

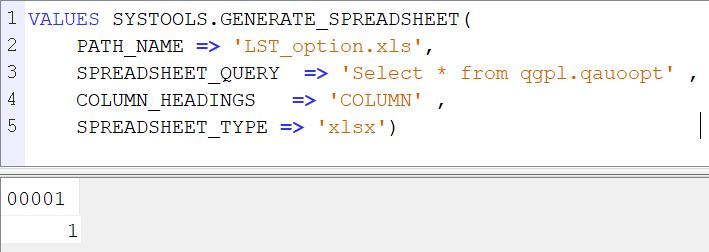
La TR 3 de la V7R5 nous apporte un nouveau service qui va permettre de générer un fichier XLS à partir d’une requête SQL
Exemple :
VALUES SYSTOOLS.GENERATE_SPREADSHEET(
PATH_NAME => ‘LST_option.xls’,
SPREADSHEET_QUERY => ‘Select * from qgpl.qauoopt’ ,
COLUMN_HEADINGS => ‘COLUMN’ ,
SPREADSHEET_TYPE => ‘xlsx’)
Remarque:
ACS doit être installé sur votre partition et si possible à jour
Attention par défaut il génère du csv
Pour les nouveaux développeur sur l’IBMi l’utilisation des indicateurs n’est pas naturel, voici comment on peut les diminuer
1) En utilisant l’INFDS pour tester les touches de fonction
2) En utilisant une zone attribut pour les DSPATR
Attention vous ne pourrez pas tous les remplacer
https://www.ibm.com/docs/fr/i/7.5?topic=80-dspatr-display-attribute-keyword-display-files
Voici un exemple
A*
A DSPSIZ(24 80 *DS3)
A CA03
A R FMT01
A*
A OVERLAY
A 1 28'Test TOUCHES INFDS/ ATTRIBUT'
A 3 2'Text'
A ZONE 12A B 3 9DSPATR(&ATTRIB)
A ATTRIB 1A P
A 22 3'F3=Exit' **free
// Exemple d'utilisation d'un écran
// Sans indicateurs
//
Dcl-F TOUCHE WORKSTN INFDS(FICHIERDS) ;
/INCLUDE INFDS_INC
/INCLUDE TOUCHE_INC
/INCLUDE ATTR_INC
// initialisation des attributs
Zone = 'Welcome';
ATTRIB = P_HI;
// Boucle su F3
DOU Touche_Ecran = F3 ;
Exfmt FMT01 ;
ENDDO ;
//
*inlr = *on ; Vous retrouverez les inculde ici
Vous avez besoin d’avoir un écran qui se met à jour automatiquement voici un exemple qui fait ca.
Cette une barre d’avancement qui rafraichit également l’heure affichée.


