SQL_DB2Contrôler la liste des utilisateurs inscrits à SMTP via sql
Petits rappels en préambule :
SNA n’est plus à utiliser, on le retrouve pourtant encore très souvent en usage sur de nombreux IBM i. Il faut passer au SMTP.
Les utilisateurs SMTP sont inscrits à un registre.
Pour accéder à ce registre on peut passer par la commande 5250 : WRKSMTPUSR – Work with All SMTP Users.
Si vous ne souhaitez pas inscrire tous vos profils au registre SMTP, il est d’usage de créer un profil NOREPLY afin de l’ajouter au registre, puis de soumettre les envois de mail, exemple :
SBMJOB CMD(SNDSMTPEMM RCP(('julien.laurier@gaia.fr')) SUBJECT(TEST) NOTE('This is not a test.')) USER(NOREPLY)
Lors de l’utilisation de la commande SNDSMTPEMM dans un programme, il est préférable de commencer par contrôler la présence du profil dans le registre SMTP. Ce registre est stocké non pas dans une table mais dans un fichier de configuration dans l’ifs : ‘/QTCPTMM/CONFIG/USERS.DAT’. C’est cette liste qui est affichée par WRKSMTPUSR, malheureusement, ces informations ne sont pas adressables directement via SQL. Il nous revient alors de créer nous même de quoi accéder à ces informations pour simplifier ces usages.
Voici une requête SQL qui permet de parser les informations présentes dans le fichier :
SELECT MAX(CASE WHEN entries.ordinal_position = 1 THEN entries.element END) AS "User profile",
MAX(CASE WHEN entries.ordinal_position = 2 THEN entries.element END) AS "SMTP mailbox alias",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 1 THEN details.element END) AS "Domain index",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 2 THEN details.element END) AS "Domain Name",
MAX(CASE WHEN entries.ordinal_position = 4 THEN entries.element END) AS "SDD name compatibility",
MAX(CASE WHEN entries.ordinal_position = 5 THEN entries.element END) AS "SDD address compatibility",
MAX(CASE WHEN entries.ordinal_position = 6 THEN entries.element END) AS "Forwarding to",
MAX(CASE WHEN entries.ordinal_position = 7 THEN entries.element END) AS "Originating from",
MAX(CASE WHEN entries.ordinal_position = 8 THEN entries.element END) AS "Data1",
MAX(CASE WHEN entries.ordinal_position = 9 THEN entries.element END) AS "Data2"
FROM TABLE (qsys2.ifs_read_utf8(path_name => '/QTCPTMM/CONFIG/USERS.DAT',
maximum_line_length => 1024)) AS lines,
TABLE (systools.split(input_list => CAST(lines.line AS VARCHAR(1024)),
delimiter => ' ')) AS entries,
TABLE (systools.split(input_list => CAST(entries.element AS VARCHAR(1024)),
delimiter => ':')) AS details
WHERE line_number > 1
GROUP BY lines.line_number);
Voici un exemple de résultat obtenu :
User profile
SMTP mailbox alias
Domain index
Domain Name
SDD name compatibility
SDD address compatibility
Forwarding to
Originating from
Data1
Data2
FORM01
*NONE
00
*NONE
FORM01
NEPTUNE
*NONE
*NONE
Y
9132
FORM02
*NONE
00
*NONE
FORM02
NEPTUNE
*NONE
*NONE
Y
9134
Pour simplifier encore plus votre usage, je vous propose une vue, ainsi qu’une fonction table :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2025-04-07 21:27:092025-04-08 09:47:08Contrôler la liste des utilisateurs inscrits à SMTP via sql
Vous devez surveiller l’IFS de votre partition et plus particulièrement la partie /home/ ou vous retrouvez les fichiers générés par vos utilisateurs et y faire le ménage régulièrement est une bonne pratique.
