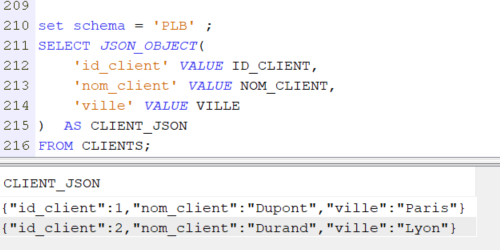
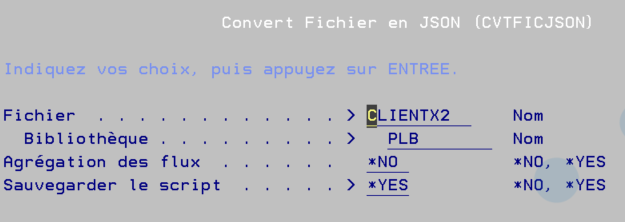
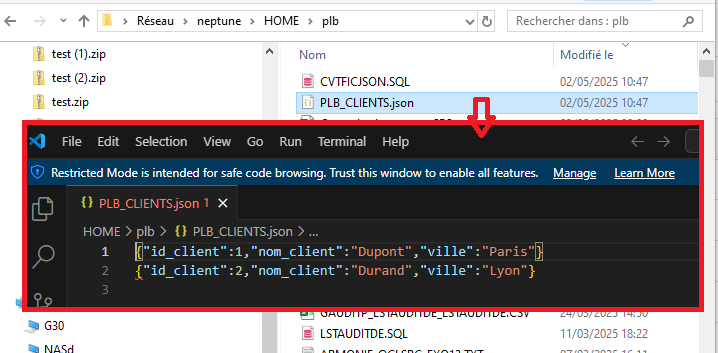
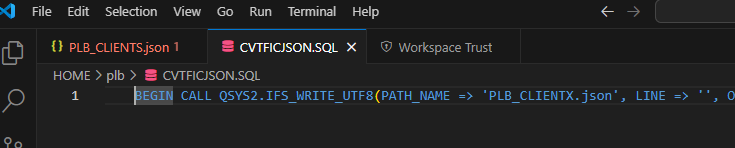
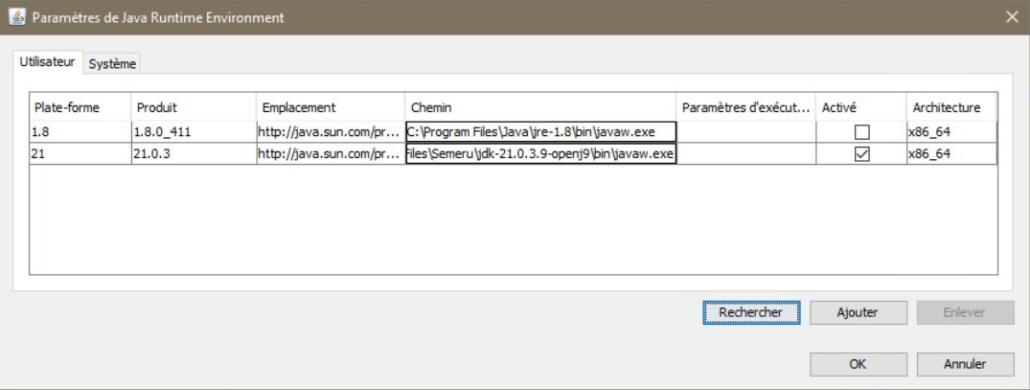
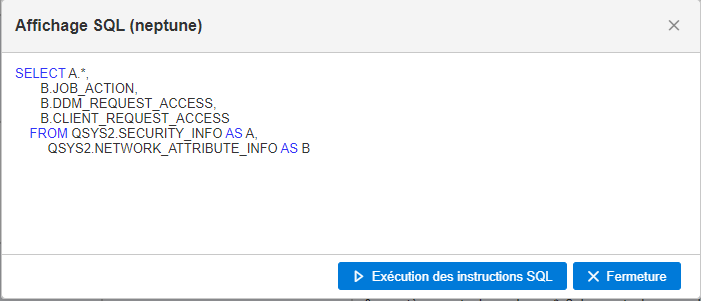
Vous connaissez l’option ACS qui vous permet de gérer vos SPOOLs , c’est une alternative intéressante à la commande WRKSPLF et si vos utilisateurs ont beaucoup de spools à gérer, ca peut leurs simplifier la tache, n’hésitez pas à leurs donner l’option, c’est relativement intuitif .
Vous pouvez par exemple faire simplement un fichier PDF et le joindre à un mail .