DSPF
A DSPSIZ(24 80 *DS3)
A CA03(03)
A* Test écran en réaffichage auto
A*
A R FMT01
A*%%TS SD 20231026 124638 PLB REL-V7R4M0 5770-WDS
A PUTOVR
A OVRDTA
A OVRATR
A 5 27'Barre d''avancement'
A DSPATR(HI)
A TEXTE 50A O 11 15
A 22 4'F3=Exit'
A STATUS 15A O 9 27 CLLE
/* Ecran en mise à jour automatique */
PGM
DCLF reaf
dcl &i *int
dcl &wtime *char 6
chgvar &lancer 'Appuyez sur <ENTER> pour démarrer'
chgvar &status 'Arrêté '
rtvsysval qtime &wtime
chgvar &time (%sst(&wtime 1 2) *tcat ':' *tcat +
%sst(&wtime 3 2) *tcat ':' *tcat +
%sst(&wtime 5 2))
SNDRCVF RCDFMT(FMT01) WAIT(*YES)
DOUNTIL COND(&IN03)
if cond(&in03) then(leave)
chgvar &lancer ' '
chgvar &status 'Démarré'
DOFOR VAR(&I) FROM(1) TO(50)
DLYJOB DLY(1)
rtvsysval qtime &wtime
chgvar &time (%sst(&wtime 1 2) *tcat ':' *tcat +
%sst(&wtime 3 2) *tcat ':' *tcat +
%sst(&wtime 5 2))
chgvar &texte (&texte *tcat '>')
SNDRCVF RCDFMT(FMT01) WAIT(*NO)
enddo
chgvar &texte ('Chargé ')
SNDRCVF RCDFMT(FMT01) WAIT(*NO)
DLYJOB DLY(2)
chgvar &in03 '1'
enddo
ENDPGM Remarque :
Votre écran doit être compiler avec l’option DFRWRT(*NO)
Vous voulez utiliser la souris dans un dspf sur dans un de vos programmes
voici un exemple en CLLE:
DSPF :
A DSPSIZ(24 80 *DS3)
A CA03(03)
A* EVENNEMENT SOURIS
A* UNSHIFT / LEFT / PRESS
A R FMT01
A*%%TS SD 20231025 171347 QSECOFR REL-V7R4M0 5770-WDS
A MOUBTN(*ULP ENTER)
A RTNCSRLOC(*MOUSE &L1 &C1 &L2 &C2)
A* RÉCUPÉRATION DU CURSEUR
A L1 3S 0H
A C1 3S 0H
A L2 3S 0H
A C2 3S 0H
A 3 13'Tester la position de la souris'
A 5 13'En faisant un clic Gauche.'
A* BOUTON BAS DE PAGE
A F1B 2Y 0B 23 2PSHBTNFLD
A PSHBTNCHC(1 'F3=>Exit' CA03)CLLE
pgm
dclf mouse
DOUNTIL COND(&IN03)
SNDRCVF RCDFMT(FMT01)
if cond(*not &in03) then(do)
SNDUSRMSG MSG('Position du curseur ligne =' *BCAT +
%CHAR(&L1) *BCAT 'et colonne =' *BCAT +
%CHAR(&C1)) MSGTYPE(*INFO)
enddo
ENDDO
endpgm Remarque:
Vous devez compiler avec l’option ENHDSP(*YES)
C’est la possibilité d’avoir un menu déroulant dans vos DSPF avec plusieurs onglets et de choisir une option, exactement comme dans windows.
Ci dessous un exemple avec son programme 2 menus déroulants ici PULLA et PULLB
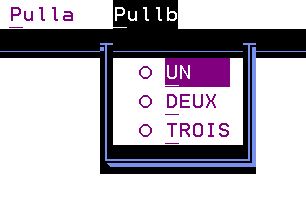
DSPF
A* Exemple de menu barre
A DSPSIZ(27 132 *DS4)
A MNUCNL(CA12)
A CA03(03 'EXIT')
A R MB MNUBAR
A MNUFLD 2Y 0B 1 2
A MNUBARCHC(1 PULLA +
A '>Pulla')
