L’utilisation des noms longs dans le code RPG est un atout supplémentaire pour le rendre plus lisible et en faciliter la maintenance.
On continue malheureusement trop souvent à utiliser les noms courts hérités de nos bases de données et du code RPG colonné, même converti en Free.
Pourtant, l’utilisation des alias dans les DDS et les déclaratives RPG ainsi que la redéfinition des indicateurs, permettent de s’affranchir totalement des noms courts au profit des noms longs.
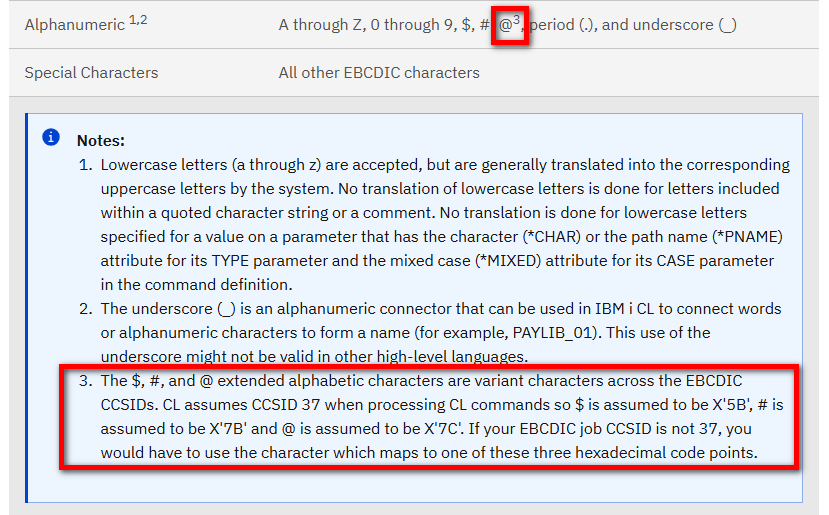
Utilisez le mot clé ALIAS dans les DDS
Le mot-clé ALIAS permet d’associer un nom long à un champ très souvent nommé avec seulement 6 caractères, et maximum 10 caractères
ALIAS dans un PF
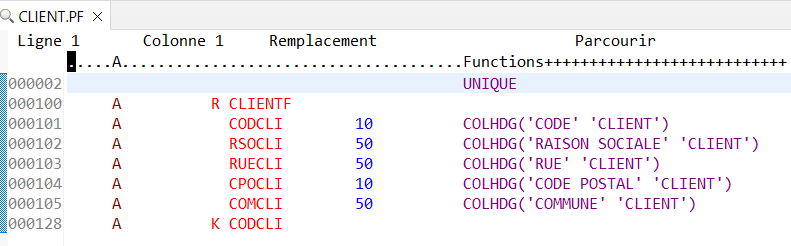
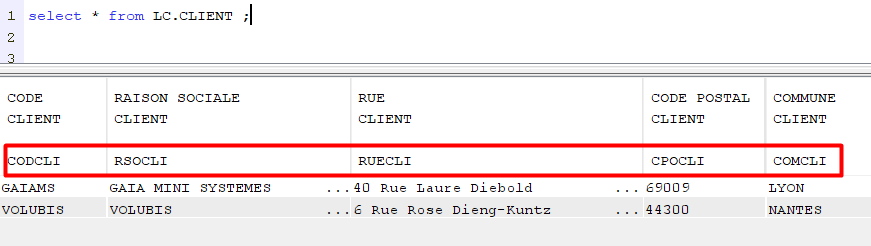
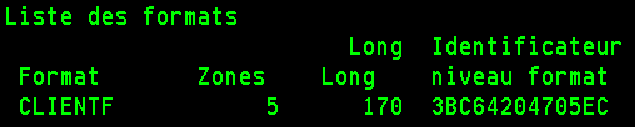
Exemple avec un fichier sans ALIAS :
.
.

.
