Vous avez un nouveau paramètre sur les commandes CRTBNDRPG ou CRTRPGMOD DATEYY( )
DATE WITH 2-DIGIT YEARS . . . . DATEYY( *ALLOW)
Ce paramètre n’est pas encore documenté dans l’aide mais vous comprenez , que c’est pour les dates sur 6 caractères
Rappel sur les dates à 6 , vous avez un point de bascule: 40 – 99 : Le siècle est supposé être « 19 » 00 – 39 : Le siècle est supposé être « 20 »
C’est dans 14 ans
Pour ce paramètre, DATEYY vous avez 3 valeurs possibles
DATEYY(*ALLOW) : autorise tous les formats de date, autrement dit, n’effectue aucune validation. DATEYY(WARN) : si une date est détectée, elle est considérée comme une année sur deux caractères, une erreur de compilation de niveau 10 est générée. DATEYY(*NOALLOW) : si une date pourrait être détectée, la compilation est renvoyée avec une erreur de niveau 30. La valeur par défaut est « *ALLOW ».
il est conseillé de compiler avec *WARM, vous aurez une liste des problèmes potentiels
Ce message apparaitra
Msg id Sv Number Seq Message text *RNF0201 10 5 002300 WARNING: A DATE WITH 2 DIGITS FOR THE YEAR ONLY SUPPORTS THE YEARS 1940 TO 2039. REASON CODE: xxxxxx.
Rappel: Pensez dans SQL à bien utiliser des formats sur 8 *ISO par exemple pour tous vos calculs
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-18 16:42:512025-08-20 11:32:37V7R6 , date sur 6 positions en RPG
Vous voulez changer le groupe d’activation d’un programme. Contrairement à une idée reçue, on peut dans certains cas renommer le groupe d’activation d’un programme ILE
Si vous créez un programme
CRTPGM
Ou
CRTBNDRPG
Vous allez indiquer le groupe d’activation d’exécution de votre programme
Vous ne pouvez pas changer le groupe d’activation par CHGPGM !
Mais vous pouvez le faire par la commande UPDPGM
avant ==> DSPPGM AATSTRET
Attribut du groupe d’activation . . . . . . . : PLB1
UPDPGM PGM(AATSTRET) MODULE(*NONE) ACTGRP(PLB45)
Valeurs des paramètres AUT et USRPRF ignorées.
L’objet remplacé AATSTRET type *PGM a été déplacé dans QRPLOBJ.
Programme AATSTRET créé dans la bibliothèque GDATA.
Programme AATSTRET mis à jour dans GDATA.
après ==>DSPPGM AATSTRET
Attribut du groupe d’activation . . . . . . . : PLB45
la seule limitation est que le groupe doit être nommé
Pour interdir ce changement à l’assemblage vous devez indiquer
CRTPGM … ALWUPD(*NO)
PS :
Cette option n’existe pas sur le CRTBNDRPG donc modifiable par défaut
Vous devez avoir le droit *change sur programme.
Rappel:
En batch on essaye d’avoir le premier programme qui crée le groupe d’activation et les programmes appelés s’exécuteront en *caller
Dans les autres cas, webservice, interactif, etc il peut être préférable d’avoir un groupe d’activation par programme
Pour analyser les groupes actifs, vous pouvez utiliser le service : QSYS2.ACTIVATION_GROUP_INFO
— Liste des groupes par Travail
SELECT A.JOB_NAME,
count(*)
FROM TABLE (
QSYS2.ACTIVE_JOB_INFO()
) AS A
LEFT JOIN TABLE (
QSYS2.ACTIVATION_GROUP_INFO(JOB_NAME => A.JOB_NAME)
) AS G
ON 1 = 1
group by A.JOB_NAME
ORDER BY count(*) desc
;
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-13 11:29:572025-08-19 13:54:43Changer le groupe d’activation d’un programme
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-04 10:53:552025-08-04 10:53:56V7R6, la liste des commandes supprimées
Vous avez une instruction SQL , MERGE qui est assez PUISSANTE pour fusionner des fichiers Voici un exemple complet :
Il intègre les éléments suivants -La création -La mise à jour -La suppression
On a 2 tables Products et Mouvements
Les règles choisies sont les suivantes :
-Si le produit existe on ajoute la quantité -S’ il est nouveau, on le créé -Si nom du produit est SUPPRESSION, on supprime
J’ai utilisé la convention de nommage *SYS
et dans tous les cas on met à jour la date de modification
-- voici les scripts pour tester
-- Création de la table des produits
-- Option *SYS et *NONE
CREATE TABLE GDATA/PRODUCTS (
PRODUCT_NUMBER DECIMAL(10, 0) NOT NULL ,
PRODUCT_NAME VARCHAR(100) NOT NULL,
QUANTITY DECIMAL(10, 0) NOT NULL DEFAULT 0,
LAST_UPDATE_TS TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (PRODUCT_NUMBER)
);
-- alimentation du fichier
INSERT INTO GDATA/PRODUCTS VALUES(1, 'CLOU', 50, current timestamp) ;
INSERT INTO GDATA/PRODUCTS VALUES(2, 'VIS', 20, current timestamp) ;
INSERT INTO GDATA/PRODUCTS VALUES(3, 'ECROU', 25, current timestamp) ;
INSERT INTO GDATA/PRODUCTS VALUES(4, 'RONDELLE', 120, current timestamp) ;
-- Création de la table des mouvements
CREATE TABLE GDATA/MOUVEMENTS (
PRODUCT_NUMBER DECIMAL(10, 0) NOT NULL ,
PRODUCT_NAME VARCHAR(100) NOT NULL,
QUANTITY DECIMAL(10, 0) NOT NULL DEFAULT 0,
LAST_UPDATE_TS TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (PRODUCT_NUMBER)
);
-- alimentation de la tables des mouvements
INSERT INTO GDATA/MOUVEMENTS VALUES(1, 'CLOU', 30, current timestamp) ; -- changement de quantité
INSERT INTO GDATA/MOUVEMENTS VALUES(3, 'SUPPRESSION', 0, current timestamp) ; -- suppression
INSERT INTO GDATA/MOUVEMENTS VALUES(5, 'RESSORT', 100, current timestamp); -- Nouveau
-- Fusion des 2 tables
MERGE INTO GDATA/PRODUCTS AS T -- T est l'alias de la table CIBLE (PRODUCTS)
USING GDATA/MOUVEMENTS AS S -- S est l'alias de la table SOURCE (MOUVEMENT)
ON (T.PRODUCT_NAME = S.PRODUCT_NAME) -- La jointure se fait sur le nom du produit
-- 1. Gérer la suppression si le produit correspond ET que la source indique 'SUPPRESSION'
WHEN MATCHED AND S.PRODUCT_NAME = 'SUPPRESSION' THEN
DELETE
-- 2. Gérer la mise à jour si le produit correspond ET que la source N'indique PAS 'SUPPRESSION'
WHEN MATCHED AND S.PRODUCT_NAME <> 'SUPPRESSION' THEN
UPDATE SET T.QUANTITY = T.QUANTITY + S.QUANTITY,
T.LAST_UPDATE_TS = CURRENT_TIMESTAMP
-- 3. Gérer l'insertion si le produit NE correspond PAS ET que la source N'indique PAS 'SUPPRESSION'
WHEN NOT MATCHED AND S.PRODUCT_NAME <> 'SUPPRESSION' THEN
INSERT (PRODUCT_NUMBER, PRODUCT_NAME, QUANTITY, LAST_UPDATE_TS)
VALUES (S.PRODUCT_NUMBER, S.PRODUCT_NAME, S.QUANTITY, CURRENT_TIMESTAMP);
Remarque :
Vous pouvez également utiliser la commande CPYF avec le paramètre MBROPT(*UPDADD) mais plus compliqué de gérer les suppressions.