A MNUBARCHC(2 PULLB +
A '>Pullb')
A MNUBARSEP( +
A (*CHAR '_'))
A
A R RECORD
A*%%TS SD 20231025 122354 PLB REL-V7R4M0 5770-WDS
A MNUBARDSP(MB &MNUCHC &PULL)
A 11 2'Nom :'
A ZONE1 30A B 11 14
A 12 2'Prénom :'
A ZONE2 20A B 12 14
A MNUCHC 2Y 0H
A PULL 2S 0H
A 13 2'Sexe :'
A F1S 2Y 0B 13 14SNGCHCFLD(*AUTOSLT (*NUMCOL 3))
A CHOICE(1 '>Homme ')
A CHOICE(2 '>Femme ')
A CHOICE(3 '>Inconnu')
A 14 2'Langue(s):'
A F1M 2Y 0B 14 14MLTCHCFLD((*NUMCOL 4))
A CHOICE(1 '>Anglais')
A CHCCTL(1 &CHOIX1)
A CHOICE(2 '>Espagnol')
A CHCCTL(2 &CHOIX2)
A CHOICE(3 'Alleman>d')
A CHCCTL(3 &CHOIX3)
A CHOICE(4 '>Italien ')
A CHCCTL(4 &CHOIX4)
A* CHOICE(5 'A>utre ')
A* CHCCTL(5 &CHOIX5)
A CHOIX1 1Y 0H
A CHOIX2 1Y 0H
A CHOIX3 1Y 0H
A CHOIX4 1Y 0H
A* CHOIX5 1Y 0H
A* Bas de page
A F1B 2Y 0B 23 2PSHBTNFLD
A PSHBTNCHC(1 'F3=>Exit' CA03)
A PSHBTNCHC(2 'E>nter')
A 9 3'Renseignements'
A R PULLA PULLDOWN
A F1 2Y 0B 1 02SNGCHCFLD(*AUTOENT)
A CHOICE(1 '>UN ')
A CHCCTL(1 &C1)
A CHOICE(2 '>DEUX')
A CHCCTL(2 &C2)
A CHOICE(3 '>TROIS')
A CHCCTL(3 &C3)
A C1 1Y 0H
A C2 1Y 0H
A C3 1Y 0H
A R PULLB PULLDOWN
A F1 2Y 0B 1 02SNGCHCFLD
A CHOICE(1 '>UN')
A CHCCTL(1 &C21)
A CHOICE(2 '>DEUX')
A CHCCTL(2 &C22)
A CHOICE(3 '>TROIS')
A CHCCTL(3 &C23)
A C21 1Y 0H
A C22 1Y 0H
A C23 1Y 0H
A
RPGLE
**FREE
// exemple de menu barre
Dcl-F MNUBAR WORKSTN ;
CLEAR RECORD ;
DoW *IN03 = '0';
Exfmt RECORD;
If *IN03 = '0';
If PULL > 0;
Select ;
When PULL = 1;
DSPLY 'Un' ;
When PULL = 2;
DSPLY 'Deux' ;
when PULL = 3;
DSPLY 'Trois' ;
Endsl;
// ici traitement des zones du format
EndIf;
EndIf;
EndDo;
*INLR = *On;Remarque :
Vous devez compiler avec l’option ENHDSP(*YES)
Pour la présentation, cet exemple comporte également
Un bouton poussoir pour les touches de fonctions
un exemple de case a cocher unique
un exemple de case à cocher multiple
Pour commencer c’est un peu compliqué, pour vous aider, vous pouvez utiliser notre générateur téléchargeable ici …
https://github.com/Plberthoin/PLB/tree/master/GENMNUBAR
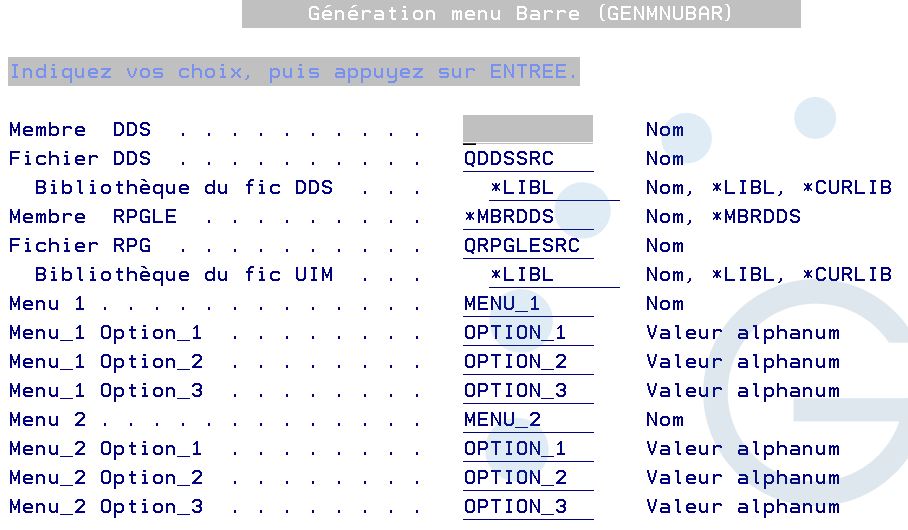
Génère un menu barre (Source DDS et RPGLE) ci dessus le code RPGLE généré

Vous devez « juste » remplacer les dsply par vos actions …
C’est la possibilité d’avoir plusieurs messages d’erreur et de pouvoir paginer dessus
Vous pouvez programmer un sous fichier message, mais ca peut être un peu compliqué à réaliser.
