Contrôler l’existence d’un fichier stream (IFS)
Lorsque l’on doit tester l’existence d’un objet dans QSYS.LIB la question ne se pose pas, on utilise la commande prévue à cet effet CHKOBJ. Pour l’IFS par contre il n’y a pas de commande toute faite.
Voici donc trois exemples de solutions pour tester l’existence d’un fichier dans l’IFS en CL et en SQLRPGLE.
(Il existe d’autres méthodes, mais celles-ci sont les plus simples).
CHKOUT / CHKIN (clle)
La commande CHKOUT permet de verrouiller un objet, ainsi les autres utilisateurs et travaux ne peuvent plus que le lire ou le copier. Il suffit de monitorer cette commande en attendant le message CPFA0A9 qui indique que le fichier n’existe pas.
Cette méthode est donc utile lorsque l’on souhaite par la même occasion verrouiller l’objet recherché.
Il ne faut pas oublier de déverrouiller l’objet une fois votre opération terminée avec la commande CHKIN.
PGM PARM(&FILEPATH)
DCL VAR(&FILEPATH) TYPE(*CHAR) LEN(256)
DCL VAR(&EXISTS) TYPE(*LGL)
CHGVAR VAR(&EXISTS) VALUE('1')
/* Verrouillage de l'objet */
CHKOUT OBJ(&FILEPATH)
MONMSG MSGID(CPFA0A9) EXEC(DO)
/* Fichier non trouvé */
/* Traitement de l'exception... */
CHGVAR VAR(&EXISTS) VALUE('0')
SNDPGMMSG MSG('Fichier inexistant')
ENDDO
/* Libération de l'objet si existant */
IF COND(&EXISTS) THEN(DO)
CHKIN OBJ(&FILEPATH)
ENDDO
ENDPGMMOV (clle)
Une solution plus simple encore, lorsque l’on n’a pas besoin de gérer le verrouillage de l’objet, est l’utilisation de la commande MOV. Initialement, elle permet de déplacer un objet, mais en indiquant le chemin de l’objet d’origine comme objet de destination, aucune action ne sera effectuée sur l’objet (pas de changement de la date de dernière modification) et on pourra encore une fois tester le message CPFA0A9.
PGM PARM(&FILEPATH)
DCL VAR(&FILEPATH) TYPE(*CHAR) LEN(256)
MOV OBJ(&FILEPATH) TOOBJ(&FILEPATH)
MONMSG MSGID(CPFA0A9) EXEC(DO)
/* Fichier non trouvé */
/* Traitement de l'exception... */
SNDPGMMSG MSG('Fichier inexistant')
ENDDO
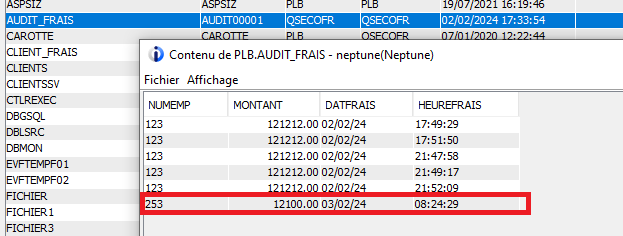
ENDPGMIFS_OBJECT_STATISTICS (SQL/SQLRPGLE)
En SQL et SQLRPGLE, le plus simple reste d’utiliser la fonction table IFS_OBJECT_STATISTICS. Pour s’assurer ne pas tomber sur un répertoire portant le nom du fichier ou autre, il est préférable de renseigner les paramètres subtree_directories et object_type_list (bien entendu en renseignant *DIR si on cherche un répertoire).
Il suffit ensuite de tester le sqlCode, s’il est égal à 100 cela signifie que le fichier est inexistant.
SELECT path_name
FROM TABLE (
qsys2.ifs_object_statistics(
start_path_name => '/home/jl/file.txt',
subtree_directories => 'NO',
object_type_list => '*STMF'
)
);Remarque
Il faut tout de même prendre en compte les droits de l’utilisateur qui réalise ces tests, en fonction de la méthode utilisée, un autre message pourrait être émit ou le fichier pourrait lui apparaitre comme inexistant.
Pour plus de détails
Documentation IBM – CHKOUT : https://www.ibm.com/docs/en/i/7.5?topic=ssw_ibm_i_75/cl/chkout.html
Documentation IBM – CHKIN : https://www.ibm.com/docs/en/i/7.5?topic=ssw_ibm_i_75/cl/chkin.html
Documentation IBM – MOV : https://www.ibm.com/docs/en/i/7.5?topic=ssw_ibm_i_75/cl/mov.html
Documentation IBM – IFS_OBJECT_STATISTICS : https://www.ibm.com/docs/en/i/7.5?topic=services-ifs-object-statistics-table-function