Vous voulez nommer votre groupe d’activation pour toute une application donc sans indiquer d’option dans le source qui seraient prioritaires par rapport à votre commande de compile
On va parler ici des BIND c’est l’opération que fait une commande pour compiler le module et l’assembler pour en faire un programme
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-29 09:05:152024-08-29 09:05:16Nommer un groupe d’activation pour des programmes RPGLE
Vous voulez connaitre la bibliothèque d’un programme en cours d’exécution, pour ajouter cette bibliothèque par exemple, pour contextualiser un exit programme, un watcher, un trigger ou pour limiter un environnement prod, versus dev. Le tout, sans harcoder une bibliothèque qui figera votre code et vos environnements.
Voici 2 exemples
En RPGLE
dcl-ds *N PSDS ;
bibli_du_pgm CHAR(10) POS(81);
nom_du_pgm CHAR(10) POS(1);
End-ds ;
dcl-s present ind ;
// on tente d'ajouter la bibliothèque
exec sql
call qcmdexc('Addlible ' concat :bibli_du_pgm concat ' *FIRST') ;
if sqlcode = 0 ;
present = *on ;
endif ;
// votre traitement ici
// on enlève si on a ajouté
if present = *on ;
exec sql
call qcmdexc('Rmvlible ' concat :bibli_du_pgm ) ;
endif ;
En CLLE
PGM
DCL VAR(&DATA) TYPE(*CHAR) LEN(80)
DCL VAR(&LIB) TYPE(*CHAR) LEN(10)
DCL VAR(&PGM) TYPE(*CHAR) LEN(10)
DCL VAR(&TEMOIN) TYPE(*LGL)
/* Paramétrage de l'appel */
CHGVAR VAR(%BIN(&DATA 1 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 5 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 9 4)) VALUE( 0)
CHGVAR VAR(%BIN(&DATA 13 4)) VALUE( 0)
/* Appel de la procédure */
CALLPRC PRC('_MATPGMNM') PARM(&DATA)
/* Extraction des informations */
chgvar &pgm %SST(&DATA 51 10)
chgvar &lib %SST(&DATA 19 10)
/* ajout de la bibliothèque */
ADDLIBLE &LIB *FIRST
monmsg cpf2103 exec(do)
chgvar &temoin '1'
enddo
/* Votre traitement ici */
/* on enlève si on a ajouté */
if cond(*not &temoin) then(do)
RMVLIBLE &LIB
enddo
ENDPGM
Remarque :
On a mis également le programme en cours dans les exemples
On a mis le code pour enlever la bibliothèque après le traitement, uniquement si c’est notre programme qui l’a ajouté.
En RPGLE si vous avez un fichier vous devrez déclarer votre fichier en USROPN et ouvrir le fichier par un OPEN, après avoir ajouté la bibliothèque
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-17 09:22:572024-08-20 10:47:56Connaitre la bibliothèque du programme en cours
Que se passe-t-il si on définit soi-même une zone IDENTITY lors de la mise à jour d’une table ?
Ce n’est évidemment pas la meilleure des idées qu’on puisse avoir, mais parfois dans l’urgence d’une correction de données …
Commençons par créer une table de tests avec une zone identité de type bigint :
CREATE TABLE NK.IDENT
(
ID BIGINT GENERATED BY DEFAULT AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER),
NOM_SQL_ZONE_CHAR FOR COLUMN ZONECHAR CHAR(20) NOT NULL DEFAULT '',
CONSTRAINT IDENT_PK PRIMARY KEY( ID)
)
RCDFMT RIDENT ;
RENAME TABLE NK.IDENT TO TESTS_IDENTITY
FOR SYSTEM NAME IDENT;
Les zones qui nous intéressent dans la vue syscolumns de QSYS2 ressemblent à ça :
select column_name,
is_identity,
identity_generation,
identity_minimum,
identity_maximum
from qsys2.syscolumns
where system_table_name ='IDENT'
and system_table_schema ='NK'
order by ordinal_position;
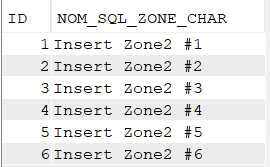
Alimentation de la table avec quelques enregistrements
insert into nk.ident (Zonechar) values ('Insert Zone2 #1');
insert into nk.ident (Zonechar) values ('Insert Zone2 #2');
insert into nk.ident (Zonechar) values ('Insert Zone2 #3');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #4');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #5');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #6');
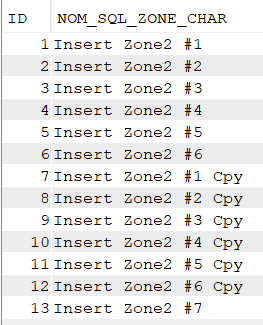
On peut ignorer ID ou le renseigner en DEFAULT, la table est alimentée :
select * from nk.ident;
Que se passe-t-il si je définis moi-même ID lors d’un insert ?
