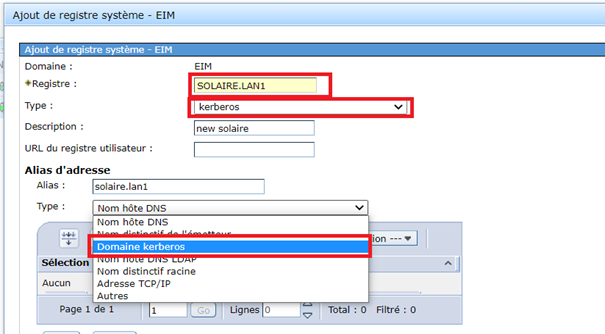
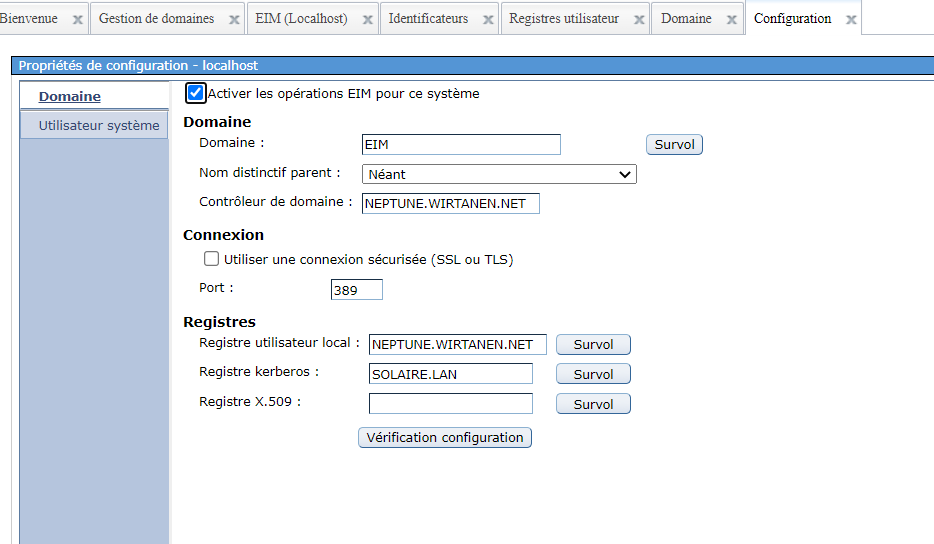
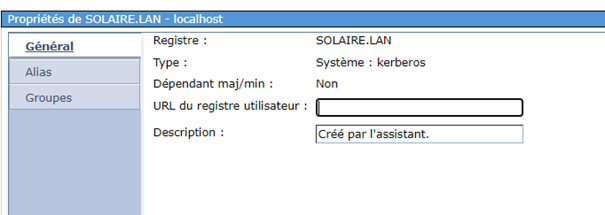
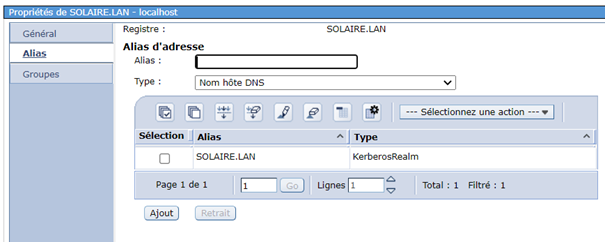
Supposons que vous utilisiez le job scheduler de l’IBMi, (WRKJOBSCDE), si vous utilisez AJS seul le fichier de départ change mais la démarche reste la même.
Notre méthode ne marche que pour le jour courant.
