L’utilisation des noms longs dans le code RPG est un atout supplémentaire pour le rendre plus lisible et en faciliter la maintenance.
On continue malheureusement trop souvent à utiliser les noms courts hérités de nos bases de données et du code RPG colonné, même converti en Free.
Pourtant, l’utilisation des alias dans les DDS et les déclaratives RPG ainsi que la redéfinition des indicateurs, permettent de s’affranchir totalement des noms courts au profit des noms longs.
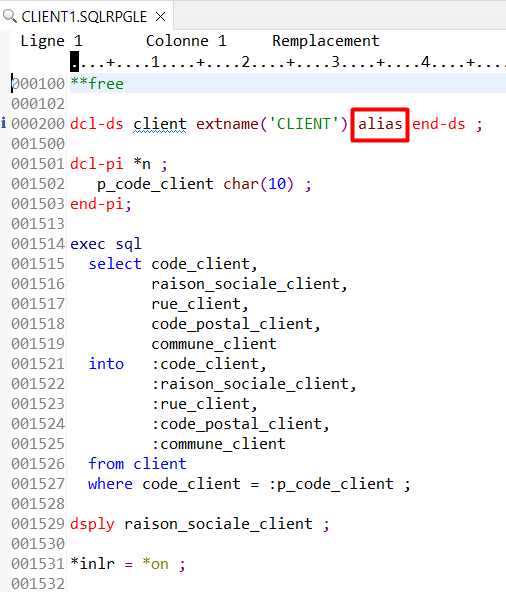
Utilisez le mot clé ALIAS dans les DDS
Le mot-clé ALIAS permet d’associer un nom long à un champ très souvent nommé avec seulement 6 caractères, et maximum 10 caractères
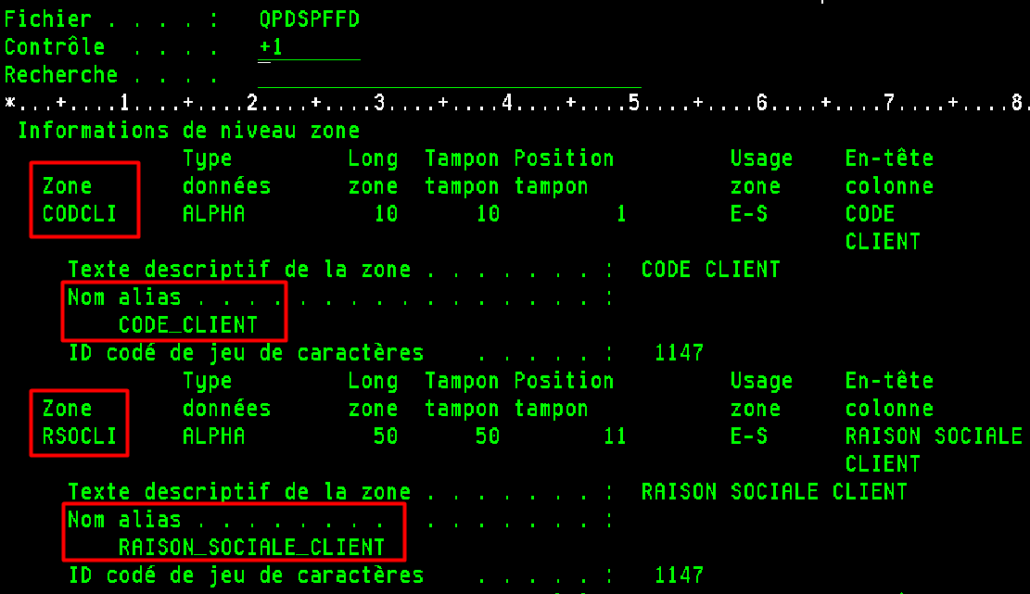
ALIAS dans un PF
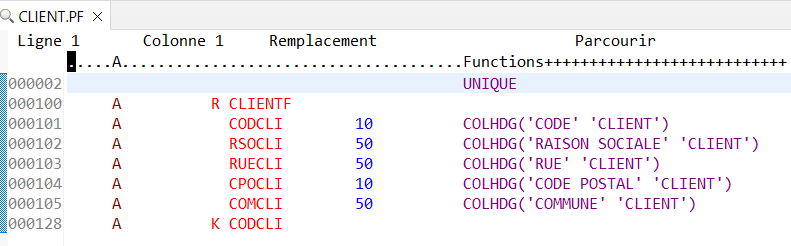
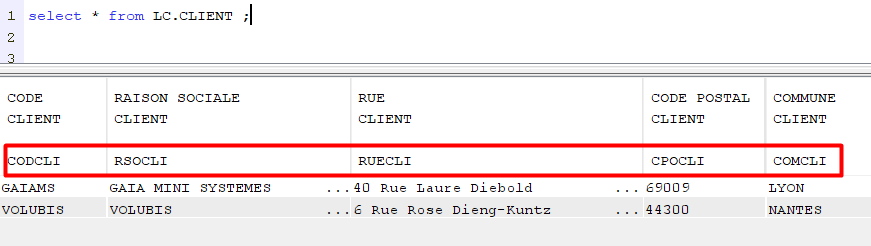
Exemple avec un fichier sans ALIAS :
.
.
.
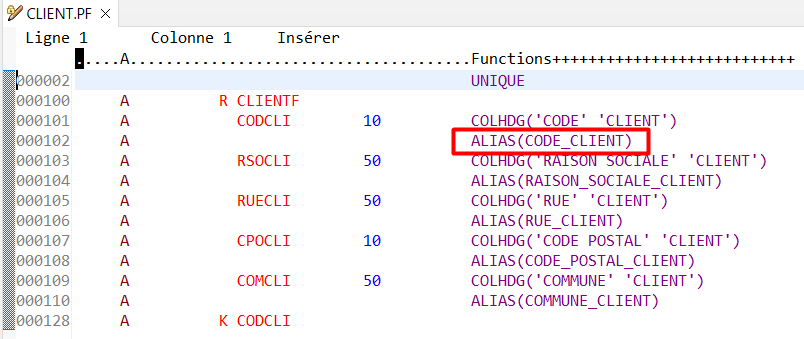
Le mot clé ALIAS peut être rajouté dans les DDS de vos fichiers sans aucun impact sur vos applications :
.
.
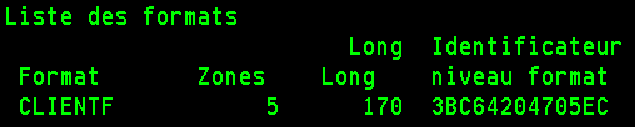
Les ALIAS peuvent être appliqués sans perte de données par un CHGPF :
Cette opération ne modifie pas le niveau de format du fichier, pas de recompilation des applications
.
.
.
.
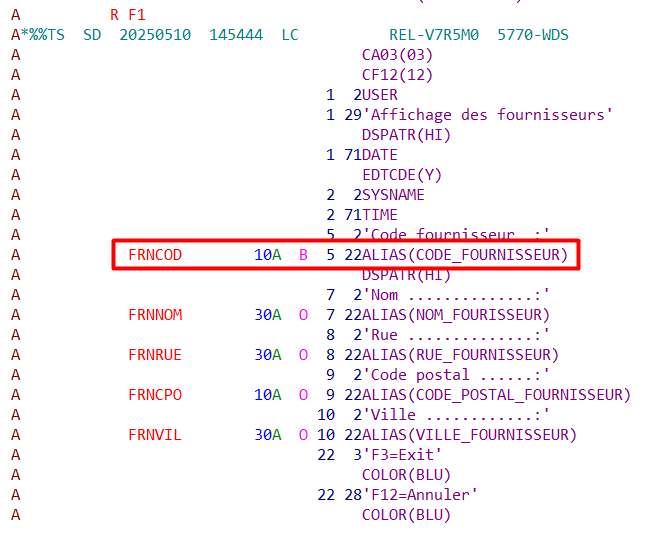
ALIAS dans un DSPF
Dans vos écrans 5250, vous pouvez aussi associer des noms longs aux noms courts sous forme d’ALIAS.
