Vous pouvez demander un tas d’informations d’audit pour tracer les violations de sécurité par exemple
Vous devez avoir le droit *AUDIT sur votre profil pour la mettre en place, c’est valeurs système qui permettent de le paramétrer les informations souhaitées
QAUDCTL, QAUDLVL, QAUDLVL2
Pour chaque information demandée, vous allez avoir un poste qui est créé dans le journal d’audit QAUDJRN.
Pour consolider ces informations, vous devez les copiez dans des fichiers il existait jusqu’à présent 2 méthodes
1) Les fichiers modèles utilisables dans des commandes IBMi
ils sont dans QSYS et commencent par QASY
DSPJRN QAUDJRN OUTPUT(*OUTFILE)
OUTFILE(MABIB/QASYPWJ5)
JRNCODE(‘T’) ENTTYP(‘PW’)
exemple pour les types PW, c’est le fichier QASYPWJ5 que vous devez dupliquer dans votre bibliothèque
DSPJRN JRN(QAUDJRN) ENTTYP(‘PW’)
OUTPUT(OUTFILE) OUTFILFMT(TYPE5) OUTFILE(MABIB/WASYPWJ5)
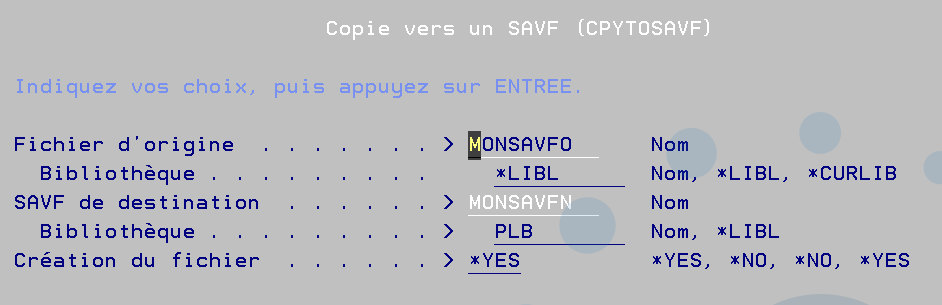
La stratégie est la suivante , la première fois vous demandez la création du fichier de sortie par un crtdupobj
et après vous ajoutez à ce fichier tous les soirs à 23 h 59 les postes PW
2) Les Technology Refresh nous apportent régulièrement des services
Ces services permettent de lire directement ces informations par SQL.
