Vous changez de machine ou de version et les dates de référence de vos objets et vos sources vont être remise à zéro, grâce aux services SQL , vous pouvez facilement conserver temporairement ces informations
Vous pourrez par exemple avoir besoin de ces informations pour faire une analyse d’impact sur l’utilisation de certain programmes ou de sources
Pour garder une trace de ces informations voici ce que vous pouvez faire
créer une bibliothèque
==> CRTLIB MIGRATION
vous avez intérêt à extraire les informations juste avant la migration
1) Sur les objets
Vous pouvez utiliser la fonction table QSYS2.OBJECT_STATISTICS
exemple :
create table migration.lstobj as( SELECT * FROM TABLE ( QSYS2.OBJECT_STATISTICS(‘ALL’,’ALL’) ) AS X ) with data
Vous pouvez si vous le voulez choisir ou éliminer des objets ou des bibliothèques.
2) sur les sources
Si vous avez des fichiers sources QRPGLESRC, QCLSRC etc …
Vous pouvez utiliser la vue QSYS2.SYSPARTITIONSTAT
exemple :
create table migration.lstsrc as( SELECT * FROM qsys2.SYSPARTITIONSTAT WHERE not source_type is null and NUMBER_ROWS > 0 ) with data
ici on limite aux membres sources non vide
Si vous avez des fichiers sources dans L’ifs, nodejs, php, python, ou même des développements traditionnels en RPGLE ou CLLE
Vous pouvez utiliser la fonction table QSYS2.IFS_OBJECT_STATISTICS
exemple :
create table migration.lstifs1 as( SELECT * FROM TABLE ( qsys2.ifs_object_statistics( start_path_name => ‘/Votre_repert/’ , subtree_directories => ‘YES’ ) ) ) with data
Vous devrez limiter à vos repertoires de sources , vous pouvez en faire plusieurs
Ensuite vous devrez envoyer votre bibliothèque sur le systéme cible
Soit par la migration naturelle qui emmènera toutes les bibliothèques ou par une opération spécifique d’envoi de la bibliothèque FTP, SAVRSTLIB etc…
Attention :
Après 6 mois cette bibliothèque devra être supprimée, elle ne servira plus à rien
Remarque :
Vous pouvez également inclure dans cette bibliothèque d’autres éléments qui pourront être utile comme :
La liste des valeurs systèmes , QSYS2.SYSTEM_VALUE_INFO Le planning des travaux , QSYS2.SCHEDULED_JOB_INFO les programmes d’exit , QSYS2.EXIT_PROGRAM_INFO les watchers , QSYS2.WATCH_INFO les bases de données DRDA , QSYS2.RDB_ENTRY_INFO les reroutages de travaux , QSYS2.ROUTING_ENTRY_INFO la table des réponses par défaut , QSYS2.REPLY_LIST_INFO etc …
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-05-08 07:31:422025-05-08 07:31:43Conserver des informations avant migration
Vous voulez commencer à utiliser des webservices en étant consommateur à partir de votre partition IBMi Et vous de ne savez pas par ou commencer voici un exemple très simple, prêt à l’emploi que vous pourrez améliorer on a choisi le site jsonplaceholder.typicode.com qui permet un accès libre , merci à eux On peut l’utiliser à partir d’un GET et le flux renvoyé est du JSON On utilisera la fonction QSYS2.HTTP_GET de la manière la plus basic On parsera le flux recu en utilisant la fonction JSON table
2 prérequis :
Vous devrez avoir une version V7R4
Votre partition devra sortir vers le site jsonplaceholder.typicode.com
**free
ctl-opt dftactgrp(*no) actgrp(*caller);
// Un exemple simple d'un appel de webservice
// on utilise le site jsonplaceholder.typicode.com
// Vous avez les numéros de 1 à 11
// Le flux renvoyé est du JSON on le parse dans une deuxième requête
//
dcl-s url varchar(256) inz('https://jsonplaceholder.typicode.com/users/1');
dcl-s Response Varchar(10000);
dcl-s nom varchar(100);
dcl-s email varchar(100);
dcl-s ville varchar(100);
dcl-s erreur varchar(200);
// Utilisation de la fonction QSYS2.HTTP_GET
exec sql
set :response = QSYS2.HTTP_GET(:url) ;
if sqlcode <> 0;
erreur = 'Erreur appel HTTP_GET : SQLCODE = ' + %char(sqlcode);
SND-MSG *INFO erreur;
return;
endif;
// Parsing du JSON avec JSON_TABLE
exec sql select name, email, address_city into
:nom, :email, :ville
from json_table(
:response, '$' columns ( name varchar(100) path '$.name',
email varchar(100) path '$.email',
address_city varchar(100) path '$.address.city' ) ) as JT;
if sqlcode <> 0;
erreur = 'Erreur parsing JSON : SQLCODE = ' + %char(sqlcode);
SND-MSG *INFO erreur;
return;
endif;
// Affichage du résultat
SND-MSG *INFO ('Nom : ' + nom);
SND-MSG *INFO ('Email : ' + email);
SND-MSG *INFO ('Ville : ' + ville);
// Fin de traitement
return;
.
