux fichiers qui sont audités.
Vous devez indiquer le paramètre PGMDTA(*JOB *CALC ‘*OBJAUD’) sur les commandes ADDEXITPGM ou CHGEXITPGM.
Exemple :
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
…
PGMDTA(*JOB *CALC ‘*OBJAUD’)
Vous devez ensuite indiquer les fichiers à auditer :
Exemple :
CHGOBJAUD OBJ(GDATA/QRPGLESRC)
OBJTYPE(FILE) OBJAUD(CHANGE)
A partir de ce moment la, seuls les fichiers audités déclencheront l’appel du programme d’exit QIBM_QDB_OPEN
Exit pgm V7R5
Vous pouvez désormais mettre des points d’exit pour savoir quand un fichier IFS est ouvert ou fermé
QIBM_QP0L_OBJ_OPEN
QIBM_QP0L_OBJ_CLOSE
le format de data utilisé est le OBOP0100
exemple de programme en CLP
/*-------------------------------------------------------------------*/
/* exit pgm QIBM_QP0L_OBJ_OPEN FMT OBOP0100 */
/* Contrôle ouverture de fichier */
/*-------------------------------------------------------------------*/
pgm (&data &retour)
/* Paramètres */
dcl &data *char 512 /* Variable recue */
dcl &retour *char 4 /* Variable renvoyée */
/* 0 pour OK */
/* 1 pour KO */
/* Variables de travail */
DCL VAR(&USER) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&DATA 1)
DCL VAR(&EXT) TYPE(*CHAR) STG(*DEFINED) LEN(8) +
DEFVAR(&DATA 11)
DCL VAR(&TYPE) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&DATA 23)
DCL VAR(&FLAG) TYPE(*CHAR) STG(*DEFINED) LEN(4) +
DEFVAR(&DATA 28)
DCL VAR(&IDENT) TYPE(*CHAR) STG(*DEFINED) +
LEN(16) DEFVAR(&DATA 33)
DCL VAR(&PATHL) TYPE(*CHAR) STG(*DEFINED) LEN(4) +
DEFVAR(&DATA 49)
DCL VAR(&PATH) TYPE(*CHAR) STG(*DEFINED) +
LEN(256) DEFVAR(&DATA 53)
dcl &len *dec (5 0)
/* Conversion du path UTF16/UCS2 vers CCSID en cours */
CALL PGM(CVTUCS2) PARM((&PATH) (&PATH))
/* Longueur après conversion / 2 car UCS2 = 2 caractères */
chgvar &len (%BIN(&PATHL) / 2)
/*--------------------------------------------*/
/* Ici Votre traitement */
/*--------------------------------------------*/
SNDUSRMSG MSG('Fichier ' *BCAT %SST(&PATH 1 &LEN) +
*BCAT ', ouvert par ' *BCAT &USER) +
MSGTYPE(*INFO)
/*--------------------------------------------*/
/* Validation de la demande 0 pour OK */
/*--------------------------------------------*/
CHGVAR VAR(%BIN(&retour)) VALUE(0)
endpgm
pour l'attachement du programme au point d'exit
ADDEXITPGM EXITPNT(QIBM_QP0L_OBJ_OPEN)
FORMAT(OBOP0100)
PGMNBR(1)
PGM(PLB/PGMIFS)
THDSAFE(*YES)
REPLACE(*NO)
attention à bien mettre le paramètre THDSAFE(*YES)
Remarque :
Le path du fichier est déclaré en UCS2 ci joint un petit programme de conversion en RPGLE , utile si vous avez choisi d’écrire votre programme en CLLE
**free
// Programme de conversion CVTUCS2
// utf16/UCS2 vers ccsid en cours par défaut
Dcl-pi *N ;
I_zon ucs2(256) ; // soit une chaine de 128
O_zon char(256) ;
End-pi ;
O_zon = I_zon ;
*inlr = *on ;Pour être analysé par le point d’exit vos fichiers doivent avoir l’attribut *RUNEXIT
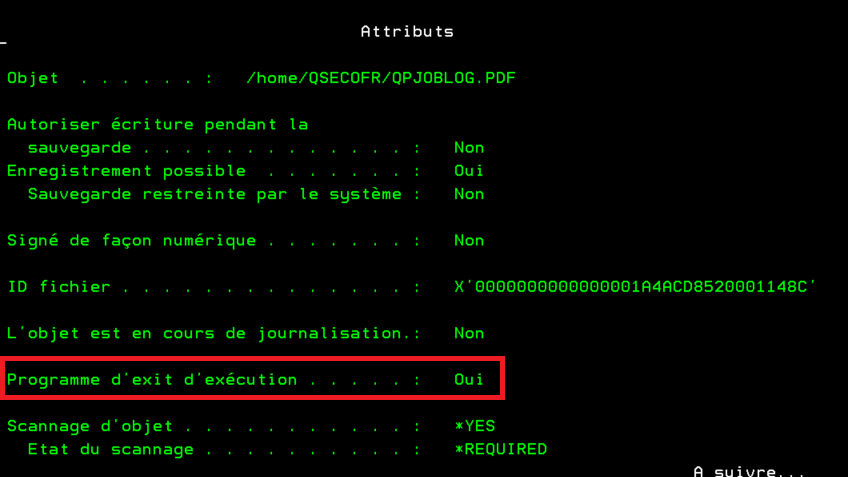
Pour le mettre sur un fichier
CHGATR OBJ(‘/home/QSECOFR/QPJOBLOG.PDF’) ATR(RUNEXIT) VALUE(YES)
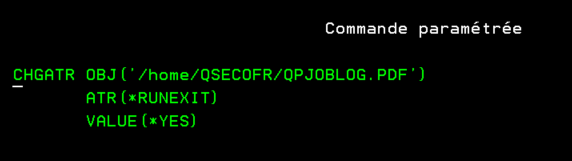
Pour le mettre sur tous les fichiers crées dans votre répertoire
CHGATR OBJ(‘/home/QSECOFR/’) ATR(CRTRUNEXIT) VALUE(YES)
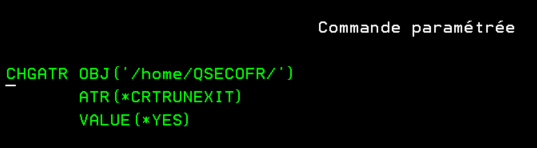
Cette information n’est pas encore disponible dans la vue QSYS2.IFS_OBJECT_STATISTICS
Transformation LF en index
Pourquoi transformer des DDS en SQL?
Une des raisons est que les index peuvent être beaucoup plus performants que les LF quand le moteur SQL les utilise.
Rappel
Pour transformer un PF en table
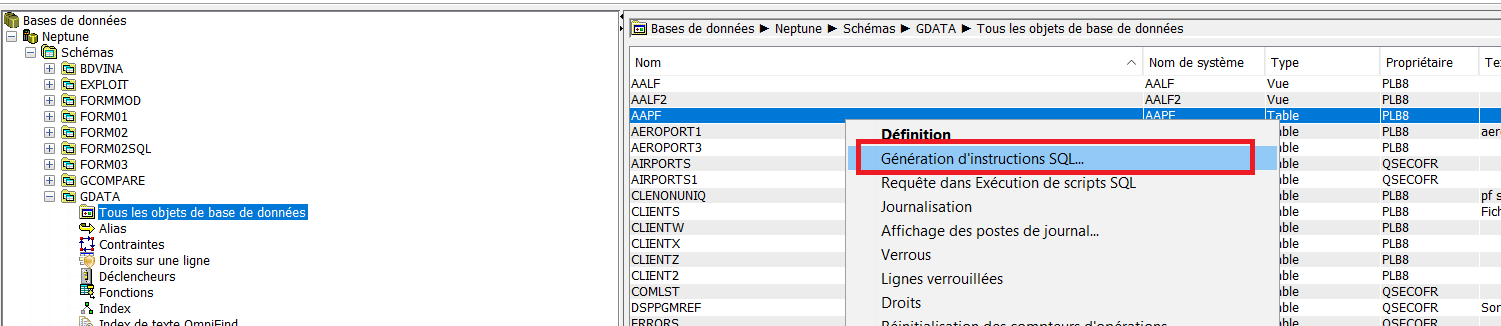
Vous devez extraire le source en utilisant l’API QSQGNDDL
Le plus simple est de passer par ACS
En faisant génération instruction SQL
Vous obtenez le source SQL qu’il aurait fallu pour générer cette table.