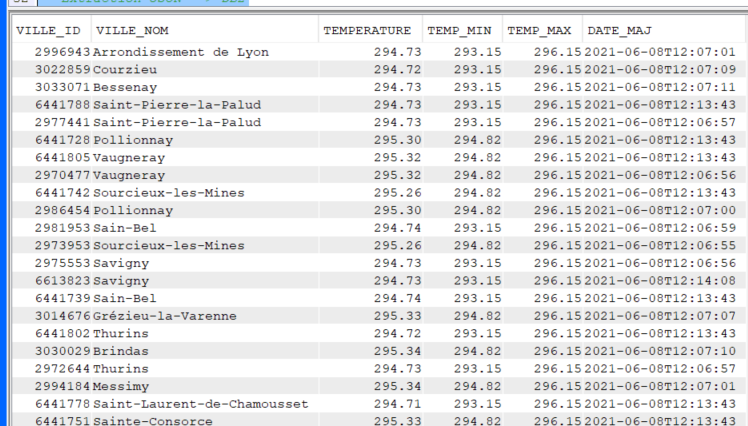
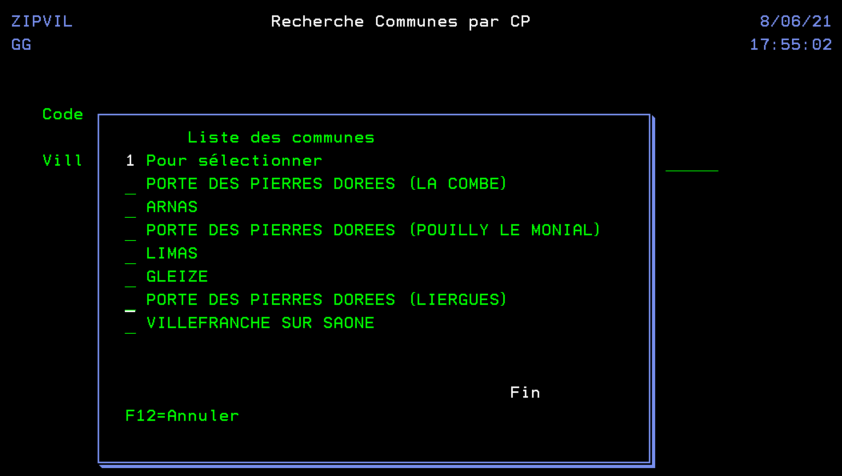
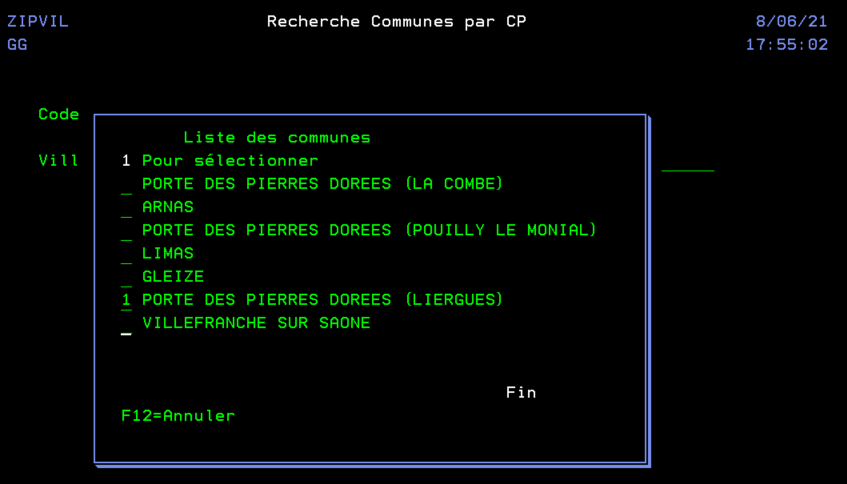
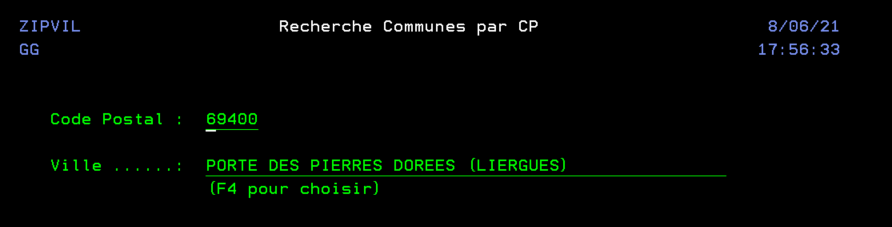
On va utiliser la date de prochaine soumission égale à la date du jour dans notre fichier SCHEDULED_JOB qui contient les jobs planifiés .
Vous devez planifier un job tous les matins à 0h et 2 minutes dans la file d’attente QCTL pour être sûr de le faire passer
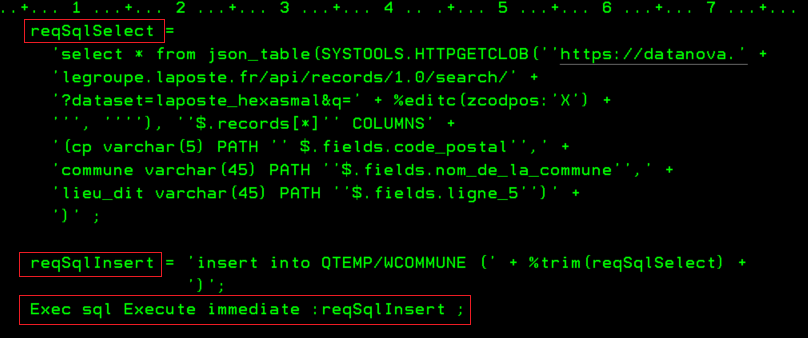
Ce job aura une requête de ce type qui créera une table plandujour
create table plandujour as (
Select SCHEDULED_JOB_NAME, SCHEDULED_TIME,
ifnull(DESCRIPTION, » ») as description
from QSYS2.SCHEDULED_JOB_INFO
where NEXT_SUBMISSION_DATE = current date and
substr(SCHEDULED_JOB_NAME, 1, 1) <> »Q »
and status <> »HELD »
order by SCHEDULED_TIME ) with data +
Vous avez ainsi tous les jobs prévus pour la journée par heure de planification.