Conclusion
Simple et efficace
Vous voyez qu’une connaissance de JSON et indispensable et donc au moins une V7R4
Appeler un webservice c’est assez simple Attention la mise au point dans certains cas peut être compliqué les idées d’amélioration seront : Tester le httpstatus qui peut être renvoyer dans le Header Parser le flux directement dans la requete http_get
etc …
Pour en savoir plus adressez vous à mes collègues qui sont des spécialistes
Une liste de sites libres pour vous entrainer
Une citation du philosophe Chuck Norris https://api.chucknorris.io/jokes/random indispensable, pour bien démarrer la journée
Bored API https://www.boredapi.com/api/activity Suggestion d’activité fun
Cat Facts https://catfact.ninja/fact Donne un fait amusant sur les chats, pour les « matouvus »
IP API (test IP) https://ipinfo.io/json
Retourne ton IP, localisation, etc. moins fun mais intéressant
Open-Meteo (météo) https://api.open-meteo.com/v1/forecast?… Météo gratuite sans clé , les autres nécessitent une clé, vous devrez lui passer des coordonnées
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-05-05 08:06:122025-05-06 08:50:01Débuter avec les webservices
Vous devez échanger un fichier avec un partenaire qui vous le demande au format JSON
Il n’existe pas de CVTJSONxx comme la commande CPYTOIMPF pour le CSV
Pas de panique vous avez des services SQL qui font ceci voici un exemple :
Création d’une table de test
SET SCHEMA = ‘votre base’; CREATE OR REPLACE TABLE CLIENTS ( ID_CLIENT INTEGER NOT NULL WITH DEFAULT, NOM_CLIENT VARCHAR ( 50) NOT NULL WITH DEFAULT, VILLE VARCHAR ( 50) NOT NULL WITH DEFAULT ) ; INSERT INTO CLIENTS VALUES(1, ‘Dupont’, ‘Paris’) ; INSERT INTO CLIENTS VALUES(2, ‘Durand’, ‘Lyon’) ;
Voici la syntaxe qu’il vous faudra utiliser pour le convertir sous forme de flux json
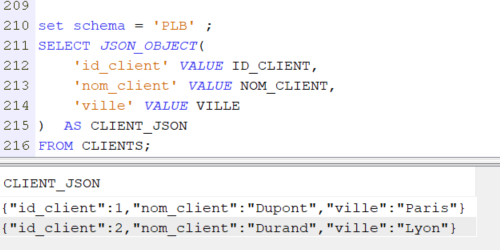
SELECT JSON_OBJECT(
'id_client' VALUE ID_CLIENT,
'nom_client' VALUE NOM_CLIENT,
'ville' VALUE VILLE
) AS CLIENT_JSON
FROM CLIENTS;
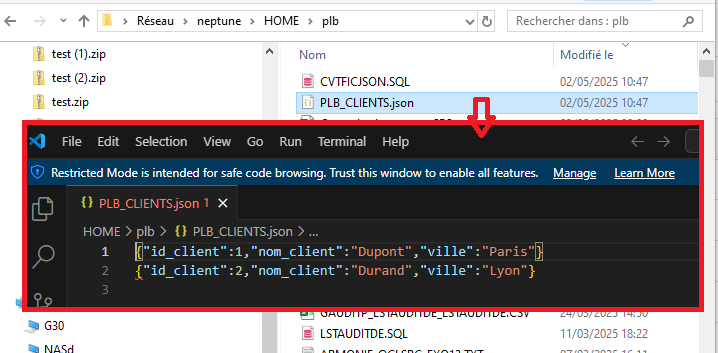
Maintenant il va falloir générer le fichier .JSON dans l’IFS par exemple en utilisant la procédure IFS_WRITE_UTF8
Malheureusement ce service n’existe pas sous forme de fonction on devra utiliser une des possibilités de SQL « Dynamic compound statement » qui permet de compiler un module dynamiquement
Ce qui donnera donc
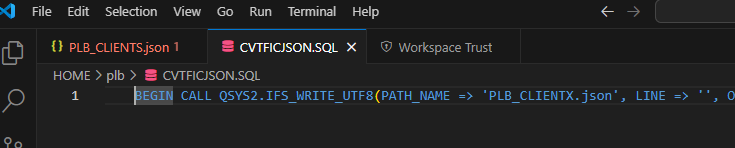
BEGIN
CALL QSYS2.IFS_WRITE_UTF8(
PATH_NAME => 'PLB_CLIENTS.json',
LINE => '',
OVERWRITE => 'REPLACE',
END_OF_LINE => 'NONE'
);
FOR SELECT TRIM(CAST(JSON_OBJECT(
'id_client' VALUE ID_CLIENT,
'nom_client' VALUE NOM_CLIENT,