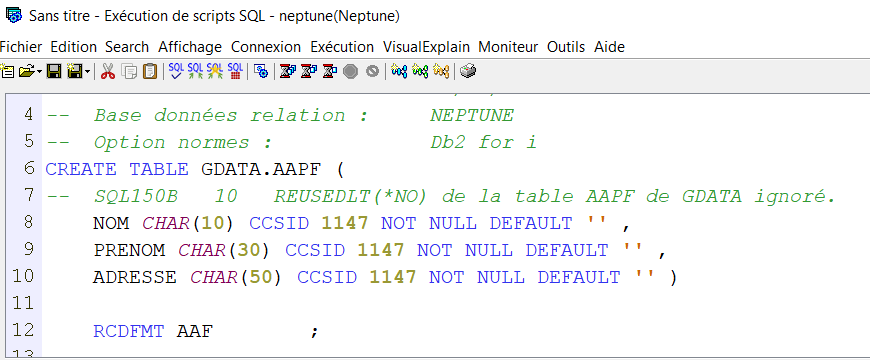
Attention tout n’est pas traduit (exemple un PF sans clé unique)
Pour transformer un LF en index sur nom par exemple

Si vous utilisez ACS, votre index est considéré comme une vue et si vous faites l’opération de génération SQL vous obtenez un source qui ne va pas vous servir à grand chose.
Remarque, par contre si vous regardez par Visual Explain vous voyez bien que le moteur utilise le PF comme un index.
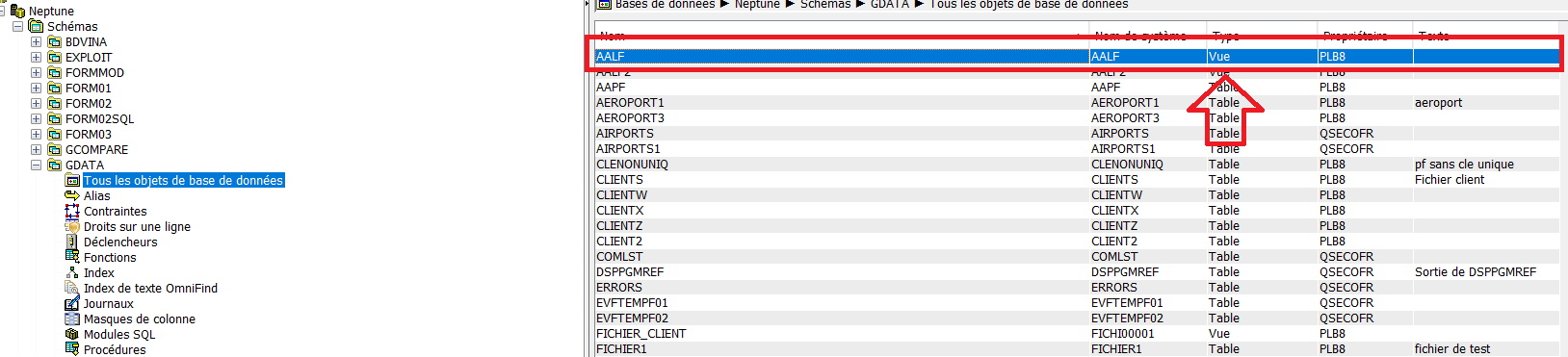
Si vous utilisez la procédure de QSYS2.GENERATE_SQL, même problème.
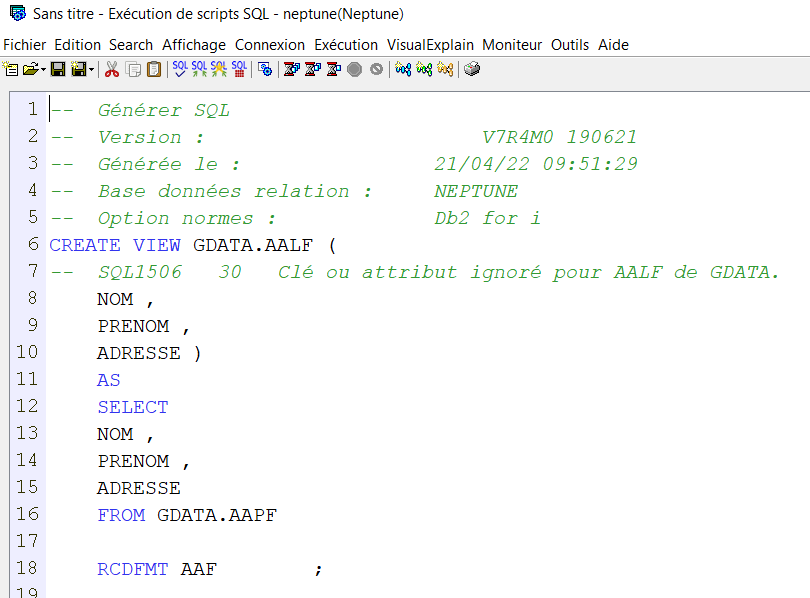
.
Si vous lui indiquez index, il ne trouve pas l’objet SQL
CALL QSYS2.GENERATE_SQL(‘AALF’, ‘GDATA’, ‘INDEX’,
‘QSQLSRC’, ‘GDATA’, ‘AALF’,
CREATE_OR_REPLACE_OPTION => ‘1’,
CONSTRAINT_OPTION => ‘2’);
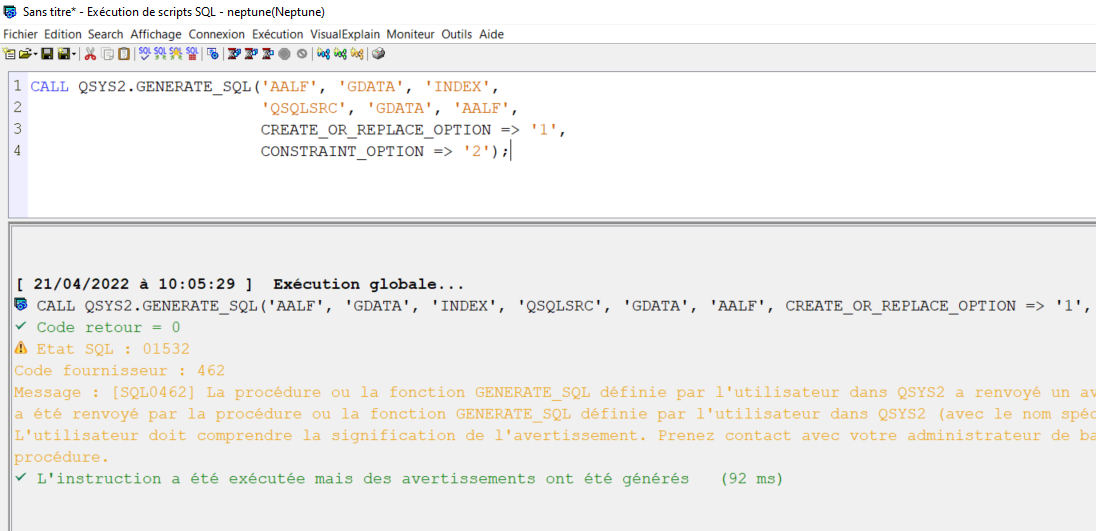
La solution est donc passer directement par l’API système QSQGNDDL.