Voici une solution simple, il suffit de mettre le mot clé ERRSFL au niveau fichier écran
![]()
Ci dessous un exemple avec son programme en CLLE
DSPF
A* Exemple sous fichier d'erreurs
A DSPSIZ(24 80 *DS3)
A ERRSFL
A CA03(03)
A R FMT01
A ZONE1 10A B 11 20
A 41 ERRMSG('Erreur ZONE 1' 41)
A ZONE2 10A B 12 20
A 42 ERRMSG('Erreur ZONE 2' 42)
A ZONE3 10A B 13 20
A 43 ERRMSG('Erreur ZONE 3' 43)
A 6 8'Sous fichier d''erreur'
A DSPATR(HI)
A 11 8'Zone 1 :'
A 12 8'Zone 2 :'
A 13 8'Zone 3 :' CLLE
/* Exemple sous fichier message d'erreur */
PGM
DCLF ERREUR
dountil &in03
SNDRCVF RCDFMT(FMT01)
IF COND(*NOT &IN03) THEN(DO)
/* activation des indicateurs d'erreur */
CHGVAR &IN41 '1'
CHGVAR &IN42 '1'
CHGVAR &IN43 '1'
enddo
enddo
ENDPGM Remarque:
La seule limitation, c’est une seule erreur par zone, mais ca suffit dans 90 % des cas
Vous pouvez utilisez des sous fichiers pour faire des sélections par case à cocher, ce qui améliore la gestion des écrans pour les utilisateurs
Voici 2 exemples
Mot clé SFLSNGCHC,
https://www.ibm.com/docs/en/i/7.4?topic=dkedfp4t8-sflsngchc-subfile-single-choice-selection-list-keyword-display-files

Le DSPF
A*%%TS SD 20231024 203749 QSECOFR REL-V7R4M0 5770-WDS
A* SOUS FICHIER À CHOIX MULTIPLE
A*
A*%%EC
A DSPSIZ(24 80 *DS3)
A CA03(03)
A R SFL01 SFL
A* ZONE À COCHER
A ZONCTL 1Y 0H SFLCHCCTL
A ZONE 10A O 4 10
A R CTL01 SFLCTL(SFL01)
A*%%TS SD 20231024 203749 QSECOFR REL-V7R4M0 5770-WDS
A SFLPAG(0005)
A WINDOW(5 5 9 31)
A* SOUS FICHIER A SELECTION UNIQUE
A SFLSNGCHC(*SLTIND *AUTOSLT)
A* TAILLE DYNAMIQUE À FOURNIR
A SFLSIZ(&SFLSIZ)
A SFLDSP
A SFLDSPCTL
A 41 SFLCLR
A 45 SFLEND(*SCRBAR *SCRBAR)
A* LIGNE EN COURS < FOURNIT PAR LE SYSTÈME
A DEMANDE 5S 0H SFLSCROLL
A* LIGNE DE LA PAGE À AFFICHER > A FOURNIR PAR LE PROGRAMME
A LIGNE 4S 0H SFLRCDNBR(*TOP)
A* TAILLE DU SOUS FICHIER > A FOURNIR PAR LE PROGRAMME
A SFLSIZ 5S 0P
A* CLÉ DU SOUS FICHIER
A CLE01 4Y 0H
A 2 01'Sous Fichier Sélection Simple'Le RPGLE
**free
// sous fichier à choix unique
ctl-opt DFTACTGRP(*NO) ;
dcl-f BOUTON8 WORKSTN
SFILE(sfl01:cle01) ;
dcl-s i int(10) ;
// Initialisation du sous fichier
SFLSIZ = 10;
LIGNE = 1;
cle01 = 0 ;
*in41 = *on ;
write ctl01 ;
*in41 = *off ;
// Chargement du sous fichier
cle01 = cle01+1 ;