Vous voulez simplifiez la vie de vos utilisateurs en leurs présentant cette option à la place d’un WRKSPLF dans vos applications existantes
Voici une ébauche de solution
Un programme de lancement
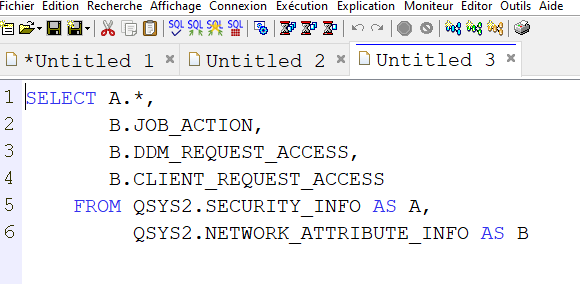
Vous devrez d’abord écrire un programme qui lance l’option ACS à partir de votre programme IBMi à base des commandes STRPCO et STRPCCMD
Voici un exemple RPGLE
**free
// Ce programme permet de remplacer les commandes WRKSPLF par
// L'explorateur de spool ACS
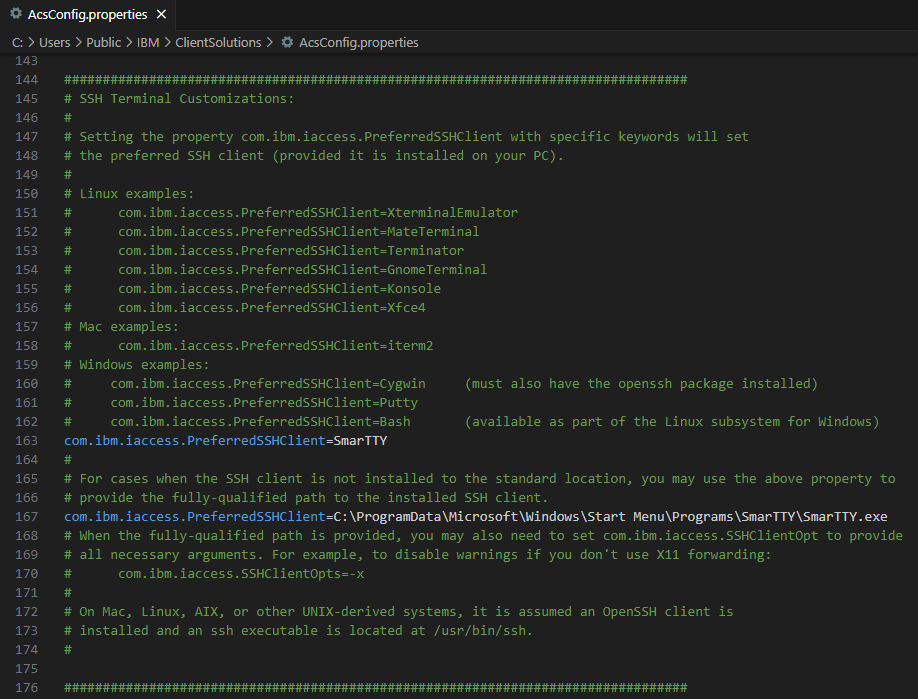
// ici le javabundle est dans \Users\Public\IBM\ClientSolutions\
//
dcl-s cmd CHAR(1024) ;
// démarrage de PCO
cmd ='STRPCO' ;
exec sql call qsys2.qcmdexc(:cmd) ;
// Démarrage de l'explorer de spools
cmd =' +
STRPCCMD PCCMD(''java -jar C:\Users\Public\IBM\ClientSolutions\acsbundle.jar +
/PLUGIN=splf /system=neptune +
Picked up _JAVA_OPTIONS: -Djava.net.preferIPv4Stack=true'') PAUSE(*NO)' ;
exec sql
call qsys2.qcmdexc(:cmd) ;
*inlr= *on ; On a fixé le répertoire du programme ici \Users\Public\IBM\ClientSolutions\
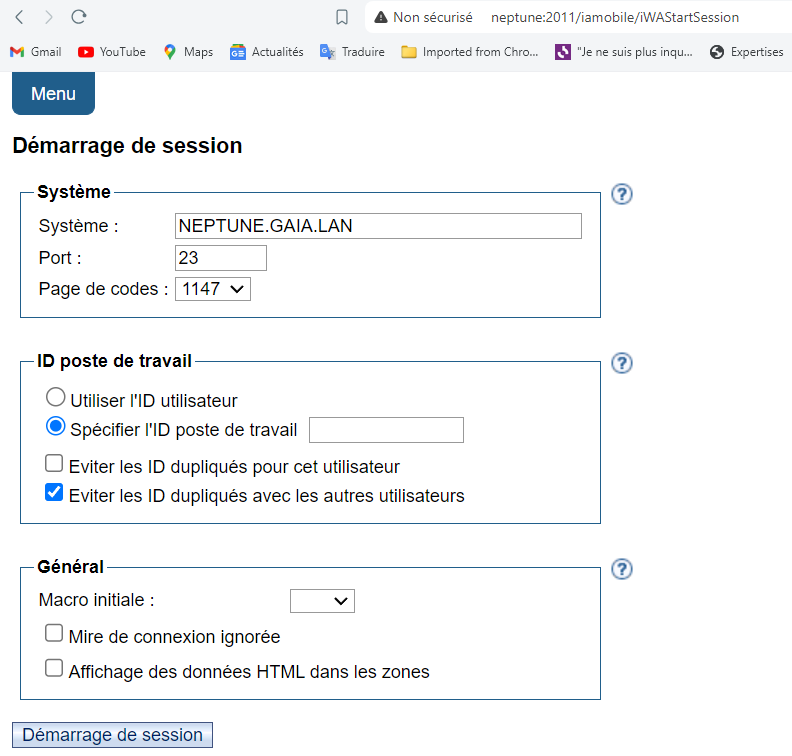
Si vous lancez ce programme, vous ouvrez alors l’écran ACS de gestion des spools, il est possible que cela vous redemande le mot de passe en fonction de votre paramétrage.