Une épuration à 30 jours semble un bon compromis
Voici 2 techniques pour réaliser cette opération
La première est à base d’un script UNIX
Voici un exemple, dans le répertoire /home/maurice/OUT on supprime les fichiers CSV de plus de 10 jours
Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Présentation
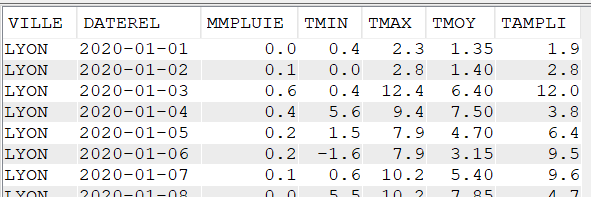
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
La ville
Le jour (AAAA-MM-JJ)
Les précipitations en mm
La température minimale du jour (en °C)
La température maximale du jour (en °C)
La température moyenne du jour (en °C)
L’amplitude de température du jour (en °C)
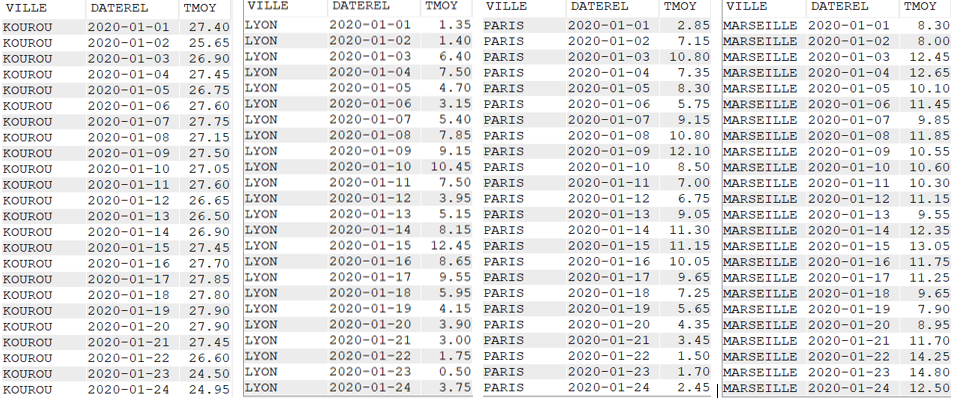
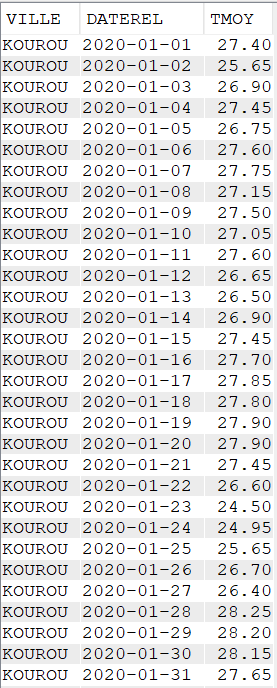
Agréger les données avec LISTAGG
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)
Données brutes
Données avec la fonction LISTAGG
Agréger les données avec GROUP BY
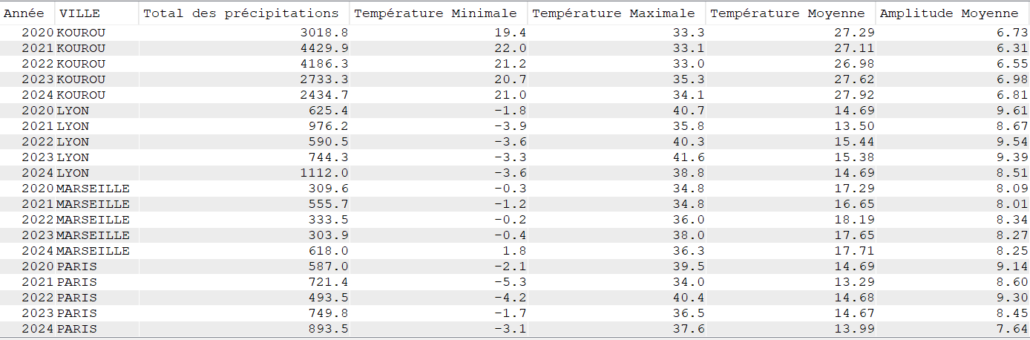
Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
SUM qui va nous permettre de faire le total des précipitations