zone = 'AAAAAAAAA' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'BBBBBBBBB' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'CCCCCCCCC' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'DDDDDDDDD' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'EEEEEEEEE' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'FFFFFFFFF' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'GGGGGGGGG' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'HHHHHHHHH' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'IIIIIIIII' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'JJJJJJJJJ' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'KKKKKKKKK' ;
Write sfl01;
// Boucle d'affichage
dou *in03 ;
exfmt ctl01 ;
if not *in03;
// Lecture de l'enregistrement sélectionné
readc sfl01 ;
if not %eof() ;
dsply zone ;
ZONCTL = 0 ;
update(e) sfl01 ;
LIGNE = demande ;
endif ;
endif ;
enddo ;
*inlr = *on ;Mot clé SFLMLTCHC
https://www.ibm.com/docs/en/i/7.4?topic=dkedfp4t8-sflmltchc-subfile-multiple-choice-selection-list-keyword-display-files
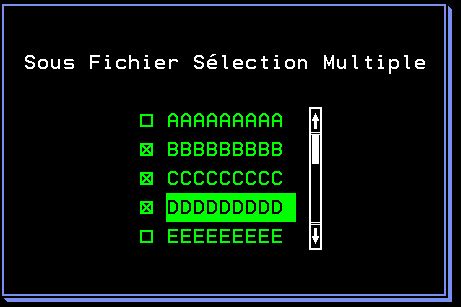
Le DSPF
A*%%TS SD 20231025 044340 QSECOFR REL-V7R4M0 5770-WDS
A* SOUS FICHIER À CHOIX MULTIPLE
A*
A*%%EC
A DSPSIZ(24 80 *DS3)
A CA03(03)
A R SFL01 SFL
A* ZONE À COCHER
A ZONCTL 1Y 0H SFLCHCCTL
A ZONE 10A O 4 10
A R CTL01 SFLCTL(SFL01)
A*%%TS SD 20231025 043531 QSECOFR REL-V7R4M0 5770-WDS
A SFLDSP
A SFLDSPCTL
A 41 SFLCLR
A 45 SFLEND(*SCRBAR *SCRBAR)
A* TAILLE DYNAMIQUE À FOURNIR
A SFLSIZ(&SFLSIZ)
A SFLPAG(0005)
A WINDOW(5 5 9 31)
A* SOUS FICHIER A SELECTION MULTIPLE
A SFLMLTCHC(&NBSEL *SLTIND)
A* LIGNE EN COURS < FOURNIT PAR LE SYSTÈME
A DEMANDE 5S 0H SFLSCROLL
A* LIGNE DE LA PAGE À AFFICHER > A FOURNIR PAR LE PROGRAMME
A LIGNE 4S 0H SFLRCDNBR(*TOP)
A* TAILLE DU SOUS FICHIER > A FOURNIR PAR LE PROGRAMME
A SFLSIZ 5S 0P
A* NOMBRE DE SELECTIONS < FOURNIT PAR LE SYSTÈME
A NBSEL 4Y 0H
A* CLÉ DU SOUS FICHIER
A CLE01 4Y 0H
A 2 1'Sous Fichier Sélection Multiple'
A DSPATR(HI)Le RPGLE
**free
// sous fichier à choix multiple
ctl-opt DFTACTGRP(*NO) ;
dcl-f BOUTON7 WORKSTN
SFILE(sfl01:cle01) ;
dcl-s i int(10) ;
// Initialisation du sous fichier
SFLSIZ = 10;
LIGNE = 1;
cle01 = 0 ;
*in41 = *on ;
write ctl01 ;
*in41 = *off ;
// Chargement du sous fichier
cle01 = cle01+1 ;