En SQL embarquée la gestion des erreurs est différente par rapport à un RPGLE classique.
Essentiellement sur 2 points
1) Ca ne plante pas Vous pouvez donc avoir des erreurs silencieuses Il est très important de traiter les SQLCODE Même si vous pensez ne pas en avoir besoin Les 3 lignes suivantes peuvent être ajoutées sans risque !
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-07-12 09:07:372025-07-12 09:09:04Gestion du SQLCODE dans un SQL embarqué
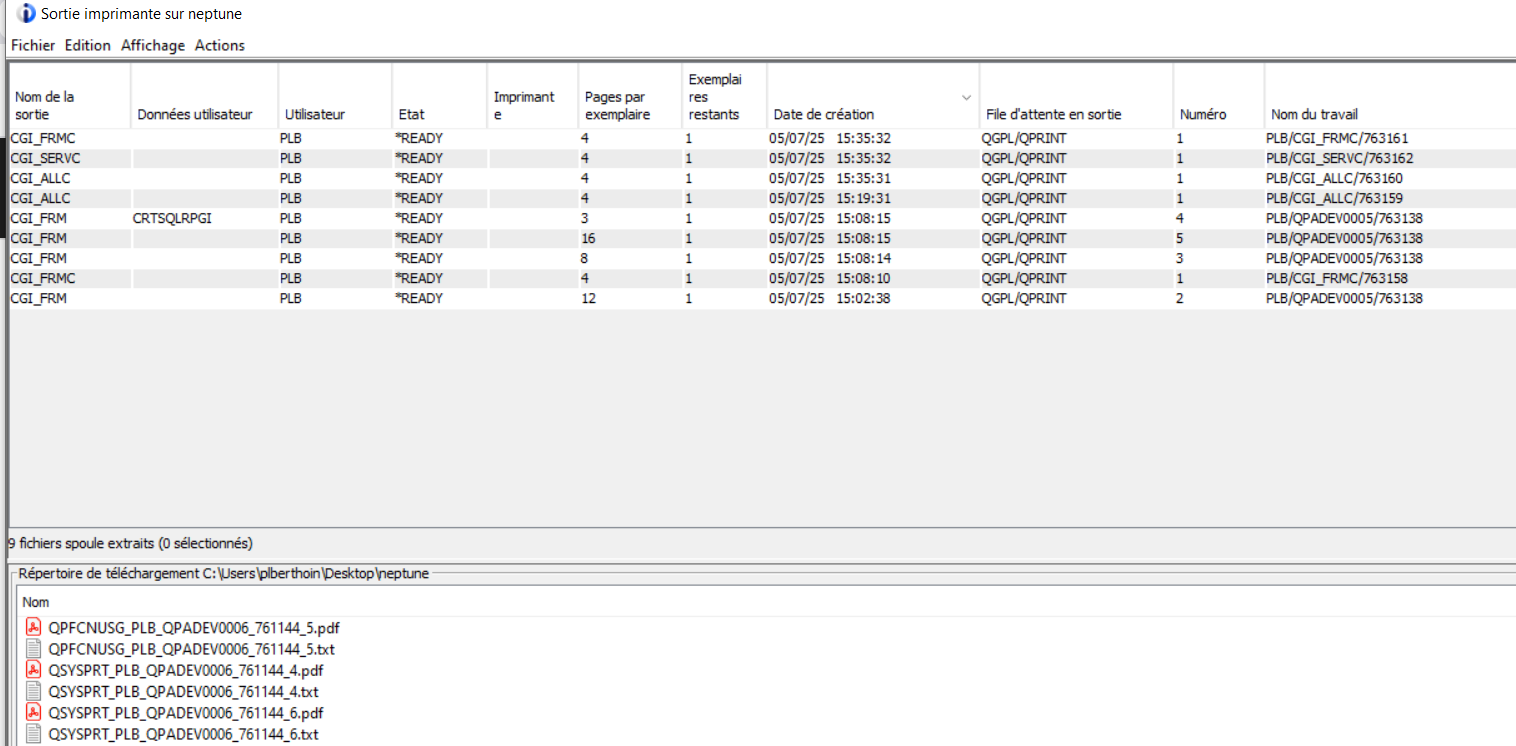
Vous connaissez l’option ACS qui vous permet de gérer vos SPOOLs , c’est une alternative intéressante à la commande WRKSPLF et si vos utilisateurs ont beaucoup de spools à gérer, ca peut leurs simplifier la tache, n’hésitez pas à leurs donner l’option, c’est relativement intuitif .
Vous pouvez par exemple faire simplement un fichier PDF et le joindre à un mail .
Vous voulez simplifiez la vie de vos utilisateurs en leurs présentant cette option à la place d’un WRKSPLF dans vos applications existantes
Voici une ébauche de solution
Un programme de lancement
Vous devrez d’abord écrire un programme qui lance l’option ACS à partir de votre programme IBMi à base des commandes STRPCO et STRPCCMD
Voici un exemple RPGLE
**free
// Ce programme permet de remplacer les commandes WRKSPLF par
// L'explorateur de spool ACS
// ici le javabundle est dans \Users\Public\IBM\ClientSolutions\
//
dcl-s cmd CHAR(1024) ;
// démarrage de PCO
cmd ='STRPCO' ;
exec sql call qsys2.qcmdexc(:cmd) ;
// Démarrage de l'explorer de spools
cmd =' +
STRPCCMD PCCMD(''java -jar C:\Users\Public\IBM\ClientSolutions\acsbundle.jar +
/PLUGIN=splf /system=neptune +
Picked up _JAVA_OPTIONS: -Djava.net.preferIPv4Stack=true'') PAUSE(*NO)' ;
exec sql
call qsys2.qcmdexc(:cmd) ;
*inlr= *on ;
On a fixé le répertoire du programme ici \Users\Public\IBM\ClientSolutions\
Si vous lancez ce programme, vous ouvrez alors l’écran ACS de gestion des spools, il est possible que cela vous redemande le mot de passe en fonction de votre paramétrage.
Un programme pour Associer à la commande WRKSPLF
Si vous voulez automatiser, vous pouvez utiliser un programme d’exit sur l’exit point QIBM_QCA_CHG_COMMAND
Vous avez la commande ADDEXITPGM pour ajouter un programme d’exit , vous pouvez également passer par la commande ==>WRKREGINF et faire l’option 8
Remarque :
Vous pouvez comme ici mettre une commande WRKSPLF dans une bibliothèque avant QSYS, qui vous permettra de bien gérer que les interactifs et de bypasser si besoin en faisant ==>QSYS/WRKSPLF .