c’est les fonctions tables qui se trouve dans SYSTOOLS et qui s’écrivent SYSTOOLS.AUDIT_JOURNAL_XX()
XX étant le type
exemple pour les types PW
SYSTOOLS.AUDIT_JOURNAL_PW()
voici un exemple
select A.VIOLATION_TYPE_DETAIL, A.AUDIT_USER_NAME , A.REMOTE_ADDRESS, A.ENTRY_TIMESTAMP
from table (SYSTOOLS.AUDIT_JOURNAL_PW(STARTING_TIMESTAMP => current timestamp – 1 days)) A
order by A.ENTRY_TIMESTAMP desc
La stratégie est la suivante , la première fois vous demandez la création du fichier de sortie par un create table as()
et après vous ajoutez à ce fichier tous les soirs à 23 h 59 les postes PW par un insert
3) Avec la TR (4 pour V7R5 et 10 pour V7R4)
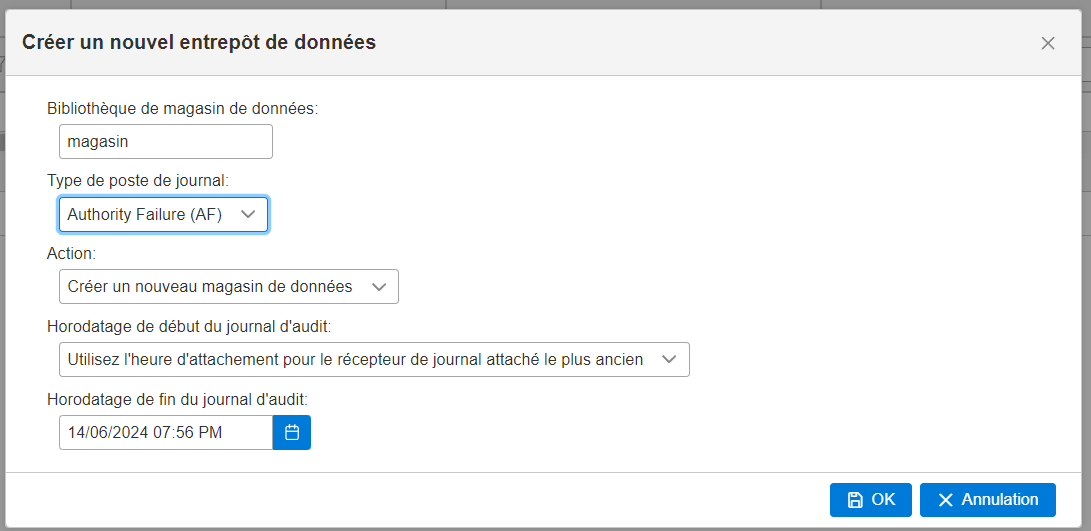
elle vous apporte une solution intégrée pour créer votre DATAMART
https://www.ibm.com/support/pages/ibm-i-75-tr4-enhancements
Vous avez 2 services
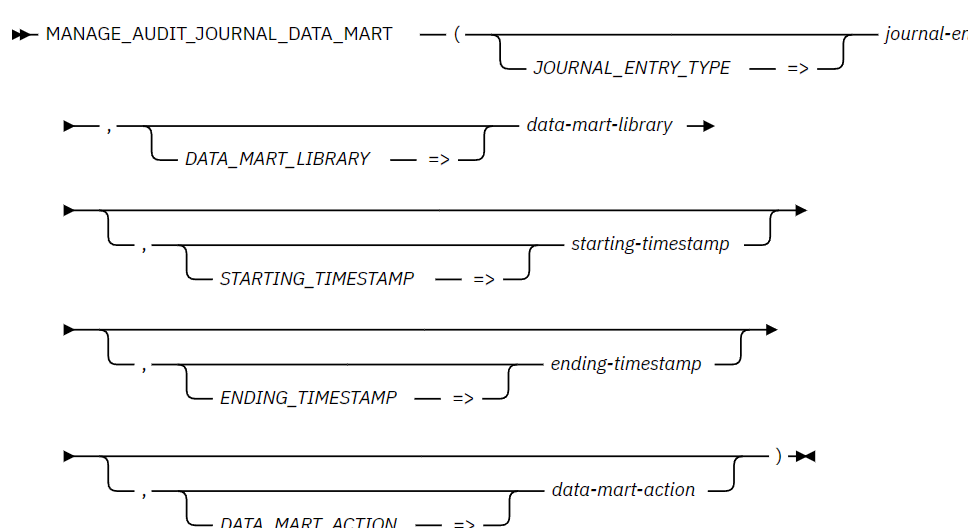
QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART procedure
QSYS2.AUDIT_JOURNAL_DATA_MART_INFO view
https://www.ibm.com/support/pages/node/7148888
ces 2 services vont faire ce que vous faisiez par SQL ou commande ibmi 2
Création du datamart le fichier résultat s’appelera AUDIT_JOURNAL_XX dans la bibliothèque que vous aurez choisi
Création de la table