Si l’identity est déjà occupée par un enregistrement : SQL n’accepte pas l’instruction, il fait ce qu’on lui a demandé !
insert into nk.ident (ID, Zonechar) values (1, 'Insert KO');
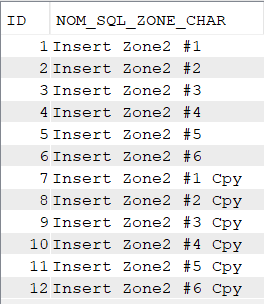
Si je fais des insertions de données dans IDENT en définissant moi-même des ID libres :
insert into nk.ident
select id+6, trim(zonechar) || ' Cpy' from nk.ident;
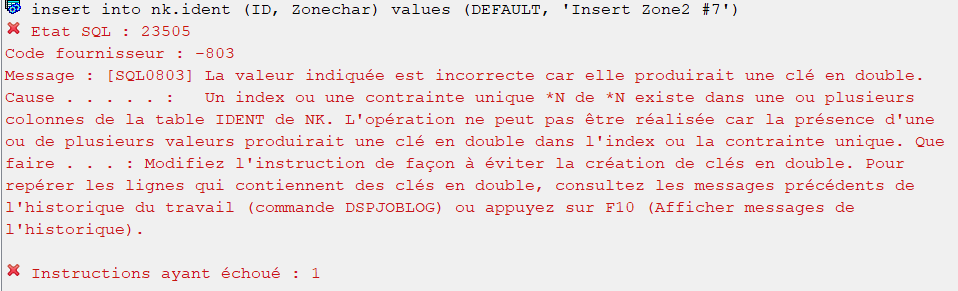
Mais si je refais une insertion de données en laissant à nouveau SQL gérer l’identity :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
On consulte la log du travail comme le message d’erreur nous invite :
select message_second_level_text
from table(qsys2.joblog_info('111778/QUSER/QZDASOINIT'))
where message_id = 'CPF5009';
Deux enregistrements sont trouvés :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti.Le membre numéro 1 (enregistrement numéro 1, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 7, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Le premier message est relatif à la tentative d’insertion « insert into nk.ident (ID, Zonechar) values (1, ‘Insert KO’); » tentée plus haut et pour laquelle l’erreur était attendue.
Le second message est relatif à «insert into nk.ident (ID, Zonechar) values (DEFAULT, ‘Insert Zone2 #7’); »
SQL a tenté d’utiliser la valeur suivante de la dernière identity qu’il a lui-même géré, mais a échoué car la valeur IDENT.ID=7 existe déjà.
Si on retente l’insertion qui vient juste d’échouer :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
Elle échoue de la même façon, sauf que cette fois SQL a tenté d’utiliser l’ID = 8 :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 8, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Comment corriger la situation ?
La solution pour se sortir de là si on a fait 3000 insertions ne va pas être de tenter 3000 insertions bidons pour que la table ait son compteur interne gérant l’identity à jour (d’ailleurs, si quelqu’un sait où il se cache je suis preneur).
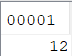
On récupère la dernière ID utilisée dans la table :
select max(ID) from nk.ident ;
Et on ajoute 1 pour mettre à jour la table :
alter table nk.ident
alter column id restart with 13;
L’instruction précédente :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
se passe bien maintenant et la numérotation de IDENT.ID a bien repris normalement :
select * from nk.ident;
Pour se prémunir de tout ceci, il suffit de vérifier la nature de la clé primaire d’une table avant de commencer à y insérer des enregistrements.