Maintenant nous allons voir comment suivre le déroulement des ces travaux
Pour suivre vos travaux on va utiliser la fonction table suivante HISTORY_LOG_INFO
exemple pour avoir les jobs du jour
SELECT * FROM TABLE(QSYS2.HISTORY_LOG_INFO(CURRENT DATE)) X
Chaque job qui tourne sur le système va générer au moins 2 messages
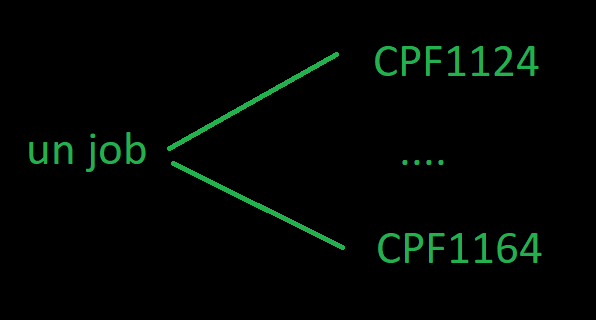
un CPF1124 Travail …/…/… démarré le
un CPF1164 Travail …/…/… arrêté le
donc
si votre travail n’a pas tourné vous n’avez aucun message
si votre travail tourne vous avez un CPF1124
si votre travail est terminé vous avez un CPF1164
Vous pouvez déjà suivre l’avancement grâce à la zone MESSAGE_TIMESTAMP et avoir une durée entre les 2 messages
Remarque :
pour savoir si votre travail c’est terminé normalement c’est un peu plus compliqué, vous devrez analyser le code fin par exemple dans la zone MESSAGE_TEXT.
code fin 0 indiquant une fin normale du traitement
Un exemple de requête (à améliorer)
pour les codes fin , pour les jobs qui débordent de la journée etc…
WITH logdujour (mgr_id, mgr_name, mgr_dept) AS(
SELECT * FROM TABLE(QSYS2.HISTORY_LOG_INFO(CURRENT DATE)) X)
select
a.SCHEDULED_JOB_NAME as nom_travail,
a.SCHEDULED_TIME as
HEURE_prev ,
ifnull(b.MESSAGE_TIMESTAMP, »1911-11-11-00.00.00.00000 ») as Heure_debut ,
ifnull(c.MESSAGE_TIMESTAMP, »1911-11-11-00.00.00.00000 ») as heure_fin,
ifnull(c.SEVERITY, »99 ») as code_sev ,
ifnull(b.FROM_JOB, » ») as name_JOB
from plandujour a
Left outer join logdujour b
on B.MESSAGE_ID = »CPF1124 » and B.FROM_JOB like( »% » concat
A.SCHEDULED_JOB_NAME concat »% »)
Left outer join logdujour c
on C.MESSAGE_ID = »CPF1164 » and C.FROM_JOB like( »% » concat
A.SCHEDULED_JOB_NAME concat »% »)
Vous pouvez planifier un job chaque soir qui vous envoie un récapitulatif de la journée, ou que les jobs en erreur par exemple.
Vous pouvez historiser ces données si vous avez besoin de consolider un suivi, etc …
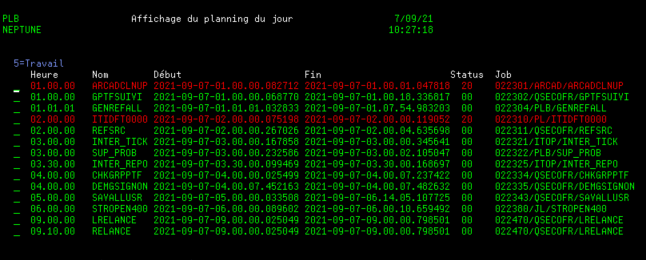
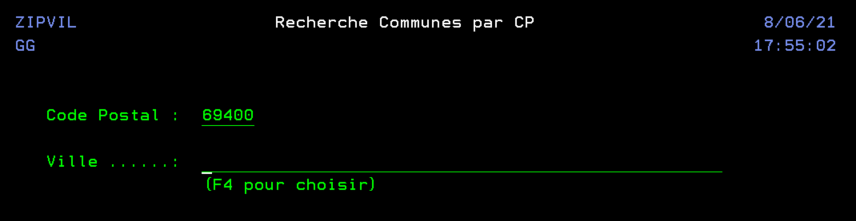
Exemple d’un outil packagé utilisé dans notre centre de service pour suivre le planning quotidien:
https://github.com/Plberthoin/PLB/tree/master/DSPPLNPRD