zone = 'AAAAAAAAA' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'BBBBBBBBB' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'CCCCCCCCC' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'DDDDDDDDD' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'EEEEEEEEE' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'FFFFFFFFF' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'GGGGGGGGG' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'HHHHHHHHH' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'IIIIIIIII' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'JJJJJJJJJ' ;
Write sfl01;
cle01 = cle01+1 ;
zone = 'KKKKKKKKK' ;
Write sfl01;
// Boucle d'affichage
dou *in03 ;
exfmt ctl01 ;
if not *in03;
// Traitement des enregistrements cochés
for i = 1 to nbsel ;
readc sfl01 ;
if not %eof();
dsply zone ;
ZONCTL = 0 ;
update(e) sfl01 ;
LIGNE = demande ;
endif ;
endfor;
endif ;
enddo ;
*inlr = *on ;
Vous devez compiler avec l’option ENHDSP(*YES)
Pour les sélection simple , vous pouvez utiliser une alternative aux cases à cocher, SFLCSRRRN qui renvoit la clé de l’enregistrement lu sans faire un READC
Vous pouvez dans vos DSPF utiliser des cases à cocher, ce qui les rendra plus sympathique sans passer sur un vrai interface graphique.
Voici deux exemples d’utilisation.
C’est le mot clé SNGCHCFLD qui permet de les définir.

Le DSPF
A* Case à cocher
A* Bouton à choix unique
A DSPSIZ(24 80 *DS3)
A CA03(03)
A R FMT01
A 1 20'Zone choix simple'
A 3 2'Sexe :'
A F1 2Y 0B 3 20SNGCHCFLD(*AUTOSLT (*NUMCOL 3))
A CHOICE(1 '>Homme ')
A CHOICE(2 '>Femme ')
A CHOICE(3 '>Inconnu')
A 23 02'F3=Exit' Le programme RPGLE
**free
ctl-opt DFTACTGRP(*NO) ;
dcl-f BOUTON5 WORKSTN ;
dou *in03 ;
exfmt fmt01 ;
if not *in03;
dsply ('Valeur sélectionée ' + %char(f1)) ;
endif ;
enddo ;
*inlr = *on ; C’est le mot clé MLTCHCFLD qui permet de les définir.

Le DSPF
A* Case à cocher
A* Bouton à choix multiple
A DSPSIZ(24 80 *DS3)
A CA03(03)
A R FMT01
A 1 20'Zone choix multiple'
A 3 2'Plat :'
A F1 2Y 0B 3 20MLTCHCFLD((*NUMCOL 3))
A CHOICE(1 'Entrée ')
A CHOICE(2 'Plat ')
A CHOICE(3 'Dessert ')
A CHCCTL(1 &CHOIX1 )
A CHCCTL(2 &CHOIX2 )
A CHCCTL(3 &CHOIX3 )
A CHOIX1 1Y 0H
A CHOIX2 1Y 0H
A CHOIX3 1Y 0H
A 23 02'F3=Exit' Le programme RPGLE
**free
ctl-opt DFTACTGRP(*NO) ;
dcl-f BOUTON6 WORKSTN ;
dou *in03 ;
exfmt fmt01 ;
if not *in03;
dsply ('Entrée ' + %char(choix1)) ;
dsply ('Plat ' + %char(choix2)) ;
dsply ('Dessert ' + %char(choix3)) ;
endif ;
enddo ;
*inlr = *on ; Vous pouvez utiliser des variables ou des identifiants de message comme texte associé.