Vous aurez intérêt a identifier les utilisateurs qui doivent bénéficier de la fonctionnalité, une solution très simple c’est l’utilisation d’une liste d’autorisation
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-07-05 16:06:412025-07-07 11:22:16Gestion des spools par ACS
Nous sommes de plus en plus nombreux à utiliser Code for IBM i !
Nous avons de nombreuses questions sur cet outil, en constante évolution.
Cette semaine, nous avons choisi de parler des profils, et de la confusion entre le profiles Visual Studio Code et les profils Code for IBM i.
Et les profils IBM i ?
Nous n’en parlerons pas ici !
Un profil IBM vous permet de vous connecter à la machine et n’existe que côté serveur.
La notion de profils dans Visual Studio Code (noté VSCode pour la suite) concerne la configuration des environnements de travail dans l’IDE.
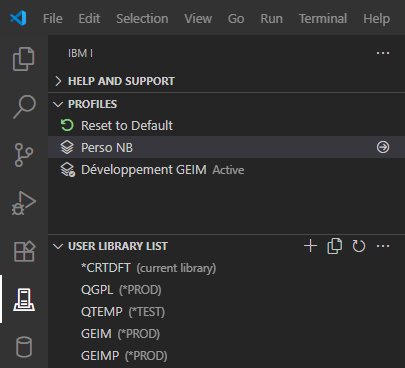
Profil Code for IBM i
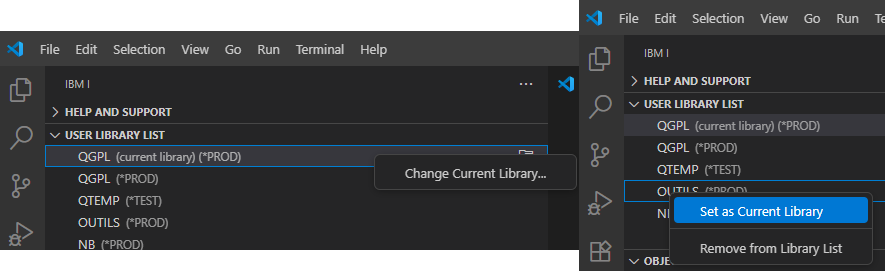
A la connexion à votre IBM i, VSCode établi une communication via un job SSH. Ensuite, l’interface propose plusieurs éléments de configuration et de navigation :
User Library List (partie utilisateur de la liste de bibliothèque) + current library (bibliothèque en cours)
Object browser (filtres sur objets / membres)
IFS shortcuts (filtres sur répertoires / fichiers)
Une fois connecté, la liste de bibliothèque affichée est celle utilisée à votre dernière connexion.
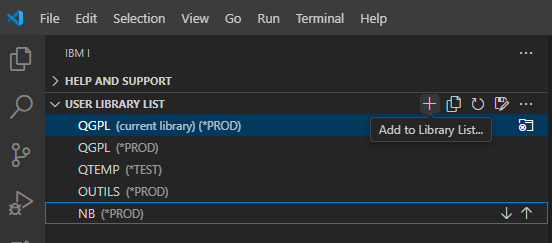
Vous pouvez modifier la bibliothèque en cours par click droit sur current library (ouvre un prompt) ou sur click droit sur une bibliothèque à définir comme en cours :
De même pour la liste de bibliothèque : ajout / suppression / réorganisation :
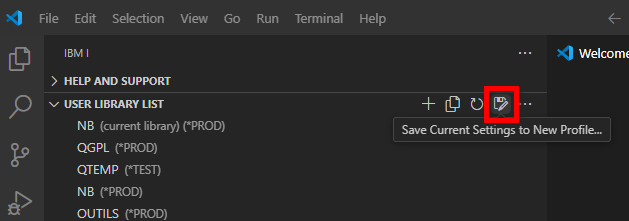
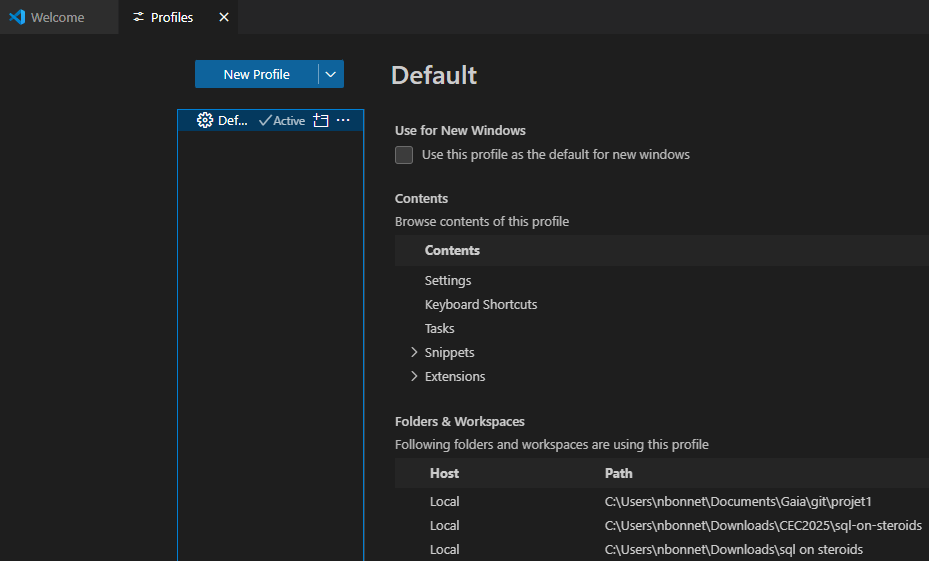
Une fois votre environnement configuré, la sauvegarde sous forme de profil vous permet de mémoriser cette configuration et de pouvoir revenir dessus plus rapidement par la suite :