Pour vous aider, on a fait une commande RTVSQLSRC que vous pouvez trouver ici
https://github.com/Plberthoin/PLB/tree/master/GOUTILS
et là vous pouvez forcer le type INDEX
RTVSQLSRC FILE(GDATA/AALF) SRCFILE(GDATA/QSQLSRC) TYPSQL(INDEX)
et là vous obtenez le source qui va bien
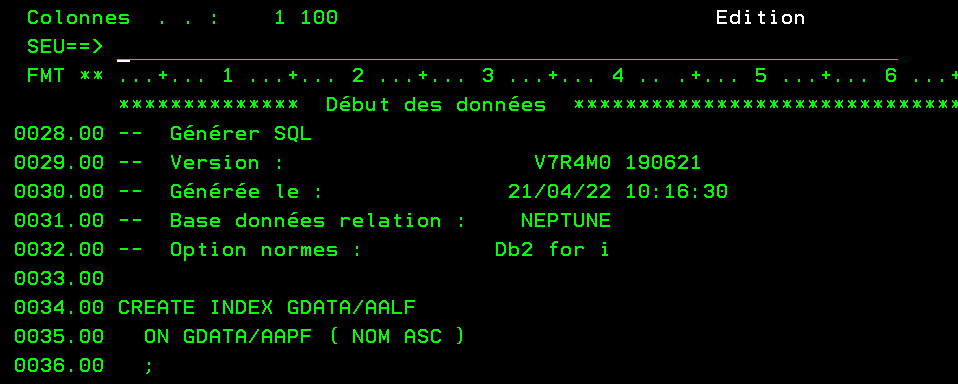
Même remarque que pour les PF (tout ne se traduit pas exemple LF avec sélection)
Une fois que vous avez le source il vous suffit alors de rejouer le script SQL.
Remarque :
Vous ne pouvez pas faire un create or replace , puisque SQL continue à voir le LF comme une vue.
Vous devez donc le supprimer avant le recréer.
Compléments apportés par Birgitta merci à elle
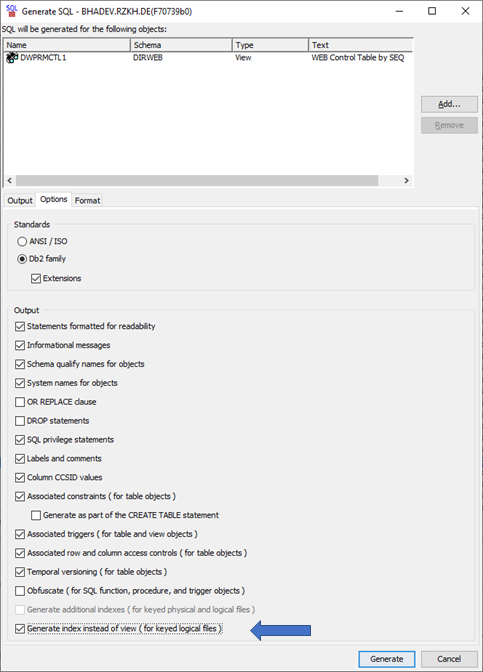
Il y a 2 options en GENERATE_SQL et le ACS wizard avec lesquelles on peut transformer LFs en index.
https://www.ibm.com/docs/en/i/7.4?topic=services-generate-sql-procedure
Out of the GENERATE_SQL documentation:
INDEX_INSTEAD_OF_VIEW – option:
The index instead of view option specifies whether a CREATE INDEX or CREATE VIEW statement will be generated for a DDS-created keyed logical file. The valid values are:
0 – A CREATE VIEW statement will be generated.
1 – A CREATE INDEX statement will be generated that matches the index for a DDS-created keyed logical file.
ADDITONAL_INDEX_OPTION:
The additional index option specifies whether additional CREATE INDEX statements will be generated for DDS-created keyed physical or logical files. The valid values are:
0 – Additional CREATE INDEX statements will not be generated.
1 – An additional CREATE INDEX statement will be generated that matches the index for a DDS-created keyed physical file. If the physical file has a PRIMARY KEY constraint, a CREATE INDEX statement is not generated.
An additional CREATE INDEX statement will be generated that matches the index for a DDS-created keyed logical file. If a value of ‘1’ is specified for the index instead of view option, an additional CREATE INDEX statement is not generated. Additional CREATE INDEX statements will also be generated that match the join indexes of a DDS-created join logical file.
Joblog pending
Sur votre système, il peut rester des logs à l’état pending, ce n’est pas normal, c’est des logs qui ne sont pas accessibles, mais qui sont là …
Vous pouvez facilement regarder cette information grâce à la vue QSYS2.SYSTEM_STATUS_INFO
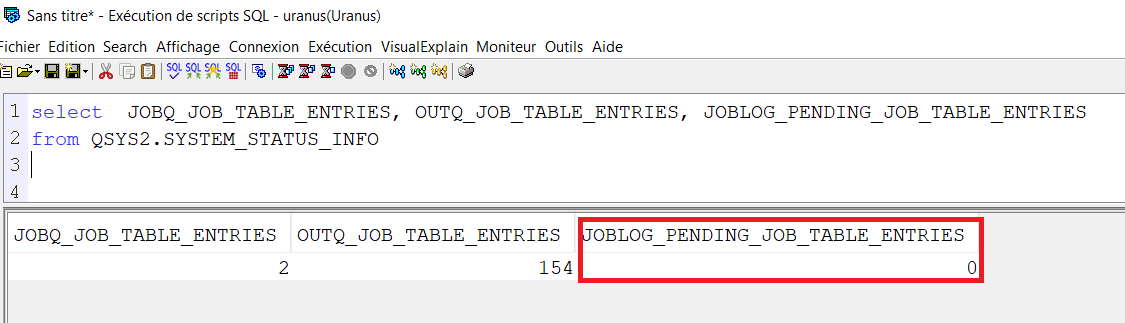
Vous devez d’abord vérifier la valeur système qui indique la production de ces logs.
c’est QLOGOUTPUT qui doit être à *JOBLOGSVR et non à *PND qui indiquerait au système de les laisser dans cet état là.
Pour supprimer ces spools inutiles vous devrez utiliser l’API QWTRMVJL
Voici un exemple d’utilisation vous pouvez la passer comme ceci
CALL PGM(QWTRMVJL) PARM(X’0000002C000000005CC1D3D34040404040405CC1D3D34040
404040405CC1D3D340405CC1D3D3404040404040′ ‘RJLS0100′ X’0000000000000000’)
Si vous repassez la requête pour contrôler :
select JOBQ_JOB_TABLE_ENTRIES, OUTQ_JOB_TABLE_ENTRIES, JOBLOG_PENDING_JOB_TABLE_ENTRIES
from QSYS2.SYSTEM_STATUS_INFO
Vous avez alors 0 dans la colonne JOBLOG_PENDING_JOB_TABLE_ENTRIES
Remarque
Si ça revient souvent vous devrez comprendre pourquoi ce phénomène se produit …
Ansible et IBM i
Qu’est-ce que Ansible ?
Ansible est un outil écrit en Python qui permet de faire des déploiements.
