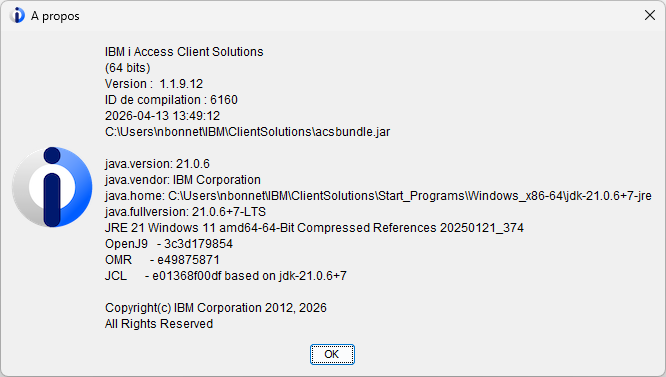
Vous devez ou vous devrez vous conformer à la norme ISO27001 :
Voici quelques points à contrôler qu’un auditeur pourrait vous demander
1) séparation DEV / TEST / PROD
Ils vérifieront que vous avez à minima 3 environnements, 2 machines sont une bonne pratique
2) Git ou gestionnaire de versions
Ils vérifieront que vous avez un versioning de votre code source, aujourd’hui git est incontournable pour réaliser cette opération
3) Revue de code documentée
Ils vérifieront que vous faites des revues de code et que vous avez des actions suite à celle-ci, exemple modernisation du code obsolète entrant en maintenance.
4) Les droits des développeurs
Ils vérifieront par exemple qu’aucun développeur reste avec *ALLOBJ permanent, et qu’il a des droits limités et tracés à les actions en production
5) Données sensibles chiffrées en transit (TLS/HTTPS)
Ils vérifieront qu’aucune données ne circule en claire , mise en œuvre de TLS
6) Contrôle des accès aux objets
Ils vérifieront les droits d’accès aux objets , la bonne pratique est *use sur les programmes *change sur les datas
7) Journalisation et suivi des changements
Ils vérifieront que les modifications effectuées correspondent à une demande documentée et éventuellement un ticket d’incident ou de correctif
8) Procédure de mise en production documentée
Ils vérifieront que vous avez un process de mise en production avec de interlocuteurs différents pour les rôles jusqu’à la mise en production
9) Normes de développement sécurisées
Ils vérifieront que vous avez des normes de développement (nommage , SQL préparé, validation des entrées ou paramètres, gestion des erreurs)
Conclusion :
Tous ces points ne vous garantissent pas de passer un audit confortable, mais ils vous permettront d’avoir des éléments pour engager un dialogue
Quand Service Commander, un serveur MCP et une locale pakistanaise décident de compliquer votre journée
Ces derniers jours, j’ai installé un serveur MCP IBM i en m’appuyant sur Service Commander. Une opération qui, sur le papier, semblait relativement simple : installer le serveur MCP, créer le service par service commander pour faciliter l’exploitation.
Pourtant, je me suis retrouvé face à un comportement particulièrement déroutant. Et c’est là que l’utilisation de l’IA (BOB en l’occurrence) s’est révélée extrêmement intéressante.
Le symptôme : ça marche… sauf quand ça ne marche pas
Le serveur MCP démarrait parfaitement lorsque je lançais cette commande avec le profil MCPSERVER créé pour l’occasion :
sc start ibmi-mcp-server
Mais avec mon profil habituel, j’obtenais systématiquement un message d’erreur, ou alors un message de complétion mais le serveur MCP était inactif.
Le détail intriguant était que le service était pourtant configuré pour soumettre le job sous le profil MCPSERVER :
sbmjob_opts: 'JOBQ(QUSRNOMAX) USER(MCPSERVER)'
En théorie, le profil appelant n’aurait donc pas dû avoir d’importance.
La tentation du mauvais diagnostic
Le premier réflexe est de suspecter :
un problème de droits ;
un problème de PATH ;
une configuration npm ;
Node.js ;
la configuration MCP ;
ou encore Service Commander lui-même.
J’ai commencé à analyser les jobs, les spools, les variables d’environnement et les traces de démarrage.
Rapidement, une chose est apparue : le job était bien soumis sous MCPSERVER, mais l’environnement du processus n’était pas toujours cohérent.
Une découverte intéressante
Les premiers logs montraient que lorsque le démarrage était demandé par NB, certaines informations restaient liées à ce profil :
HOME=/home/NB
USER=nb
LOGNAME=nb
alors que le job tournait sous MCPSERVER.
J’ai donc modifié la configuration pour désactiver l’héritage implicite de l’environnement :
environment_is_inheriting_vars: false
et défini explicitement les variables nécessaires.
Le comportement a changé, mais le problème n’était toujours pas totalement résolu.
Le vrai coupable : la commande de démarrage
Pendant plusieurs itérations, j’ai tenté de simplifier la définition du service :
Pourquoi un serveur IBM i situé en France essayait-il d’utiliser une locale pakistanaise ?