Donner un nom à l’enregistrement :
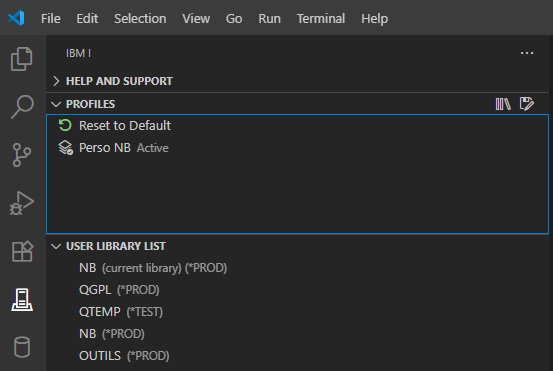
Une nouvelle option de gestion des profils est alors affichée :
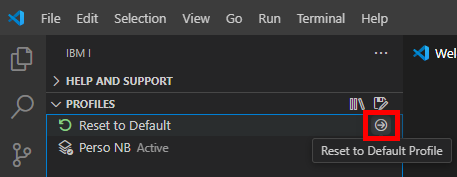
Elle vous permet de revenir à la situation d’origine de votre profil (si vous avez ajouter/supprimer des bibliothèques par exemple) :
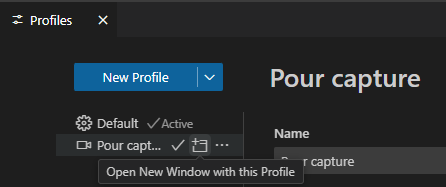
Mais surtout vous pouvez créer d’autres profils, correspondants à d’autres situations :
Développement projet 1
Développement projet n …
Tests projet 1
Production
…
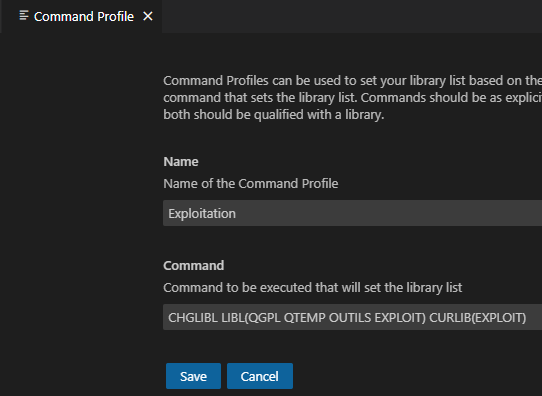
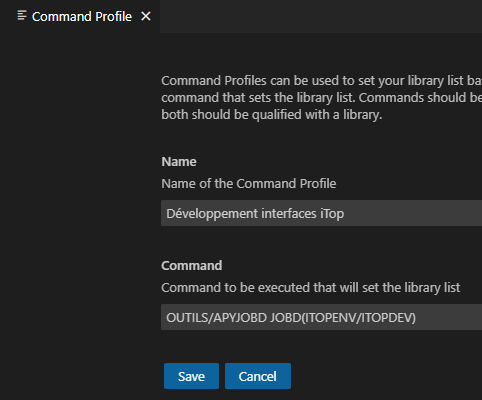
Vous pouvez aussi créer un profil directement en indiquant une commande de mise en place de l’environnement, basiquement un CHGLIBL :
Pour plus de souplesse, surtout lors de travail en équipe, nous vous conseillons de créer une *JOBD par « projet » côté serveur, avec une commande qui met en place les bibliothèque de la *JOBD. Cela vous permet de modifier la *JOBD sans intervenir sur l’ensemble des clients :
En réalité, le profil permet de stocker l’ensemble des éléments suivants :
Le profil Visual Studio Code vous permet d’avoir plusieurs configurations de VSCode avec une installation unique : des attributs de l’environnement peuvent être modifiés via un fichier de configuration.
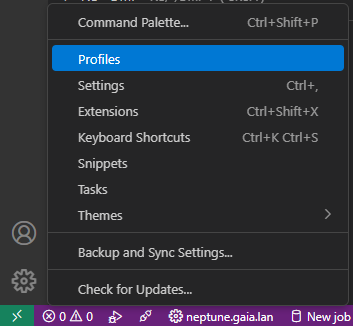
Depuis le menu des paramètres, aller dans les profils :
Nous pouvons alors gérer les profils, en créer/supprimer, modifier les attributs :
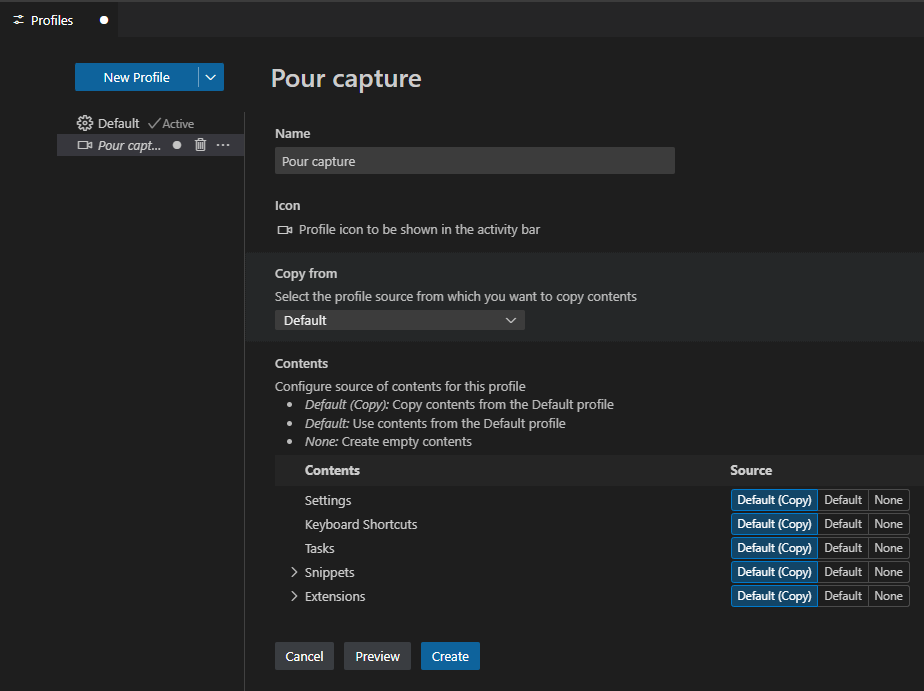
Il est par exemple possible de créer un profil :
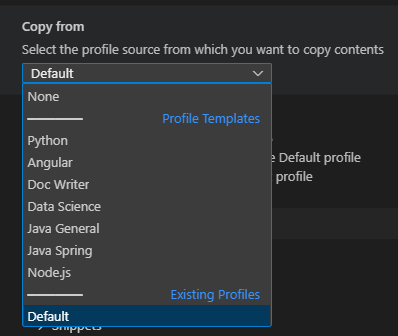
Par copie d’un profil existant, ou totalement vide. Et lors de la copie, vous choisissez les éléments de paramétrages, de personnalisation de clavier etc … Une icône spécifique peut être attribuée pour identifier rapidement les profils.