*NUMCOL sert à mettre les options sur la même ligne , par défaut elles sont en colonne.
Vous utilisez RDI pour éditer vos programmes RPGLE et vous avez des cartes de déclaratives
H,D,F et vous voulez les convertir en free , voici 2 solutions simples
Solution 1, en ligne sur notre site
https://www.volubis.fr/convertisseur.html
Collez votre sélection dans le formulaire et appuyer sur le bouton Convert
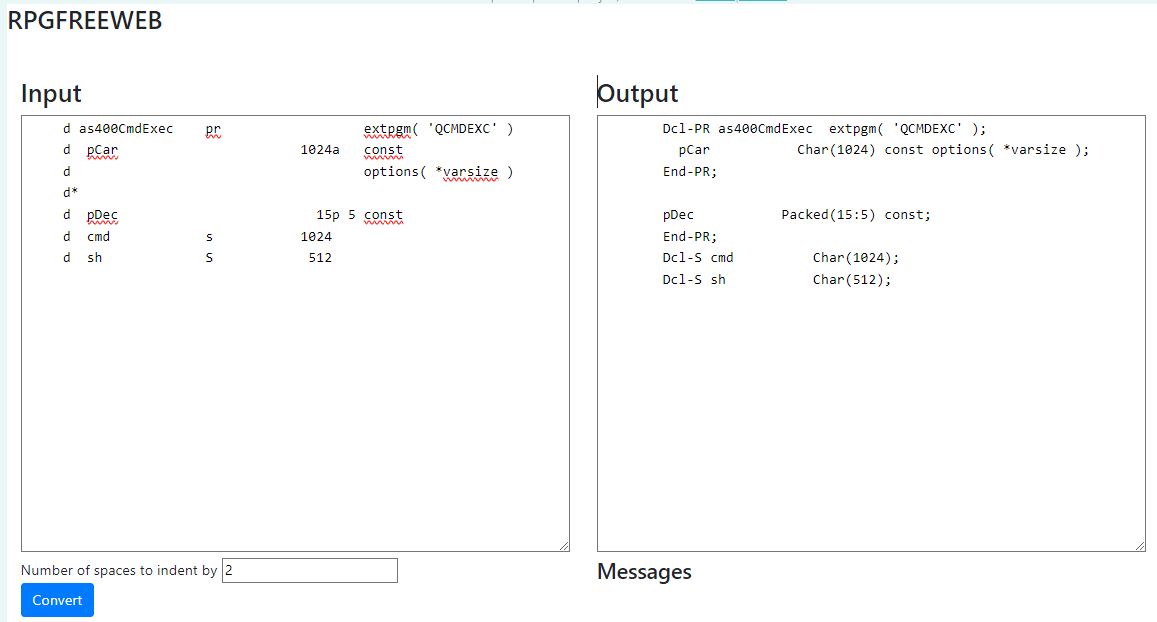
Il vous faudra recopier votre sélection.