Après investigation, j’ai découvert que Service Commander contient la logique suivante :lorsque aucune locale UTF-8 n’est définie dans l’environnement, Service Commander choisit simplement… la dernière locale (par ordre alphabétique) UTF-8 trouvée sur le système.
Sur ma machine, c’était : ur_PK.UTF-8, c’est-à-dire :
ur = ourdou
PK = Pakistan
D’où le message surprenant.
La solution a finalement consisté à définir explicitement :
export LC_ALL=FR_FR.UTF-8@euro
dans ~/.profile et ~/.bashrc
Depuis, plus aucun avertissement.
Et BOB dans tout ça alors ?
Ce que l’IA m’a réellement apporté ?
La partie la plus intéressante de cette aventure n’est pas le problème technique lui-même, j’aurais fini par trouver la solution. Les indices étaient là :
les spools ;
les joblogs ;
les variables d’environnement ;
le comportement différent selon le profil utilisé.
Mais cela m’aurait probablement pris plusieurs heures supplémentaires, que j’aurais réparti sur plusieurs jours.
L’IA n’a pas « résolu le problème à ma place ». Elle n’a pas eu accès à ma machine (je vous rappelle que j’installais le serveur MCP à ce moment là), à mes commandes ou à la documentation interne de mon environnement.
En revanche, elle a joué un rôle extrêmement utile :
proposer des pistes d’investigation ;
analyser rapidement les spools ;
repérer les incohérences ;
suggérer des vérifications ciblées ;
éliminer de nombreuses hypothèses ;
structurer le raisonnement.
En pratique, elle s’est comportée comme un collègue expérimenté assis à côté de moi, capable de relire instantanément chaque log et de suggérer la prochaine étape.
J’hallucine ?
Pas beaucoup sur cette affaire là ! Pas de commande (shell ou IBM i) extravagante, de boucle dans les réponse, d’idée totalement saugrenue.
Attention, plusieurs critères à prendre en compte :
je connais le sujet
j’ai fait des prompts verbeux et précis
j’ai détecté les mauvaises pistes ET donner les informations pour que BOB comprenne pourquoi c’est une mauvaise piste
Ce que je retiens
L’apport principal de BOB dans ce type de situation n’est pas le remplacement de l’expertise.
C’est l’accélération du diagnostic.
Mon expertise IBM i m’a permis d’interpréter les résultats, de comprendre les implications et de valider les solutions. L’IA, elle, m’a aidé à parcourir beaucoup plus rapidement l’arbre des hypothèses possibles.
Résultat :
un serveur MCP fonctionnel ;
une configuration Service Commander plus robuste ;
une anomalie de locale identifiée et corrigée ;
et quelques heures gagnées sur une enquête qui aurait probablement été bien plus longue en solitaire.
Et, accessoirement, j’ouvrirais une issue sur la gestion des locales par service commander !
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-03 10:54:102026-07-03 11:00:16Les droits d’un fichier IFS à sa création
Vous voulez savoir le droit qu’un utilisateur aura quand il tentera d’accéder à un fichier IFS
Voici un script avec les requêtes qui vous aidera à déterminer le droit que vous obtiendrez.
Vous aurez 8 étapes possibles , et il s’arrêtera à la première correspondance.
--
-- Voici une liste de commande SQL pour trouver le droit d'un utilisateur
-- Sur un fichier IFS
-- ici l'utilisateur PLB
-- tente d'accéder au fichier
--/home/plb/Controle_demarrage_SBS.csv
-- 1 si user *ALLOBJ
-- Si oui tous les droits
--
SELECT SPECIAL_AUTHORITIES,
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 2 si user sur l'objet
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = 'PLB';
--
-- 3 si utilisateur dans liste d'autorisations
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = 'PLB'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
-- 4 si groupe all obj
-- Si oui tous les droits
--
SELECT
SPECIAL_AUTHORITIES
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = ( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
-- 5 si groupe sur l'objet
--
SELECT * FROM TABLE(QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv'))
where AUTHORIZATION_NAME =
( SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB');
--
--6 Si groupe dans la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = (SELECT GROUP_PROFILE_NAME
FROM qsys2.user_info
WHERE AUTHORIZATION_NAME = 'PLB')
AND AUTHORIZATION_LIST = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
--
--7 Si public
--
SELECT *
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND DATA_AUTHORITY <> '*AUTL';
--
--8 Si public reporté sur la liste d'autorisation
--
SELECT *
FROM QSYS2.AUTHORIZATION_LIST_USER_INFO
WHERE AUTHORIZATION_NAME = '*PUBLIC'
AND AUTHORIZATION_LISt = (SELECT AUTHORIZATION_LIST
FROM TABLE (
QSYS2.IFS_OBJECT_PRIVILEGES('/home/plb/Controle_demarrage_SBS.csv')
)
WHERE AUTHORIZATION_NAME <> '*PUBLIC');
Remarque :
Ce mécanisme peut être complété par des groupe additionnels , les droits proposés devenant complétifs (‘Ajouter au droit existant’)
Il est conseillé de les utiliser modérément , on peut avoir un système de droit assez efficace juste avec le mécanisme historique
Dans l’IFS l’adoption de droit ne s’applique pas, mais dans vos sript sh vous pouvez utiliser la notion de SETUID
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-07-03 10:13:032026-07-03 10:13:04Droit d’utilisateur sur un fichier IFS
Nous lançons une initiative dédiée à l’Open Source sur IBM i avec une ambition simple et modeste :
Ouvrir, partager et moderniser l’écosystème.
