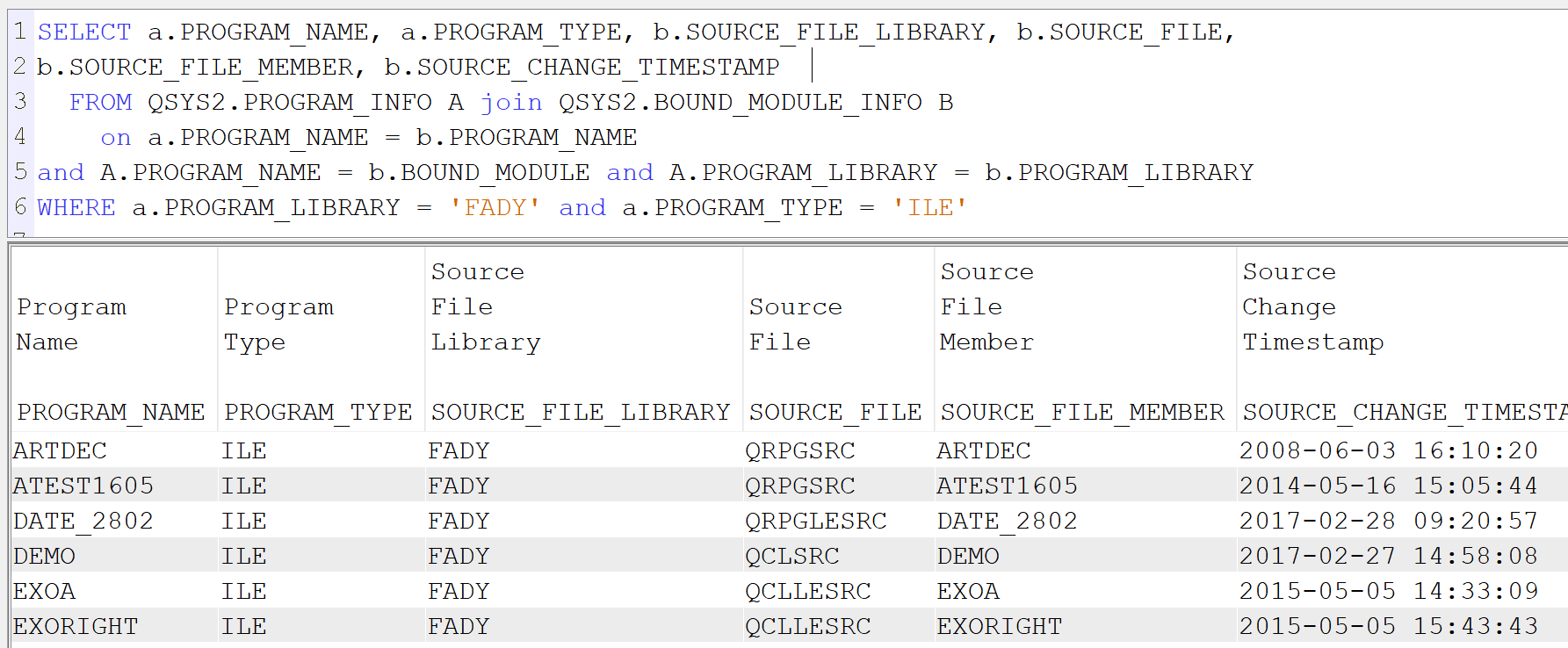
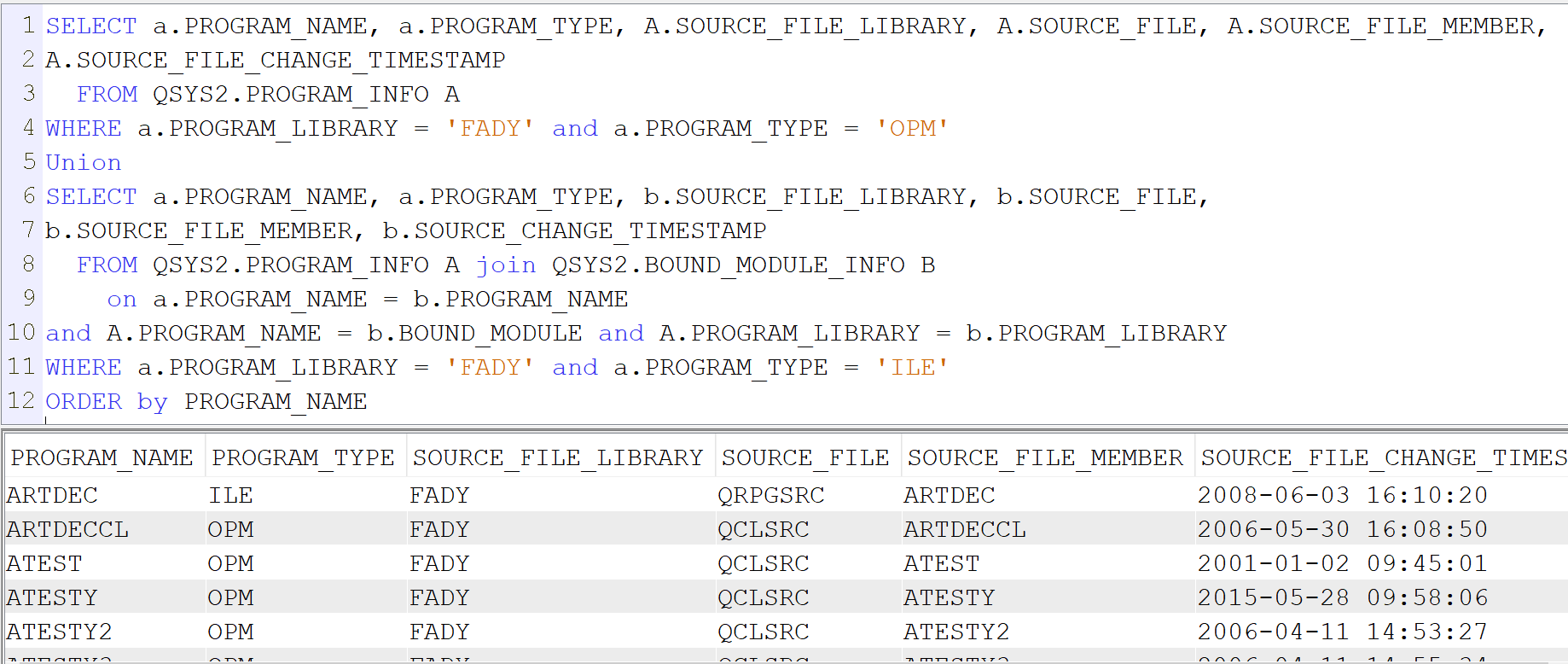
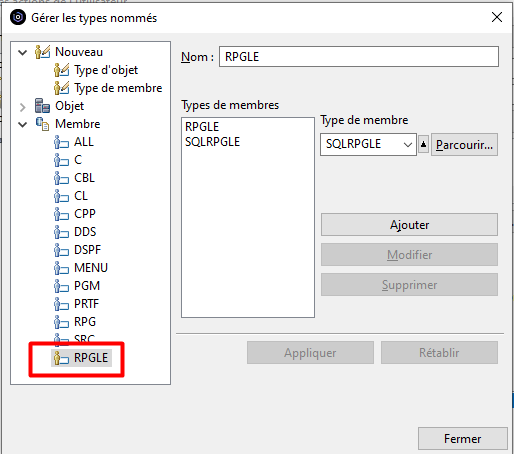
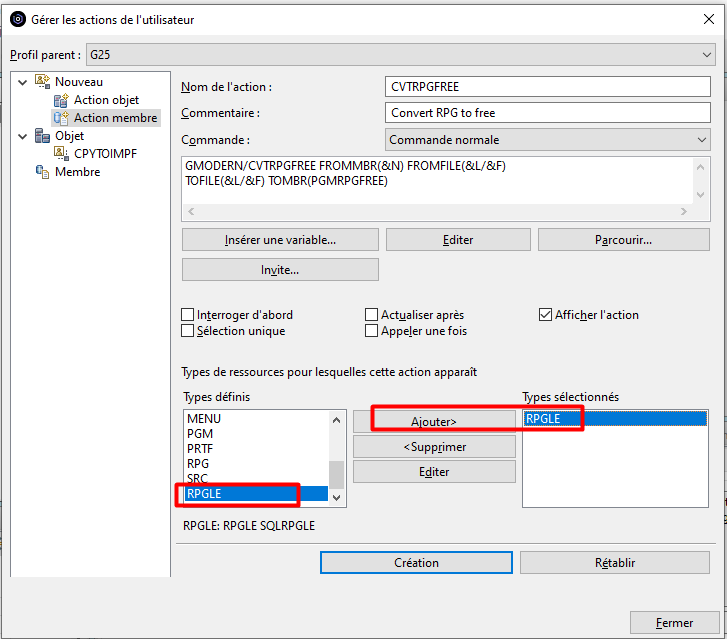
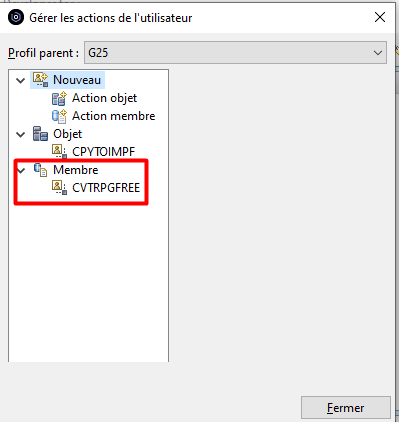
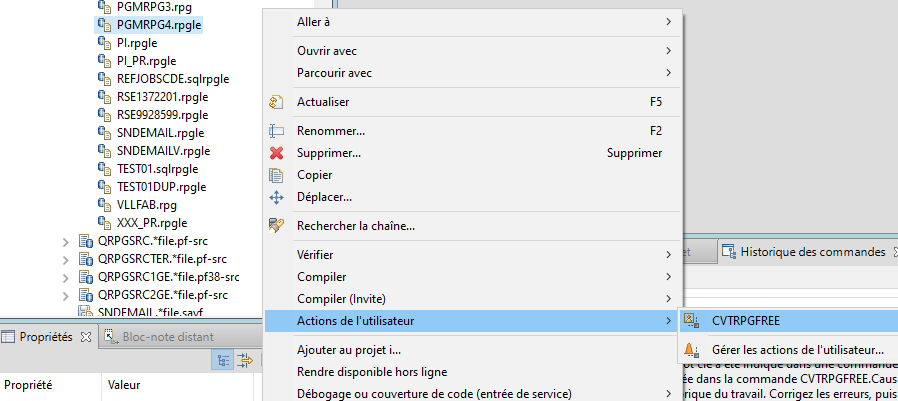
Lorsque l’on crée un programme de service il est intéressant de classer les procédures utilisées dans différents modules afin de faciliter une maintenance future. On peut regrouper par exemple les procédures par fonctionnalité métier (prise de commandes, rangement, calculs de taux,… ) ou par proximité technique (manipulation de chaines de caractères, calcul d’un modulo, manipulation de dates,… ). Dans l’article intitulé « CONTROLER IBAN & RIB » on regroupe les deux fonctions bancaires au sein d’une même procédure.