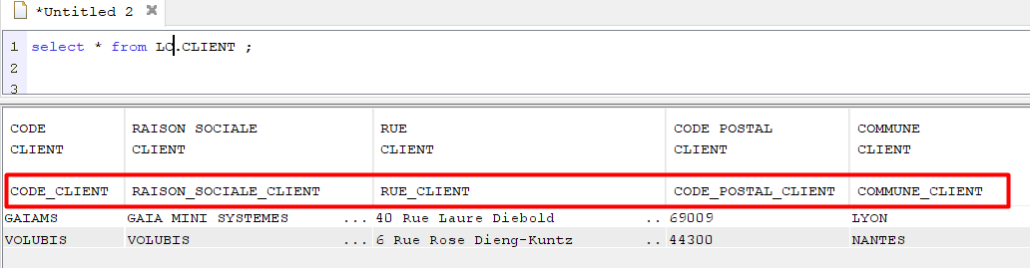
Les ALIAS longs peuvent être utilisés dans le code RPG à la place des noms courts.
.
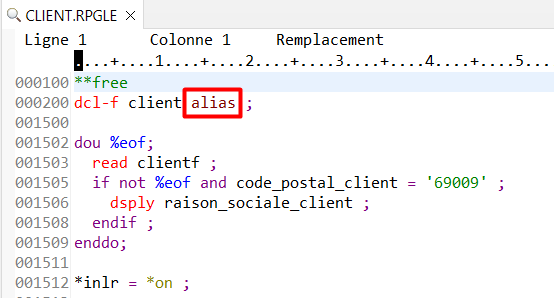
Utilisez le mot clé ALIAS dans la déclaration d’ouverture du fichier
Il vous permet d’utiliser les ALIAS du fichier en tant que noms de variables, dans le code RPG
.
.
Utilisez le mot clé ALIAS dans la déclaration d’une DS externe
Il vous permet d’utiliser les ALIAS du fichier externe de la DS en tant que noms de variables, dans le code RPG
.
.
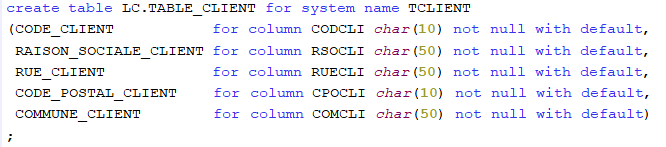
Noms longs et noms courts dans une table SQL
Lorsque vous créez une table SQL, vous lui attribuez un nom long SQL mais vous pouvez aussi lui attribuer un nom court de votre choix par la clause SYSTEM NAME afin d’éviter que le système ne lui attribue un nom court par défaut.
Pour la même raison, il est conseillé d’attribuer à chaque colonne un nom court en plus du nom long, par la clause FOR COLUMN
.
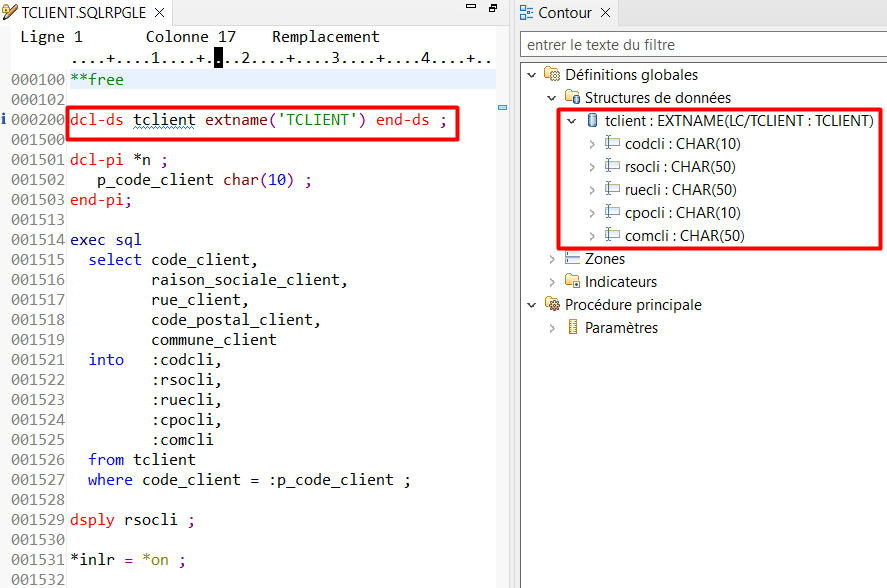
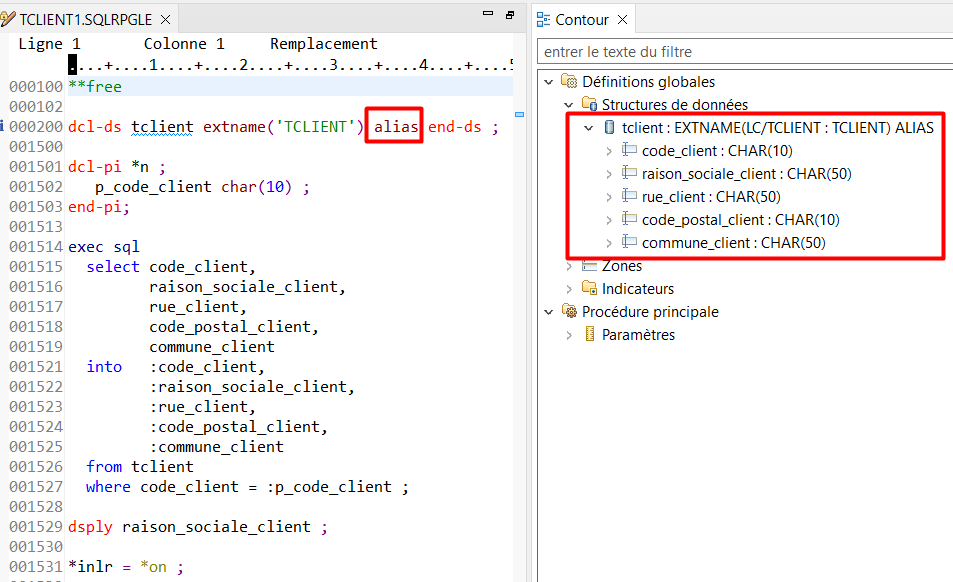
Dans le code RPG, vous pouvez déclarez la DS de votre table pour qu’elle utilise les noms courts (sans mot clé ALIAS) ou les noms longs (avec le mot clé ALIAS) :
Déclaration d’une DS externe pour une table SQL avec utilisation des noms courts
.
Déclaration d’une DS externe pour une table SQL avec utilisation des noms longs
.