Trop souvent perçu comme un monde fermé, IBM i possède pourtant une richesse technique exceptionnelle. Avec l’Open Source, nous voulons favoriser l’innovation, encourager les échanges entre équipes, accélérer la modernisation des applications et rendre les outils accessibles à tous.
Cette initiative proposera des outils concrets (RPG, SQL, CLLE, APIs), des frameworks prêts à l’emploi, des exemples industrialisables et des bonnes pratiques terrain.
Que vous soyez développeur, architecte ou administrateur IBM i, vous êtes les bienvenus pour contribuer, tester et améliorer ces projets.
Ensemble, faisons évoluer IBM i vers un modèle plus ouvert, collaboratif et moderne.
Pour commencer nous décidons de mettre open source quelques produits ici sur notre Github :
Non classéDe Lyon à l’IBM i : quand les cartes perforées tissent encore notre code
La semaine dernière, à Lyon, lors du congrès Common Europe 2026, nous avons parlé modernisation, APIs, IA… et futur de l’IBM i.
Mais au détour des conversations, difficile d’oublier une évidence : une partie de notre ADN technologique est née ici même, à Lyon.
Et si les développeurs RPG d’aujourd’hui partageaient, sans toujours le savoir, un héritage direct avec les canuts et les métiers Jacquard ?
Lyon, berceau d’une révolution : le métier Jacquard
Au début du XIXe siècle, Lyon est la capitale mondiale de la soie. Les métiers à tisser sont complexes, coûteux et surtout… difficiles à piloter.
En 1801, Joseph Marie Jacquard introduit une innovation majeure : un métier à tisser contrôlé par des cartes perforées.
Chaque carte représente une ligne du motif à tisser. Les trous dictent mécaniquement quelles aiguilles doivent être activées.
C’est simple, robuste, et surtout :
programmable
reproductible
automatisable
Autrement dit : le premier système programmable industriel de l’histoire.
Napoléon, sponsor inattendu du “code”
Le métier Jacquard n’a pas été immédiatement accepté. Les canuts voyaient cette innovation comme une menace pour leur savoir-faire… et certains métiers ont même été détruits. C’est finalement Napoléon Bonaparte qui a soutenu Jacquard et officialisé l’usage de sa machine.
On pourrait presque dire que l’histoire de la “programmation” a démarré avec :
une innovation disruptive
une résistance des utilisateurs
et un sponsor politique pour imposer le changement
Un schéma… encore très actuel ?
La carte perforée : premier support de programmation
Le principe est fondamental :
L’information n’est plus dans la machine, elle est dans un support externe.
Chaque trou correspond à une instruction binaire :
trou → action
pas de trou → pas d’action
Ce modèle va traverser les décennies et inspirer directement les premiers systèmes informatiques.
Ada Lovelace avait déjà compris
Au XIXe siècle, Charles Babbage conçoit sa “machine analytique”, ancêtre de l’ordinateur.
Son idée ? Utiliser… des cartes perforées inspirées directement du métier Jacquard.
Et Ada Lovelace, souvent considérée comme la première développeuse de l’histoire, va encore plus loin. Elle comprend que la machine pourrait manipuler autre chose que des chiffres.
Elle écrit, en substance :
“La machine pourrait composer de la musique si on lui donnait les règles.”
Autrement dit : la programmation n’était déjà plus une question de calcul, mais de logique et de création.
Du textile au numérique : l’héritage IBM
IBM industrialise massivement l’usage des cartes perforées au XXe siècle.
Le RPG : un langage façonné par les cartes
Le langage RPG, introduit dans les années 1960, est directement conçu pour… les cartes perforées.
Chaque ligne de code correspond à une carte. Chaque colonne a une signification précise.
Exemple :
colonnes 1–5 : libre
colonne 6 : type de ligne
reste : spécifications
Ce format n’est pas une contrainte arbitraire, c’est un héritage physique.
Une histoire de continuité
Nous n’avons pas changé de paradigme Nous avons changé de support
Du métier Jacquard à l’IBM i :
on programme
on structure
on exécute
Conclusion : coder, c’est tisser
À Lyon, pendant le Congrès de Common Europe, difficile de ne pas voir le parallèle :
Les développeurs IBM i sont les héritiers des canuts !
Et au fond, nous faisons le même métier : Transformer des instructions en valeur.
/wp-content/uploads/2017/05/logogaia.png00Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2026-06-23 09:45:002026-06-22 11:37:56De Lyon à l’IBM i : quand les cartes perforées tissent encore notre code
Aujourd’hui vous verrez comment créer un programme capable de convertir un fichier html en PDF depuis votre IBM i à l’aide d’un appel d’API externe.