Sur DB2 l’usage d’IDENTITY dans une table SQL n’est pas très répandu, il est donc nécessaire de comprendre la structure d’une table avant de l’utiliser. L’IDENTITY se révèle alors pratique tant qu’on laisse le système la gérer. On peut bien sûr, dans des cas exceptionnels, la gérer soi-même si on fait attention…
/wp-content/uploads/2017/05/logogaia.png00Nicolas kintz/wp-content/uploads/2017/05/logogaia.pngNicolas kintz2024-08-13 09:51:272024-08-13 09:51:28Gestion de l’IDENTITY d’une table
Analyse par les fichiers supports ( c’est des fichiers modèles qui sont dans QSYS ) CRTDUPOBJ OBJ(QAWCTPJE) FROMLIB(QSYS) OBJTYPE(*FILE) TOLIB(Votrebib) NEWOBJ(QPFRADJTP)
pour analyser le suivi ici du pour des travaux interactifs
SELECT TPPNAM, TPFLG1, TPCSIZ, TPCRES, TPCACT, TPDFLT, TPNFLT, TPWI, TPAW, TPCJOB, TPAJOB, TPNSIZ, TPNACT FROM Votrebib/QPFRADJTP WHERE TPPNAM = ‘*INTERACT’ order by TPDATE, TPTIME
Deuxième exemple, voir les ports filtrés sur votre partition
Analyse par services SQL
create table votrebib.analyse as( WITH Log_Port AS ( SELECT CAST(ENTRY_DATA AS VARCHAR(1000)) AS entry FROM TABLE ( QSYS2.DISPLAY_JOURNAL(‘QUSRSYS’, ‘QIPFILTER’, JOURNAL_ENTRY_TYPES => ‘TF’) ) ) SELECT SUBSTR(entry, 1, 10) AS line, SUBSTR(entry, 29, 15) AS AdrSrcIp, SUBSTR(entry, 44, 5) AS SrcPort, SUBSTR(entry, 49, 15) AS AdrDestIp, SUBSTR(entry, 64, 5) AS DestPort FROM Log_Port ) WITH DATA;
Remarques
Certains journaux sont en standard , d’autres devront être démarrés Si vous n’analysez pas ne les démarrer pas Pensez à faire le ménage dans les récepteurs si vous les démarrez
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-02 09:13:592024-08-14 15:49:25Utilisez les journaux Système
Vous voulez créer un trigger qui vous indique la création d’un enregistrement dans un fichier par exemple pour superviser, dans notre exemple on enverra un email , il est conseillé de faire un fichier de paramétrage
En SQL ca créera un programme CEE et ca l’associera au trigger
CREATE OR REPLACE TRIGGER ALERTE_MSG
AFTER INSERT ON REP_VALID
REFERENCING NEW AS N
FOR EACH ROW
MODE DB2ROW
-- email destinataire
BEGIN
DECLARE W_EMAIL CHAR(50);
DECLARE W_SUJET CHAR(100);
DECLARE W_NOTES CHAR(200);
DECLARE EXIT HANDLER FOR SQLSTATE '38501'
RESIGNAL SQLSTATE '38501' SET MESSAGE_TEXT = 'ENVOI MAIL IMPOSSIBLE.';
SET W_NOTES = 'Job : ' concat trim(N.REPNBR)
concat '/' concat trim(N.REPUSER) concat '/' concat trim(N.REPJOB) ;
SET W_EMAIL = 'votre@email.fr' ;
SET W_SUJET = 'Enregistrement crée' ;
CALL QCMDEXC('SNDSMTPEMM RCP((''' concat trim(w_email) concat
''')) SUBJECT(''' concat trim(replace(w_sujet , '''', '"'))
concat ''') NOTE('''
concat trim(replace(W_NOTES , '''' , '"')) concat''') CONTENT(*HTML)') ;
END;
Remarques :
Dans les 2 cas si l’utilisateur n’est pas inscrit à la liste de distribution votre email ne sera pas envoyé c’est plus simple de gérer l’erreur en CLP. Si vous devez accéder aux données du buffer ca sera plus rapide et plus simple en SQL ici n.zone
C’est des triggers après , puisque l’information doit être écrite dans tous les cas .