Certains profils types sont également fournis :
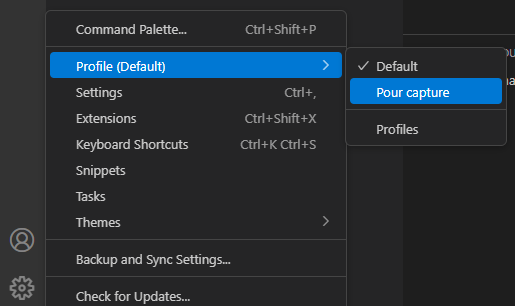
Une fois le profil créé, vous pouvez passer de l’un à l’autre :
Ou bien ouvrir une autre fenêtre avec un profil différent :
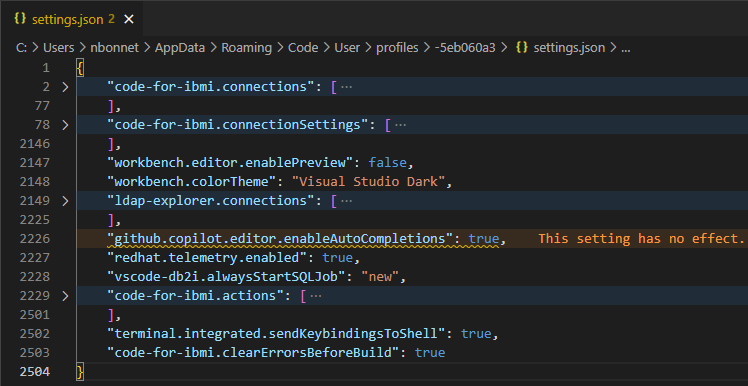
Depuis les propriétés du profil, les différentes catégories (Settings, keyboard shortcuts etc …) correspondent à des fichiers de configuration différents. Lorsque vous double-cliquer sur « Settings » :
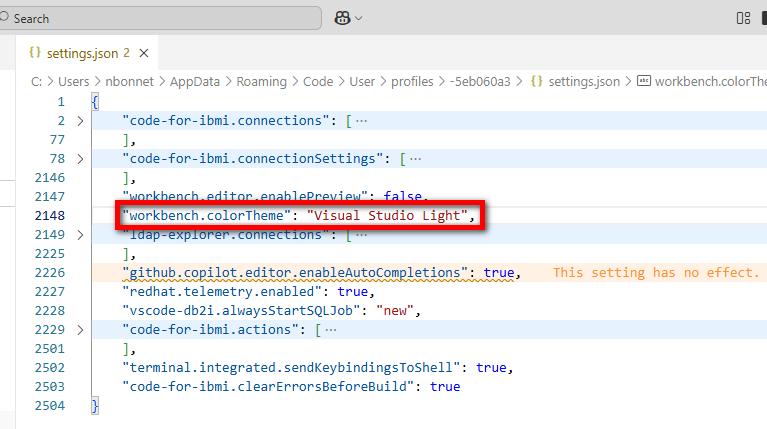
Vous pouvez modifier les propriétés en direct, le changement est pris en compte à l’enregistrement du fichier :
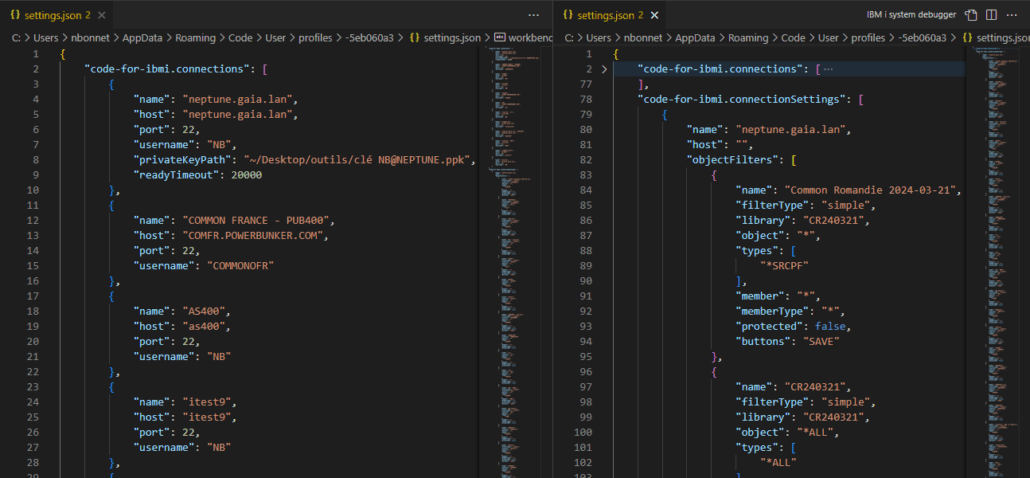
Vous remarquez que l’ensemble des informations des profils Code for IBM i sont stockés ici, dans les profils Visual Studio Code :
Vous pouvez donc facilement éditer, modifier, échanger (regarder les options d’import/export) toutes les configurations afférentes.
Avec un peu d’habitude, vous pouvez ouvrir différentes instances pour différents usage.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-06-23 22:04:512025-06-23 22:04:52Visual Studio Code et Code for IBM i : profils
Dans une base de données bien définie, nos enregistrements sont identifiés par des clés (ie unique). Il existe toutefois différentes façon de matérialiser ces clés en SQL.
Première bonne résolution : on ne parlera pas ici des DDS (PF/LF) !
Quelques rappels
je n’insiste pas, mais une base de donnée relationnelle, DB2 for i dans notre cas, fonctionne à la perfection, à condition de pouvoir identifier nos enregistrements par des clés.
Une normalisation raisonnable pour une application de gestion est la forme normale de Boyce-Codd (dérivée de la 3ème FN).
Clés
Vous pouvez implémenter vos clés de différentes façons, voici une synthèse :
Type
Où
Support valeur nulle ?
Support doublon ?
Commentaire
Contrainte de clé primaire
Table
Non
Non
Valeur nulle non admise, même si la colonne clé le supporte
Contrainte d’unicité
Table
Oui
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Index unique
Index
Oui
Non
Gère des clés uniques. La valeur NULL est supportée pour 1 unique occurrence
Index unique where not null
Index
Ouis
non : valeurs non nulles oui : valeurs nulles
Gère des clés uniques uniquement si non nulles
Attention donc à la définition de UNIQUE : à priori ce qui n’est pas NULL est UNIQUE.
Concrètement ?
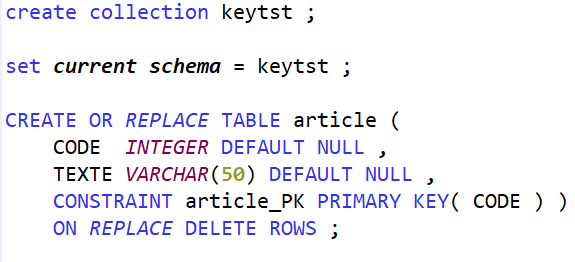
Prenons un cas de test simpliste pour montrer la mécanique : un fichier article avec une clé et un libellé
Clé primaire
La colonne CODE admet des valeurs nulles, mais est fait l’objet de la contrainte de clé primaire.
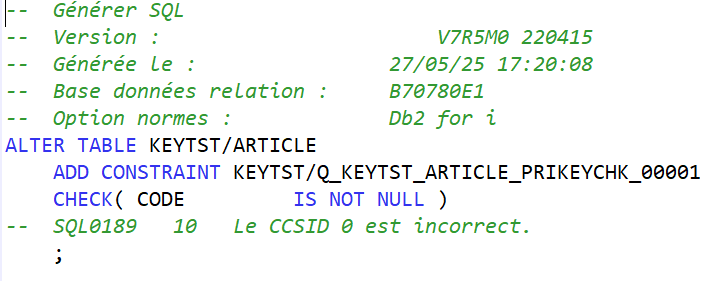
A la création de la contrainte de clé primaire, le système créé automatiquement une contrainte de type CHECK pour interdire l’utilisation de valeur nulle dans cette colonne :
Avec :
La clé primaire joue son rôle avec des valeurs non nulles :
Et des valeurs nulles :
On retrouve ici le nom de la contrainte générée automatiquement !