'ville' VALUE VILLE
) AS VARCHAR(32000))) AS Line_to_write
FROM PLB.CLIENTS
DO
CALL QSYS2.IFS_WRITE_UTF8(
PATH_NAME => 'PLB_CLIENTS.json',
LINE => Line_to_write
);
END FOR;
END;
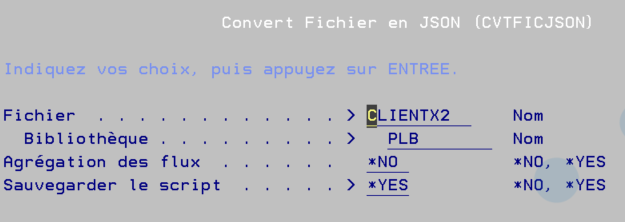
Si vous avez beaucoup de fichiers à convertir ca peut être fastidieux pas de panique nous avons fait une commande qui va vous aider
https://github.com/Plberthoin/PLB/tree/master/GTOOLS, vous avez l’habitude un source SQLRPGLE et un source CMD à compiler , voila SME
Vous pouvez enregistrer le scripte SQL (CVTFICJSON.SQL) avec l’option Sauvegarder le scripte
Vous pourrez le customiser :
en le formatant par ACS ,
en enlevant des zones
en sélectionnant des enregistrements
etc …
Remarque :
Vous avez une option pour agréger
Vous pouvez faire beaucoup mieux , c’est juste pour vous aider à démarrer dans le domaine
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-05-02 12:16:162025-05-02 12:16:17Convertissez un fichier en JSON
pgm parm(&type)
dcl &type *char 4
dclf qsys/QADSPFFD
/* Récupération du CCSID de la première zone de qadbxref */
DSPFFD FILE(QSYS/QADBXREF) OUTPUT(*OUTFILE) +
OUTFILE(QTEMP/WADSPFFD) /* w */
OVRDBF FILE(QADSPFFD) TOFILE(QTEMP/WADSPFFD) +
LVLCHK(*NO)
RCVF
/* Changement du job au bon CCSID */
chgjob ccsid(&WHCSID)
/* Pour contrôler les objets fournis par IBM qui sont manquants */
if cond(&type = '*CHK') then(do)
CALL QSYS/QSQIBMCHK
enddo
/* Pour corriger */
if cond(&type = '*FIX') then(do)
CALL QSYS/QSQSYSIBM
enddo
dltovr FILE(QADSPFFD)
endpgm
Pour contrôler
==>CTLSRVSQL *CHK
Vous allez avoir ces messages dans la LOG
QSQXRLF OBJECTS FOUND = 55 QSQXRLF OBJECTS UNKNOWN = 0 QSQXRLF OBJECTS MISSING = 0 QSQSYSIBM OBJECTS FOUND = 716 QSQSYSIBM OBJECTS UNKNOWN = 0 QSQSYSIBM OBJECTS MISSING = 0 SYSTOOLS OBJECTS FOUND = 105 SYSTOOLS OBJECTS UNKNOWN = 0 SYSTOOLS OBJECTS MISSING = 0 TOTAL IBM OBJECTS FOUND = 876 TOTAL IBM OBJECTS UNKNOWN = 0 TOTAL IBM OBJECTS MISSING = 0 QSQIBMCHK – OBJECT VERIFICATION COMPLETE
Si vous avez des erreurs par exemple 1 dans OBJECTS UNKNOWN vous devrez corriger
Pour corriger
==>CTLSRVSQL *FIX
Vous allez avoir ces messages dans la LOG
QSQSYSIBM ASNEEDED PROCESSING SUCCESSFUL FOR 1236 COMPONENTS.
PS : Vous n’avez pas besoin d’être en mode restreint Mais vous devez être *SECADM et *ALLOBJ
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-04-18 13:44:082025-04-22 13:56:30Contrôler la cohérence des services SQL
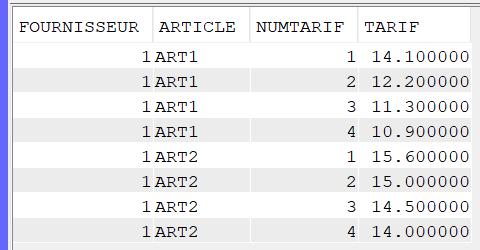
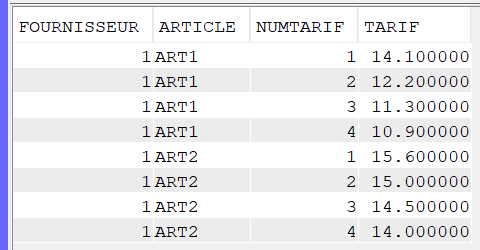
Le pivot est une technique que vous permet de faire pivoter la sortie d’une requête de ligne à colonne et inversement.