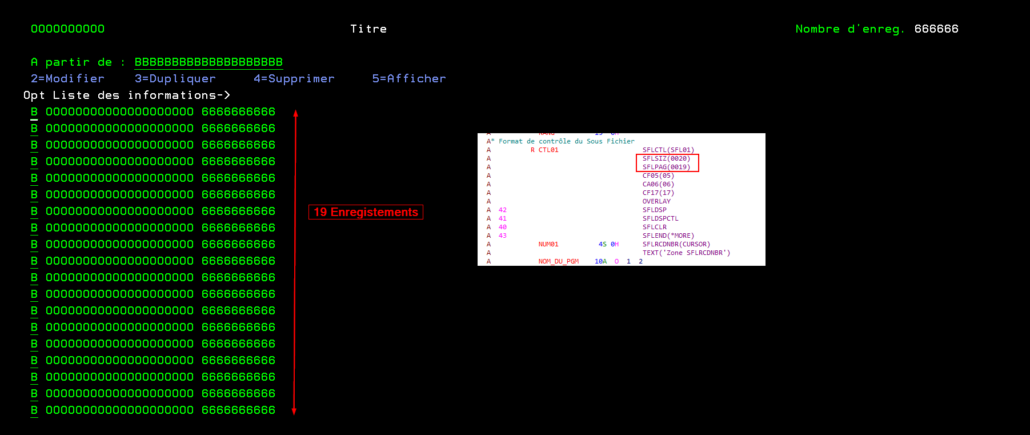
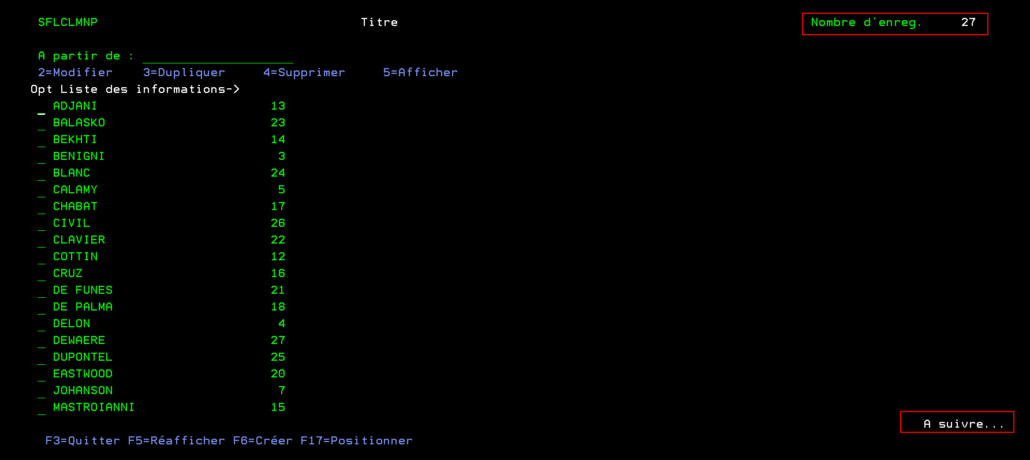
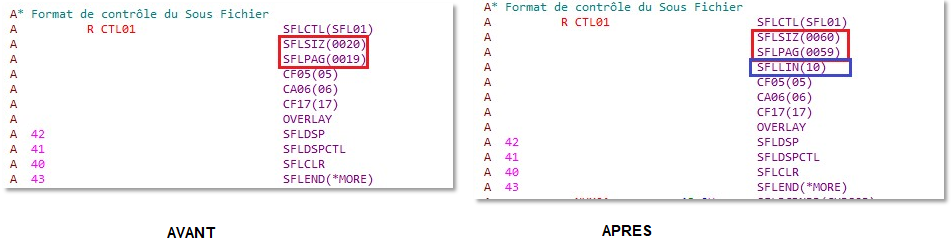
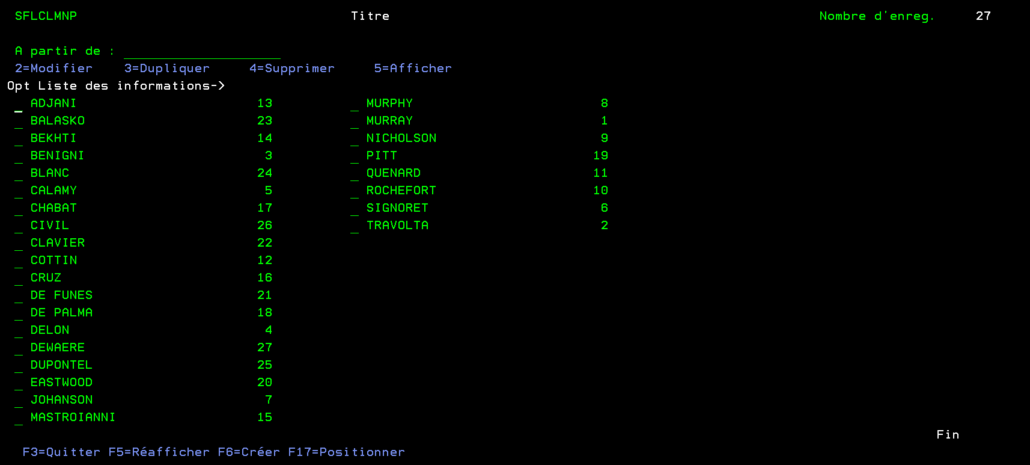
Un sous-fichier nous permet d’afficher un nombre de lignes qui est limité par la taille de l’écran. Cette taille est définie dans le script source de l’écran par le paramètre SFLPAG.