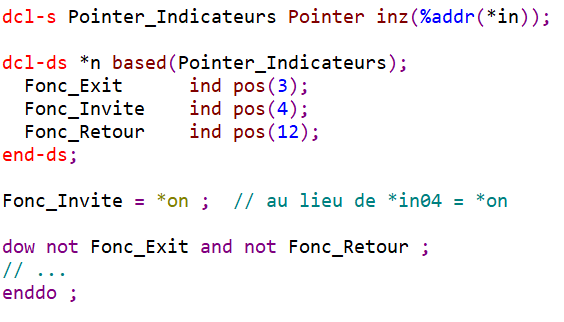
Renommez les indicateurs *INxx
Vous pouvez vous affranchir des indicateurs *INxx dans le code RPG en les renommant :
https://www.gaia.fr/wp-content/uploads/2025/05/Laurent_Chavanel.png321322Laurent Chavanel/wp-content/uploads/2017/05/logogaia.pngLaurent Chavanel2025-05-12 11:42:532025-05-12 11:42:54S’affranchir des noms courts en RPG
Vous changez de machine ou de version et les dates de référence de vos objets et vos sources vont être remise à zéro, grâce aux services SQL , vous pouvez facilement conserver temporairement ces informations
Vous pourrez par exemple avoir besoin de ces informations pour faire une analyse d’impact sur l’utilisation de certain programmes ou de sources
Pour garder une trace de ces informations voici ce que vous pouvez faire
créer une bibliothèque
==> CRTLIB MIGRATION
vous avez intérêt à extraire les informations juste avant la migration
1) Sur les objets
Vous pouvez utiliser la fonction table QSYS2.OBJECT_STATISTICS
exemple :
create table migration.lstobj as( SELECT * FROM TABLE ( QSYS2.OBJECT_STATISTICS(‘ALL’,’ALL’) ) AS X ) with data
Vous pouvez si vous le voulez choisir ou éliminer des objets ou des bibliothèques.
2) sur les sources
Si vous avez des fichiers sources QRPGLESRC, QCLSRC etc …
Vous pouvez utiliser la vue QSYS2.SYSPARTITIONSTAT
exemple :
create table migration.lstsrc as( SELECT * FROM qsys2.SYSPARTITIONSTAT WHERE not source_type is null and NUMBER_ROWS > 0 ) with data
ici on limite aux membres sources non vide
Si vous avez des fichiers sources dans L’ifs, nodejs, php, python, ou même des développements traditionnels en RPGLE ou CLLE
Vous pouvez utiliser la fonction table QSYS2.IFS_OBJECT_STATISTICS
exemple :
create table migration.lstifs1 as( SELECT * FROM TABLE ( qsys2.ifs_object_statistics( start_path_name => ‘/Votre_repert/’ , subtree_directories => ‘YES’ ) ) ) with data
Vous devrez limiter à vos repertoires de sources , vous pouvez en faire plusieurs
Ensuite vous devrez envoyer votre bibliothèque sur le systéme cible
Soit par la migration naturelle qui emmènera toutes les bibliothèques ou par une opération spécifique d’envoi de la bibliothèque FTP, SAVRSTLIB etc…
Attention :
Après 6 mois cette bibliothèque devra être supprimée, elle ne servira plus à rien
Remarque :
Vous pouvez également inclure dans cette bibliothèque d’autres éléments qui pourront être utile comme :
La liste des valeurs systèmes , QSYS2.SYSTEM_VALUE_INFO Le planning des travaux , QSYS2.SCHEDULED_JOB_INFO les programmes d’exit , QSYS2.EXIT_PROGRAM_INFO les watchers , QSYS2.WATCH_INFO les bases de données DRDA , QSYS2.RDB_ENTRY_INFO les reroutages de travaux , QSYS2.ROUTING_ENTRY_INFO la table des réponses par défaut , QSYS2.REPLY_LIST_INFO etc …
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-05-08 07:31:422025-05-08 07:31:43Conserver des informations avant migration
Vous devez échanger un fichier avec un partenaire qui vous le demande au format JSON
Il n’existe pas de CVTJSONxx comme la commande CPYTOIMPF pour le CSV
Pas de panique vous avez des services SQL qui font ceci voici un exemple :
Création d’une table de test
SET SCHEMA = ‘votre base’; CREATE OR REPLACE TABLE CLIENTS ( ID_CLIENT INTEGER NOT NULL WITH DEFAULT, NOM_CLIENT VARCHAR ( 50) NOT NULL WITH DEFAULT, VILLE VARCHAR ( 50) NOT NULL WITH DEFAULT ) ; INSERT INTO CLIENTS VALUES(1, ‘Dupont’, ‘Paris’) ; INSERT INTO CLIENTS VALUES(2, ‘Durand’, ‘Lyon’) ;
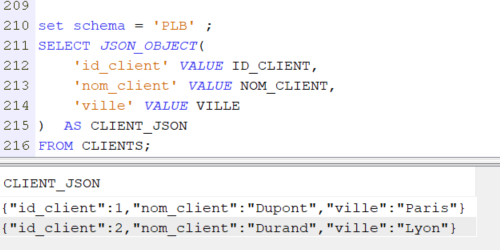
Voici la syntaxe qu’il vous faudra utiliser pour le convertir sous forme de flux json
SELECT JSON_OBJECT(
'id_client' VALUE ID_CLIENT,
'nom_client' VALUE NOM_CLIENT,
'ville' VALUE VILLE
) AS CLIENT_JSON
FROM CLIENTS;
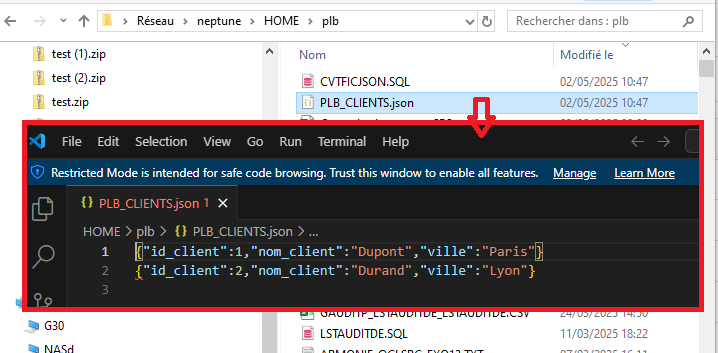
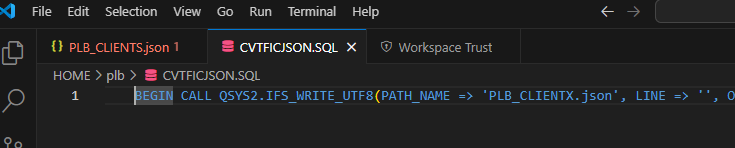
Maintenant il va falloir générer le fichier .JSON dans l’IFS par exemple en utilisant la procédure IFS_WRITE_UTF8
Malheureusement ce service n’existe pas sous forme de fonction on devra utiliser une des possibilités de SQL « Dynamic compound statement » qui permet de compiler un module dynamiquement
Ce qui donnera donc
BEGIN
CALL QSYS2.IFS_WRITE_UTF8(
PATH_NAME => 'PLB_CLIENTS.json',
LINE => '',
OVERWRITE => 'REPLACE',
END_OF_LINE => 'NONE'
);
FOR SELECT TRIM(CAST(JSON_OBJECT(
'id_client' VALUE ID_CLIENT,
'nom_client' VALUE NOM_CLIENT,
'ville' VALUE VILLE
) AS VARCHAR(32000))) AS Line_to_write
FROM PLB.CLIENTS
DO
CALL QSYS2.IFS_WRITE_UTF8(
PATH_NAME => 'PLB_CLIENTS.json',
LINE => Line_to_write
);
END FOR;
END;
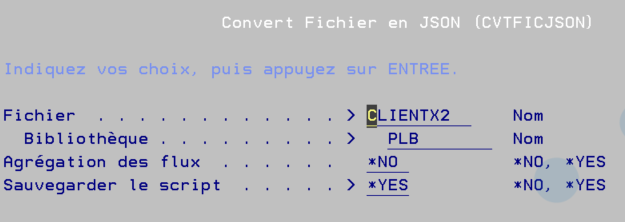
Si vous avez beaucoup de fichiers à convertir ca peut être fastidieux pas de panique nous avons fait une commande qui va vous aider
https://github.com/Plberthoin/PLB/tree/master/GTOOLS, vous avez l’habitude un source SQLRPGLE et un source CMD à compiler , voila SME
Vous pouvez enregistrer le scripte SQL (CVTFICJSON.SQL) avec l’option Sauvegarder le scripte
Vous pourrez le customiser :
en le formatant par ACS ,
en enlevant des zones
en sélectionnant des enregistrements
etc …
Remarque :
Vous avez une option pour agréger
Vous pouvez faire beaucoup mieux , c’est juste pour vous aider à démarrer dans le domaine
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-05-02 12:16:162025-05-02 12:16:17Convertissez un fichier en JSON
Retour sur une problématique récurrente et souvent mal comprise, donc mal gérée … Et qui pourrait bien s’amplifier avec l’usage plus intensif de l’Open Source.