Lorsque l’on veut créer un programme de service il faut procéder en deux temps :
- Créer les modules contenant les procédures et fonctions
CRTSQLRPGI OBJ(MyLibrary/MyModuleXX) SRCFILE(MyLibrary/MySRCPF) SRCMBR(MyModuleXX) OBJTYPE(MODULE) REPLACE(YES) DBGVIEW(*SOURCE)
- Créer le programme de service qui intègrera les modules
CRTSRVPGM SRVPGM(MyLibrary/MyServicePGM) MODULE(MyLibrary/MyModule0 MyLibrary/MyModule1 MyLibrary/MyModule2 MyLibrary/MyModule3 MyLibrary/MyModule4) EXPORT(*SRCFILE) SRCFILE(MyLibrary/QSRVSRC) SRCMBR(MySrcMBR)
Nous vous proposons donc de créer une fonction qui permettra d’enchainer ces deux opérations (nous nous limiterons à la possibilité d’agréger 10 modules dans un programme de service)
Présentation de la commande
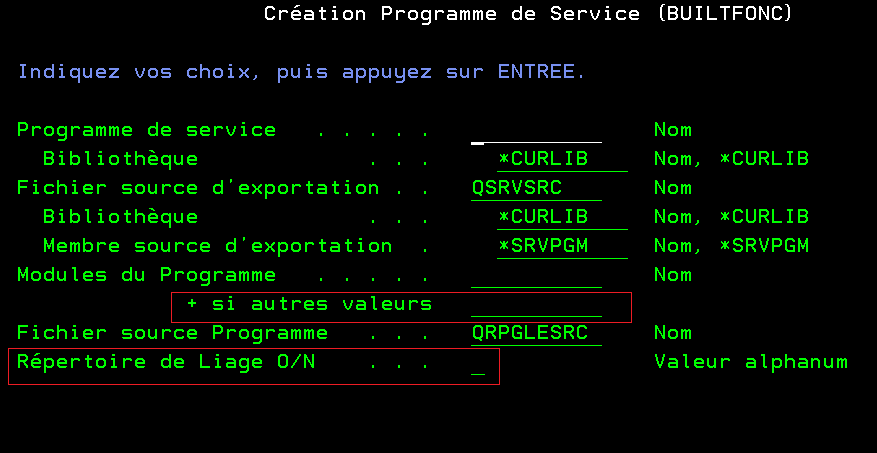
Cette commande permet de saisir plusieurs modules et de les intégrer directement dans un programme de service

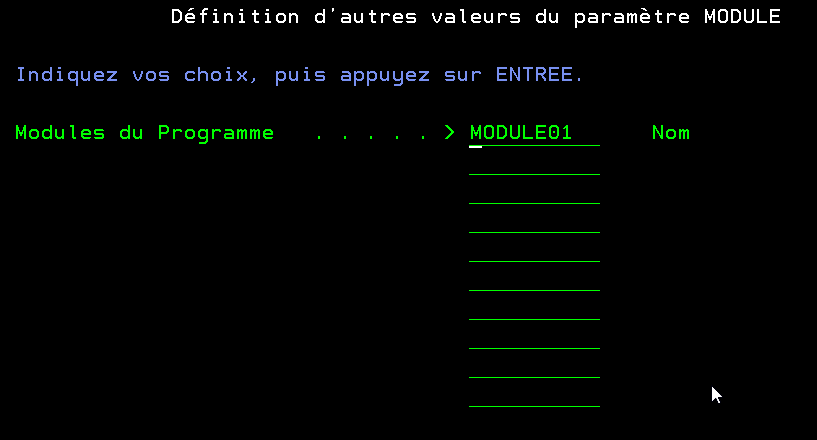
On peut également ajouter un répertoire de liage, si besoin

Source de la commande
CMD PROMPT('Création Programme de Service')
PARM KWD(SRVPGM) TYPE(Q0) MIN(1) PROMPT('Programme de service ')
Q0: QUAL TYPE(*NAME) LEN(10) MIN(1)
QUAL TYPE(*NAME) LEN(10) DFT(*CURLIB) SPCVAL((*CURLIB)) MIN(0) +
PROMPT('Bibliothèque ')
PARM KWD(SRVSRC) TYPE(Q1) PROMPT('Fichier source d''exportation')
Q1: QUAL TYPE(*NAME) LEN(10) DFT(QSRVSRC) MIN(0)
QUAL TYPE(*NAME) LEN(10) DFT(*CURLIB) SPCVAL((*CURLIB)) MIN(0) +
PROMPT('Bibliothèque ')
QUAL TYPE(*NAME) LEN(10) DFT(*SRVPGM) SPCVAL((*SRVPGM)) MIN(0) +
PROMPT('Membre source d''exportation')
PARM KWD(MODULE) TYPE(*NAME) LEN(10) MAX(10) PROMPT('Modules du Programme ')
PARM KWD(SRCFIL) TYPE(*NAME) LEN(10) MIN(0) DFT(QRPGLESRC) PROMPT('Fichier +
source Programme ')
PARM KWD(ONBNDDIR) TYPE(*CHAR) LEN(1) MIN(0) PROMPT('Répertoire de Liage O/N ')
PARM KWD(BNDDIR) TYPE(*NAME) LEN(10) MIN(0) PMTCTL(LIAGE) +
PROMPT('Répertoire de Liage ')
LIAGE: PMTCTL CTL(SRCFIL) COND((*NE '')) NBRTRUE(*ALL)
PMTCTL CTL(SRVSRC) COND((*NE '')) NBRTRUE(*ALL) LGLREL(*AND)
PMTCTL CTL(ONBNDDIR) COND((*EQ 'O')) NBRTRUE(*ALL) LGLREL(*AND)