Solution 2, installez un plugin Eclipse
Craig Rutledge en a créé un bien il est disponible ici
https://jcrcmds.sourceforge.net/eclipse/rdi8.0/
Suivez la procédure pour paramétrer le plugin dans RDI et l’installation de la bibliothèque JCRCMDS s’il elle n’existe pas sur votre partition, c’est la commande JCRHDF qui sera utilisée, vous pouvez également l’utiliser en 5250, si vous le désirez
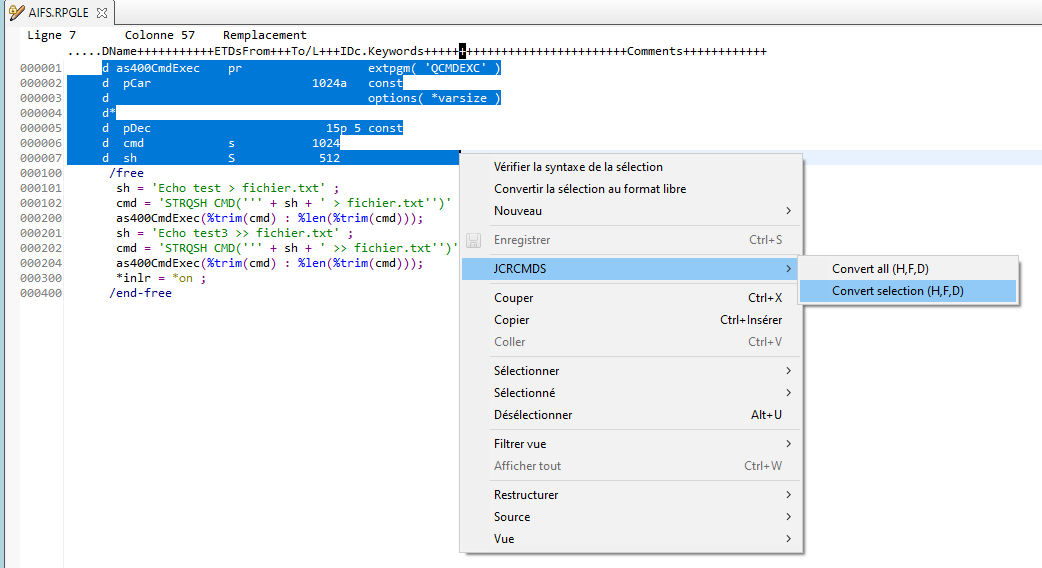
L’utilisation est très simple dans un source de type RPGLE ou SQLRPGLE , vous avez une nouvelle option sur le clic droit, JCRCMDS.
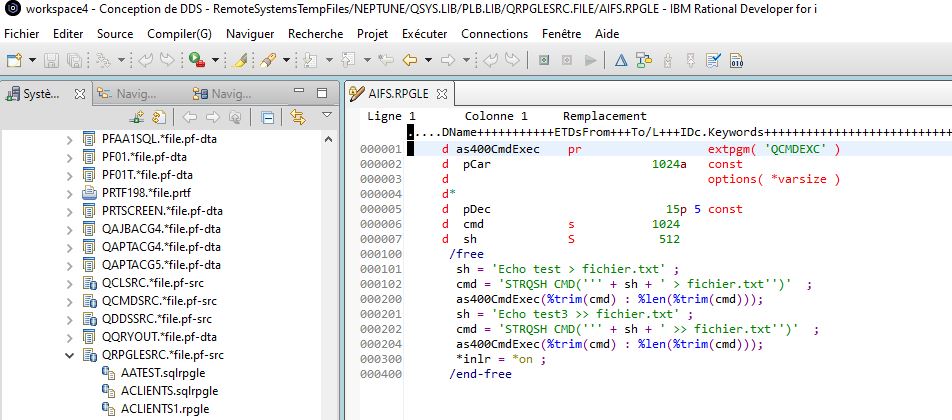
.
.
.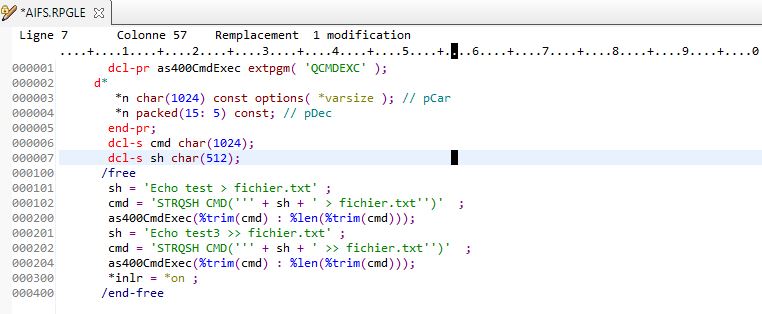
Voila , simple et efficace