On possède un fichier que l’on souhaite afficher et qui contient plus de 19 enregistrement. Il serait donc intéressant de l’afficher sur plusieurs colonnes.
Solution
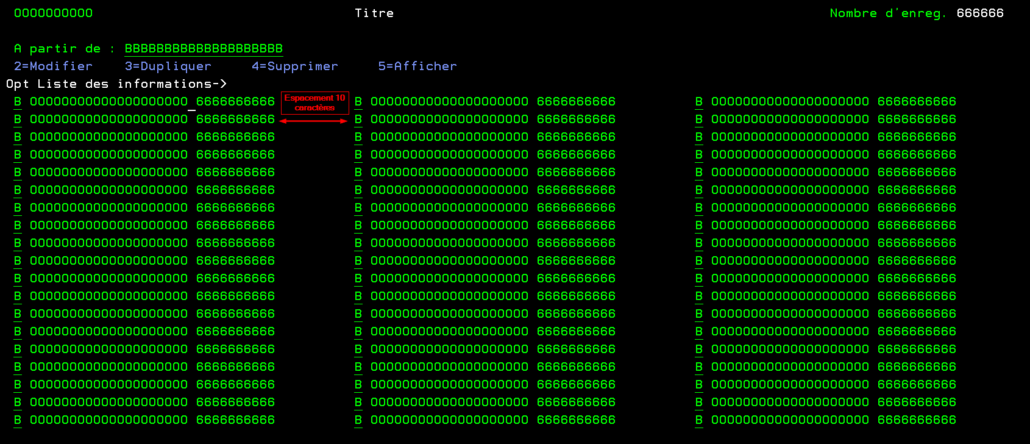
Une petite modification du script source permet de créer un sous fichier qui contient plusieurs colonnes. Il faut donc indiquer le nombre total de données que l’on souhaite voir à l’écran dans SFLPAG ainsi que le nombre de caractère qui séparent deux colonnes
La maquette se présente ainsi, le paramètre de SFLLIN correspond à l’espace (en caractères) entre deux colonnes.
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-07-16 09:38:142024-07-16 09:48:33Afficher plusieurs colonnes d’enregistrements dans un sous-fichier
Vous avez des possibilités en standard sur votre IBMi : Pour générer du PDF Pour générer du CSV Pour Générer du TXT
Comment rendre efficace et intégrer ces fichiers sous WINDOWS ?
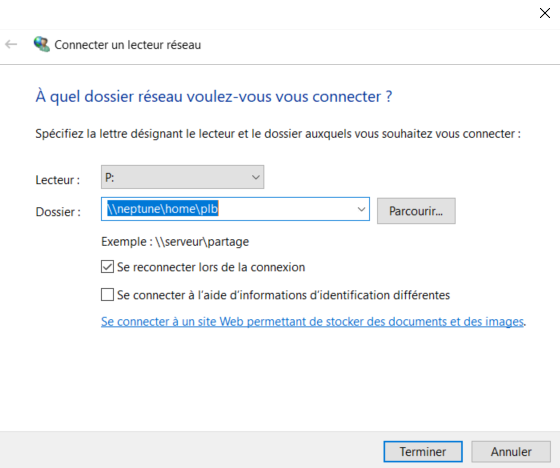
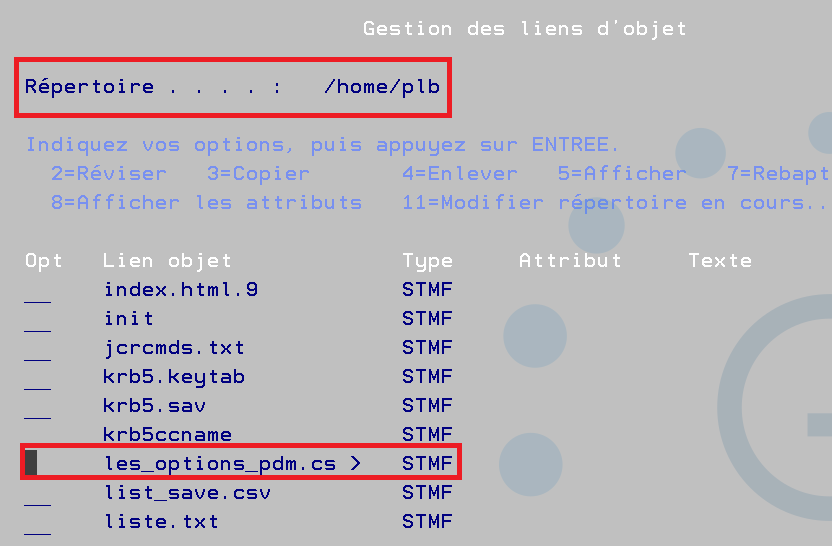
1 ) Le profil utilisateur propose en standard un répertoire par défaut, /home/votreuser.