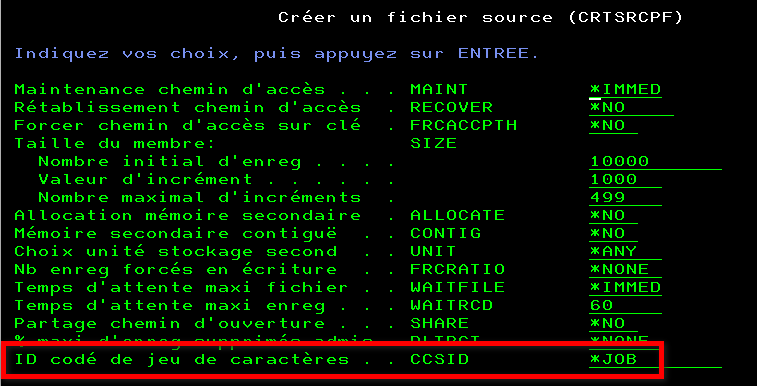
Vous utilisez historiquement des fichiers sources (objet *FILE attribut PF-SRC) pour stocker vos sources : ces fichiers sont créés avec un CCSID, par défaut le CCSID du job dans lequel vous exécutez la commande CRTSRCPF
Usuellement vous obtiendrez des fichiers sources avec un CCSID 297 ou 1147 pour la France. Si vos machines sont « incorrectement » réglées, un CCSID 65535 (hexadécimal).
Mais également, par restauration d’autres produits, certainement des fichiers avec un CCSID 37 (US).
Pour les langages de programmation (dont le SQL), le CCSID du fichier source est important pour les constantes, qui peuvent par définition êtres des caractères nationaux quelconques. Quant aux instructions, la grammaire des langages les définis sans ambiguïtés.
Caractères spéciaux / nationaux
Pour toutes les commandes, instructions, éléments du langage, pas de soucis d’interprétation
A la compilation, les constantes sont interprétées suivant le CCSID du job, pas celui du source !
En général, les deux CCSID sont identiques.
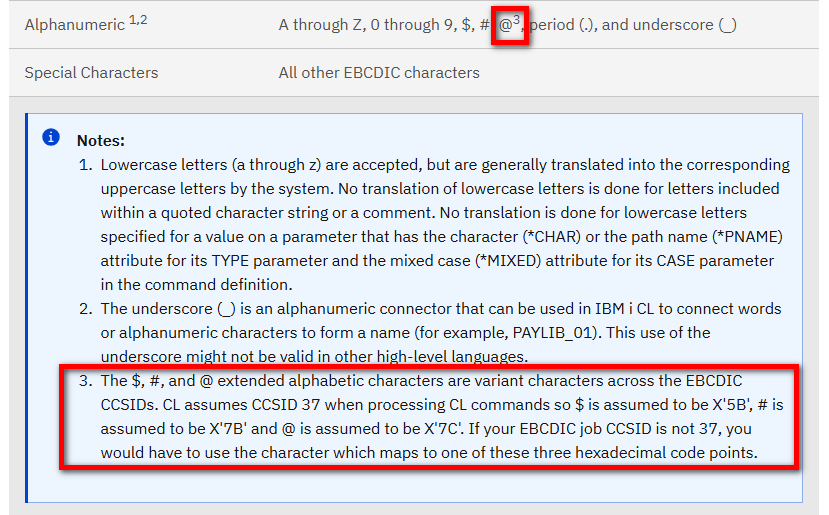
Par contre, pour les caractères spéciaux utilisés, si l’on regarde de plus près le cas du CL, la documentation indique :
Voilà qui explique les fameuses transformations de @ en à !
En synthèse : le compilateur considère tous les éléments du langage comme étant en CCSID 37, hors les constantes alphanumériques et les quelques caractères listés ici.
Pour le CL : impossible d’utiliser les opérateurs symboliques |> (*BCAT), |< (*TCAT) et || (*CAT)
Le caractère | est mal interprété. Vous devez le remplacer par un !, ou utiliser les opérateurs non symboliques (*BCAT, *TCAT et *CAT).
Pour le SQL : impossible d’utiliser l’opérateur || (même raison).
Vous devez le remplacer par un !!, ou utiliser l’opérateur concat.
Evolution du RPG
Le principe est le même.
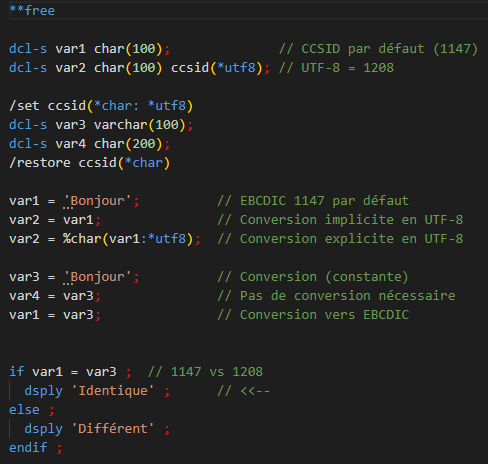
Toutefois le langage vous permet également de contrôler le CCSID des variables déclarées. Et depuis la 7.2, de nouvelles directives de pré-compilation permettent d’indiquer des valeurs de CCSID par défaut par bloc de source :
Et pour l’IFS ?
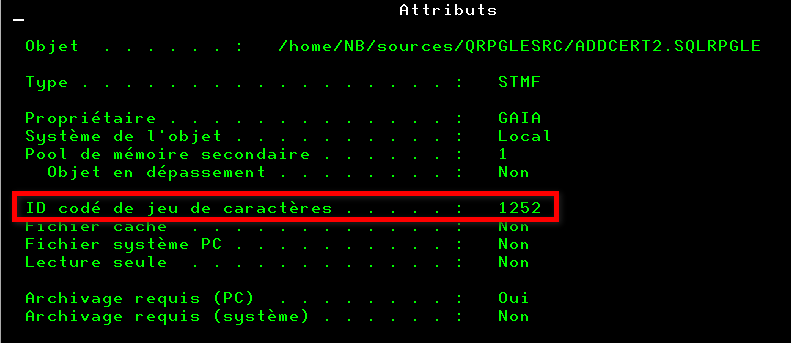
Sur l’IFS, chaque fichier (source ou non) dispose également d’un CCSID. Sa valeur dépend principalement de la façon de créer le fichier (par un éditeur type RDi/VSCode, partage netserver, transfert FTP …).
Premier point d’attention : l’encodage du contenu du fichier doit correspondre à son attribut *CCSID !
VSCode vous indique le CCSID de la donnée, par exemple :
Mais :
1252 = Windows occidental (proche de l’UTF-8 mais pas identique). La raison est que VSCode travaille naturellement en UTF-8.
RDi gère correctement l’encodage/décodage par rapport à la description du fichier.
Pour les autres outils, à voir au cas par cas !