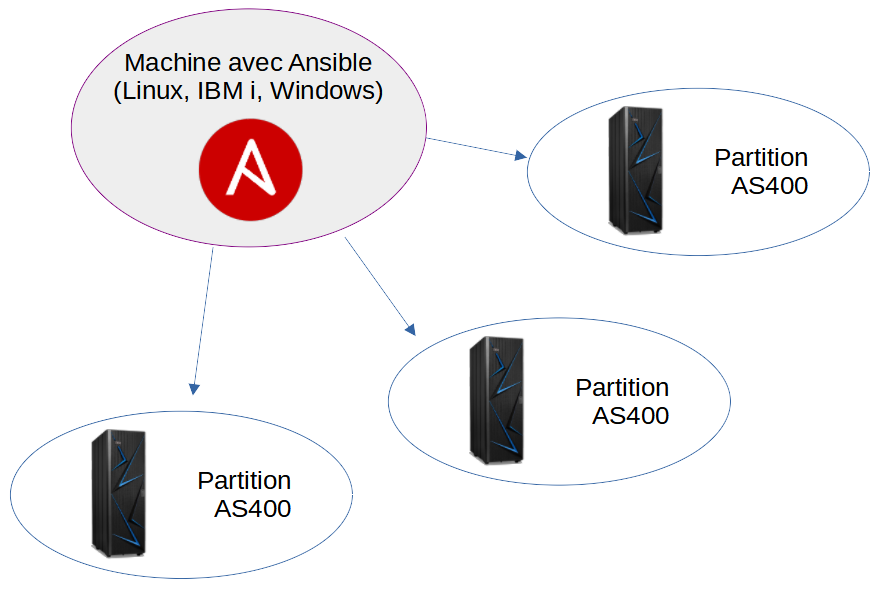
Ansible se sert de deux fichiers de configuration pour fonctionner.
Le premier est l’inventory, il regroupe les adresses réseau des machines qu’on souhaite gérer.
Le second est un playbook, il agit comme un script qu’on pourra exécuter sur n’importe laquelle des machines de l’inventory.
Tous les fichiers de configuration d’Ansible sont au format YAML.
À partir de ces deux fichiers Ansible établit des connexions SSH sur les machines de notre choix (depuis l’inventory), transfert le playbook sur les machines connectées, l’exécute et enfin fait remonter les résultats.
Cette approche permet de facilement réaliser n’importe quel type de déploiement à petite comme à grande échelle en écrivant un seul script, et en utilisant une seule commande.
Les résultats et les erreurs (si il y en a) sont tous remontés une fois que tout est fini.
Ansible est écrit en Python et l’utilise également pour exécuter les playbooks sur les machines, il faut donc que ce dernier soit installé sur les systèmes où l’on veut faire des déploiements.
Les actions qu’on peut demander à Ansible de réaliser sont des modules, qui permettent de réaliser une tâche spécifique.
Chaque tâche dans le playbook utilise un module, et on peut ajouter autant de tâches qu’on a besoin, comme dans un script.
Parmi les modules fournis avec Ansible on peut par exemple exécuter des commandes shell, manipuler des fichiers, en télécharger, etc.
L’intérêt du fonctionnement par modules c’est que tout le monde peut en écrire et on peut utiliser ceux qui sont publiés sur Ansible Galaxy par la communauté.
Cette plateforme regroupe des centaines de collections, qui contiennent un ou plusieurs modules. Il en existe déjà pour énormément de services et applications de toutes sortes (bien trop pour tous les citer ici).
Il y a également des collections fournies par IBM pour interagir avec leurs systèmes, notamment l’IBM i avec la collection power_ibmi.
Pour réaliser des plus petites tâches rapidement il est possible d’exécuter des commandes dites ad hoc. L’exécution sera la même qu’avec un playbook, sauf qu’il n’y aura pas besoin de créer un playbook, à la place on donne les paramètres du module directement dans la ligne de commande.
Cette méthode est très utile pour des actions simples et moins fréquentes, par exemple pour redémarrer toutes les machines d’un inventory.
Quelques exemples simples
Voici à quoi ressemble un inventory très simple qui liste deux machines (machineA et machineB).
all:
hosts:
machineA:
ansible_host: 10.0.0.1
machineB:
ansible_host: 10.0.0.2
vars:
ansible_ssh_user: rootLa partie vars permet de donner des paramètres supplémentaires pour les connexions SSH et l’exécution des modules.
Le paramètre ansible_ssh_user permet d’indiquer en tant que quel utilisateur Ansible doit se connecter par SSH, ici nous serons root.
Voilà désormais un playbook très simple également qui ne fait qu’un simple ping, cela permet de vérifier si Ansible peut se connecter aux machines et exécuter un playbook.
- name: playbook ping
gather_facts: no
hosts: all
tasks:
- ping:Le paramètre gather_facts est par défaut configuré sur yes. Le gather facts récupère des informations sur le système où le playbook s’exécute (système d’exploitation, environnement, versions de Python/Ansible, etc) qu’on peut ensuite utiliser dans le playbook ou afficher. Ici on ne souhaite faire qu’un ping pour vérifier qu’Ansible fonctionne bien, on peut désactiver le gather facts puisqu’on ne s’en sert pas.
Le paramètre hosts permet d’indiquer sur quels machines de l’inventory ce playbook doit être exécuté par défaut.
Le paramètre tasks liste chaque tâche à exécuter (avec le nom du module). Ici on utilise le module ansible.builtin.ping qu’on peut abréger en ping.
Pour exécuter ce playbook on utilise la commande ansible-playbook -i inventory.yml playbook.yml (en remplaçant bien entendu les noms des fichiers par ceux que vous avez).
Voici le résultat qu’on obtient avec l’inventory et le playbook précédents :
$ ansible-playbook -i inventory.yml ping.yml
PLAY [playbook ping] *****************************************************************
TASK [ping] **************************************************************************
ok: [machineA]
ok: [machineB]
PLAY RECAP ***************************************************************************
machineA : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
machineB : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Ansible nous rapporte que la tâche ping a réussi sur les deux machines. La partie PLAY RECAP résume les résultats de toutes les tâches.
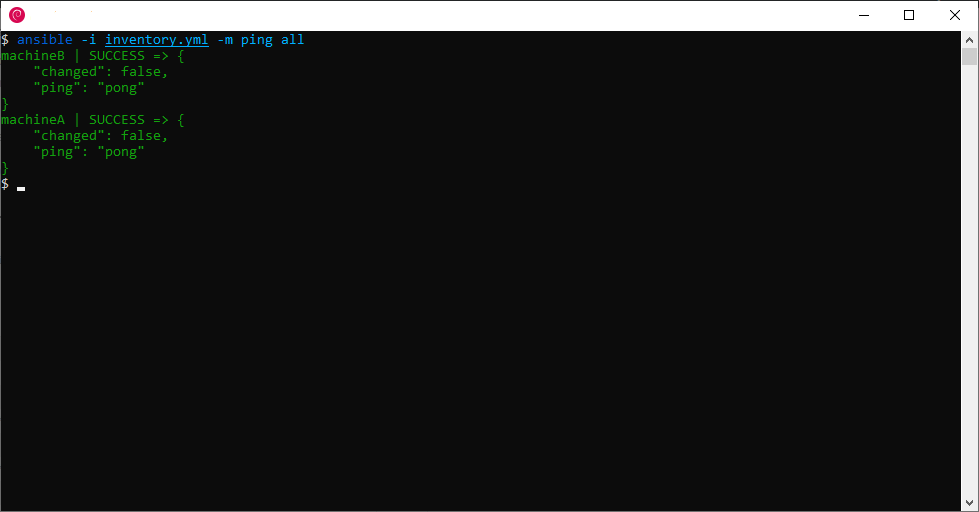
L’équivalent de ce playbook en mode Ad Hoc est la commande :
$ ansible -i inventory.yml -m ping allLe dernier paramètre all correspond au paramètre hosts du playbook, il indique d’exécuter la commande sur tous les hôtes présents dans l’inventory.