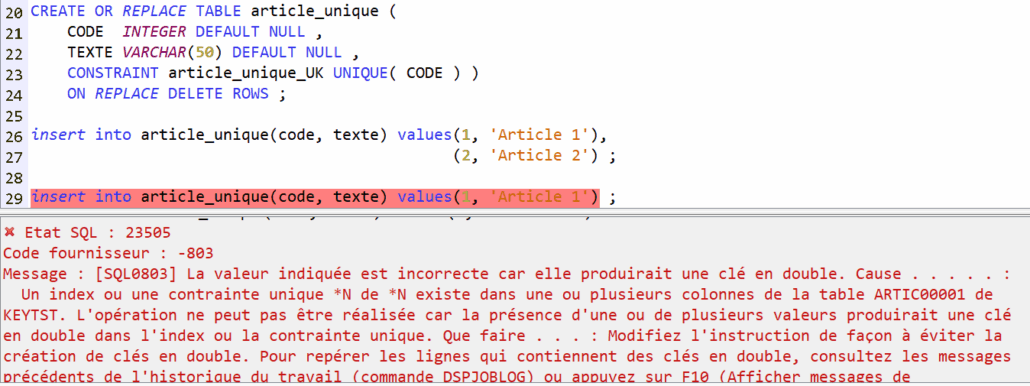
Avec une contrainte de clé unique ?
Le comportement est identique sur une clé non nulle.
Mais avec une clé nulle (ou dont une partie est nulle si elle composée) :
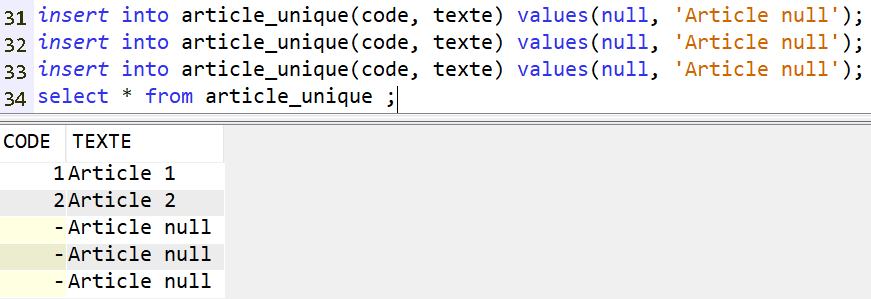
On peut ajouter un index unique pour gérer le problème. Dans ce cas, une et une seule valeur nulle sera acceptée :
Mais dans ce cas pourquoi ne pas utiliser une clé primaire ??
Clé étrangère, jointure
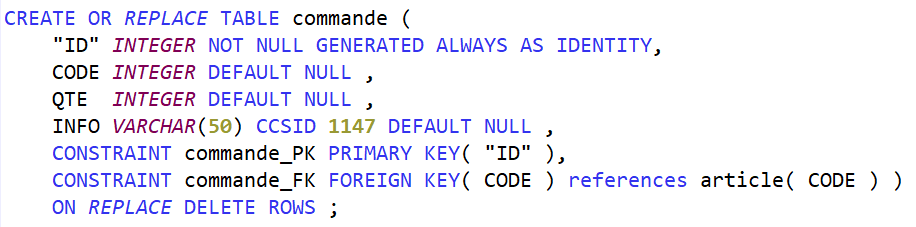
Ajoutons un fichier des commandes, ici une simplification extrême : 1 commande = 1 article.
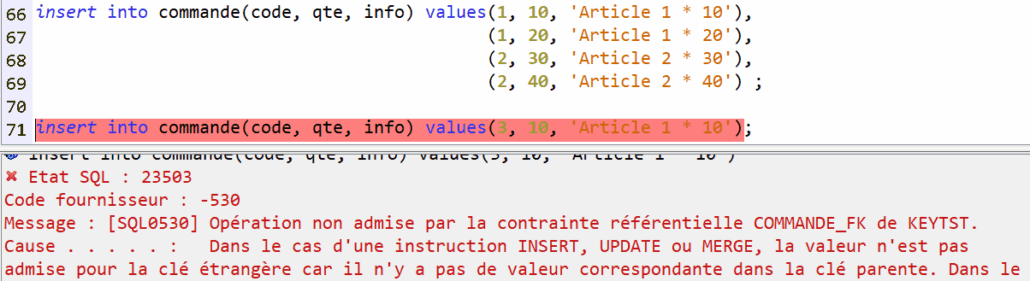
On ajoute une contrainte de clé étrangère qui matérialise la relation entre les tables commande et article. Pour cette contrainte commande_FK, il doit exister une contrainte de clé primaire ou de clé unique sur la colonne CODE dans la table article.
La contrainte se déclenche si l’article référencé n’existe pas :
Cas identique mais en s’appuyant sur la table article_unique qui dispose d’une clé unique et non primaire :
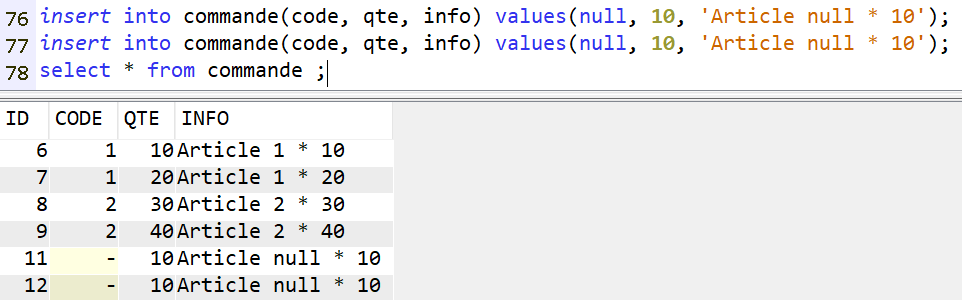
Dans ce cas les valeurs nulles sont supportées, en multiples occurrences (sauf à ajouter encore une fois un index unique au niveau de la commande).
Récapitulons ici nos données pour comprendre les jointures :
Démarrons par ARTICLE & COMMANDE :
La table ARTICLE ne peut pas avoir de clé nulle, donc pas d’ambiguïté ici
Avec right join ou full outer join nous accèderons au lignes de commande pour lesquelles CODE = null.
C’est le comportement attendu.
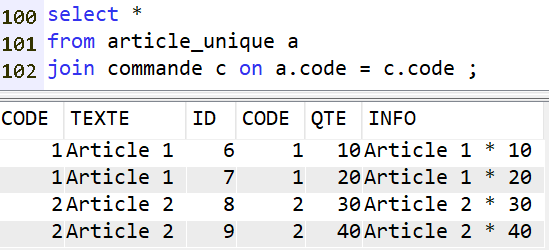
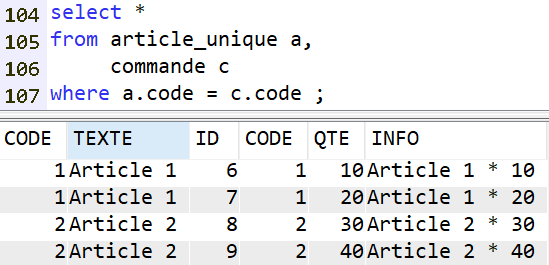
Voyons avec ARTICLE_UNIQUE et COMMANDE :
Ici on pourrait s’attendre à obtenir également les lignes 11 et 12 de la table COMMANDE : le CODE est nulle pour celles-ci, mais il existe une ligne d’ARTICLE pour laquelle le code est null. Il devrait donc y avoir égalité.