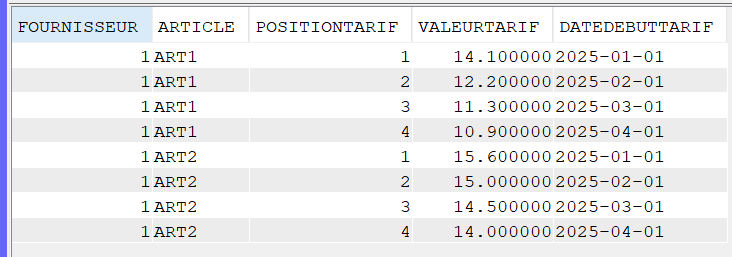
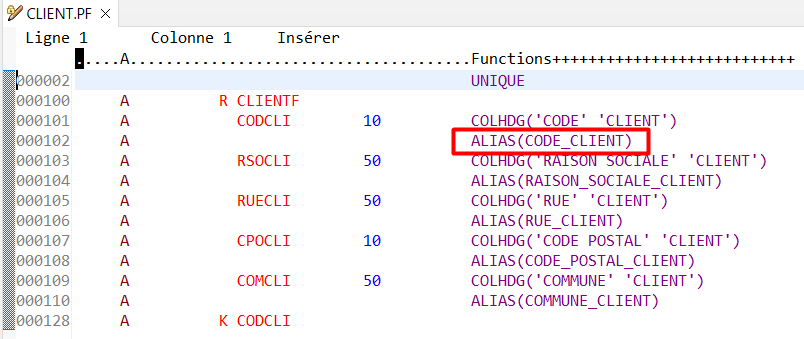
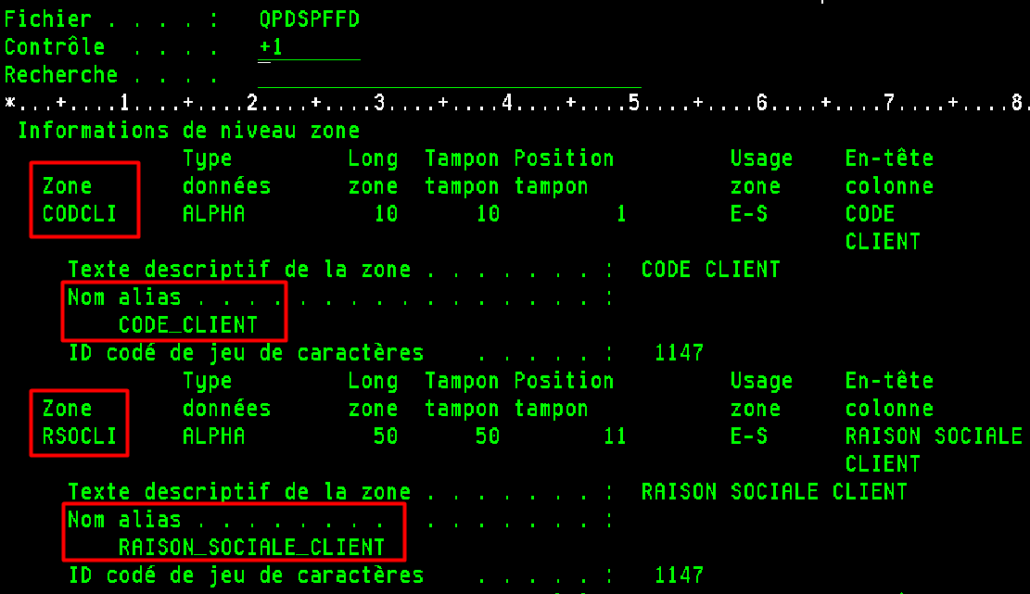
Le mot clé ALIAS peut être rajouté dans les DDS de vos fichiers sans aucun impact sur vos applications :
.
.
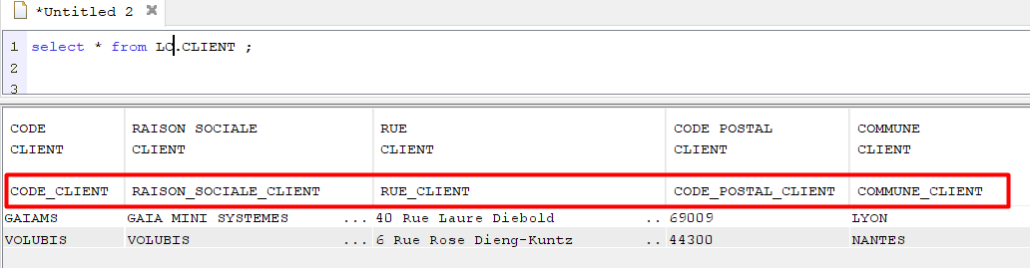
Les ALIAS peuvent être appliqués sans perte de données par un CHGPF :
CHGPF FILE(LC/CLIENT) SRCFILE(LC/QDDSSRC) SRCMBR(CLIENT)
Cette opération ne modifie pas le niveau de format du fichier, pas de recompilation des applications
.
.
.
.