Evolution des compilateurs
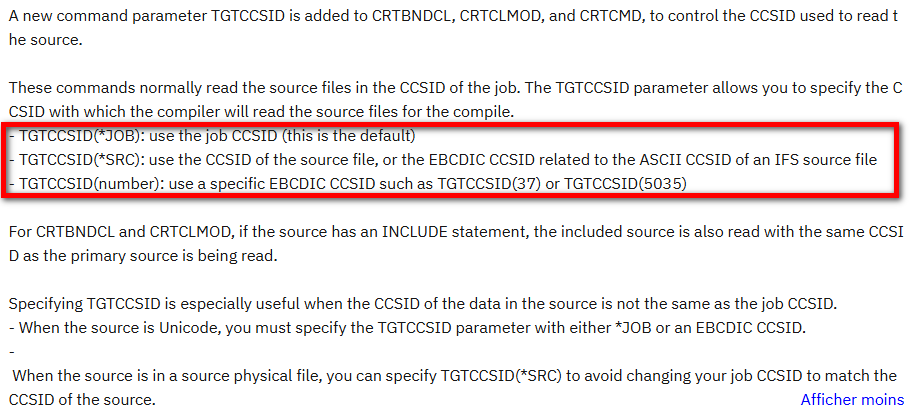
Les compilateurs C, CPP, CL, RPG, COBOL supportent désormais (PTF en fonction des compilateurs) un paramètre TGTCCSID :
En réalité ce paramètre a été ajouté pour permettre la compilation plus facilement depuis l’IFS, principalement depuis des fichiers IFS en UTF-8.
Cela ne règle pas nos problèmes précédents, les éléments du langage n’étant pas concernés : nous auront toujours le problème d’interprétation du |
Par contre, c’est utile pour la bonne interprétation des constantes lorsque le job de compilation a un CCSID du source. Et cela permet une meilleure intégration dans les outils d’automatisation.
Le script propose d’indiquer un CCSID pour les fichiers sources. Mais la seule solution viable est de compiler avec un job en CCSID 37 :
soit CHGJOB CCSID(37) avant de lancer le script
soit vous pouvez vous créer un profil dédié en CCSID 37 si ces opérations sont récurrentes
Tant que vous n’avez pas de caractères nationaux dans le codes !
Retrouver le CCSID de ses fichiers sources
SELECT f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA, c."CCSID" FROM qsys2.systables f JOIN qsys2.syscolumns c ON (c.SYSTEM_TABLE_NAME, c.SYSTEM_TABLE_SCHEMA) = (f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA) WHERE f.file_type = 'S' AND LEFT(f.system_table_name, 8) <> 'EVFTEMPF' AND c.SYSTEM_COLUMN_NAME = 'SRCDTA' ORDER BY c."CCSID", f.SYSTEM_TABLE_SCHEMA, f.SYSTEM_TABLE_NAME;
Nouveau venu dans les bibliothèques middleware pour IBMi, MAPEPIRE est un outil simple pour récupérer des données de votre serveur et les travailler sur de applications tierces, telles que des outils d’analyse de données, de la bureautique, etc.
Nous allons vous présenter la possibilité d’installer et d’utiliser le produit simplement
sur le serveur
sur votre client, en fonction du langage que vous souhaitez utiliser.
Les langages disponibles pour l’instant sont :
JAVA, NODE.JS, PYTHON
Ici, l’exemple détaillé sera effectué avec le langage PYTHON.
Nous n’intervenons pas dans cet article sur les différents paramétrages de l’outil. Nous y reviendrons dans un article suivant. (exit points, ports, etc.)
Serveur
Installation de MAPEPIRE sur le serveur
yum install mapepire
mapepire sera installé dans le répertoire
/qOpenSys/pkgs/bin
Démarrage
Note : dans cet article, on ne détaille ps le démarrage automatique
nohup /qopensys/pkgs/bin/mapepire &
Client
Notre exemple consiste à lister tous les travaux actifs en cours, les répertorier dans une trame PANDAS, puis de sauvegarder les données dans une feuille EXCEL
Pré requis
Python 3 installé et fonctionnel
un répertoire pour le code
Facultatif : un environnement virtuel
EXCEL
librairies installées :
pandas
openpyxl (factultatif)
installation MAPEPIRE
sous l’environnement virtuel (si configuré) ou sur l’environnement global
pip install mapepire-python
le code de notre exemple TEST.PY
#mapepire
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
#--------------------------------------------------
creds = DaemonServer(
host="serveuràcontacter",
port=8076,
user="utilisateur",
password='motdepasse',
ignoreUnauthorized=True,
)
job = SQLJob()
res = job.connect(creds)
#
# Travaux actifs
#
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
countjobs = result['data'][0]['TOTALTRAVAUX']
startT = datetime.now()
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
endT = datetime.now()
delta = endT - startT
print(f"travaux actifs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframActj = pd.DataFrame(result['data'])
#print(dframActj)
#
#récupération des utilisateurs dans une 2ème Frame (dframUsesrs)
#
startT = datetime.now()
result = job.query_and_run("""
WITH USERS AS (
SELECT
CASE GROUP_ID_NUMBER
WHEN 0 THEN 'USER'
ELSE 'GROUP'
END AS PROFILE_TYPE,
A.*,
CAST(TEXT_DESCRIPTION AS VARCHAR(50) CCSID 1147)
AS TEXT_DESCRIPTION_CASTED
FROM (
SELECT *
FROM QSYS2.USER_INFO
) AS A
)
SELECT *
FROM USERS
""",
rows_to_fetch=500)
endT = datetime.now()
delta = endT - startT
print(f"Utilisateurs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframUsers = pd.DataFrame(result['data'])
#print(dframUsers)
print("Sauvegarde vers Excel")
with pd.ExcelWriter('/users/ericfroehlicher/Documents/donnes_dataframe.xlsx') as writer:
dframActj.to_excel(writer, sheet_name='ACTjobs')
dframUsers.to_excel(writer, sheet_name='Utilisateurs')
Un peu d’explications
1 – Import des resources dont on a besoin
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
2 – Déclaration des données de connexion (serveur, utilisateur, mot def passe)
CONSEIL: pour l’instant, toujours laisser le port 8076
Ici, on crée un travail simple, synchrone (SQLJob)
4 – les requêtes synchrones
#comptage des travaux (pour l'exemple de l'utilisation du json)
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
# je récupère directement la valeur lue
countjobs = result['data'][0]['TOTALTRAVAUX']
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
A
Les données obtenues sont au format JSON. (voir plus bas les données brutes)
5 – Insertion des données dans un frame PANDAS et sauvegarde vers EXCEL
#insertion des résultats dans un Frame PANDAS
dframe = pd.DataFrame(result['data'])
print(dframe)
print("Sauvegarde vers Excel")
dframe.to_excel(
"/users/ericfroehlicher/Documents/travaux_actifs.xlsx",
sheet_name="Travaux actifs",
index=False
)
Retour de mapepire
Le flux de données renvoyé par MAPEPIRE contient l’ensemble des données et méta données au format JSON.