Comme par exemple transformer ce résultat :
Par ce résultat :
Commençons par la création des tables
Imaginons que nous avons un ancien fichier des tarifs contenant 4 tarifs (dans 4 colonnes pour la table TARIF_H et 4 enregistrements pour la table TARIF_V)
TARIF_H : Table avec des tarifs sur une seule ligne mais dans plusieurs colonnes
Utilisation du mot clé LATERAL pour faire une jointure LATERAL et afficher les tarifs sur plusieurs lignes. Nous allons la combiner avec la fonction VALUE ce qui nous permettra d’ajouter une colonne avec la position du tarif (Tarif colonne 1 = position tarif 1, Tarif colonne 2 = position tarif 2 etc…).
select T.fournisseur, T.article, V.POSITIONTARIF, V.VALEURTARIF
from FG.TARIF_H as T,
LATERAL(VALUES (1, T.TARIF1),
(2, T.TARIF2),
(3, T.TARIF3),
(4, T.TARIF4)) as V(POSITIONTARIF, VALEURTARIF)
where FOURNISSEUR = 1;
ps : La clause where n’est pas indispensable pour notre cas.
Résultat :
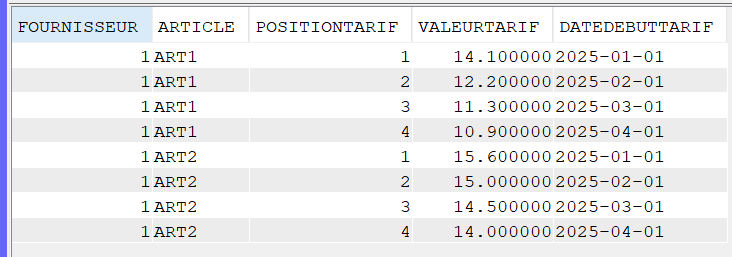
Imaginons que nous avons pour chaque tarif une colonne « date début tarif » (et certainement fin de tarif 🙂 ).
alter table TARIF_H add column DATEDEBUTTARIF1 date;
alter table TARIF_H add column DATEDEBUTTARIF2 date;
alter table TARIF_H add column DATEDEBUTTARIF3 date;
alter table TARIF_H add column DATEDEBUTTARIF4 date;
Il faudra simplement l’ajouter dans la jointure LATERAL ainsi que dans la sélection des zones à afficher :
select T.fournisseur, T.article, V.POSITIONTARIF, V.VALEURTARIF, V.DATEDEBUTTARIF
from FG.TARIF_H as T,
LATERAL(VALUES (1, T.TARIF1, T.DATEDEBUTTARIF1),
(2, T.TARIF2, T.DATEDEBUTTARIF2),
(3, T.TARIF3, T.DATEDEBUTTARIF3),
(4, T.TARIF4, T.DATEDEBUTTARIF4)) as V(POSITIONTARIF, VALEURTARIF, DATEDEBUTTARIF)
where FOURNISSEUR = 1;
Résultat :
Passage d’un affichage vertical à horizontal
Cette fois-ci nous allons utiliser la fonction d’agrégation MAX (même si nous savons qu’il n’y aura qu’un tarif avec le numéro 1, 2, 3 etc…) avec un groupage sur le fournisseur et numéro d’article.
select fournisseur, article,
max(case when numtarif = 1 then tarif end) as Tarif1,
max(case when numtarif = 2 then tarif end) as Tarif2,
max(case when numtarif = 3 then tarif end) as Tarif3,
max(case when numtarif = 4 then tarif end) as Tarif4
from TARIF_V
group by fournisseur, article;
Résultat :
Nous sommes d’accord qu’il existe d’autres méthodes pour faire pivoter des données (listagg etc…).
SQL_DB2Contrôler la liste des utilisateurs inscrits à SMTP via sql
Petits rappels en préambule :
SNA n’est plus à utiliser, on le retrouve pourtant encore très souvent en usage sur de nombreux IBM i. Il faut passer au SMTP.
Les utilisateurs SMTP sont inscrits à un registre.
Pour accéder à ce registre on peut passer par la commande 5250 : WRKSMTPUSR – Work with All SMTP Users.
Si vous ne souhaitez pas inscrire tous vos profils au registre SMTP, il est d’usage de créer un profil NOREPLY afin de l’ajouter au registre, puis de soumettre les envois de mail, exemple :
SBMJOB CMD(SNDSMTPEMM RCP(('julien.laurier@gaia.fr')) SUBJECT(TEST) NOTE('This is not a test.')) USER(NOREPLY)
Lors de l’utilisation de la commande SNDSMTPEMM dans un programme, il est préférable de commencer par contrôler la présence du profil dans le registre SMTP. Ce registre est stocké non pas dans une table mais dans un fichier de configuration dans l’ifs : ‘/QTCPTMM/CONFIG/USERS.DAT’. C’est cette liste qui est affichée par WRKSMTPUSR, malheureusement, ces informations ne sont pas adressables directement via SQL. Il nous revient alors de créer nous même de quoi accéder à ces informations pour simplifier ces usages.