Le paramètre -m ping indique quel module utiliser (la documentation sur les commandes ad hoc est disponible ici).
Ansible for i
IBM fournit la collection power_ibmi qui contient beaucoup de modules pour interagir avec les IBM i, la documentation se trouve ici, et la référence des modules ici.
Cette collection est d’ailleurs disponible sur Github ici (avec plusieurs exemples et autres ressources).
Voici un exemple de playbook qui utilise cette collection, plus particulièrement le module ibmi_sysval. Ce playbook va récupérer une valeur système puis faire une assertion de sa valeur.
- hosts: all
gather_facts: no
collections:
- ibm.power_ibmi
tasks:
- name: Vérification CCSID
ibmi_sysval:
sysvalue:
- {'name': 'qccsid', 'expect': '1147'}Le paramètre collections indique qu’il faut d’abord chercher le module ibmi_sysval dans les collections énumérées (dans l’ordre) mais cette partie est optionnelle (comme indiqué dans la documentation ici).
Puis on indique que l’élément nommé qccsid dans la variable de retour sysvalue doit correspondre à la valeur 1147.
Voilà le résultat qu’on obtient lorsque la valeur système correspond :
$ ansible-playbook -i inventory.yml assert_ccsid.yml
PLAY [all] ***************************************************************************
TASK [Vérification CCSID] ************************************************************
ok: [machineA]
ok: [machineB]
PLAY RECAP ***************************************************************************
machineB : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
machineA : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Et si le QCCSID ne correspond pas Ansible affiche une erreur à la place de ok: [machine], au format JSON :
fatal: [machineA]: FAILED! =>
{
"changed": false,
"fail_list": [{
"check": "equal",
"compliant": false,
"expect": "1147",
"msg": "Compliant check failed",
"name": "QCCSID",
"rc": -2,
"type": "10i0",
"value": "65535"
}],
"message": "",
"msg": "non-zero return code when get system value:-2",
"rc": -2,
"stderr": "non-zero return code when get system value:-2",
"stderr_lines": ["non-zero return code when get system value:-2"],
"sysval": []
}Note: Dans le terminal cette erreur est souvent affichée sans indentation ni retours à la ligne.
Ici on peut voir que l’assertion a échoué, la valeur système était 65535, mais le playbook s’attendait à ce qu’elle soit 1147.
Il y a de nombreux autres cas d’usage, plusieurs exemples sont disponibles sur le dépôt Github ansible-for-i.
Il y a quelques exemples pour des utilisations spécifiques ici, et d’autres exemples de playbooks ici.
Interfaces graphiques : AWX et Tower
Ansible est un outil qui s’utilise dans le terminal, mais il existe deux solutions qui fournissent une interface graphique plus intuitive en plus d’autres fonctionnalités (planification de tâches, gestion de plusieurs utilisateurs et de leurs droits, notifications).
Ces deux solutions sont AWX et Tower, les deux sont très similaires : AWX est un projet open-source (disponible ici), et Tower (disponible ici) est une solution qui est basée sur AWX mais qui nécessite une licence.
La principale différence entre les deux est que Tower subit beaucoup plus de tests pour être plus stable et vous pouvez recevoir de l’aide du support technique Red Hat si besoin. AWX en revanche est moins testé et donc plus susceptible de rencontrer des instabilités, il n’y a également pas de support technique pour AWX.
Si la stabilité est une nécessité (comme en environnement de production) mieux vaut s’orienter vers Tower.
AWX est compatible sur Linux (les distributions les plus populaires devraient toutes le faire fonctionner), Tower est également compatible sur Linux mais est beaucoup restreint. Actuellement ce dernier n’est compatible que sur Red Hat Enterprise Linux (RHEL), CentOS et Ubuntu.
Nous avons testé AWX sur Debian (Bullseye), l’installation peut être assez compliquée lorsqu’on découvre AWX et son environnement mais son utilisation est plutôt intuitive.
L’interface et le fonctionnement de Tower sont quasiment identiques à AWX.
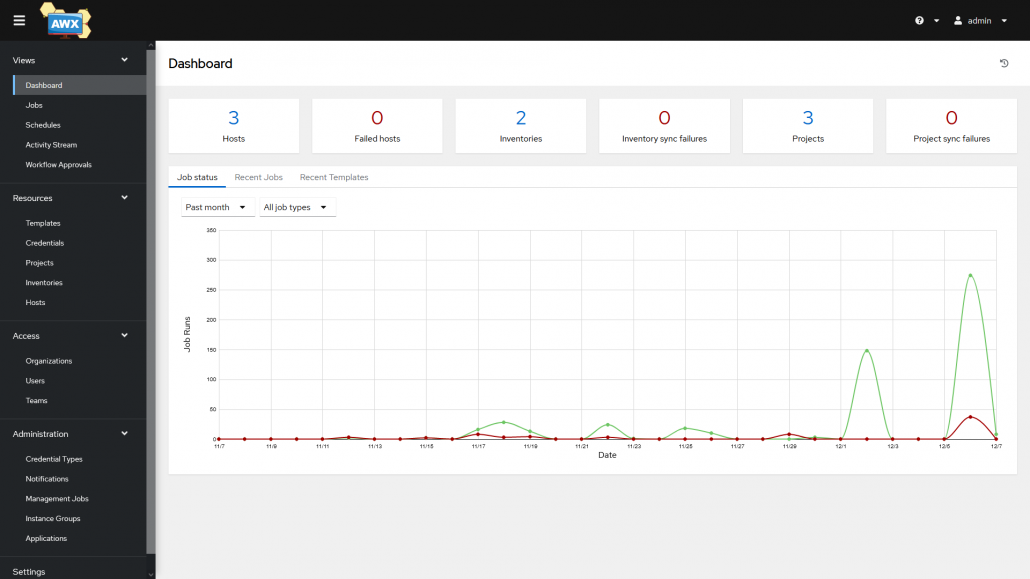
Il y a plusieurs différences dans la manière d’utiliser Ansible dans le terminal et depuis AWX.
La configuration des machines, de leurs identifiants et des inventory est similaire et très facile. En revanche pour les playbooks ce n’est pas la même méthode.
Premièrement on doit configurer un projet. Un projet est un groupe d’un ou plusieurs playbooks sous la forme d’un dépôt Git ou d’une archive.