Voici un extrait du flux retourné (exemple sur 5 travaux)
/wp-content/uploads/2017/05/logogaia.png00Eric Froehlicher/wp-content/uploads/2017/05/logogaia.pngEric Froehlicher2025-03-14 16:52:362025-03-14 16:52:37Générer des données avec MAPEPIRE en PYTHON
Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Présentation
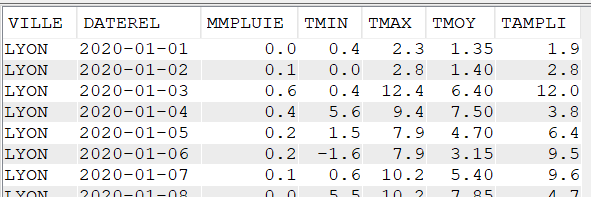
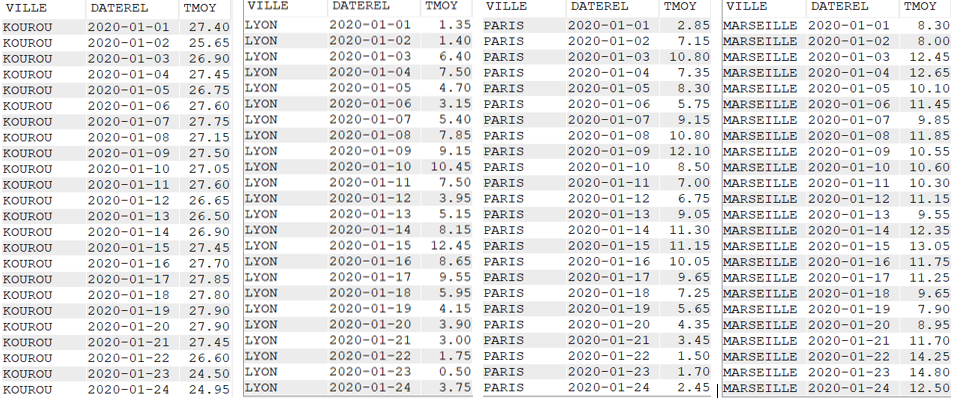
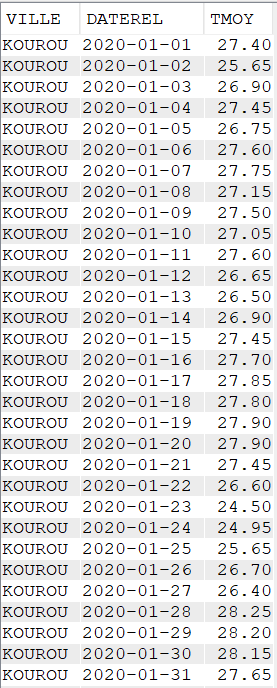
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
La ville
Le jour (AAAA-MM-JJ)
Les précipitations en mm
La température minimale du jour (en °C)
La température maximale du jour (en °C)
La température moyenne du jour (en °C)
L’amplitude de température du jour (en °C)
Agréger les données avec LISTAGG
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)
Données brutes
Données avec la fonction LISTAGG
Agréger les données avec GROUP BY
Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
SUM qui va nous permettre de faire le total des précipitations
MIN pour extraire la température minimale
MAX pour extraire la température maximale
AVG pour faire une moyenne (de la température ainsi que de l’amplitude des températures)
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
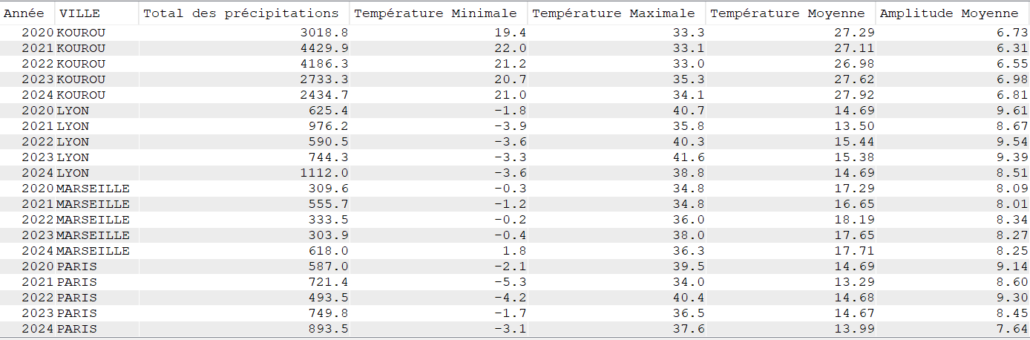
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";
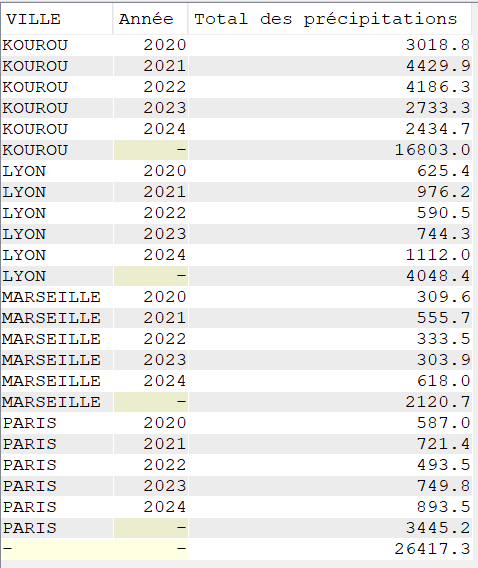
Utilisation de ROLLUP
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";
L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
VILLE / ANNEE
VILLE
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
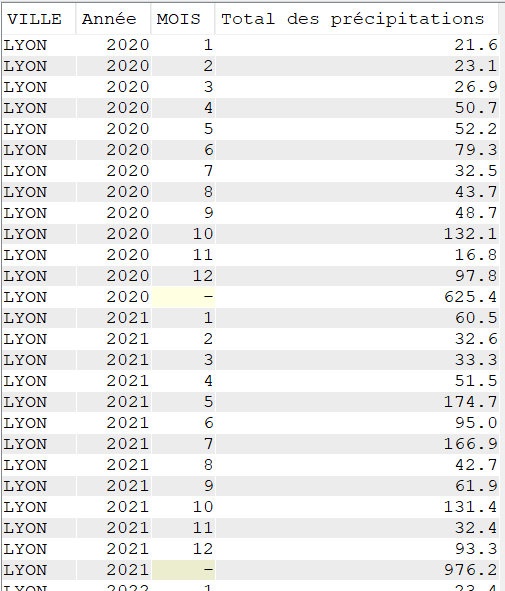
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));
…
…
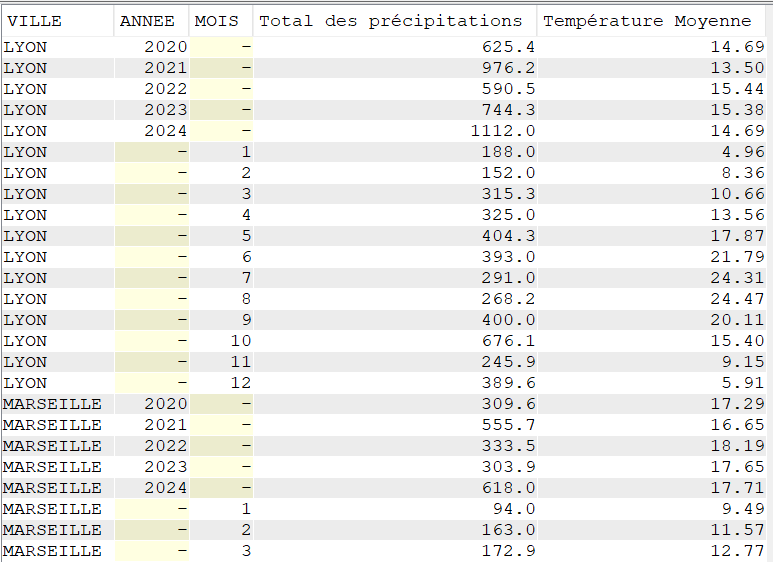
Utilisation de CUBE
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
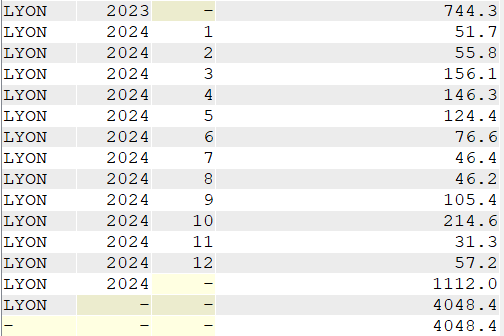
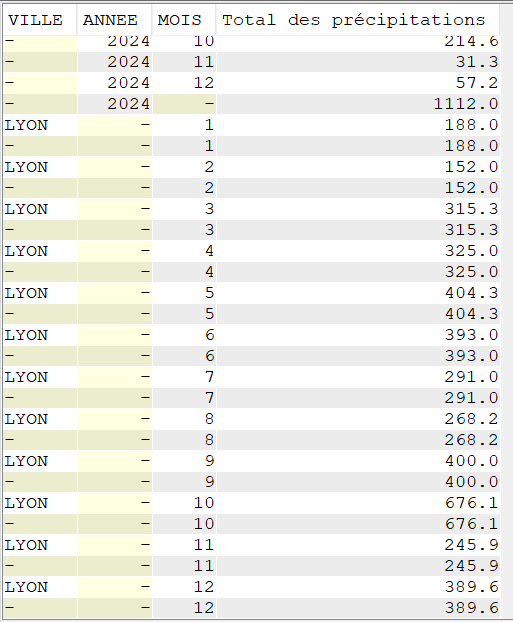
SELECT VILLE, YEAR(DATEREL) Annee, MONTH(DATEREL) Mois, SUM(MMPLUIE) "Total des précipitations" FROM CLIMAT WHERE VILLE = 'LYON' GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
Par VILLE et ANNEE
Par VILLE et sur la période de mesure
Sur la période de mesure (valeur identique à la précédente car une seule ville sélectionnée ici)
Par VILLE pour chaque mois de la période sélectionnée (ou simplement pour chaque mois de la période sélectionnée)
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Utilisation de GROUPING SETS
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);
Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
Tableau Croisé avec Agrégation et CASE
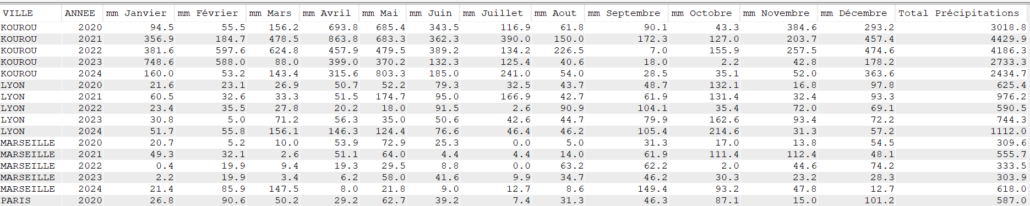
Avec SUM
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
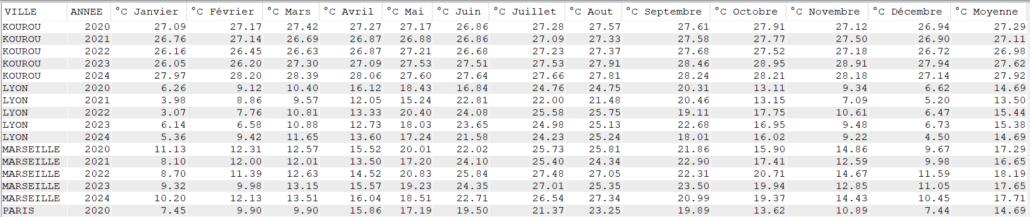
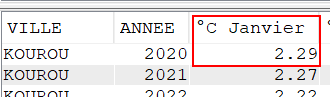
Avec AVG
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Note sur l’utilisation de SUM vs AVG dans un tableau croisé
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
Avec ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.
NULL est ignoré par AVG, garantissant une moyenne correcte.
Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)
Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)
Utiliser SQL pour faire une analyse
Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
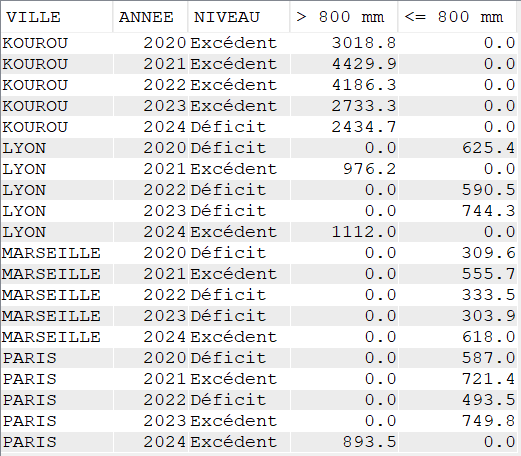
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL);
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2025-03-04 09:03:202025-03-04 09:28:33Regroupements et Analyses avec SQL
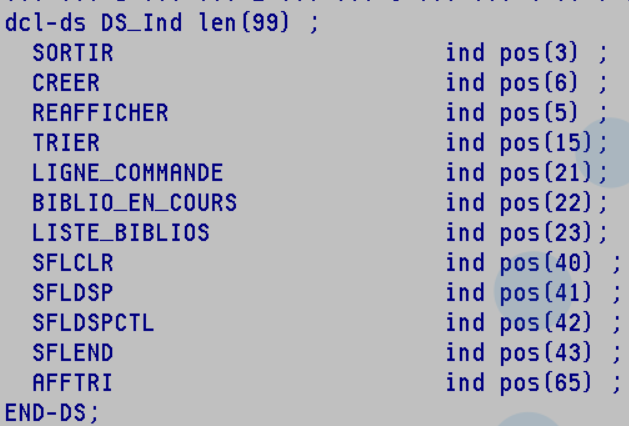
Les indicateurs font parti intégrante des développements RPG, c’est des booléens dont le nom commence par *IN, certain ont plus ou moins disparu (remplacé par des %EOF, %FOUND, ou un SQLCODE ) , mais les indicateurs *IN01 à *IN99 continuent à être utilisé par exemple dans les DSPF.
On va essayer de voir une méthode qui rendra le code plus lisible pour les jeunes recrues qui devront faire de la maintenance
On va prendre un exemple à partir d’un DSPF
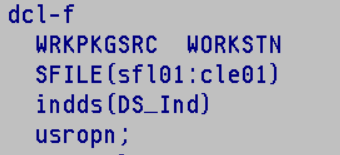
Votre écran devra avoir le mot clé INDARA qui indique qu’on va gérer les indicateurs dans un buffer séparé
Pour la déclaration de votre écran vous devrez lui indiquer le mot clé INDDS qui indiquera la DS qui contiendra le tableau de ces indicateurs.
voici un exemple de DS avec les indicateurs nommé
Exemple :
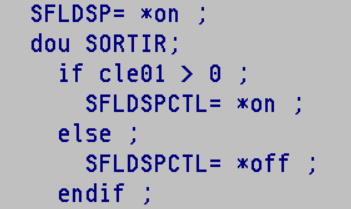
*IN03 / SORTIR
Voici ci dessus un exemple de code RPG FREE, utilisant les noms indiqués dans la DS, on voit tout de suite mieux ce qu’on fait
Remarque :
Vous pouvez mettre votre DS dans un include et le déclarer dans chaque programme , ce qui permettra d’uniformiser votre tableau des indicateurs
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-02-24 11:03:502025-02-25 09:31:53Nommez vos indicateurs en RPGLE
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2025-02-17 14:38:202025-02-17 14:44:48Gestion de l’état null dans les SQLRPGLE
Voici 5 fonctions qui peuvent vous intéresser pour manipuler des dates en SQL.