Vous devez créer cette directory qui deviendra alors votre répertoire par défaut. La prise en compte est à la prochaine connexion Vous pouvez contrôler en faisant ==> WRKLNK
2 ) Sur l’ibmi vous devez monter un partage, s’il n’existe pas encore sur le répertoire /home
3 ) Sur votre PC il est conseillé de monter un partage windows sur /home/votreuser chez nous lettre P.
4 ) Sur votre PC vous devrez vérifier que vos associations d’extension de fichier sont bien rattachées au bon logiciel
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-06-20 15:59:522024-06-20 16:10:18Intégrer Windows dans vos applications 5250
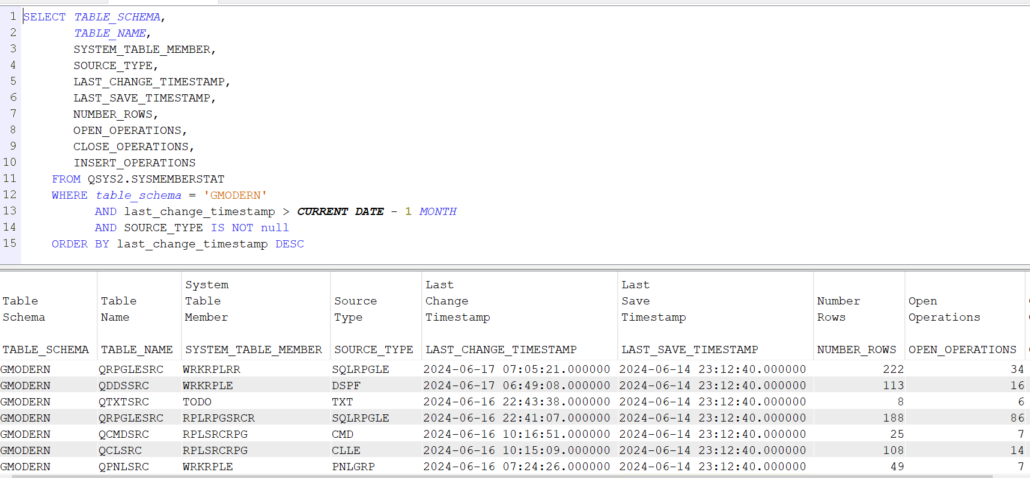
Avec TR4 de la version V7R5 est arrivé la vue SYSMEMBERSTAT qui permet d’avoir des statistiques sur les membres, des informations supplémentaires à celles existantes à ce jour.