LIAG2: PMTCTL CTL(ONBNDDIR) COND((*EQ 'O') (*EQ 'N')) NBRTRUE(*EQ 1)
Programme de controle
PGM PARM(&SRVPGMLIB &SRVBIBMBR &MODULE &SRCFIL +
&ONBNDDIR &BNDDIR)
DCL VAR(&VAR1) TYPE(*INT) LEN(2)
DCL VAR(&POS) TYPE(*INT) LEN(2)
DCL VAR(&CPT) TYPE(*INT) LEN(2)
DCL VAR(&SRVPGMLIB) TYPE(*CHAR) LEN(20)
DCL VAR(&SRVPGM) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&SRVPGMLIB 1)
DCL VAR(&SRVLIB) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&SRVPGMLIB 11)
DCL VAR(&SRVBIBMBR) TYPE(*CHAR) LEN(30)
DCL VAR(&SRVFIC) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&SRVBIBMBR 1)
DCL VAR(&SRVBIB) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&SRVBIBMBR 11)
DCL VAR(&SRVMBR) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&SRVBIBMBR 21)
DCL VAR(&MODULE) TYPE(*CHAR) LEN(102)
DCL VAR(&VALMOD) TYPE(*CHAR) LEN(10)
DCL VAR(&SRCFIL) TYPE(*CHAR) LEN(10)
DCL VAR(&ONBNDDIR) TYPE(*CHAR) LEN(1)
DCL VAR(&BNDDIR) TYPE(*CHAR) LEN(10)
DCL VAR(&LSTMOD) TYPE(*CHAR) LEN(250)
DCL VAR(&COMMANDE) TYPE(*CHAR) LEN(500)
/* Initialiser les variables */
CHGVAR VAR(&VAR1) VALUE(%BIN(&MODULE 1 2))
IF COND(&SRVLIB *EQ '*CURLIB') THEN(RTVJOBA +
CURLIB(&SRVLIB))
/* Extraction de chaque poste */
DOFOR VAR(&CPT) FROM(1) TO(&VAR1)
CHGVAR VAR(&POS) VALUE(3 + (&CPT - 1) * 10)
CHGVAR VAR(&VALMOD) VALUE(%SST(&MODULE &POS 10))
CRTSQLRPGI OBJ(&SRVLIB/&VALMOD) SRCFILE(&SRVLIB/&SRCFIL) +
SRCMBR(&VALMOD) OBJTYPE(*MODULE) +
REPLACE(*YES) DBGVIEW(*SOURCE)
CHGVAR VAR(&LSTMOD) VALUE(%TRIM(&LSTMOD) !! ' ' !! +
%TRIM(&SRVLIB) !! '/' !! %TRIM(&VALMOD))
ENDDO
CHGVAR VAR(&COMMANDE) VALUE('CRTSRVPGM SRVPGM(' !! +
%TRIM(&SRVLIB) !! '/' !! %TRIM(&SRVPGM) !! ') +
MODULE(' !! %TRIM(&LSTMOD) !! ') +
EXPORT(*SRCFILE) SRCFILE(' !! %TRIM(&SRVBIB) !! +
'/' !! %TRIM(&SRVFIC) !! ') SRCMBR(' !! +
%TRIM(&SRVMBR) !! ')')
CALL PGM(QCMDEXC) PARM(&COMMANDE %LEN(&COMMANDE))
IF COND(&ONBNDDIR = 'O') THEN(DO)
CHKOBJ OBJ(&SRVLIB/&BNDDIR) OBJTYPE(*BNDDIR)
MONMSG MSGID(CPF9801) EXEC(CRTBNDDIR +
BNDDIR(&SRVLIB/&BNDDIR))
ADDBNDDIRE BNDDIR(&SRVLIB/&BNDDIR) OBJ((&SRVLIB/&SRVPGM))
ENDDO
ENDPGM