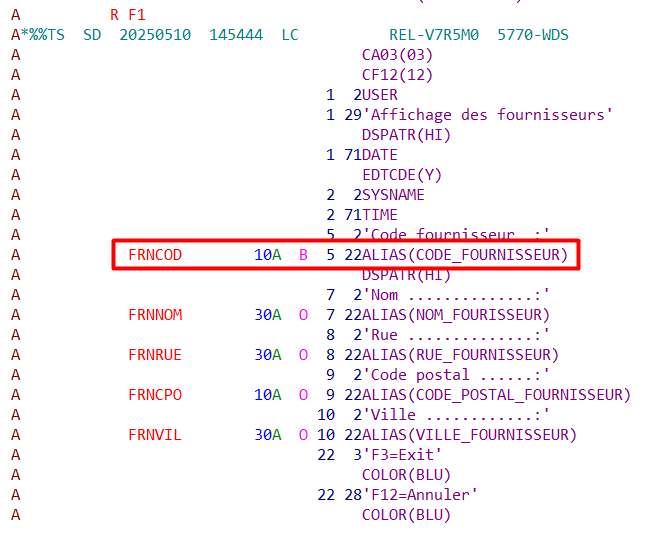
ALIAS dans un DSPF
Dans vos écrans 5250, vous pouvez aussi associer des noms longs aux noms courts sous forme d’ALIAS.
Les ALIAS longs peuvent être utilisés dans le code RPG à la place des noms courts.
.
Utilisez le mot clé ALIAS dans la déclaration d’ouverture du fichier
Il vous permet d’utiliser les ALIAS du fichier en tant que noms de variables, dans le code RPG
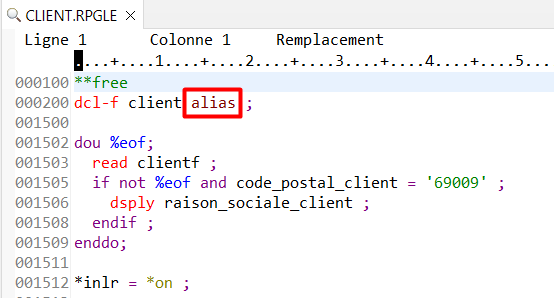
.

.
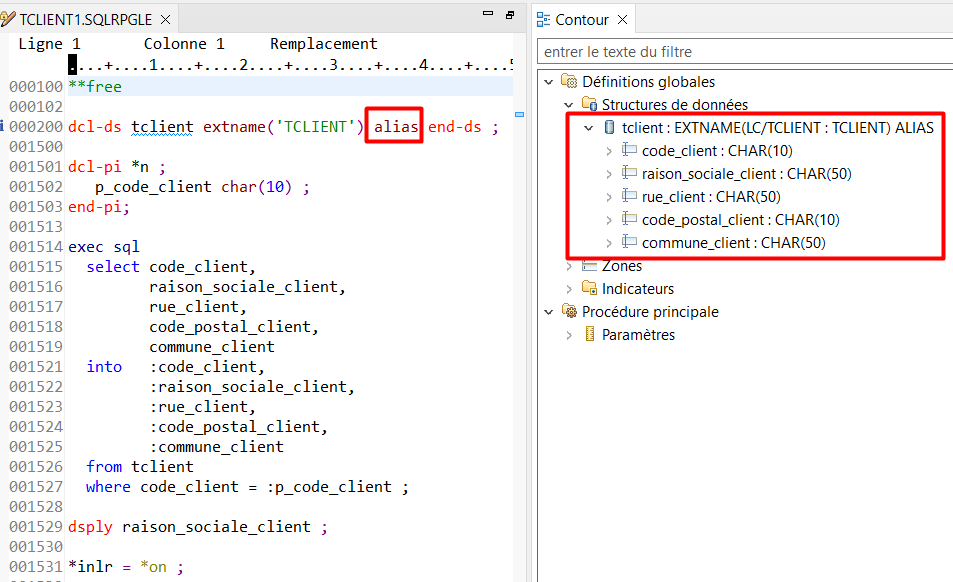
Utilisez le mot clé ALIAS dans la déclaration d’une DS externe
Il vous permet d’utiliser les ALIAS du fichier externe de la DS en tant que noms de variables, dans le code RPG
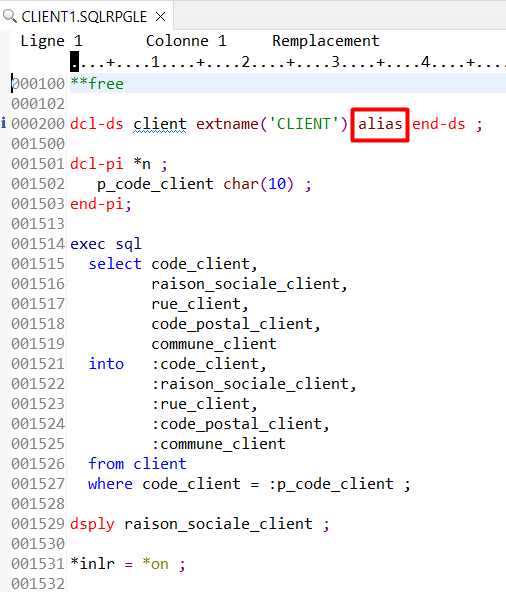
.