Voici une requête SQL qui permet de parser les informations présentes dans le fichier :
SELECT MAX(CASE WHEN entries.ordinal_position = 1 THEN entries.element END) AS "User profile",
MAX(CASE WHEN entries.ordinal_position = 2 THEN entries.element END) AS "SMTP mailbox alias",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 1 THEN details.element END) AS "Domain index",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 2 THEN details.element END) AS "Domain Name",
MAX(CASE WHEN entries.ordinal_position = 4 THEN entries.element END) AS "SDD name compatibility",
MAX(CASE WHEN entries.ordinal_position = 5 THEN entries.element END) AS "SDD address compatibility",
MAX(CASE WHEN entries.ordinal_position = 6 THEN entries.element END) AS "Forwarding to",
MAX(CASE WHEN entries.ordinal_position = 7 THEN entries.element END) AS "Originating from",
MAX(CASE WHEN entries.ordinal_position = 8 THEN entries.element END) AS "Data1",
MAX(CASE WHEN entries.ordinal_position = 9 THEN entries.element END) AS "Data2"
FROM TABLE (qsys2.ifs_read_utf8(path_name => '/QTCPTMM/CONFIG/USERS.DAT',
maximum_line_length => 1024)) AS lines,
TABLE (systools.split(input_list => CAST(lines.line AS VARCHAR(1024)),
delimiter => ' ')) AS entries,
TABLE (systools.split(input_list => CAST(entries.element AS VARCHAR(1024)),
delimiter => ':')) AS details
WHERE line_number > 1
GROUP BY lines.line_number);
Voici un exemple de résultat obtenu :
User profile
SMTP mailbox alias
Domain index
Domain Name
SDD name compatibility
SDD address compatibility
Forwarding to
Originating from
Data1
Data2
FORM01
*NONE
00
*NONE
FORM01
NEPTUNE
*NONE
*NONE
Y
9132
FORM02
*NONE
00
*NONE
FORM02
NEPTUNE
*NONE
*NONE
Y
9134