Rappel sur l’IBMi vous pouvez générer du PDF en utilisant :
Transform Services produit sous licence IBM mais très sommaire
Une solution open source que vous installez sur votre partition
Exemple:
wkhtmltopdf (outil de conversion) qui n’est en fait plus du tout maintenu.
On va donc présenter une autre solution qui se base sur les API
Nous avons choisi l’API qui s’appelle PDFSPARK. Cette solution vous permet de tester notre outil, vous avez jusqu’à 20 requêtes/minute sans clé alors que la plupart des autres API demandent une inscription et proposent environ que 15 requêtes/jour avec un forfait gratuit.
Normalement l’API reçoit une page en ligne en html puis la convertie, mais ici on voulait un .html depuis l’IFS donc j’ai demandé à l’IA (claude) de me faire juste un mini programme pour l’utiliser avec un fichier local et il m’a donné ça :
#!/QOpenSys/usr/bin/bash
export PATH=/QOpenSys/pkgs/bin:/QOpenSys/usr/bin:/usr/bin:$PATH
HTML_FILE=$(echo -n "$1" | tr -d ' ')
PDF_FILE="${HTML_FILE%.html}.pdf"
if [ ! -f "$HTML_FILE" ]; then
echo "ERROR: HTML file not found"
exit 1
fi
HTML_CONTENT=$(cat "$HTML_FILE" | jq -Rs .)
curl -s -X POST "https://pdfspark.dev/api/v1/pdf/from-html" \
-H "Content-Type: application/json" \
-d "{\"html\": $HTML_CONTENT, \"options\": {\"format\": \"A4\"}}" \
-o "$PDF_FILE"
echo "DONE : $PDF_FILE"
echo "Your file is located in : $HTML_FILE"
Le programme fait, dans l’ordre :
Récupère le chemin du fichier à convertir en paramètre
Crée un PDF du même nom (que le nom du fichier)
Vérifie si le fichier existe vraiment
Lis le .html passé en paramètre et le converti en JSON pour ensuite l’injecter dans l’API (jq -Rs)
Et ensuite la requête curl donnée par le site de l’API
Puis il y a le programme CL qui appelle le .sh depuis 5250 :
PGM PARM(&FILE)
/* début de la construction de la commande bash */
DCL VAR(&NULL) TYPE(*CHAR) LEN(1) VALUE(X'00')
DCL VAR(&BASH) TYPE(*CHAR) LEN(100) +
VALUE('/QOpenSys/usr/bin/bash')
DCL VAR(&CONVERT) TYPE(*CHAR) LEN(100) +
VALUE('/chemin/vers/votre/fichier/html2pdf.sh')