.
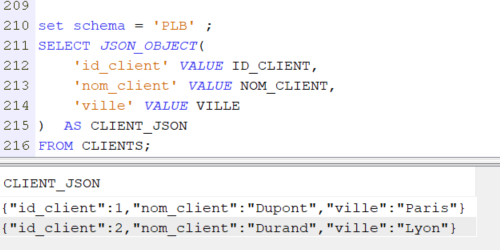
Noms longs et noms courts dans une table SQL
Lorsque vous créez une table SQL, vous lui attribuez un nom long SQL mais vous pouvez aussi lui attribuer un nom court de votre choix par la clause SYSTEM NAME afin d’éviter que le système ne lui attribue un nom court par défaut.
Pour la même raison, il est conseillé d’attribuer à chaque colonne un nom court en plus du nom long, par la clause FOR COLUMN
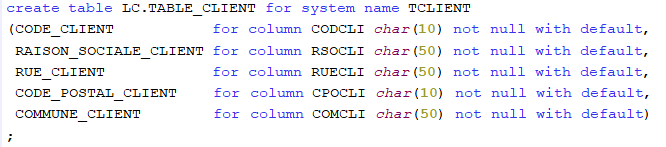
.
Dans le code RPG, vous pouvez déclarez la DS de votre table pour qu’elle utilise les noms courts (sans mot clé ALIAS) ou les noms longs (avec le mot clé ALIAS) :
Déclaration d’une DS externe pour une table SQL avec utilisation des noms courts
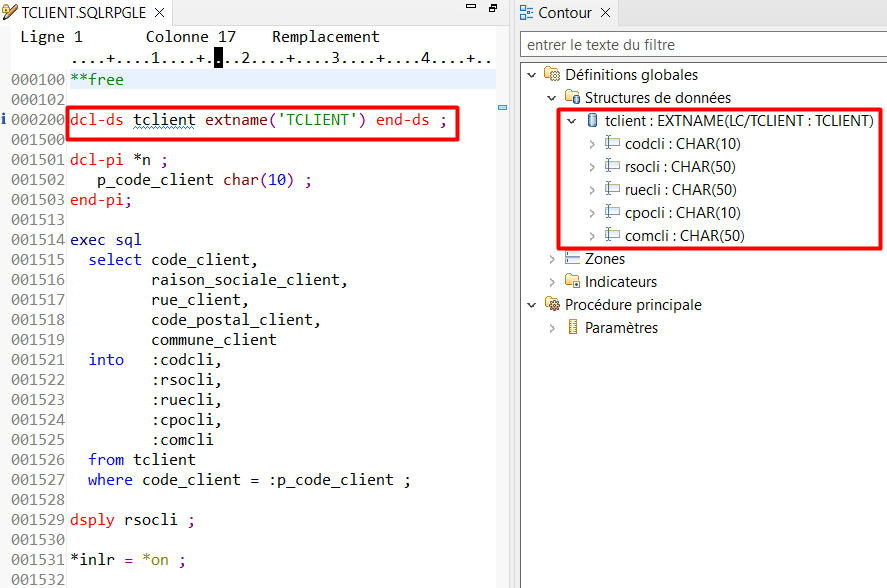
.
Déclaration d’une DS externe pour une table SQL avec utilisation des noms longs
.
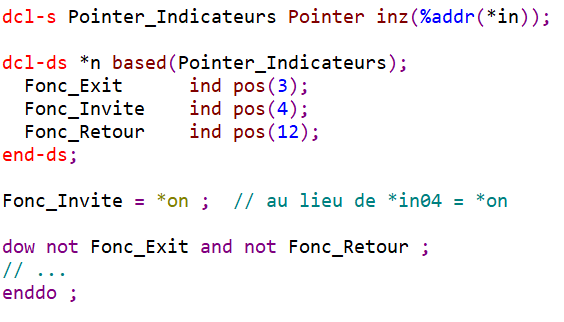
Renommez les indicateurs *INxx
Vous pouvez vous affranchir des indicateurs *INxx dans le code RPG en les renommant :
.