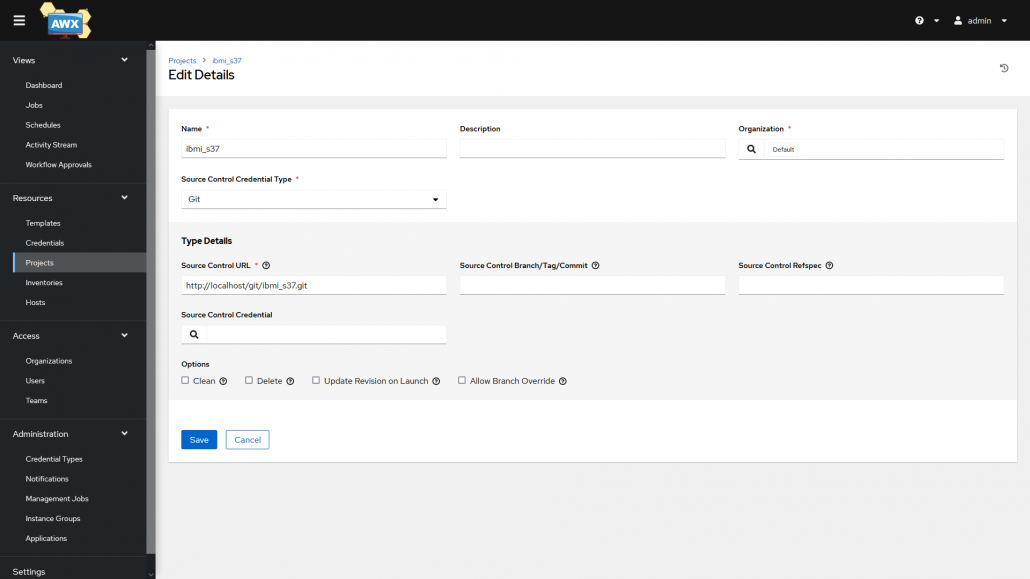
Ensuite il faut créer des templates, une template peut être considérée comme la commande pour exécuter un playbook : on choisit quel playbook exécuter depuis un projet, on choisit sur quel inventory l’exécuter et les identifiants à utiliser pour les connexions SSH sur les machines de l’inventory.
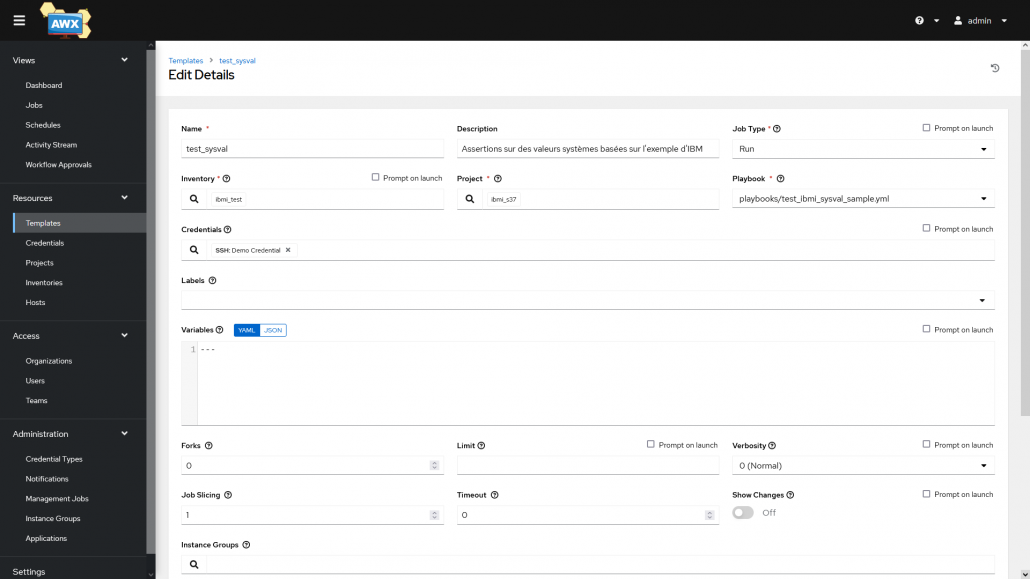
On peut ensuite exécuter les templates et suivre leurs avancements et résultats dans l’onglet Jobs ou depuis la page de la template.
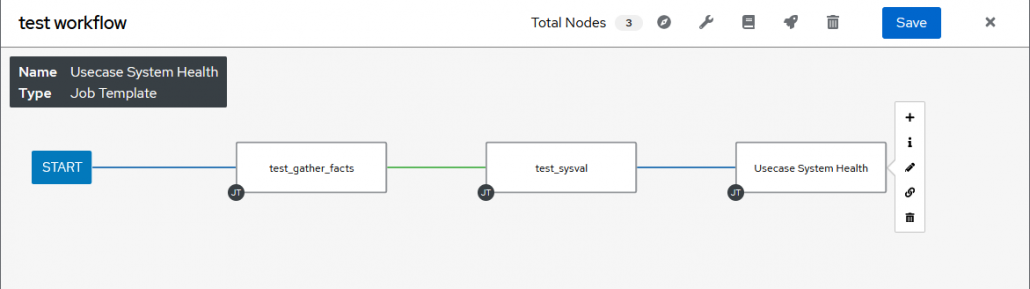
Dans l’onglet des templates on peut aussi créer des workflows, un workflow permet d’exécuter plusieurs templates à la suite en y ajoutant des conditions.
On peut choisir d’exécuter certaines templates si une autre réussit, et d’autres si elle échoue.
Ressources et liens utiles pour apprendre Ansible
Cette courte présentation vise à vous faire découvrir Ansible et ne couvre donc que les bases (beaucoup de détails ont été omis pour éviter la surcharge d’informations). Ansible est un outil très complet et il existe de nombreuses ressources pour apprendre à le prendre en main et le maîtriser.
En voici quelques unes pour bien débuter :
- Documentation officielle Ansible
- Ansible 101 – Ansible for beginners (introduction aux bases)
- Ansible Galaxy
- Tutoriels et formation Ansible par xavki (sur YouTube)
- Article d’IBM sur Ansible et l’IBM i
- Ansible support for IBM i
Ansible est un outil très puissant aux applications nombreuses, et peut notamment faciliter l’administration des IBM i (surtout à grande échelle). Malheureusement il n’existe à l’heure actuelle aucune solution clé en main, apprendre à utiliser Ansible et créer ses propres playbooks est indispensable.
Cet apprentissage peut prendre du temps sans expérience préalable avec les environnements Unix et/ou Python. Mais si Ansible peut paraître difficile à prendre en main et maîtriser, des solutions plus guidées et faciles d’accès pourraient arriver à l’avenir, permettant à tous d’utiliser Ansible à son plein potentiel sans avoir à le maîtriser chaque aspect.

Authentification par JWT (Json Web Token)
Pour mettre en place une authentification par JWT sur IBMi, on utilise l’API Qc3VerifySignature.
Le JWT
Il est composé de trois partie :
- Un entête (header)
- Une charge utile (payload)
- Une signature numérique
Pour obtenir la signature, il faut tout d’abord encoder séparément le header et le payload avec BaseURL64, ensuite, on les concatène en les séparant d’un point.
On calcule enfin une signature d’après le header et le payload afin de garantir que le jeton n’a pas été modifié, d’après l’algorithme défini dans le header (RS256, HS256, HS512, …). Cette signature binaire est elle-même encodée ensuite en Base64URL.
On obtient ainsi le JWT : { header }.{ payload }.{ signature }
Préparation
Afin de tester cette API, il faut dans un premier temps générer une clé au format PEM en suivant les étapes ci-dessous :
- openssl req -new -out monserveur.csr
Pour créer une demande certificate (.csr = certificat signing request)
Cela crée deux fichiers : monserveur.csr et privkey.pem
- openssl rsa -in privkey.pem -out monserveur.key
Cela crée le fichier monserveur.key (clé privée sans le mot de passe)
- openssl x509 -in monserveur.csr -out monserveur.cert -req -signkey monserveur.key
Cela crée le fichier monserveur.cert, qui est le certificat.
Paramètres d’appels de Qc3VerifySignature
- Signature
La signature est fournie en BASE64, il faut la convertir en binaire pour la fournir à l’API
- Longueur de signature
La longueur de la signature fournie après sa conversion
- Donnée à contrôler
{ header }.{ payload } en ASCII
- Longueur de la donnée à contrôler
- Format de la donnée à contrôler
- Description de l’algorithme
C’ ‘est une Data Structure qui contient les paramètres de l’algorithme.
- Format de la description de l’algorithme
- Description de la clé
C’ ‘est une Data Structure qui contient les paramètres de la clé.