/* fin de la construction de la commande bash */
/* Création de la variable FILE pour rentrer en paramètre
le chemin vers le fichier à convertir depuis 5250 */
DCL VAR(&FILE) TYPE(*CHAR) LEN(256)
DCL VAR(&FILETRIM) TYPE(*CHAR) LEN(100)
/* concaténation des variables
pour former la commande bash final */
CHGVAR VAR(&FILETRIM) VALUE(&FILE)
CHGVAR VAR(&BASH) VALUE(&BASH *TCAT &NULL)
CHGVAR VAR(&CONVERT) VALUE(&CONVERT *TCAT &NULL)
CHGVAR VAR(&FILETRIM) VALUE(&FILETRIM *TCAT &NULL)
/*Appel de QP2SHELL pour l'exécution de la commande*/
CALL PGM(QP2SHELL) PARM(&BASH &CONVERT &FILETRIM)
ENDIT:
ENDPGM
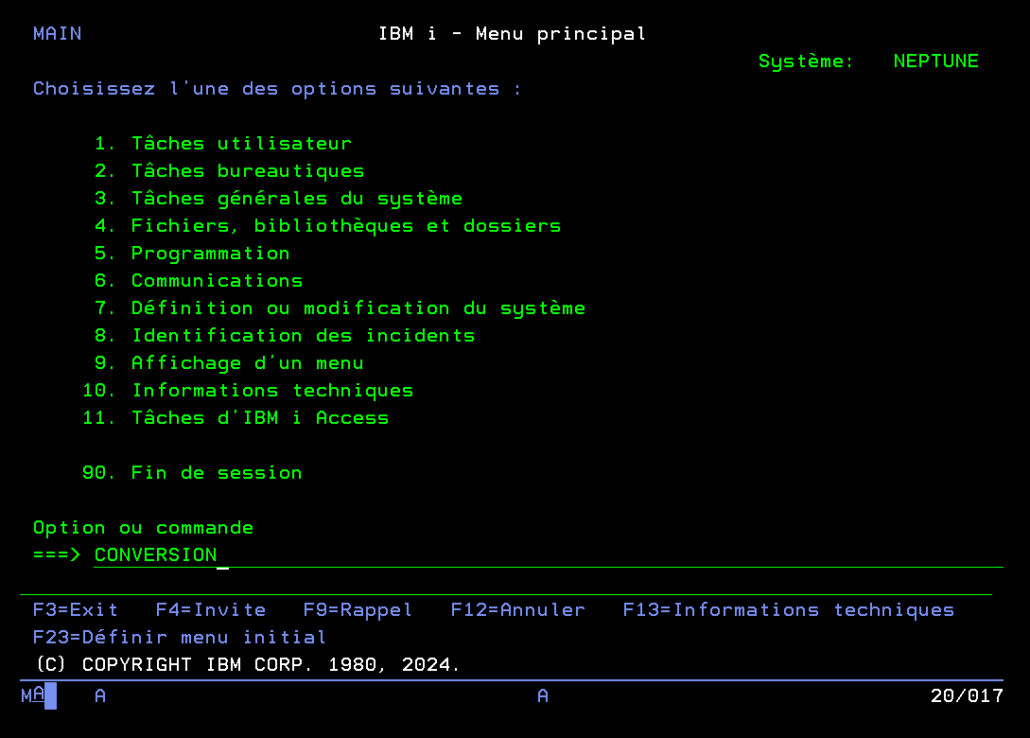
Après compilation et ajout de la librairie, il suffit d’appeler ce programme via l’interface 5250 avec en paramètre le chemin vers le fichier .html que vous voulez convertir en PDF :
Pour l’instant, le nouveau fichier .PDF sera enregistré au même endroit que le .html
Et pour vous faciliter encore plus la tâche,
vous pouvez créer une commande à appeler depuis 5250 en créant un fichier CONVERSION.CMD comme ceci :
CMD PROMPT('Conversion html vers pdf')
PARM KWD(FICHIER) TYPE(*CHAR) LEN(256) MIN(1) +
PROMPT('Fichier à convertir')
puis la compiler.
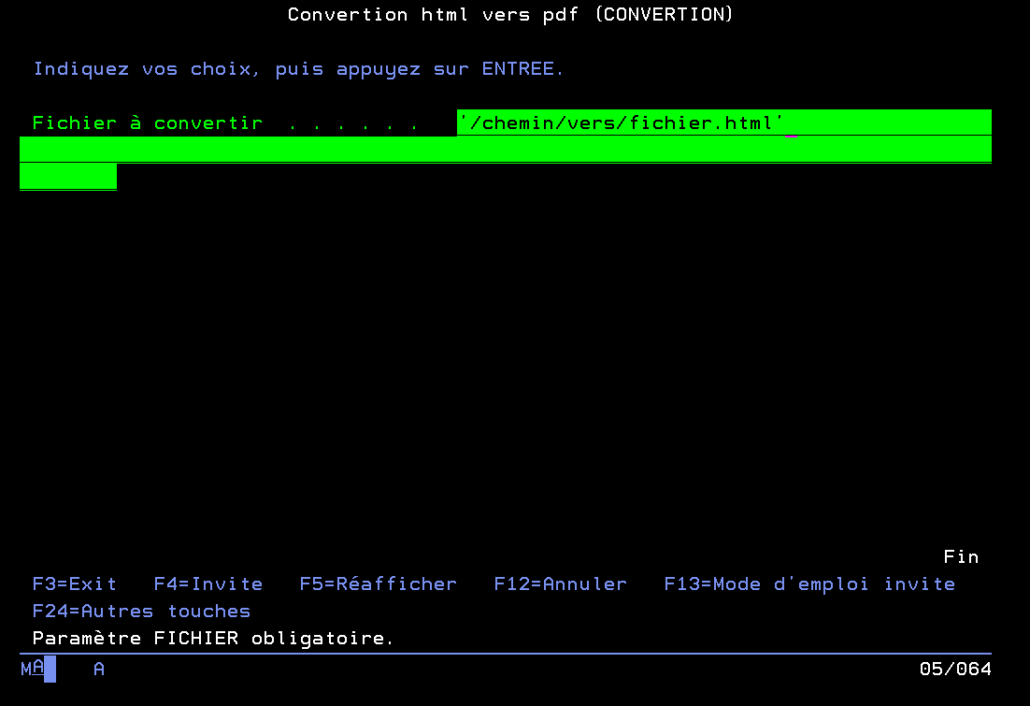
Au final
Vous pourrez appeler votre programme de conversion depuis 5250 juste avec la commande : conversion puis en appuyant sur F4, tomber sur cet écran qui vous permettra de renseigner (entre simple quote ‘ ) le chemin vers le fichier à convertir (également utilisable en batch):
Remarques :
Votre IBMi devra sortir vers l’URL https://pdfspark.dev sur le port 443 , ou vers le provider que vous aurez choisi
Vous pourrez faire des PDF plus évolués que par Transformer, et il est assez facile de générer du HTML.
Vous devrez choisir votre partenaire surtout si vous voulez traiter des données confidentielles
Ici nous avons choisi de faire du CURL , mais vous pouvez utiliser si vous le préférez un programme SQLRPGLE
Vous pouvez bien sur améliorer ce code à votre guise.