MIN pour extraire la température minimale
MAX pour extraire la température maximale
AVG pour faire une moyenne (de la température ainsi que de l’amplitude des températures)
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
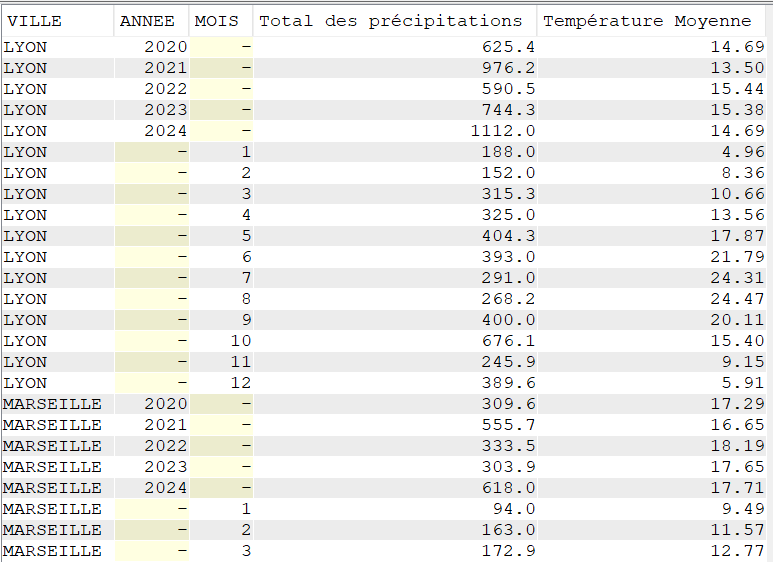
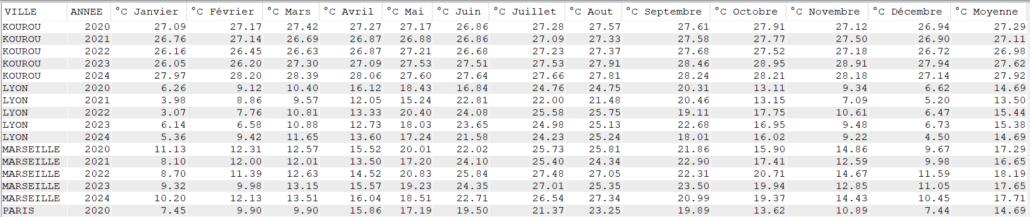
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";
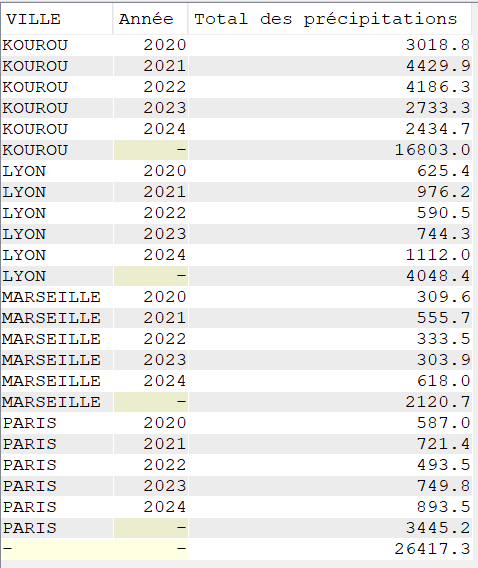
Utilisation de ROLLUP
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";
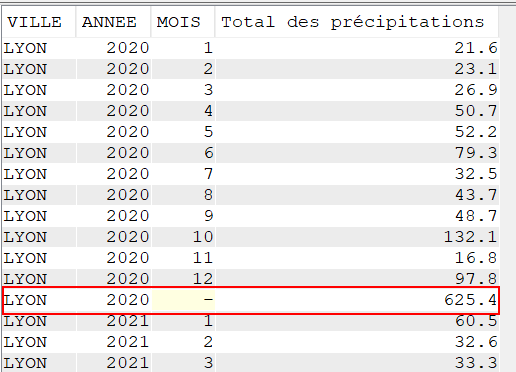
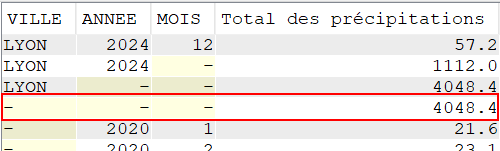
L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
VILLE / ANNEE
VILLE
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
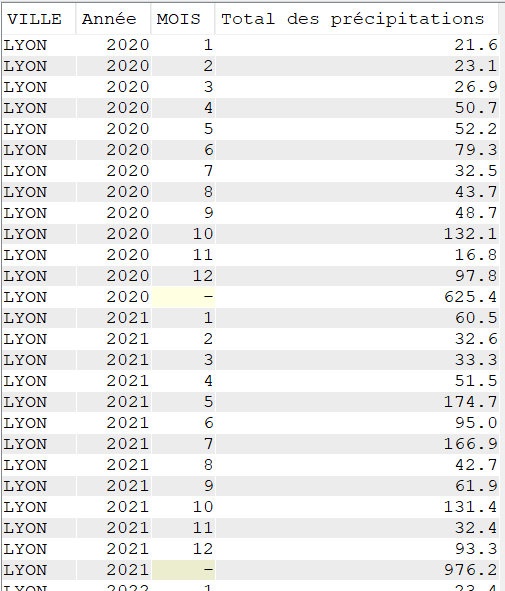
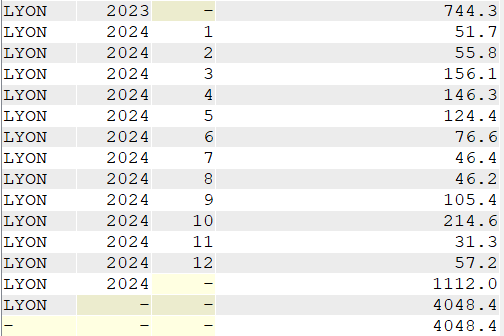
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));
…
…
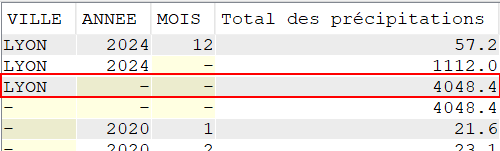
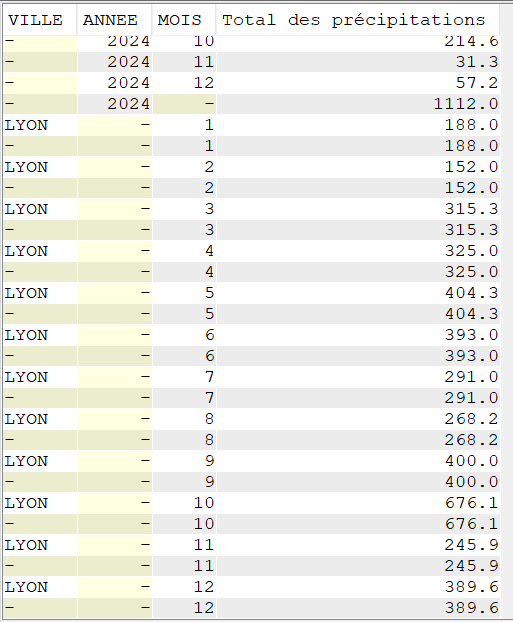
Utilisation de CUBE
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