- Format de la description de la clé
- Fournisseur de service cryptographique (0, 1 ou 2)
- Nom du périphérique de cryptographie (à blanc si fournisseur 1 ou 0)
- Code Erreur
C’est une Data Structure qui indique le code retour de l’exécution
Cinématique
Pour mettre en place l’appel à Qc3VerifySignature, nous avons défini les formats suivants :
- Données DATA0100 : La donnée est contrôlée sur sa valeur et sa longueur
- Algorithme ALGD0400 : Paramètres pour une opération de vérification de signature
- Clé KEYD0600 : Certificat PEM (voir paragraphe « Préparation »)
Données
On crée la donnée à contrôler en concaténant header et payload, séparés d’un point, comme expliqué au paragraphe précédent.
Exemple :

ATTENTION : Il faut, pour être utilisable, que celle-ci soit en ASCII. Pour ce faire on utilise le programme système QDCXLATE qui permet de faire de la conversion de chaines de caractères grâce à des tables système.
Data Structure du format ALGD0400 (algorithme) :
cipher INT(10) inz(50) // Code secret pour RSA , initialisé à 50
PKA CHAR(1) inz(1) // PKCS bloc 01
filler CHAR(3) inz(x’000000’) // Réservé : ce champ doit rester NULL
hash INT(10) inz(3) // Signature Algorithme de Hash 3=SHA256
Data Structure du format KEYD0600 (clé) :
keylen INT(10) // Longueur du certificat PEM
filler CHAR(4) inz(x’00000000′) // Réservé : ce champ doit rester NULL
key CHAR(4096) CCSID(65535) // Certificat PEM en ASCII
Code Retour
L’appel de l’API avec les paramètres choisis , retourne un Data Structure ErrorCode décrite ci-dessous :
bytesProv INT(10) inz( %size( ErrorCode ) ); // ou 64 pour voir MSGID
bytesAvail INT(10) inz(0);
MSGID CHAR(7);
filler CHAR (1);
data CHAR (48);
Dans le cas où la signature est vérifiée, les valeurs retour sont les suivantes
- BYTESPROV = 64
- BYTESAVAIL = 0
- MSGID = ‘ ‘
- FILLER = ‘ ‘
- DATA = ‘ ‘
Si la signature n’est pas vérifiée, les valeurs retour seront :
- BYTESPROV = 64
- BYTESAVAIL = 15
- MSGID = ‘CPF9DEF’
- FILLER = ‘0’
- DATA = ‘ ‘
QCMDEXC en Fonction SQL
Depuis la TR4 de la version V7R4, vous pouvez utiliser la fonction QCMDEXC
C’est l’occasion de faire un rappel sur les différents usages disponibles jusque la
1 ) C’est une API (un programme) que vous pouvez appelez depuis un programme RPG ou CLP
en RPGLE
Dcl-Pr Exec_Commande QCMDEXC ExtPgm(‘QCMDEXC’);
Cmd Char(3000) Const;
CmdLen packed(15:5) Const;
End-Pr;
Dcl-S Gbl_Cmd Char(3000);
Gbl_Cmd = ‘Votre commande’ ;
Exec_commande(Gbl_Cmd : %len(Gbl_Cmd)) ;
En CLLE
PGM
DCL &CMD *CHAR 300
DCL &LEN *DEC (15 5)
CHGVAR &CMD (‘VOTRE COMMANDE’)
CHGVAR &LEN %LEN(&CMD)
CALL QCMDEXC (&CMD &LEN)
2) C’est une procédure SQL
call qcmdexc(‘votre commande’)
en SQL embarqué
Dcl-S Gbl_Cmd Char(3000);
call qcmdexc(:Gbl_Cmd)
3) C’est une Fonction SQL à partir de la TR4
Réorganisation des fichiers BD
SELECT qcmdexc(‘RGZPFM FILE(‘ concat
trim(substr(TABLE_SCHEMA, 1 , 10))
concat ‘/’ concat
substr(TABLE_NAME, 1 , 10) concat ‘)’) as résultat
FROM systables WHERE TABLE_SCHEMA =
‘GDATA’ and FILE_TYPE = ‘D’
la fonction renvoi 1 si ok et -1 si ko
Conclusion :
Vous avez un aperçu des possibilités qcmdexc sur la machine, à vous de jouer !
UTILISATION DES API EN SQL
Récupérer une API
Il existe un grand nombre d’API aux fonctionnalités diverses dont certaines nous permettent de récupérer des données structurées dans différents formats (XML, JSON, …).
Grace aux fonctions SQL de l’IBMi nous pouvons récupérer ces données pour les insérer dans les fichiers de la base de données.
Pour les exemples qui suivent, on se base sur trois API tirées du site https://openweathermap.org/ :
- Une première qui récupère la météo dans une ville donnée
https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=xml’
- Une qui récupère jusqu’à 50 communes autour de coordonnées choisies
https://api.openweathermap.org/data/2.5/find?lat=45.75&lon=4.5833&cnt=50&appid={API key}&mode=xml
- Une qui récupère jusqu’à des communes dans un rectangle de coordonnées choisies
https:// api.openweathermap.org/data/2.5/box/city?bbox=4,45,8,46,50&appid={API key}
Extraire les données de l’API
Sortie API en XML
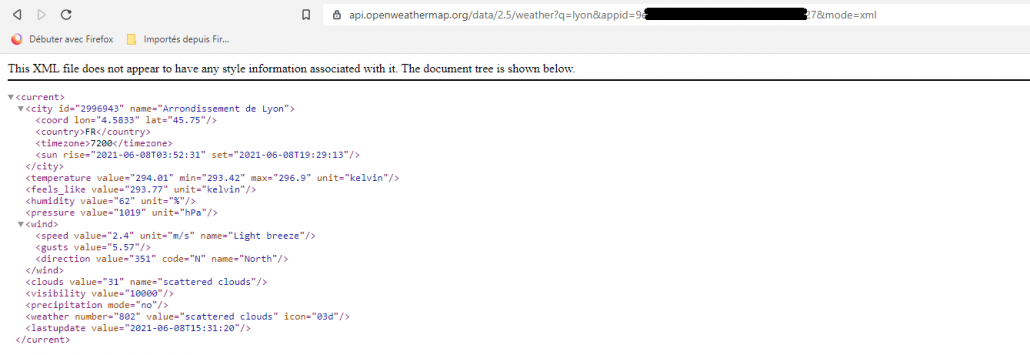
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values
char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=xml',''), 4096))
ws(data);

Sortie API en JSON

La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values
char(SYSTOOLS.HTTPGETCLOB('api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}',''), 4096))
ws(data);

Sortie API en HTML

La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values
char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=html',''), 4096))
ws(data);

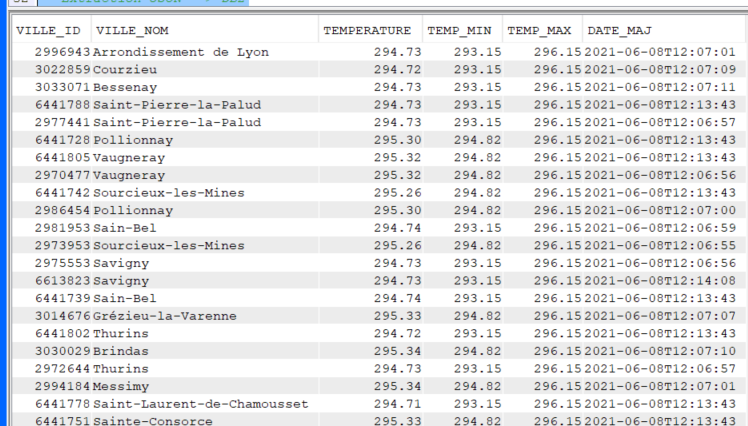
Récupération des données
En XML
On crée un fichier qui contiendra les colonnes que l’on veut récupérer (Ville, Température en cours, date, …)
CREATE TABLE GG/METEODB;
(VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT,
VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT,
TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT,
TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT,
TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT,
DATE_MAJ CHAR (20) NOT NULL WITH DEFAULT)
Récupérer les données de l’API dans le fichier créé :
INSERT INTO GG.METEODB
select xdata.* FROM xmltable('$doc/cities/list/item'
PASSING XMLPARSE(document SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/find?lat=45.75&lon=4.5833&cnt=10&appid={API key}&mode=xml','')) AS "doc"
COLUMNS
ville_id decimal(9, 0) PATH 'city/@id',
ville_nom varchar(50) PATH 'city/@name',
temperature decimal(5, 2) PATH 'temperature/@value',
temp_min decimal(5, 2) PATH 'temperature/@min',
temp_max decimal(5, 2) PATH 'temperature/@max',
date_maj varchar(20) PATH 'lastupdate/@value' ) as xdata;

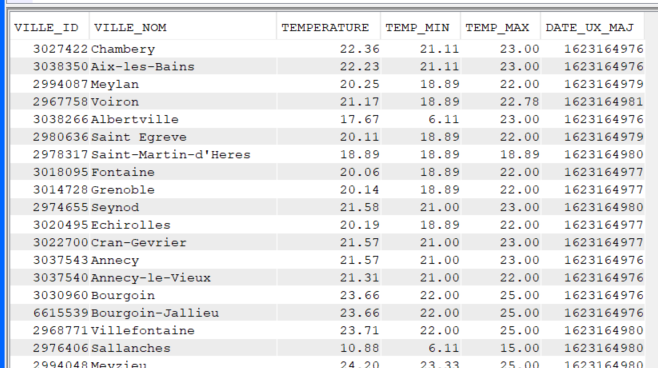
En JSON
Contrairement à XML, on peut créer tout de suite un fichier qui contiendra les colonnes que l’on veut récupérer.