Pour simplifier encore plus votre usage, je vous propose une vue, ainsi qu’une fonction table :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2025-04-07 21:27:092025-04-08 09:47:08Contrôler la liste des utilisateurs inscrits à SMTP via sql
Vous devez surveiller l’IFS de votre partition et plus particulièrement la partie /home/ ou vous retrouvez les fichiers générés par vos utilisateurs et y faire le ménage régulièrement est une bonne pratique.
Une épuration à 30 jours semble un bon compromis
Voici 2 techniques pour réaliser cette opération
La première est à base d’un script UNIX
Voici un exemple, dans le répertoire /home/maurice/OUT on supprime les fichiers CSV de plus de 10 jours
Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Présentation
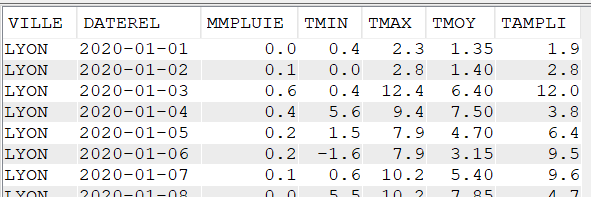
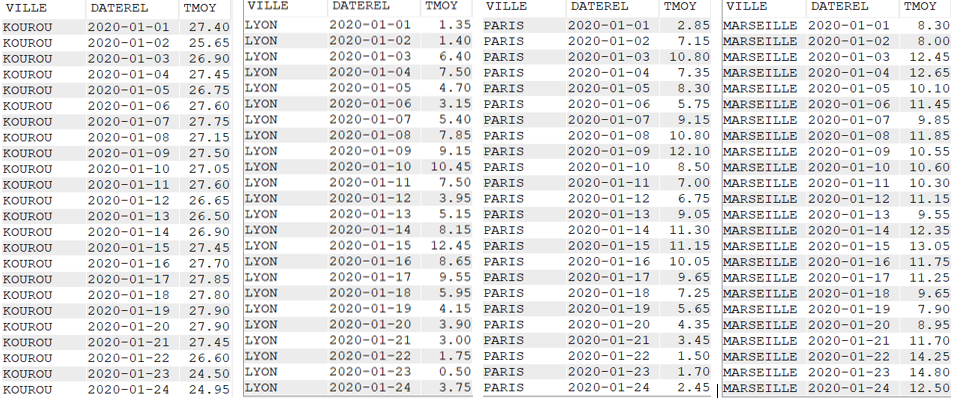
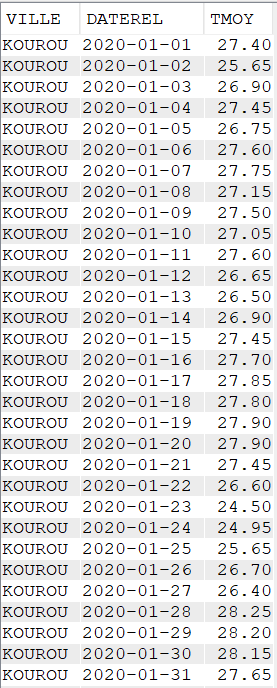
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
La ville
Le jour (AAAA-MM-JJ)
Les précipitations en mm
La température minimale du jour (en °C)
La température maximale du jour (en °C)
La température moyenne du jour (en °C)
L’amplitude de température du jour (en °C)
Agréger les données avec LISTAGG
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)
Données brutes
Données avec la fonction LISTAGG
Agréger les données avec GROUP BY
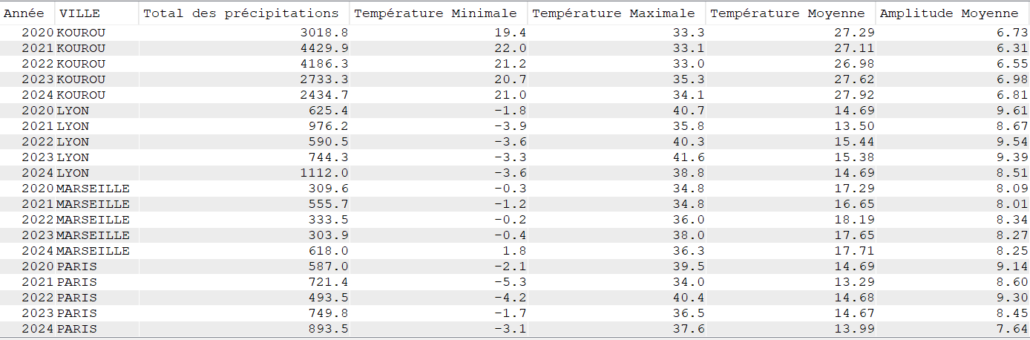
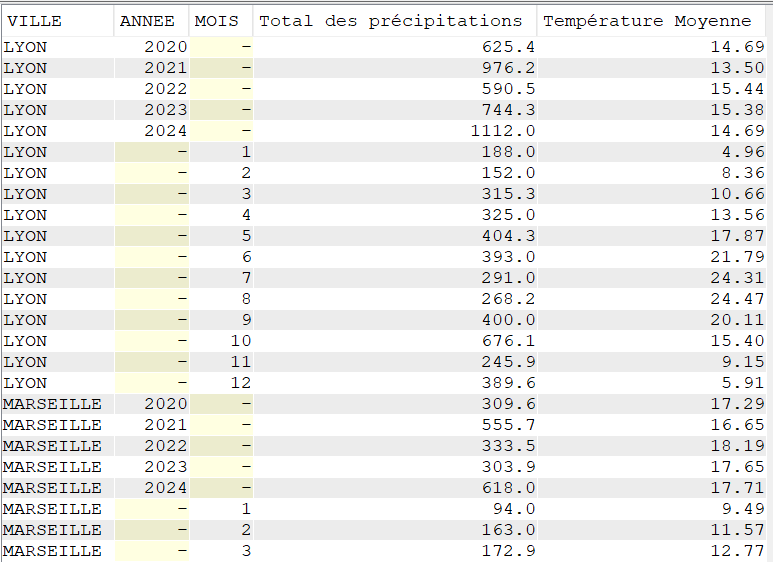
Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
SUM qui va nous permettre de faire le total des précipitations
MIN pour extraire la température minimale
MAX pour extraire la température maximale
AVG pour faire une moyenne (de la température ainsi que de l’amplitude des températures)
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
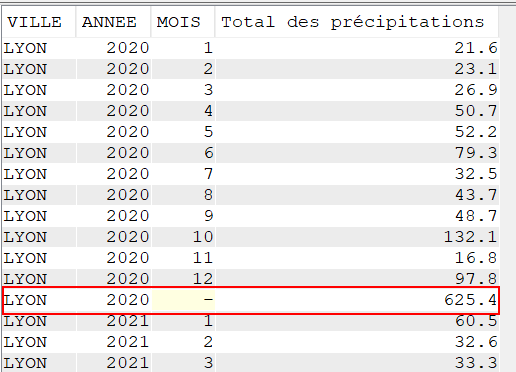