SELECT VILLE, YEAR(DATEREL) Annee, MONTH(DATEREL) Mois, SUM(MMPLUIE) "Total des précipitations" FROM CLIMAT WHERE VILLE = 'LYON' GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
Par VILLE et ANNEE
Par VILLE et sur la période de mesure
Sur la période de mesure (valeur identique à la précédente car une seule ville sélectionnée ici)
Par VILLE pour chaque mois de la période sélectionnée (ou simplement pour chaque mois de la période sélectionnée)
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Utilisation de GROUPING SETS
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);
Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
Tableau Croisé avec Agrégation et CASE
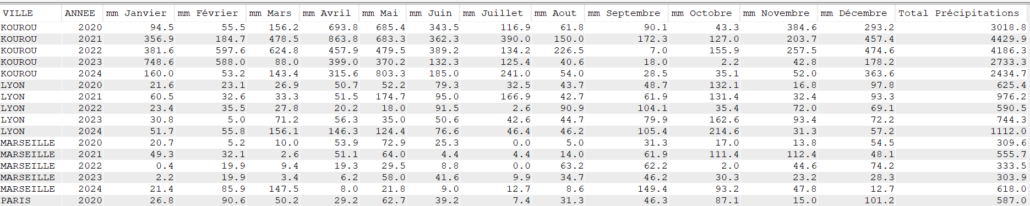
Avec SUM
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Avec AVG
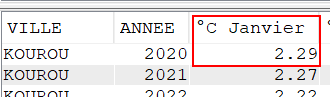
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Note sur l’utilisation de SUM vs AVG dans un tableau croisé
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
Avec ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.
NULL est ignoré par AVG, garantissant une moyenne correcte.
Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)
Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)
Utiliser SQL pour faire une analyse
Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
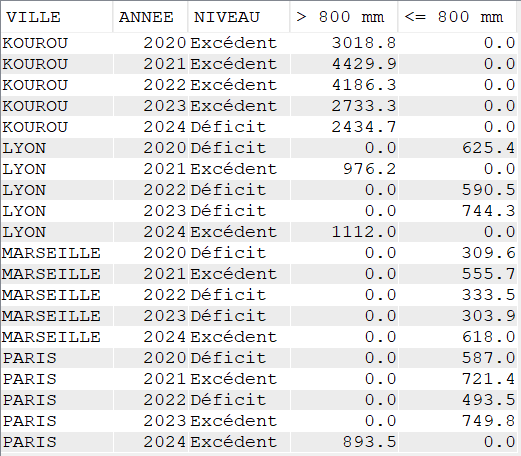
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL);
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2025-03-04 09:03:202025-03-04 09:28:33Regroupements et Analyses avec SQL
Si vous avez mis en œuvre le journal vous pouvez et même devez analyser les refus de connexion. Le plus souvent c’est un mauvais mot de passe mais ca peut être aussi une attaque, ou un comportement douteux
Voici une requête simple qui permet cette analyse rapide
SELECT JOB_NAME, USER_NAME, FUNCTION, MESSAGE_ID, MESSAGE_TIMESTAMP FROM TABLE(QSYS2.DISPLAY_JOURNAL(‘QSYS’, ‘QAUDJRN’)) WHERE MESSAGE_ID IN (‘CPF2234’, ‘CPF1107’, ‘CPF1393’) ORDER BY MESSAGE_TIMESTAMP DESC;
Les messages traités ici CPF2234 Tentative de connexion échouée. CPF1107 Mot de passe incorrect. CPF1393 Accès refusé.
Remarque : Vous pouvez ajouter des filtres (plage horaire, autres messages de refus , etc …) Vous devrez découper vous même la zone entry data, vous pouvez également utiliser les fonctions table QSYS2.DISPLAY_JOURNALxx spécialisées par TYPE
Les indicateurs font parti intégrante des développements RPG, c’est des booléens dont le nom commence par *IN, certain ont plus ou moins disparu (remplacé par des %EOF, %FOUND, ou un SQLCODE ) , mais les indicateurs *IN01 à *IN99 continuent à être utilisé par exemple dans les DSPF.
On va essayer de voir une méthode qui rendra le code plus lisible pour les jeunes recrues qui devront faire de la maintenance
On va prendre un exemple à partir d’un DSPF
Votre écran devra avoir le mot clé INDARA qui indique qu’on va gérer les indicateurs dans un buffer séparé
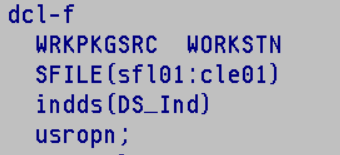
Pour la déclaration de votre écran vous devrez lui indiquer le mot clé INDDS qui indiquera la DS qui contiendra le tableau de ces indicateurs.
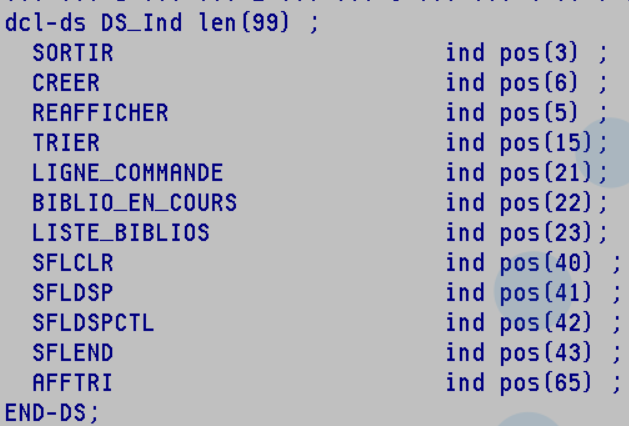
voici un exemple de DS avec les indicateurs nommé
Exemple :
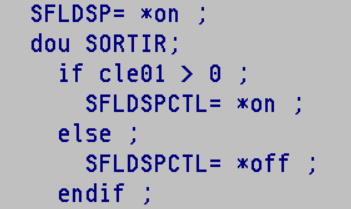
*IN03 / SORTIR
Voici ci dessus un exemple de code RPG FREE, utilisant les noms indiqués dans la DS, on voit tout de suite mieux ce qu’on fait
Remarque :
Vous pouvez mettre votre DS dans un include et le déclarer dans chaque programme , ce qui permettra d’uniformiser votre tableau des indicateurs
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-02-24 11:03:502025-02-25 09:31:53Nommez vos indicateurs en RPGLE
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2025-02-17 14:38:202025-02-17 14:44:48Gestion de l’état null dans les SQLRPGLE
Voici 5 fonctions qui peuvent vous intéresser pour manipuler des dates en SQL.