En réalité les jointures ne fonctionnent qu’avec des valeurs non nulles
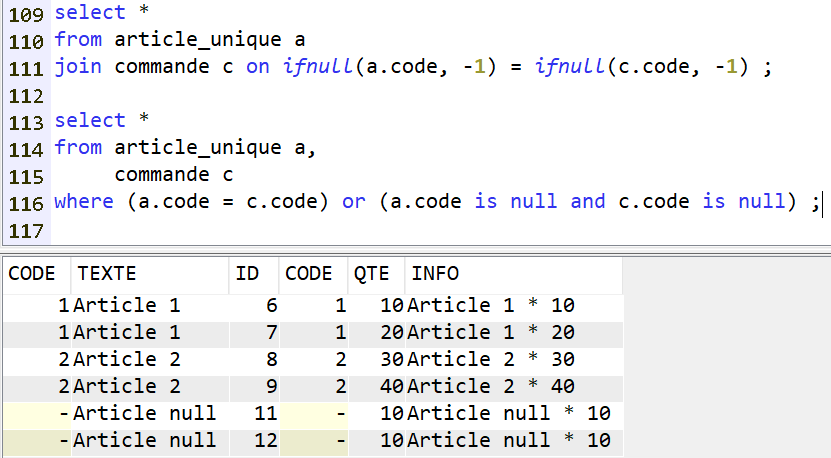
De même que la clause WHERE :
Il faut donc utiliser ce style de syntaxe :
C’est à dire :
soit remplacer les valeurs nulles par des valeurs inexistantes dans les données réelles
soit explicitement indiquer la condition de nullité conjointe
Bref, syntaxiquement cela va rapidement se complexifier dans des requêtes plus évoluées.
Clé composée
Evidemment, c’est pire ! Imaginons que l’on ait une clé primaire/unique dans la table ARTICLE composée de 2 colonnes (CODE1, CODE2), et donc présentes toutes les deux dans la table COMMANDE :
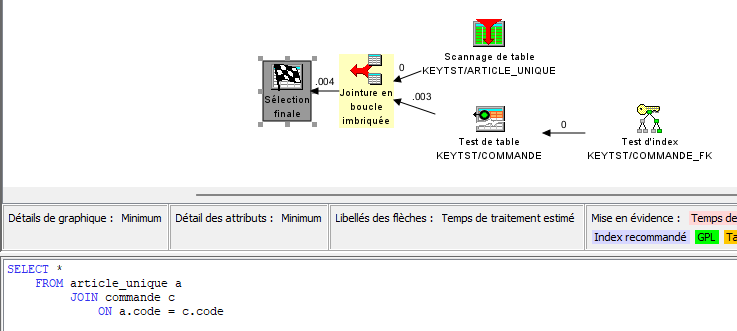
Et les performances ?
En utilisant la jointure, l’optimiseur est capable de prendre en charge des accès par index :
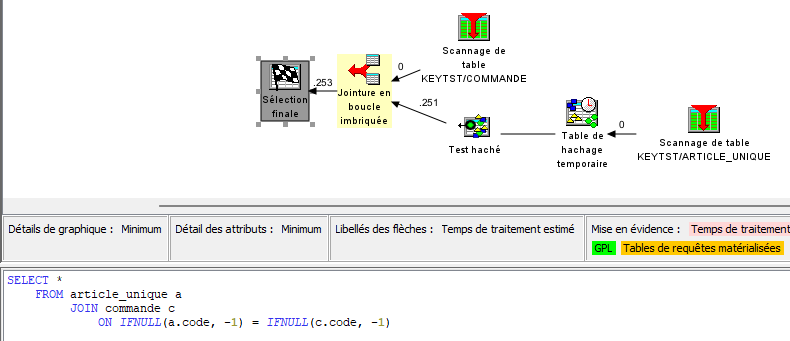
Mais en utilisant IFNULL/COALESCE, ces valeurs deviennent des valeurs calculées, ce qui invalide l’usage des index :
Ce n’est donc pas viable sur des volumes plus importants. Il existe des solutions (index dérivés par exemple) mais la mécanique se complique encore !
Préconisations
De façon générale pour vos données de gestion, en excluant les fichier de travail (QTEMP a d’autres propriétés), les fichiers de logs, les fichier d’import/export …
Pas de valeur NULL dans vos clés
Pour les clés atomique c’est une évidence, pour les clés composées c’est beaucoup plus simple
Une contrainte de clé primaire pour toutes vos tables !
N’hésitez pas à utiliser des clés auto-incrémentées
Des contraintes d’unicités ou des index uniques pour vos autres contraintes d’unicité, techniques ou fonctionnelles
Pas d’excès, sinon il y a un défaut de conception (cf les formes normales)
Si possible des contraintes de clé étrangère pour matérialiser les relations entre les tables
Délicat sur l’existant, les traitements doivent tenir compte du sens de la relation
Favorisez l’usage des clés, contraintes et index par l’optimiseur
Scalabilité entre vos environnements de développement/test et la production
Cela permet de revenir sur le principe de l’implémentation via du code RPG :
Le code est basé sur les APIs QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
Le moteur DB2 appelle l’implémentation :
1 appel initial
1 appel par poste de liste à retourner
1 appel final
Nous utilisons __errno pour retrouver les codes erreur de l’APIs. Les différentes valeurs sont déclarées sous forme de constante.
La fonction SQL retourne les SQL STATE suivants :
02000 lorsque l’on attend la fin des données (fin normale)
38999 pour les erreurs. Cette valeur est arbitraire
Si possible, nous retrouvons le libellé de l’erreur retournée par l’API via strerror et on le retourne à DB2.