CALL QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART(JOURNAL_ENTRY_TYPE => ‘PW’,
DATA_MART_LIBRARY => ‘MALIB’,
STARTING_TIMESTAMP => CURRENT DATE – 1 MONTH,
ENDING_TIMESTAMP => CURRENT TIMESTAMP);
Alimentation quotidienne de la table
CALL QSYS2.MANAGE_AUDIT_JOURNAL_DATA_MART(JOURNAL_ENTRY_TYPE => ‘PW’,
DATA_MART_LIBRARY => ‘MALIB’,
STARTING_TIMESTAMP => ‘*CONTINUE’,
ENDING_TIMESTAMP => CURRENT TIMESTAMP,
DATA_MART_ACTION => ‘ADD’
);
Vous avez une vue qui vous permet de suivre vos mises à jour de datamart
SELECT DATA_MART_LIBRARY, DATA_MART_TABLE, JOURNAL_ENTRY_TYPE, BUILD_END, FAILURE_DETAIL
FROM QSYS2.AUDIT_JOURNAL_DATA_MART_INFO
WHERE JOURNAL_ENTRY_TYPE = ‘PW’ AND DATA_MART_LIBRARY = ‘MALIB’ ;
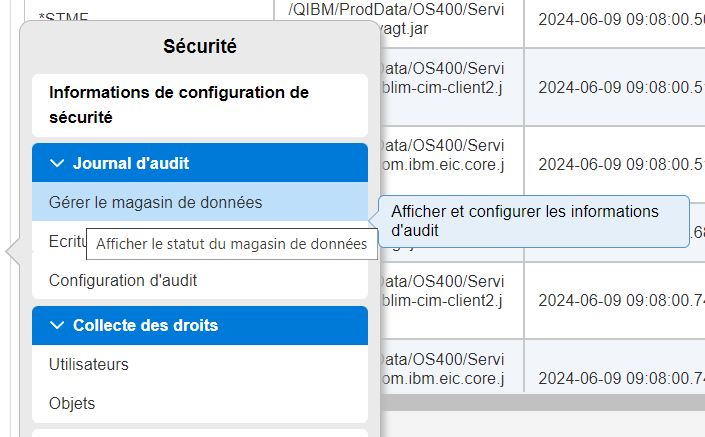
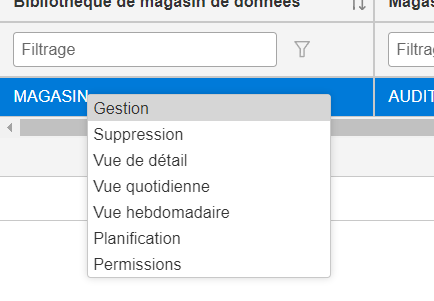
Vous pourrez également manager par Navigator for i
Remarque :
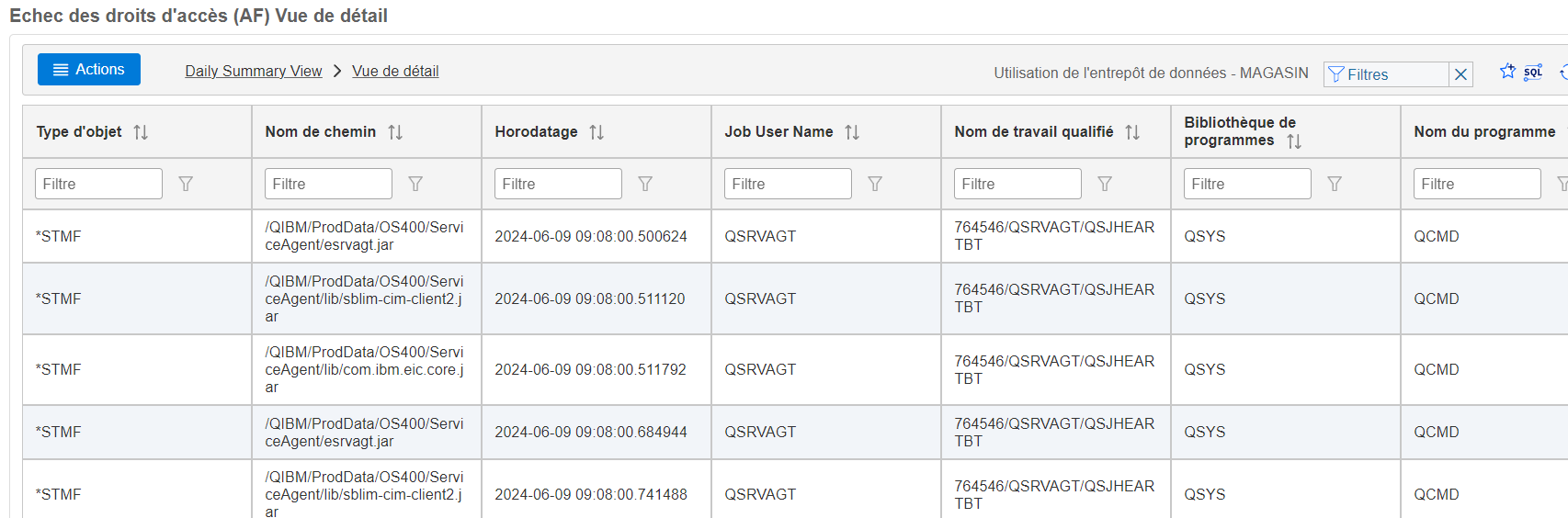
Bien sur vous avez toujours aussi un onglet dans Navigator for i qui vous permet de voir sous forme de graphique les résultats , mais attention uniquement sur les postes en cours .
Si vous avez déjà une solution, c’est compliqué de revenir dessus, mais si vous n’avez rien ca vous simplifier considérablement les taches.
Attention dans tous les cas c’est à vous d’épurer les récepteurs quand vous les avez traité