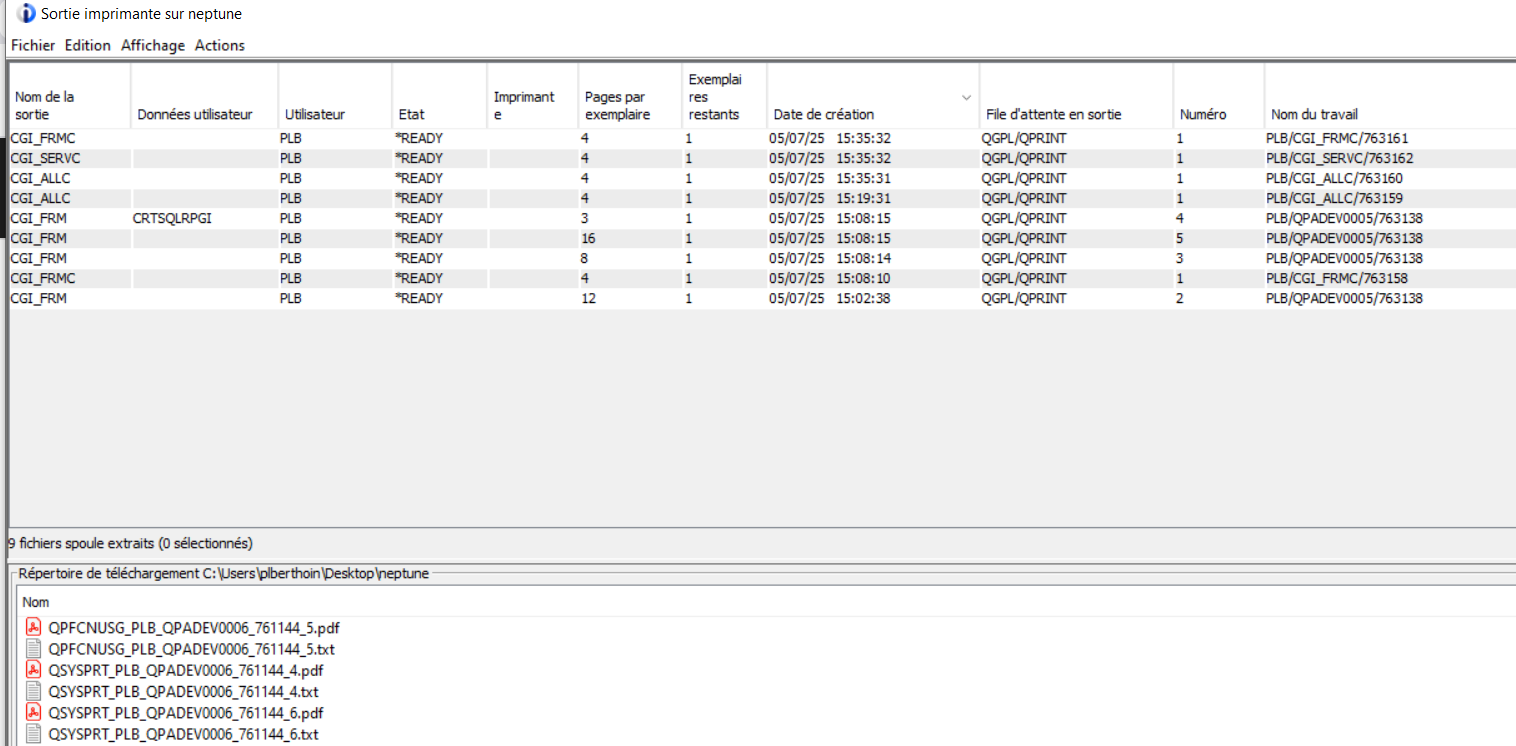
Un programme pour Associer à la commande WRKSPLF
Si vous voulez automatiser, vous pouvez utiliser un programme d’exit sur l’exit point QIBM_QCA_CHG_COMMAND
PGM PARM(&COMMAND)
/* ADDEXITPGM EXITPNT(QIBM_QCA_CHG_COMMAND) FORMAT(CHGC0100) PGMNBR(1) PGM(GDATA/WRKSPLFAC1) */
/* PGMDTA(*JOB 20 'WRKSPLF QSYSGAIA ') */
DCL VAR(&COMMAND) TYPE(*CHAR) LEN(256)
DCL VAR(&Cmdibm ) TYPE(*CHAR) LEN(20)
chgvar &cmdibm %sst(&COMMAND 29 20)
IF COND(&CMDIBM *EQ 'WRKSPLF QSYSGAIA') THEN(DO)
CALL PGM(WRKSPLFACS)
ENDDO
RETURN