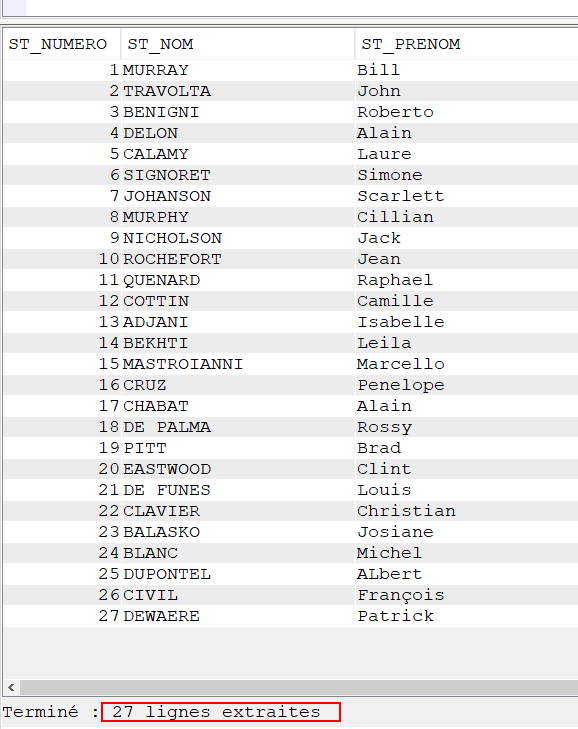
Voici un exemple :
SELECT TABLE_SCHEMA,
TABLE_NAME,
SYSTEM_TABLE_MEMBER,
SOURCE_TYPE,
LAST_CHANGE_TIMESTAMP,
LAST_SAVE_TIMESTAMP,
NUMBER_ROWS,
OPEN_OPERATIONS,
CLOSE_OPERATIONS,
INSERT_OPERATIONS
FROM QSYS2.SYSMEMBERSTAT
WHERE table_schema = 'GMODERN'
AND last_change_timestamp > CURRENT DATE - 1 MONTH
AND SOURCE_TYPE IS NOT null
ORDER BY last_change_timestamp DESC
Résultat
Rappel :
Il existe déjà une vue SYSPARTITIONSTAT qui donne sensiblement les mêmes informations
et ne rêver pas vous n’avez toujours pas le dernier utilisateur qui a modifié
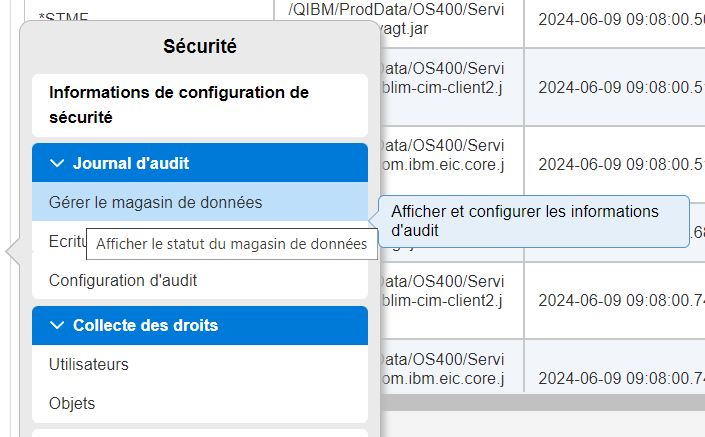
Une des nouveautés de la dernière TR est de pouvoir analyser et exporter les analyses de journaux d’audit à partir d’un interface graphique dans navigator for i.
le menu
Vous avez la nouvelle option, gérer les magasins d’audit
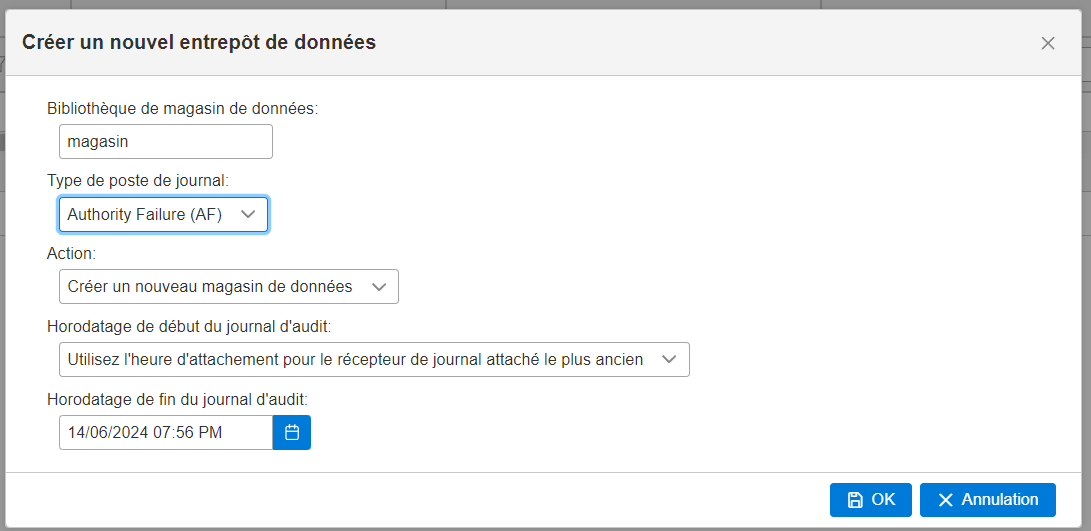