/wp-content/uploads/2017/05/logogaia.png00Noah Vergely/wp-content/uploads/2017/05/logogaia.pngNoah Vergely2026-06-09 09:16:082026-06-09 09:16:10Html vers pdf dans l’IBM i
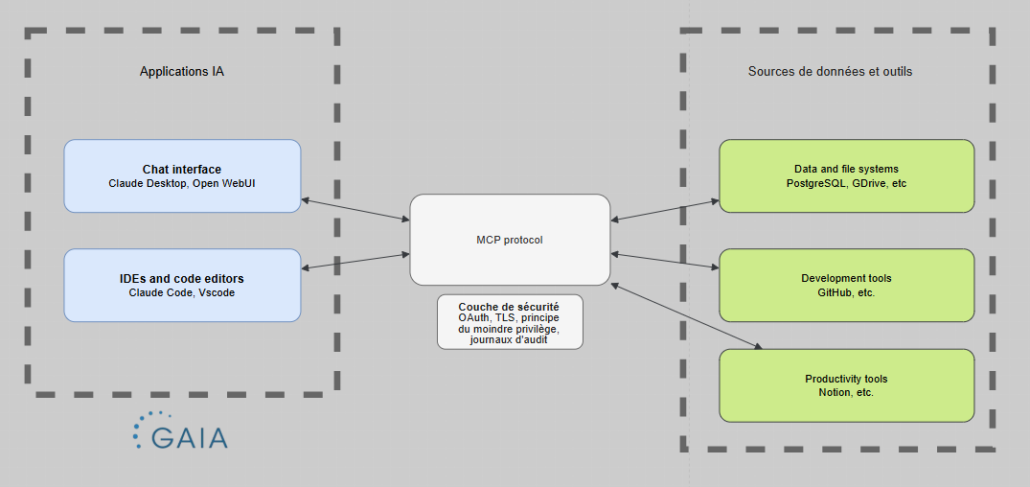
API, IA, VSCodeQu’est-ce que le Model Context Protocol (MCP) ?
Définition du protocole MCP
Le Model Context Protocol (MCP) est un protocole ouvert et standardisé qui permet aux intelligences artificielles (comme Claude, ChatGPT, ou autres grands modèles de langage) de se connecter facilement à des outils, services et sources de données externes. C’est un peu comme l’USB-C des applications IA : au lieu d’avoir un câble différent pour chaque appareil, tu as un seul connecteur universel qui fonctionne avec tout.
Comment ça fonctionne ?
Sans MCP, chaque outil (GitHub, base de données, email, API) avait sa propre façon de se connecter, ce qui obligeait les développeurs à créer des intégrations personnalisées pour chaque combinaison. Avec le MCP, tout le monde utilise la même méthode standard, ce qui rend les connexions beaucoup plus simples et universelles.
Le MCP permet aux IA de sortir de leurs données d’entraînement et d’accéder à des informations en temps réel. Mais surtout, il leur permet d’agir dans le monde réel. Par exemple, tu peux demander à ton IA dans VS Code de lire un fichier source, puis d’écrire automatiquement un résumé dans ton outil de prise de notes comme Notion. D’autres actions possibles : envoyer un email, consulter GitHub, modifier un fichier, créer un événement dans l’agenda, etc. C’est ce qui rend possible l’IA agentique : des programmes intelligents capables de poursuivre des objectifs et d’entreprendre des actions de manière autonome, sans que l’humain ait à copier-coller ou basculer manuellement entre ses outils.
Pourquoi est-il important de s’intéresser au protocole MCP ?
Pour rappel, le protocole MCP joue un rôle essentiel puisqu’il facilite les échanges entre les IA, les applications et les outils utilisés en entreprise. Il permet de connecter plus simplement différents systèmes tout en améliorant la circulation et l’exploitation des données.
Selon les différents rôles dans une entreprise, le MCP apporte plusieurs avantages :
Équipes techniques et développeurs : il simplifie les intégrations, réduit la complexité du développement et accélère la mise en place de nouveaux outils.
Managers et responsables métiers : il améliore l’automatisation, la circulation des informations et l’efficacité des processus internes.
Pour les responsables métiers et managers : ilaméliore la circulation des informations et facilite l’automatisation de certaines tâches. Il aide les managers à gagner du temps, à mieux suivre les activités et à prendre des décisions plus efficacement grâce à un accès simplifié aux données.
En résumé les MCP accompagne la modernisation des entreprises en favorisant des architectures plus connectées, flexibles et évolutives.
Exemple d’utilisation :
Étapes du processus
L’utilisateur saisit sa question dans l’interface de chat (ex. : « Quelles commandes sont en retard cette semaine ? »).
L’assistant IA transmet la requête au serveur MCP PostgreSQL ou autre.
Le serveur MCP traduit la requête en SQL et interroge la bdd.
Le résultat est retourné au LLM, qui formule une réponse en langage naturel.
L’utilisateur obtient une réponse contextualisée, sans accès direct à la base.
La sécurité des MCP
Le MCP supporte OAuth pour l’authentification et recommande TLS pour le chiffrement des échanges.deux mécanismes que tu dois explicitement configurer, ils ne sont pas actifs par défaut
Le modèle Zero Trust : « ne jamais faire confiance au réseau, même interne ».