CREATE TABLE GG.METEOBD
(VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT,
VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT,
TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT,
TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT,
TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT,
DATE_UX_MAJ DECIMAL (12, 0) NOT NULL WITH DEFAULT)
Récupérer les données de l’API dans le fichier créé :
INSERT INTO GG.METEOBD
select * from JSON_TABLE(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/box/city?bbox=4,45,8,46,50&appid={API key}','') ,
'$.list[*]'
COLUMNS
(ville_id decimal(9, 0) PATH '$.id',
ville_nom varchar(50) PATH '$.name',
temperature decimal(5, 2) PATH '$.main.temp',
temp_min decimal(5, 2) PATH '$.main.temp_min',
temp_max decimal(5, 2) PATH '$.main.temp_max',
date_ux_maj decimal(12, 0) PATH '$.dt'));

Pour aller plus loin
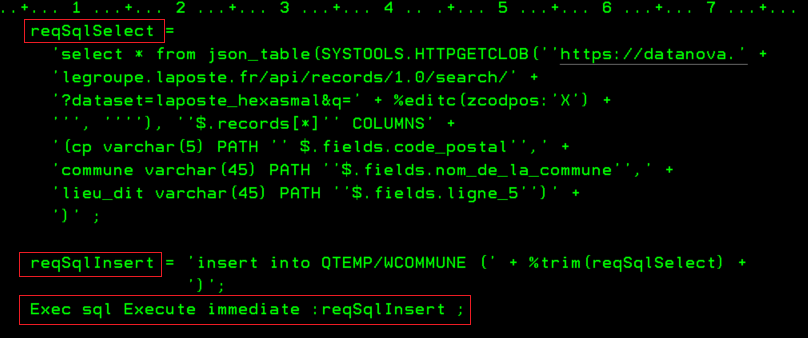
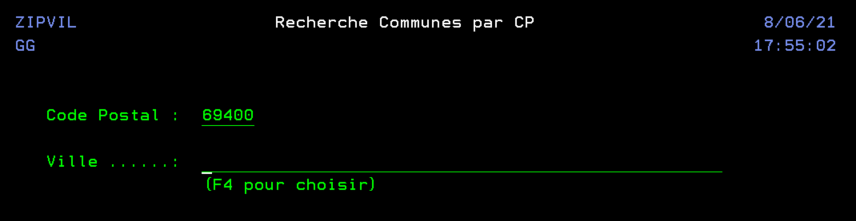
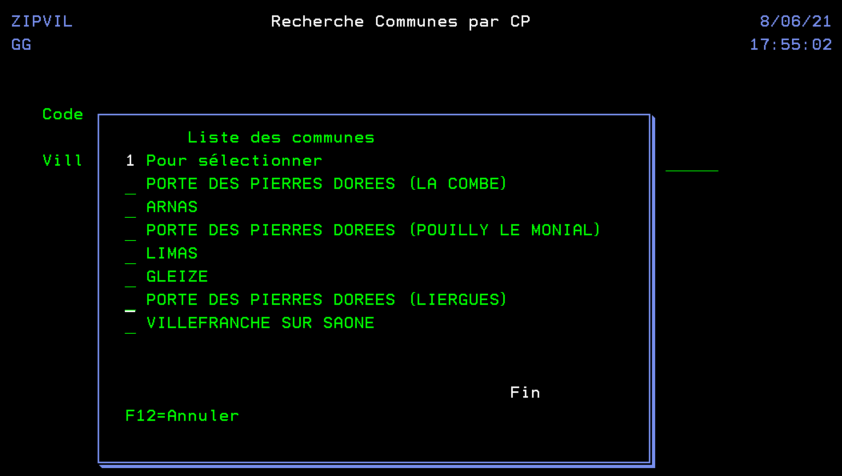
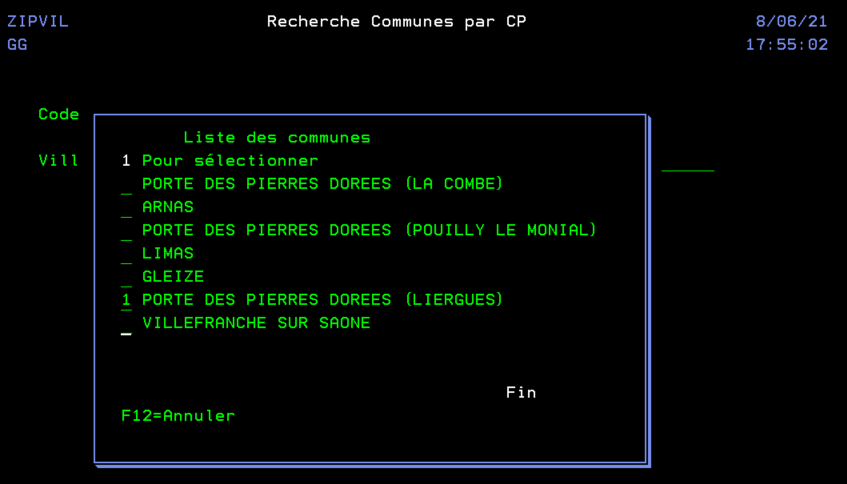
En utilisant une API de LA POSTE qui ne nécessite pas d’inscription au préalable, ni d’identification. Nous pouvons réaliser un programme qui nous aide à retrouver une commune à partir d’un code postal, dans l’optique d’aider au remplissage de certains formulaires.
On crée un fichier temporaire en interrogeant directement l’API.