vous devez commencer par en créer un
Attention la bibliothèque doit existée
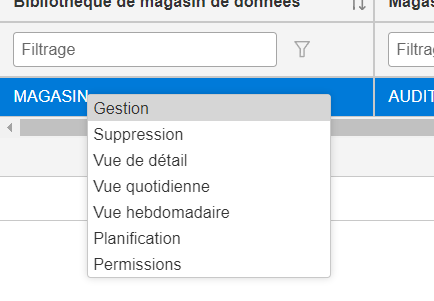
Une fois les données agrégées vous avez une liste de vos magasins
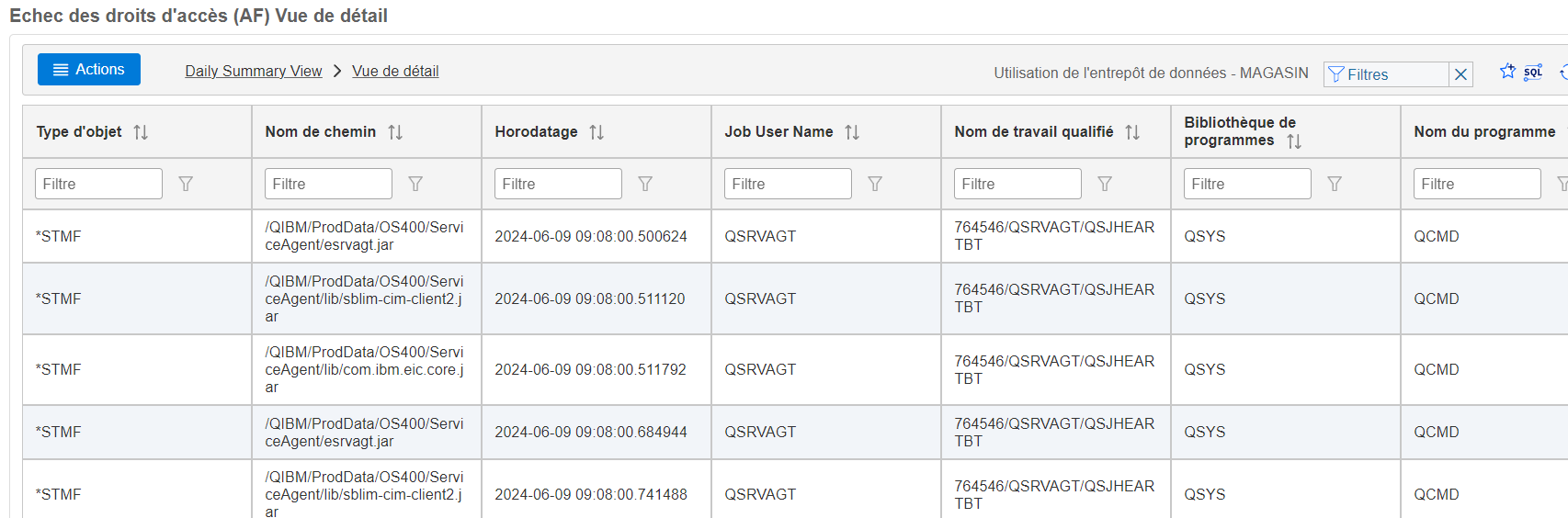
vous avez un menu qui vous permet de voir le détail du contenu du magasin
Vous avez le détail de votre magasin que vous pouvez consulter ou exporter par exemple
le menu action
Conclusion
Ca facilite grandement l’utilisation et la restitution des informations d’audit
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-06-14 20:21:082024-06-14 20:21:09Gérer les magasins de datas
SELECT * FROM TABLE(QSYS2.TRACKED_JOB_INFO(JOB_QUEUE_LIBRARY_FILTER => ‘GG’, JOB_QUEUE_FILTER => ‘GGTEST’)) ORDER BY INTERNAL_JOB_IDENTIFIER, ROUTING_STEP;
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-05-10 15:35:052024-05-10 15:35:06Gestion du suivi des tâches soumises