je vous rappelle que pour les utiliser, vos zones doivent être au format date et si ce n’est pas le cas vous devrez utiliser la fonction date pour vous mettre dans le format attendu Exemple : values date(‘2012-01-01’)
Il est fortement conseillé si manipulez des dates de vous mettre dans un format *ISO pour éviter les problèmes de bascule des dates à 6 positions
1) Vous avez besoin de connaitre le premier jour du mois Vous avez la fonction FIRST_DAY() values FIRST_DAY(‘2012-12-12’) ; renverra 2012-12-01
pour le jour en cours FIRST_DAY(current date) = current date
2) Vous avez besoin de connaitre le dernier jour du mois Vous avez la fonction LAST_DAY() values LAST_DAY(‘2012-12-12’) ; renverra 2012-12-31
Pour le jour en cours LAST_DAY(current date) = current date
3) Vous voulez connaitre le numéro du jour dans l’année , le rang julien Vous avez la fonction DAYOFYEAR()
values DAYOFYEAR(‘2012-12-12’) renverra 347
4) Connaitre le jour de la semaine Vous avez la fonction DAYOFWEEK() elle vous renverra un numéro de 1 à 7 qui est le numéro du jour dans la semaine attention 1 c’est le dimanche values DAYOFWEEK(‘2012-12-12’) vous renverra 4 Si vous voulez commencer le lundi values DAYOFWEEK(‘2012-12-12’) – 1 , attention bien sur, un dimanche vous aurez 0
5) Connaitre le nombre de jours depuis le premier janvier 01
Vous avez la fonction DAYS()
values DAYS(‘2012-12-12’) renverra 734849 Cette fonction sert souvent pour calculer le nombre de jours entre 2 dates
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-01-27 10:42:242025-01-28 10:21:085 Astuces SQL sur les dates
SQL_DB2Lire facilement les données dans le journal d’un fichier
La journalisation des fichiers peut vous fournir plein d’informations notamment sur les modifications de données.
Pour exploiter ces informations, vous pouvez utiliser
le DSPJRN historique
la fonction table SQL QSYS2.DISPLAY_JOURNAL
Mais dans les 2 cas nous trouvons face à la complexité de la gestion de la zone entry_data qui contient un buffer complet de votre enregistrement base de données.
Nous proposons depuis longtemps l’outil gratuit ANAJRN que vous pouvez télécharger ici :
Le principe est le suivant, vous devez avoir le compilateur RPG sur votre partition, puisqu’il compile dynamiquement le programme de sortie.
Mais pour faire plus Kevin et moins Robert, j’ai mis au point une méthode à base de SQL qui nous permet d’arriver au même résultat.
La table NKSQL.STAGIAIRE a été crée et journalisée :
CREATE TABLE nksql.stagiaire
(
numero_stagiaire FOR COLUMN numstag int NOT NULL WITH DEFAULT,
nom_stagaire FOR COLUMN nomstag CHAR ( 50) NOT NULL WITH DEFAULT,
prenom_stagaire FOR COLUMN prestag CHAR ( 50) NOT NULL WITH DEFAULT,
date_entree FOR COLUMN datent DATE NOT NULL WITH DEFAULT,
PRIMARY KEY (numero_stagiaire)
) ;
Quelques actions sur la table pour alimenter le journal :
INSERT INTO NKSQL.STAGIAIRE VALUES(5, 'da Caravaggio', 'Michelangelo', date(now()));
UPDATE NKSQL.STAGIAIRE SET date_entree = '2024-12-06' WHERE numero_stagiaire = 2;
INSERT INTO NKSQL.STAGIAIRE VALUES(6, 'Magritte', 'René', date(now()- 2 months)) ;
DELETE FROM NKSQL.STAGIAIRE WHERE numero_stagiaire = 6;
L’exemple est prêt, retrouvons les données !