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";
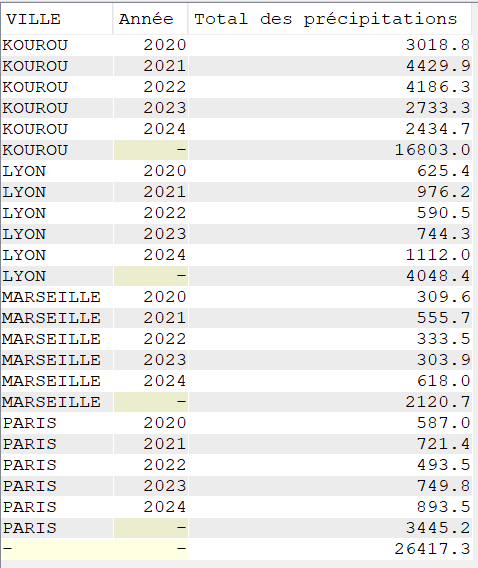
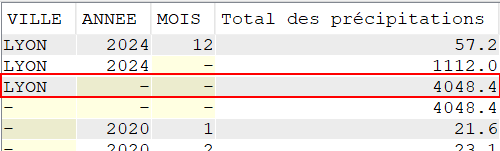
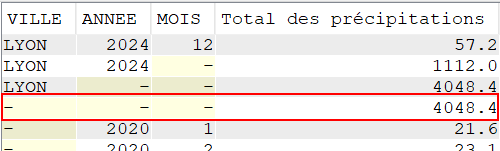
Utilisation de ROLLUP
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";
L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
VILLE / ANNEE
VILLE
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
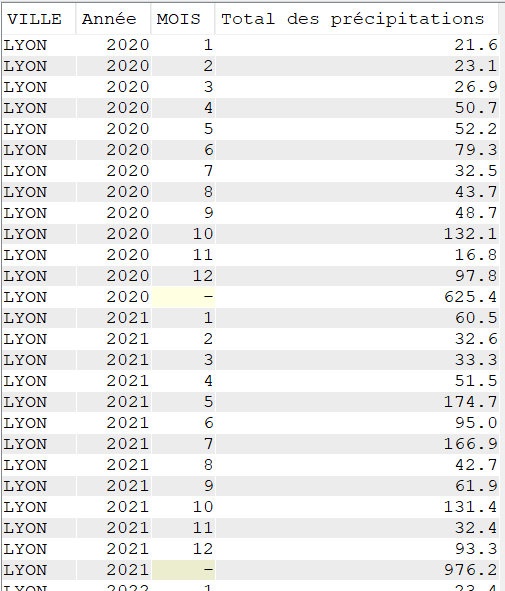
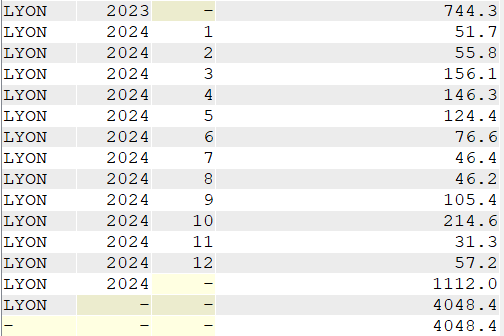
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));
…
…
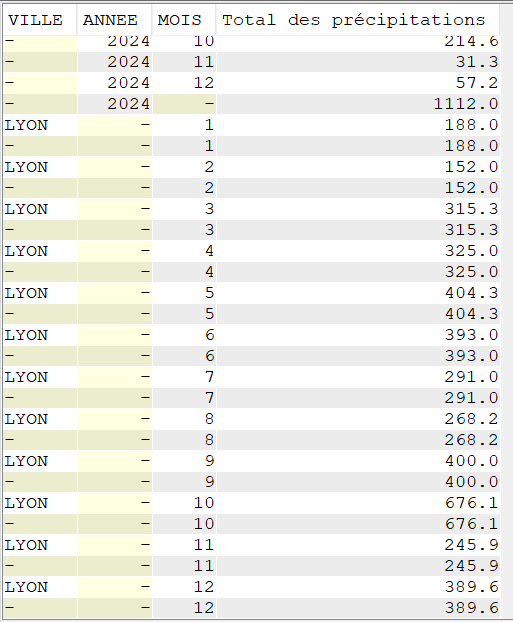
Utilisation de CUBE
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
SELECT VILLE, YEAR(DATEREL) Annee, MONTH(DATEREL) Mois, SUM(MMPLUIE) "Total des précipitations" FROM CLIMAT WHERE VILLE = 'LYON' GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
Par VILLE et ANNEE
Par VILLE et sur la période de mesure
Sur la période de mesure (valeur identique à la précédente car une seule ville sélectionnée ici)
Par VILLE pour chaque mois de la période sélectionnée (ou simplement pour chaque mois de la période sélectionnée)
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Utilisation de GROUPING SETS
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);
Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
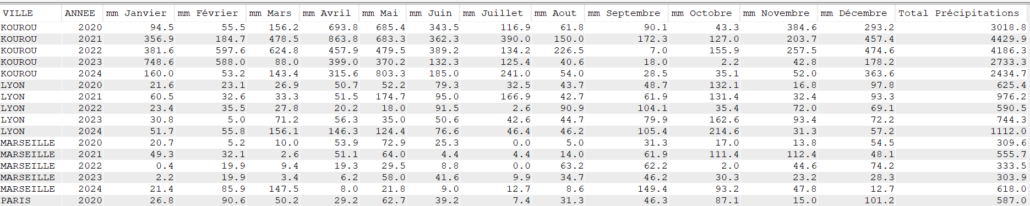
Tableau Croisé avec Agrégation et CASE
Avec SUM
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
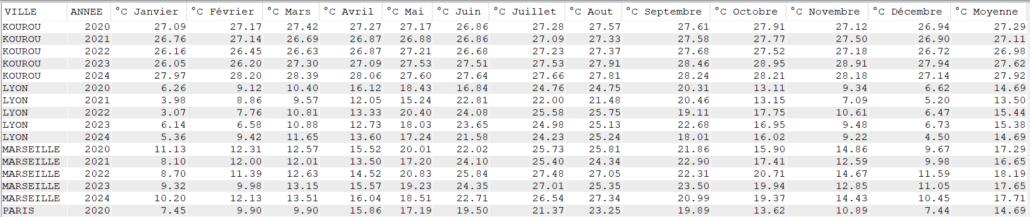
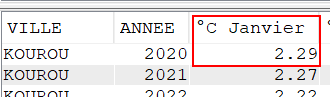
Avec AVG
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Note sur l’utilisation de SUM vs AVG dans un tableau croisé
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
Avec ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.