Les bonnes pratiques recommandées :
Accorder aux serveurs MCP uniquement les droits strictement nécessaires à leur fonctionnement, conformément au principe du moindre privilège, afin de limiter les risques liés aux erreurs, attaques ou accès non autorisés.
Contrôler régulièrement les accès et permissions attribués à chaque serveur pour éviter toute autorisation excessive ou inutile.
Vérifier et comprendre précisément les accès accordés lors de la mise en place d’une connexion MCP.
Utiliser exclusivement des serveurs MCP fiables et de confiance.
Human-in-the-loop : toujours exiger une confirmation manuelle avant les actions critiques (suppression, déploiement, envoi)
Sandboxing : isoler les serveurs MCP dans des containers Docker pour limiter la portée d’une compromission
Rotation des secrets : ne jamais hardcoder de clés API dans la config MCP.
/wp-content/uploads/2017/05/logogaia.png00Dilhan Dincer/wp-content/uploads/2017/05/logogaia.pngDilhan Dincer2026-06-02 10:00:002026-06-02 17:23:19Qu’est-ce que le Model Context Protocol (MCP) ?
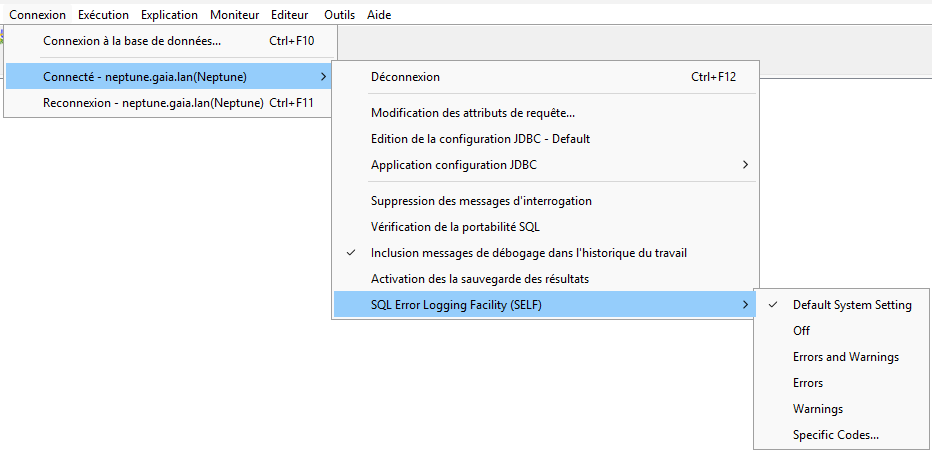
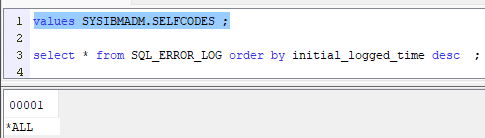
Concrètement, cela modifie la liste des erreurs qui sont tracées dans la vue SQL_ERROR_LOG. Cette liste est stockée dans la variable globale SYSIBMADM.SELFCODES, avec quelques valeurs spéciales (*ALL, *ERROR, *WARN, *NONE).
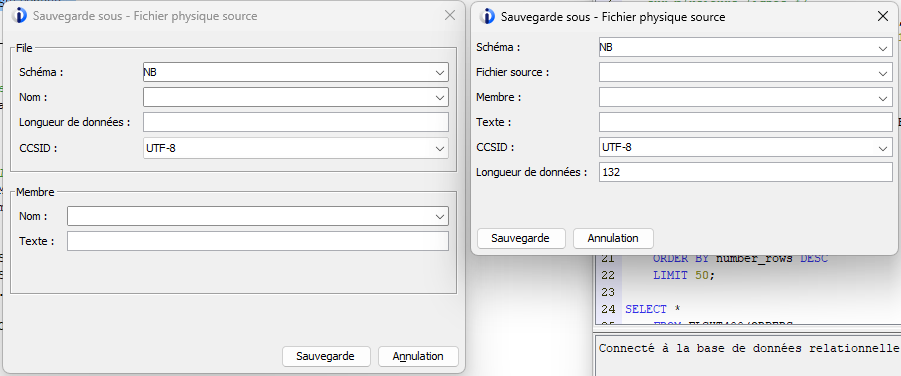
Fichiers physiques source
Amélioration de la fenêtre de dialogue pour la sauvegarde en fichiers sources :
Gestion des fins de ligne
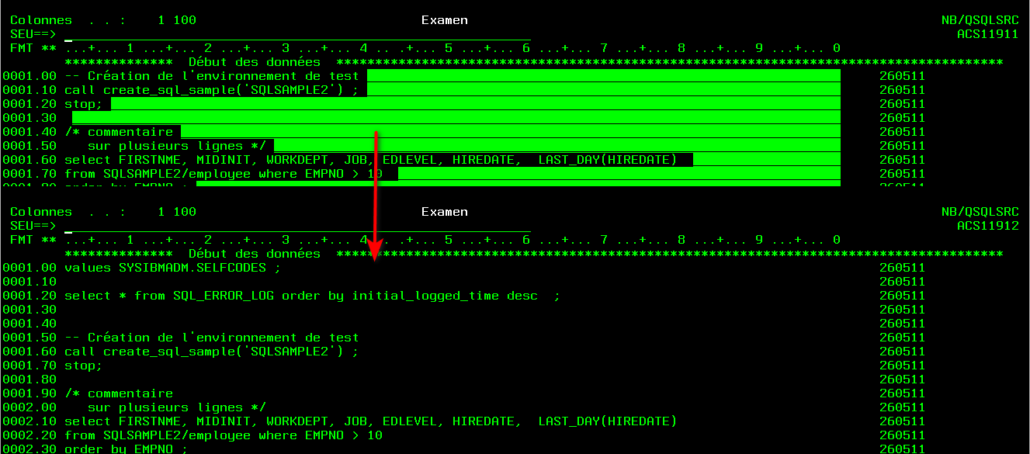
Les caractères LF (x’25’) ne sont plus insérés en fin de ligne dans le cas d’une sauvegarde en fichier source :
Il n’y pas d’impact à l’éxecution (RUNSQLSTM), mais plus de confort !