D’abord il faut retrouver le journal, et tant qu’à avoir SQL ouvert, j’utilise QSYS2.OBJECT_STATISTICS :
select objlib,
objname,
journal_library,
journal_name,
journal_images,
omit_journal_entry,
journal_start_timestamp
from table(qsys2.object_statistics('NKSQL', '*FILE', 'STAGIAIRE'))
where journaled = 'YES';
Ensuite il faut extraire ce journal. Dans un fichier temporaire ou non :
CREATE OR REPLACE TABLE qtemp.extrac_jrn AS (
SELECT journal_code,
journal_entry_type,
entry_timestamp,
user_name,
job_name,
job_number,
program_name,
entry_data
FROM TABLE (QSYS2.DISPLAY_JOURNAL(JOURNAL_LIBRARY =>'NKSQL',
JOURNAL_NAME =>'QSQJRN',
STARTING_RECEIVER_LIBRARY =>'*CURCHAIN',
JOURNAL_CODES =>'R',
OBJECT_LIBRARY =>'NKSQL',
OBJECT_NAME =>'STAGIAIRE',
OBJECT_OBJTYPE =>'*FILE',
OBJECT_MEMBER =>'STAGIAIRE')
) AS X
ORDER BY entry_timestamp DESC)
WITH DATA ON REPLACE DELETE ROWS;
On peut consulter cette extraction de journal, mais les données de enrty_data ne sont pas lisibles
SELECT * FROM qtemp.extrac_jrn ;
La requête qui suit va permettre de nous donner l’outil d’interprétation spécifique à cette table :
select
case
when data_type = 'DATE' then 'date(interpret(substr(entry_data, '
when data_type = 'TIMESTMP' then 'timestamp(interpret(substr(entry_data, '
else 'interpret(substr(entry_data, '
end concat
case
when ordinal_position = 1 then '1'
else
(select trim(char(sum(case when data_type = 'DATE' then storage+6 when data_type = 'TIMESTMP' then storage+16 else storage end))+1)
from qsys2.syscolumns c
where a.system_table_name = c.system_table_name
and a.system_table_schema = c.system_table_schema
and a.ordinal_position > c.ordinal_position)
end concat
', ' concat
case
when data_type = 'DATE' then '10'
when data_type = 'TIMESTMP' then '26'
else trim(char(storage))
end concat
') as ' concat
case
when data_type in( 'TIMESTMP', 'DATE') then 'CHAR'
else trim(data_type)
end concat
case
when data_type = 'BIGINT' then ''
when data_type = 'SMALLINT' then ''
when data_type = 'NUMERIC' then '(' concat trim(char(a.length)) concat ', ' concat trim(char(numeric_scale)) concat ')'
when data_type = 'DECIMAL' then '(' concat trim(char(a.length)) concat ', ' concat trim(char(numeric_scale)) concat ')'
when data_type = 'CHAR' then '(' concat trim(char(a.length)) concat ')'
when data_type = 'VARCHAR' then '(' concat trim(char(a.length)) concat ')'
when data_type = 'INTEGER' then ''
when data_type = 'TIMESTMP' then '(26)'
when data_type = 'DATE' then '(10)'
end concat
Case
when data_type in ('DATE', 'TIMESTMP') then ')) '
else ') as '
end concat
trim(system_column_name) concat
',' as interpretation
from qsys2.syscolumns a
join qsys2.sysfiles b
on a.system_table_name = b.system_table_name
and a.system_table_schema = b.system_table_schema
where b.native_type = 'PHYSICAL'
and b.file_type = 'DATA'
and b.system_table_name = 'STAGIAIRE'
and b.system_table_schema = 'NKSQL'
order by ordinal_position;
Ce resulset, à une virgule près, est intégré dans la requête de visualisation de qtemp.extrac_jrn :
select journal_entry_type,
entry_timestamp,
user_name,
job_name,
job_number,
program_name,
-- à la suite le copier coller du resultset de la requête précédente :
interpret(substr(entry_data, 1, 4) as INTEGER) as NUMSTAG,
interpret(substr(entry_data, 5, 50) as CHAR(50)) as NOMSTAG,
interpret(substr(entry_data, 55, 50) as CHAR(50)) as PRESTAG,
date(interpret(substr(entry_data, 105, 10) as CHAR(10))) DATENT
from qtemp.extrac_jrn;
On voit bien les deux créations, la mise à jour et la suppression d’enregistrement.
La partie la plus utile de cet article est celle qui produit les interpret à partir de QSYS2.SYSCOLUMNS et QSYS2.SYSFILES. Pour l’instant elle a bien fonctionné sur toutes les tables/fichiers que j’ai rencontré mais vous pouvez certainement l’améliorer !
Vous pouvez aussi directement inclure les interpret de la dernière requête dans celle du DISPLAY_JOURNAL.