NULL est ignoré par AVG, garantissant une moyenne correcte.
Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)
Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)
Utiliser SQL pour faire une analyse
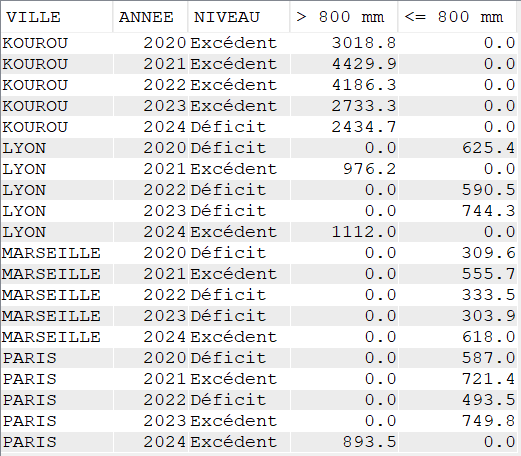
Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL);
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2025-03-04 09:03:202025-03-04 09:28:33Regroupements et Analyses avec SQL
Si vous avez mis en œuvre le journal vous pouvez et même devez analyser les refus de connexion. Le plus souvent c’est un mauvais mot de passe mais ca peut être aussi une attaque, ou un comportement douteux
Voici une requête simple qui permet cette analyse rapide
SELECT JOB_NAME, USER_NAME, FUNCTION, MESSAGE_ID, MESSAGE_TIMESTAMP FROM TABLE(QSYS2.DISPLAY_JOURNAL(‘QSYS’, ‘QAUDJRN’)) WHERE MESSAGE_ID IN (‘CPF2234’, ‘CPF1107’, ‘CPF1393’) ORDER BY MESSAGE_TIMESTAMP DESC;
Les messages traités ici CPF2234 Tentative de connexion échouée. CPF1107 Mot de passe incorrect. CPF1393 Accès refusé.
Remarque : Vous pouvez ajouter des filtres (plage horaire, autres messages de refus , etc …) Vous devrez découper vous même la zone entry data, vous pouvez également utiliser les fonctions table QSYS2.DISPLAY_JOURNALxx spécialisées par TYPE
Les indicateurs font parti intégrante des développements RPG, c’est des booléens dont le nom commence par *IN, certain ont plus ou moins disparu (remplacé par des %EOF, %FOUND, ou un SQLCODE ) , mais les indicateurs *IN01 à *IN99 continuent à être utilisé par exemple dans les DSPF.
On va essayer de voir une méthode qui rendra le code plus lisible pour les jeunes recrues qui devront faire de la maintenance
On va prendre un exemple à partir d’un DSPF
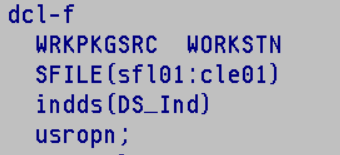
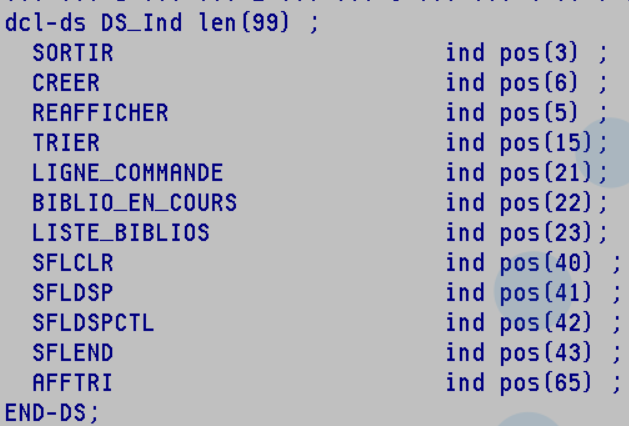
Votre écran devra avoir le mot clé INDARA qui indique qu’on va gérer les indicateurs dans un buffer séparé
Pour la déclaration de votre écran vous devrez lui indiquer le mot clé INDDS qui indiquera la DS qui contiendra le tableau de ces indicateurs.
voici un exemple de DS avec les indicateurs nommé
Exemple :
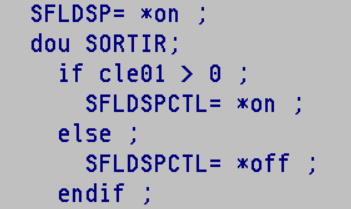
*IN03 / SORTIR
Voici ci dessus un exemple de code RPG FREE, utilisant les noms indiqués dans la DS, on voit tout de suite mieux ce qu’on fait
Remarque :
Vous pouvez mettre votre DS dans un include et le déclarer dans chaque programme , ce qui permettra d’uniformiser votre tableau des indicateurs
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-02-24 11:03:502025-02-25 09:31:53Nommez vos indicateurs en RPGLE