Code RPG :
**free
// Compilation / liage :
// CRTRPGMOD MODULE(NB/VLDLUDTF) SRCFILE(NB/QRPGLESRC)
// OPTION(*EVENTF) DBGVIEW(*SOURCE)
// CRTSRVPGM SRVPGM(NB/VLDLUDTF) EXPORT(*ALL) ACTGRP(*CALLER)
// Implémentation de la fonction UDTF VALIDATION_LIST_ENTRIES
// Liste les entrées d'une liste de validation
// Utilise l'API QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
// @todo :
// - ajouter le support de la conversion de CCSID
// - améliorer la gestion des erreurs
ctl-opt nomain option(*srcstmt : *nodebugio) ;
// Déclarations pour APIs : QsyFindFirstValidationLstEntry et QsyFindNextValidationLstEntry
dcl-ds Qsy_Qual_Name_T qualified template ;
name char(10) inz ;
lib char(10) inz ;
end-ds ;
dcl-ds Qsy_Entry_ID_Info_T qualified template ;
Entry_ID_Len int(10) inz ;
Entry_ID_CCSID uns(10) inz ;
Entry_ID char(100) inz ;
end-ds ;
dcl-ds Qsy_Rtn_Vld_Lst_Ent_T qualified template ;
dcl-ds Entry_ID_Info likeds( Qsy_Entry_ID_Info_T) inz ;
dcl-ds Encr_Data_Info ;
Encr_Data_len int(10) inz;
Encr_Data_CCSID uns(10) inz;
Encr_Data char(600) inz ;
end-ds ;
dcl-ds Entry_Data_Info ;
Entry_Data_len int(10) ;
Entry_Data_CCSID uns(10) ;
Entry_Data char(1000) ;
end-ds ;
Reserved char(4) inz ;
Entry_More_Info char(100) inz ;
end-ds ;
dcl-pr QsyFindFirstValidationLstEntry int(10) extproc('QsyFindFirstValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
dcl-pr QsyFindNextValidationLstEntry int(10) extproc('QsyFindNextValidationLstEntry');
vldList likeds(Qsy_Qual_Name_T) const ;
entryIdInfo likeds(Qsy_Entry_ID_Info_T) ;
vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) ;
end-pr ;
// Retrouver le code erreur de l'API
dcl-pr getErrNo int(10) ;
end-pr ;
// Code erreur
dcl-c EACCES 3401 ;
dcl-c EAGAIN 3406 ;
dcl-c EDAMAGE 3484 ;
dcl-c EINVAL 3021 ;
dcl-c ENOENT 3025 ;
dcl-c ENOREC 3026 ;
dcl-c EUNKNOWN 3474 ;
// Retrouver le libellé du code erreur
dcl-pr strError pointer extproc(*CWIDEN : 'strerror') ;
errNo int(10) value ;
end-pr ;
// gestion UDTF
dcl-c CALL_OPEN -1;
dcl-c CALL_FETCH 0;
dcl-c CALL_CLOSE 1;
dcl-c PARM_NULL -1;
dcl-c PARM_NOTNULL 0;
// Liste les entrées de la liste de validation
// ==========================================================================
dcl-proc vldl_list export ;
// Déclarations globales
dcl-s ret int(10) inz ;
dcl-s errno int(10) inz ;
dcl-ds vldListEntry likeds(Qsy_Rtn_Vld_Lst_Ent_T) inz static ;
dcl-ds vldlname likeds(Qsy_Qual_Name_T) inz static ;
dcl-s first ind inz(*on) static ;
dcl-pi *n ;
// input parms
pvldl_lib varchar(10) const ;
pvldl_name varchar(10) const ;
// output columns
pEntry_ID varchar(100) ;
pEntry_Data varchar(1000) ;
// null indicators
pvldl_lib_n int(5) const ;
pvldl_name_n int(5) const ;
pEntry_ID_n int(5) ;
pEntry_Data_n int(5) ;
// db2sql
pstate char(5);
pFunction varchar(517) const;
pSpecific varchar(128) const;
perrorMsg varchar(1000);
pCallType int(10) const;
end-pi ;
// Paramètres en entrée
if pvldl_name_n = PARM_NULL or pvldl_lib_n = PARM_NULL;
pstate = '38999' ;
perrorMsg = 'VALIDATION_LIST_LIBRARY ou VALIDATION_LIST_NAME est null' ;
return ;
endif ;
select;
when ( pCallType = CALL_OPEN );
// appel initial : initialisation des variables statiques
vldlname.name = pvldl_name ;
vldlname.Lib = pvldl_lib ;
clear vldListEntry ;
first = *on ;
when ( pCallType = CALL_FETCH );
// retrouver l'entrée suivante
exsr doFetch ;
when ( pCallType = CALL_CLOSE );
// rien à faire
endsl;
// traitement de l'entrée suivante
begsr doFetch ;
if first ;
ret = QsyFindFirstValidationLstEntry( vldlname : vldListEntry);
first = *off ;
else ;
ret = QsyFindNextValidationLstEntry( vldlname :
vldListEntry.Entry_ID_Info : vldListEntry);
endif ;
if ret = 0 ;
// Entrée trouvée
monitor ;
pEntry_ID = %left(vldListEntry.Entry_ID_Info.Entry_ID :
vldListEntry.Entry_ID_Info.Entry_ID_Len);
pEntry_Data = %left(vldListEntry.Entry_Data_Info.Entry_Data :
vldListEntry.Entry_Data_Info.Entry_Data_len) ;
pEntry_ID_n = PARM_NOTNULL ;
pEntry_Data_n = PARM_NOTNULL ;
on-error ;
// Erreur de conversion
pstate = '38999' ;
perrorMsg = 'Erreur de conversion' ;
endmon ;
else ;
// Entrée non trouvée : erreur ou fin de lecture
errno = getErrNo() ;
select ;
when errno in %list( ENOENT : ENOREC ) ; // fin de lecture
pstate = '02000' ;
return ;
other ; // Erreur
pstate = '38999' ;
perrorMsg = %str(strError(errno)) ;
endsl ;
endif ;
endsr ;
end-proc ;
// Retrouver le code erreur de l'API
dcl-proc getErrNo ;
dcl-pr getErrNoPtr pointer ExtProc('__errno') ;
end-pr ;
dcl-pi *n int(10) ;
end-pi;
dcl-s errNo int(10) based(errNoPtr) ;
errNoPtr = getErrNoPtr() ;
return errNo ;
end-proc;
Code SQL :
set current schema = NB ;
set path = 'NB' ;
Create or replace Function VALIDATION_LIST_ENTRIES (
VALIDATION_LIST_LIBRARY varchar(10),
VALIDATION_LIST_NAME varchar(10) )
Returns Table
(
VALIDATION_USER varchar(100),
ENTRY_DATA varchar(1000)
)
external name 'VLDLUDTF(VLDL_LIST)'
language rpgle
parameter style db2sql
no sql
not deterministic
disallow parallel;
cl: DLTVLDL VLDL(NB/DEMO) ;
cl: CRTVLDL VLDL(NB/DEMO) TEXT('Démo VALIDATION_LIST_ENTRIES') ;
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 1',
PASSWORD => 'MDP user 1',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 2',
PASSWORD => 'MDP user 2',
ENTRY_DATA => 'Client 1'));
VALUES SYSTOOLS.ERRNO_INFO(SYSTOOLS.ADD_VALIDATION_LIST_ENTRY(
VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO',
VALIDATION_USER => 'user 3',
PASSWORD => 'MDP user 3',
ENTRY_DATA => 'Client 2'));
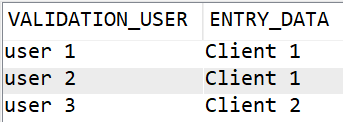
select * from table(VALIDATION_LIST_ENTRIES( VALIDATION_LIST_LIBRARY => 'NB',
VALIDATION_LIST_NAME => 'DEMO' )) ;
Cela produit :
Libre à vous maintenant d’utiliser ce résultat pour jointer avec vos fichiers de log HTTP (autorisation basique sur une liste de validation par exemple), avec le service USER_INFO_BASIC, croiser les profils présents dans vos différentes listes …
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-05-26 11:45:252025-05-26 11:45:26Gérer vos listes de validation avec SQL !