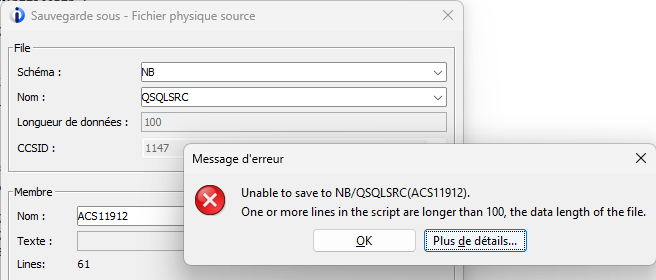
Gestion de la taille des lignes
Lors de l’enregistrement, au lieu de tronquer les lignes, un message permet d’avertir :
Exemples SQL
13 nouveaux exemples pour les services SQL :
SELF – System-wide controls
SELF – Job-level controls
SELF – Log Queries
SELF – Removing historical rows
SELF – Initial Stack
SELF – Top occurrences
SELF – QA use case exampleSecurity – Who is creating objects in the IFS root
Security – Who is creating objects in the /QOpenSys subdirectory
Security – IFS first-level directories that are open to attack
Pour connaitre le type d’un fichier, vous pouvez vous baser sur le type du Fichier .PDF, .JPG, etc …
Ou vous baser sur le nombre magique , ou signature binaire soit les 4 premiers octets en Hexa
SELECT HEX(SUBSTR(LINE, 1, 4)) AS SIGNATURE FROM TABLE(QSYS2.IFS_READ_BINARY(‘/home/test.pdf’)) FETCH FIRST 1 ROW ONLY;
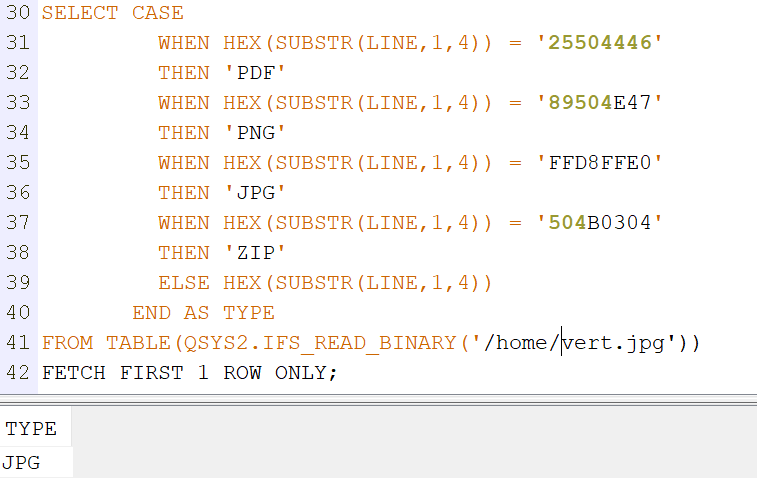
Voici un exemple sur 4 fichiers que vous pouvez trouver sur votre partition
SELECT CASE
WHEN HEX(SUBSTR(LINE,1,4)) = '25504446'
THEN 'PDF'
WHEN HEX(SUBSTR(LINE,1,4)) = '89504E47'
THEN 'PNG'
WHEN HEX(SUBSTR(LINE,1,4)) = 'FFD8FFE0'
THEN 'JPG'
WHEN HEX(SUBSTR(LINE,1,4)) = '504B0304'
THEN 'ZIP'
ELSE 'Autre' // inconnu
END AS TYPE
FROM TABLE(QSYS2.IFS_READ_BINARY('/home/vert.jpg'))
FETCH FIRST 1 ROW ONLY;
Résultat :
Conclusion :
C’est simple, et efficace, il y a sans doute d’autres manières de faire
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2026-05-11 14:42:272026-05-11 14:42:28Trouver le type d’un fichier