/wp-content/uploads/2017/05/logogaia.png00Nicolas kintz/wp-content/uploads/2017/05/logogaia.pngNicolas kintz2025-01-21 08:51:132025-03-03 15:28:34Lire facilement les données dans le journal d’un fichier
La precaunistation d’IBM et de faire IPL à chaque appliction de PTFs pour ne pas perdre le chache SQL par exemple
Mais, il y a quand même un point inviter à en faire plus, c’est la mémoire qui est perdu sur certain travaux
Vous avez une vue QSYS2.SYSTMPSTG qui permet
La vue SYSTMPSTG contient une ligne pour chaque espace de stockage temporaire qui contient une quantité de stockage temporaire sur le système. Le stockage temporaire est un stockage qui ne persiste pas lors d’un redémarrage du système d’exploitation. on parle de « BUCKET »
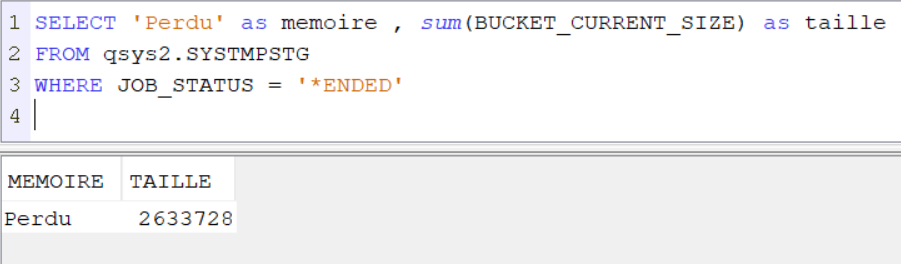
Voici une requête qui montre l’espace perdu par les jobs terminés
SELECT ‘Perdu’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’
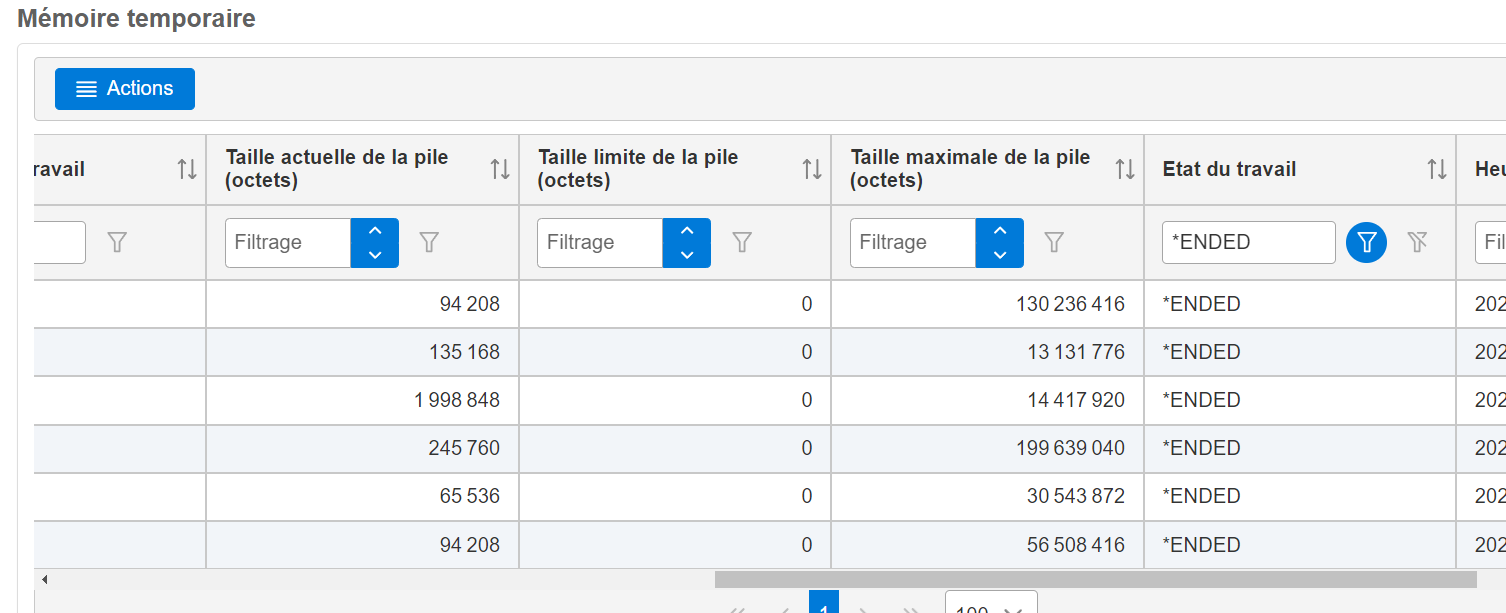
le détail
SELECT JOB_NAME, JOB_USER_NAME, JOB_NUMBER , BUCKET_CURRENT_SIZE FROM qsys2.SYSTMPSTG WHERE JOB_STATUS = ‘*ENDED’ order by BUCKET_CURRENT_SIZE desc
Voici une requête qui donne la taille totale
SELECT ‘Total’ as memoire , sum(BUCKET_CURRENT_SIZE) as taille FROM qsys2.SYSTMPSTG ;
Vous pouvez faire un ratio et si il est important 10 % par exemple
Vous devrez faire une IPL, pour récupérer cette mémoire
Vue dans Navigator For I
Ps: A ce jour il n’y a pas d’autres solutions pour récupérer cette mémoire