ENDPGM Vous avez la commande ADDEXITPGM pour ajouter un programme d’exit , vous pouvez également passer par la commande ==>WRKREGINF et faire l’option 8
Remarque :
Vous pouvez comme ici mettre une commande WRKSPLF dans une bibliothèque avant QSYS, qui vous permettra de bien gérer que les interactifs et de bypasser si besoin en faisant ==>QSYS/WRKSPLF .
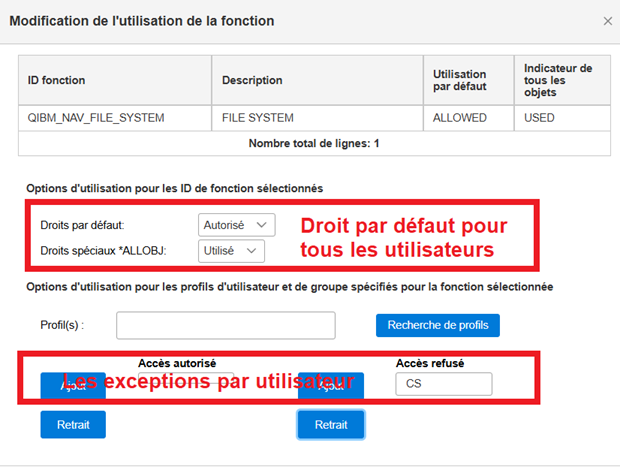
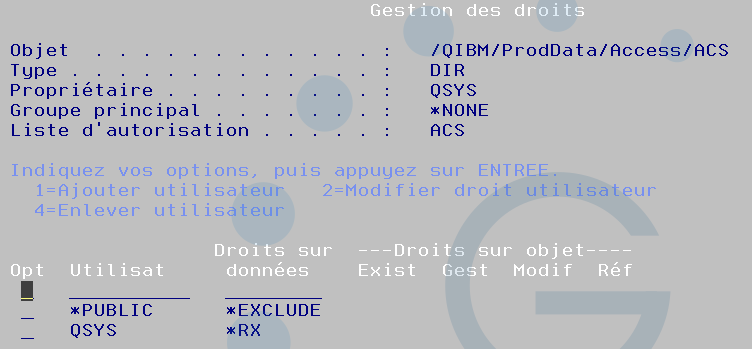
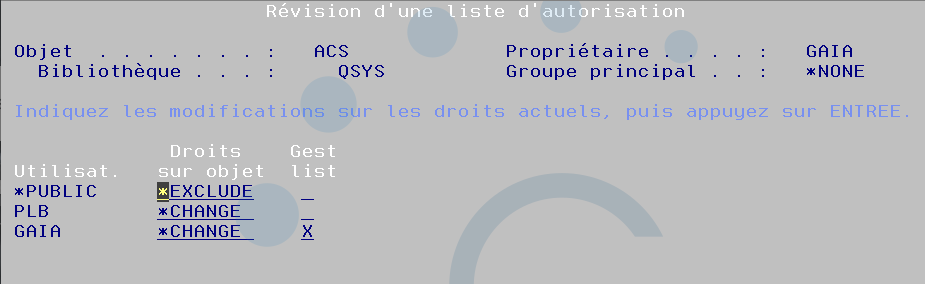
Vous aurez intérêt a identifier les utilisateurs qui doivent bénéficier de la fonctionnalité, une solution très simple c’est l’utilisation d’une liste d’autorisation