je vous rappelle que pour les utiliser, vos zones doivent être au format date et si ce n’est pas le cas vous devrez utiliser la fonction date pour vous mettre dans le format attendu Exemple : values date(‘2012-01-01’)
Il est fortement conseillé si manipulez des dates de vous mettre dans un format *ISO pour éviter les problèmes de bascule des dates à 6 positions
1) Vous avez besoin de connaitre le premier jour du mois Vous avez la fonction FIRST_DAY() values FIRST_DAY(‘2012-12-12’) ; renverra 2012-12-01
pour le jour en cours FIRST_DAY(current date) = current date
2) Vous avez besoin de connaitre le dernier jour du mois Vous avez la fonction LAST_DAY() values LAST_DAY(‘2012-12-12’) ; renverra 2012-12-31
Pour le jour en cours LAST_DAY(current date) = current date
3) Vous voulez connaitre le numéro du jour dans l’année , le rang julien Vous avez la fonction DAYOFYEAR()
values DAYOFYEAR(‘2012-12-12’) renverra 347
4) Connaitre le jour de la semaine Vous avez la fonction DAYOFWEEK() elle vous renverra un numéro de 1 à 7 qui est le numéro du jour dans la semaine attention 1 c’est le dimanche values DAYOFWEEK(‘2012-12-12’) vous renverra 4 Si vous voulez commencer le lundi values DAYOFWEEK(‘2012-12-12’) – 1 , attention bien sur, un dimanche vous aurez 0
5) Connaitre le nombre de jours depuis le premier janvier 01
Vous avez la fonction DAYS()
values DAYS(‘2012-12-12’) renverra 734849 Cette fonction sert souvent pour calculer le nombre de jours entre 2 dates
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-01-27 10:42:242025-01-28 10:21:085 Astuces SQL sur les dates
Voici comment visualiser l’historique d’une macro-commande Arcad
Objectifs :
Lorsqu’une macro-commande se termine en anomalie, la joblog peut ne pas être toujours évidente à décrypter ou pire elle peut avoir été supprimée.
Cet article a pour objectif de présenter process à suivre pour pouvoir visualiser chaque étape d’exécution d’une macro-commande Arcad.
Pour cela il faut :
Retrouver l’instance de la macro commande à analyser
Afficher l’historique de l’instance à analyser
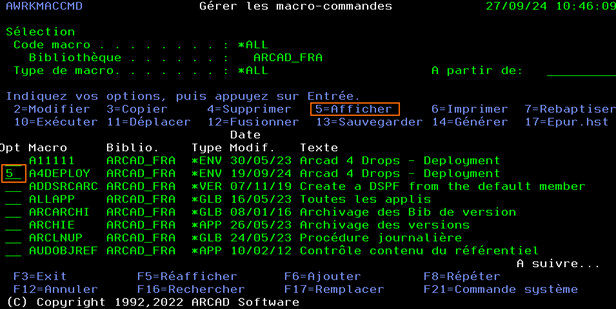
1) Recherche de l’instance de la macro-commande à analyser :
Lancer la commande AWRKMACCMD pour accéder à la liste des macro-commandes Arcad.
Lancer l’option 5 AFFICHER sur la macro-commande concernée.
Une fois la macro-commande affichée :
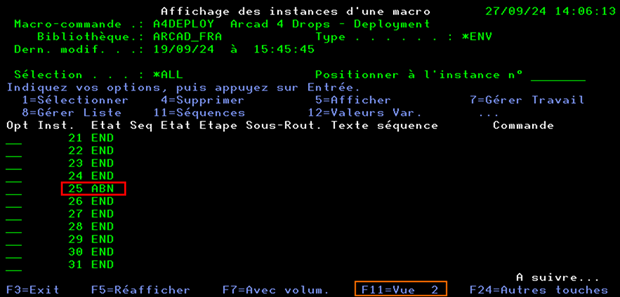
Faire F9 pour afficher toutes les instances de lancement de la macro-commande
La liste des instances d’exécution de la macro-commande s’affiche.
Dans l’exemple ci-dessus on voit que la 25eme instance n’a pas abouti (Etat à ABN = Abandon).
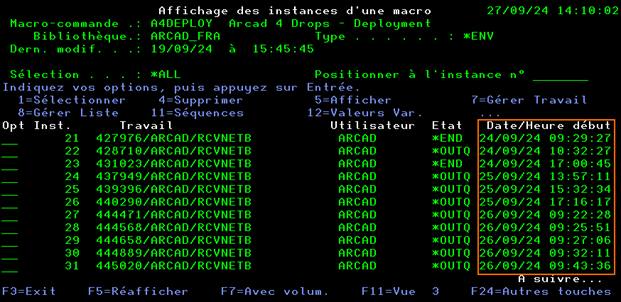
La touche F11 permet de changer de vue et ainsi afficher les dates de traitement, cela facilite l’identification précise de l’instance à analyser.
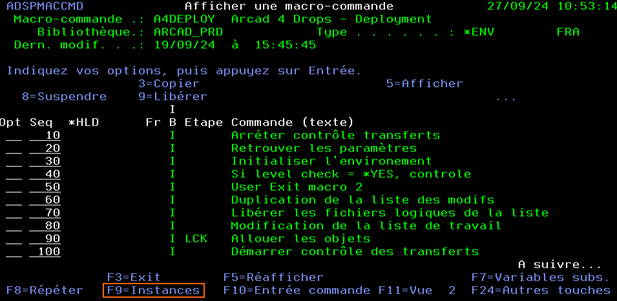
2) Afficher l’historique de l’instance à analyser
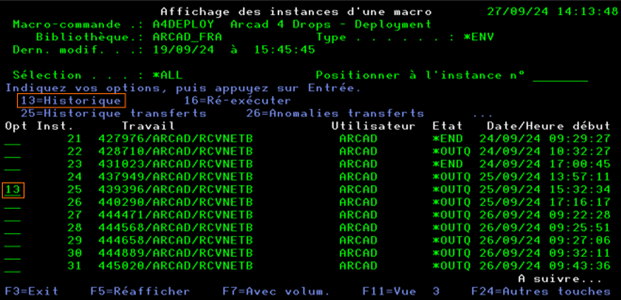
Lancer l’option 13 (Historique) sur l’instance à analyser
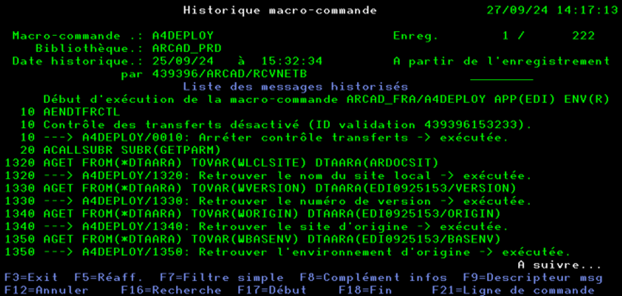
L’historique des commandes de la macro-commande sera alors affiché
Pour rappel :
Les lignes en rouge correspondent aux alertes Arcad Attention : ce ne sont pas toujours des anomalies.
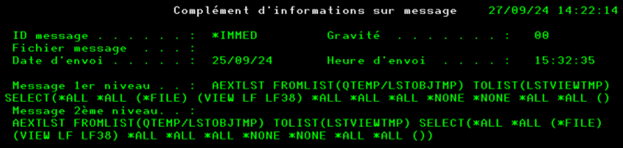
La touche F8 permet d’afficher l’intégralité de la commande Arcad sur laquelle est positionné le curseur. Cela permet de visualiser toute la commande avec tous ses paramètres
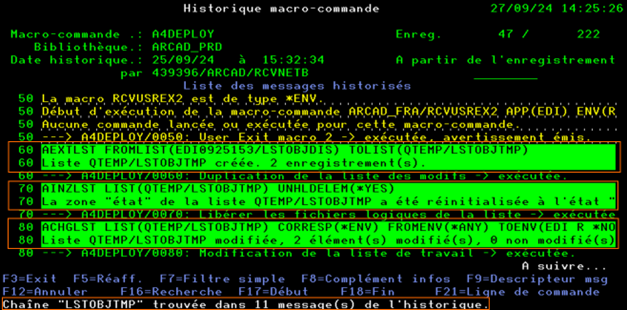
La touche F16 permet de rechercher une chaine de caractères dans l’ensemble des commandes affichées. Les lignes contenant la chaine de caractères recherchées seront affichées en surbrillance.
Le nombre d’occurrences trouvées sera affiché en bas de l’écran.